Ngôn ngữ lập trình Rust
biên soạn bởi Steve Klabnik, Carol Nichols, và Chris Krycho, với sự đóng góp của cộng đồng Rust
bản dịch Tiếng Việt được thực hiện bởi Tuấn Em, với sự đóng góp của cộng đồng Rust tại Việt Nam
Phiên bản này của cuốn sách giả định rằng bạn đang sử dụng Rust 1.90.0 (phát
hành ngày 18-09-2025) hoặc mới hơn với edition = "2024" trong tệp Cargo.toml
của tất cả các dự án để cấu hình chúng sử dụng các quy ước của Rust phiên
bản 2024. Xem phần “Cài đặt“ của Chương 1 để cài đặt
hoặc cập nhật Rust.
Định dạng HTML có sẵn trực tuyến tại
https://rust-book.tuanem.com/ và ngoại tuyến
với các bản cài đặt Rust được thực hiện với rustup; chạy lệnh
rustup doc --book để mở.
Một số bản dịch từ cộng đồng cũng có sẵn.
Cuốn sách này có bản in và định dạng ebook từ No Starch Press.
🚨 Bạn muốn có trải nghiệm học tập tương tác hơn? Hãy thử phiên bản khác của Sách Rust, với các tính năng: câu đố, làm nổi bật, trực quan hóa và nhiều hơn nữa: https://rust-book.cs.brown.edu
Lời nói đầu
Không phải lúc nào cũng rõ ràng, nhưng ngôn ngữ lập trình Rust về cơ bản là sự trao quyền: bất kể bạn đang viết code loại nào, Rust trao quyền cho bạn vươn xa hơn, tự tin lập trình trong nhiều lĩnh vực đa dạng hơn so với trước đây.
Ví dụ, hãy xem xét công việc "cấp hệ thống" liên quan đến các chi tiết cấp thấp của quản lý bộ nhớ, biểu diễn dữ liệu và tính đồng thời. Thông thường, lĩnh vực lập trình này được xem là khó hiểu, chỉ tiếp cận được với một số ít người đã dành nhiều năm học tập để tránh những lỗi tiềm ẩn phổ biến của nó. Và thậm chí những người làm việc với nó cũng vô cùng thận trọng, để tránh code của họ bị khai thác lỗ hổng, sập chương trình hoặc hư hỏng dữ liệu.
Rust phá vỡ những rào cản này bằng cách loại bỏ những lỗi tiềm ẩn cũ và cung cấp một bộ công cụ thân thiện, hoàn thiện để giúp bạn trên suốt chặng đường. Các lập trình viên cần "đi sâu" hơn vào kiểm soát cấp thấp có thể làm vậy với Rust mà không phải chấp nhận rủi ro thường gặp của sập chương trình hoặc lỗ hổng bảo mật, và không cần phải học các chi tiết phức tạp của một công cụ không ổn định. Hơn thế nữa, ngôn ngữ được thiết kế để hướng dẫn bạn viết code đáng tin cậy một cách tự nhiên, hiệu quả về cả tốc độ và sử dụng bộ nhớ.
Các lập trình viên đã làm việc với code cấp thấp có thể sử dụng Rust để nâng cao tham vọng của họ. Ví dụ, việc đưa tính song song vào Rust là một hoạt động tương đối ít rủi ro: trình biên dịch sẽ phát hiện các lỗi cổ điển cho bạn. Và bạn có thể giải quyết quyết liệt hơn các tối ưu hóa trong mã của mình với sự tự tin rằng bạn sẽ không vô tình gây ra sập chương trình hoặc lỗ hổng.
Nhưng Rust không giới hạn ở lập trình hệ thống cấp thấp. Nó đủ linh hoạt và tiện dụng để làm cho các ứng dụng CLI, máy chủ web và nhiều loại code khác trở nên khá dễ chịu để viết — bạn sẽ tìm thấy các ví dụ đơn giản về cả hai trong phần sau của cuốn sách. Làm việc với Rust cho phép bạn xây dựng kỹ năng có thể chuyển đổi từ lĩnh vực này sang lĩnh vực khác; bạn có thể học Rust bằng cách viết một ứng dụng web, sau đó áp dụng những kỹ năng tương tự đó để nhắm đến Raspberry Pi của bạn.
Cuốn sách này hoàn toàn khai thác tiềm năng của Rust trong việc trao quyền cho người dùng. Đây là một tài liệu thân thiện và dễ tiếp cận nhằm giúp bạn nâng cao không chỉ kiến thức về Rust, mà còn mở rộng hiểu biết và sự tự tin với tư cách là một lập trình viên nói chung. Vì vậy, hãy bắt đầu, sẵn sàng để học và chào mừng bạn đến với cộng đồng Rust!
— Nicholas Matsakis và Aaron Turon
Giới thiệu
Lưu ý: Phiên bản này của cuốn sách giống với The Rust Programming Language có sẵn ở dạng in và sách điện tử từ No Starch Press.
Chào mừng bạn đến với Ngôn ngữ lập trình Rust, một cuốn sách nhập môn về Rust. Ngôn ngữ lập trình Rust giúp bạn viết phần mềm nhanh hơn và đáng tin cậy hơn. Tính tiện dụng cấp cao và kiểm soát cấp thấp thường mâu thuẫn với nhau trong thiết kế ngôn ngữ lập trình; Rust thách thức xung đột đó. Thông qua cân bằng giữa năng lực kỹ thuật mạnh mẽ và trải nghiệm tuyệt vời của lập trình viên, Rust cho bạn lựa chọn để kiểm soát chi tiết cấp thấp (như sử dụng bộ nhớ) mà không gặp phải tất cả những rắc rối thường liên quan đến việc kiểm soát như vậy.
Rust dành cho ai
Rust lý tưởng cho nhiều người vì nhiều lý do khác nhau. Hãy xem xét một vài nhóm quan trọng nhất.
Các nhóm lập trình viên
Rust đang chứng minh là một công cụ hiệu quả cho việc hợp tác giữa các nhóm lớn gồm các lập trình viên với các mức độ kiến thức lập trình hệ thống khác nhau. Mã cấp thấp dễ bị các lỗi tinh vi, mà trong hầu hết các ngôn ngữ khác chỉ có thể phát hiện thông qua kiểm tra kỹ lưỡng và xem xét mã cẩn thận bởi các lập trình viên có kinh nghiệm. Trong Rust, trình biên dịch đóng vai trò như một người gác cổng bằng cách từ chối biên dịch mã với những lỗi khó nắm bắt này, bao gồm cả lỗi đồng thời. Bằng cách làm việc cùng với trình biên dịch, nhóm có thể tập trung thời gian vào logic của chương trình thay vì săn lùng lỗi.
Rust cũng mang đến các công cụ phát triển hiện đại cho thế giới lập trình hệ thống:
- Cargo, trình quản lý phụ thuộc và công cụ xây dựng đi kèm, giúp thêm, biên dịch và quản lý các phụ thuộc một cách dễ dàng và nhất quán trên toàn bộ hệ sinh thái Rust.
- Công cụ định dạng
rustfmtđảm bảo một phong cách viết mã nhất quán giữa các lập trình viên. - Rust Language Server cung cấp tích hợp với Môi trường Phát triển Tích hợp (IDE) cho việc hoàn thành mã và báo lỗi trực tiếp.
Bằng cách sử dụng các công cụ này và các công cụ khác trong hệ sinh thái Rust, các lập trình viên có thể làm việc hiệu quả trong khi viết mã cấp hệ thống.
Học sinh
Rust dành cho học sinh và những người quan tâm đến việc học về các khái niệm hệ thống. Sử dụng Rust, nhiều người đã học về các chủ đề như phát triển hệ điều hành. Cộng đồng rất chào đón và sẵn sàng trả lời các câu hỏi của học sinh. Thông qua các nỗ lực như cuốn sách này, các nhóm Rust muốn làm cho các khái niệm hệ thống trở nên dễ tiếp cận hơn với nhiều người, đặc biệt là những người mới bắt đầu lập trình.
Các công ty
Hàng trăm công ty, từ nhỏ đến lớn, sử dụng Rust trong môi trường production cho nhiều nhiệm vụ khác nhau, bao gồm các công cụ dòng lệnh, dịch vụ web, công cụ DevOps, thiết bị nhúng, phân tích và chuyển mã âm thanh và video, tiền điện tử, tin sinh học, công cụ tìm kiếm, ứng dụng Internet of Things, học máy, và thậm chí là các phần quan trọng của trình duyệt web Firefox.
Các nhà phát triển mã nguồn mở
Rust dành cho những người muốn xây dựng ngôn ngữ lập trình Rust, cộng đồng, công cụ phát triển và thư viện. Chúng tôi rất mong bạn đóng góp vào ngôn ngữ Rust.
Những người coi trọng tốc độ và sự ổn định
Rust dành cho những người khao khát tốc độ và sự ổn định trong một ngôn ngữ. Khi nói đến tốc độ, chúng tôi muốn nói về cả tốc độ chạy của mã Rust và tốc độ mà Rust cho phép bạn viết chương trình. Các kiểm tra của trình biên dịch Rust đảm bảo sự ổn định thông qua việc thêm tính năng và tái cấu trúc. Điều này trái ngược với mã cũ khó sửa đổi trong các ngôn ngữ không có các kiểm tra này, điều làm các nhà phát triển thường sợ sửa đổi. Bằng cách cố gắng đạt được các trừu tượng cấp cao không tốn kém biên dịch thành mã cấp thấp nhanh như mã viết thủ công - Rust cố gắng làm cho mã an toàn cũng trở thành mã nhanh.
Ngôn ngữ Rust hy vọng hỗ trợ nhiều người dùng khác nữa; những người được đề cập ở đây chỉ là một số bên liên quan nhất. Nhìn chung, tham vọng lớn nhất của Rust là loại bỏ các sự đánh đổi mà các lập trình viên đã chấp nhận trong nhiều thập kỷ bằng cách cung cấp sự an toàn và năng suất, tốc độ và tính tiện dụng. Hãy thử Rust và xem liệu các lựa chọn của nó có phù hợp với bạn không.
Cuốn sách này dành cho ai
Cuốn sách này giả định rằng bạn đã viết mã trong một ngôn ngữ lập trình khác, nhưng không giả định bạn đã viết mã trong ngôn ngữ nào. Chúng tôi đã cố gắng làm cho tài liệu này dễ tiếp cận rộng rãi với những người có nền tảng lập trình đa dạng. Chúng tôi không dành nhiều thời gian để nói về lập trình là gì hoặc cách suy nghĩ về nó. Nếu bạn hoàn toàn mới với lập trình, bạn sẽ được phục vụ tốt hơn bằng cách đọc một cuốn sách cung cấp một giới thiệu về lập trình.
Cách sử dụng cuốn sách này
Nói chung, cuốn sách này giả định rằng bạn đang đọc nó theo thứ tự từ đầu đến cuối. Các chương sau xây dựng trên các khái niệm trong các chương trước, và các chương trước có thể không đi sâu vào chi tiết về một chủ đề cụ thể nhưng sẽ xem xét lại chủ đề đó trong một chương sau.
Bạn sẽ tìm thấy hai loại chương trong cuốn sách này: các chương khái niệm và các chương dự án. Trong các chương khái niệm, bạn sẽ học về một khía cạnh của Rust. Trong các chương dự án, chúng ta sẽ cùng nhau xây dựng các chương trình nhỏ, áp dụng những gì bạn đã học được cho đến nay. Chương 2, Chương 12 và Chương 21 là các chương dự án; phần còn lại là các chương khái niệm.
Chương 1 giải thích cách cài đặt Rust, cách viết một chương trình “Hello, world!”, và cách sử dụng Cargo, trình quản lý gói và công cụ xây dựng của Rust. Chương 2 là một phần giới thiệu thực hành về việc viết một chương trình trong Rust, cho bạn xây dựng một trò chơi đoán số. Ở đây, chúng tôi đề cập đến các khái niệm ở mức cao, và các chương sau sẽ cung cấp thêm chi tiết. Nếu bạn muốn bắt tay vào làm ngay lập tức, Chương 2 là nơi dành cho bạn. Nếu bạn là một người học tỉ mỉ đặc biệt thích học mọi thứ chi tiết trước khi tiếp tục, bạn có thể muốn bỏ qua Chương 2 và đi thẳng đến Chương 3, đề cập đến các đặc điểm của Rust tương tự như các ngôn ngữ lập trình khác; sau đó, bạn có thể quay lại Chương 2 khi bạn muốn làm việc trên một dự án áp dụng các chi tiết bạn đã học.
Trong Chương 4 bạn sẽ học về hệ thống quyền sở hữu của Rust. Chương 5
thảo luận về struct và phương thức, và Chương 6 đề cập đến enum, biểu thức
match, và cấu trúc luồng điều khiển if let và let...else. Bạn sẽ sử dụng
struct và enum để tạo các kiểu dữ liệu tùy chỉnh trong Rust.
Trong Chương 7, bạn sẽ học về hệ thống module của Rust và về các quy tắc bảo mật để tổ chức mã của bạn và Giao diện Lập trình Ứng dụng (API) công khai của nó. Chương 8 thảo luận về một số cấu trúc dữ liệu collection phổ biến mà thư viện tiêu chuẩn cung cấp: vector, chuỗi và hash map. Chương 9 khám phá triết lý và kỹ thuật xử lý lỗi của Rust.
Chương 10 đi sâu vào generics, traits và lifetimes, cho bạn khả năng để định
nghĩa mã áp dụng cho nhiều kiểu dữ liệu. Chương 11 là tất cả về kiểm thử, mà
ngay cả với các đảm bảo an toàn của Rust cũng cần thiết để đảm bảo logic chương
trình của bạn là chính xác. Trong Chương 12, chúng ta sẽ triển khai xây dựng
cho riêng mình cho một phần chức năng của công cụ dòng lệnh grep tìm kiếm văn
bản trong các tệp. Để làm điều này, chúng ta sẽ sử dụng nhiều khái niệm đã thảo
luận trong các chương trước.
Chương 13 khám phá closure và iterator: các đặc điểm của Rust đến từ các ngôn ngữ lập trình hàm. Trong Chương 14, chúng ta sẽ xem xét Cargo sâu hơn và nói về các thực hành tốt nhất để chia sẻ thư viện của bạn với người khác. Chương 15 thảo luận về các con trỏ thông minh mà thư viện tiêu chuẩn cung cấp và các traits cần thiết cho chức năng của chúng.
Trong Chương 16, chúng ta sẽ đi qua các mô hình lập trình đồng thời khác nhau và nói về cách Rust giúp bạn lập trình trong nhiều luồng một cách không sợ hãi. Trong Chương 17, chúng ta xây dựng trên đó bằng cách khám phá cú pháp async và await của Rust, cùng với các task, future và stream, và mô hình đồng thời nhẹ mà chúng cho phép.
Chương 18 xem xét cách các đặc trưng của Rust so sánh với các nguyên tắc lập trình hướng đối tượng mà bạn có thể quen thuộc. Chương 19 là một tài liệu tham khảo về mẫu và khớp mẫu, là những cách mạnh mẽ để biểu đạt ý tưởng trong suốt các chương trình Rust. Chương 20 chứa một loạt các chủ đề nâng cao thú vị, bao gồm Rust không an toàn, macro, và tìm hiểu sâu hơn về lifetimes, traits, kiểu dữ liệu, hàm và closure.
Trong Chương 21, chúng ta sẽ hoàn thành một dự án trong đó chúng ta sẽ triển khai một máy chủ web đa luồng cấp thấp!
Cuối cùng, một số phụ lục chứa thông tin hữu ích về ngôn ngữ theo định dạng tham khảo hơn. Phụ lục A đề cập đến các từ khóa của Rust, Phụ lục B đề cập đến các toán tử và ký hiệu của Rust, Phụ lục C đề cập đến các traits có thể được dẫn xuất do thư viện tiêu chuẩn cung cấp, Phụ lục D đề cập đến một số công cụ phát triển hữu ích, và Phụ lục E giải thích các phiên bản Rust. Trong Phụ lục F, bạn có thể tìm thấy các bản dịch của cuốn sách, và trong Phụ lục G chúng tôi sẽ đề cập đến cách Rust được tạo ra và Rust nightly là gì.
Không có cách nào sai để đọc cuốn sách này: Nếu bạn muốn bỏ qua, hãy làm điều đó! Bạn có thể phải quay lại các chương trước nếu bạn gặp bất kỳ sự nhầm lẫn nào. Nhưng hãy làm bất cứ điều gì phù hợp với bạn.
Một phần quan trọng của quá trình học Rust là học cách đọc các thông báo lỗi mà trình biên dịch hiển thị: Những thông báo này sẽ hướng dẫn bạn đến mã chạy được. Vì vậy, chúng tôi sẽ cung cấp nhiều ví dụ không biên dịch cùng với thông báo lỗi mà trình biên dịch sẽ hiển thị cho bạn trong mỗi tình huống. Hãy biết rằng nếu bạn nhập và chạy một ví dụ ngẫu nhiên, nó có thể không biên dịch! Hãy chắc chắn rằng bạn đọc văn bản xung quanh để xem liệu ví dụ bạn đang cố gắng chạy sẽ gây lỗi hay không. Trong hầu hết các trường hợp, chúng tôi sẽ hướng dẫn bạn đến phiên bản chính xác của bất kỳ mã nào không biên dịch được. Ferris cũng sẽ giúp bạn phân biệt mã không chạy được:
| Ferris | Ý nghĩa |
|---|---|
 | Mã này không biên dịch! |
 | Mã này gây hoảng loạn! (panic!) |
 | Mã này không tạo ra hành vi mong muốn. |
Trong hầu hết các tình huống, chúng tôi sẽ dẫn bạn đến phiên bản chính xác của bất kỳ mã nào không biên dịch.
Mã nguồn
Các tệp mã nguồn mà từ đó cuốn sách này được tạo ra có thể được tìm thấy trên GitHub.
Bắt đầu
Hãy bắt đầu hành trình Rust của bạn! Có rất nhiều điều để học, nhưng mọi hành trình đều có điểm khởi đầu. Trong chương này, chúng ta sẽ thảo luận:
- Cài đặt Rust trên Linux, macOS và Windows
- Viết một chương trình in ra
Hello, world! - Sử dụng
cargo, trình quản lý gói và hệ thống build của Rust
Cài đặt
Bước đầu tiên là cài đặt Rust. Chúng ta sẽ tải Rust thông qua rustup, một công
cụ dòng lệnh để quản lý các phiên bản Rust và các công cụ liên quan. Bạn sẽ cần
kết nối internet để tải xuống.
Lưu ý: Nếu bạn không muốn sử dụng
rustupvì một số lý do, vui lòng xem trang Phương pháp Cài đặt Rust khác để biết thêm lựa chọn.
Các bước sau đây cài đặt phiên bản ổn định mới nhất của trình biên dịch Rust. Sự đảm bảo về tính ổn định của Rust đảm bảo rằng tất cả các ví dụ trong sách này biên dịch được sẽ tiếp tục biên dịch được với các phiên bản Rust mới hơn. Đầu ra có thể khác nhau một chút giữa các phiên bản vì Rust thường cải thiện thông báo lỗi và cảnh báo. Nói cách khác, bất kỳ phiên bản Rust ổn định, mới hơn nào mà bạn cài đặt bằng các bước này sẽ hoạt động như mong đợi với nội dung của cuốn sách này.
Ký hiệu Dòng lệnh
Trong chương này và xuyên suốt cuốn sách, chúng tôi sẽ hiển thị một số lệnh được sử dụng trong terminal. Các dòng mà bạn nên nhập vào terminal đều bắt đầu bằng
$. Bạn không cần phải gõ ký tự$; đó là dấu nhắc dòng lệnh được hiển thị để chỉ ra điểm bắt đầu của mỗi lệnh. Các dòng không bắt đầu bằng$thường hiển thị đầu ra của lệnh trước đó. Ngoài ra, các ví dụ dành riêng cho PowerShell sẽ sử dụng>thay vì$.
Cài đặt rustup trên Linux hoặc macOS
Nếu bạn đang sử dụng Linux hoặc macOS, mở terminal và nhập lệnh sau:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Lệnh này tải xuống một script và bắt đầu cài đặt công cụ rustup, công cụ này
sẽ cài đặt phiên bản ổn định mới nhất của Rust. Bạn có thể được yêu cầu nhập mật
khẩu. Nếu cài đặt thành công, dòng sau sẽ xuất hiện:
Rust is installed now. Great!
Bạn cũng sẽ cần một linker, là một chương trình mà Rust sử dụng để kết hợp các đầu ra đã biên dịch thành một tệp. Có khả năng bạn đã có sẵn một cái. Nếu bạn gặp lỗi linker, bạn nên cài đặt một trình biên dịch C, thường sẽ bao gồm một linker. Một trình biên dịch C cũng hữu ích vì một số gói Rust phổ biến phụ thuộc vào mã C và sẽ cần một trình biên dịch C.
Trên macOS, bạn có thể có một trình biên dịch C bằng cách chạy:
$ xcode-select --install
Người dùng Linux nên cài đặt GCC hoặc Clang, theo tài liệu của bản phân phối của
họ. Ví dụ, nếu bạn sử dụng Ubuntu, bạn có thể cài đặt gói build-essential.
Cài đặt rustup trên Windows
Trên Windows, truy cập https://www.rust-lang.org/tools/install và làm theo hướng dẫn để cài đặt Rust. Tại một số điểm trong quá trình cài đặt, bạn sẽ được yêu cầu cài đặt Visual Studio. Điều này cung cấp một linker và các thư viện gốc cần thiết để biên dịch chương trình. Nếu bạn cần thêm trợ giúp với bước này, xem https://rust-lang.github.io/rustup/installation/windows-msvc.html
Phần còn lại của cuốn sách này sử dụng các lệnh hoạt động trong cả cmd.exe và PowerShell. Nếu có sự khác biệt cụ thể, chúng tôi sẽ giải thích nên sử dụng cái nào.
Khắc phục sự cố
Để kiểm tra xem bạn đã cài đặt Rust đúng cách chưa, mở shell và nhập dòng này:
$ rustc --version
Bạn sẽ thấy số phiên bản, commit hash và ngày commit cho phiên bản ổn định mới nhất đã được phát hành, theo định dạng sau:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Nếu bạn thấy thông tin này, bạn đã cài đặt Rust thành công! Nếu bạn không thấy
thông tin này, kiểm tra xem Rust có trong biến hệ thống %PATH% của bạn như
sau.
Trong Windows CMD, sử dụng:
> echo %PATH%
Trong PowerShell, sử dụng:
> echo $env:Path
Trong Linux và macOS, sử dụng:
$ echo $PATH
Nếu tất cả đều đúng và Rust vẫn không hoạt động, có một số nơi bạn có thể nhận trợ giúp. Tìm hiểu cách liên hệ với các Rustaceans khác (một biệt danh ngớ ngẩn mà chúng tôi tự gọi mình) trên trang cộng đồng.
Cập nhật và gỡ cài đặt
Khi Rust đã được cài đặt qua rustup, việc cập nhật lên phiên bản mới phát hành
rất dễ dàng. Từ shell của bạn, chạy script cập nhật sau:
$ rustup update
Để gỡ cài đặt Rust và rustup, chạy script gỡ cài đặt sau từ shell của bạn:
$ rustup self uninstall
Đọc tài liệu cục bộ
Việc cài đặt Rust cũng bao gồm một bản sao cục bộ của tài liệu để bạn có thể đọc
nó khi không có kết nối internet. Chạy rustup doc để mở tài liệu cục bộ trong
trình duyệt của bạn.
Bất cứ khi nào một kiểu dữ liệu hoặc hàm được cung cấp bởi thư viện tiêu chuẩn và bạn không chắc chắn nó làm gì hoặc cách sử dụng nó, hãy sử dụng tài liệu giao diện lập trình ứng dụng (API) để tìm hiểu!
Sử dụng Trình soạn thảo văn bản và IDEs
Cuốn sách này không đưa ra giả định về công cụ bạn sử dụng để viết mã Rust. Hầu hết các trình soạn thảo văn bản đều có thể hoàn thành công việc! Tuy nhiên, nhiều trình soạn thảo văn bản và môi trường phát triển tích hợp (IDEs) có hỗ trợ tích hợp cho Rust. Bạn luôn có thể tìm thấy danh sách khá cập nhật của nhiều trình soạn thảo và IDE trên trang công cụ trên trang web Rust.
Làm việc ngoại tuyến với cuốn sách này
Trong một số ví dụ, chúng tôi sẽ sử dụng các gói Rust ngoài thư viện tiêu chuẩn.
Để làm việc qua các ví dụ đó, bạn sẽ cần có kết nối internet hoặc đã tải xuống
các phụ thuộc đó trước. Để tải xuống các phụ thuộc trước, bạn có thể chạy các
lệnh sau. (Chúng tôi sẽ giải thích cargo là gì và từng lệnh này làm gì chi
tiết sau.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Điều này sẽ lưu trữ các gói đã tải xuống để bạn không cần phải tải xuống chúng
sau này. Sau khi bạn đã chạy lệnh này, bạn không cần giữ thư mục
get-dependencies. Nếu bạn đã chạy lệnh này, bạn có thể sử dụng cờ --offline
với tất cả các lệnh cargo trong phần còn lại của cuốn sách để sử dụng các
phiên bản đã lưu trữ này thay vì cố gắng sử dụng mạng.
Xin chào, Thế giới!
Bây giờ bạn đã cài đặt Rust, đã đến lúc viết chương trình Rust đầu tiên của bạn.
Theo truyền thống khi học một ngôn ngữ mới, chúng ta thường viết một chương
trình nhỏ in ra dòng chữ Hello, world! lên màn hình, vì vậy chúng ta sẽ làm
điều tương tự ở đây!
Lưu ý: Cuốn sách này giả định bạn đã có kiến thức cơ bản về dòng lệnh. Rust không đưa ra yêu cầu cụ thể nào về công cụ soạn thảo hoặc nơi lưu trữ mã của bạn, vì vậy nếu bạn thích sử dụng IDE thay vì dòng lệnh, hãy tự nhiên sử dụng IDE yêu thích của bạn. Nhiều IDE hiện nay có một số mức độ hỗ trợ Rust; hãy kiểm tra tài liệu của IDE để biết chi tiết. Đội ngũ Rust đã tập trung vào việc hỗ trợ IDE thông qua
rust-analyzer. Xem Phụ lục D để biết thêm chi tiết.
Thiết lập thư mục dự án
Bạn sẽ bắt đầu bằng việc tạo một thư mục để lưu trữ mã Rust của bạn. Đối với Rust, nơi lưu trữ mã của bạn không quan trọng, nhưng đối với các bài tập và dự án trong sách này, chúng tôi gợi ý tạo một thư mục projects trong thư mục home của bạn và lưu giữ tất cả các dự án của bạn ở đó.
Mở một terminal và nhập các lệnh sau để tạo một thư mục projects và một thư mục cho dự án “Hello, world!” trong thư mục projects.
Đối với Linux, macOS và PowerShell trên Windows, nhập:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Đối với Windows CMD, nhập:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Chương trình Rust cơ bản
Tiếp theo, tạo một tệp nguồn mới và gọi nó là main.rs. Các tệp Rust luôn kết thúc bằng phần mở rộng .rs. Nếu bạn sử dụng nhiều hơn một từ trong tên tệp của mình, quy ước là sử dụng dấu gạch dưới để tách chúng. Ví dụ, sử dụng hello_world.rs thay vì helloworld.rs.
Bây giờ mở tệp main.rs mà bạn vừa tạo và nhập mã trong Listing 1-1.
fn main() { println!("Hello, world!"); }
Lưu tệp và quay lại cửa sổ terminal của bạn trong thư mục ~/projects/hello_world. Trên Linux hoặc macOS, nhập các lệnh sau để biên dịch và chạy tệp:
$ rustc main.rs
$ ./main
Hello, world!
Trên Windows, nhập lệnh .\main thay vì ./main:
> rustc main.rs
> .\main
Hello, world!
Bất kể hệ điều hành của bạn là gì, chuỗi Hello, world! sẽ được in ra terminal.
Nếu bạn không thấy đầu ra này, hãy tham khảo lại phần “Khắc phục sự
cố” của phần Cài đặt để biết cách nhận trợ
giúp.
Nếu Hello, world! đã được in ra, chúc mừng bạn! Bạn đã chính thức viết một
chương trình Rust. Điều đó làm cho bạn trở thành một lập trình viên Rust — chào
mừng!
Cấu trúc của một chương trình Rust
Hãy xem xét chi tiết chương trình “Hello, world!” này. Đây là mảnh ghép đầu tiên:
fn main() { }
Những dòng này định nghĩa một hàm tên là main. Hàm main là một hàm đặc biệt:
Nó luôn là mã đầu tiên chạy trong mọi chương trình Rust thực thi. Ở đây, dòng
đầu tiên khai báo một hàm tên là main không có tham số và không trả về gì. Nếu
có tham số, chúng sẽ nằm trong dấu ngoặc đơn (()).
Thân hàm được bao bọc trong {}. Rust yêu cầu dấu ngoặc nhọn xung quanh tất cả
thân hàm. Đó là phong cách tốt để đặt dấu ngoặc nhọn mở trên cùng một dòng với
khai báo hàm, thêm một khoảng trắng ở giữa.
Lưu ý: Nếu bạn muốn tuân theo một phong cách chuẩn trong các dự án Rust, bạn có thể sử dụng công cụ định dạng tự động gọi là
rustfmtđể định dạng mã của bạn theo một phong cách cụ thể (đọc thêm vềrustfmttrong Phụ lục D). Đội ngũ phát triển Rust đã bao gồm công cụ này trong bản phân phối Rust tiêu chuẩn, giống nhưrustc, vì vậy nó có thể đã được cài đặt trên máy tính của bạn!
Thân hàm main chứa mã sau:
#![allow(unused)] fn main() { println!("Hello, world!"); }
Dòng này thực hiện tất cả công việc trong chương trình nhỏ này: Nó in văn bản lên màn hình. Có ba chi tiết quan trọng cần chú ý ở đây.
Đầu tiên, println! là một macro của Rust. Thay vì nếu nó được gọi là một hàm,
nó sẽ được nhập là println (không có !). Các macro của Rust là một cách để
viết mã tạo ra mã để mở rộng cú pháp Rust, và chúng ta sẽ thảo luận chi tiết hơn
về chúng trong Chương 20. Hiện tại, bạn chỉ cần
biết rằng việc sử dụng ! có nghĩa là bạn đang gọi một macro thay vì một hàm
bình thường và các macro không luôn tuân theo các quy tắc giống như các hàm.
Thứ hai, bạn thấy chuỗi "Hello, world!". Chúng ta truyền chuỗi này làm đối số
cho println!, và chuỗi được in ra màn hình.
Thứ ba, chúng ta kết thúc dòng bằng dấu chấm phẩy (;), điều này cho biết rằng
biểu thức này đã kết thúc, và biểu thức tiếp theo đã sẵn sàng để bắt đầu. Hầu
hết các dòng mã Rust kết thúc bằng dấu chấm phẩy.
Biên dịch và Chạy
Bạn vừa chạy một chương trình mới tạo, vì vậy hãy xem xét từng bước trong quá trình.
Trước khi chạy một chương trình Rust, bạn phải biên dịch nó bằng trình biên dịch
Rust bằng cách nhập lệnh rustc và truyền cho nó tên tệp nguồn của bạn, như thế
này:
$ rustc main.rs
Nếu bạn có nền tảng C hoặc C++, bạn sẽ nhận thấy điều này tương tự như gcc
hoặc clang. Sau khi biên dịch thành công, Rust xuất ra một tệp thực thi nhị
phân.
Trên Linux, macOS và PowerShell trên Windows, bạn có thể thấy tệp thực thi bằng
cách nhập lệnh ls trong shell của bạn:
$ ls
main main.rs
Trên Linux và macOS, bạn sẽ thấy hai tệp. Với PowerShell trên Windows, bạn sẽ thấy ba tệp giống như bạn sẽ thấy khi sử dụng CMD. Với CMD trên Windows, bạn sẽ nhập lệnh sau:
> dir /B %= tùy chọn /B chỉ hiển thị tên tệp =%
main.exe
main.pdb
main.rs
Điều này hiển thị tệp mã nguồn với phần mở rộng .rs, tệp thực thi (main.exe trên Windows, nhưng main trên tất cả các nền tảng khác), và, khi sử dụng Windows, một tệp chứa thông tin gỡ lỗi với phần mở rộng .pdb. Từ đây, bạn chạy tệp main hoặc main.exe, như sau:
$ ./main # hoặc .\main trên Windows
Nếu main.rs của bạn là chương trình “Hello, world!” của bạn, dòng này sẽ in
Hello, world! lên terminal của bạn.
Nếu bạn quen thuộc hơn với một ngôn ngữ động, chẳng hạn như Ruby, Python hoặc JavaScript, bạn có thể không quen với việc biên dịch và chạy một chương trình như các bước riêng biệt. Rust là một ngôn ngữ biên dịch trước (ahead-of-time compiled), có nghĩa là bạn có thể biên dịch một chương trình và đưa tệp thực thi cho người khác, và họ có thể chạy nó ngay cả khi không cài đặt Rust. Nếu bạn đưa cho ai đó một tệp .rb, .py hoặc .js, họ cần phải có một triển khai Ruby, Python hoặc JavaScript tương ứng được cài đặt. Nhưng trong những ngôn ngữ đó, bạn chỉ cần một lệnh để biên dịch và chạy chương trình của bạn. Mọi thứ đều là sự đánh đổi trong thiết kế ngôn ngữ.
Chỉ biên dịch với rustc là đủ cho các chương trình đơn giản, nhưng khi dự án
của bạn phát triển, bạn sẽ muốn quản lý tất cả các tùy chọn và làm cho việc chia
sẻ mã của bạn trở nên dễ dàng. Tiếp theo, chúng tôi sẽ giới thiệu cho bạn công
cụ Cargo, công cụ sẽ giúp bạn viết các chương trình Rust thực tế.
Xin chào, Cargo!
Cargo là hệ thống build và quản lý gói của Rust. Hầu hết các Rustacean (lập trình viên Rust) đều sử dụng công cụ này để quản lý các dự án Rust vì Cargo xử lý nhiều tác vụ cho bạn, chẳng hạn như xây dựng code, tải xuống các thư viện mà code của bạn phụ thuộc và build các thư viện đó. (Chúng tôi gọi các thư viện mà code của bạn cần là dependencies - các phụ thuộc.)
Các chương trình Rust đơn giản nhất, như cái chúng ta đã viết cho đến giờ, không có bất kỳ phụ thuộc nào. Nếu chúng ta xây dựng dự án "Hello, world!" với Cargo, nó sẽ chỉ sử dụng một phần của Cargo cho việc xử lý build code của bạn. Khi bạn viết các chương trình Rust phức tạp hơn, bạn sẽ thêm các phụ thuộc, và nếu bạn bắt đầu một dự án bằng Cargo, việc thêm phụ thuộc sẽ dễ dàng hơn nhiều.
Vì phần lớn các dự án Rust sử dụng Cargo, phần còn lại của cuốn sách này giả định rằng bạn cũng đang sử dụng Cargo. Cargo được cài đặt cùng với Rust nếu bạn đã sử dụng trình cài đặt chính thức được thảo luận trong phần "Cài đặt". Nếu bạn đã cài đặt Rust thông qua một số phương tiện khác, hãy kiểm tra xem Cargo đã được cài đặt chưa bằng cách nhập lệnh sau vào terminal của bạn:
$ cargo --version
Nếu bạn thấy một số phiên bản, bạn đã có nó! Nếu bạn thấy một lỗi, chẳng hạn như
command not found, hãy xem tài liệu cho phương thức cài đặt của bạn để xác
định cách cài đặt Cargo riêng biệt.
Tạo một dự án với Cargo
Hãy tạo một dự án mới sử dụng Cargo và xem nó khác với dự án "Hello, world!" ban đầu của chúng ta như thế nào. Quay lại thư mục projects của bạn (hoặc bất cứ nơi nào bạn đã quyết định lưu trữ code). Sau đó, trên bất kỳ hệ điều hành nào, chạy lệnh sau:
$ cargo new hello_cargo
$ cd hello_cargo
Lệnh đầu tiên tạo một thư mục và dự án mới có tên hello_cargo. Chúng ta đã đặt tên dự án là hello_cargo, và Cargo tạo các tệp của nó trong một thư mục cùng tên.
Đi vào thư mục hello_cargo và liệt kê các tệp. Bạn sẽ thấy rằng Cargo đã tạo hai tệp và một thư mục cho chúng ta: một tệp Cargo.toml và một thư mục src với một tệp main.rs bên trong.
Nó cũng đã khởi tạo một repository Git mới cùng với tệp .gitignore. Các tệp
Git sẽ không được tạo nếu bạn chạy cargo new trong một Git repository đã tồn
tại; bạn có thể ghi đè hành vi này bằng cách sử dụng cargo new --vcs=git.
Lưu ý: Git là một hệ thống quản lý phiên bản phổ biến. Bạn có thể thay đổi
cargo newđể sử dụng một hệ thống quản lý phiên bản khác hoặc không sử dụng hệ thống quản lý phiên bản nào bằng cách sử dụng cờ--vcs. Chạycargo new --helpđể xem các tùy chọn có sẵn.
Mở Cargo.toml trong trình soạn thảo văn bản bạn chọn. Nó sẽ trông giống với mã trong Listing 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
Tệp này có định dạng TOML (Tom's Obvious, Minimal Language), đây là định dạng cấu hình của Cargo.
Dòng đầu tiên, [package], là một tiêu đề phần cho biết rằng các câu lệnh tiếp
theo đang cấu hình một gói. Khi chúng ta thêm thông tin vào tệp này, chúng ta sẽ
thêm các phần khác.
Ba dòng tiếp theo thiết lập thông tin cấu hình mà Cargo cần để biên dịch chương
trình của bạn: tên, phiên bản và phiên bản của Rust để sử dụng. Chúng ta sẽ nói
về khóa edition trong Phụ lục E.
Dòng cuối cùng, [dependencies], là phần bắt đầu cho bạn liệt kê bất kỳ phụ
thuộc nào của dự án. Trong Rust, các gói mã được gọi là crates. Chúng ta sẽ
không cần bất kỳ crate nào khác cho dự án này, nhưng chúng ta sẽ cần trong dự án
đầu tiên ở Chương 2, vì vậy chúng ta sẽ sử dụng phần phụ thuộc này sau.
Bây giờ mở src/main.rs và xem qua:
Tên tệp: src/main.rs
fn main() { println!("Hello, world!"); }
Cargo đã tạo một chương trình "Hello, world!" cho bạn, giống như cái mà chúng ta đã viết trong Listing 1-1! Cho đến nay, sự khác biệt giữa dự án của chúng ta và dự án mà Cargo đã tạo là Cargo đặt mã trong thư mục src, và chúng ta có một tệp cấu hình Cargo.toml ở thư mục cấp cao nhất.
Cargo mong muốn các tệp mã nguồn của bạn nằm trong thư mục src. Thư mục dự án cấp cao nhất chỉ dành cho các tệp README, thông tin giấy phép, các tệp cấu hình và bất kỳ thứ gì khác không liên quan đến mã của bạn. Sử dụng Cargo giúp bạn tổ chức các dự án. Có một vị trí cho mọi thứ, và mọi thứ đều ở đúng vị trí.
Nếu bạn đã bắt đầu một dự án không sử dụng Cargo, như chúng ta đã làm với dự án
"Hello, world!", bạn có thể chuyển đổi nó thành một dự án sử dụng Cargo. Di
chuyển mã dự án vào thư mục src và tạo một tệp Cargo.toml thích hợp. Một
cách dễ dàng để có được tệp Cargo.toml đó là chạy cargo init, nó sẽ tạo tự
động cho bạn.
Xây dựng và chạy một dự án Cargo
Bây giờ hãy xem có gì khác khi chúng ta xây dựng và chạy chương trình "Hello, world!" với Cargo! Từ thư mục hello_cargo của bạn, xây dựng dự án của bạn bằng cách nhập lệnh sau:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Lệnh này tạo một tệp thực thi trong target/debug/hello_cargo (hoặc target\debug\hello_cargo.exe trên Windows) thay vì trong thư mục hiện tại của bạn. Vì bản dựng mặc định là bản dựng debug, Cargo đặt tệp nhị phân vào một thư mục có tên debug. Bạn có thể chạy tệp thực thi bằng lệnh này:
$ ./target/debug/hello_cargo # hoặc .\target\debug\hello_cargo.exe trên Windows
Hello, world!
Nếu mọi việc suôn sẻ, Hello, world! sẽ được in ra terminal. Chạy cargo build
lần đầu tiên cũng khiến Cargo tạo một tệp mới ở cấp cao nhất: Cargo.lock. Tệp
này theo dõi các phiên bản chính xác của các phụ thuộc trong dự án của bạn. Dự
án này không có phụ thuộc, vì vậy tệp hơi thưa thớt. Bạn sẽ không bao giờ cần
thay đổi tệp này theo cách thủ công; Cargo quản lý nội dung của nó cho bạn.
Chúng ta vừa xây dựng một dự án với cargo build và chạy nó với
./target/debug/hello_cargo, nhưng chúng ta cũng có thể sử dụng cargo run để
biên dịch mã và sau đó chạy tệp thực thi kết quả tất cả trong một lệnh:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Sử dụng cargo run thuận tiện hơn việc phải nhớ chạy cargo build và sau đó sử
dụng toàn bộ đường dẫn đến tệp nhị phân, vì vậy hầu hết các nhà phát triển sử
dụng cargo run.
Lưu ý rằng lần này chúng ta không thấy đầu ra cho biết rằng Cargo đang biên dịch
hello_cargo. Cargo nhận ra rằng các tệp không thay đổi, vì vậy nó đã không xây
dựng lại mà chỉ chạy tệp nhị phân. Nếu bạn đã sửa đổi mã nguồn, Cargo sẽ xây
dựng lại dự án trước khi chạy nó, và bạn sẽ thấy đầu ra này:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo cũng cung cấp một lệnh có tên là cargo check. Lệnh này nhanh chóng kiểm
tra mã của bạn để đảm bảo nó biên dịch được nhưng không tạo ra tệp thực thi:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Tại sao bạn lại không muốn có một tệp thực thi? Thông thường, cargo check
nhanh hơn nhiều so với cargo build vì nó bỏ qua bước tạo ra tệp thực thi. Nếu
bạn đang liên tục kiểm tra công việc của mình trong khi viết mã, việc sử dụng
cargo check sẽ tăng tốc quá trình cho bạn biết liệu dự án của bạn vẫn đang
biên dịch hay không! Như vậy, nhiều Rustacean chạy cargo check định kỳ khi họ
viết chương trình của họ để đảm bảo nó biên dịch. Sau đó, họ chạy cargo build
khi họ sẵn sàng sử dụng tệp thực thi.
Hãy tổng kết những gì chúng ta đã học được cho đến nay về Cargo:
- Chúng ta có thể tạo một dự án bằng
cargo new. - Chúng ta có thể xây dựng một dự án bằng
cargo build. - Chúng ta có thể xây dựng và chạy một dự án trong một bước bằng
cargo run. - Chúng ta có thể xây dựng một dự án mà không tạo ra tệp nhị phân để kiểm tra
lỗi bằng
cargo check. - Thay vì lưu kết quả của bản dựng trong cùng thư mục với mã của chúng ta, Cargo lưu trữ nó trong thư mục target/debug.
Một lợi ích bổ sung của việc sử dụng Cargo là các lệnh giống nhau bất kể bạn đang làm việc trên hệ điều hành nào. Vì vậy, tại thời điểm này, chúng tôi sẽ không cung cấp hướng dẫn cụ thể cho Linux và macOS so với Windows nữa.
Build cho release (phát hành)
Khi dự án của bạn cuối cùng đã sẵn sàng để phát hành, bạn có thể sử dụng
cargo build --release để biên dịch nó với các tối ưu hóa. Lệnh này sẽ tạo một
tệp thực thi trong target/release thay vì target/debug. Các tối ưu hóa làm
cho mã Rust của bạn chạy nhanh hơn, nhưng việc bật chúng làm kéo dài thời gian
biên dịch chương trình. Đây là lý do tại sao có hai hồ sơ khác nhau: một cho
phát triển, khi bạn muốn xây dựng lại nhanh chóng và thường xuyên, và một khác
để xây dựng chương trình cuối cùng mà bạn sẽ giao cho người dùng, sẽ không được
xây dựng lại nhiều lần và sẽ chạy nhanh nhất có thể. Nếu bạn đang đo hiệu suất
thời gian chạy của mã, hãy chắc chắn chạy cargo build --release và đo hiệu
suất với tệp thực thi trong target/release.
Tận dụng các quy ước của Cargo
Với các dự án đơn giản, Cargo không cung cấp nhiều giá trị hơn so với chỉ sử
dụng rustc, nhưng nó sẽ chứng minh giá trị của nó khi chương trình của bạn trở
nên phức tạp hơn. Khi chương trình phát triển thành nhiều tệp hoặc cần một phụ
thuộc, thì sẽ dễ dàng hơn nhiều để Cargo phối hợp việc xây dựng.
Mặc dù dự án hello_cargo đơn giản, nhưng bây giờ nó sử dụng nhiều công cụ thực
tế mà bạn sẽ sử dụng trong phần còn lại của sự nghiệp Rust của mình. Trên thực
tế, để làm việc trên bất kỳ dự án hiện có nào, bạn có thể sử dụng các lệnh sau
để kiểm tra mã sử dụng Git, thay đổi thành thư mục của dự án đó, và xây dựng:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Để biết thêm thông tin về Cargo, hãy xem tài liệu của nó.
Tóm tắt
Bạn đã có một khởi đầu tuyệt vời cho hành trình Rust của mình! Trong chương này, bạn đã học cách:
- Cài đặt phiên bản Rust ổn định mới nhất sử dụng
rustup. - Cập nhật lên phiên bản Rust mới hơn.
- Mở tài liệu đã cài đặt cục bộ.
- Viết và chạy chương trình "Hello, world!" sử dụng
rustctrực tiếp. - Tạo và chạy một dự án mới sử dụng các quy ước của Cargo.
Đây là thời điểm tuyệt vời để xây dựng một chương trình đáng kể hơn để làm quen với việc đọc và viết mã Rust. Vì vậy, trong Chương 2, chúng ta sẽ xây dựng một chương trình trò chơi đoán số. Nếu bạn thích bắt đầu bằng cách học cách các khái niệm lập trình phổ biến hoạt động trong Rust, hãy xem Chương 3 và sau đó quay lại Chương 2.
Lập Trình Một Trò Chơi Đoán Số
Hãy cùng bắt đầu làm quen với Rust thông qua một dự án thực tế! Chương này sẽ
giới thiệu cho bạn một số khái niệm phổ biến trong Rust bằng cách hướng dẫn bạn
sử dụng chúng trong một chương trình thực tế. Bạn sẽ học về let, match,
phương thức, hàm liên kết, crate bên ngoài và nhiều hơn nữa! Trong các chương
tiếp theo, chúng ta sẽ khám phá những ý tưởng này chi tiết hơn. Trong chương
này, bạn chỉ cần thực hành những kiến thức cơ bản.
Chúng ta sẽ triển khai một bài tập lập trình cổ điển dành cho người mới bắt đầu: trò chơi đoán số. Trò chơi hoạt động như sau: Chương trình sẽ tạo ra một số nguyên ngẫu nhiên từ 1 đến 100. Sau đó, chương trình sẽ yêu cầu người chơi nhập vào một số để đoán. Sau khi nhập số đoán, chương trình sẽ cho biết số đoán đó là quá nhỏ hay quá lớn. Nếu số đoán chính xác, trò chơi sẽ in ra thông báo chúc mừng và kết thúc.
Thiết Lập Một Dự Án Mới
Để thiết lập một dự án mới, hãy đi đến thư mục projects mà bạn đã tạo trong Chương 1 và tạo một dự án mới bằng Cargo, như sau:
$ cargo new guessing_game
$ cd guessing_game
Lệnh đầu tiên, cargo new, lấy tên của dự án (guessing_game) làm đối số đầu
tiên. Lệnh thứ hai sẽ chuyển đến thư mục của dự án mới.
Hãy xem file Cargo.toml đã được tạo ra:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
Như bạn đã thấy trong Chương 1, cargo new tạo ra một chương trình “Hello,
world!” cho bạn. Hãy xem file src/main.rs:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
Bây giờ hãy biên dịch chương trình “Hello, world!” này và chạy nó trong cùng một
bước bằng cách sử dụng lệnh cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
Lệnh run rất hữu ích khi bạn cần lặp lại nhanh chóng trên một dự án, như chúng
ta sẽ làm trong trò chơi này, nhanh chóng kiểm tra từng lần lặp trước khi chuyển
sang lần tiếp theo.
Mở lại file src/main.rs. Bạn sẽ viết tất cả mã trong file này.
Xử Lý Một Số Đoán
Phần đầu tiên của chương trình trò chơi đoán số sẽ yêu cầu người dùng nhập vào, xử lý đầu vào đó và kiểm tra xem đầu vào có đúng dạng mong đợi hay không. Để bắt đầu, chúng ta sẽ cho phép người chơi nhập vào một số đoán. Nhập mã trong Listing 2-1 vào src/main.rs.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Mã này chứa rất nhiều thông tin, vì vậy hãy đi qua từng dòng một. Để lấy đầu vào
từ người dùng và sau đó in kết quả ra màn hình, chúng ta cần đưa thư viện đầu
vào/đầu ra io vào phạm vi. Thư viện io đến từ thư viện tiêu chuẩn, được gọi
là std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Theo mặc định, Rust có một tập hợp các mục được định nghĩa trong thư viện tiêu chuẩn mà nó đưa vào phạm vi của mọi chương trình. Tập hợp này được gọi là prelude, và bạn có thể xem tất cả trong tài liệu thư viện tiêu chuẩn.
Nếu một kiểu bạn muốn sử dụng không có trong prelude, bạn phải đưa kiểu đó vào
phạm vi rõ ràng bằng một câu lệnh use. Sử dụng thư viện std::io cung cấp cho
bạn một số tính năng hữu ích, bao gồm khả năng chấp nhận đầu vào từ người dùng.
Như bạn đã thấy trong Chương 1, hàm main là điểm vào của chương trình:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Cú pháp fn khai báo một hàm mới; dấu ngoặc đơn, (), chỉ ra rằng không có
tham số; và dấu ngoặc nhọn, {, bắt đầu thân của hàm.
Như bạn cũng đã học trong Chương 1, println! là một macro in một chuỗi ra màn
hình:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Mã này đang in ra một lời nhắc cho biết trò chơi là gì và yêu cầu đầu vào từ người dùng.
Lưu Trữ Giá Trị Với Biến
Tiếp theo, chúng ta sẽ tạo một biến để lưu trữ đầu vào từ người dùng, như sau:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Bây giờ chương trình đang trở nên thú vị! Có rất nhiều điều đang diễn ra trong
dòng nhỏ này. Chúng ta sử dụng câu lệnh let để tạo biến. Đây là một ví dụ
khác:
let apples = 5;Dòng này tạo ra một biến mới có tên là apples và gán nó với giá trị 5. Trong
Rust, các biến mặc định là không thay đổi, có nghĩa là một khi chúng ta gán giá
trị cho biến, giá trị đó sẽ không thay đổi. Chúng ta sẽ thảo luận chi tiết về
khái niệm này trong phần “Biến và Tính Không Thay
Đổi” trong Chương 3. Để làm cho một
biến có thể thay đổi, chúng ta thêm mut trước tên biến:
let apples = 5; // không thay đổi
let mut bananas = 5; // có thể thay đổiLưu ý: Cú pháp
//bắt đầu một bình luận kéo dài đến cuối dòng. Rust bỏ qua mọi thứ trong bình luận. Chúng ta sẽ thảo luận chi tiết về bình luận trong Chương 3.
Quay lại chương trình trò chơi đoán số, bây giờ bạn đã biết rằng let mut guess
sẽ giới thiệu một biến có thể thay đổi có tên là guess. Dấu bằng (=) cho
Rust biết chúng ta muốn gán một cái gì đó cho biến ngay bây giờ. Ở bên phải của
dấu bằng là giá trị mà guess được gán, đó là kết quả của việc gọi
String::new, một hàm trả về một phiên bản mới của một String.
String là một kiểu chuỗi được cung cấp bởi thư viện
tiêu chuẩn, là một đoạn văn bản có thể mở rộng, được mã hóa UTF-8.
Cú pháp :: trong dòng ::new chỉ ra rằng new là một hàm liên kết của kiểu
String. Một hàm liên kết là một hàm được triển khai trên một kiểu, trong
trường hợp này là String. Hàm new này tạo ra một chuỗi mới, trống. Bạn sẽ
tìm thấy một hàm new trên nhiều kiểu vì nó là một tên phổ biến cho một hàm tạo
ra một giá trị mới của một loại nào đó.
Tóm lại, dòng let mut guess = String::new(); đã tạo ra một biến có thể thay
đổi hiện đang được gán với một phiên bản mới, trống của một String. Whew!
Nhận Đầu Vào Từ Người Dùng
Nhớ lại rằng chúng ta đã bao gồm chức năng đầu vào/đầu ra từ thư viện tiêu chuẩn
với use std::io; ở dòng đầu tiên của chương trình. Bây giờ chúng ta sẽ gọi hàm
stdin từ module io, điều này sẽ cho phép chúng ta xử lý đầu vào từ người
dùng:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Nếu chúng ta không nhập module io với use std::io; ở đầu chương trình, chúng
ta vẫn có thể sử dụng hàm này bằng cách viết lời gọi hàm này là
std::io::stdin. Hàm stdin trả về một phiên bản của
std::io::Stdin, là một kiểu đại diện cho một tay cầm
đến đầu vào tiêu chuẩn cho terminal của bạn.
Tiếp theo, dòng .read_line(&mut guess) gọi phương thức
read_line trên tay cầm đầu vào tiêu chuẩn để lấy
đầu vào từ người dùng. Chúng ta cũng đang truyền &mut guess làm đối số cho
read_line để cho nó biết chuỗi nào để lưu trữ đầu vào từ người dùng. Công việc
đầy đủ của read_line là lấy bất cứ thứ gì người dùng nhập vào đầu vào tiêu
chuẩn và thêm vào một chuỗi (mà không ghi đè nội dung của nó), vì vậy chúng ta
truyền chuỗi đó làm đối số. Đối số chuỗi cần phải có thể thay đổi để phương thức
có thể thay đổi nội dung của chuỗi.
Dấu & chỉ ra rằng đối số này là một tham chiếu, điều này cho bạn một cách để
cho nhiều phần của mã truy cập vào một phần dữ liệu mà không cần phải sao chép
dữ liệu đó vào bộ nhớ nhiều lần. Tham chiếu là một tính năng phức tạp, và một
trong những lợi thế lớn của Rust là cách sử dụng tham chiếu an toàn và dễ dàng.
Bạn không cần phải biết nhiều chi tiết đó để hoàn thành chương trình này. Hiện
tại, tất cả những gì bạn cần biết là, giống như các biến, các tham chiếu mặc
định là không thay đổi. Do đó, bạn cần viết &mut guess thay vì &guess để làm
cho nó có thể thay đổi. (Chương 4 sẽ giải thích tham chiếu chi tiết hơn.)
Xử Lý Khả Năng Thất Bại Với Result
Chúng ta vẫn đang làm việc trên dòng mã này. Chúng ta hiện đang thảo luận về dòng văn bản thứ ba, nhưng lưu ý rằng nó vẫn là một phần của một dòng mã logic duy nhất. Phần tiếp theo là phương thức này:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Chúng ta có thể đã viết mã này như sau:
io::stdin().read_line(&mut guess).expect("Failed to read line");Tuy nhiên, một dòng dài rất khó đọc, vì vậy tốt nhất là chia nó ra. Thường thì
nên giới thiệu một dòng mới và các khoảng trắng khác để giúp chia nhỏ các dòng
dài khi bạn gọi một phương thức với cú pháp .method_name(). Bây giờ hãy thảo
luận về những gì dòng này làm.
Như đã đề cập trước đó, read_line đặt bất cứ thứ gì người dùng nhập vào chuỗi
mà chúng ta truyền cho nó, nhưng nó cũng trả về một giá trị Result.
Result là một liệt kê,
thường được gọi là enum, là một kiểu có thể ở một trong nhiều trạng thái có
thể. Chúng ta gọi mỗi trạng thái có thể là một biến thể.
Chương 6 sẽ bao gồm các enum chi tiết hơn. Mục đích của
các kiểu Result này là để mã hóa thông tin xử lý lỗi.
Các biến thể của Result là Ok và Err. Biến thể Ok chỉ ra rằng hoạt động
đã thành công, và nó chứa giá trị được tạo ra thành công. Biến thể Err có
nghĩa là hoạt động đã thất bại, và nó chứa thông tin về cách hoặc lý do tại sao
hoạt động thất bại.
Các giá trị của kiểu Result, giống như các giá trị của bất kỳ kiểu nào, có các
phương thức được định nghĩa trên chúng. Một phiên bản của Result có một phương
thức expect mà bạn có thể gọi. Nếu phiên bản này của
Result là một giá trị Err, expect sẽ làm cho chương trình bị sập và hiển
thị thông báo mà bạn đã truyền làm đối số cho expect. Nếu phương thức
read_line trả về một Err, nó có thể là kết quả của một lỗi đến từ hệ điều
hành cơ bản. Nếu phiên bản này của Result là một giá trị Ok, expect sẽ lấy
giá trị trả về mà Ok đang giữ và trả về chỉ giá trị đó cho bạn để bạn có thể
sử dụng nó. Trong trường hợp này, giá trị đó là số byte trong đầu vào của người
dùng.
Nếu bạn không gọi expect, chương trình sẽ biên dịch, nhưng bạn sẽ nhận được
một cảnh báo:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust cảnh báo rằng bạn chưa sử dụng giá trị Result trả về từ read_line, chỉ
ra rằng chương trình chưa xử lý một lỗi có thể xảy ra.
Cách đúng để loại bỏ cảnh báo là thực sự viết mã xử lý lỗi, nhưng trong trường
hợp của chúng ta, chúng ta chỉ muốn làm cho chương trình này bị sập khi có vấn
đề xảy ra, vì vậy chúng ta có thể sử dụng expect. Bạn sẽ học về cách khôi phục
từ lỗi trong Chương 9.
In Giá Trị Với println! Placeholder
Ngoài dấu ngoặc nhọn đóng, chỉ còn một dòng nữa để thảo luận trong mã cho đến nay:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Dòng này in ra chuỗi hiện chứa đầu vào của người dùng. Bộ {} của dấu ngoặc
nhọn là một placeholder: Hãy nghĩ về {} như những cái kẹp nhỏ giữ một giá trị
tại chỗ. Khi in giá trị của một biến, tên biến có thể được đặt bên trong dấu
ngoặc nhọn. Khi in kết quả của việc đánh giá một biểu thức, đặt dấu ngoặc nhọn
trống trong chuỗi định dạng, sau đó theo sau chuỗi định dạng với một danh sách
các biểu thức được phân tách bằng dấu phẩy để in trong mỗi placeholder dấu ngoặc
nhọn trống theo cùng thứ tự. In một biến và kết quả của một biểu thức trong một
lần gọi println! sẽ trông như thế này:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} and y + 2 = {}", y + 2); }
Mã này sẽ in x = 5 and y + 2 = 12.
Kiểm Tra Phần Đầu Tiên
Hãy kiểm tra phần đầu tiên của trò chơi đoán số. Chạy nó bằng cách sử dụng
cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
Tại thời điểm này, phần đầu tiên của trò chơi đã hoàn thành: Chúng ta đang nhận đầu vào từ bàn phím và sau đó in nó ra.
Tạo Một Số Bí Mật
Tiếp theo, chúng ta cần tạo ra một số bí mật mà người dùng sẽ cố gắng đoán. Số
bí mật nên khác nhau mỗi lần để trò chơi thú vị hơn khi chơi nhiều lần. Chúng ta
sẽ sử dụng một số ngẫu nhiên từ 1 đến 100 để trò chơi không quá khó. Rust chưa
bao gồm chức năng tạo số ngẫu nhiên trong thư viện tiêu chuẩn của nó. Tuy nhiên,
nhóm Rust cung cấp một crate rand với chức năng này.
Bổ sung tính chức năng với một Crate
Nhớ rằng một crate là một tập hợp các file mã nguồn Rust. Dự án mà chúng ta đã
xây dựng là một binary crate, là một tệp thực thi. Crate rand là một library
crate, chứa mã được sử dụng trong các chương trình khác và không thể thực thi
độc lập.
Sự phối hợp của Cargo với các crate bên ngoài là nơi Cargo thực sự tỏa sáng.
Trước khi chúng ta có thể viết mã sử dụng rand, chúng ta cần sửa đổi file
Cargo.toml để bao gồm crate rand làm phụ thuộc. Mở file đó ngay bây giờ và
thêm dòng sau vào cuối, bên dưới phần tiêu đề [dependencies] mà Cargo đã tạo
cho bạn. Hãy chắc chắn chỉ định rand chính xác như chúng tôi đã làm ở đây, với
số phiên bản này, hoặc các ví dụ mã trong hướng dẫn này có thể không hoạt động:
Filename: Cargo.toml
[dependencies]
rand = "0.8.5"
Trong file Cargo.toml, mọi thứ theo sau một tiêu đề là một phần của phần đó
tiếp tục cho đến khi một phần khác bắt đầu. Trong [dependencies], bạn nói với
Cargo những crate bên ngoài mà dự án của bạn phụ thuộc vào và các phiên bản của
các crate đó mà bạn yêu cầu. Trong trường hợp này, chúng ta chỉ định crate
rand với chỉ định phiên bản ngữ nghĩa 0.8.5. Cargo hiểu Semantic
Versioning (đôi khi được gọi là SemVer), là một tiêu
chuẩn để viết số phiên bản. Chỉ định 0.8.5 thực sự là viết tắt của ^0.8.5,
có nghĩa là bất kỳ phiên bản nào ít nhất là 0.8.5 nhưng dưới 0.9.0.
Cargo coi các phiên bản này có API công khai tương thích với phiên bản 0.8.5, và chỉ định này đảm bảo bạn sẽ nhận được bản phát hành vá lỗi mới nhất mà vẫn biên dịch được với mã trong chương này. Bất kỳ phiên bản nào từ 0.9.0 trở lên không được đảm bảo có cùng API như những gì các ví dụ sau đây sử dụng.
Bây giờ, mà không thay đổi bất kỳ mã nào, hãy xây dựng dự án, như được hiển thị trong Listing 2-2.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
Bạn có thể thấy các số phiên bản khác nhau (nhưng tất cả sẽ tương thích với mã, nhờ SemVer!) và các dòng khác nhau (tùy thuộc vào hệ điều hành), và các dòng có thể ở một thứ tự khác.
Khi chúng ta bao gồm một phụ thuộc bên ngoài, Cargo sẽ lấy các phiên bản mới nhất của mọi thứ mà phụ thuộc đó cần từ registry, là một bản sao của dữ liệu từ Crates.io. Crates.io là nơi mọi người trong hệ sinh thái Rust đăng các dự án Rust mã nguồn mở của họ để người khác sử dụng.
Sau khi cập nhật registry, Cargo kiểm tra phần [dependencies] và tải xuống bất
kỳ crate nào được liệt kê mà chưa được tải xuống. Trong trường hợp này, mặc dù
chúng ta chỉ liệt kê rand làm phụ thuộc, Cargo cũng đã lấy các crate khác mà
rand phụ thuộc vào để hoạt động. Sau khi tải xuống các crate, Rust biên dịch
chúng và sau đó biên dịch dự án với các phụ thuộc có sẵn.
Nếu bạn ngay lập tức chạy cargo build lại mà không thực hiện bất kỳ thay đổi
nào, bạn sẽ không nhận được bất kỳ kết quả nào ngoài dòng Finished. Cargo biết
rằng nó đã tải xuống và biên dịch các phụ thuộc, và bạn chưa thay đổi bất kỳ
điều gì về chúng trong file Cargo.toml của bạn. Cargo cũng biết rằng bạn chưa
thay đổi bất kỳ điều gì về mã của bạn, vì vậy nó không biên dịch lại mã đó.
Không có gì để làm, nó chỉ đơn giản thoát ra.
Nếu bạn mở file src/main.rs, thực hiện một thay đổi nhỏ và sau đó lưu nó và xây dựng lại, bạn sẽ chỉ thấy hai dòng kết quả:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Những dòng này cho thấy rằng Cargo chỉ cập nhật bản dựng với thay đổi nhỏ của bạn đối với file src/main.rs. Các phụ thuộc của bạn không thay đổi, vì vậy Cargo biết rằng nó có thể tái sử dụng những gì nó đã tải xuống và biên dịch cho những phụ thuộc đó.
Đảm Bảo Các Bản Dựng Có Thể Tái Tạo
Cargo có một cơ chế đảm bảo bạn có thể tái tạo cùng một artifact mỗi khi bạn
hoặc bất kỳ ai khác xây dựng mã của bạn: Cargo sẽ chỉ sử dụng các phiên bản của
các phụ thuộc mà bạn đã chỉ định cho đến khi bạn chỉ định khác. Ví dụ, giả sử
rằng tuần tới phiên bản 0.8.6 của crate rand ra mắt, và phiên bản đó chứa một
bản sửa lỗi quan trọng, nhưng nó cũng chứa một lỗi hồi quy sẽ làm hỏng mã của
bạn. Để xử lý điều này, Rust tạo file Cargo.lock lần đầu tiên bạn chạy
cargo build, vì vậy bây giờ chúng ta có file này trong thư mục
guessing_game.
Khi bạn xây dựng một dự án lần đầu tiên, Cargo sẽ tìm ra tất cả các phiên bản của các phụ thuộc phù hợp với tiêu chí và sau đó ghi chúng vào file Cargo.lock. Khi bạn xây dựng dự án của mình trong tương lai, Cargo sẽ thấy rằng file Cargo.lock tồn tại và sẽ sử dụng các phiên bản được chỉ định ở đó thay vì làm tất cả công việc tìm ra các phiên bản lại. Điều này cho phép bạn có một bản dựng có thể tái tạo tự động. Nói cách khác, dự án của bạn sẽ vẫn ở phiên bản 0.8.5 cho đến khi bạn nâng cấp rõ ràng, nhờ vào file Cargo.lock. Vì file Cargo.lock quan trọng đối với các bản dựng có thể tái tạo, nó thường được kiểm tra vào kiểm soát nguồn cùng với phần còn lại của mã trong dự án của bạn.
Cập Nhật Một Crate Để Nhận Phiên Bản Mới
Khi bạn muốn cập nhật một crate, Cargo cung cấp lệnh update, lệnh này sẽ bỏ
qua file Cargo.lock và tìm ra tất cả các phiên bản mới nhất phù hợp với các
chỉ định của bạn trong Cargo.toml. Cargo sau đó sẽ ghi các phiên bản đó vào
file Cargo.lock. Ngoài ra, theo mặc định, Cargo sẽ chỉ tìm các phiên bản lớn
hơn 0.8.5 và nhỏ hơn 0.9.0. Nếu crate rand đã phát hành hai phiên bản mới
0.8.6 và 0.9.0, bạn sẽ thấy điều sau nếu bạn chạy cargo update:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.9.0)
Cargo bỏ qua phiên bản 0.9.0. Tại thời điểm này, bạn cũng sẽ nhận thấy một thay
đổi trong file Cargo.lock ghi nhận rằng phiên bản của crate rand mà bạn đang
sử dụng bây giờ là 0.8.6. Để sử dụng phiên bản 0.9.0 của rand hoặc bất kỳ
phiên bản nào trong loạt 0.9.x, bạn sẽ phải cập nhật file Cargo.toml để
trông như thế này:
[dependencies]
rand = "0.9.0"
Lần tiếp theo bạn chạy cargo build, Cargo sẽ cập nhật registry của các crate
có sẵn và đánh giá lại các yêu cầu của bạn về rand theo phiên bản mới mà bạn
đã chỉ định.
Có rất nhiều điều để nói về Cargo và hệ sinh thái của nó, mà chúng ta sẽ thảo luận trong Chương 14, nhưng hiện tại, đó là tất cả những gì bạn cần biết. Cargo làm cho việc tái sử dụng các thư viện rất dễ dàng, vì vậy các Rustaceans có thể viết các dự án nhỏ hơn được lắp ráp từ một số gói.
Tạo Một Số Ngẫu Nhiên
Hãy bắt đầu sử dụng rand để tạo ra một số để đoán. Bước tiếp theo là cập nhật
src/main.rs, như được hiển thị trong Listing 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Đầu tiên, chúng ta thêm dòng use rand::Rng;. Trait Rng định nghĩa các phương
thức mà các bộ tạo số ngẫu nhiên triển khai, và trait này phải nằm trong phạm vi
để chúng ta sử dụng các phương thức đó. Chương 10 sẽ bao gồm các trait chi tiết.
Tiếp theo, chúng ta thêm hai dòng ở giữa. Trong dòng đầu tiên, chúng ta gọi hàm
rand::thread_rng để lấy bộ tạo số ngẫu nhiên cụ thể mà chúng ta sẽ sử dụng:
một bộ tạo số ngẫu nhiên cục bộ cho luồng thực thi hiện tại và được khởi tạo bởi
hệ điều hành. Sau đó, chúng ta gọi phương thức gen_range trên bộ tạo số ngẫu
nhiên. Phương thức này được định nghĩa bởi trait Rng mà chúng ta đã đưa vào
phạm vi với câu lệnh use rand::Rng;. Phương thức gen_range lấy một biểu thức
phạm vi làm đối số và tạo ra một số ngẫu nhiên trong phạm vi đó. Loại biểu thức
phạm vi mà chúng ta đang sử dụng ở đây có dạng start..=end và bao gồm cả giới
hạn dưới và giới hạn trên, vì vậy chúng ta cần chỉ định 1..=100 để yêu cầu một
số từ 1 đến 100.
Lưu ý: Bạn sẽ không chỉ biết các trait nào để sử dụng và các phương thức và hàm nào để gọi từ một crate, vì vậy mỗi crate có tài liệu với hướng dẫn sử dụng nó. Một tính năng thú vị khác của Cargo là chạy lệnh
cargo doc --opensẽ xây dựng tài liệu được cung cấp bởi tất cả các phụ thuộc của bạn cục bộ và mở nó trong trình duyệt của bạn. Nếu bạn quan tâm đến các chức năng khác trong craterand, ví dụ, hãy chạycargo doc --openvà nhấp vàorandtrong thanh bên trái.
Dòng mới thứ hai in ra số bí mật. Điều này hữu ích trong khi chúng ta đang phát triển chương trình để có thể kiểm tra nó, nhưng chúng ta sẽ xóa nó khỏi phiên bản cuối cùng. Nó không phải là một trò chơi nếu chương trình in ra câu trả lời ngay khi nó bắt đầu!
Hãy thử chạy chương trình một vài lần:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
Bạn nên nhận được các số ngẫu nhiên khác nhau, và tất cả chúng nên là các số từ 1 đến 100. Làm tốt lắm!
So Sánh Số Đoán Với Số Bí Mật
Bây giờ chúng ta đã có đầu vào từ người dùng và một số ngẫu nhiên, chúng ta có thể so sánh chúng. Bước đó được hiển thị trong Listing 2-4. Lưu ý rằng mã này sẽ không biên dịch ngay lập tức, như chúng ta sẽ giải thích.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Đầu tiên, chúng ta thêm một câu lệnh use khác, đưa một kiểu gọi là
std::cmp::Ordering vào phạm vi từ thư viện tiêu chuẩn. Kiểu Ordering là một
enum khác và có các biến thể Less, Greater và Equal. Đây là ba kết quả có
thể xảy ra khi bạn so sánh hai giá trị.
Sau đó, chúng ta thêm năm dòng mới ở cuối sử dụng kiểu Ordering. Phương thức
cmp so sánh hai giá trị và có thể được gọi trên bất kỳ thứ gì có thể so sánh.
Nó lấy một tham chiếu đến bất kỳ thứ gì bạn muốn so sánh: ở đây nó đang so sánh
guess với secret_number. Sau đó, nó trả về một biến thể của enum Ordering
mà chúng ta đã đưa vào phạm vi với câu lệnh use. Chúng ta sử dụng một biểu
thức match để quyết định làm gì tiếp theo dựa trên
biến thể nào của Ordering được trả về từ lời gọi đến cmp với các giá trị
trong guess và secret_number.
Một biểu thức match được tạo thành từ các nhánh. Một nhánh bao gồm một mẫu
để so khớp, và mã sẽ được chạy nếu giá trị được đưa vào match phù hợp với mẫu
của nhánh đó. Rust lấy giá trị được đưa vào match và xem qua mẫu của từng
nhánh lần lượt. Các mẫu và cấu trúc match là các tính năng mạnh mẽ của Rust:
chúng cho phép bạn biểu đạt nhiều tình huống mà mã của bạn có thể gặp phải và
chúng đảm bảo bạn xử lý tất cả chúng. Các tính năng này sẽ được bao gồm chi tiết
trong Chương 6 và Chương 19, tương ứng.
Hãy đi qua một ví dụ với biểu thức match mà chúng ta sử dụng ở đây. Giả sử
rằng người dùng đã đoán 50 và số bí mật được tạo ngẫu nhiên lần này là 38.
Khi mã so sánh 50 với 38, phương thức cmp sẽ trả về Ordering::Greater vì 50
lớn hơn 38. Biểu thức match nhận giá trị Ordering::Greater và bắt đầu kiểm
tra mẫu của từng nhánh. Nó xem mẫu của nhánh đầu tiên, Ordering::Less, và thấy
rằng giá trị Ordering::Greater không phù hợp với Ordering::Less, vì vậy nó
bỏ qua mã trong nhánh đó và chuyển sang nhánh tiếp theo. Mẫu của nhánh tiếp theo
là Ordering::Greater, điều này phù hợp với Ordering::Greater! Mã liên kết
trong nhánh đó sẽ được thực thi và in ra Too big! trên màn hình. Biểu thức
match kết thúc sau khi khớp thành công đầu tiên, vì vậy nó sẽ không xem nhánh
cuối cùng trong tình huống này.
Tuy nhiên, mã trong Listing 2-4 sẽ không biên dịch ngay lập tức. Hãy thử nó:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
Lỗi cốt lõi cho biết rằng có các kiểu không khớp. Rust có một hệ thống kiểu
mạnh mẽ và tĩnh. Tuy nhiên, nó cũng có suy luận kiểu. Khi chúng ta viết
let mut guess = String::new(), Rust có thể suy luận rằng guess nên là một
String và không bắt chúng ta phải viết kiểu. Mặt khác, secret_number là một
kiểu số. Một vài kiểu số của Rust có thể có giá trị từ 1 đến 100: i32, một số
32-bit; u32, một số 32-bit không dấu; i64, một số 64-bit; cũng như các kiểu
khác. Trừ khi được chỉ định khác, Rust mặc định là một i32, đó là kiểu của
secret_number trừ khi bạn thêm thông tin kiểu ở nơi khác để Rust suy luận một
kiểu số khác. Lý do cho lỗi là Rust không thể so sánh một chuỗi và một kiểu số.
Cuối cùng, chúng ta muốn chuyển đổi String mà chương trình đọc làm đầu vào
thành một kiểu số để chúng ta có thể so sánh nó về mặt số học với số bí mật.
Chúng ta làm điều đó bằng cách thêm dòng này vào thân hàm main:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Dòng này là:
let guess: u32 = guess.trim().parse().expect("Please type a number!");Chúng ta tạo một biến có tên là guess. Nhưng chờ đã, chương trình đã có một
biến có tên là guess chưa? Đúng vậy, nhưng may mắn thay Rust cho phép chúng ta
che bóng giá trị trước đó của guess bằng một giá trị mới. Che bóng cho phép
chúng ta tái sử dụng tên biến guess thay vì buộc chúng ta phải tạo hai biến
duy nhất, chẳng hạn như guess_str và guess, ví dụ. Chúng ta sẽ bao gồm điều
này chi tiết hơn trong Chương 3, nhưng hiện tại, hãy
biết rằng tính năng này thường được sử dụng khi bạn muốn chuyển đổi một giá trị
từ một kiểu sang một kiểu khác.
Chúng ta gán biến mới này với biểu thức guess.trim().parse(). guess trong
biểu thức đề cập đến biến guess ban đầu chứa đầu vào dưới dạng chuỗi. Phương
thức trim trên một phiên bản String sẽ loại bỏ bất kỳ khoảng trắng nào ở đầu
và cuối, điều mà chúng ta phải làm trước khi có thể chuyển đổi chuỗi thành một
u32, chỉ có thể chứa dữ liệu số. Người dùng phải nhấn enter để thỏa
mãn read_line và nhập số đoán của họ, điều này thêm một ký tự xuống dòng vào
chuỗi. Ví dụ, nếu người dùng nhập 5 và nhấn enter, guess
trông như thế này: 5\n. \n đại diện cho “xuống dòng.” (Trên Windows, nhấn
enter sẽ dẫn đến một ký tự xuống dòng và một ký tự trở về, \r\n.)
Phương thức trim loại bỏ \n hoặc \r\n, chỉ để lại 5.
Phương thức parse trên chuỗi chuyển đổi một chuỗi
thành một kiểu khác. Ở đây, chúng ta sử dụng nó để chuyển đổi từ một chuỗi thành
một số. Chúng ta cần nói với Rust kiểu số chính xác mà chúng ta muốn bằng cách
sử dụng let guess: u32. Dấu hai chấm (:) sau guess cho Rust biết rằng
chúng ta sẽ chú thích kiểu của biến. Rust có một vài kiểu số tích hợp; u32
được thấy ở đây là một số nguyên 32-bit không dấu. Đó là một lựa chọn mặc định
tốt cho một số dương nhỏ. Bạn sẽ học về các kiểu số khác trong Chương
3.
Ngoài ra, chú thích u32 trong chương trình ví dụ này và so sánh với
secret_number có nghĩa là Rust sẽ suy luận rằng secret_number cũng nên là
một u32. Vì vậy, bây giờ so sánh sẽ là giữa hai giá trị cùng kiểu!
Phương thức parse sẽ chỉ hoạt động trên các ký tự có thể chuyển đổi hợp lý
thành số và do đó có thể dễ dàng gây ra lỗi. Nếu, ví dụ, chuỗi chứa A👍%, sẽ
không có cách nào để chuyển đổi điều đó thành một số. Vì nó có thể thất bại,
phương thức parse trả về một kiểu Result, giống như phương thức read_line
(được thảo luận trước đó trong
“Xử Lý Khả Năng Thất Bại Với Result”).
Chúng ta sẽ xử lý Result này theo cùng cách bằng cách sử dụng phương thức
expect một lần nữa. Nếu parse trả về một biến thể Err của Result vì nó
không thể tạo ra một số từ chuỗi, lời gọi expect sẽ làm cho trò chơi bị sập và
in ra thông báo mà chúng ta đưa ra. Nếu parse có thể chuyển đổi thành công
chuỗi thành một số, nó sẽ trả về biến thể Ok của Result, và expect sẽ trả
về số mà chúng ta muốn từ giá trị Ok.
Hãy chạy chương trình ngay bây giờ:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Tuyệt vời! Mặc dù đã thêm các khoảng trắng trước số đoán, chương trình vẫn nhận ra rằng người dùng đã đoán 76. Chạy chương trình một vài lần để xác minh hành vi khác nhau với các loại đầu vào khác nhau: đoán số chính xác, đoán một số quá lớn và đoán một số quá nhỏ.
Chúng ta đã có hầu hết trò chơi hoạt động, nhưng người dùng chỉ có thể đoán một lần. Hãy thay đổi điều đó bằng cách thêm một vòng lặp!
Cho Phép Nhiều Lần Đoán Với Vòng Lặp
Từ khóa loop tạo ra một vòng lặp vô hạn. Chúng ta sẽ thêm một vòng lặp để cho
phép người dùng có nhiều cơ hội đoán số hơn:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}Như bạn có thể thấy, chúng ta đã di chuyển mọi thứ từ lời nhắc nhập số đoán trở đi vào một vòng lặp. Hãy chắc chắn thụt lề các dòng bên trong vòng lặp thêm bốn khoảng trắng mỗi dòng và chạy chương trình lại. Chương trình bây giờ sẽ yêu cầu một số đoán khác mãi mãi, điều này thực sự giới thiệu một vấn đề mới. Dường như người dùng không thể thoát ra!
Người dùng luôn có thể ngắt chương trình bằng cách sử dụng phím tắt
ctrl-C. Nhưng có một cách khác để thoát khỏi con quái vật
không thể thỏa mãn này, như đã đề cập trong phần thảo luận về parse trong
“So Sánh Số Đoán Với Số Bí Mật”:
nếu người dùng nhập một câu trả lời không phải là số, chương trình sẽ bị sập.
Chúng ta có thể tận dụng điều đó để cho phép người dùng thoát ra, như được hiển
thị ở đây:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Nhập quit sẽ thoát khỏi trò chơi, nhưng như bạn sẽ nhận thấy, việc nhập bất kỳ
đầu vào không phải là số nào khác cũng sẽ thoát ra. Điều này là không tối ưu, ít
nhất là; chúng ta muốn trò chơi cũng dừng lại khi số đoán chính xác.
Thoát Sau Khi Đoán Đúng
Hãy lập trình trò chơi để thoát khi người dùng thắng bằng cách thêm một câu lệnh
break:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Thêm dòng break sau You win! làm cho chương trình thoát khỏi vòng lặp khi
người dùng đoán đúng số bí mật. Thoát khỏi vòng lặp cũng có nghĩa là thoát khỏi
chương trình, vì vòng lặp là phần cuối cùng của main.
Xử Lý Đầu Vào Không Hợp Lệ
Để tinh chỉnh thêm hành vi của trò chơi, thay vì làm cho chương trình bị sập khi
người dùng nhập vào một số không phải là số, hãy làm cho trò chơi bỏ qua số
không phải là số để người dùng có thể tiếp tục đoán. Chúng ta có thể làm điều đó
bằng cách thay đổi dòng mà guess được chuyển đổi từ một String thành một
u32, như được hiển thị trong Listing 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Chúng ta chuyển từ một lời gọi expect sang một biểu thức match để chuyển từ
việc làm cho chương trình bị sập khi có lỗi sang xử lý lỗi. Nhớ rằng parse trả
về một kiểu Result và Result là một enum có các biến thể Ok và Err.
Chúng ta đang sử dụng một biểu thức match ở đây, như chúng ta đã làm với kết
quả Ordering của phương thức cmp.
Nếu parse có thể chuyển đổi thành công chuỗi thành một số, nó sẽ trả về một
giá trị Ok chứa số kết quả. Giá trị Ok đó sẽ khớp với mẫu của nhánh đầu
tiên, và biểu thức match sẽ chỉ trả về giá trị num mà parse đã tạo ra và
đặt bên trong giá trị Ok. Số đó sẽ kết thúc ngay tại nơi chúng ta muốn trong
biến guess mới mà chúng ta đang tạo.
Nếu parse không thể chuyển đổi chuỗi thành một số, nó sẽ trả về một giá trị
Err chứa thêm thông tin về lỗi. Giá trị Err không khớp với mẫu Ok(num)
trong nhánh đầu tiên của match, nhưng nó khớp với mẫu Err(_) trong nhánh thứ
hai. Dấu gạch dưới, _, là một giá trị bắt tất cả; trong ví dụ này, chúng ta
đang nói rằng chúng ta muốn khớp với tất cả các giá trị Err, bất kể thông tin
nào chúng có bên trong. Vì vậy, chương trình sẽ thực thi mã của nhánh thứ hai,
continue, điều này cho chương trình biết đi đến lần lặp tiếp theo của loop
và yêu cầu một số đoán khác. Vì vậy, về cơ bản, chương trình bỏ qua tất cả các
lỗi mà parse có thể gặp phải!
Bây giờ mọi thứ trong chương trình nên hoạt động như mong đợi. Hãy thử nó:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Tuyệt vời! Với một tinh chỉnh nhỏ cuối cùng, chúng ta sẽ hoàn thành trò chơi
đoán số. Nhớ rằng chương trình vẫn đang in ra số bí mật. Điều đó hoạt động tốt
cho việc kiểm tra, nhưng nó làm hỏng trò chơi. Hãy xóa println! in ra số bí
mật. Listing 2-6 hiển thị mã hoàn chỉnh.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Tại thời điểm này, bạn đã xây dựng thành công trò chơi đoán số. Chúc mừng!
Tóm Tắt
Dự án này là một cách thực hành để giới thiệu cho bạn nhiều khái niệm mới trong
Rust: let, match, hàm, việc sử dụng các crate bên ngoài và nhiều hơn nữa.
Trong các chương tiếp theo, bạn sẽ học về các khái niệm này chi tiết hơn. Chương
3 bao gồm các khái niệm mà hầu hết các ngôn ngữ lập trình đều có, chẳng hạn như
biến, kiểu dữ liệu và hàm, và chỉ cho bạn cách sử dụng chúng trong Rust. Chương
4 khám phá quyền sở hữu, một tính năng làm cho Rust khác biệt so với các ngôn
ngữ khác. Chương 5 thảo luận về cấu trúc và cú pháp phương thức, và Chương 6
giải thích cách hoạt động của các enum.
Các Khái Niệm Lập Trình Phổ Biến
Chương này bao gồm các khái niệm xuất hiện trong hầu hết mọi ngôn ngữ lập trình và cách chúng hoạt động trong Rust. Nhiều ngôn ngữ lập trình có nhiều điểm chung ở cốt lõi. Không có khái niệm nào được trình bày trong chương này là độc quyền của Rust, nhưng chúng ta sẽ thảo luận về chúng trong bối cảnh của Rust và giải thích các quy ước xung quanh việc sử dụng các chúng.
Cụ thể, bạn sẽ học về biến, các kiểu dữ liệu cơ bản, hàm, bình luận, và luồng điều khiển. Những nền tảng này sẽ có trong mọi chương trình Rust, và việc học chúng sớm sẽ giúp bạn có một nền tảng vững chắc để bắt đầu.
Từ khóa
Ngôn ngữ Rust có một tập hợp các từ khóa được dành riêng để sử dụng bởi ngôn ngữ này, tương tự như trong các ngôn ngữ khác. Hãy lưu ý rằng bạn không thể sử dụng những từ này làm tên của biến hoặc hàm. Hầu hết các từ khóa đều có ý nghĩa đặc biệt, và bạn sẽ sử dụng chúng để thực hiện các nhiệm vụ khác nhau trong chương trình Rust của mình; một số ít không có chức năng cụ thể nào liên quan đến chúng nhưng đã được dành riêng cho các chức năng có thể được thêm vào Rust trong tương lai. Bạn có thể tìm thấy danh sách các từ khóa trong Phụ lục A.
Biến và Tính Khả Biến
Như đã đề cập trong phần "Lưu Trữ Giá Trị với Biến", theo mặc định, các biến là không thể thay đổi (immutable). Đây là một trong nhiều sự hướng dẫn mà Rust cung cấp cho bạn để viết code theo cách tận dụng lợi thế về tính an toàn và dễ dàng trong xử lý đồng thời mà Rust mang lại. Tuy nhiên, bạn vẫn có tùy chọn để làm cho các biến của mình có thể thay đổi (mutable). Hãy cùng khám phá cách thức và lý do tại sao Rust khuyến khích bạn ưu tiên tính bất biến và lý do tại sao đôi khi bạn có thể muốn lựa chọn khác.
Khi một biến là bất biến, sau khi một giá trị được gắn với một tên, bạn không
thể thay đổi giá trị đó. Để minh họa điều này, hãy tạo một dự án mới có tên là
variables trong thư mục projects của bạn bằng cách sử dụng
cargo new variables.
Sau đó, trong thư mục variables mới của bạn, mở src/main.rs và thay thế mã của nó bằng đoạn mã sau, mã này sẽ chưa biên dịch được ngay:
Tên tệp: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Lưu và chạy chương trình bằng cách sử dụng cargo run. Bạn sẽ nhận được thông
báo lỗi liên quan đến lỗi bất biến, như được hiển thị trong kết quả này:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Ví dụ này cho thấy cách trình biên dịch giúp bạn tìm ra lỗi trong các chương trình của mình. Lỗi biên dịch có thể gây khó chịu, nhưng thực sự chúng chỉ có nghĩa là chương trình của bạn chưa an toàn để thực hiện những gì bạn muốn; chúng không có nghĩa là bạn không phải là một lập trình viên giỏi! Ngay cả những người dùng Rust có kinh nghiệm vẫn gặp lỗi biên dịch.
Bạn nhận được thông báo lỗi cannot assign twice to immutable variable `x`
bởi vì bạn đã cố gắn một giá trị thứ hai cho biến bất biến x.
Điều quan trọng là chúng ta gặp lỗi khi biên dịch khi chúng ta cố gắng thay đổi một giá trị được chỉ định là bất biến bởi vì tình huống này có thể dẫn đến lỗi. Nếu một phần trong code của chúng ta hoạt động dựa trên giả định rằng một giá trị sẽ không bao giờ thay đổi và một phần khác của code thay đổi giá trị đó, thì có thể phần đầu tiên của code sẽ không làm những gì nó được thiết kế để làm. Nguyên nhân của loại lỗi này có thể khó theo dõi sau khi nó xảy ra, đặc biệt là khi phần code thứ hai chỉ thay đổi giá trị đôi khi. Trình biên dịch của Rust đảm bảo rằng khi bạn tuyên bố một giá trị sẽ không thay đổi, nó thực sự sẽ không thay đổi, vì vậy bạn không phải tự theo dõi nó. Do đó, code của bạn dễ dàng suy luận hơn.
Nhưng tính khả biến có thể rất hữu ích và có thể làm cho code trở nên thuận tiện
hơn khi viết. Mặc dù các biến là bất biến theo mặc định, bạn có thể làm cho
chúng trở nên khả biến bằng cách thêm mut trước tên biến như bạn đã làm trong
Chương 2. Thêm mut cũng truyền
đạt ý định cho những người đọc code trong tương lai bằng cách chỉ ra rằng các
phần khác của code sẽ thay đổi giá trị của biến này.
Ví dụ, hãy thay đổi src/main.rs thành như sau:
Tên tệp: src/main.rs
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
Khi chúng ta chạy chương trình bây giờ, chúng ta sẽ nhận được:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
Chúng ta được phép thay đổi giá trị gắn với x từ 5 thành 6 khi sử dụng
mut. Cuối cùng, quyết định sử dụng tính khả biến hay không tùy thuộc vào bạn
và phụ thuộc vào những gì bạn nghĩ là rõ ràng nhất trong tình huống cụ thể đó.
Khai báo Hằng số
Giống như các biến bất biến, hằng số là các giá trị được gắn với một tên và không được phép thay đổi, nhưng có một vài sự khác biệt giữa hằng số và biến.
Đầu tiên, bạn không được phép sử dụng mut với hằng số. Hằng số không chỉ bất
biến theo mặc định—chúng luôn bất biến. Bạn khai báo hằng số bằng từ khóa
const thay vì từ khóa let, và kiểu của giá trị phải được chú thích. Chúng
ta sẽ đề cập đến các kiểu và chú thích kiểu trong phần tiếp theo, "Kiểu Dữ
Liệu", vì vậy đừng lo lắng về các chi tiết ngay bây
giờ. Chỉ cần biết rằng bạn phải luôn chú thích kiểu.
Hằng số có thể được khai báo trong bất kỳ phạm vi nào, bao gồm cả phạm vi toàn cục, làm cho chúng hữu ích cho các giá trị mà nhiều phần của code cần biết.
Sự khác biệt cuối cùng là hằng số chỉ có thể được đặt thành một biểu thức hằng, không phải là kết quả của một giá trị chỉ có thể được tính toán trong thời gian chạy.
Đây là một ví dụ về khai báo hằng số:
#![allow(unused)] fn main() { const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3; }
Tên của hằng số là THREE_HOURS_IN_SECONDS và giá trị của nó được đặt thành kết
quả của việc nhân 60 (số giây trong một phút) với 60 (số phút trong một giờ) với
3 (số giờ mà chúng ta muốn đếm trong chương trình này). Quy ước đặt tên của Rust
cho hằng số là sử dụng tất cả các chữ in hoa với dấu gạch dưới giữa các từ.
Trình biên dịch có thể đánh giá một tập hợp giới hạn các hoạt động tại thời điểm
biên dịch, cho phép chúng ta chọn cách viết giá trị này theo cách dễ hiểu và xác
minh hơn, thay vì đặt hằng số này thành giá trị 10.800. Xem phần đánh giá hằng
số trong Rust Reference để biết thêm thông tin về các hoạt động có
thể được sử dụng khi khai báo hằng số.
Hằng số có hiệu lực trong suốt thời gian chương trình chạy, trong phạm vi mà chúng được khai báo. Thuộc tính này làm cho hằng số hữu ích cho các giá trị trong lĩnh vực ứng dụng của bạn mà nhiều phần của chương trình có thể cần biết, chẳng hạn như số điểm tối đa mà bất kỳ người chơi nào của trò chơi được phép kiếm được, hoặc tốc độ ánh sáng.
Việc đặt tên cho các giá trị cứng được sử dụng trong suốt chương trình của bạn dưới dạng hằng số là hữu ích trong việc truyền đạt ý nghĩa của giá trị đó cho những người duy trì code trong tương lai. Nó cũng giúp bạn chỉ cần có một nơi trong code mà bạn cần thay đổi nếu giá trị cứng cần được cập nhật trong tương lai.
Che Khuất (Shadowing)
Như bạn đã thấy trong hướng dẫn trò chơi đoán số trong Chương
2, bạn có thể khai báo
một biến mới với cùng tên với một biến trước đó. Người dùng Rust nói rằng biến
đầu tiên bị che khuất bởi biến thứ hai, có nghĩa là biến thứ hai là những gì
trình biên dịch sẽ thấy khi bạn sử dụng tên của biến. Trên thực tế, biến thứ hai
che khuất biến đầu tiên, lấy bất kỳ việc sử dụng nào của tên biến cho chính nó
cho đến khi nó tự bị che khuất hoặc phạm vi kết thúc. Chúng ta có thể che khuất
một biến bằng cách sử dụng cùng tên biến và lặp lại việc sử dụng từ khóa let
như sau:
Tên tệp: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); }
Chương trình này đầu tiên gắn x với giá trị 5. Sau đó, nó tạo một biến mới
x bằng cách lặp lại let x =, lấy giá trị ban đầu và cộng thêm 1 để giá trị
của x sau đó là 6. Sau đó, trong phạm vi bên trong được tạo bằng dấu ngoặc
nhọn, câu lệnh let thứ ba cũng che khuất x và tạo một biến mới, nhân giá trị
trước đó với 2 để cho x giá trị là 12. Khi phạm vi đó kết thúc, việc che
khuất bên trong kết thúc và x trở về giá trị 6. Khi chúng ta chạy chương
trình này, nó sẽ xuất ra như sau:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
Che khuất khác với việc đánh dấu một biến là mut vì chúng ta sẽ gặp lỗi biên
dịch nếu chúng ta vô tình cố gắng gán lại cho biến này mà không sử dụng từ khóa
let. Bằng cách sử dụng let, chúng ta có thể thực hiện một vài biến đổi trên
một giá trị nhưng làm cho biến đó bất biến sau khi các biến đổi đó đã hoàn
thành.
Sự khác biệt khác giữa mut và che khuất là vì chúng ta đang tạo một biến mới
khi chúng ta sử dụng từ khóa let lần nữa, chúng ta có thể thay đổi kiểu của
giá trị nhưng vẫn tái sử dụng cùng một tên. Ví dụ, giả sử chương trình của chúng
ta yêu cầu người dùng hiển thị số lượng khoảng trắng mà họ muốn giữa một số văn
bản bằng cách nhập các ký tự khoảng trắng, và sau đó chúng ta muốn lưu trữ đầu
vào đó dưới dạng số:
fn main() { let spaces = " "; let spaces = spaces.len(); }
Biến spaces đầu tiên là kiểu chuỗi và biến spaces thứ hai là kiểu số. Việc
che khuất do đó giúp chúng ta không phải nghĩ ra các tên khác nhau, như
spaces_str và spaces_num; thay vào đó, chúng ta có thể tái sử dụng cái tên
đơn giản hơn là spaces. Tuy nhiên, nếu chúng ta cố gắng sử dụng mut cho việc
này, như được hiển thị ở đây, chúng ta sẽ gặp lỗi biên dịch:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}Lỗi nói rằng chúng ta không được phép thay đổi kiểu của một biến:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Bây giờ chúng ta đã khám phá cách hoạt động của các biến, hãy xem xét nhiều loại dữ liệu khác mà biến có thể có.
Kiểu Dữ Liệu
Mỗi giá trị trong Rust thuộc về một kiểu dữ liệu nhất định, điều này cho Rust biết loại dữ liệu đang được chỉ định để nó biết cách làm việc với dữ liệu đó. Chúng ta sẽ xem xét hai tập con kiểu dữ liệu: kiểu vô hướng (scalar) và kiểu phức hợp (compound).
Hãy nhớ rằng Rust là một ngôn ngữ kiểu tĩnh, nghĩa là nó phải biết kiểu của
tất cả các biến tại thời điểm biên dịch. Trình biên dịch thường có thể suy ra
kiểu mà chúng ta muốn sử dụng dựa trên giá trị và cách chúng ta sử dụng nó.
Trong các trường hợp có nhiều kiểu có thể xảy ra, chẳng hạn như khi chúng ta
chuyển đổi một String thành một kiểu số bằng cách sử dụng parse trong phần
"So sánh số đoán với số bí
mật" ở Chương 2, chúng
ta phải thêm chú thích kiểu, như sau:
#![allow(unused)] fn main() { let guess: u32 = "42".parse().expect("Not a number!"); }
Nếu chúng ta không thêm chú thích kiểu : u32 như trong đoạn mã trên, Rust sẽ
hiển thị lỗi sau, có nghĩa là trình biên dịch cần thêm thông tin từ chúng ta để
biết kiểu nào chúng ta muốn sử dụng:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Bạn sẽ thấy các chú thích kiểu khác nhau cho các kiểu dữ liệu khác.
Kiểu Vô Hướng
Một kiểu vô hướng biểu diễn một giá trị đơn lẻ. Rust có bốn kiểu vô hướng cơ bản: số nguyên, số thực dấu phẩy động, Boolean và ký tự. Có thể bạn đã quen thuộc với những kiểu này từ các ngôn ngữ lập trình khác. Chúng ta hãy xem cách chúng hoạt động trong Rust.
Kiểu Số Nguyên
Số nguyên là một số không có phần thập phân. Chúng ta đã sử dụng một kiểu số
nguyên trong Chương 2, kiểu u32. Khai báo kiểu này cho biết rằng giá trị được
liên kết với nó phải là một số nguyên không dấu (các kiểu số nguyên có dấu bắt
đầu bằng i thay vì u) chiếm 32 bit không gian lưu trữ. Bảng 3-1 cho thấy các
kiểu số nguyên tích hợp trong Rust. Chúng ta có thể sử dụng bất kỳ biến thể nào
trong số này để khai báo kiểu của một giá trị số nguyên.
Bảng 3-1: Các Kiểu Số Nguyên trong Rust
| Độ dài | Có dấu | Không dấu |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| phụ thuộc vào kiến trúc | isize | usize |
Mỗi biến thể có thể có dấu hoặc không dấu và có một kích thước rõ ràng. Có dấu và không dấu đề cập đến việc liệu số đó có thể âm hay không—nói cách khác, liệu số đó cần có dấu kèm theo (có dấu) hay chỉ bao giờ cũng dương và do đó có thể được biểu diễn mà không cần dấu (không dấu). Giống như viết số trên giấy: khi dấu quan trọng, số được hiển thị với dấu cộng hoặc dấu trừ; tuy nhiên, khi có thể giả định rằng số đó là dương, nó được hiển thị không có dấu. Số có dấu được lưu trữ bằng cách sử dụng biểu diễn bù hai.
Mỗi biến thể có dấu có thể lưu trữ số từ −(2n − 1) đến 2n −
1 − 1 bao gồm cả hai đầu, trong đó n là số bit mà biến thể đó sử dụng.
Vì vậy, i8 có thể lưu trữ số từ −(27) đến 27 − 1, tương
đương từ −128 đến 127. Các biến thể không dấu có thể lưu trữ số từ 0 đến
2n − 1, nên u8 có thể lưu trữ số từ 0 đến 28 − 1, tương
đương từ 0 đến 255.
Ngoài ra, các kiểu isize và usize phụ thuộc vào kiến trúc của máy tính mà
chương trình của bạn đang chạy: 64 bit nếu bạn đang sử dụng kiến trúc 64 bit và
32 bit nếu bạn đang sử dụng kiến trúc 32 bit.
Bạn có thể viết số nguyên theo bất kỳ dạng nào được hiển thị trong Bảng 3-2. Lưu
ý rằng các số nguyên có thể thuộc nhiều kiểu số khác nhau cho phép hậu tố kiểu,
chẳng hạn như 57u8, để chỉ định kiểu. Số nguyên cũng có thể sử dụng _ như
một dấu phân cách trực quan để làm cho số dễ đọc hơn, chẳng hạn như 1_000, sẽ
có giá trị giống như khi bạn chỉ định 1000.
Bảng 3-2: Các Số Nguyên trong Rust
| Dạng số | Ví dụ |
|---|---|
| Thập phân | 98_222 |
| Thập lục phân | 0xff |
| Bát phân | 0o77 |
| Nhị phân | 0b1111_0000 |
Byte (u8 chỉ) | b'A' |
Vậy làm thế nào để biết kiểu số nguyên nào để sử dụng? Nếu bạn không chắc chắn,
mặc định của Rust thường là nơi tốt để bắt đầu: các kiểu số nguyên mặc định là
i32. Trường hợp chính mà bạn sẽ sử dụng isize hoặc usize là khi đánh chỉ
số cho một số loại bộ sưu tập.
Tràn số nguyên
Giả sử bạn có một biến kiểu
u8có thể lưu giá trị từ 0 đến 255. Nếu bạn cố gắng thay đổi biến thành một giá trị ngoài phạm vi đó, chẳng hạn như 256, tràn số nguyên sẽ xảy ra, có thể dẫn đến một trong hai hành vi. Khi bạn biên dịch ở chế độ debug, Rust bao gồm các kiểm tra tràn số nguyên khiến chương trình của bạn panic khi chạy nếu hành vi này xảy ra. Rust sử dụng thuật ngữ panicking khi một chương trình kết thúc với lỗi; chúng ta sẽ thảo luận sâu hơn về panic trong phần "Lỗi không thể khôi phục vớipanic!" trong Chương 9.Khi bạn biên dịch ở chế độ phát hành với cờ
--release, Rust không bao gồm các kiểm tra tràn số nguyên gây ra panic. Thay vào đó, nếu xảy ra tràn, Rust thực hiện bao quanh bù hai. Nói ngắn gọn, các giá trị lớn hơn giá trị tối đa mà kiểu có thể lưu trữ "bao quanh" về giá trị tối thiểu mà kiểu có thể lưu trữ. Trong trường hợp củau8, giá trị 256 trở thành 0, giá trị 257 trở thành 1, và cứ thế. Chương trình sẽ không panic, nhưng biến sẽ có giá trị có lẽ không phải là giá trị mà bạn mong đợi nó phải có. Việc dựa vào hành vi bao quanh của tràn số nguyên được coi là một lỗi.Để xử lý rõ ràng khả năng tràn, bạn có thể sử dụng các họ phương thức sau được cung cấp bởi thư viện chuẩn cho các kiểu số nguyên nguyên thủy:
- Bao quanh trong mọi chế độ với các phương thức
wrapping_*, nhưwrapping_add.- Trả về giá trị
Nonenếu có tràn với các phương thứcchecked_*.- Trả về giá trị và một Boolean cho biết liệu có tràn hay không với các phương thức
overflowing_*.- Bão hòa ở giá trị tối thiểu hoặc tối đa của giá trị với các phương thức
saturating_*.
Kiểu Số Thực Dấu Phẩy Động
Rust cũng có hai kiểu nguyên thủy cho số thực dấu phẩy động, là số có dấu thập
phân. Kiểu số thực dấu phẩy động của Rust là f32 và f64, có kích thước lần
lượt là 32 bit và 64 bit. Kiểu mặc định là f64 vì trên CPU hiện đại, nó có tốc
độ gần tương đương với f32 nhưng có khả năng chính xác cao hơn. Tất cả các
kiểu số thực dấu phẩy động đều có dấu.
Đây là một ví dụ thể hiện số thực dấu phẩy động trong hành động:
Tên tập tin: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
Số thực dấu phẩy động được biểu diễn theo tiêu chuẩn IEEE-754.
Phép Toán Số Học
Rust hỗ trợ các phép toán cơ bản mà bạn mong đợi cho tất cả các loại số: cộng,
trừ, nhân, chia và lấy phần dư. Phép chia số nguyên cắt cụt về phía số không đến
số nguyên gần nhất. Đoạn mã sau cho thấy cách bạn sử dụng mỗi phép toán trong
một câu lệnh let:
Tên tập tin: src/main.rs
fn main() { // addition let sum = 5 + 10; // subtraction let difference = 95.5 - 4.3; // multiplication let product = 4 * 30; // division let quotient = 56.7 / 32.2; let truncated = -5 / 3; // Results in -1 // remainder let remainder = 43 % 5; }
Mỗi biểu thức trong các câu lệnh này sử dụng một toán tử toán học và đánh giá thành một giá trị duy nhất, sau đó được gắn với một biến. Phụ lục B chứa danh sách tất cả các toán tử mà Rust cung cấp.
Kiểu Boolean
Cũng giống như trong hầu hết các ngôn ngữ lập trình khác, kiểu Boolean trong
Rust có hai giá trị có thể có: true và false. Boolean có kích thước một
byte. Kiểu Boolean trong Rust được chỉ định bằng bool. Ví dụ:
Tên tập tin: src/main.rs
fn main() { let t = true; let f: bool = false; // with explicit type annotation }
Cách chính để sử dụng giá trị Boolean là thông qua các điều kiện, chẳng hạn như
biểu thức if. Chúng ta sẽ tìm hiểu cách biểu thức if hoạt động trong Rust
trong phần "Luồng Điều Khiển".
Kiểu Ký Tự
Kiểu char của Rust là kiểu bảng chữ cái nguyên thủy nhất của ngôn ngữ. Dưới
đây là một số ví dụ về khai báo giá trị char:
Tên tập tin: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // with explicit type annotation let heart_eyed_cat = '😻'; }
Lưu ý rằng chúng ta chỉ định các ký tự bằng dấu nháy đơn, khác với chuỗi, sử
dụng dấu nháy kép. Kiểu char của Rust có kích thước bốn byte và đại diện cho
một giá trị scalar của Unicode, nghĩa là nó có thể đại diện cho nhiều hơn chỉ là
ASCII. Các chữ cái có dấu; ký tự tiếng Trung, tiếng Nhật và tiếng Hàn; biểu
tượng cảm xúc; và khoảng trắng có độ rộng bằng không đều là giá trị char hợp
lệ trong Rust. Giá trị scalar của Unicode nằm trong khoảng từ U+0000 đến
U+D7FF và U+E000 đến U+10FFFF bao gồm. Tuy nhiên, "ký tự" không thực sự là
một khái niệm trong Unicode, vì vậy trực giác của con người về "ký tự" có thể
không khớp với khái niệm char trong Rust. Chúng ta sẽ thảo luận chi tiết về
chủ đề này trong "Lưu Trữ Văn Bản Mã Hóa UTF-8 với
Chuỗi" ở Chương 8.
Kiểu Phức Hợp
Kiểu phức hợp có thể nhóm nhiều giá trị thành một kiểu. Rust có hai kiểu phức hợp nguyên thủy: bộ giá trị (tuple) và mảng.
Kiểu Bộ Giá Trị
Một bộ giá trị là một cách chung để nhóm một số giá trị có nhiều kiểu khác nhau vào một kiểu phức hợp. Bộ giá trị có độ dài cố định: một khi được khai báo, chúng không thể tăng hoặc giảm kích thước.
Chúng ta tạo một bộ giá trị bằng cách viết một danh sách các giá trị được phân tách bằng dấu phẩy bên trong dấu ngoặc đơn. Mỗi vị trí trong bộ giá trị có một kiểu, và các kiểu của các giá trị khác nhau trong bộ giá trị không nhất thiết phải giống nhau. Chúng tôi đã thêm chú thích kiểu tùy chọn trong ví dụ này:
Tên tập tin: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
Biến tup gắn với toàn bộ bộ giá trị vì bộ giá trị được coi là một phần tử phức
hợp đơn lẻ. Để lấy các giá trị riêng lẻ từ một bộ giá trị, chúng ta có thể sử
dụng pattern matching để phá hủy cấu trúc một giá trị bộ giá trị, như sau:
Tên tập tin: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); }
Chương trình này đầu tiên tạo ra một bộ giá trị và gắn nó với biến tup. Sau
đó, nó sử dụng một pattern với let để lấy tup và biến nó thành ba biến riêng
biệt, x, y và z. Điều này được gọi là phá hủy cấu trúc vì nó chia một bộ
giá trị thành ba phần. Cuối cùng, chương trình in giá trị của y, là 6.4.
Chúng ta cũng có thể truy cập trực tiếp một phần tử của bộ giá trị bằng cách sử
dụng dấu chấm (.) theo sau là chỉ số của giá trị mà chúng ta muốn truy cập. Ví
dụ:
Tên tập tin: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
Chương trình này tạo ra bộ giá trị x và sau đó truy cập vào mỗi phần tử của bộ
giá trị bằng cách sử dụng các chỉ số tương ứng của chúng. Như với hầu hết các
ngôn ngữ lập trình, chỉ số đầu tiên trong bộ giá trị là 0.
Bộ giá trị không có giá trị nào có một tên đặc biệt, unit. Giá trị này và kiểu
tương ứng của nó đều được viết là () và đại diện cho một giá trị trống hoặc
một kiểu trả về trống. Biểu thức ngầm định trả về giá trị unit nếu chúng không
trả về bất kỳ giá trị nào khác.
Kiểu Mảng
Một cách khác để có một tập hợp gồm nhiều giá trị là với một mảng. Không giống như bộ giá trị, mọi phần tử của mảng phải có cùng kiểu. Không giống như mảng trong một số ngôn ngữ khác, mảng trong Rust có độ dài cố định.
Chúng ta viết các giá trị trong một mảng như một danh sách được phân tách bằng dấu phẩy bên trong dấu ngoặc vuông:
Tên tập tin: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
Mảng hữu ích khi bạn muốn dữ liệu của mình được phân bổ trên stack, giống như các kiểu khác mà chúng ta đã thấy cho đến nay, thay vì trên heap (chúng ta sẽ thảo luận thêm về stack và heap trong Chương 4) hoặc khi bạn muốn đảm bảo rằng bạn luôn có một số lượng phần tử cố định. Mảng không linh hoạt như kiểu vector, tuy nhiên. Một vector là một kiểu tập hợp tương tự được cung cấp bởi thư viện chuẩn được phép tăng hoặc giảm kích thước vì nội dung của nó nằm trên heap. Nếu bạn không chắc liệu nên sử dụng một mảng hay một vector, khả năng là bạn nên sử dụng một vector. Chương 8 thảo luận chi tiết hơn về vector.
Tuy nhiên, mảng hữu ích hơn khi bạn biết số lượng phần tử sẽ không cần thay đổi. Ví dụ, nếu bạn đang sử dụng tên của các tháng trong một chương trình, bạn có lẽ sẽ sử dụng một mảng thay vì một vector vì bạn biết nó sẽ luôn chứa 12 phần tử:
#![allow(unused)] fn main() { let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; }
Bạn viết kiểu của một mảng bằng cách sử dụng dấu ngoặc vuông với kiểu của mỗi phần tử, dấu chấm phẩy, và sau đó là số phần tử trong mảng, như sau:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
Ở đây, i32 là kiểu của mỗi phần tử. Sau dấu chấm phẩy, số 5 cho biết mảng
chứa năm phần tử.
Bạn cũng có thể khởi tạo một mảng để chứa cùng một giá trị cho mỗi phần tử bằng cách chỉ định giá trị ban đầu, theo sau là dấu chấm phẩy, và sau đó là độ dài của mảng trong dấu ngoặc vuông, như được hiển thị ở đây:
#![allow(unused)] fn main() { let a = [3; 5]; }
Mảng có tên a sẽ chứa 5 phần tử mà tất cả sẽ được thiết lập ban đầu với giá
trị 3. Điều này tương đương với việc viết let a = [3, 3, 3, 3, 3]; nhưng
theo cách ngắn gọn hơn.
Truy Cập Phần Tử Mảng
Một mảng là một khối bộ nhớ đơn với kích thước đã biết, cố định có thể được cấp phát trên stack. Bạn có thể truy cập các phần tử của mảng bằng cách sử dụng chỉ số, như sau:
Tên tập tin: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; }
Trong ví dụ này, biến có tên first sẽ nhận giá trị 1 vì đó là giá trị tại
chỉ số [0] trong mảng. Biến có tên second sẽ nhận giá trị 2 từ chỉ số
[1] trong mảng.
Truy Cập Phần Tử Mảng Không Hợp Lệ
Hãy xem điều gì xảy ra nếu bạn cố gắng truy cập một phần tử của mảng ở ngoài cuối mảng. Giả sử bạn chạy mã này, tương tự như trò chơi đoán số ở Chương 2, để nhận chỉ số mảng từ người dùng:
Tên tập tin: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}Mã này biên dịch thành công. Nếu bạn chạy mã này bằng cargo run và nhập 0,
1, 2, 3, hoặc 4, chương trình sẽ in ra giá trị tương ứng tại chỉ số đó
trong mảng. Nếu thay vào đó bạn nhập một số ngoài cuối mảng, chẳng hạn như 10,
bạn sẽ thấy đầu ra như sau:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Chương trình dẫn đến lỗi thời gian chạy ở điểm sử dụng một giá trị không hợp
lệ trong phép toán đánh chỉ số. Chương trình kết thúc với một thông báo lỗi và
không thực thi câu lệnh println! cuối cùng. Khi bạn cố gắng truy cập một phần
tử bằng cách sử dụng chỉ số, Rust sẽ kiểm tra xem chỉ số mà bạn đã chỉ định có
nhỏ hơn độ dài mảng hay không. Nếu chỉ số lớn hơn hoặc bằng độ dài, Rust sẽ
panic. Kiểm tra này phải được thực hiện ở thời gian chạy, đặc biệt là trong
trường hợp này, vì trình biên dịch không thể nào biết được người dùng sẽ nhập
giá trị nào khi họ chạy mã sau này.
Đây là một ví dụ về nguyên tắc an toàn bộ nhớ của Rust trong hành động. Trong nhiều ngôn ngữ bậc thấp, loại kiểm tra này không được thực hiện, và khi bạn cung cấp một chỉ số không chính xác, bộ nhớ không hợp lệ có thể bị truy cập. Rust bảo vệ bạn khỏi loại lỗi này bằng cách thoát ngay lập tức thay vì cho phép truy cập bộ nhớ và tiếp tục. Chương 9 thảo luận thêm về xử lý lỗi của Rust và cách bạn có thể viết mã an toàn, dễ đọc mà không panic cũng không cho phép truy cập bộ nhớ không hợp lệ.
Các Hàm
Hàm xuất hiện phổ biến trong mã Rust. Bạn đã thấy một trong những hàm quan trọng
nhất trong ngôn ngữ này: hàm main, đó là điểm khởi đầu của nhiều chương trình.
Bạn cũng đã thấy từ khóa fn, cho phép bạn khai báo các hàm mới.
Mã Rust sử dụng snake case là quy ước phong cách cho tên hàm và tên biến, trong đó tất cả các chữ cái đều là chữ thường và dấu gạch dưới phân tách các từ. Đây là một chương trình chứa ví dụ về định nghĩa hàm:
Filename: src/main.rs
fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); }
Chúng ta định nghĩa một hàm trong Rust bằng cách nhập fn theo sau là tên hàm
và một tập hợp dấu ngoặc đơn. Dấu ngoặc nhọn cho trình biên dịch biết nơi bắt
đầu và kết thúc thân hàm.
Chúng ta có thể gọi bất kỳ hàm nào mà chúng ta đã định nghĩa bằng cách nhập tên
hàm theo sau bởi tập hợp dấu ngoặc đơn. Vì another_function được định nghĩa
trong chương trình, nó có thể được gọi từ bên trong hàm main. Lưu ý rằng chúng
ta đã định nghĩa another_function sau hàm main trong mã nguồn; chúng ta
cũng có thể đã định nghĩa nó trước. Rust không quan tâm bạn định nghĩa hàm của
mình ở đâu, chỉ cần chúng được định nghĩa ở đâu đó trong một phạm vi mà người
gọi có thể nhìn thấy.
Hãy bắt đầu một dự án nhị phân mới có tên là functions để khám phá hàm sâu
hơn. Đặt ví dụ another_function trong src/main.rs và chạy nó. Bạn sẽ thấy
kết quả sau:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
Các dòng thực thi theo thứ tự chúng xuất hiện trong hàm main. Đầu tiên, thông
báo "Hello, world!" được in ra, và sau đó another_function được gọi và thông
báo của nó được in ra.
Tham số
Chúng ta có thể định nghĩa hàm có tham số, đó là các biến đặc biệt là một phần của chữ ký hàm. Khi một hàm có tham số, bạn có thể cung cấp cho nó các giá trị cụ thể cho các tham số đó. Về mặt kỹ thuật, các giá trị cụ thể được gọi là đối số, nhưng trong cuộc trò chuyện thông thường, mọi người thường sử dụng từ tham số và đối số thay thế cho nhau cho cả biến trong định nghĩa một hàm hoặc các giá trị cụ thể được truyền vào khi bạn gọi một hàm.
Trong phiên bản này của another_function, chúng ta thêm một tham số:
Filename: src/main.rs
fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); }
Hãy thử chạy chương trình này; bạn sẽ nhận được kết quả sau:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
Khai báo của another_function có một tham số có tên là x. Kiểu của x được
xác định là i32. Khi chúng ta truyền 5 vào another_function, macro
println! đặt 5 vào nơi có cặp dấu ngoặc nhọn chứa x trong chuỗi định dạng.
Trong chữ ký hàm, bạn phải khai báo kiểu của mỗi tham số. Đây là một quyết định có chủ đích trong thiết kế của Rust: yêu cầu chú thích kiểu trong định nghĩa hàm có nghĩa là trình biên dịch hầu như không cần bạn sử dụng chúng ở nơi khác trong mã để xác định kiểu bạn muốn. Trình biên dịch cũng có thể đưa ra thông báo lỗi hữu ích hơn nếu nó biết kiểu nào mà hàm mong đợi.
Khi định nghĩa nhiều tham số, hãy phân tách khai báo tham số bằng dấu phẩy, như thế này:
Filename: src/main.rs
fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); }
Ví dụ này tạo ra một hàm có tên là print_labeled_measurement với hai tham số.
Tham số đầu tiên có tên là value và là một i32. Tham số thứ hai có tên là
unit_label và có kiểu char. Sau đó hàm in ra văn bản chứa cả value và
unit_label.
Hãy thử chạy mã này. Thay thế chương trình hiện có trong tập tin src/main.rs
của dự án functions bằng ví dụ trước đó và chạy nó bằng cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
Vì chúng ta đã gọi hàm với 5 là giá trị cho value và 'h' là giá trị cho
unit_label, kết quả chương trình chứa những giá trị đó.
Câu lệnh và Biểu thức
Phần thân hàm được cấu thành từ một chuỗi các câu lệnh, tùy chọn kết thúc bằng một biểu thức. Cho đến nay, các hàm chúng ta đã đề cập chưa bao gồm một biểu thức kết thúc, nhưng bạn đã thấy một biểu thức như một phần của một câu lệnh. Bởi vì Rust là một ngôn ngữ dựa trên biểu thức, đây là một sự phân biệt quan trọng cần hiểu. Các ngôn ngữ khác không có sự phân biệt giống nhau, vì vậy hãy xem xét câu lệnh và biểu thức là gì và cách sự khác biệt của chúng ảnh hưởng đến phần thân của các hàm.
- Câu lệnh là những chỉ thị thực hiện một số hành động và không trả về giá trị.
- Biểu thức đánh giá thành một giá trị kết quả.
Hãy xem một số ví dụ.
Chúng ta thực sự đã sử dụng câu lệnh và biểu thức rồi. Việc tạo ra một biến và
gán giá trị cho nó với từ khóa let là một câu lệnh. Trong Listing 3-1,
let y = 6; là một câu lệnh.
fn main() { let y = 6; }
Định nghĩa hàm cũng là câu lệnh; toàn bộ ví dụ trước đó là một câu lệnh tự nó. (Như chúng ta sẽ thấy dưới đây, gọi một hàm không phải là một câu lệnh, tuy nhiên.)
Câu lệnh không trả về giá trị. Do đó, bạn không thể gán một câu lệnh let cho
một biến khác, như mã sau cố gắng làm; bạn sẽ gặp lỗi:
Filename: src/main.rs
fn main() {
let x = (let y = 6);
}Khi bạn chạy chương trình này, lỗi bạn sẽ nhận được trông như thế này:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
Câu lệnh let y = 6 không trả về giá trị, vì vậy không có gì để x ràng buộc.
Điều này khác với những gì xảy ra trong các ngôn ngữ khác, chẳng hạn như C và
Ruby, nơi phép gán trả về giá trị của phép gán. Trong các ngôn ngữ đó, bạn có
thể viết x = y = 6 và cả x và y đều có giá trị 6; điều đó không đúng
trong Rust.
Biểu thức đánh giá thành một giá trị và tạo nên phần lớn phần còn lại của mã mà
bạn sẽ viết trong Rust. Hãy xem xét một phép toán toán học, chẳng hạn như
5 + 6, đó là một biểu thức đánh giá thành giá trị 11. Biểu thức có thể là
một phần của câu lệnh: trong Listing 3-1, 6 trong câu lệnh let y = 6; là một
biểu thức đánh giá thành giá trị 6. Gọi một hàm là một biểu thức. Gọi một
macro là một biểu thức. Một khối phạm vi mới được tạo ra với dấu ngoặc nhọn là
một biểu thức, ví dụ:
Filename: src/main.rs
fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); }
Biểu thức này:
{
let x = 3;
x + 1
}là một khối mà trong trường hợp này, đánh giá thành 4. Giá trị đó được ràng
buộc với y như một phần của câu lệnh let. Lưu ý rằng dòng x + 1 không có
dấu chấm phẩy ở cuối, khác với hầu hết các dòng mà bạn đã thấy cho đến nay. Biểu
thức không bao gồm dấu chấm phẩy kết thúc. Nếu bạn thêm dấu chấm phẩy vào cuối
một biểu thức, bạn biến nó thành một câu lệnh, và nó sẽ không trả về giá trị
nữa. Hãy ghi nhớ điều này khi bạn khám phá giá trị trả về của hàm và biểu thức
tiếp theo.
Hàm với Giá trị Trả về
Hàm có thể trả về giá trị cho mã gọi chúng. Chúng ta không đặt tên cho các giá
trị trả về, nhưng chúng ta phải khai báo kiểu của chúng sau một mũi tên (->).
Trong Rust, giá trị trả về của hàm đồng nghĩa với giá trị của biểu thức cuối
cùng trong khối của phần thân hàm. Bạn có thể trả về sớm từ một hàm bằng cách sử
dụng từ khóa return và chỉ định một giá trị, nhưng hầu hết các hàm đều trả về
biểu thức cuối cùng một cách ngầm định. Đây là một ví dụ về một hàm trả về một
giá trị:
Filename: src/main.rs
fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); }
Không có lời gọi hàm, macro, hay thậm chí câu lệnh let trong hàm five—chỉ có
số 5 đứng một mình. Đó là một hàm hoàn toàn hợp lệ trong Rust. Lưu ý rằng kiểu
trả về của hàm cũng được chỉ định, là -> i32. Hãy thử chạy mã này; kết quả sẽ
trông như thế này:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
Số 5 trong five là giá trị trả về của hàm, đó là lý do tại sao kiểu trả về
là i32. Hãy xem xét điều này chi tiết hơn. Có hai phần quan trọng: đầu tiên,
dòng let x = five(); cho thấy rằng chúng ta đang sử dụng giá trị trả về của
một hàm để khởi tạo một biến. Bởi vì hàm five trả về 5, dòng đó giống như
sau:
#![allow(unused)] fn main() { let x = 5; }
Thứ hai, hàm five không có tham số và định nghĩa kiểu của giá trị trả về,
nhưng phần thân của hàm chỉ là một 5 cô đơn không có dấu chấm phẩy vì đó là
một biểu thức mà chúng ta muốn trả về giá trị.
Hãy xem một ví dụ khác:
Filename: src/main.rs
fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 }
Chạy mã này sẽ in ra The value of x is: 6. Nhưng nếu chúng ta đặt một dấu chấm
phẩy ở cuối dòng chứa x + 1, biến nó từ một biểu thức thành một câu lệnh,
chúng ta sẽ nhận được lỗi:
Filename: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}Biên dịch mã này tạo ra lỗi như sau:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Thông báo lỗi chính, mismatched types (không khớp kiểu), tiết lộ vấn đề cốt
lõi với mã này. Định nghĩa của hàm plus_one nói rằng nó sẽ trả về một i32,
nhưng câu lệnh không đánh giá thành một giá trị, được biểu thị bởi (), kiểu
đơn vị. Do đó, không có gì được trả về, mâu thuẫn với định nghĩa hàm và dẫn đến
lỗi. Trong kết quả này, Rust cung cấp một thông báo để có thể giúp khắc phục vấn
đề này: nó đề xuất loại bỏ dấu chấm phẩy, điều đó sẽ khắc phục lỗi.
Chú thích
Tất cả các lập trình viên đều cố gắng làm cho mã của họ dễ hiểu, nhưng đôi khi cần có những giải thích thêm. Trong những trường hợp này, lập trình viên để lại chú thích (comments) trong mã nguồn mà trình biên dịch sẽ bỏ qua nhưng người đọc mã nguồn có thể thấy hữu ích.
Đây là một chú thích đơn giản:
#![allow(unused)] fn main() { // xin chào, thế giới }
Trong Rust, phong cách chú thích thông dụng bắt đầu bằng hai dấu gạch chéo, và
chú thích tiếp tục đến hết dòng. Đối với các chú thích kéo dài hơn một dòng, bạn
cần phải thêm // ở mỗi dòng, như thế này:
#![allow(unused)] fn main() { // Chúng ta đang làm một điều gì đó phức tạp ở đây, đủ dài để chúng ta cần // nhiều dòng chú thích để làm điều đó! Ồ! Hy vọng rằng, chú thích này sẽ // giải thích những gì đang diễn ra. }
Chú thích cũng có thể được đặt ở cuối dòng chứa mã:
Tên tệp: src/main.rs
fn main() { let lucky_number = 7; // I'm feeling lucky today }
Nhưng bạn sẽ thường thấy chúng được sử dụng trong định dạng này, với chú thích trên một dòng riêng phía trên mã mà nó đang chú thích:
Tên tệp: src/main.rs
fn main() { // I'm feeling lucky today let lucky_number = 7; }
Rust cũng có một loại chú thích khác, chú thích tài liệu, mà chúng ta sẽ thảo luận trong phần "Xuất bản một Crate lên Crates.io" của Chương 14.
Luồng Điều Khiển
Khả năng chạy một số mã tùy thuộc vào việc một điều kiện là true và chạy một
số mã lặp đi lặp lại trong khi một điều kiện là true là những khối xây dựng cơ
bản trong hầu hết các ngôn ngữ lập trình. Các cấu trúc phổ biến nhất cho phép
bạn kiểm soát luồng thực thi của mã Rust là biểu thức if và vòng lặp.
Biểu Thức if
Biểu thức if cho phép bạn phân nhánh mã của mình dựa trên các điều kiện. Bạn
cung cấp một điều kiện và sau đó nói, "Nếu điều kiện này được đáp ứng, hãy chạy
khối mã này. Nếu điều kiện không được đáp ứng, đừng chạy khối mã này."
Tạo một dự án mới có tên branches trong thư mục projects của bạn để khám phá
biểu thức if. Trong tệp src/main.rs, nhập nội dung sau:
Tên tệp: src/main.rs
fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } }
Tất cả các biểu thức if bắt đầu bằng từ khóa if, theo sau là một điều kiện.
Trong trường hợp này, điều kiện kiểm tra xem biến number có giá trị nhỏ hơn 5
hay không. Chúng ta đặt khối mã để thực thi nếu điều kiện là true ngay sau
điều kiện bên trong dấu ngoặc nhọn. Các khối mã liên kết với các điều kiện trong
biểu thức if đôi khi được gọi là nhánh, giống như các nhánh trong biểu thức
match mà chúng ta đã thảo luận trong phần "So Sánh Dự Đoán với Số Bí
Mật" của Chương 2.
Tùy chọn, chúng ta cũng có thể bao gồm một biểu thức else, mà chúng ta đã chọn
ở đây, để cung cấp cho chương trình một khối mã thay thế để thực thi nếu điều
kiện đánh giá thành false. Nếu bạn không cung cấp một biểu thức else và điều
kiện là false, chương trình sẽ bỏ qua khối if và chuyển sang đoạn mã tiếp
theo.
Hãy thử chạy mã này; bạn sẽ thấy đầu ra sau:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
Hãy thử thay đổi giá trị của number thành một giá trị khiến điều kiện thành
false để xem điều gì xảy ra:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Chạy chương trình lần nữa và xem đầu ra:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
Cũng cần lưu ý rằng điều kiện trong mã này phải là một bool. Nếu điều kiện
không phải là bool, chúng ta sẽ gặp lỗi. Ví dụ, hãy thử chạy mã sau:
Tên tệp: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}Điều kiện if đánh giá thành một giá trị 3 lần này, và Rust báo lỗi:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Lỗi chỉ ra rằng Rust mong đợi một bool nhưng nhận được một số nguyên. Không
giống như các ngôn ngữ như Ruby và JavaScript, Rust sẽ không tự động chuyển đổi
các kiểu không phải Boolean thành Boolean. Bạn phải rõ ràng và luôn cung cấp cho
if một Boolean làm điều kiện của nó. Nếu chúng ta muốn khối mã if chạy chỉ
khi một số không bằng 0, ví dụ, chúng ta có thể thay đổi biểu thức if thành
như sau:
Tên tệp: src/main.rs
fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } }
Chạy mã này sẽ in ra number was something other than zero.
Xử Lý Nhiều Điều Kiện với else if
Bạn có thể sử dụng nhiều điều kiện bằng cách kết hợp if và else trong một
biểu thức else if. Ví dụ:
Tên tệp: src/main.rs
fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
Chương trình này có bốn đường dẫn có thể thực hiện. Sau khi chạy nó, bạn sẽ thấy đầu ra sau:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
Khi chương trình này thực thi, nó kiểm tra từng biểu thức if lần lượt và thực
thi thân đầu tiên mà điều kiện đánh giá thành true. Lưu ý rằng mặc dù 6 chia
hết cho 2, chúng ta không thấy đầu ra number is divisible by 2, cũng không
thấy văn bản number is not divisible by 4, 3, or 2 từ khối else. Đó là vì
Rust chỉ thực thi khối cho điều kiện true đầu tiên, và khi tìm thấy một điều
kiện, nó thậm chí không kiểm tra phần còn lại.
Sử dụng quá nhiều biểu thức else if có thể làm rối mã của bạn, vì vậy nếu bạn
có nhiều hơn một, bạn có thể muốn cấu trúc lại mã của mình. Chương 6 mô tả một
cấu trúc phân nhánh mạnh mẽ của Rust gọi là match cho những trường hợp này.
Sử dụng if trong một câu lệnh let
Vì if là một biểu thức, chúng ta có thể sử dụng nó ở phía bên phải của câu
lệnh let để gán kết quả cho một biến, như trong Listing 3-2.
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); }
Biến number sẽ được gắn với một giá trị dựa trên kết quả của biểu thức if.
Chạy mã này để xem điều gì xảy ra:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
Hãy nhớ rằng các khối mã đánh giá thành biểu thức cuối cùng trong chúng, và các
số tự chúng cũng là biểu thức. Trong trường hợp này, giá trị của toàn bộ biểu
thức if phụ thuộc vào khối mã nào được thực thi. Điều này có nghĩa là các giá
trị có khả năng là kết quả từ mỗi nhánh của if phải cùng một loại; trong
Listing 3-2, kết quả của cả nhánh if và nhánh else đều là số nguyên i32.
Nếu các loại không khớp, như trong ví dụ sau, chúng ta sẽ gặp lỗi:
Tên tệp: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}Khi cố gắng biên dịch mã này, chúng ta sẽ gặp lỗi. Các nhánh if và else có
kiểu giá trị không tương thích, và Rust chỉ ra chính xác nơi tìm thấy vấn đề
trong chương trình:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Biểu thức trong khối if đánh giá thành một số nguyên, và biểu thức trong khối
else đánh giá thành một chuỗi. Điều này sẽ không hoạt động vì các biến phải có
một kiểu duy nhất, và Rust cần biết tại thời điểm biên dịch kiểu biến number
là gì, một cách chắc chắn. Biết kiểu của number cho phép trình biên dịch xác
minh kiểu là hợp lệ ở mọi nơi chúng ta sử dụng number. Rust sẽ không thể làm
điều đó nếu kiểu của number chỉ được xác định trong thời gian chạy; trình biên
dịch sẽ phức tạp hơn và sẽ cung cấp ít đảm bảo hơn về mã nếu phải theo dõi nhiều
kiểu giả định cho bất kỳ biến nào.
Lặp Lại với Vòng Lặp
Thường rất hữu ích để thực thi một khối mã nhiều lần. Cho nhiệm vụ này, Rust cung cấp một số vòng lặp, sẽ chạy qua mã bên trong thân vòng lặp đến cuối và sau đó bắt đầu lại từ đầu ngay lập tức. Để thử nghiệm với vòng lặp, hãy tạo một dự án mới có tên loops.
Rust có ba loại vòng lặp: loop, while, và for. Hãy thử từng loại.
Lặp Lại Mã với loop
Từ khóa loop yêu cầu Rust thực thi một khối mã lặp đi lặp lại mãi mãi hoặc cho
đến khi bạn yêu cầu nó dừng lại.
Ví dụ, hãy thay đổi tệp src/main.rs trong thư mục loops của bạn để trông như thế này:
Tên tệp: src/main.rs
fn main() {
loop {
println!("again!");
}
}Khi chúng ta chạy chương trình này, chúng ta sẽ thấy again! được in liên tục
cho đến khi chúng ta dừng chương trình bằng tay. Hầu hết các terminal hỗ trợ
phím tắt ctrl-c để ngắt một chương trình bị kẹt trong một
vòng lặp liên tục. Hãy thử:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
Ký hiệu ^C biểu thị nơi bạn đã nhấn ctrl-c.
Bạn có thể sẽ thấy hoặc không thấy từ again! được in sau ^C, tùy thuộc vào
vị trí mã trong vòng lặp khi nó nhận được tín hiệu ngắt.
May mắn thay, Rust cũng cung cấp một cách để thoát khỏi vòng lặp bằng mã. Bạn có
thể đặt từ khóa break trong vòng lặp để yêu cầu chương trình dừng thực thi
vòng lặp. Hãy nhớ rằng chúng ta đã làm điều này trong trò chơi đoán số ở phần
"Thoát Sau Khi Đoán Đúng" của
Chương 2 để thoát chương trình khi người dùng thắng trò chơi bằng cách đoán đúng
số.
Chúng ta cũng đã sử dụng continue trong trò chơi đoán số, trong một vòng lặp
nó bảo chương trình bỏ qua bất kỳ mã còn lại nào trong lần lặp này của vòng lặp
và chuyển sang lần lặp tiếp theo.
Trả Về Giá Trị từ Vòng Lặp
Một trong những cách sử dụng của loop là thử lại một hoạt động mà bạn biết có
thể thất bại, chẳng hạn như kiểm tra xem một luồng đã hoàn thành công việc của
nó hay chưa. Bạn cũng có thể cần truyền kết quả của hoạt động đó ra khỏi vòng
lặp đến phần còn lại của mã của bạn. Để làm điều này, bạn có thể thêm giá trị
bạn muốn trả về sau biểu thức break bạn sử dụng để dừng vòng lặp; giá trị đó
sẽ được trả về từ vòng lặp để bạn có thể sử dụng nó, như được hiển thị ở đây:
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); }
Trước vòng lặp, chúng ta khai báo một biến có tên counter và khởi tạo nó thành
0. Sau đó, chúng ta khai báo một biến có tên result để giữ giá trị trả về từ
vòng lặp. Trong mỗi lần lặp của vòng lặp, chúng ta thêm 1 vào biến counter,
và sau đó kiểm tra xem counter có bằng 10 không. Khi nó bằng 10, chúng ta
sử dụng từ khóa break với giá trị counter * 2. Sau vòng lặp, chúng ta sử
dụng dấu chấm phẩy để kết thúc câu lệnh gán giá trị cho result. Cuối cùng,
chúng ta in giá trị trong result, trong trường hợp này là 20.
Bạn cũng có thể return từ bên trong một vòng lặp. Trong khi break chỉ thoát
khỏi vòng lặp hiện tại, return luôn thoát khỏi hàm hiện tại.
Nhãn Vòng Lặp để Phân Biệt Giữa Nhiều Vòng Lặp
Nếu bạn có vòng lặp trong vòng lặp, break và continue áp dụng cho vòng lặp
bên trong nhất tại thời điểm đó. Bạn có thể tùy chọn chỉ định một nhãn vòng
lặp trên một vòng lặp mà bạn có thể sử dụng với break hoặc continue để chỉ
định rằng những từ khóa đó áp dụng cho vòng lặp được gắn nhãn thay vì vòng lặp
bên trong nhất. Nhãn vòng lặp phải bắt đầu bằng một dấu nháy đơn. Đây là một ví
dụ với hai vòng lặp lồng nhau:
fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); }
Vòng lặp bên ngoài có nhãn 'counting_up, và nó sẽ đếm lên từ 0 đến 2. Vòng lặp
bên trong không có nhãn đếm ngược từ 10 đến 9. break đầu tiên không chỉ định
nhãn sẽ chỉ thoát khỏi vòng lặp bên trong. Câu lệnh break 'counting_up; sẽ
thoát khỏi vòng lặp bên ngoài. Mã này in:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
Vòng Lặp Có Điều Kiện với while
Một chương trình thường cần đánh giá một điều kiện trong một vòng lặp. Trong khi
điều kiện là true, vòng lặp chạy. Khi điều kiện không còn là true, chương
trình gọi break, dừng vòng lặp. Có thể thực hiện hành vi như thế này bằng cách
kết hợp loop, if, else, và break; bạn có thể thử điều đó bây giờ trong
một chương trình, nếu bạn muốn. Tuy nhiên, mẫu này rất phổ biến nên Rust có một
cấu trúc ngôn ngữ tích hợp cho nó, gọi là vòng lặp while. Trong Listing 3-3,
chúng ta sử dụng while để chạy chương trình ba lần, đếm ngược mỗi lần, và sau
đó, sau vòng lặp, in một thông báo và thoát.
fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); }
Cấu trúc này loại bỏ rất nhiều việc lồng nhau sẽ cần thiết nếu bạn sử dụng
loop, if, else, và break, và nó rõ ràng hơn. Trong khi một điều kiện
đánh giá thành true, mã chạy; nếu không, nó thoát khỏi vòng lặp.
Lặp Qua một Tập Hợp với for
Bạn có thể chọn sử dụng cấu trúc while để lặp qua các phần tử của một tập hợp,
chẳng hạn như một mảng. Ví dụ, vòng lặp trong Listing 3-4 in ra từng phần tử
trong mảng a.
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } }
Ở đây, mã đếm qua các phần tử trong mảng. Nó bắt đầu từ chỉ mục 0, và sau đó
lặp cho đến khi đạt đến chỉ mục cuối cùng trong mảng (đó là khi index < 5
không còn true nữa). Chạy mã này sẽ in mọi phần tử trong mảng:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
Tất cả năm giá trị mảng xuất hiện trong terminal, như mong đợi. Mặc dù index
sẽ đạt đến giá trị 5 tại một thời điểm nào đó, vòng lặp dừng thực thi trước
khi cố gắng lấy giá trị thứ sáu từ mảng.
Tuy nhiên, cách tiếp cận này dễ xảy ra lỗi; chúng ta có thể khiến chương trình
hoảng sợ nếu giá trị chỉ mục hoặc điều kiện kiểm tra không chính xác. Ví dụ, nếu
bạn thay đổi định nghĩa của mảng a để có bốn phần tử nhưng quên cập nhật điều
kiện thành while index < 4, mã sẽ hoảng sợ. Nó cũng chậm, vì trình biên dịch
thêm mã thời gian chạy để thực hiện kiểm tra điều kiện xem chỉ mục có nằm trong
giới hạn của mảng trong mỗi lần lặp qua vòng lặp không.
Là một lựa chọn thay thế ngắn gọn hơn, bạn có thể sử dụng vòng lặp for và thực
thi một số mã cho mỗi phần tử trong một tập hợp. Một vòng lặp for trông giống
như mã trong Listing 3-5.
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } }
Khi chúng ta chạy mã này, chúng ta sẽ thấy đầu ra giống như trong Listing 3-4.
Quan trọng hơn, bây giờ chúng ta đã tăng độ an toàn của mã và loại bỏ khả năng
xảy ra lỗi có thể dẫn đến vượt quá cuối mảng hoặc không đi đủ xa và bỏ qua một
số phần tử. Mã máy được tạo từ vòng lặp for cũng có thể hiệu quả hơn, vì chỉ
mục không cần phải so sánh với độ dài của mảng ở mỗi lần lặp.
Sử dụng vòng lặp for, bạn sẽ không cần phải nhớ thay đổi bất kỳ mã nào khác
nếu bạn thay đổi số lượng giá trị trong mảng, như bạn sẽ làm với phương pháp
được sử dụng trong Listing 3-4.
Sự an toàn và ngắn gọn của vòng lặp for làm cho chúng trở thành cấu trúc vòng
lặp được sử dụng phổ biến nhất trong Rust. Ngay cả trong những tình huống mà bạn
muốn chạy một số mã một số lần nhất định, như trong ví dụ đếm ngược sử dụng vòng
lặp while trong Listing 3-3, hầu hết người dùng Rust sẽ sử dụng vòng lặp
for. Cách để làm điều đó sẽ là sử dụng một Range, được cung cấp bởi thư viện
tiêu chuẩn, tạo ra tất cả các số theo thứ tự bắt đầu từ một số và kết thúc trước
một số khác.
Đây là cách đếm ngược sẽ trông như thế nào khi sử dụng vòng lặp for và một
phương pháp khác mà chúng ta chưa nói đến, rev, để đảo ngược phạm vi:
Tên tệp: src/main.rs
fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); }
Mã này tốt hơn một chút, phải không?
Tóm Tắt
Bạn đã làm được! Đây là một chương đáng kể: bạn đã học về biến, kiểu dữ liệu vô
hướng và phức hợp, hàm, nhận xét, biểu thức if, và vòng lặp! Để thực hành với
các khái niệm được thảo luận trong chương này, hãy thử xây dựng các chương trình
để thực hiện các việc sau:
- Chuyển đổi nhiệt độ giữa Fahrenheit và Celsius.
- Tạo số Fibonacci thứ n.
- In lời bài hát Giáng sinh "The Twelve Days of Christmas", tận dụng sự lặp lại trong bài hát.
Khi bạn sẵn sàng tiếp tục, chúng ta sẽ nói về một khái niệm trong Rust mà không thường tồn tại trong các ngôn ngữ lập trình khác: quyền sở hữu.
Hiểu về Ownership
Ownership (quyền sở hữu) là tính năng độc đáo nhất của Rust và có ảnh hưởng sâu sắc đến phần còn lại của ngôn ngữ. Nó cho phép Rust đảm bảo an toàn bộ nhớ mà không cần bộ thu gom rác (garbage collector), vì vậy việc hiểu cách ownership hoạt động là rất quan trọng. Trong chương này, chúng ta sẽ nói về ownership cũng như một số tính năng liên quan: borrowing (mượn), slices (lát cắt), và cách Rust bố trí dữ liệu trong bộ nhớ.
Quyền Sở Hữu Là Gì?
Quyền sở hữu (Ownership) là một tập hợp các quy tắc chi phối cách chương trình Rust quản lý bộ nhớ. Tất cả các chương trình đều phải quản lý cách sử dụng bộ nhớ máy tính khi chạy. Một số ngôn ngữ có cơ chế thu gom rác (garbage collection) thường xuyên tìm kiếm bộ nhớ không còn được sử dụng khi chương trình đang chạy; trong các ngôn ngữ khác, lập trình viên phải cấp phát và giải phóng bộ nhớ một cách rõ ràng. Rust sử dụng cách tiếp cận thứ ba: bộ nhớ được quản lý thông qua hệ thống quyền sở hữu với một tập hợp các quy tắc mà trình biên dịch kiểm tra. Nếu bất kỳ quy tắc nào bị vi phạm, chương trình sẽ không biên dịch được. Không có tính năng nào của quyền sở hữu sẽ làm chậm chương trình khi nó đang chạy.
Vì quyền sở hữu là một khái niệm mới đối với nhiều lập trình viên, nên cần một khoảng thời gian để làm quen. Tin tốt là càng có nhiều kinh nghiệm với Rust và các quy tắc của hệ thống quyền sở hữu, bạn sẽ càng dễ dàng phát triển một cách tự nhiên các đoạn mã an toàn và hiệu quả. Hãy cứ tiếp tục!
Khi bạn hiểu quyền sở hữu, bạn sẽ có một nền tảng vững chắc để hiểu các tính năng khiến Rust trở nên độc đáo. Trong chương này, bạn sẽ học về quyền sở hữu thông qua làm việc với một số ví dụ tập trung vào một cấu trúc dữ liệu rất phổ biến: chuỗi (strings).
Stack và Heap
Nhiều ngôn ngữ lập trình không yêu cầu bạn phải suy nghĩ về stack và heap thường xuyên. Nhưng trong một ngôn ngữ lập trình hệ thống như Rust, việc một giá trị nằm trên stack hay heap ảnh hưởng đến cách ngôn ngữ hoạt động và lý do bạn phải đưa ra những quyết định nhất định. Các phần của quyền sở hữu sẽ được mô tả liên quan đến stack và heap sau trong chương này, vì vậy đây là một giải thích ngắn gọn để chuẩn bị.
Cả stack và heap đều là những phần của bộ nhớ có sẵn để mã của bạn sử dụng trong thời gian chạy, nhưng chúng được cấu trúc theo những cách khác nhau. Stack lưu trữ các giá trị theo thứ tự nhận được và xóa các giá trị theo thứ tự ngược lại. Điều này được gọi là vào sau, ra trước (last in, first out). Hãy nghĩ về một chồng đĩa: khi bạn thêm đĩa, bạn đặt chúng lên trên cùng của chồng, và khi bạn cần một cái đĩa, bạn lấy một cái từ trên cùng. Việc thêm hoặc xóa đĩa từ giữa hoặc đáy sẽ không hiệu quả! Việc thêm dữ liệu được gọi là đẩy vào stack, và việc xóa dữ liệu được gọi là lấy ra khỏi stack. Tất cả dữ liệu được lưu trữ trên stack phải có kích thước đã biết và cố định. Dữ liệu có kích thước không xác định tại thời điểm biên dịch hoặc kích thước có thể thay đổi phải được lưu trữ trên heap thay thế.
Heap ít có tổ chức hơn: khi bạn đặt dữ liệu trên heap, bạn yêu cầu một lượng không gian nhất định. Bộ phân bổ bộ nhớ tìm một chỗ trống trong heap đủ lớn, đánh dấu nó là đang sử dụng, và trả về một con trỏ, đó là địa chỉ của vị trí đó. Quá trình này được gọi là cấp phát trên heap và đôi khi được viết tắt là chỉ cấp phát (việc đẩy các giá trị vào stack không được coi là cấp phát). Vì con trỏ đến heap có kích thước đã biết và cố định, bạn có thể lưu trữ con trỏ trên stack, nhưng khi bạn muốn dữ liệu thực tế, bạn phải đi theo con trỏ. Hãy nghĩ về việc được sắp xếp chỗ ngồi tại một nhà hàng. Khi bạn vào, bạn nói số người trong nhóm của bạn, và người phục vụ tìm một bàn trống vừa đủ cho mọi người và dẫn bạn đến đó. Nếu ai đó trong nhóm của bạn đến muộn, họ có thể hỏi bạn đã được xếp chỗ ở đâu để tìm bạn.
Đẩy vào stack nhanh hơn cấp phát trên heap vì bộ cấp phát không bao giờ phải tìm kiếm vị trí để lưu trữ dữ liệu mới; vị trí đó luôn ở đỉnh của stack. So sánh, việc cấp phát không gian trên heap đòi hỏi nhiều công việc hơn vì bộ cấp phát phải trước tiên tìm một không gian đủ lớn để chứa dữ liệu và sau đó thực hiện các công việc quản lý để chuẩn bị cho lần cấp phát tiếp theo.
Truy cập dữ liệu trong heap thường chậm hơn truy cập dữ liệu trên stack vì bạn phải đi theo con trỏ để đến đó. Các bộ xử lý hiện đại nhanh hơn nếu chúng nhảy ít hơn trong bộ nhớ. Tiếp tục ví dụ, hãy xem xét một người phục vụ tại nhà hàng đang nhận đơn đặt hàng từ nhiều bàn. Hiệu quả nhất là lấy tất cả đơn đặt hàng tại một bàn trước khi chuyển sang bàn tiếp theo. Việc nhận đơn đặt hàng từ bàn A, sau đó nhận đơn đặt hàng từ bàn B, sau đó quay lại A, và sau đó lại đến bàn B sẽ là một quá trình chậm hơn nhiều. Tương tự, bộ xử lý thường có thể làm công việc của mình tốt hơn nếu nó làm việc với dữ liệu gần với dữ liệu khác (như trên stack) thay vì xa hơn (như có thể trên heap).
Khi mã của bạn gọi một hàm, các giá trị được truyền vào hàm (bao gồm cả các con trỏ đến dữ liệu trên heap) và các biến cục bộ của hàm được đẩy vào stack. Khi hàm kết thúc, những giá trị này được lấy ra khỏi stack.
Theo dõi những phần mã nào đang sử dụng dữ liệu nào trên heap, giảm thiểu lượng dữ liệu trùng lặp trên heap, và dọn sạch dữ liệu không sử dụng trên heap để bạn không bị hết không gian, tất cả đều là những vấn đề mà quyền sở hữu giải quyết. Một khi bạn hiểu quyền sở hữu, bạn sẽ không cần phải nghĩ về stack và heap thường xuyên nữa, nhưng biết rằng mục đích chính của quyền sở hữu là quản lý dữ liệu heap có thể giúp giải thích lý do tại sao nó hoạt động như vậy.
Các Quy Tắc Quyền Sở Hữu
Đầu tiên, hãy xem xét các quy tắc quyền sở hữu. Ghi nhớ những quy tắc này khi chúng ta làm việc với các ví dụ minh họa:
- Mỗi giá trị trong Rust có một chủ sở hữu.
- Tại một thời điểm chỉ có thể có một chủ sở hữu.
- Khi chủ sở hữu ra khỏi phạm vi, giá trị sẽ bị hủy.
Phạm Vi Biến
Bây giờ chúng ta đã vượt qua cú pháp Rust cơ bản, chúng ta sẽ không bao gồm tất
cả mã fn main() { trong các ví dụ, vì vậy nếu bạn đang làm theo, hãy đảm bảo
đặt các ví dụ sau vào hàm main một cách thủ công. Do đó, các ví dụ của chúng
ta sẽ ngắn gọn hơn một chút, cho phép chúng ta tập trung vào các chi tiết thực
tế hơn là mã boilerplate.
Như một ví dụ đầu tiên về quyền sở hữu, chúng ta sẽ xem xét phạm vi của một số biến. Một phạm vi là phạm vi trong một chương trình mà một mục có giá trị. Xét biến sau:
#![allow(unused)] fn main() { let s = "hello"; }
Biến s tham chiếu đến một chuỗi chữ, trong đó giá trị của chuỗi được mã hóa
cứng vào văn bản của chương trình của chúng ta. Biến có giá trị từ điểm mà nó
được khai báo cho đến khi kết thúc phạm vi hiện tại. Listing 4-1 cho thấy một
chương trình với các chú thích cho biết nơi biến s sẽ có giá trị.
fn main() { { // s is not valid here, since it's not yet declared let s = "hello"; // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no longer valid }
Nói cách khác, có hai điểm quan trọng về thời gian ở đây:
- Khi
svào phạm vi, nó có giá trị. - Nó vẫn có giá trị cho đến khi nó ra khỏi phạm vi.
Ở điểm này, mối quan hệ giữa phạm vi và thời điểm các biến có giá trị tương tự
như trong các ngôn ngữ lập trình khác. Bây giờ chúng ta sẽ xây dựng dựa trên
hiểu biết này bằng cách giới thiệu kiểu dữ liệu String.
Kiểu String
Để minh họa các quy tắc của quyền sở hữu, chúng ta cần một kiểu dữ liệu phức tạp
hơn những gì chúng ta đã đề cập trong phần "Kiểu Dữ
Liệu" của Chương 3. Các kiểu được đề cập trước đó có
kích thước đã biết, có thể được lưu trữ trên stack và lấy ra khỏi stack khi phạm
vi của chúng kết thúc, và có thể được sao chép nhanh chóng và dễ dàng để tạo một
phiên bản độc lập mới nếu một phần khác của mã cần sử dụng cùng giá trị trong
phạm vi khác. Nhưng chúng ta muốn xem xét dữ liệu được lưu trữ trên heap và khám
phá cách Rust biết khi nào dọn dẹp dữ liệu đó, và kiểu String là một ví dụ
tuyệt vời.
Chúng ta sẽ tập trung vào các phần của String liên quan đến quyền sở hữu.
Những khía cạnh này cũng áp dụng cho các kiểu dữ liệu phức tạp khác, dù chúng
được cung cấp bởi thư viện chuẩn hay được tạo bởi bạn. Chúng ta sẽ thảo luận về
String sâu hơn trong Chương 8.
Chúng ta đã thấy các chuỗi chữ, trong đó giá trị chuỗi được mã hóa cứng vào
chương trình của chúng ta. Chuỗi chữ rất tiện lợi, nhưng chúng không phù hợp cho
mọi tình huống mà chúng ta muốn sử dụng văn bản. Một lý do là chúng không thay
đổi được. Một lý do khác là không phải mọi giá trị chuỗi đều có thể biết khi
chúng ta viết mã của mình: ví dụ, nếu chúng ta muốn lấy đầu vào từ người dùng và
lưu trữ nó? Đối với những tình huống này, Rust có một kiểu chuỗi thứ hai,
String. Kiểu này quản lý dữ liệu được cấp phát trên heap và do đó có thể lưu
trữ một lượng văn bản không xác định đối với chúng ta tại thời điểm biên dịch.
Bạn có thể tạo một String từ một chuỗi chữ bằng cách sử dụng hàm from, như
sau:
#![allow(unused)] fn main() { let s = String::from("hello"); }
Toán tử hai dấu hai chấm :: cho phép chúng ta đặt tên hàm from cụ thể này
dưới kiểu String thay vì sử dụng một loại tên như string_from. Chúng ta sẽ
thảo luận về cú pháp này nhiều hơn trong phần "Cú pháp Phương
thức" của Chương 5, và khi chúng ta nói về không
gian tên với các mô-đun trong "Đường dẫn để Tham chiếu đến một Mục trong Cây
Mô-đun" trong Chương 7.
Loại chuỗi này có thể thay đổi:
fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() appends a literal to a String println!("{s}"); // this will print `hello, world!` }
Vậy, sự khác biệt ở đây là gì? Tại sao String có thể thay đổi được nhưng các
chuỗi chữ thì không? Sự khác biệt nằm ở cách hai loại này xử lý bộ nhớ.
Bộ Nhớ và Cấp Phát
Trong trường hợp của chuỗi chữ, chúng ta biết nội dung tại thời điểm biên dịch, vì vậy văn bản được mã hóa cứng trực tiếp vào tệp thực thi cuối cùng. Đây là lý do tại sao chuỗi chữ nhanh chóng và hiệu quả. Nhưng những thuộc tính này chỉ có từ tính không thay đổi của chuỗi chữ. Tiếc thay, chúng ta không thể đặt một khối bộ nhớ vào tệp nhị phân cho mỗi đoạn văn bản có kích thước không xác định tại thời điểm biên dịch và có kích thước có thể thay đổi trong khi chạy chương trình.
Với kiểu String, để hỗ trợ một đoạn văn bản có thể thay đổi và phát triển,
chúng ta cần phân bổ một lượng bộ nhớ trên heap, không xác định tại thời điểm
biên dịch, để chứa nội dung. Điều này có nghĩa:
- Bộ nhớ phải được yêu cầu từ bộ phân bổ bộ nhớ tại thời điểm chạy.
- Chúng ta cần một cách để trả lại bộ nhớ này cho bộ cấp phát khi chúng ta đã
xong với
Stringcủa mình.
Phần đầu tiên được thực hiện bởi chúng ta: khi chúng ta gọi String::from, việc
triển khai của nó yêu cầu bộ nhớ mà nó cần. Điều này khá phổ biến trong lập
trình ngôn ngữ.
Tuy nhiên, phần thứ hai là khác nhau. Trong các ngôn ngữ có bộ thu gom rác
(GC), GC theo dõi và dọn dẹp bộ nhớ không còn được sử dụng nữa, và chúng ta
không cần phải nghĩ về nó. Trong hầu hết các ngôn ngữ không có GC, trách nhiệm
của chúng ta là xác định khi nào bộ nhớ không còn được sử dụng và gọi mã để giải
phóng nó một cách rõ ràng, giống như chúng ta đã yêu cầu nó. Làm điều này một
cách chính xác về mặt lịch sử là một vấn đề lập trình khó khăn. Nếu chúng ta
quên, chúng ta sẽ lãng phí bộ nhớ. Nếu chúng ta làm quá sớm, chúng ta sẽ có một
biến không hợp lệ. Nếu chúng ta làm hai lần, đó cũng là một lỗi. Chúng ta cần
ghép chính xác một allocate với chính xác một free.
Rust đi theo một con đường khác: bộ nhớ được trả lại tự động một khi biến sở hữu
nó ra khỏi phạm vi. Dưới đây là một phiên bản của ví dụ phạm vi từ Listing 4-1
sử dụng một String thay vì một chuỗi chữ:
fn main() { { let s = String::from("hello"); // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no // longer valid }
Có một điểm tự nhiên mà chúng ta có thể trả lại bộ nhớ mà String của chúng ta
cần cho bộ cấp phát: khi s ra khỏi phạm vi. Khi một biến ra khỏi phạm vi, Rust
gọi một hàm đặc biệt cho chúng ta. Hàm này được gọi là
drop, và đó là nơi tác giả của String có thể đặt mã
để trả lại bộ nhớ. Rust gọi drop tự động tại dấu ngoặc nhọn đóng.
Lưu ý: Trong C++, mô hình này của việc phân bổ tài nguyên tại cuối của vòng đời của một mục đôi khi được gọi là Resource Acquisition Is Initialization (RAII). Chức năng
droptrong Rust sẽ quen thuộc với bạn nếu bạn đã sử dụng các mẫu RAII.
Mô hình này có một tác động sâu sắc đến cách mã Rust được viết. Nó có vẻ đơn giản ngay bây giờ, nhưng hành vi của mã có thể bất ngờ trong các tình huống phức tạp hơn khi chúng ta muốn có nhiều biến sử dụng dữ liệu chúng ta đã cấp phát trên heap. Hãy khám phá một số tình huống đó ngay bây giờ.
Các Biến và Dữ Liệu Tương Tác với Move
Nhiều biến có thể tương tác với cùng một dữ liệu theo những cách khác nhau trong Rust. Hãy xem một ví dụ sử dụng một số nguyên trong Listing 4-2.
fn main() { let x = 5; let y = x; }
Chúng ta có thể đoán được đoạn mã này đang làm gì: "gán giá trị 5 cho x; sau
đó tạo một bản sao của giá trị trong x và gán nó cho y." Bây giờ chúng ta có
hai biến, x và y, và cả hai đều bằng 5. Đây thực sự là những gì đang xảy
ra, bởi vì số nguyên là các giá trị đơn giản với kích thước đã biết, cố định, và
hai giá trị 5 này được đẩy vào stack.
Bây giờ hãy xem phiên bản String:
fn main() { let s1 = String::from("hello"); let s2 = s1; }
Điều này trông rất giống, vì vậy chúng ta có thể giả định rằng cách nó hoạt động
sẽ giống nhau: nghĩa là, dòng thứ hai sẽ tạo một bản sao của giá trị trong s1
và gán nó cho s2. Nhưng điều này không hoàn toàn là những gì xảy ra.
Hãy xem Hình 4-1 để xem điều gì đang xảy ra với String bên dưới bề mặt. Một
String bao gồm ba phần, được hiển thị ở bên trái: một con trỏ đến bộ nhớ chứa
nội dung của chuỗi, một độ dài, và một dung lượng. Nhóm dữ liệu này được lưu trữ
trên stack. Ở bên phải là bộ nhớ trên heap chứa nội dung.

Hình 4-1: Biểu diễn trong bộ nhớ của một String chứa giá
trị "hello" được gắn với s1
Độ dài là lượng bộ nhớ, tính bằng byte, mà nội dung của String đang sử dụng
hiện tại. Dung lượng là tổng lượng bộ nhớ, tính bằng byte, mà String đã nhận
từ bộ cấp phát. Sự khác biệt giữa độ dài và dung lượng là quan trọng, nhưng
không phải trong ngữ cảnh này, vì vậy hiện tại, việc bỏ qua dung lượng là ổn.
Khi chúng ta gán s1 cho s2, dữ liệu String được sao chép, nghĩa là chúng
ta sao chép con trỏ, độ dài và dung lượng nằm trên stack. Chúng ta không sao
chép dữ liệu trên heap mà con trỏ trỏ tới. Nói cách khác, biểu diễn dữ liệu
trong bộ nhớ trông giống như Hình 4-2.

Hình 4-2: Biểu diễn trong bộ nhớ của biến s2 có một bản
sao của con trỏ, độ dài và dung lượng của s1
Biểu diễn không trông giống như Hình 4-3, đây là cách bộ nhớ sẽ trông như thế
nào nếu Rust cũng sao chép dữ liệu heap. Nếu Rust làm điều này, thao tác
s2 = s1 có thể rất tốn kém về hiệu suất thời gian chạy nếu dữ liệu trên heap
lớn.

Hình 4-3: Một khả năng khác cho những gì s2 = s1 có thể
làm nếu Rust cũng sao chép dữ liệu heap
Trước đó, chúng ta đã nói rằng khi một biến ra khỏi phạm vi, Rust tự động gọi
hàm drop và dọn sạch bộ nhớ heap cho biến đó. Nhưng Hình 4-2 cho thấy cả hai
con trỏ dữ liệu đều trỏ đến cùng một vị trí. Đây là một vấn đề: khi s2 và s1
ra khỏi phạm vi, cả hai sẽ cố gắng giải phóng cùng một bộ nhớ. Điều này được gọi
là lỗi giải phóng bộ nhớ hai lần và là một trong những lỗi an toàn bộ nhớ mà
chúng ta đã đề cập trước đó. Giải phóng bộ nhớ hai lần có thể dẫn đến hư hỏng bộ
nhớ, điều này có thể dẫn đến lỗ hổng bảo mật.
Để đảm bảo an toàn bộ nhớ, sau dòng let s2 = s1;, Rust coi s1 như không còn
hợp lệ. Do đó, Rust không cần phải giải phóng bất cứ thứ gì khi s1 ra khỏi
phạm vi. Kiểm tra những gì xảy ra khi bạn cố gắng sử dụng s1 sau khi s2 được
tạo; nó sẽ không hoạt động:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Bạn sẽ nhận được lỗi như thế này vì Rust ngăn bạn sử dụng tham chiếu không hợp lệ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Nếu bạn đã nghe về các thuật ngữ sao chép nông (shallow copy) và sao chép sâu
(deep copy) trong khi làm việc với các ngôn ngữ khác, khái niệm sao chép con
trỏ, độ dài và dung lượng mà không sao chép dữ liệu có thể nghe giống như đang
thực hiện sao chép nông. Nhưng vì Rust cũng làm cho biến đầu tiên không hợp lệ,
nên thay vì được gọi là sao chép nông, nó được gọi là di chuyển (move). Trong
ví dụ này, chúng ta sẽ nói rằng s1 đã được di chuyển vào s2. Vì vậy, những
gì thực sự xảy ra được hiển thị trong Hình 4-4.

Hình 4-4: Biểu diễn trong bộ nhớ sau khi s1 đã bị vô
hiệu
Điều đó giải quyết vấn đề của chúng ta! Với chỉ s2 hợp lệ, khi nó ra khỏi phạm
vi, nó một mình sẽ giải phóng bộ nhớ, và chúng ta đã hoàn thành.
Ngoài ra, có một lựa chọn thiết kế được ngụ ý bởi điều này: Rust sẽ không bao giờ tự động tạo các bản sao "sâu" của dữ liệu của bạn. Do đó, bất kỳ tự động sao chép nào cũng có thể được giả định là có chi phí thấp về hiệu suất thời gian chạy.
Phạm Vi và Gán
Điều ngược lại cũng đúng cho mối quan hệ giữa phạm vi, quyền sở hữu và bộ nhớ
được giải phóng thông qua hàm drop. Khi bạn gán một giá trị hoàn toàn mới cho
một biến hiện có, Rust sẽ gọi drop và giải phóng bộ nhớ của giá trị ban đầu
ngay lập tức. Xem xét mã này, ví dụ:
fn main() { let mut s = String::from("hello"); s = String::from("ahoy"); println!("{s}, world!"); }
Ban đầu chúng ta khai báo một biến s và gắn nó với một String có giá trị
"hello". Sau đó chúng ta ngay lập tức tạo một String mới với giá trị
"ahoy" và gán nó cho s. Tại thời điểm này, không có gì tham chiếu đến giá
trị ban đầu trên heap một chút nào.

Hình 4-5: Biểu diễn trong bộ nhớ sau khi giá trị ban đầu đã bị thay thế hoàn toàn.
Vì vậy, chuỗi ban đầu ngay lập tức ra khỏi phạm vi. Rust sẽ chạy hàm drop trên
nó và bộ nhớ của nó sẽ được giải phóng ngay lập tức. Khi chúng ta in giá trị vào
cuối, nó sẽ là "ahoy, world!".
Các Biến và Dữ Liệu Tương Tác với Clone
Nếu chúng ta muốn sao chép sâu dữ liệu heap của String, không chỉ dữ liệu
stack, chúng ta có thể sử dụng một phương thức phổ biến gọi là clone. Chúng ta
sẽ thảo luận về cú pháp phương thức trong Chương 5, nhưng vì các phương thức là
một tính năng phổ biến trong nhiều ngôn ngữ lập trình, bạn có thể đã thấy chúng
trước đây.
Đây là một ví dụ về phương thức clone trong hành động:
fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {s1}, s2 = {s2}"); }
Điều này hoạt động tốt và rõ ràng tạo ra hành vi được hiển thị trong Hình 4-3, nơi dữ liệu heap thực sự được sao chép.
Khi bạn thấy một lệnh gọi đến clone, bạn biết rằng một số mã tùy ý đang được
thực thi và mã đó có thể tốn kém. Đó là một dấu hiệu trực quan rằng điều gì đó
khác biệt đang xảy ra.
Dữ Liệu Chỉ Trên Stack: Copy
Còn một chi tiết khác mà chúng ta chưa đề cập. Mã này sử dụng số nguyên—một phần đã được hiển thị trong Listing 4-2—hoạt động và hợp lệ:
fn main() { let x = 5; let y = x; println!("x = {x}, y = {y}"); }
Nhưng mã này dường như trái ngược với những gì chúng ta vừa học: chúng ta không
có lệnh gọi clone, nhưng x vẫn hợp lệ và không bị di chuyển vào y.
Lý do là các kiểu như số nguyên có kích thước đã biết tại thời điểm biên dịch
được lưu trữ hoàn toàn trên stack, nên các bản sao của giá trị thực tế được tạo
nhanh chóng. Điều đó có nghĩa là không có lý do tại sao chúng ta muốn ngăn x
không còn hợp lệ sau khi chúng ta tạo biến y. Nói cách khác, không có sự khác
biệt giữa sao chép sâu và nông ở đây, vì vậy việc gọi clone sẽ không làm gì
khác so với sao chép nông thông thường, và chúng ta có thể bỏ qua nó.
Rust có một chú thích đặc biệt gọi là trait Copy mà chúng ta có thể đặt trên
các kiểu được lưu trữ trên stack, như số nguyên (chúng ta sẽ nói nhiều hơn về
trait trong Chương 10). Nếu một kiểu triển khai trait
Copy, các biến sử dụng nó không bị di chuyển, mà là được sao chép một cách tầm
thường, khiến chúng vẫn hợp lệ sau khi gán cho một biến khác.
Rust sẽ không cho phép chúng ta chú thích một kiểu với Copy nếu kiểu đó, hoặc
bất kỳ phần nào của nó, đã triển khai trait Drop. Nếu kiểu cần điều gì đó đặc
biệt xảy ra khi giá trị ra khỏi phạm vi và chúng ta thêm chú thích Copy vào
kiểu đó, chúng ta sẽ nhận được lỗi biên dịch. Để tìm hiểu về cách thêm chú thích
Copy vào kiểu của bạn để triển khai trait, xem "Các Trait Có thể Dẫn
xuất" trong Phụ lục C.
Vậy, các kiểu nào triển khai trait Copy? Bạn có thể kiểm tra tài liệu cho kiểu
đã cho để chắc chắn, nhưng theo quy tắc chung, bất kỳ nhóm giá trị vô hướng đơn
giản nào cũng có thể triển khai Copy, và không có gì yêu cầu cấp phát hoặc là
một dạng tài nguyên có thể triển khai Copy. Đây là một số kiểu triển khai
Copy:
- Tất cả các kiểu số nguyên, chẳng hạn như
u32. - Kiểu Boolean,
bool, với giá trịtruevàfalse. - Tất cả các kiểu số thực, chẳng hạn như
f64. - Kiểu ký tự,
char. - Tuple, nếu chúng chỉ chứa các kiểu cũng triển khai
Copy. Ví dụ,(i32, i32)triển khaiCopy, nhưng(i32, String)thì không.
Quyền Sở Hữu và Hàm
Cơ chế của việc truyền một giá trị cho một hàm tương tự như khi gán một giá trị cho một biến. Truyền một biến cho một hàm sẽ di chuyển hoặc sao chép, giống như gán. Listing 4-3 có một ví dụ với một số chú thích cho thấy các biến đi vào và ra khỏi phạm vi ở đâu.
fn main() { let s = String::from("hello"); // s comes into scope takes_ownership(s); // s's value moves into the function... // ... and so is no longer valid here let x = 5; // x comes into scope makes_copy(x); // Because i32 implements the Copy trait, // x does NOT move into the function, // so it's okay to use x afterward. } // Here, x goes out of scope, then s. However, because s's value was moved, // nothing special happens. fn takes_ownership(some_string: String) { // some_string comes into scope println!("{some_string}"); } // Here, some_string goes out of scope and `drop` is called. The backing // memory is freed. fn makes_copy(some_integer: i32) { // some_integer comes into scope println!("{some_integer}"); } // Here, some_integer goes out of scope. Nothing special happens.
Nếu chúng ta cố gắng sử dụng s sau cuộc gọi đến takes_ownership, Rust sẽ đưa
ra một lỗi biên dịch. Những kiểm tra tĩnh này bảo vệ chúng ta khỏi các sai lầm.
Hãy thử thêm mã vào main sử dụng s và x để xem bạn có thể sử dụng chúng ở
đâu và nơi quy tắc sở hữu ngăn bạn làm như vậy.
Giá Trị Trả Về và Phạm Vi
Việc trả về giá trị cũng có thể chuyển quyền sở hữu. Listing 4-4 hiển thị một ví dụ về một hàm trả về một số giá trị, với các chú thích tương tự như trong Listing 4-3.
fn main() { let s1 = gives_ownership(); // gives_ownership moves its return // value into s1 let s2 = String::from("hello"); // s2 comes into scope let s3 = takes_and_gives_back(s2); // s2 is moved into // takes_and_gives_back, which also // moves its return value into s3 } // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing // happens. s1 goes out of scope and is dropped. fn gives_ownership() -> String { // gives_ownership will move its // return value into the function // that calls it let some_string = String::from("yours"); // some_string comes into scope some_string // some_string is returned and // moves out to the calling // function } // This function takes a String and returns a String. fn takes_and_gives_back(a_string: String) -> String { // a_string comes into // scope a_string // a_string is returned and moves out to the calling function }
Quyền sở hữu của một biến tuân theo cùng một mô hình mọi lúc: gán một giá trị
cho một biến khác sẽ di chuyển nó. Khi một biến bao gồm dữ liệu trên heap ra
khỏi phạm vi, giá trị sẽ được dọn dẹp bởi drop trừ khi quyền sở hữu của dữ
liệu đã được chuyển sang một biến khác.
Mặc dù điều này hoạt động, việc lấy quyền sở hữu và sau đó trả lại quyền sở hữu với mọi hàm hơi tẻ nhạt. Nếu chúng ta muốn cho một hàm sử dụng một giá trị nhưng không lấy quyền sở hữu? Khá là phiền toái khi bất cứ thứ gì chúng ta truyền vào cũng cần được truyền lại nếu chúng ta muốn sử dụng lại, cùng với bất kỳ dữ liệu nào có từ thân hàm mà chúng ta cũng có thể muốn trả về.
Rust cho phép chúng ta trả về nhiều giá trị bằng cách sử dụng một tuple, như được hiển thị trong Listing 4-5.
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{s2}' is {len}."); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // len() returns the length of a String (s, length) }
Nhưng đây là quá nhiều nghi thức và rất nhiều công việc cho một khái niệm nên phổ biến. May mắn thay, Rust có một tính năng để sử dụng một giá trị mà không chuyển quyền sở hữu, được gọi là tham chiếu (references).
Tham Chiếu và Mượn
Vấn đề với đoạn mã tuple trong Listing 4-5 là chúng ta phải trả lại String cho
hàm gọi để chúng ta vẫn có thể sử dụng String sau cuộc gọi đến
calculate_length, bởi vì String đã được chuyển vào calculate_length. Thay
vào đó, chúng ta có thể cung cấp một tham chiếu đến giá trị String. Tham
chiếu (reference) giống như một con trỏ ở chỗ nó là một địa chỉ mà chúng ta có
thể theo dõi để truy cập dữ liệu được lưu trữ tại địa chỉ đó; dữ liệu đó thuộc
sở hữu của một biến khác. Không giống như con trỏ, một tham chiếu được đảm bảo
trỏ đến một giá trị hợp lệ của một kiểu dữ liệu cụ thể trong suốt thời gian tồn
tại của tham chiếu đó.
Đây là cách bạn sẽ định nghĩa và sử dụng một hàm calculate_length có một tham
chiếu đến một đối tượng làm tham số thay vì lấy quyền sở hữu của giá trị:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { s.len() }
Đầu tiên, lưu ý rằng tất cả các mã tuple trong khai báo biến và giá trị trả về
của hàm đã biến mất. Thứ hai, lưu ý rằng chúng ta truyền &s1 vào
calculate_length và trong định nghĩa của nó, chúng ta lấy &String thay vì
String. Các dấu và (&) này đại diện cho tham chiếu, và chúng cho phép bạn
tham chiếu đến một số giá trị mà không lấy quyền sở hữu của nó. Hình 4-6 minh
họa khái niệm này.

Hình 4-6: Một sơ đồ của &String s trỏ đến
String s1
Lưu ý: Ngược lại với việc tham chiếu bằng cách sử dụng
&là giải tham chiếu (dereferencing), được thực hiện với toán tử giải tham chiếu,*. Chúng ta sẽ thấy một số cách sử dụng toán tử giải tham chiếu trong Chương 8 và thảo luận chi tiết về giải tham chiếu trong Chương 15.
Hãy xem xét kỹ hơn cuộc gọi hàm ở đây:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { s.len() }
Cú pháp &s1 cho phép chúng ta tạo một tham chiếu trỏ đến giá trị của s1
nhưng không sở hữu nó. Vì tham chiếu không sở hữu nó, giá trị mà nó trỏ đến sẽ
không bị hủy khi tham chiếu không còn được sử dụng nữa.
Tương tự, chữ ký của hàm sử dụng & để chỉ ra rằng kiểu của tham số s là một
tham chiếu. Hãy thêm một số chú thích giải thích:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { // s is a reference to a String s.len() } // Here, s goes out of scope. But because s does not have ownership of what // it refers to, the String is not dropped.
Phạm vi mà biến s có giá trị giống như phạm vi của bất kỳ tham số hàm nào,
nhưng giá trị được trỏ đến bởi tham chiếu không bị hủy khi s không còn được sử
dụng nữa, vì s không có quyền sở hữu. Khi các hàm có tham chiếu làm tham số
thay vì các giá trị thực tế, chúng ta sẽ không cần trả lại các giá trị để trả
lại quyền sở hữu, vì chúng ta chưa bao giờ có quyền sở hữu.
Chúng ta gọi hành động tạo một tham chiếu là mượn (borrowing). Như trong cuộc sống thực, nếu một người sở hữu một thứ gì đó, bạn có thể mượn nó từ họ. Khi bạn xong việc, bạn phải trả lại nó. Bạn không sở hữu nó.
Vậy, điều gì sẽ xảy ra nếu chúng ta cố gắng sửa đổi thứ gì đó mà chúng ta đang mượn? Hãy thử mã trong Listing 4-6. Cảnh báo trước: nó không hoạt động!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}Đây là lỗi:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Giống như các biến là không thay đổi theo mặc định, các tham chiếu cũng vậy. Chúng ta không được phép sửa đổi một thứ mà chúng ta có tham chiếu đến.
Tham Chiếu Có Thể Thay Đổi
Chúng ta có thể sửa mã từ Listing 4-6 để cho phép chúng ta sửa đổi một giá trị đã mượn chỉ với một vài điều chỉnh nhỏ sử dụng, thay vào đó, một tham chiếu có thể thay đổi (mutable reference):
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
Đầu tiên, chúng ta thay đổi s thành mut. Sau đó, chúng ta tạo một tham chiếu
có thể thay đổi với &mut s khi chúng ta gọi hàm change, và cập nhật chữ ký
hàm để chấp nhận một tham chiếu có thể thay đổi với some_string: &mut String.
Điều này làm cho nó rất rõ ràng rằng hàm change sẽ thay đổi giá trị mà nó
mượn.
Tham chiếu có thể thay đổi có một hạn chế lớn: nếu bạn có một tham chiếu có thể
thay đổi đến một giá trị, bạn không thể có tham chiếu nào khác đến giá trị đó.
Mã này cố gắng tạo hai tham chiếu có thể thay đổi đến s sẽ thất bại:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Đây là lỗi:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Lỗi này nói rằng mã này không hợp lệ vì chúng ta không thể mượn s như một biến
có thể thay đổi nhiều hơn một lần tại một thời điểm. Lần mượn có thể thay đổi
đầu tiên là trong r1 và phải kéo dài cho đến khi nó được sử dụng trong
println!, nhưng giữa việc tạo tham chiếu có thể thay đổi đó và việc sử dụng
nó, chúng ta đã cố gắng tạo một tham chiếu có thể thay đổi khác trong r2 mà
mượn cùng dữ liệu như r1.
Hạn chế ngăn nhiều tham chiếu có thể thay đổi đến cùng một dữ liệu tại cùng một thời điểm cho phép thay đổi nhưng theo một cách rất có kiểm soát. Đây là điều mà các lập trình viên Rust mới gặp khó khăn vì hầu hết các ngôn ngữ cho phép bạn thay đổi bất cứ khi nào bạn muốn. Lợi ích của việc có hạn chế này là Rust có thể ngăn chặn đua dữ liệu tại thời điểm biên dịch. Đua dữ liệu (data race) tương tự như một điều kiện đua và xảy ra khi có ba hành vi sau:
- Hai hoặc nhiều con trỏ truy cập cùng một dữ liệu tại cùng một thời điểm.
- Ít nhất một trong các con trỏ đang được sử dụng để ghi vào dữ liệu.
- Không có cơ chế nào đang được sử dụng để đồng bộ hóa việc truy cập vào dữ liệu.
Đua dữ liệu gây ra hành vi không xác định và có thể khó chẩn đoán và sửa chữa khi bạn đang cố gắng theo dõi chúng trong thời gian chạy; Rust ngăn chặn vấn đề này bằng cách từ chối biên dịch mã có đua dữ liệu!
Như mọi khi, chúng ta có thể sử dụng dấu ngoặc nhọn để tạo một phạm vi mới, cho phép nhiều tham chiếu có thể thay đổi, miễn là chúng không đồng thời xuất hiện:
fn main() { let mut s = String::from("hello"); { let r1 = &mut s; } // r1 goes out of scope here, so we can make a new reference with no problems. let r2 = &mut s; }
Rust áp dụng một quy tắc tương tự cho việc kết hợp tham chiếu có thể thay đổi và không thể thay đổi. Mã này dẫn đến lỗi:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{r1}, {r2}, and {r3}");
}Đây là lỗi:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ôi! Chúng ta cũng không thể có một tham chiếu có thể thay đổi trong khi chúng ta có một tham chiếu không thể thay đổi đến cùng một giá trị.
Người dùng của một tham chiếu không thể thay đổi không mong đợi giá trị đột nhiên thay đổi dưới chân họ! Tuy nhiên, nhiều tham chiếu không thể thay đổi được cho phép vì không ai chỉ đọc dữ liệu có khả năng ảnh hưởng đến việc đọc dữ liệu của người khác.
Lưu ý rằng phạm vi của một tham chiếu bắt đầu từ nơi nó được giới thiệu và tiếp
tục thông qua lần cuối cùng tham chiếu đó được sử dụng. Ví dụ, mã này sẽ biên
dịch vì lần sử dụng cuối cùng của các tham chiếu không thể thay đổi là trong
println!, trước khi tham chiếu có thể thay đổi được giới thiệu:
fn main() { let mut s = String::from("hello"); let r1 = &s; // no problem let r2 = &s; // no problem println!("{r1} and {r2}"); // Variables r1 and r2 will not be used after this point. let r3 = &mut s; // no problem println!("{r3}"); }
Phạm vi của các tham chiếu không thể thay đổi r1 và r2 kết thúc sau
println! nơi chúng được sử dụng lần cuối, đó là trước khi tham chiếu có thể
thay đổi r3 được tạo. Các phạm vi này không chồng lấn, vì vậy mã này được cho
phép: trình biên dịch có thể biết rằng tham chiếu không còn được sử dụng tại một
điểm trước khi kết thúc phạm vi.
Mặc dù các lỗi mượn có thể gây bực bội đôi khi, hãy nhớ rằng đó là trình biên dịch Rust chỉ ra một lỗi tiềm ẩn sớm (tại thời điểm biên dịch thay vì tại thời điểm chạy) và chỉ cho bạn chính xác nơi vấn đề nằm ở. Sau đó, bạn không phải theo dõi lý do tại sao dữ liệu của bạn không phải là những gì bạn nghĩ nó là.
Tham Chiếu Treo
Trong các ngôn ngữ có con trỏ, rất dễ vô tình tạo ra một con trỏ treo (dangling pointer)—một con trỏ tham chiếu đến một vị trí trong bộ nhớ có thể đã được cấp cho ai đó khác—bằng cách giải phóng một số bộ nhớ trong khi vẫn giữ một con trỏ đến bộ nhớ đó. Ngược lại, trong Rust, trình biên dịch đảm bảo rằng các tham chiếu sẽ không bao giờ là tham chiếu treo: nếu bạn có một tham chiếu đến một số dữ liệu, trình biên dịch sẽ đảm bảo rằng dữ liệu sẽ không ra khỏi phạm vi trước tham chiếu đến dữ liệu đó.
Hãy thử tạo một tham chiếu treo để xem cách Rust ngăn chúng với một lỗi thời điểm biên dịch:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}Đây là lỗi:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Thông báo lỗi này đề cập đến một tính năng mà chúng ta chưa đề cập: thời gian tồn tại (lifetimes). Chúng ta sẽ thảo luận về thời gian tồn tại chi tiết trong Chương 10. Nhưng, nếu bạn bỏ qua các phần về thời gian tồn tại, thông báo có chứa chìa khóa cho lý do tại sao mã này là một vấn đề:
kiểu trả về của hàm này chứa một giá trị đã mượn, nhưng không có giá trị
nào để mượn từ đó
Hãy xem xét kỹ hơn chính xác những gì đang xảy ra ở mỗi giai đoạn của mã
dangle của chúng ta:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope and is dropped, so its memory goes away.
// Danger!Vì s được tạo bên trong dangle, khi mã của dangle hoàn thành, s sẽ bị
giải phóng. Nhưng chúng ta đã cố gắng trả về một tham chiếu đến nó. Điều đó có
nghĩa là tham chiếu này sẽ trỏ đến một String không hợp lệ. Điều đó không tốt!
Rust sẽ không cho phép chúng ta làm điều này.
Giải pháp ở đây là trả về String trực tiếp:
fn main() { let string = no_dangle(); } fn no_dangle() -> String { let s = String::from("hello"); s }
Điều này hoạt động mà không có vấn đề gì. Quyền sở hữu được chuyển ra ngoài và không có gì bị giải phóng.
Các Quy Tắc của Tham Chiếu
Hãy tổng kết những gì chúng ta đã thảo luận về tham chiếu:
- Tại bất kỳ thời điểm nào, bạn có thể có hoặc là một tham chiếu có thể thay đổi hoặc là bất kỳ số lượng tham chiếu không thể thay đổi nào.
- Tham chiếu phải luôn hợp lệ.
Tiếp theo, chúng ta sẽ xem xét một loại tham chiếu khác: slice.
Kiểu Slice
Slices cho phép bạn tham chiếu đến một chuỗi liên tiếp các phần tử trong một bộ sưu tập. Slice là một loại tham chiếu, nên nó không có quyền sở hữu.
Đây là một bài toán nhỏ: viết một hàm nhận vào một chuỗi các từ được phân tách bởi khoảng trắng và trả về từ đầu tiên mà nó tìm thấy trong chuỗi đó. Nếu hàm không tìm thấy khoảng trắng trong chuỗi, toàn bộ chuỗi phải là một từ, do đó toàn bộ chuỗi sẽ được trả về.
Lưu ý: Để giới thiệu về string slice, chúng ta giả định chỉ xử lý ASCII trong phần này; một thảo luận chi tiết hơn về xử lý UTF-8 nằm trong phần "Lưu trữ văn bản được mã hóa UTF-8 với Strings" ở Chương 8.
Hãy cùng xem xét cách viết chữ ký của hàm này mà không sử dụng slices, để hiểu vấn đề mà slices sẽ giải quyết:
fn first_word(s: &String) -> ?Hàm first_word có một tham số kiểu &String. Chúng ta không cần quyền sở hữu,
nên điều này là hợp lý. (Theo cách viết thông thường của Rust, hàm không lấy
quyền sở hữu của các đối số của chúng trừ khi cần thiết, và lý do sẽ trở nên rõ
ràng hơn khi chúng ta tiếp tục.) Nhưng chúng ta nên trả về gì? Chúng ta không
thực sự có cách để nói về một phần của một chuỗi. Tuy nhiên, chúng ta có thể
trả về chỉ số của vị trí kết thúc từ, được chỉ định bằng một khoảng trắng. Hãy
thử điều đó, như trong Listing 4-7.
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() {}
Vì chúng ta cần đi qua từng phần tử của String và kiểm tra xem một giá trị có
phải là khoảng trắng không, chúng ta sẽ chuyển đổi String thành một mảng byte
bằng phương thức as_bytes.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Tiếp theo, chúng ta tạo một iterator qua mảng byte bằng phương thức iter:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Chúng ta sẽ thảo luận về iterators chi tiết hơn trong Chương
13. Hiện tại, hãy biết rằng iter là một phương thức trả
về mỗi phần tử trong một bộ sưu tập và enumerate bao bọc kết quả của iter và
trả về mỗi phần tử dưới dạng một tuple. Phần tử đầu tiên của tuple trả về từ
enumerate là chỉ số, và phần tử thứ hai là tham chiếu đến phần tử. Điều này
thuận tiện hơn một chút so với việc tự tính toán chỉ số.
Vì phương thức enumerate trả về một tuple, chúng ta có thể sử dụng các mẫu để
phân rã tuple đó. Chúng ta sẽ thảo luận về các mẫu chi tiết hơn trong Chương
6. Trong vòng lặp for, chúng ta chỉ định một mẫu có i
cho chỉ số trong tuple và &item cho byte đơn lẻ trong tuple. Bởi vì chúng ta
có được tham chiếu đến phần tử từ .iter().enumerate(), chúng ta sử dụng &
trong mẫu.
Bên trong vòng lặp for, chúng ta tìm kiếm byte đại diện cho khoảng trắng bằng
cách sử dụng cú pháp byte literal. Nếu chúng ta tìm thấy một khoảng trắng, chúng
ta trả về vị trí. Nếu không, chúng ta trả về độ dài của chuỗi bằng cách sử dụng
s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Bây giờ chúng ta đã có cách để tìm ra chỉ số của vị trí kết thúc từ đầu tiên
trong chuỗi, nhưng có một vấn đề. Chúng ta đang trả về một usize riêng lẻ,
nhưng đó chỉ là một số có ý nghĩa trong ngữ cảnh của &String. Nói cách khác,
vì nó là một giá trị tách biệt khỏi String, không có gì đảm bảo rằng nó sẽ vẫn
hợp lệ trong tương lai. Xem xét chương trình trong Listing 4-8 sử dụng hàm
first_word từ Listing 4-7.
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let word = first_word(&s); // word will get the value 5 s.clear(); // this empties the String, making it equal to "" // word still has the value 5 here, but s no longer has any content that we // could meaningfully use with the value 5, so word is now totally invalid! }
Chương trình này biên dịch mà không có lỗi nào và cũng sẽ như vậy nếu chúng ta
sử dụng word sau khi gọi s.clear(). Bởi vì word không liên kết với trạng
thái của s chút nào, word vẫn chứa giá trị 5. Chúng ta có thể sử dụng giá
trị 5 đó với biến s để cố gắng trích xuất từ đầu tiên, nhưng điều này sẽ là
một lỗi vì nội dung của s đã thay đổi kể từ khi chúng ta lưu 5 vào word.
Việc phải lo lắng về chỉ số trong word không đồng bộ với dữ liệu trong s là
tẻ nhạt và dễ gây lỗi! Việc quản lý các chỉ số này thậm chí còn mong manh hơn
nếu chúng ta viết một hàm second_word. Chữ ký của nó sẽ phải trông như thế
này:
fn second_word(s: &String) -> (usize, usize) {Bây giờ chúng ta đang theo dõi một chỉ số bắt đầu và một chỉ số kết thúc, và chúng ta có nhiều giá trị hơn được tính toán từ dữ liệu trong một trạng thái cụ thể nhưng không gắn liền với trạng thái đó chút nào. Chúng ta có ba biến không liên quan đến nhau nổi xung quanh cần phải được giữ đồng bộ.
May mắn thay, Rust có một giải pháp cho vấn đề này: string slices.
String Slices
Một string slice là một tham chiếu đến một chuỗi liên tiếp các phần tử của một
String, và nó trông như thế này:
fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
Thay vì một tham chiếu đến toàn bộ String, hello là một tham chiếu đến một
phần của String, được chỉ định trong phần [0..5]. Chúng ta tạo slices bằng
cách sử dụng một phạm vi trong ngoặc vuông bằng cách chỉ định
[starting_index..ending_index], trong đó starting_index là vị trí đầu tiên
trong slice và ending_index là vị trí sau vị trí cuối cùng trong slice. Về
mặt nội bộ, cấu trúc dữ liệu slice lưu trữ vị trí bắt đầu và độ dài của slice,
mà tương ứng với ending_index trừ đi starting_index. Vì vậy, trong
trường hợp let world = &s[6..11];, world sẽ là một slice chứa một con trỏ
đến byte tại chỉ số 6 của s với giá trị độ dài là 5.
Hình 4-7 minh họa điều này trong một sơ đồ.

Hình 4-7: String slice tham chiếu đến một phần của một
String
Với cú pháp phạm vi .. của Rust, nếu bạn muốn bắt đầu từ chỉ số 0, bạn có thể
bỏ giá trị trước hai dấu chấm. Nói cách khác, hai cách viết sau là tương đương:
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[..2]; }
Tương tự, nếu slice của bạn bao gồm byte cuối cùng của String, bạn có thể bỏ
số cuối. Điều đó có nghĩa là các cách viết sau là tương đương:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[3..len]; let slice = &s[3..]; }
Bạn cũng có thể bỏ cả hai giá trị để lấy một slice của toàn bộ chuỗi. Vì vậy, hai cách viết sau là tương đương:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
Lưu ý: Các chỉ số phạm vi của string slice phải nằm tại các ranh giới ký tự UTF-8 hợp lệ. Nếu bạn cố gắng tạo một string slice ở giữa một ký tự đa byte, chương trình của bạn sẽ kết thúc với một lỗi.
Với tất cả thông tin này, hãy viết lại first_word để trả về một slice. Kiểu
dùng để biểu thị "string slice" được viết là &str:
fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
Chúng ta lấy chỉ số cho vị trí kết thúc của từ theo cách tương tự như trong Listing 4-7, bằng cách tìm kiếm lần xuất hiện đầu tiên của một khoảng trắng. Khi chúng ta tìm thấy một khoảng trắng, chúng ta trả về một string slice sử dụng phần đầu của chuỗi và chỉ số của khoảng trắng làm chỉ số bắt đầu và kết thúc.
Bây giờ khi chúng ta gọi first_word, chúng ta nhận được một giá trị duy nhất
gắn liền với dữ liệu cơ bản. Giá trị bao gồm một tham chiếu đến điểm bắt đầu của
slice và số phần tử trong slice.
Việc trả về một slice cũng sẽ hoạt động cho một hàm second_word:
fn second_word(s: &String) -> &str {Bây giờ chúng ta có một API đơn giản hơn nhiều mà khó bị sai sót hơn bởi vì
trình biên dịch sẽ đảm bảo các tham chiếu vào String vẫn hợp lệ. Hãy nhớ lại
lỗi trong chương trình ở Listing 4-8, khi chúng ta nhận được chỉ số đến vị trí
kết thúc từ đầu tiên nhưng sau đó xóa chuỗi khiến cho chỉ số của chúng ta không
còn hợp lệ? Đoạn mã đó về mặt logic là không đúng nhưng không hiển thị lỗi ngay
lập tức. Các vấn đề sẽ xuất hiện sau nếu chúng ta tiếp tục cố gắng sử dụng chỉ
số từ đầu tiên với một chuỗi đã bị làm rỗng. Slices làm cho lỗi này là không thể
và cho chúng ta biết rằng chúng ta có vấn đề với mã của mình sớm hơn nhiều. Sử
dụng phiên bản slice của first_word sẽ báo lỗi khi biên dịch:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}Đây là lỗi biên dịch:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Hãy nhớ lại từ quy tắc mượn rằng nếu chúng ta có một tham chiếu bất biến đến một
thứ gì đó, chúng ta không thể đồng thời lấy một tham chiếu có thể thay đổi. Bởi
vì clear cần cắt ngắn String, nó cần lấy một tham chiếu có thể thay đổi.
println! sau lời gọi đến clear sử dụng tham chiếu trong word, do đó tham
chiếu bất biến phải vẫn còn hoạt động tại thời điểm đó. Rust không cho phép tham
chiếu có thể thay đổi trong clear và tham chiếu bất biến trong word tồn tại
cùng một lúc, và việc biên dịch thất bại. Rust không chỉ làm cho API của chúng
ta dễ sử dụng hơn, mà còn loại bỏ toàn bộ một lớp lỗi tại thời điểm biên dịch!
String Literals dưới dạng Slices
Nhớ lại rằng chúng ta đã nói về việc string literals được lưu trữ bên trong mã nhị phân. Bây giờ khi chúng ta đã biết về slices, chúng ta có thể hiểu đúng về string literals:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
Kiểu của s ở đây là &str: đó là một slice trỏ đến một điểm cụ thể của mã nhị
phân. Đây cũng là lý do tại sao string literals là bất biến; &str là một tham
chiếu bất biến.
String Slices dưới dạng Tham số
Khi biết rằng bạn có thể lấy slices của literals và giá trị String dẫn chúng
ta đến một cải tiến nữa cho first_word, và đó là chữ ký của nó:
fn first_word(s: &String) -> &str {Một Rustacean có kinh nghiệm hơn sẽ viết chữ ký như trong Listing 4-9 thay vì
như trên vì nó cho phép chúng ta sử dụng cùng một hàm cho cả giá trị &String
và giá trị &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Nếu chúng ta có một string slice, chúng ta có thể truyền nó trực tiếp. Nếu chúng
ta có một String, chúng ta có thể truyền một slice của String hoặc một tham
chiếu đến String. Tính linh hoạt này tận dụng deref coercions, một tính năng
mà chúng ta sẽ đề cập trong phần "Implicit Deref Coercions with Functions and
Methods" của Chương 15.
Việc định nghĩa một hàm nhận một string slice thay vì một tham chiếu đến một
String làm cho API của chúng ta trở nên tổng quát và hữu ích hơn mà không mất
bất kỳ chức năng nào:
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // `first_word` works on slices of `String`s, whether partial or whole. let word = first_word(&my_string[0..6]); let word = first_word(&my_string[..]); // `first_word` also works on references to `String`s, which are equivalent // to whole slices of `String`s. let word = first_word(&my_string); let my_string_literal = "hello world"; // `first_word` works on slices of string literals, whether partial or // whole. let word = first_word(&my_string_literal[0..6]); let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Các Slices Khác
String slices, như bạn có thể tưởng tượng, là đặc biệt dành cho chuỗi. Nhưng có một kiểu slice chung hơn. Xét mảng này:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
Cũng như chúng ta có thể muốn tham chiếu đến một phần của một chuỗi, chúng ta có thể muốn tham chiếu đến một phần của một mảng. Chúng ta sẽ thực hiện như sau:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
Slice này có kiểu &[i32]. Nó hoạt động giống như string slices, bằng cách lưu
trữ một tham chiếu đến phần tử đầu tiên và một độ dài. Bạn sẽ sử dụng kiểu slice
này cho tất cả các loại bộ sưu tập khác. Chúng ta sẽ thảo luận về các bộ sưu tập
này chi tiết khi chúng ta nói về vectors trong Chương 8.
Tóm tắt
Các khái niệm về quyền sở hữu, mượn và slices đảm bảo an toàn bộ nhớ trong các chương trình Rust tại thời điểm biên dịch. Ngôn ngữ Rust cho bạn quyền kiểm soát đối với việc sử dụng bộ nhớ của bạn theo cách giống như các ngôn ngữ lập trình hệ thống khác, nhưng việc có chủ sở hữu của dữ liệu tự động dọn dẹp dữ liệu đó khi chủ sở hữu ra khỏi phạm vi có nghĩa là bạn không cần phải viết và gỡ lỗi mã bổ sung để có được sự kiểm soát này.
Quyền sở hữu ảnh hưởng đến cách thức hoạt động của nhiều phần khác của Rust, vì
vậy chúng ta sẽ nói về các khái niệm này thêm trong suốt phần còn lại của cuốn
sách. Hãy chuyển sang Chương 5 và xem xét việc nhóm các phần dữ liệu lại với
nhau trong một struct.
Sử dụng Structs để Cấu trúc Dữ liệu Liên quan
Một struct, hay structure, là một kiểu dữ liệu tùy chỉnh cho phép bạn đóng gói và đặt tên cho nhiều giá trị liên quan tạo thành một nhóm có ý nghĩa. Nếu bạn đã quen với ngôn ngữ hướng đối tượng, struct giống như các thuộc tính dữ liệu của một đối tượng. Trong chương này, chúng ta sẽ so sánh và đối chiếu tuple với struct để xây dựng trên những gì bạn đã biết và chứng minh khi nào struct là cách tốt hơn để nhóm dữ liệu.
Chúng ta sẽ trình bày cách định nghĩa và khởi tạo struct. Chúng ta sẽ thảo luận về cách định nghĩa các hàm liên kết, đặc biệt là loại hàm liên kết được gọi là methods, để chỉ định hành vi liên quan đến một kiểu struct. Struct và enums (được thảo luận trong Chương 6) là các khối xây dựng để tạo ra các kiểu mới trong miền chương trình của bạn để tận dụng tối đa khả năng kiểm tra kiểu tại thời điểm biên dịch của Rust.
Định nghĩa và Khởi tạo Struct
Struct tương tự như tuple, đã được thảo luận trong phần "Kiểu Tuple", ở chỗ cả hai đều chứa nhiều giá trị liên quan. Giống như tuple, các thành phần của một struct có thể có kiểu khác nhau. Khác với tuple, trong một struct, bạn sẽ đặt tên cho từng phần dữ liệu để làm rõ ý nghĩa của các giá trị. Việc thêm các tên này có nghĩa là struct linh hoạt hơn tuple: bạn không phải dựa vào thứ tự của dữ liệu để xác định hoặc truy cập các giá trị của một thực thể.
Để định nghĩa một struct, chúng ta nhập từ khóa struct và đặt tên cho toàn bộ
struct. Tên của struct nên mô tả ý nghĩa của các phần dữ liệu được nhóm lại với
nhau. Sau đó, bên trong dấu ngoặc nhọn, chúng ta định nghĩa tên và kiểu của các
phần dữ liệu, mà chúng ta gọi là trường (fields). Ví dụ, Listing 5-1 hiển thị
một struct lưu trữ thông tin về tài khoản người dùng.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() {}
Để sử dụng struct sau khi đã định nghĩa nó, chúng ta tạo ra một instance (thực
thể) của struct đó bằng cách xác định giá trị cụ thể cho mỗi trường. Chúng ta
tạo một thực thể bằng cách nêu tên của struct và sau đó thêm dấu ngoặc nhọn chứa
các cặp key: value, trong đó key là tên của các trường và value là dữ liệu
mà chúng ta muốn lưu trữ trong các trường đó. Chúng ta không cần phải chỉ định
các trường theo cùng thứ tự mà chúng ta đã khai báo trong struct. Nói cách khác,
định nghĩa struct giống như một khuôn mẫu chung cho kiểu dữ liệu, và các thực
thể điền vào khuôn mẫu đó với dữ liệu cụ thể để tạo ra các giá trị của kiểu đó.
Ví dụ, chúng ta có thể khai báo một người dùng cụ thể như trong Listing 5-2.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; }
Để lấy một giá trị cụ thể từ struct, chúng ta sử dụng ký hiệu dấu chấm. Ví dụ,
để truy cập địa chỉ email của người dùng này, chúng ta sử dụng user1.email.
Nếu thực thể là có thể thay đổi, chúng ta có thể thay đổi giá trị bằng cách sử
dụng ký hiệu dấu chấm và gán vào một trường cụ thể. Listing 5-3 cho thấy cách
thay đổi giá trị trong trường email của một thực thể User có thể thay đổi.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let mut user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; user1.email = String::from("anotheremail@example.com"); }
Lưu ý rằng toàn bộ thực thể phải là có thể thay đổi; Rust không cho phép chúng ta đánh dấu chỉ một số trường nhất định là có thể thay đổi. Giống như với bất kỳ biểu thức nào, chúng ta có thể tạo một thực thể mới của struct làm biểu thức cuối cùng trong thân hàm để ngầm định trả về thực thể mới đó.
Listing 5-4 hiển thị một hàm build_user trả về một thực thể User với email
và tên người dùng đã cho. Trường active nhận giá trị là true, và
sign_in_count nhận giá trị là 1.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username: username, email: email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
Việc đặt tên các tham số của hàm giống với tên trường của struct là hợp lý,
nhưng việc phải lặp lại tên trường email và username cùng với biến là hơi tẻ
nhạt. Nếu struct có nhiều trường hơn, việc lặp lại mỗi tên sẽ càng phiền phức
hơn. May mắn thay, có một cách viết tắt thuận tiện!
Sử dụng Field Init Shorthand
Vì tên tham số và tên trường struct là hoàn toàn giống nhau trong Listing 5-4,
chúng ta có thể sử dụng cú pháp field init shorthand để viết lại build_user
để nó hoạt động chính xác như cũ nhưng không có sự lặp lại của username và
email, như trong Listing 5-5.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username, email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
Ở đây, chúng ta đang tạo một thực thể mới của struct User, nó có một trường
tên là email. Chúng ta muốn đặt giá trị của trường email thành giá trị trong
tham số email của hàm build_user. Vì trường email và tham số email có
cùng tên, chúng ta chỉ cần viết email thay vì email: email.
Tạo Thực thể từ Các Thực thể Khác với Cú pháp Cập nhật Struct
Thường rất hữu ích khi tạo một thực thể mới của một struct bao gồm hầu hết các giá trị từ một thực thể khác của cùng kiểu, nhưng thay đổi một số. Bạn có thể làm điều này bằng cách sử dụng cú pháp cập nhật struct (struct update syntax).
Đầu tiên, trong Listing 5-6, chúng ta thấy cách tạo một thực thể User mới
trong user2 theo cách thông thường, không sử dụng cú pháp cập nhật. Chúng ta
đặt một giá trị mới cho email nhưng sử dụng các giá trị giống nhau từ user1
mà chúng ta đã tạo ra trong Listing 5-2.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; }
Sử dụng cú pháp cập nhật struct, chúng ta có thể đạt được cùng kết quả với ít mã
hơn, như trong Listing 5-7. Cú pháp .. chỉ định rằng các trường còn lại không
được đặt rõ ràng sẽ có cùng giá trị với các trường trong thực thể đã cho.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { email: String::from("another@example.com"), ..user1 }; }
Mã trong Listing 5-7 cũng tạo ra một thực thể trong user2 có giá trị khác cho
email nhưng có cùng giá trị cho các trường username, active, và
sign_in_count từ user1. ..user1 phải đặt cuối cùng để chỉ định rằng bất kỳ
trường còn lại nào nên lấy giá trị của chúng từ các trường tương ứng trong
user1, nhưng chúng ta có thể chọn chỉ định giá trị cho nhiều trường tùy ý theo
bất kỳ thứ tự nào, bất kể thứ tự của các trường trong định nghĩa struct.
Lưu ý rằng cú pháp cập nhật struct sử dụng = như một phép gán; điều này là vì
nó di chuyển dữ liệu, giống như chúng ta đã thấy trong phần "Variables and Data
Interacting with Move". Trong ví dụ này, chúng ta không
còn có thể sử dụng user1 sau khi tạo user2 vì String trong trường
username của user1 đã được di chuyển vào user2. Nếu chúng ta đã cung cấp
cho user2 giá trị String mới cho cả email và username, và do đó chỉ sử
dụng các giá trị active và sign_in_count từ user1, thì user1 vẫn sẽ hợp
lệ sau khi tạo ra user2. Cả active và sign_in_count đều là các kiểu thực
hiện trait Copy, do đó hành vi mà chúng ta đã thảo luận trong phần
"Stack-Only Data: Copy" sẽ được áp dụng. Chúng ta cũng
vẫn có thể sử dụng user1.email trong ví dụ này, vì giá trị của nó không bị di
chuyển ra khỏi user1.
Sử dụng Tuple Struct Không Có Trường Được Đặt Tên để Tạo Các Kiểu Khác Nhau
Rust cũng hỗ trợ struct trông giống như tuple, được gọi là tuple struct. Tuple struct có thêm ý nghĩa mà tên struct cung cấp nhưng không có tên được liên kết với các trường của chúng; thay vào đó, chúng chỉ có các kiểu của các trường. Tuple struct hữu ích khi bạn muốn đặt tên cho toàn bộ tuple và làm cho tuple đó thành một kiểu khác với các tuple khác, và khi đặt tên cho mỗi trường như trong một struct thông thường sẽ dài dòng hoặc thừa thãi.
Để định nghĩa một tuple struct, bắt đầu với từ khóa struct và tên struct theo
sau là các kiểu trong tuple. Ví dụ, ở đây chúng ta định nghĩa và sử dụng hai
tuple struct có tên là Color và Point:
struct Color(i32, i32, i32); struct Point(i32, i32, i32); fn main() { let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
Lưu ý rằng giá trị black và origin là các kiểu khác nhau vì chúng là các
thực thể của các tuple struct khác nhau. Mỗi struct bạn định nghĩa là kiểu riêng
của nó, ngay cả khi các trường trong struct có thể có cùng kiểu. Ví dụ, một hàm
nhận một tham số kiểu Color không thể nhận một Point làm đối số, mặc dù cả
hai kiểu đều được tạo thành từ ba giá trị i32. Nếu không, các thực thể tuple
struct tương tự như tuple ở chỗ bạn có thể phân rã chúng thành các phần riêng
lẻ, và bạn có thể sử dụng . theo sau bởi chỉ số để truy cập một giá trị riêng
lẻ. Khác với tuple, tuple struct yêu cầu bạn đặt tên kiểu của struct khi bạn
phân rã chúng. Ví dụ, chúng ta sẽ viết let Point(x, y, z) = origin; để phân rã
các giá trị trong điểm origin thành các biến có tên là x, y, và z.
Unit-Like Struct Không Có Trường Nào
Bạn cũng có thể định nghĩa struct không có trường nào! Những thứ này được gọi là
unit-like struct vì chúng hoạt động tương tự như (), kiểu đơn vị mà chúng ta
đã đề cập trong phần "The Tuple Type". Unit-like struct
có thể hữu ích khi bạn cần thực hiện một trait trên một kiểu nhưng không có bất
kỳ dữ liệu nào mà bạn muốn lưu trữ trong chính kiểu đó. Chúng ta sẽ thảo luận về
trait trong Chương 10. Đây là một ví dụ về việc khai báo và khởi tạo một unit
struct có tên là AlwaysEqual:
struct AlwaysEqual; fn main() { let subject = AlwaysEqual; }
Để định nghĩa AlwaysEqual, chúng ta sử dụng từ khóa struct, tên mà chúng ta
muốn, và sau đó là dấu chấm phẩy. Không cần dấu ngoặc nhọn hoặc dấu ngoặc tròn!
Sau đó chúng ta có thể lấy một thực thể của AlwaysEqual trong biến subject
theo cách tương tự: sử dụng tên mà chúng ta đã định nghĩa, không có dấu ngoặc
nhọn hoặc dấu ngoặc tròn nào. Hãy tưởng tượng rằng sau này chúng ta sẽ thực hiện
hành vi cho kiểu này sao cho mọi thực thể của AlwaysEqual luôn bằng với mọi
thực thể của bất kỳ kiểu nào khác, có lẽ để có một kết quả đã biết cho mục đích
kiểm tra. Chúng ta sẽ không cần bất kỳ dữ liệu nào để thực hiện hành vi đó! Bạn
sẽ thấy trong Chương 10 cách định nghĩa trait và thực hiện chúng trên bất kỳ
kiểu nào, bao gồm cả unit-like struct.
Quyền sở hữu Dữ liệu trong Struct
Trong định nghĩa struct
Userở Listing 5-1, chúng ta đã sử dụng kiểuStringcó quyền sở hữu thay vì kiểu string slice&str. Đây là một lựa chọn có chủ đích bởi vì chúng ta muốn mỗi thực thể của struct này sở hữu tất cả dữ liệu của nó và cho dữ liệu đó hợp lệ miễn là toàn bộ struct còn hợp lệ.Cũng có thể để struct lưu trữ các tham chiếu đến dữ liệu thuộc sở hữu của một thứ khác, nhưng để làm điều đó đòi hỏi phải sử dụng lifetimes, một tính năng của Rust mà chúng ta sẽ thảo luận trong Chương 10. Lifetimes đảm bảo rằng dữ liệu được tham chiếu bởi một struct là hợp lệ miễn là struct còn tồn tại. Hãy giả sử bạn cố gắng lưu trữ một tham chiếu trong một struct mà không chỉ định lifetimes, như sau; điều này sẽ không hoạt động:
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: "someusername123", email: "someone@example.com", sign_in_count: 1, }; }Trình biên dịch sẽ phàn nàn rằng nó cần bộ chỉ định lifetime:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` (bin "structs") due to 2 previous errorsTrong Chương 10, chúng ta sẽ thảo luận về cách sửa những lỗi này để bạn có thể lưu trữ tham chiếu trong struct, nhưng hiện tại, chúng ta sẽ sửa các lỗi như thế này bằng cách sử dụng các kiểu có quyền sở hữu như
Stringthay vì các tham chiếu như&str.
Chương trình Ví dụ Sử dụng Structs
Để hiểu khi nào chúng ta nên sử dụng structs, hãy viết một chương trình tính diện tích của hình chữ nhật. Chúng ta sẽ bắt đầu bằng việc sử dụng các biến đơn lẻ, và sau đó cải tiến chương trình cho đến khi chúng ta sử dụng structs.
Hãy tạo một dự án binary mới với Cargo có tên rectangles để tính diện tích hình chữ nhật dựa trên chiều rộng và chiều cao được chỉ định bằng pixel. Listing 5-8 hiển thị một chương trình ngắn với một cách thực hiện chính xác điều đó trong tệp src/main.rs của dự án chúng ta.
fn main() { let width1 = 30; let height1 = 50; println!( "The area of the rectangle is {} square pixels.", area(width1, height1) ); } fn area(width: u32, height: u32) -> u32 { width * height }
Bây giờ, chạy chương trình này bằng cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
Đoạn mã này thành công trong việc tính diện tích của hình chữ nhật bằng cách gọi
hàm area với mỗi kích thước, nhưng chúng ta có thể làm nhiều hơn nữa để làm
cho mã này rõ ràng và dễ đọc hơn.
Vấn đề với đoạn mã này thể hiện rõ trong chữ ký của hàm area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Hàm area được cho là để tính diện tích của một hình chữ nhật, nhưng hàm mà
chúng ta đã viết có hai tham số, và không có chỗ nào trong chương trình của
chúng ta làm rõ rằng các tham số này có liên quan đến nhau. Sẽ dễ đọc và dễ quản
lý hơn nếu nhóm chiều rộng và chiều cao lại với nhau. Chúng ta đã thảo luận về
một cách chúng ta có thể làm điều đó trong phần "Kiểu
Tuple" của Chương 3: bằng cách sử dụng các
tuple.
Cải tiến với Tuples
Listing 5-9 hiển thị một phiên bản khác của chương trình chúng ta sử dụng tuples.
fn main() { let rect1 = (30, 50); println!( "The area of the rectangle is {} square pixels.", area(rect1) ); } fn area(dimensions: (u32, u32)) -> u32 { dimensions.0 * dimensions.1 }
Ở một khía cạnh, chương trình này tốt hơn. Tuples cho phép chúng ta thêm một chút cấu trúc và giờ đây chúng ta chỉ truyền một đối số. Nhưng ở một khía cạnh khác, phiên bản này ít rõ ràng hơn: tuples không đặt tên cho các phần tử của chúng, vì vậy chúng ta phải lập chỉ mục vào các phần của tuple, làm cho phép tính của chúng ta kém rõ ràng hơn.
Việc nhầm lẫn chiều rộng và chiều cao sẽ không ảnh hưởng đến phép tính diện
tích, nhưng nếu chúng ta muốn vẽ hình chữ nhật trên màn hình, điều đó sẽ quan
trọng! Chúng ta sẽ phải nhớ rằng width là chỉ mục tuple 0 và height là chỉ
mục tuple 1. Điều này sẽ càng khó hơn cho người khác để hiểu và ghi nhớ nếu họ
sử dụng mã của chúng ta. Bởi vì chúng ta chưa truyền đạt ý nghĩa của dữ liệu
trong mã của mình, việc dễ gây ra lỗi hơn.
Cải tiến với Structs: Thêm Ý nghĩa
Chúng ta sử dụng structs để thêm ý nghĩa bằng cách gắn nhãn cho dữ liệu. Chúng ta có thể chuyển đổi tuple chúng ta đang sử dụng thành một struct với một tên cho toàn bộ cũng như các tên cho các phần, như được hiển thị trong Listing 5-10.
struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", area(&rect1) ); } fn area(rectangle: &Rectangle) -> u32 { rectangle.width * rectangle.height }
Ở đây, chúng ta đã định nghĩa một struct và đặt tên nó là Rectangle. Bên trong
dấu ngoặc nhọn, chúng ta định nghĩa các trường là width và height, cả hai
đều có kiểu u32. Sau đó, trong main, chúng ta tạo một instance cụ thể của
Rectangle có chiều rộng 30 và chiều cao 50.
Hàm area của chúng ta bây giờ được định nghĩa với một tham số, mà chúng ta đã
đặt tên là rectangle, có kiểu là một tham chiếu không thể thay đổi đến một
instance struct Rectangle. Như đã đề cập trong Chương 4, chúng ta muốn mượn
struct thay vì lấy quyền sở hữu của nó. Bằng cách này, main giữ quyền sở hữu
và có thể tiếp tục sử dụng rect1, đó là lý do tại sao chúng ta sử dụng &
trong chữ ký hàm và nơi chúng ta gọi hàm.
Hàm area truy cập vào các trường width và height của instance Rectangle
(lưu ý rằng việc truy cập các trường của một instance struct đã được mượn không
di chuyển các giá trị trường, đó là lý do tại sao bạn thường thấy việc mượn các
struct). Chữ ký hàm cho area bây giờ nói chính xác những gì chúng ta muốn:
tính diện tích của Rectangle, sử dụng các trường width và height. Điều này
truyền đạt rằng chiều rộng và chiều cao có liên quan đến nhau, và nó đưa ra các
tên mô tả cho các giá trị thay vì sử dụng các giá trị chỉ mục tuple 0 và 1.
Đây là một thắng lợi cho sự rõ ràng.
Thêm Chức năng Hữu ích với Derived Traits
Sẽ rất hữu ích nếu có thể in ra một instance của Rectangle trong khi chúng ta
đang gỡ lỗi chương trình và xem các giá trị cho tất cả các trường của nó.
Listing 5-11 thử sử dụng macro println! như chúng ta
đã sử dụng trong các chương trước. Tuy nhiên, điều này sẽ không hoạt động.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1}");
}Khi chúng ta biên dịch đoạn mã này, chúng ta nhận được một lỗi với thông báo cốt lõi này:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
Macro println! có thể thực hiện nhiều loại định dạng, và theo mặc định, dấu
ngoặc nhọn báo cho println! sử dụng định dạng được gọi là Display: đầu ra
dành cho người dùng cuối trực tiếp. Các kiểu nguyên thủy mà chúng ta đã thấy cho
đến nay triển khai Display theo mặc định vì chỉ có một cách bạn muốn hiển thị
1 hoặc bất kỳ kiểu nguyên thủy nào khác cho người dùng. Nhưng với các struct,
cách println! nên định dạng đầu ra ít rõ ràng hơn vì có nhiều khả năng hiển
thị hơn: Bạn có muốn dấu phẩy hay không? Bạn có muốn in dấu ngoặc nhọn? Tất cả
các trường có nên được hiển thị không? Do tính mơ hồ này, Rust không cố đoán
những gì chúng ta muốn, và các struct không có sẵn thực thi của Display để sử
dụng với println! và placeholder {}.
Nếu chúng ta tiếp tục đọc các lỗi, chúng ta sẽ tìm thấy ghi chú hữu ích này:
| |`Rectangle` cannot be formatted with the default formatter
| required by this formatting parameter
Hãy thử nó! Lệnh gọi macro println! bây giờ sẽ trông như
println!("rect1 is {rect1:?}");. Đặt đặc tả :? bên trong dấu ngoặc nhọn báo
cho println! rằng chúng ta muốn sử dụng một định dạng đầu ra được gọi là
Debug. Trait Debug cho phép chúng ta in struct theo cách hữu ích cho các nhà
phát triển để chúng ta có thể thấy giá trị của nó trong khi chúng ta đang gỡ lỗi
mã của mình.
Biên dịch mã với thay đổi này. Chết tiệt! Chúng ta vẫn nhận được một lỗi:
error[E0277]: `Rectangle` doesn't implement `Debug`
Nhưng một lần nữa, trình biên dịch cung cấp cho chúng ta một ghi chú hữu ích:
| required by this formatting parameter
|
Rust có bao gồm chức năng để in ra thông tin gỡ lỗi, nhưng chúng ta phải chọn
tham gia một cách rõ ràng để làm cho chức năng đó có sẵn cho struct của chúng
ta. Để làm điều đó, chúng ta thêm thuộc tính ngoài #[derive(Debug)] ngay trước
định nghĩa struct, như được hiển thị trong Listing 5-12.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {rect1:?}"); }
Bây giờ khi chúng ta chạy chương trình, chúng ta sẽ không gặp bất kỳ lỗi nào, và chúng ta sẽ thấy đầu ra sau:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Tuyệt! Đây không phải là đầu ra đẹp nhất, nhưng nó hiển thị các giá trị của tất
cả các trường cho instance này, điều này chắc chắn sẽ giúp ích trong quá trình
gỡ lỗi. Khi chúng ta có các struct lớn hơn, sẽ hữu ích khi có đầu ra dễ đọc hơn
một chút; trong những trường hợp đó, chúng ta có thể sử dụng {:#?} thay vì
{:?} trong chuỗi println!. Trong ví dụ này, sử dụng kiểu {:#?} sẽ xuất ra
như sau:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Một cách khác để in ra một giá trị sử dụng định dạng Debug là sử dụng macro
dbg!, lấy quyền sở hữu của một biểu thức (trái ngược với
println!, lấy một tham chiếu), in ra tệp và số dòng nơi lệnh gọi macro dbg!
đó xuất hiện trong mã của bạn cùng với giá trị kết quả của biểu thức đó, và trả
lại quyền sở hữu của giá trị.
Lưu ý: Gọi macro
dbg!in ra luồng bảng điều khiển lỗi tiêu chuẩn (stderr), trái ngược vớiprintln!, in ra luồng bảng điều khiển đầu ra tiêu chuẩn (stdout). Chúng ta sẽ nói thêm vềstderrvàstdouttrong phần "Viết Thông báo Lỗi cho Standard Error Thay vì Standard Output" trong Chương 12.
Đây là một ví dụ trong đó chúng ta quan tâm đến giá trị được gán cho trường
width, cũng như giá trị của toàn bộ struct trong rect1:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let scale = 2; let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); }
Chúng ta có thể đặt dbg! xung quanh biểu thức 30 * scale và, bởi vì dbg!
trả lại quyền sở hữu của giá trị biểu thức, trường width sẽ nhận được cùng một
giá trị như thể chúng ta không có lệnh gọi dbg! ở đó. Chúng ta không muốn
dbg! lấy quyền sở hữu của rect1, vì vậy chúng ta sử dụng một tham chiếu đến
rect1 trong lệnh gọi tiếp theo. Đây là đầu ra của ví dụ này:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
Chúng ta có thể thấy phần đầu tiên của đầu ra đến từ dòng 10 của src/main.rs
nơi chúng ta đang gỡ lỗi biểu thức 30 * scale, và giá trị kết quả của nó là
60 (định dạng Debug được thực hiện cho các số nguyên là chỉ in giá trị của
chúng). Lệnh gọi dbg! trên dòng 14 của src/main.rs xuất ra giá trị của
&rect1, đó là struct Rectangle. Đầu ra này sử dụng định dạng Debug đẹp của
kiểu Rectangle. Macro dbg! có thể thực sự hữu ích khi bạn đang cố gắng tìm
hiểu xem mã của bạn đang làm gì!
Ngoài trait Debug, Rust đã cung cấp một số trait cho chúng ta sử dụng với
thuộc tính derive có thể thêm hành vi hữu ích cho các kiểu tùy chỉnh của chúng
ta. Những trait đó và hành vi của chúng được liệt kê trong Phụ lục
C. Chúng ta sẽ đề cập đến cách triển khai các trait này
với hành vi tùy chỉnh cũng như cách tạo trait của riêng mình trong Chương 10.
Ngoài ra còn có nhiều thuộc tính khác ngoài derive; để biết thêm thông tin,
xem phần "Thuộc tính" của Tham chiếu Rust.
Hàm area của chúng ta rất cụ thể: nó chỉ tính diện tích của hình chữ nhật. Sẽ
hữu ích hơn nếu gắn hành vi này chặt chẽ hơn với struct Rectangle của chúng ta
vì nó sẽ không hoạt động với bất kỳ kiểu nào khác. Hãy xem xét làm thế nào chúng
ta có thể tiếp tục cải tiến mã này bằng cách chuyển hàm area thành phương
thức area được định nghĩa trên kiểu Rectangle của chúng ta.
Cú pháp Method
Method tương tự như các hàm: chúng ta khai báo chúng với từ khóa fn và một
tên, chúng có thể có các tham số và giá trị trả về, và chúng chứa một số mã được
chạy khi method được gọi từ nơi khác. Không giống như các hàm, method được định
nghĩa trong ngữ cảnh của một struct (hoặc một enum hoặc một trait object, mà
chúng ta sẽ đề cập trong Chương 6 và Chương
18, tương ứng), và tham số đầu tiên của chúng
luôn là self, đại diện cho instance của struct mà method đang được gọi.
Định nghĩa Method
Hãy thay đổi hàm area có một instance Rectangle làm tham số và thay vào đó,
tạo một method area được định nghĩa trên struct Rectangle, như thể hiện
trong Listing 5-13.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", rect1.area() ); }
Để định nghĩa hàm trong ngữ cảnh của Rectangle, chúng ta bắt đầu một khối
impl (implementation) cho Rectangle. Mọi thứ trong khối impl này sẽ được
liên kết với kiểu Rectangle. Sau đó, chúng ta di chuyển hàm area vào trong
dấu ngoặc nhọn impl và thay đổi tham số đầu tiên (và trong trường hợp này, duy
nhất) thành self trong chữ ký và mọi nơi trong nội dung hàm. Trong main, nơi
chúng ta đã gọi hàm area và truyền rect1 như một đối số, chúng ta có thể sử
dụng cú pháp method để gọi method area trên instance Rectangle của chúng
ta. Cú pháp method được đặt sau một instance: chúng ta thêm một dấu chấm theo
sau bởi tên method, dấu ngoặc đơn, và bất kỳ đối số nào.
Trong chữ ký cho area, chúng ta sử dụng &self thay vì
rectangle: &Rectangle. &self thực tế là viết tắt của self: &Self. Trong
một khối impl, kiểu Self là bí danh cho kiểu mà khối impl đang áp dụng.
Method phải có một tham số tên là self kiểu Self làm tham số đầu tiên, vì
vậy Rust cho phép bạn viết tắt điều này với chỉ tên self ở vị trí tham số đầu
tiên. Lưu ý rằng chúng ta vẫn cần sử dụng & trước viết tắt self để chỉ ra
rằng method này mượn instance Self, giống như chúng ta đã làm trong
rectangle: &Rectangle. Method có thể lấy quyền sở hữu của self, mượn self
không thay đổi như chúng ta đã làm ở đây, hoặc mượn self có thể thay đổi,
giống như chúng có thể với bất kỳ tham số nào khác.
Chúng ta chọn &self ở đây vì cùng lý do chúng ta đã sử dụng &Rectangle trong
phiên bản hàm: chúng ta không muốn lấy quyền sở hữu, và chúng ta chỉ muốn đọc dữ
liệu trong struct, không viết vào nó. Nếu chúng ta muốn thay đổi instance mà
chúng ta đã gọi method như một phần của những gì method làm, chúng ta sẽ sử dụng
&mut self làm tham số đầu tiên. Có một method lấy quyền sở hữu của instance
bằng cách chỉ sử dụng self làm tham số đầu tiên là hiếm; kỹ thuật này thường
được sử dụng khi method chuyển đổi self thành một cái gì đó khác và bạn muốn
ngăn người gọi sử dụng instance ban đầu sau khi chuyển đổi.
Lý do chính để sử dụng method thay vì hàm, ngoài việc cung cấp cú pháp method và
không phải lặp lại kiểu của self trong mọi chữ ký method, là để tổ chức. Chúng
ta đã đặt tất cả những thứ có thể làm với một instance của một kiểu trong một
khối impl thay vì làm cho người dùng tương lai của mã chúng ta phải tìm kiếm
khả năng của Rectangle ở nhiều nơi khác nhau trong thư viện mà chúng ta cung
cấp.
Lưu ý rằng chúng ta có thể chọn đặt tên cho một method giống với tên của một
trong các trường của struct. Ví dụ, chúng ta có thể định nghĩa một method trên
Rectangle cũng được đặt tên là width:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn width(&self) -> bool { self.width > 0 } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; if rect1.width() { println!("The rectangle has a nonzero width; it is {}", rect1.width); } }
Ở đây, chúng ta đang chọn cách làm cho method width trả về true nếu giá trị
trong trường width của instance lớn hơn 0 và false nếu giá trị là 0:
chúng ta có thể sử dụng một trường trong một method cùng tên cho bất kỳ mục đích
nào. Trong main, khi chúng ta theo sau rect1.width với dấu ngoặc đơn, Rust
biết chúng ta đang đề cập đến method width. Khi chúng ta không sử dụng dấu
ngoặc đơn, Rust biết chúng ta đang đề cập đến trường width.
Thường xuyên, nhưng không phải lúc nào cũng vậy, khi chúng ta đặt cho một method cùng tên với một trường, chúng ta muốn nó chỉ trả về giá trị trong trường đó và không làm gì khác. Các method như thế này được gọi là getter, và Rust không tự động triển khai chúng cho các trường của struct như một số ngôn ngữ khác. Getter rất hữu ích vì bạn có thể làm cho trường này riêng tư nhưng method là công khai, và do đó cho phép truy cập chỉ đọc vào trường đó như một phần của API công khai của kiểu. Chúng ta sẽ thảo luận về các khái niệm công khai và riêng tư là gì và cách chỉ định một trường hoặc method là công khai hay riêng tư trong Chương 7.
Toán tử
->Ở Đâu?Trong C và C++, hai toán tử khác nhau được sử dụng để gọi method: bạn sử dụng
.nếu bạn đang gọi một method trực tiếp trên đối tượng và->nếu bạn đang gọi method trên một con trỏ đến đối tượng và cần giải tham chiếu con trỏ trước. Nói cách khác, nếuobjectlà một con trỏ,object->something()tương tự như(*object).something().Rust không có một toán tử tương đương với
->; thay vào đó, Rust có một tính năng gọi là tham chiếu và giải tham chiếu tự động. Gọi method là một trong số ít nơi trong Rust có hành vi này.Đây là cách nó hoạt động: khi bạn gọi một method bằng
object.something(), Rust tự động thêm&,&mut, hoặc*đểobjectkhớp với chữ ký của method. Nói cách khác, những điều sau đây là giống nhau:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }Cái đầu tiên trông gọn gàng hơn nhiều. Hành vi tham chiếu tự động này hoạt động bởi vì method có một người nhận rõ ràng—kiểu của
self. Với người nhận và tên của một method, Rust có thể xác định rõ ràng liệu method đang đọc (&self), biến đổi (&mut self), hay tiêu thụ (self). Thực tế là Rust làm cho việc mượn ngầm định cho người nhận method là một phần lớn của việc làm cho quyền sở hữu trở nên tiện dụng trong thực tế.
Method với Nhiều Tham số
Hãy thực hành sử dụng method bằng cách triển khai một method thứ hai trên struct
Rectangle. Lần này chúng ta muốn một instance của Rectangle lấy một instance
khác của Rectangle và trả về true nếu Rectangle thứ hai có thể nằm hoàn
toàn bên trong self (tức là Rectangle đầu tiên); nếu không, nó sẽ trả về
false. Nghĩa là, một khi chúng ta đã định nghĩa method can_hold, chúng ta
muốn có thể viết chương trình được hiển thị trong Listing 5-14.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}Đầu ra dự kiến sẽ trông giống như sau bởi vì cả hai kích thước của rect2 đều
nhỏ hơn kích thước của rect1, nhưng rect3 rộng hơn rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
Chúng ta biết mình muốn định nghĩa một method, vì vậy nó sẽ nằm trong khối
impl Rectangle. Tên method sẽ là can_hold, và nó sẽ lấy một bản mượn không
thay đổi của một Rectangle khác làm tham số. Chúng ta có thể biết kiểu của
tham số sẽ là gì bằng cách nhìn vào mã gọi method: rect1.can_hold(&rect2)
truyền vào &rect2, đó là một bản mượn không thay đổi cho rect2, một instance
của Rectangle. Điều này có ý nghĩa vì chúng ta chỉ cần đọc rect2 (thay vì
viết, có nghĩa là chúng ta cần một bản mượn có thể thay đổi), và chúng ta muốn
main giữ quyền sở hữu của rect2 để chúng ta có thể sử dụng nó lại sau khi
gọi method can_hold. Giá trị trả về của can_hold sẽ là một giá trị Boolean,
và việc triển khai sẽ kiểm tra xem chiều rộng và chiều cao của self có lớn hơn
chiều rộng và chiều cao của Rectangle khác hay không, tương ứng. Hãy thêm
method can_hold mới vào khối impl từ Listing 5-13, như được hiển thị trong
Listing 5-15.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
Khi chúng ta chạy mã này với hàm main trong Listing 5-14, chúng ta sẽ nhận
được đầu ra mong muốn. Method có thể lấy nhiều tham số mà chúng ta thêm vào chữ
ký sau tham số self, và những tham số đó hoạt động giống như tham số trong
hàm.
Hàm Liên kết
Tất cả các hàm được định nghĩa trong một khối impl được gọi là hàm liên kết
bởi vì chúng được liên kết với kiểu được đặt tên sau impl. Chúng ta có thể
định nghĩa các hàm liên kết mà không có self là tham số đầu tiên của chúng (và
do đó không phải là method) bởi vì chúng không cần một instance của kiểu để làm
việc với. Chúng ta đã sử dụng một hàm như thế này: hàm String::from mà được
định nghĩa trên kiểu String.
Các hàm liên kết không phải là method thường được sử dụng cho các constructor sẽ
trả về một instance mới của struct. Những hàm này thường được gọi là new,
nhưng new không phải là một tên đặc biệt và không được tích hợp sẵn trong ngôn
ngữ. Ví dụ, chúng ta có thể chọn cung cấp một hàm liên kết có tên square sẽ có
một tham số kích thước và sử dụng nó làm cả chiều rộng và chiều cao, từ đó giúp
tạo một Rectangle vuông dễ dàng hơn thay vì phải chỉ định cùng một giá trị hai
lần:
Tên tệp: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn square(size: u32) -> Self { Self { width: size, height: size, } } } fn main() { let sq = Rectangle::square(3); }
Từ khóa Self trong kiểu trả về và trong nội dung của hàm là bí danh cho kiểu
xuất hiện sau từ khóa impl, trong trường hợp này là Rectangle.
Để gọi hàm liên kết này, chúng ta sử dụng cú pháp :: với tên struct;
let sq = Rectangle::square(3); là một ví dụ. Hàm này được đặt tên trong không
gian tên bởi struct: cú pháp :: được sử dụng cho cả hàm liên kết và không gian
tên được tạo bởi các module. Chúng ta sẽ thảo luận về các module trong Chương
7.
Nhiều Khối impl
Mỗi struct được phép có nhiều khối impl. Ví dụ, Listing 5-15 tương đương với
mã được hiển thị trong Listing 5-16, trong đó mỗi method nằm trong khối impl
riêng của nó.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
Không có lý do gì để tách các method này thành nhiều khối impl ở đây, nhưng
đây là cú pháp hợp lệ. Chúng ta sẽ thấy một trường hợp trong đó nhiều khối
impl là hữu ích trong Chương 10, nơi chúng ta thảo luận về các kiểu và trait
generic.
Tóm tắt
Struct cho phép bạn tạo các kiểu tùy chỉnh có ý nghĩa cho miền của bạn. Bằng
cách sử dụng struct, bạn có thể giữ các phần dữ liệu liên quan với nhau và đặt
tên cho mỗi phần để làm mã của bạn rõ ràng. Trong các khối impl, bạn có thể
định nghĩa các hàm được liên kết với kiểu của bạn, và method là một loại hàm
liên kết cho phép bạn chỉ định hành vi mà các instance của struct của bạn có.
Nhưng struct không phải là cách duy nhất để bạn tạo kiểu tùy chỉnh: hãy chuyển sang tính năng enum của Rust để thêm một công cụ khác vào hộp công cụ của bạn.
Enums và Pattern Matching
Trong chương này, chúng ta sẽ tìm hiểu về enumerations, hay còn được gọi là
enums. Enums cho phép bạn định nghĩa một kiểu bằng cách liệt kê các biến thể
(variants) có thể có của nó. Đầu tiên chúng ta sẽ định nghĩa và sử dụng một enum
để chỉ ra cách một enum có thể mã hóa ý nghĩa cùng với dữ liệu. Tiếp theo, chúng
ta sẽ khám phá một enum đặc biệt hữu ích là Option, nó biểu thị rằng một giá
trị có thể là một cái gì đó hoặc không là gì cả. Sau đó, chúng ta sẽ xem xét
cách mà pattern matching trong biểu thức match giúp dễ dàng chạy các đoạn mã
khác nhau cho các giá trị khác nhau của một enum. Cuối cùng, chúng ta sẽ tìm
hiểu cách cấu trúc if let là một thành ngữ khác tiện lợi và ngắn gọn có sẵn để
xử lý enums trong mã của bạn.
Định nghĩa một Enum
Trong khi struct cung cấp cho bạn cách nhóm các trường và dữ liệu liên quan với
nhau, như một Rectangle với width và height của nó, enum cho bạn cách để
nói rằng một giá trị là một trong một tập hợp các giá trị có thể có. Ví dụ,
chúng ta có thể muốn nói rằng Rectangle là một trong một tập hợp các hình dạng
có thể có bao gồm cả Circle và Triangle. Để làm được điều này, Rust cho phép
chúng ta mã hóa các khả năng này như một enum.
Hãy xem xét một tình huống mà chúng ta có thể muốn biểu đạt trong mã và tìm hiểu tại sao enum hữu ích và phù hợp hơn struct trong trường hợp này. Giả sử chúng ta cần làm việc với địa chỉ IP. Hiện tại, hai chuẩn chính được sử dụng cho địa chỉ IP: phiên bản bốn và phiên bản sáu. Vì đây là những khả năng duy nhất cho một địa chỉ IP mà chương trình của chúng ta sẽ gặp phải, chúng ta có thể liệt kê tất cả các biến thể có thể có, đó là nơi mà enumeration có được tên gọi của nó.
Bất kỳ địa chỉ IP nào cũng có thể là địa chỉ phiên bản bốn hoặc phiên bản sáu, nhưng không thể là cả hai cùng một lúc. Đặc tính đó của địa chỉ IP làm cho cấu trúc dữ liệu enum trở nên thích hợp bởi vì một giá trị enum chỉ có thể là một trong các biến thể của nó. Cả hai địa chỉ phiên bản bốn và phiên bản sáu đều về cơ bản vẫn là địa chỉ IP, vì vậy chúng nên được xử lý như cùng một kiểu khi mã đang xử lý các tình huống áp dụng cho bất kỳ loại địa chỉ IP nào.
Chúng ta có thể biểu đạt khái niệm này trong mã bằng cách định nghĩa một enum
IpAddrKind và liệt kê các loại có thể có của địa chỉ IP, V4 và V6. Đây là
các biến thể của enum:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
IpAddrKind bây giờ là một kiểu dữ liệu tùy chỉnh mà chúng ta có thể sử dụng ở
nơi khác trong mã của mình.
Giá trị Enum
Chúng ta có thể tạo các instance của mỗi biến thể của IpAddrKind như thế này:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Lưu ý rằng các biến thể của enum được đặt tên trong không gian tên dưới định
danh của nó, và chúng ta sử dụng dấu hai chấm kép để tách chúng. Điều này hữu
ích bởi vì bây giờ cả hai giá trị IpAddrKind::V4 và IpAddrKind::V6 đều thuộc
cùng một kiểu: IpAddrKind. Chúng ta sau đó có thể, ví dụ, định nghĩa một hàm
nhận bất kỳ IpAddrKind nào:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Và chúng ta có thể gọi hàm này với cả hai biến thể:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Sử dụng enum thậm chí còn có nhiều lợi thế hơn. Khi suy nghĩ nhiều hơn về kiểu địa chỉ IP của chúng ta, hiện tại chúng ta không có cách nào để lưu trữ dữ liệu thực tế của địa chỉ IP; chúng ta chỉ biết nó thuộc loại nào. Vì bạn vừa mới học về struct trong Chương 5, bạn có thể bị cám dỗ để giải quyết vấn đề này với struct như được thể hiện trong Listing 6-1.
fn main() { enum IpAddrKind { V4, V6, } struct IpAddr { kind: IpAddrKind, address: String, } let home = IpAddr { kind: IpAddrKind::V4, address: String::from("127.0.0.1"), }; let loopback = IpAddr { kind: IpAddrKind::V6, address: String::from("::1"), }; }
Ở đây, chúng ta đã định nghĩa một struct IpAddr có hai trường: một trường
kind là kiểu IpAddrKind (enum mà chúng ta đã định nghĩa trước đó) và một
trường address kiểu String. Chúng ta có hai instance của struct này.
Instance đầu tiên là home, và nó có giá trị IpAddrKind::V4 làm kind với dữ
liệu địa chỉ liên quan là 127.0.0.1. Instance thứ hai là loopback. Nó có
biến thể khác của IpAddrKind làm giá trị kind của nó, V6, và có địa chỉ
::1 liên kết với nó. Chúng ta đã sử dụng một struct để nhóm các giá trị kind
và address lại với nhau, vì vậy bây giờ biến thể được liên kết với giá trị.
Tuy nhiên, biểu diễn cùng một khái niệm chỉ bằng enum thì ngắn gọn hơn: thay vì
một enum bên trong một struct, chúng ta có thể đưa dữ liệu trực tiếp vào mỗi
biến thể enum. Định nghĩa mới này của enum IpAddr nói rằng cả hai biến thể
V4 và V6 sẽ có các giá trị String liên quan:
fn main() { enum IpAddr { V4(String), V6(String), } let home = IpAddr::V4(String::from("127.0.0.1")); let loopback = IpAddr::V6(String::from("::1")); }
Chúng ta gắn dữ liệu trực tiếp vào mỗi biến thể của enum, vì vậy không cần một
struct bổ sung. Ở đây, cũng dễ dàng hơn để thấy một chi tiết khác về cách enum
hoạt động: tên của mỗi biến thể enum mà chúng ta định nghĩa cũng trở thành một
hàm xây dựng một instance của enum đó. Nghĩa là, IpAddr::V4() là một lệnh gọi
hàm nhận một đối số String và trả về một instance của kiểu IpAddr. Chúng ta
tự động nhận được hàm constructor này được định nghĩa là kết quả của việc định
nghĩa enum.
Có một lợi thế khác khi sử dụng enum thay vì struct: mỗi biến thể có thể có các
loại và số lượng dữ liệu liên quan khác nhau. Địa chỉ IP phiên bản bốn sẽ luôn
có bốn thành phần số mà sẽ có giá trị từ 0 đến 255. Nếu chúng ta muốn lưu trữ
địa chỉ V4 dưới dạng bốn giá trị u8 nhưng vẫn biểu đạt địa chỉ V6 dưới
dạng một giá trị String, chúng ta sẽ không thể làm được với một struct. Enum
xử lý trường hợp này một cách dễ dàng:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1")); }
Chúng ta đã thể hiện một số cách khác nhau để định nghĩa cấu trúc dữ liệu để lưu
trữ phiên bản bốn và phiên bản sáu địa chỉ IP. Tuy nhiên, hóa ra, muốn lưu trữ
địa chỉ IP và mã hóa loại nào của chúng là rất phổ biến đến nỗi thư viện chuẩn
đã có một định nghĩa mà chúng ta có thể sử dụng! Hãy xem
cách thư viện chuẩn định nghĩa IpAddr: nó có chính xác enum và các biến thể mà
chúng ta đã định nghĩa và sử dụng, nhưng nó nhúng dữ liệu địa chỉ bên trong các
biến thể dưới dạng hai struct khác nhau, được định nghĩa khác nhau cho mỗi biến
thể:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
Đoạn mã này minh họa rằng bạn có thể đặt bất kỳ loại dữ liệu nào bên trong một biến thể enum: chuỗi, kiểu số, hoặc struct, ví dụ vậy. Bạn thậm chí có thể bao gồm một enum khác! Ngoài ra, các kiểu thư viện chuẩn thường không phức tạp hơn nhiều so với những gì bạn có thể nghĩ ra.
Lưu ý rằng mặc dù thư viện chuẩn chứa một định nghĩa cho IpAddr, chúng ta vẫn
có thể tạo và sử dụng định nghĩa của riêng mình mà không gây xung đột vì chúng
ta chưa đưa định nghĩa của thư viện chuẩn vào phạm vi của mình. Chúng ta sẽ nói
thêm về việc đưa các kiểu vào phạm vi trong Chương 7.
Hãy xem một ví dụ khác về enum trong Listing 6-2: ví dụ này có sự đa dạng về các kiểu nhúng trong các biến thể của nó.
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Enum này có bốn biến thể với các kiểu khác nhau:
QuitKhông có dữ liệu nào liên kết với nó.MoveCó các trường có tên, giống như một struct.WriteBao gồm mộtStringduy nhất.ChangeColorBao gồm ba giá trịi32.
Định nghĩa một enum với các biến thể như trong Listing 6-2 tương tự như việc
định nghĩa các loại định nghĩa struct khác nhau, ngoại trừ việc enum không sử
dụng từ khóa struct và tất cả các biến thể được nhóm lại với nhau dưới kiểu
Message. Các struct sau đây có thể lưu trữ cùng dữ liệu mà các biến thể enum
trước đó lưu trữ:
struct QuitMessage; // unit struct struct MoveMessage { x: i32, y: i32, } struct WriteMessage(String); // tuple struct struct ChangeColorMessage(i32, i32, i32); // tuple struct fn main() {}
Nhưng nếu chúng ta sử dụng các struct khác nhau, mỗi struct có kiểu riêng, chúng
ta không thể dễ dàng định nghĩa một hàm để nhận bất kỳ loại thông điệp nào trong
số này như chúng ta có thể làm với enum Message được định nghĩa trong Listing
6-2, vốn là một kiểu duy nhất.
Có một điểm tương đồng nữa giữa enum và struct: giống như chúng ta có thể định
nghĩa các phương thức trên struct bằng cách sử dụng impl, chúng ta cũng có thể
định nghĩa các phương thức trên enum. Đây là một phương thức có tên call mà
chúng ta có thể định nghĩa trên enum Message của chúng ta:
fn main() { enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } impl Message { fn call(&self) { // method body would be defined here } } let m = Message::Write(String::from("hello")); m.call(); }
Nội dung của phương thức sẽ sử dụng self để lấy giá trị mà chúng ta đã gọi
phương thức trên đó. Trong ví dụ này, chúng ta đã tạo một biến m có giá trị
Message::Write(String::from("hello")), và đó là giá trị mà self sẽ là trong
nội dung của phương thức call khi m.call() chạy.
Hãy xem một enum khác trong thư viện chuẩn rất phổ biến và hữu ích: Option.
Enum Option và Lợi thế của Nó So với Giá trị Null
Phần này khám phá một trường hợp nghiên cứu của Option, một enum khác được
định nghĩa bởi thư viện chuẩn. Kiểu Option mã hóa kịch bản rất phổ biến trong
đó một giá trị có thể là một thứ gì đó hoặc có thể là không có gì.
Ví dụ, nếu bạn yêu cầu phần tử đầu tiên trong danh sách không rỗng, bạn sẽ nhận được một giá trị. Nếu bạn yêu cầu phần tử đầu tiên trong danh sách rỗng, bạn sẽ không nhận được gì. Biểu đạt khái niệm này trong hệ thống kiểu có nghĩa là trình biên dịch có thể kiểm tra liệu bạn đã xử lý tất cả các trường hợp mà bạn nên xử lý hay chưa; điều này có thể ngăn chặn các lỗi cực kỳ phổ biến trong các ngôn ngữ lập trình khác.
Thiết kế ngôn ngữ lập trình thường được nghĩ đến theo nghĩa của các tính năng bạn bao gồm, nhưng các tính năng bạn loại trừ cũng quan trọng. Rust không có tính năng null mà nhiều ngôn ngữ khác có. Null là một giá trị có nghĩa là không có giá trị nào ở đó. Trong các ngôn ngữ có null, biến luôn có thể ở một trong hai trạng thái: null hoặc không-null.
Trong bài thuyết trình năm 2009 của mình "Null References: The Billion Dollar Mistake," Tony Hoare, người phát minh ra null, đã nói như sau:
Tôi gọi đó là sai lầm hàng tỷ đô la của mình. Vào thời điểm đó, tôi đang thiết kế hệ thống kiểu đầu tiên toàn diện cho các tham chiếu trong một ngôn ngữ hướng đối tượng. Mục tiêu của tôi là đảm bảo rằng tất cả việc sử dụng tham chiếu phải hoàn toàn an toàn, với việc kiểm tra được thực hiện tự động bởi trình biên dịch. Nhưng tôi đã không thể cưỡng lại cám dỗ đặt vào một tham chiếu null, đơn giản vì nó rất dễ thực hiện. Điều này đã dẫn đến vô số lỗi, lỗ hổng và hệ thống bị sập, có lẽ đã gây ra tổn thất và thiệt hại hàng tỷ đô la trong bốn mươi năm qua.
Vấn đề với giá trị null là nếu bạn cố gắng sử dụng một giá trị null như một giá trị không-null, bạn sẽ gặp một loại lỗi nào đó. Bởi vì thuộc tính null hoặc không-null này là phổ biến, rất dễ mắc phải loại lỗi này.
Tuy nhiên, khái niệm mà null đang cố gắng biểu đạt vẫn là một khái niệm hữu ích: một null là một giá trị hiện không hợp lệ hoặc vắng mặt vì một lý do nào đó.
Vấn đề thực sự không phải là với khái niệm mà là với cách triển khai cụ thể. Vì
vậy, Rust không có null, nhưng nó có một enum có thể mã hóa khái niệm về một giá
trị đang hiện diện hoặc vắng mặt. Enum này là Option<T>, và nó được định
nghĩa bởi thư viện chuẩn như sau:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
Enum Option<T> rất hữu ích đến nỗi nó thậm chí được đưa vào prelude; bạn không
cần phải đưa nó vào phạm vi một cách rõ ràng. Các biến thể của nó cũng được bao
gồm trong prelude: bạn có thể sử dụng Some và None trực tiếp mà không cần
tiền tố Option::. Enum Option<T> vẫn chỉ là một enum thông thường, và
Some(T) và None vẫn là các biến thể của kiểu Option<T>.
Cú pháp <T> là một tính năng của Rust mà chúng ta chưa nói đến. Đó là một tham
số kiểu generic, và chúng ta sẽ đề cập đến generic chi tiết hơn trong Chương 10.
Hiện tại, tất cả những gì bạn cần biết là <T> có nghĩa là biến thể Some của
enum Option có thể chứa một phần dữ liệu của bất kỳ kiểu nào, và mỗi kiểu cụ
thể được sử dụng thay thế cho T làm cho toàn bộ kiểu Option<T> trở thành một
kiểu khác. Dưới đây là một số ví dụ về việc sử dụng các giá trị Option để lưu
trữ các kiểu số và kiểu ký tự:
fn main() { let some_number = Some(5); let some_char = Some('e'); let absent_number: Option<i32> = None; }
Kiểu của some_number là Option<i32>. Kiểu của some_char là Option<char>,
là một kiểu khác. Rust có thể suy ra các kiểu này bởi vì chúng ta đã chỉ định
một giá trị bên trong biến thể Some. Đối với absent_number, Rust yêu cầu
chúng ta chú thích toàn bộ kiểu Option: trình biên dịch không thể suy ra kiểu
mà biến thể Some tương ứng sẽ giữ bằng cách chỉ nhìn vào một giá trị None. Ở
đây, chúng ta nói với Rust rằng chúng ta muốn absent_number có kiểu
Option<i32>.
Khi chúng ta có một giá trị Some, chúng ta biết rằng một giá trị đang hiện
diện và giá trị đó được giữ bên trong Some. Khi chúng ta có một giá trị
None, theo một nghĩa nào đó, nó có nghĩa giống như null: chúng ta không có một
giá trị hợp lệ. Vậy tại sao việc có Option<T> lại tốt hơn việc có null?
Nói ngắn gọn, bởi vì Option<T> và T (trong đó T có thể là bất kỳ kiểu nào)
là các kiểu khác nhau, trình biên dịch sẽ không cho phép chúng ta sử dụng giá
trị Option<T> như thể nó là một giá trị hợp lệ chắc chắn. Ví dụ, đoạn mã này
sẽ không biên dịch, bởi vì nó đang cố gắng cộng một i8 với một Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}Nếu chúng ta chạy mã này, chúng ta sẽ nhận được một thông báo lỗi như thế này:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Mạnh mẽ! Về thực chất, thông báo lỗi này có nghĩa là Rust không hiểu cách cộng
một i8 và một Option<i8>, bởi vì chúng là các kiểu khác nhau. Khi chúng ta
có một giá trị của một kiểu như i8 trong Rust, trình biên dịch sẽ đảm bảo rằng
chúng ta luôn có một giá trị hợp lệ. Chúng ta có thể tiến hành một cách tự tin
mà không cần kiểm tra null trước khi sử dụng giá trị đó. Chỉ khi chúng ta có một
Option<i8> (hoặc bất kỳ kiểu giá trị nào mà chúng ta đang làm việc) thì chúng
ta mới phải lo lắng về việc có thể không có một giá trị, và trình biên dịch sẽ
đảm bảo chúng ta xử lý trường hợp đó trước khi sử dụng giá trị.
Nói cách khác, bạn phải chuyển đổi một Option<T> thành một T trước khi bạn
có thể thực hiện các hoạt động T với nó. Nói chung, điều này giúp bắt được một
trong những vấn đề phổ biến nhất với null: giả định rằng một thứ không phải null
khi nó thực sự là null.
Việc loại bỏ nguy cơ giả định không chính xác một giá trị không-null giúp bạn tự
tin hơn về mã của mình. Để có một giá trị có thể là null, bạn phải chọn tham gia
một cách rõ ràng bằng cách làm cho kiểu của giá trị đó là Option<T>. Sau đó,
khi bạn sử dụng giá trị đó, bạn bắt buộc phải xử lý một cách rõ ràng trường hợp
khi giá trị là null. Mọi nơi mà một giá trị có kiểu không phải là Option<T>,
bạn có thể an toàn giả định rằng giá trị không phải là null. Đây là một quyết
định thiết kế có chủ ý của Rust để hạn chế sự phổ biến của null và tăng tính an
toàn của mã Rust.
Vậy làm thế nào để bạn lấy giá trị T ra khỏi một biến thể Some khi bạn có
một giá trị kiểu Option<T> để bạn có thể sử dụng giá trị đó? Enum Option<T>
có một số lượng lớn các phương thức hữu ích trong nhiều tình huống khác nhau;
bạn có thể kiểm tra chúng trong tài liệu của nó. Làm quen
với các phương thức trên Option<T> sẽ cực kỳ hữu ích trong hành trình của bạn
với Rust.
Nói chung, để sử dụng một giá trị Option<T>, bạn muốn có mã sẽ xử lý mỗi biến
thể. Bạn muốn một số mã chỉ chạy khi bạn có giá trị Some(T), và mã này được
phép sử dụng T bên trong. Bạn muốn một số mã khác chỉ chạy nếu bạn có một giá
trị None, và mã đó không có giá trị T nào để sử dụng. Biểu thức match là
một cấu trúc luồng điều khiển làm chính xác điều này khi được sử dụng với enum:
nó sẽ chạy mã khác nhau tùy thuộc vào biến thể nào của enum mà nó có, và mã đó
có thể sử dụng dữ liệu bên trong giá trị phù hợp.
Cấu trúc Điều khiển Luồng match
Rust có một cấu trúc điều khiển luồng cực kỳ mạnh mẽ gọi là match, cho phép
bạn so sánh một giá trị với một loạt các mẫu và sau đó thực thi mã dựa trên mẫu
nào phù hợp. Các mẫu có thể được tạo thành từ các giá trị văn bản, tên biến, ký
tự đại diện, và nhiều thứ khác; Chương 19 bao
gồm tất cả các loại mẫu khác nhau và chức năng của chúng. Sức mạnh của match
đến từ tính biểu đạt của các mẫu và việc trình biên dịch xác nhận rằng tất cả
các trường hợp có thể xảy ra đều được xử lý.
Hãy nghĩ về biểu thức match giống như một máy phân loại tiền xu: các đồng xu
trượt xuống một đường ray với các lỗ có kích thước khác nhau dọc theo nó, và mỗi
đồng xu rơi qua lỗ đầu tiên mà nó gặp và vừa với nó. Tương tự như vậy, các giá
trị đi qua từng mẫu trong một match, và tại mẫu đầu tiên mà giá trị "vừa vặn,"
giá trị đó rơi vào khối mã liên quan để được sử dụng trong quá trình thực thi.
Nói về tiền xu, hãy sử dụng chúng làm ví dụ với match! Chúng ta có thể viết
một hàm nhận một đồng xu không xác định của Hoa Kỳ và, tương tự như máy đếm, xác
định loại đồng xu nào và trả về giá trị của nó bằng xu, như trong Listing 6-3.
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
Hãy phân tích match trong hàm value_in_cents. Đầu tiên, chúng ta liệt kê từ
khóa match và theo sau là một biểu thức, trong trường hợp này là giá trị
coin. Điều này có vẻ rất giống với một biểu thức điều kiện được sử dụng với
if, nhưng có một sự khác biệt lớn: với if, điều kiện cần phải đánh giá thành
một giá trị Boolean, nhưng ở đây nó có thể là bất kỳ kiểu dữ liệu nào. Kiểu của
coin trong ví dụ này là enum Coin mà chúng ta đã định nghĩa ở dòng đầu tiên.
Tiếp theo là các nhánh của match. Một nhánh có hai phần: một mẫu và một đoạn
mã. Nhánh đầu tiên ở đây có mẫu là giá trị Coin::Penny và sau đó là toán tử
=> tách biệt mẫu và mã sẽ chạy. Mã trong trường hợp này chỉ đơn giản là giá
trị 1. Mỗi nhánh được tách biệt với nhánh tiếp theo bằng một dấu phẩy.
Khi biểu thức match thực thi, nó so sánh giá trị kết quả với mẫu của mỗi
nhánh, theo thứ tự. Nếu một mẫu khớp với giá trị, đoạn mã liên kết với mẫu đó sẽ
được thực thi. Nếu mẫu đó không khớp với giá trị, việc thực thi tiếp tục đến
nhánh tiếp theo, tương tự như trong máy phân loại tiền xu. Chúng ta có thể có
nhiều nhánh tùy theo nhu cầu: trong Listing 6-3, match của chúng ta có bốn
nhánh.
Đoạn mã liên kết với mỗi nhánh là một biểu thức, và giá trị kết quả của biểu
thức trong nhánh khớp là giá trị được trả về cho toàn bộ biểu thức match.
Chúng ta thường không sử dụng dấu ngoặc nhọn nếu mã trong nhánh match ngắn gọn,
như trong Listing 6-3 nơi mỗi nhánh chỉ trả về một giá trị. Nếu bạn muốn chạy
nhiều dòng mã trong một nhánh match, bạn phải sử dụng dấu ngoặc nhọn, và dấu
phẩy sau nhánh sau đó là tùy chọn. Ví dụ, đoạn mã sau in ra "Lucky penny!" mỗi
khi phương thức được gọi với một Coin::Penny, nhưng vẫn trả về giá trị cuối
cùng của khối, 1:
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 } Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
Các Mẫu Gắn với Giá trị
Một tính năng hữu ích khác của nhánh match là chúng có thể gắn với các phần của giá trị khớp với mẫu. Đây là cách chúng ta có thể trích xuất các giá trị từ các biến thể enum.
Ví dụ, hãy thay đổi một trong các biến thể enum của chúng ta để lưu trữ dữ liệu
bên trong nó. Từ năm 1999 đến 2008, Hoa Kỳ đã đúc đồng 25 xu với các thiết kế
khác nhau cho mỗi tiểu bang trong số 50 tiểu bang trên một mặt. Không có đồng xu
nào khác có thiết kế tiểu bang, vì vậy chỉ có đồng quarter có giá trị bổ sung
này. Chúng ta có thể thêm thông tin này vào enum bằng cách thay đổi biến thể
Quarter để bao gồm một giá trị UsState được lưu trữ bên trong nó, như chúng
ta đã làm trong Listing 6-4.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() {}
Hãy tưởng tượng rằng một người bạn đang cố gắng sưu tập tất cả 50 đồng quarter của các tiểu bang. Trong khi chúng ta phân loại tiền lẻ theo loại đồng xu, chúng ta cũng sẽ nói to tên của tiểu bang liên quan đến mỗi đồng quarter để nếu đó là một đồng mà bạn của chúng ta chưa có, họ có thể thêm nó vào bộ sưu tập của mình.
Trong biểu thức match cho đoạn mã này, chúng ta thêm một biến có tên state vào
mẫu khớp với các giá trị của biến thể Coin::Quarter. Khi một Coin::Quarter
khớp, biến state sẽ gắn với giá trị của tiểu bang của đồng quarter đó. Sau đó,
chúng ta có thể sử dụng state trong đoạn mã cho nhánh đó, như sau:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {state:?}!"); 25 } } } fn main() { value_in_cents(Coin::Quarter(UsState::Alaska)); }
Nếu chúng ta gọi value_in_cents(Coin::Quarter(UsState::Alaska)), coin sẽ là
Coin::Quarter(UsState::Alaska). Khi chúng ta so sánh giá trị đó với từng nhánh
match, không có nhánh nào khớp cho đến khi chúng ta đến Coin::Quarter(state).
Tại thời điểm đó, giá trị gắn với state sẽ là UsState::Alaska. Chúng ta có
thể sử dụng giá trị gắn đó trong biểu thức println!, từ đó lấy được giá trị
tiểu bang bên trong ra khỏi biến thể enum Coin cho Quarter.
Khớp với Option<T>
Trong phần trước, chúng ta muốn lấy giá trị T bên trong ra khỏi trường hợp
Some khi sử dụng Option<T>; chúng ta cũng có thể xử lý Option<T> bằng cách
sử dụng match, như chúng ta đã làm với enum Coin! Thay vì so sánh các đồng
xu, chúng ta sẽ so sánh các biến thể của Option<T>, nhưng cách biểu thức
match hoạt động vẫn giữ nguyên.
Giả sử chúng ta muốn viết một hàm nhận một Option<i32> và, nếu có giá trị bên
trong, cộng thêm 1 vào giá trị đó. Nếu không có giá trị bên trong, hàm sẽ trả về
giá trị None và không cố gắng thực hiện bất kỳ thao tác nào.
Hàm này rất dễ viết, nhờ match, và sẽ trông giống như Listing 6-5.
fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
Hãy xem xét lần thực thi đầu tiên của plus_one chi tiết hơn. Khi chúng ta gọi
plus_one(five), biến x trong thân của plus_one sẽ có giá trị Some(5).
Sau đó, chúng ta so sánh giá trị đó với từng nhánh match:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Giá trị Some(5) không khớp với mẫu None, vì vậy chúng ta tiếp tục đến nhánh
tiếp theo:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Some(5) có khớp với Some(i) không? Có! Chúng ta có cùng một biến thể. i
gắn với giá trị được chứa trong Some, vì vậy i nhận giá trị 5. Sau đó, mã
trong nhánh match được thực thi, vì vậy chúng ta cộng 1 vào giá trị của i và
tạo ra một giá trị Some mới với tổng 6 bên trong.
Bây giờ hãy xem xét lần gọi thứ hai của plus_one trong Listing 6-5, trong đó
x là None. Chúng ta đi vào match và so sánh với nhánh đầu tiên:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Nó khớp! Không có giá trị để cộng thêm, vì vậy chương trình dừng lại và trả về
giá trị None ở phía bên phải của =>. Bởi vì nhánh đầu tiên đã khớp, không có
nhánh nào khác được so sánh.
Kết hợp match và enum rất hữu ích trong nhiều tình huống. Bạn sẽ thấy mẫu này
rất nhiều trong mã Rust: match đối với một enum, gắn một biến với dữ liệu bên
trong, và sau đó thực thi mã dựa trên nó. Ban đầu có thể hơi khó hiểu, nhưng một
khi bạn đã quen với nó, bạn sẽ ước rằng mọi ngôn ngữ đều có nó. Nó luôn là một
tính năng yêu thích của người dùng.
Các Match Đều Phải Đầy đủ
Có một khía cạnh khác của match mà chúng ta cần thảo luận: các mẫu của nhánh
phải bao gồm tất cả các khả năng. Hãy xem xét phiên bản này của hàm plus_one
của chúng ta, có một lỗi và sẽ không biên dịch được:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Chúng ta không xử lý trường hợp None, vì vậy mã này sẽ gây ra lỗi. May mắn
thay, đây là một lỗi mà Rust biết cách phát hiện. Nếu chúng ta cố gắng biên dịch
mã này, chúng ta sẽ nhận được lỗi này:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust biết rằng chúng ta không bao gồm mọi trường hợp có thể xảy ra, và thậm chí
còn biết mẫu nào chúng ta đã quên! Các match trong Rust là đầy đủ: chúng ta
phải liệt kê tất cả các khả năng để mã hợp lệ. Đặc biệt là trong trường hợp
Option<T>, khi Rust ngăn chúng ta quên xử lý rõ ràng trường hợp None, nó bảo
vệ chúng ta khỏi việc giả định rằng chúng ta có một giá trị khi chúng ta có thể
có null, từ đó làm cho lỗi hàng tỷ đô la đã thảo luận trước đó trở nên không
thể.
Mẫu Bắt tất cả và Placeholder _
Sử dụng enum, chúng ta cũng có thể thực hiện các hành động đặc biệt cho một số
giá trị cụ thể, nhưng đối với tất cả các giá trị khác, thực hiện một hành động
mặc định. Hãy tưởng tượng chúng ta đang triển khai một trò chơi, trong đó, nếu
bạn tung được số 3 trên xúc xắc, người chơi của bạn không di chuyển, mà thay vào
đó nhận được một chiếc mũ đẹp mới. Nếu bạn tung được số 7, người chơi của bạn
mất một chiếc mũ đẹp. Đối với tất cả các giá trị khác, người chơi của bạn di
chuyển số ô đó trên bàn chơi. Dưới đây là một match triển khai logic đó, với
kết quả của việc tung xúc xắc được cố định thay vì một giá trị ngẫu nhiên, và
tất cả logic khác được biểu diễn bằng các hàm không có nội dung vì việc triển
khai chúng nằm ngoài phạm vi của ví dụ này:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), other => move_player(other), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn move_player(num_spaces: u8) {} }
Đối với hai nhánh đầu tiên, các mẫu là các giá trị văn bản 3 và 7. Đối với
nhánh cuối cùng bao gồm mọi giá trị có thể khác, mẫu là biến mà chúng ta đã chọn
đặt tên là other. Mã chạy cho nhánh other sử dụng biến bằng cách truyền nó
vào hàm move_player.
Mã này biên dịch được, mặc dù chúng ta chưa liệt kê tất cả các giá trị có thể có
của một u8, bởi vì mẫu cuối cùng sẽ khớp với tất cả các giá trị không được
liệt kê cụ thể. Mẫu bắt tất cả này đáp ứng yêu cầu rằng match phải đầy đủ. Lưu
ý rằng chúng ta phải đặt nhánh bắt tất cả cuối cùng vì các mẫu được đánh giá
theo thứ tự. Nếu chúng ta đặt nhánh bắt tất cả sớm hơn, các nhánh khác sẽ không
bao giờ chạy, vì vậy Rust sẽ cảnh báo chúng ta nếu chúng ta thêm nhánh sau một
nhánh bắt tất cả!
Rust cũng có một mẫu mà chúng ta có thể sử dụng khi muốn bắt tất cả nhưng không
muốn sử dụng giá trị trong mẫu bắt tất cả: _ là một mẫu đặc biệt khớp với
bất kỳ giá trị nào và không gắn với giá trị đó. Điều này nói với Rust rằng chúng
ta sẽ không sử dụng giá trị, vì vậy Rust sẽ không cảnh báo chúng ta về một biến
không được sử dụng.
Hãy thay đổi luật của trò chơi: bây giờ, nếu bạn tung bất kỳ số nào khác ngoài 3
hoặc 7, bạn phải tung lại. Chúng ta không còn cần sử dụng giá trị bắt tất cả
nữa, vì vậy chúng ta có thể thay đổi mã của mình để sử dụng _ thay vì biến có
tên other:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => reroll(), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn reroll() {} }
Ví dụ này cũng đáp ứng yêu cầu đầy đủ vì chúng ta đang rõ ràng bỏ qua tất cả các giá trị khác trong nhánh cuối cùng; chúng ta không quên bất cứ điều gì.
Cuối cùng, chúng ta sẽ thay đổi luật của trò chơi một lần nữa để không có gì
khác xảy ra trong lượt của bạn nếu bạn tung bất kỳ số nào khác ngoài 3 hoặc 7.
Chúng ta có thể biểu đạt điều đó bằng cách sử dụng giá trị đơn vị (kiểu tuple
rỗng mà chúng ta đã đề cập trong phần "Kiểu Tuple") làm
mã đi kèm với nhánh _:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => (), } fn add_fancy_hat() {} fn remove_fancy_hat() {} }
Ở đây, chúng ta đang nói với Rust một cách rõ ràng rằng chúng ta sẽ không sử dụng bất kỳ giá trị nào khác không khớp với mẫu trong một nhánh trước đó, và chúng ta không muốn chạy bất kỳ mã nào trong trường hợp này.
Còn nhiều điều về mẫu và khớp mà chúng ta sẽ đề cập trong Chương
19. Hiện tại, chúng ta sẽ tiếp tục với cú pháp
if let, có thể hữu ích trong các tình huống mà biểu thức match hơi dài dòng.
Điều khiển Luồng Ngắn Gọn với if let và let...else
Cú pháp if let cho phép bạn kết hợp if và let thành một cách ít dài dòng
hơn để xử lý các giá trị khớp với một mẫu trong khi bỏ qua phần còn lại. Hãy xem
xét chương trình trong Listing 6-6 khớp với một giá trị Option<u8> trong biến
config_max nhưng chỉ muốn thực thi mã nếu giá trị là biến thể Some.
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("The maximum is configured to be {max}"), _ => (), } }
Nếu giá trị là Some, chúng ta in ra giá trị trong biến thể Some bằng cách
gắn giá trị với biến max trong mẫu. Chúng ta không muốn làm gì với giá trị
None. Để thỏa mãn biểu thức match, chúng ta phải thêm _ => () sau khi xử
lý chỉ một biến thể, đó là mã mẫu khó chịu cần thêm.
Thay vào đó, chúng ta có thể viết điều này ngắn gọn hơn bằng cách sử dụng
if let. Đoạn mã sau hoạt động giống như match trong Listing 6-6:
fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("The maximum is configured to be {max}"); } }
Cú pháp if let lấy một mẫu và một biểu thức được phân tách bằng dấu bằng. Nó
hoạt động giống cách như match, trong đó biểu thức được đưa vào match và mẫu
là nhánh đầu tiên của nó. Trong trường hợp này, mẫu là Some(max), và max gắn
với giá trị bên trong Some. Sau đó, chúng ta có thể sử dụng max trong phần
thân của khối if let tương tự như cách chúng ta sử dụng max trong nhánh
match tương ứng. Mã trong khối if let chỉ chạy nếu giá trị khớp với mẫu.
Sử dụng if let có nghĩa là ít phải gõ hơn, ít thụt đầu dòng, và ít mã mẫu. Tuy
nhiên, bạn mất đi kiểm tra tính đầy đủ mà match bắt buộc để đảm bảo bạn không
quên xử lý bất kỳ trường hợp nào. Việc lựa chọn giữa match và if let phụ
thuộc vào những gì bạn đang làm trong tình huống cụ thể và liệu việc đạt được sự
ngắn gọn có phải là một sự đánh đổi phù hợp cho việc mất đi kiểm tra tính đầy đủ
hay không.
Nói cách khác, bạn có thể coi if let như là cú pháp đường tắt cho match mà
chạy mã khi giá trị khớp với một mẫu và sau đó bỏ qua tất cả các giá trị khác.
Chúng ta có thể bao gồm một else với if let. Khối mã đi kèm với else giống
như khối mã sẽ đi kèm với trường hợp _ trong biểu thức match tương đương với
if let và else. Nhớ lại định nghĩa enum Coin trong Listing 6-4, trong đó
biến thể Quarter cũng chứa một giá trị UsState. Nếu chúng ta muốn đếm tất cả
các đồng xu không phải quarter mà chúng ta thấy đồng thời thông báo về tiểu bang
của các quarter, chúng ta có thể làm điều đó với biểu thức match, như thế này:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; match coin { Coin::Quarter(state) => println!("State quarter from {state:?}!"), _ => count += 1, } }
Hoặc chúng ta có thể sử dụng biểu thức if let và else, như thế này:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; if let Coin::Quarter(state) = coin { println!("State quarter from {state:?}!"); } else { count += 1; } }
Duy trì trên "Đường Hạnh phúc" với let...else
Mẫu phổ biến là thực hiện một số tính toán khi một giá trị hiện diện và trả về
một giá trị mặc định nếu không. Tiếp tục với ví dụ của chúng ta về tiền xu với
một giá trị UsState, nếu chúng ta muốn nói điều gì đó hài hước tùy thuộc vào
tuổi của tiểu bang trên đồng quarter, chúng ta có thể giới thiệu một phương thức
trên UsState để kiểm tra tuổi của một tiểu bang, như sau:
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { if let Coin::Quarter(state) = coin { if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } else { None } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
Sau đó, chúng ta có thể sử dụng if let để khớp với loại xu, giới thiệu một
biến state trong phần thân của điều kiện, như trong Listing 6-7.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { if let Coin::Quarter(state) = coin { if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } else { None } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
Điều đó hoàn thành công việc, nhưng nó đã đẩy công việc vào trong phần thân của
câu lệnh if let, và nếu công việc cần làm phức tạp hơn, có thể khó theo dõi
chính xác cách các nhánh cấp cao liên quan đến nhau. Chúng ta cũng có thể tận
dụng thực tế là các biểu thức tạo ra một giá trị hoặc để tạo ra state từ
if let hoặc để trả về sớm, như trong Listing 6-8. (Bạn cũng có thể làm tương
tự với match.)
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { let state = if let Coin::Quarter(state) = coin { state } else { return None; }; if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
Điều này cũng hơi khó theo dõi theo cách riêng của nó! Một nhánh của if let
tạo ra một giá trị, và nhánh kia trả về hoàn toàn từ hàm.
Để làm cho mẫu phổ biến này dễ diễn đạt hơn, Rust có let...else. Cú pháp
let...else lấy một mẫu ở phía bên trái và một biểu thức ở bên phải, rất giống
với if let, nhưng nó không có nhánh if, chỉ có nhánh else. Nếu mẫu khớp,
nó sẽ gắn giá trị từ mẫu trong phạm vi bên ngoài. Nếu mẫu không khớp, chương
trình sẽ chuyển vào nhánh else, phải trả về từ hàm.
Trong Listing 6-9, bạn có thể thấy Listing 6-8 trông như thế nào khi sử dụng
let...else thay cho if let.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { let Coin::Quarter(state) = coin else { return None; }; if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
Lưu ý rằng nó vẫn "trên đường hạnh phúc" trong phần thân chính của hàm theo cách
này, không có luồng điều khiển khác biệt đáng kể cho hai nhánh như if let đã
làm.
Nếu bạn có tình huống mà chương trình của bạn có logic quá dài dòng để diễn đạt
bằng match, hãy nhớ rằng if let và let...else cũng có trong bộ công cụ
Rust của bạn.
Tóm tắt
Bây giờ chúng ta đã đề cập đến cách sử dụng enum để tạo các kiểu tùy chỉnh có
thể là một trong một tập hợp các giá trị được liệt kê. Chúng ta đã thấy cách
kiểu Option<T> của thư viện tiêu chuẩn giúp bạn sử dụng hệ thống kiểu để ngăn
chặn lỗi. Khi các giá trị enum có dữ liệu bên trong, bạn có thể sử dụng match
hoặc if let để trích xuất và sử dụng các giá trị đó, tùy thuộc vào số lượng
trường hợp bạn cần xử lý.
Các chương trình Rust của bạn giờ đây có thể diễn đạt các khái niệm trong miền của bạn bằng cách sử dụng struct và enum. Việc tạo các kiểu tùy chỉnh để sử dụng trong API của bạn đảm bảo tính an toàn kiểu: trình biên dịch sẽ đảm bảo rằng các hàm của bạn chỉ nhận các giá trị thuộc kiểu mà mỗi hàm mong đợi.
Để cung cấp một API được tổ chức tốt cho người dùng của bạn, dễ dàng sử dụng và chỉ hiển thị chính xác những gì người dùng của bạn sẽ cần, bây giờ hãy chuyển sang các mô-đun của Rust.
Quản lý Dự án Ngày càng Lớn với Packages, Crates, và Modules
Khi bạn viết các chương trình lớn, việc tổ chức mã của bạn sẽ ngày càng trở nên quan trọng. Bằng cách nhóm các chức năng liên quan và tách riêng mã với các tính năng riêng biệt, bạn sẽ làm rõ nơi tìm mã thực hiện một tính năng cụ thể và nơi để thay đổi cách một tính năng hoạt động.
Các chương trình chúng ta đã viết cho đến nay đều nằm trong một module trong một tệp. Khi một dự án phát triển, bạn nên tổ chức mã bằng cách chia nó thành nhiều module và sau đó là nhiều tệp. Một package có thể chứa nhiều binary crate và tùy chọn một library crate. Khi một package phát triển, bạn có thể trích xuất các phần thành các crate riêng biệt trở thành các phụ thuộc bên ngoài. Chương này đề cập đến tất cả các kỹ thuật này. Đối với các dự án rất lớn bao gồm một tập hợp các package có liên quan phát triển cùng nhau, Cargo cung cấp workspaces, mà chúng ta sẽ đề cập trong "Cargo Workspaces" ở Chương 14.
Chúng ta cũng sẽ thảo luận về việc đóng gói chi tiết triển khai, điều này cho phép bạn tái sử dụng mã ở mức cao hơn: khi bạn đã triển khai một thao tác, mã khác có thể gọi mã của bạn thông qua giao diện công khai mà không cần biết cách triển khai hoạt động như thế nào. Cách bạn viết mã định nghĩa những phần nào là công khai cho mã khác sử dụng và những phần nào là chi tiết triển khai riêng tư mà bạn có quyền thay đổi. Đây là một cách khác để hạn chế lượng chi tiết mà bạn phải giữ trong đầu.
Một khái niệm liên quan là phạm vi: ngữ cảnh lồng nhau mà mã được viết có một tập hợp các tên được định nghĩa là "trong phạm vi." Khi đọc, viết và biên dịch mã, các lập trình viên và trình biên dịch cần biết liệu một tên cụ thể tại một vị trí cụ thể đề cập đến một biến, hàm, struct, enum, module, hằng số, hoặc mục khác và mục đó có ý nghĩa gì. Bạn có thể tạo phạm vi và thay đổi những tên nào đang ở trong hoặc ngoài phạm vi. Bạn không thể có hai mục với cùng một tên trong cùng một phạm vi; các công cụ có sẵn để giải quyết xung đột tên.
Rust có một số tính năng cho phép bạn quản lý tổ chức mã của mình, bao gồm những chi tiết nào được hiển thị, những chi tiết nào là riêng tư, và những tên nào nằm trong mỗi phạm vi trong chương trình của bạn. Những tính năng này, đôi khi được gọi chung là hệ thống module, bao gồm:
- Packages: Một tính năng của Cargo cho phép bạn xây dựng, kiểm tra và chia sẻ crates
- Crates: Một cây các module tạo ra một thư viện hoặc một tệp thực thi
- Modules và use: Cho phép bạn kiểm soát tổ chức, phạm vi và quyền riêng tư của các đường dẫn
- Paths: Một cách để đặt tên cho một mục, chẳng hạn như struct, hàm hoặc module
Trong chương này, chúng ta sẽ đề cập đến tất cả các tính năng này, thảo luận về cách chúng tương tác, và giải thích cách sử dụng chúng để quản lý phạm vi. Đến cuối chương, bạn sẽ có hiểu biết vững chắc về hệ thống module và có thể làm việc với các phạm vi như một chuyên gia!
Packages và Crates
Phần đầu tiên của hệ thống module mà chúng ta sẽ đề cập đến là packages và crates.
Một crate là đơn vị code nhỏ nhất mà trình biên dịch Rust xem xét tại một thời
điểm. Ngay cả khi bạn chạy rustc thay vì cargo và truyền vào một tệp mã
nguồn duy nhất (như chúng ta đã làm trong "Viết và Chạy Chương Trình Rust" ở
Chương 1), trình biên dịch xem tệp đó là một crate. Crates có thể chứa modules,
và các modules có thể được định nghĩa trong các tệp khác được biên dịch cùng với
crate, như chúng ta sẽ thấy trong các phần tiếp theo.
Một crate có thể có một trong hai hình thức: binary crate hoặc library crate.
Binary crates là các chương trình bạn có thể biên dịch thành một tệp thực thi
để chạy, như một chương trình dòng lệnh hoặc một máy chủ. Mỗi crate này phải có
một hàm gọi là main để xác định điều gì sẽ xảy ra khi chương trình thực thi
chạy. Tất cả các crate chúng ta đã tạo cho đến nay đều là binary crates.
Library crates không có hàm main, và chúng không được biên dịch thành tệp
thực thi. Thay vào đó, chúng định nghĩa các chức năng được thiết kế để chia sẻ
giữa nhiều dự án. Ví dụ, crate rand mà chúng ta đã sử dụng trong Chương
2 cung cấp chức năng tạo số ngẫu nhiên. Hầu hết thời gian
khi các lập trình viên Rust nói “crate,“ họ thường muốn nói đến library crate,
và họ sử dụng "crate" thay thế cho khái niệm lập trình chung là “library.“
Crate root là một tệp mã nguồn mà trình biên dịch Rust bắt đầu từ đó và tạo thành module gốc của crate của bạn (chúng ta sẽ giải thích kỹ về modules trong "Định nghĩa Modules để Kiểm soát Phạm vi và Quyền riêng tư").
Một package là một gói gồm một hoặc nhiều crates cung cấp một tập hợp chức năng. Một package chứa một tệp Cargo.toml mô tả cách xây dựng các crates đó. Cargo thực chất là một package chứa binary crate cho công cụ dòng lệnh mà bạn đã sử dụng để xây dựng mã của mình. Package Cargo cũng chứa một library crate mà binary crate phụ thuộc vào. Các dự án khác có thể phụ thuộc vào library crate Cargo để sử dụng logic tương tự như công cụ dòng lệnh Cargo sử dụng.
Một package có thể chứa nhiều binary crates tùy thích, nhưng nhiều nhất chỉ có một library crate. Một package phải chứa ít nhất một crate, dù đó là library hay binary crate.
Hãy đi qua những gì xảy ra khi chúng ta tạo một package. Đầu tiên, chúng ta nhập
lệnh cargo new my-project:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
Sau khi chúng ta chạy cargo new my-project, chúng ta sử dụng ls để xem những
gì Cargo tạo ra. Trong thư mục dự án, có một tệp Cargo.toml, tạo ra một
package. Có một thư mục src chứa main.rs. Mở Cargo.toml trong trình soạn
thảo của bạn và lưu ý rằng không có đề cập đến src/main.rs. Cargo tuân theo
quy ước rằng src/main.rs là crate root của một binary crate có cùng tên với
package. Tương tự, Cargo biết rằng nếu thư mục package chứa src/lib.rs, thì
package chứa một library crate có cùng tên với package, và src/lib.rs là crate
root. Cargo truyền các tệp crate root cho rustc để xây dựng thư viện hoặc
chương trình.
Ở đây, chúng ta có một package chỉ chứa src/main.rs, nghĩa là nó chỉ chứa một
binary crate có tên là my-project. Nếu một package chứa src/main.rs và
src/lib.rs, nó có hai crates: một binary và một library, cả hai đều có cùng
tên với package. Một package có thể có nhiều binary crates bằng cách đặt các tệp
trong thư mục src/bin: mỗi tệp sẽ là một binary crate riêng biệt.
Định nghĩa Modules để Kiểm soát Phạm vi và Quyền riêng tư
Trong phần này, chúng ta sẽ nói về modules và các phần khác của hệ thống module,
cụ thể là paths (đường dẫn), cho phép bạn đặt tên cho các item; từ khóa use
đưa một đường dẫn vào phạm vi; và từ khóa pub để công khai các item. Chúng ta
cũng sẽ thảo luận về từ khóa as, các gói bên ngoài, và toán tử glob.
Bảng tóm tắt về Modules
Trước khi đi vào chi tiết về modules và đường dẫn, ở đây chúng tôi cung cấp một
tài liệu tham khảo nhanh về cách modules, đường dẫn, từ khóa use và từ khóa
pub hoạt động trong trình biên dịch, và cách mà hầu hết các nhà phát triển tổ
chức mã của họ. Chúng ta sẽ đi qua các ví dụ cho từng quy tắc này trong suốt
chương này, nhưng đây là một nơi tuyệt vời để tham khảo như một lời nhắc về cách
modules hoạt động.
- Bắt đầu từ crate root: Khi biên dịch một crate, trình biên dịch đầu tiên tìm kiếm trong tệp crate root (thường là src/lib.rs cho library crate hoặc src/main.rs cho binary crate) để biên dịch mã.
- Khai báo modules: Trong tệp crate root, bạn có thể khai báo modules mới;
giả sử bạn khai báo một module "garden" với
mod garden;. Trình biên dịch sẽ tìm kiếm mã của module ở những nơi sau:- Trực tiếp, trong dấu ngoặc nhọn thay thế dấu chấm phẩy sau
mod garden - Trong tệp src/garden.rs
- Trong tệp src/garden/mod.rs
- Trực tiếp, trong dấu ngoặc nhọn thay thế dấu chấm phẩy sau
- Khai báo submodules: Trong bất kỳ tệp nào khác ngoài crate root, bạn có
thể khai báo submodules. Ví dụ, bạn có thể khai báo
mod vegetables;trong src/garden.rs. Trình biên dịch sẽ tìm kiếm mã của submodule trong thư mục có tên của module cha ở những nơi sau:- Trực tiếp, ngay sau
mod vegetables, trong dấu ngoặc nhọn thay vì dấu chấm phẩy - Trong tệp src/garden/vegetables.rs
- Trong tệp src/garden/vegetables/mod.rs
- Trực tiếp, ngay sau
- Đường dẫn đến mã trong modules: Khi một module là một phần của crate của
bạn, bạn có thể tham chiếu đến mã trong module đó từ bất kỳ nơi nào khác trong
cùng crate đó, miễn là các quy tắc quyền riêng tư cho phép, sử dụng đường dẫn
đến mã. Ví dụ, một kiểu
Asparagustrong module vegetables của garden sẽ được tìm thấy tạicrate::garden::vegetables::Asparagus. - Riêng tư vs. công khai: Mã trong một module mặc định là riêng tư từ các
module cha của nó. Để làm cho một module công khai, khai báo nó với
pub modthay vìmod. Để làm cho các item trong một module công khai cũng công khai, sử dụngpubtrước khai báo của chúng. - Từ khóa
use: Trong một phạm vi, từ khóausetạo ra các lối tắt đến các item để giảm lặp lại các đường dẫn dài. Trong bất kỳ phạm vi nào có thể tham chiếu đếncrate::garden::vegetables::Asparagus, bạn có thể tạo một lối tắt vớiuse crate::garden::vegetables::Asparagus;và từ đó trở đi bạn chỉ cần viếtAsparagusđể sử dụng kiểu đó trong phạm vi.
Ở đây, chúng ta tạo một binary crate có tên backyard minh họa các quy tắc này.
Thư mục của crate, cũng có tên là backyard, chứa các tệp và thư mục sau:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
Tệp crate root trong trường hợp này là src/main.rs, và nó chứa:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}Dòng pub mod garden; cho trình biên dịch biết để bao gồm mã mà nó tìm thấy
trong src/garden.rs, đó là:
pub mod vegetables;Ở đây, pub mod vegetables; có nghĩa là mã trong src/garden/vegetables.rs
cũng được bao gồm. Mã đó là:
#[derive(Debug)]
pub struct Asparagus {}Bây giờ chúng ta hãy đi vào chi tiết của các quy tắc này và minh họa chúng trong hành động!
Nhóm Mã Liên quan trong Modules
Modules cho phép chúng ta tổ chức mã trong một crate để dễ đọc và tái sử dụng. Modules cũng cho phép chúng ta kiểm soát quyền riêng tư của các item vì mã trong một module mặc định là riêng tư. Các item riêng tư là chi tiết triển khai nội bộ không có sẵn cho việc sử dụng bên ngoài. Chúng ta có thể chọn làm cho các modules và các item bên trong chúng công khai, điều này làm cho chúng hiện ra để cho phép mã bên ngoài sử dụng và phụ thuộc vào chúng.
Làm ví dụ, chúng ta hãy viết một library crate cung cấp chức năng của một nhà hàng. Chúng ta sẽ định nghĩa các chữ ký của các hàm nhưng để phần thân của chúng trống để tập trung vào việc tổ chức mã hơn là triển khai của một nhà hàng.
Trong ngành công nghiệp nhà hàng, một số phần của nhà hàng được gọi là front of house (tiền sảnh) và những phần khác là back of house (hậu trường). Front of house là nơi khách hàng đến; điều này bao gồm nơi các chủ nhà đón tiếp khách hàng, nhân viên phục vụ ghi nhận đơn hàng và thanh toán, và người pha chế pha đồ uống. Back of house là nơi các đầu bếp và người nấu ăn làm việc trong nhà bếp, người rửa bát dọn dẹp, và người quản lý làm công việc hành chính.
Để cấu trúc crate của chúng ta theo cách này, chúng ta có thể tổ chức các hàm
của nó thành các modules lồng nhau. Tạo một thư viện mới có tên restaurant
bằng cách chạy cargo new restaurant --lib. Sau đó nhập mã trong Listing 7-1
vào src/lib.rs để định nghĩa một số modules và chữ ký hàm; mã này là phần
front of house.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}Chúng ta định nghĩa một module với từ khóa mod theo sau là tên của module
(trong trường hợp này, front_of_house). Phần thân của module sau đó đi vào
trong dấu ngoặc nhọn. Bên trong modules, chúng ta có thể đặt các module khác,
như trong trường hợp này với các module hosting và serving. Modules cũng có
thể chứa các định nghĩa cho các item khác, như structs, enums, constants,
traits, và như trong Listing 7-1, các hàm.
Bằng cách sử dụng modules, chúng ta có thể nhóm các định nghĩa liên quan với nhau và đặt tên tại sao chúng liên quan. Các lập trình viên sử dụng mã này có thể điều hướng mã dựa trên các nhóm thay vì phải đọc qua tất cả các định nghĩa, làm cho việc tìm kiếm các định nghĩa liên quan đến họ trở nên dễ dàng hơn. Các lập trình viên thêm chức năng mới vào mã này sẽ biết nơi để đặt mã để giữ cho chương trình được tổ chức.
Trước đây, chúng ta đã đề cập rằng src/main.rs và src/lib.rs được gọi là
crate roots. Lý do cho tên của chúng là vì nội dung của một trong hai tệp này
tạo thành một module có tên crate ở gốc của cấu trúc module của crate, được
gọi là cây module.
Listing 7-2 hiển thị cây module cho cấu trúc trong Listing 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
Cây này cho thấy cách một số modules lồng bên trong các module khác; ví dụ,
hosting lồng bên trong front_of_house. Cây cũng cho thấy rằng một số modules
là siblings (anh chị em), có nghĩa là chúng được định nghĩa trong cùng một
module; hosting và serving là anh chị em được định nghĩa trong
front_of_house. Nếu module A được chứa bên trong module B, chúng ta nói rằng
module A là con của module B và module B là cha của module A. Lưu ý rằng
toàn bộ cây module được gốc dưới module ẩn có tên crate.
Cây module có thể nhắc bạn nhớ đến cây thư mục của hệ thống tệp trên máy tính của bạn; đây là một so sánh rất đúng! Giống như các thư mục trong hệ thống tệp, bạn sử dụng modules để tổ chức mã của mình. Và giống như các tệp trong một thư mục, chúng ta cần một cách để tìm thấy các module của mình.
Đường dẫn để Tham chiếu đến một Item trong Cây Module
Để chỉ cho Rust vị trí một item trong cây module, chúng ta sử dụng một đường dẫn tương tự như cách chúng ta sử dụng đường dẫn khi điều hướng trong hệ thống tệp. Để gọi một hàm, chúng ta cần biết đường dẫn của nó.
Một đường dẫn có thể có hai hình thức:
- Một đường dẫn tuyệt đối là đường dẫn đầy đủ bắt đầu từ gốc của crate; đối
với mã từ một crate bên ngoài, đường dẫn tuyệt đối bắt đầu bằng tên crate, và
đối với mã từ crate hiện tại, nó bắt đầu bằng từ khóa
crate. - Một đường dẫn tương đối bắt đầu từ module hiện tại và sử dụng
self,super, hoặc một định danh trong module hiện tại.
Cả đường dẫn tuyệt đối và tương đối đều được theo sau bởi một hoặc nhiều định
danh được phân tách bởi dấu hai chấm kép (::).
Quay lại Listing 7-1, giả sử chúng ta muốn gọi hàm add_to_waitlist. Điều này
cũng giống như việc hỏi: đâu là đường dẫn của hàm add_to_waitlist? Listing 7-3
chứa nội dung của Listing 7-1 nhưng đã loại bỏ một số modules và hàm.
Chúng ta sẽ thể hiện hai cách để gọi hàm add_to_waitlist từ một hàm mới,
eat_at_restaurant, được định nghĩa trong gốc của crate. Các đường dẫn này là
đúng, nhưng vẫn còn một vấn đề khác sẽ ngăn ví dụ này biên dịch như hiện tại.
Chúng ta sẽ giải thích lý do sau.
Hàm eat_at_restaurant là một phần của API công khai của thư viện crate của
chúng ta, vì vậy chúng ta đánh dấu nó bằng từ khóa pub. Trong phần "Hiển thị
Đường dẫn với từ khóa pub", chúng ta sẽ đi sâu hơn về
pub.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Lần đầu tiên chúng ta gọi hàm add_to_waitlist trong eat_at_restaurant, chúng
ta sử dụng đường dẫn tuyệt đối. Hàm add_to_waitlist được định nghĩa trong cùng
crate với eat_at_restaurant, điều đó có nghĩa là chúng ta có thể sử dụng từ
khóa crate để bắt đầu một đường dẫn tuyệt đối. Sau đó, chúng ta bao gồm từng
module liên tiếp cho đến khi chúng ta đến được add_to_waitlist. Bạn có thể
tưởng tượng một hệ thống tệp với cùng cấu trúc: chúng ta sẽ chỉ định đường dẫn
/front_of_house/hosting/add_to_waitlist để chạy chương trình
add_to_waitlist; việc sử dụng tên crate để bắt đầu từ gốc của crate giống
như việc sử dụng / để bắt đầu từ gốc hệ thống tệp trong shell của bạn.
Lần thứ hai chúng ta gọi add_to_waitlist trong eat_at_restaurant, chúng ta
sử dụng một đường dẫn tương đối. Đường dẫn bắt đầu với front_of_house, tên của
module được định nghĩa ở cùng cấp độ của cây module với eat_at_restaurant. Ở
đây, tương đương với hệ thống tệp sẽ là sử dụng đường dẫn
front_of_house/hosting/add_to_waitlist. Việc bắt đầu bằng tên module có nghĩa
là đường dẫn là tương đối.
Việc chọn sử dụng đường dẫn tương đối hay tuyệt đối là một quyết định bạn sẽ đưa
ra dựa trên dự án của mình, và nó phụ thuộc vào việc bạn có nhiều khả năng di
chuyển mã định nghĩa item riêng biệt hay cùng với mã sử dụng item đó. Ví dụ, nếu
chúng ta di chuyển module front_of_house và hàm eat_at_restaurant vào một
module có tên customer_experience, chúng ta sẽ cần cập nhật đường dẫn tuyệt
đối đến add_to_waitlist, nhưng đường dẫn tương đối vẫn sẽ hợp lệ. Tuy nhiên,
nếu chúng ta di chuyển riêng hàm eat_at_restaurant vào một module có tên
dining, đường dẫn tuyệt đối đến lệnh gọi add_to_waitlist sẽ giữ nguyên,
nhưng đường dẫn tương đối sẽ cần được cập nhật. Ưu tiên chung của chúng ta là
chỉ định đường dẫn tuyệt đối vì có khả năng cao hơn là chúng ta sẽ muốn di
chuyển các định nghĩa mã và lệnh gọi các item độc lập với nhau.
Hãy thử biên dịch Listing 7-3 và tìm hiểu tại sao nó chưa thể biên dịch! Các lỗi mà chúng ta nhận được được hiển thị trong Listing 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Các thông báo lỗi nói rằng module hosting là riêng tư. Nói cách khác, chúng ta
có các đường dẫn đúng cho module hosting và hàm add_to_waitlist, nhưng Rust
không cho phép chúng ta sử dụng chúng vì nó không có quyền truy cập vào các phần
riêng tư. Trong Rust, tất cả các item (hàm, phương thức, cấu trúc, enums,
modules, và hằng số) mặc định là riêng tư đối với các module cha. Nếu bạn muốn
làm cho một item như một hàm hoặc cấu trúc riêng tư, bạn đặt nó trong một
module.
Các item trong một module cha không thể sử dụng các item riêng tư bên trong các module con, nhưng các item trong các module con có thể sử dụng các item trong module tổ tiên của chúng. Điều này là vì các module con bọc và ẩn chi tiết triển khai của chúng, nhưng các module con có thể thấy bối cảnh mà chúng được định nghĩa. Để tiếp tục với ẩn dụ của chúng ta, hãy nghĩ về các quy tắc quyền riêng tư giống như văn phòng phía sau của một nhà hàng: những gì diễn ra ở đó là riêng tư đối với khách hàng nhà hàng, nhưng các quản lý văn phòng có thể thấy và làm mọi thứ trong nhà hàng mà họ điều hành.
Rust đã chọn để hệ thống module hoạt động theo cách này để việc ẩn các chi tiết
triển khai bên trong là mặc định. Bằng cách đó, bạn biết những phần nào của mã
bên trong mà bạn có thể thay đổi mà không làm hỏng mã bên ngoài. Tuy nhiên, Rust
có cung cấp cho bạn tùy chọn để hiển thị các phần bên trong của mã module con
cho các module tổ tiên bên ngoài bằng cách sử dụng từ khóa pub để làm một item
công khai.
Hiển thị Đường dẫn với từ khóa pub
Hãy quay lại lỗi trong Listing 7-4 đã nói với chúng ta rằng module hosting là
riêng tư. Chúng ta muốn hàm eat_at_restaurant trong module cha có quyền truy
cập vào hàm add_to_waitlist trong module con, vì vậy chúng ta đánh dấu module
hosting bằng từ khóa pub, như được hiển thị trong Listing 7-5.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Thật không may, mã trong Listing 7-5 vẫn dẫn đến lỗi trình biên dịch, như được hiển thị trong Listing 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Chuyện gì đã xảy ra? Thêm từ khóa pub trước mod hosting làm cho module công
khai. Với thay đổi này, nếu chúng ta có thể truy cập front_of_house, chúng ta
có thể truy cập hosting. Nhưng nội dung của hosting vẫn là riêng tư; việc
làm cho module công khai không làm cho nội dung của nó công khai. Từ khóa pub
trên một module chỉ cho phép mã trong các module tổ tiên của nó tham chiếu đến
nó, không phải truy cập vào mã bên trong của nó. Bởi vì các module là vùng chứa,
không có nhiều điều chúng ta có thể làm chỉ bằng cách làm cho module công khai;
chúng ta cần đi xa hơn và chọn làm cho một hoặc nhiều item trong module công
khai.
Các lỗi trong Listing 7-6 nói rằng hàm add_to_waitlist là riêng tư. Các quy
tắc quyền riêng tư áp dụng cho các cấu trúc, enums, hàm, và phương thức cũng như
các module.
Hãy cũng làm cho hàm add_to_waitlist công khai bằng cách thêm từ khóa pub
trước định nghĩa của nó, như trong Listing 7-7.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Bây giờ mã sẽ biên dịch! Để hiểu tại sao việc thêm từ khóa pub cho phép chúng
ta sử dụng các đường dẫn này trong eat_at_restaurant liên quan đến các quy tắc
quyền riêng tư, hãy xem đường dẫn tuyệt đối và tương đối.
Trong đường dẫn tuyệt đối, chúng ta bắt đầu với crate, gốc của cây module của
crate. Module front_of_house được định nghĩa trong gốc của crate. Mặc dù
front_of_house không công khai, vì hàm eat_at_restaurant được định nghĩa
trong cùng module với front_of_house (nghĩa là, eat_at_restaurant và
front_of_house là anh chị em), chúng ta có thể tham chiếu đến front_of_house
từ eat_at_restaurant. Tiếp theo là module hosting được đánh dấu là pub.
Chúng ta có thể truy cập module cha của hosting, nên chúng ta có thể truy cập
hosting. Cuối cùng, hàm add_to_waitlist được đánh dấu là pub và chúng ta
có thể truy cập module cha của nó, vì vậy lệnh gọi hàm này hoạt động!
Trong đường dẫn tương đối, logic giống với đường dẫn tuyệt đối ngoại trừ bước
đầu tiên: thay vì bắt đầu từ gốc của crate, đường dẫn bắt đầu từ
front_of_house. Module front_of_house được định nghĩa trong cùng module với
eat_at_restaurant, nên đường dẫn tương đối bắt đầu từ module mà
eat_at_restaurant được định nghĩa hoạt động. Sau đó, vì hosting và
add_to_waitlist được đánh dấu là pub, phần còn lại của đường dẫn hoạt động,
và lệnh gọi hàm này hợp lệ!
Nếu bạn có kế hoạch chia sẻ crate thư viện của mình để các dự án khác có thể sử dụng mã của bạn, API công khai của bạn là hợp đồng của bạn với người dùng của crate xác định cách họ có thể tương tác với mã của bạn. Có nhiều cân nhắc xung quanh việc quản lý thay đổi đối với API công khai của bạn để giúp mọi người dễ dàng hơn khi phụ thuộc vào crate của bạn. Những cân nhắc này nằm ngoài phạm vi của cuốn sách này; nếu bạn quan tâm đến chủ đề này, hãy xem Các Hướng dẫn API của Rust.
Các Phương pháp Tốt nhất cho Packages với Binary và Library
Chúng ta đã đề cập rằng một package có thể chứa cả gốc của binary crate src/main.rs cũng như gốc của library crate src/lib.rs, và cả hai crates sẽ có tên package theo mặc định. Thông thường, các package với mô hình này chứa cả library và binary crate sẽ có đủ lượng mã trong binary crate để khởi động một chương trình thực thi gọi mã được khai báo trong library crate. Điều này cho phép các dự án khác hưởng lợi từ hầu hết chức năng mà package cung cấp vì mã của library crate có thể được chia sẻ.
Cây module nên được định nghĩa trong src/lib.rs. Sau đó, bất kỳ item công khai nào có thể được sử dụng trong binary crate bằng cách bắt đầu đường dẫn với tên của package. Binary crate trở thành người dùng của library crate giống như một crate bên ngoài hoàn toàn sẽ sử dụng library crate: nó chỉ có thể sử dụng API công khai. Điều này giúp bạn thiết kế một API tốt; không chỉ là bạn là tác giả, bạn cũng là khách hàng!
Trong Chương 12, chúng ta sẽ minh họa phương pháp tổ chức này với một chương trình dòng lệnh sẽ chứa cả binary crate và library crate.
Bắt đầu Đường dẫn Tương đối với super
Chúng ta có thể xây dựng đường dẫn tương đối bắt đầu ở module cha, thay vì
module hiện tại hoặc gốc của crate, bằng cách sử dụng super ở đầu đường dẫn.
Điều này giống như việc bắt đầu một đường dẫn hệ thống tệp với cú pháp .. có
nghĩa là đi đến thư mục cha. Sử dụng super cho phép chúng ta tham chiếu đến
một item mà chúng ta biết là trong module cha, điều này có thể làm cho việc sắp
xếp lại cây module dễ dàng hơn khi module có liên quan chặt chẽ với module cha
nhưng module cha có thể được di chuyển đến nơi khác trong cây module vào một
ngày nào đó.
Hãy xem xét mã trong Listing 7-8 mô hình hóa tình huống mà một đầu bếp sửa một
đơn hàng không chính xác và tự mang ra cho khách hàng. Hàm fix_incorrect_order
được định nghĩa trong module back_of_house gọi hàm deliver_order được định
nghĩa trong module cha bằng cách chỉ định đường dẫn đến deliver_order, bắt đầu
với super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}Hàm fix_incorrect_order nằm trong module back_of_house, nên chúng ta có thể
sử dụng super để đi đến module cha của back_of_house, trong trường hợp này
là crate, gốc. Từ đó, chúng ta tìm kiếm deliver_order và tìm thấy nó. Thành
công! Chúng ta nghĩ rằng module back_of_house và hàm deliver_order có khả
năng sẽ giữ nguyên mối quan hệ với nhau và được di chuyển cùng nhau nếu chúng ta
quyết định tổ chức lại cây module của crate. Do đó, chúng ta đã sử dụng super
để chúng ta sẽ có ít nơi hơn để cập nhật mã trong tương lai nếu mã này được di
chuyển đến một module khác.
Làm cho Structs và Enums Công khai
Chúng ta cũng có thể sử dụng pub để chỉ định structs và enums là công khai,
nhưng có một vài chi tiết bổ sung đối với việc sử dụng pub với structs và
enums. Nếu chúng ta sử dụng pub trước định nghĩa struct, chúng ta làm cho
struct công khai, nhưng các trường của struct vẫn sẽ là riêng tư. Chúng ta có
thể làm cho từng trường công khai hoặc không tùy theo từng trường hợp. Trong
Listing 7-9, chúng ta đã định nghĩa một struct back_of_house::Breakfast công
khai với một trường toast công khai nhưng một trường seasonal_fruit riêng
tư. Điều này mô hình hóa trường hợp trong một nhà hàng mà khách hàng có thể chọn
loại bánh mì đi kèm với bữa ăn, nhưng đầu bếp quyết định loại trái cây đi kèm
với bữa ăn dựa trên mùa nào và có sẵn trong kho. Loại trái cây có sẵn thay đổi
nhanh chóng, vì vậy khách hàng không thể chọn trái cây hoặc thậm chí không thể
thấy họ sẽ nhận được loại trái cây nào.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}Bởi vì trường toast trong struct back_of_house::Breakfast là công khai,
trong eat_at_restaurant chúng ta có thể viết và đọc trường toast bằng cách
sử dụng ký hiệu dấu chấm. Lưu ý rằng chúng ta không thể sử dụng trường
seasonal_fruit trong eat_at_restaurant, bởi vì seasonal_fruit là riêng tư.
Hãy thử bỏ comment dòng sửa đổi giá trị trường seasonal_fruit để xem lỗi bạn
nhận được!
Cũng lưu ý rằng bởi vì back_of_house::Breakfast có một trường riêng tư, struct
cần cung cấp một hàm liên kết công khai để xây dựng một thể hiện của Breakfast
(chúng ta đã đặt tên nó là summer ở đây). Nếu Breakfast không có một hàm như
vậy, chúng ta không thể tạo một thể hiện của Breakfast trong
eat_at_restaurant bởi vì chúng ta không thể đặt giá trị của trường riêng tư
seasonal_fruit trong eat_at_restaurant.
Ngược lại, nếu chúng ta làm cho một enum công khai, tất cả các biến thể của nó
đều công khai. Chúng ta chỉ cần từ khóa pub trước từ khóa enum, như được
hiển thị trong Listing 7-10.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}Vì chúng ta đã làm cho enum Appetizer công khai, chúng ta có thể sử dụng các
biến thể Soup và Salad trong eat_at_restaurant.
Enums không hữu ích lắm trừ khi các biến thể của chúng là công khai; sẽ rất
phiền toái khi phải chú thích tất cả các biến thể enum với pub trong mọi
trường hợp, vì vậy mặc định cho các biến thể enum là công khai. Structs thường
hữu ích mà không cần các trường của chúng là công khai, vì vậy các trường struct
tuân theo quy tắc chung là mọi thứ mặc định là riêng tư trừ khi được chú thích
với pub.
Có một tình huống khác liên quan đến pub mà chúng ta chưa đề cập, và đó là
tính năng hệ thống module cuối cùng của chúng ta: từ khóa use. Chúng ta sẽ đề
cập đến use riêng lẻ trước, và sau đó chúng ta sẽ thể hiện cách kết hợp pub
và use.
Đưa Đường dẫn vào Phạm vi với từ khóa use
Việc phải viết ra các đường dẫn để gọi hàm có thể cảm thấy bất tiện và lặp đi
lặp lại. Trong Listing 7-7, cho dù chúng ta chọn đường dẫn tuyệt đối hoặc tương
đối đến hàm add_to_waitlist, mỗi khi chúng ta muốn gọi add_to_waitlist chúng
ta phải chỉ định cả front_of_house và hosting. May mắn thay, có một cách để
đơn giản hóa quá trình này: chúng ta có thể tạo một lối tắt đến đường dẫn với từ
khóa use một lần, và sau đó sử dụng tên ngắn hơn ở mọi nơi khác trong phạm vi.
Trong Listing 7-11, chúng ta đưa module crate::front_of_house::hosting vào
phạm vi của hàm eat_at_restaurant để chúng ta chỉ cần chỉ định
hosting::add_to_waitlist để gọi hàm add_to_waitlist trong
eat_at_restaurant.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Việc thêm use và một đường dẫn trong một phạm vi tương tự như việc tạo một
liên kết tượng trưng trong hệ thống tệp. Bằng cách thêm
use crate::front_of_house::hosting trong gốc crate, hosting bây giờ là một
tên hợp lệ trong phạm vi đó, giống như thể module hosting đã được định nghĩa
trong gốc crate. Đường dẫn được đưa vào phạm vi bằng use cũng kiểm tra quyền
riêng tư, giống như bất kỳ đường dẫn nào khác.
Lưu ý rằng use chỉ tạo lối tắt cho phạm vi cụ thể mà use xảy ra. Listing
7-12 di chuyển hàm eat_at_restaurant vào một module con mới có tên là
customer, sau đó là một phạm vi khác với câu lệnh use, vì vậy phần thân hàm
sẽ không biên dịch được.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}Lỗi trình biên dịch cho thấy lối tắt không còn áp dụng trong module customer:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of unresolved module or unlinked crate `hosting`
|
= help: if you wanted to use a crate named `hosting`, use `cargo add hosting` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Lưu ý cũng có một cảnh báo rằng use không còn được sử dụng trong phạm vi của
nó! Để khắc phục vấn đề này, hãy di chuyển use vào module customer, hoặc
tham chiếu lối tắt trong module cha với super::hosting trong module con
customer.
Tạo Đường dẫn use Thuần phong
Trong Listing 7-11, bạn có thể đã tự hỏi tại sao chúng ta chỉ định
use crate::front_of_house::hosting và sau đó gọi hosting::add_to_waitlist
trong eat_at_restaurant, thay vì chỉ định đường dẫn use hoàn toàn đến hàm
add_to_waitlist để đạt được kết quả tương tự, như trong Listing 7-13.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}Mặc dù cả Listing 7-11 và Listing 7-13 đều thực hiện cùng một nhiệm vụ, Listing
7-11 là cách thuần phong để đưa một hàm vào phạm vi với use. Việc đưa module
cha của hàm vào phạm vi với use có nghĩa là chúng ta phải chỉ định module cha
khi gọi hàm. Chỉ định module cha khi gọi hàm làm rõ rằng hàm không được định
nghĩa cục bộ trong khi vẫn giảm thiểu việc lặp lại đường dẫn đầy đủ. Đoạn mã
trong Listing 7-13 không rõ ràng về nơi add_to_waitlist được định nghĩa.
Mặt khác, khi đưa vào structs, enums, và các item khác với use, việc chỉ định
đường dẫn đầy đủ là thuần phong. Listing 7-14 thể hiện cách thuần phong để đưa
struct HashMap của thư viện chuẩn vào phạm vi của một binary crate.
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
Không có lý do mạnh mẽ đằng sau cách viết này: đó chỉ là quy ước đã nổi lên, và mọi người đã quen với việc đọc và viết mã Rust theo cách này.
Ngoại lệ cho cách viết này là nếu chúng ta đưa hai item có cùng tên vào phạm vi
với các câu lệnh use, vì Rust không cho phép điều đó. Listing 7-15 thể hiện
cách đưa hai kiểu Result vào phạm vi có cùng tên nhưng có module cha khác
nhau, và cách tham chiếu đến chúng.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}Như bạn có thể thấy, việc sử dụng các module cha phân biệt hai kiểu Result.
Nếu thay vào đó chúng ta chỉ định use std::fmt::Result và
use std::io::Result, chúng ta sẽ có hai kiểu Result trong cùng một phạm vi,
và Rust sẽ không biết chúng ta muốn nói đến kiểu nào khi chúng ta sử dụng
Result.
Cung cấp Tên Mới với từ khóa as
Có một giải pháp khác cho vấn đề đưa hai kiểu có cùng tên vào cùng một phạm vi
với use: sau đường dẫn, chúng ta có thể chỉ định as và một tên cục bộ mới,
hoặc alias (biệt danh), cho kiểu đó. Listing 7-16 thể hiện một cách khác để
viết mã trong Listing 7-15 bằng cách đổi tên một trong hai kiểu Result sử dụng
as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}Trong câu lệnh use thứ hai, chúng ta đã chọn tên mới IoResult cho kiểu
std::io::Result, điều này sẽ không xung đột với Result từ std::fmt mà
chúng ta cũng đã đưa vào phạm vi. Listing 7-15 và Listing 7-16 đều được coi là
thuần phong, vì vậy sự lựa chọn là ở bạn!
Tái xuất Tên với pub use
Khi chúng ta đưa một tên vào phạm vi với từ khóa use, tên đó là riêng tư đối
với phạm vi mà chúng ta đã nhập nó vào. Để cho phép mã bên ngoài phạm vi đó tham
chiếu đến tên đó như thể nó đã được định nghĩa trong phạm vi đó, chúng ta có thể
kết hợp pub và use. Kỹ thuật này được gọi là re-exporting (tái xuất) vì
chúng ta đưa một item vào phạm vi nhưng cũng làm cho item đó có sẵn cho người
khác đưa vào phạm vi của họ.
Listing 7-17 thể hiện mã trong Listing 7-11 với use trong module gốc được thay
đổi thành pub use.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Trước thay đổi này, mã bên ngoài sẽ phải gọi hàm add_to_waitlist bằng cách sử
dụng đường dẫn restaurant::front_of_house::hosting::add_to_waitlist(), điều
này cũng đòi hỏi module front_of_house phải được đánh dấu là pub. Bây giờ
pub use này đã tái xuất module hosting từ module gốc, mã bên ngoài có thể sử
dụng đường dẫn restaurant::hosting::add_to_waitlist() thay thế.
Tái xuất rất hữu ích khi cấu trúc nội bộ của mã của bạn khác với cách các lập
trình viên gọi mã của bạn sẽ nghĩ về miền. Ví dụ, trong phép ẩn dụ nhà hàng này,
những người điều hành nhà hàng nghĩ về "front of house" và "back of house."
Nhưng khách hàng ghé thăm một nhà hàng có lẽ sẽ không nghĩ về các phần của nhà
hàng theo những thuật ngữ đó. Với pub use, chúng ta có thể viết mã của mình
với một cấu trúc nhưng hiển thị một cấu trúc khác. Làm như vậy giúp thư viện của
chúng ta được tổ chức tốt cho các lập trình viên làm việc trên thư viện và các
lập trình viên gọi thư viện. Chúng ta sẽ xem một ví dụ khác về pub use và cách
nó ảnh hưởng đến tài liệu crate của bạn trong "Xuất một Public API Tiện lợi với
pub use" trong Chương 14.
Sử dụng Các Gói Bên ngoài
Trong Chương 2, chúng ta đã lập trình một dự án trò chơi đoán số sử dụng một gói
bên ngoài có tên là rand để có được số ngẫu nhiên. Để sử dụng rand trong dự
án của chúng ta, chúng ta đã thêm dòng này vào Cargo.toml:
rand = "0.8.5"
Thêm rand như một phụ thuộc trong Cargo.toml cho Cargo biết phải tải xuống
gói rand và bất kỳ phụ thuộc nào từ crates.io và làm cho
rand có sẵn cho dự án của chúng ta.
Sau đó, để đưa các định nghĩa rand vào phạm vi của gói của chúng ta, chúng ta
đã thêm một dòng use bắt đầu bằng tên của crate, rand, và liệt kê các item
chúng ta muốn đưa vào phạm vi. Hãy nhớ lại rằng trong "Tạo một Số Ngẫu
nhiên" trong Chương 2, chúng ta đã đưa trait Rng vào
phạm vi và gọi hàm rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Các thành viên của cộng đồng Rust đã làm cho nhiều gói có sẵn tại
crates.io, và việc kéo bất kỳ gói nào vào gói của bạn đều
liên quan đến các bước tương tự: liệt kê chúng trong tệp Cargo.toml của gói
của bạn và sử dụng use để đưa các item từ các crate đó vào phạm vi.
Lưu ý rằng thư viện chuẩn std cũng là một crate bên ngoài đối với gói của
chúng ta. Bởi vì thư viện chuẩn được đi kèm với ngôn ngữ Rust, chúng ta không
cần phải thay đổi Cargo.toml để bao gồm std. Nhưng chúng ta cần tham chiếu
đến nó với use để đưa các item từ đó vào phạm vi của gói của chúng ta. Ví dụ,
với HashMap chúng ta sẽ sử dụng dòng này:
#![allow(unused)] fn main() { use std::collections::HashMap; }
Đây là một đường dẫn tuyệt đối bắt đầu bằng std, tên của crate thư viện chuẩn.
Sử dụng Đường dẫn Lồng nhau để Làm sạch Danh sách use Lớn
Nếu chúng ta sử dụng nhiều item được định nghĩa trong cùng một crate hoặc cùng
một module, việc liệt kê mỗi item trên một dòng riêng có thể chiếm nhiều không
gian dọc trong các tệp của chúng ta. Ví dụ, hai câu lệnh use này chúng ta đã
có trong trò chơi đoán số trong Listing 2-4 đưa các item từ std vào phạm vi:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Thay vào đó, chúng ta có thể sử dụng đường dẫn lồng nhau để đưa các item tương tự vào phạm vi trong một dòng. Chúng ta làm điều này bằng cách chỉ định phần chung của đường dẫn, theo sau là hai dấu hai chấm, và sau đó là dấu ngoặc nhọn quanh danh sách các phần của đường dẫn khác nhau, như được hiển thị trong Listing 7-18.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Trong các chương trình lớn hơn, việc đưa nhiều item vào phạm vi từ cùng một
crate hoặc module sử dụng đường dẫn lồng nhau có thể giảm đáng kể số lượng câu
lệnh use riêng biệt cần thiết!
Chúng ta có thể sử dụng đường dẫn lồng nhau ở bất kỳ cấp độ nào trong một đường
dẫn, điều này rất hữu ích khi kết hợp hai câu lệnh use có chung một đường dẫn
con. Ví dụ, Listing 7-19 thể hiện hai câu lệnh use: một câu lệnh đưa std::io
vào phạm vi và một câu lệnh đưa std::io::Write vào phạm vi.
use std::io;
use std::io::Write;Phần chung của hai đường dẫn này là std::io, và đó là toàn bộ đường dẫn đầu
tiên. Để hợp nhất hai đường dẫn này thành một câu lệnh use, chúng ta có thể sử
dụng self trong đường dẫn lồng nhau, như được hiển thị trong Listing 7-20.
use std::io::{self, Write};Dòng này đưa std::io và std::io::Write vào phạm vi.
Toán tử Glob
Nếu chúng ta muốn đưa tất cả các item công khai được định nghĩa trong một
đường dẫn vào phạm vi, chúng ta có thể chỉ định đường dẫn đó theo sau bởi toán
tử glob *:
#![allow(unused)] fn main() { use std::collections::*; }
Câu lệnh use này đưa tất cả các item công khai được định nghĩa trong
std::collections vào phạm vi hiện tại. Hãy cẩn thận khi sử dụng toán tử glob!
Glob có thể làm cho nó khó hơn để biết những tên nào đang trong phạm vi và tên
được sử dụng trong chương trình của bạn được định nghĩa ở đâu. Ngoài ra, nếu phụ
thuộc thay đổi các định nghĩa của nó, những gì bạn đã import cũng thay đổi theo,
điều này có thể dẫn đến lỗi trình biên dịch khi bạn nâng cấp phụ thuộc nếu phụ
thuộc đó thêm một định nghĩa có cùng tên với một định nghĩa của bạn trong cùng
phạm vi, chẳng hạn.
Toán tử glob thường được sử dụng khi kiểm thử để đưa mọi thứ đang được kiểm thử
vào module tests; chúng ta sẽ nói về điều đó trong "Cách Viết Kiểm
thử" trong Chương 11. Toán tử glob cũng đôi khi
được sử dụng như một phần của mẫu prelude: xem
tài liệu thư viện chuẩn
để biết thêm thông tin về mẫu đó.
Tách Module Thành Nhiều File Khác Nhau
Cho đến nay, tất cả các ví dụ trong chương này đều định nghĩa nhiều module trong một file. Khi các module trở nên lớn, bạn có thể muốn di chuyển các định nghĩa của chúng vào một file riêng biệt để làm cho mã dễ điều hướng hơn.
Ví dụ, hãy bắt đầu từ mã trong Listing 7-17 với nhiều module nhà hàng. Chúng ta sẽ trích xuất module vào các file thay vì định nghĩa tất cả module trong file gốc của crate. Trong trường hợp này, file gốc của crate là src/lib.rs, nhưng quy trình này cũng hoạt động với các crate nhị phân mà file gốc của crate là src/main.rs.
Đầu tiên, chúng ta sẽ trích xuất module front_of_house vào file riêng của nó.
Xóa mã trong dấu ngoặc nhọn của module front_of_house, chỉ để lại khai báo
mod front_of_house;, để src/lib.rs chứa mã hiển thị trong Listing 7-21. Lưu
ý rằng mã này sẽ không biên dịch được cho đến khi chúng ta tạo file
src/front_of_house.rs trong Listing 7-22.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Tiếp theo, đặt mã đã nằm trong dấu ngoặc nhọn vào một file mới có tên
src/front_of_house.rs, như trong Listing 7-22. Trình biên dịch biết phải tìm
file này vì nó đã gặp khai báo module trong gốc của crate với tên
front_of_house.
pub mod hosting {
pub fn add_to_waitlist() {}
}Lưu ý rằng bạn chỉ cần tải một file bằng khai báo mod một lần trong cây
module của bạn. Khi trình biên dịch biết file đó là một phần của dự án (và biết
vị trí của mã trong cây module dựa vào nơi bạn đặt câu lệnh mod), các file
khác trong dự án của bạn nên tham chiếu đến mã của file đã được tải bằng đường
dẫn đến nơi nó được khai báo, như đã đề cập trong phần "Đường dẫn để tham chiếu
đến một mục trong cây module". Nói cách khác, mod
không phải là một thao tác "include" mà bạn có thể đã thấy trong các ngôn ngữ
lập trình khác.
Tiếp theo, chúng ta sẽ trích xuất module hosting vào file riêng của nó. Quy
trình này hơi khác vì hosting là một module con của front_of_house, không
phải của module gốc. Chúng ta sẽ đặt file cho hosting trong một thư mục mới
được đặt tên theo tổ tiên của nó trong cây module, trong trường hợp này là
src/front_of_house.
Để bắt đầu di chuyển hosting, chúng ta thay đổi src/front_of_house.rs để chỉ
chứa khai báo của module hosting:
pub mod hosting;Sau đó chúng ta tạo một thư mục src/front_of_house và một file hosting.rs để
chứa các định nghĩa được tạo trong module hosting:
pub fn add_to_waitlist() {}Nếu thay vào đó chúng ta đặt hosting.rs trong thư mục src, trình biên dịch
sẽ mong đợi mã hosting.rs nằm trong một module hosting được khai báo trong
gốc của crate, chứ không phải được khai báo là con của module front_of_house.
Các quy tắc của trình biên dịch về việc kiểm tra file nào cho mã của module nào
có nghĩa là các thư mục và file khớp chặt chẽ hơn với cây module.
Đường dẫn file thay thế
Cho đến nay chúng ta đã đề cập đến các đường dẫn file kiểu mẫu nhất mà trình biên dịch Rust sử dụng, nhưng Rust cũng hỗ trợ một kiểu đường dẫn file cũ hơn. Đối với module có tên
front_of_houseđược khai báo trong gốc của crate, trình biên dịch sẽ tìm kiếm mã của module trong:
- src/front_of_house.rs (những gì chúng ta đã đề cập)
- src/front_of_house/mod.rs (kiểu cũ hơn, vẫn được hỗ trợ)
Đối với module có tên
hostinglà một module con củafront_of_house, trình biên dịch sẽ tìm kiếm mã của module trong:
- src/front_of_house/hosting.rs (những gì chúng ta đã đề cập)
- src/front_of_house/hosting/mod.rs (kiểu cũ hơn, vẫn được hỗ trợ)
Nếu bạn sử dụng cả hai kiểu cho cùng một module, bạn sẽ gặp lỗi biên dịch. Sử dụng kết hợp cả hai kiểu cho các module khác nhau trong cùng một dự án là được phép, nhưng có thể gây nhầm lẫn cho những người điều hướng dự án của bạn.
Nhược điểm chính của kiểu sử dụng các file có tên mod.rs là dự án của bạn có thể kết thúc với nhiều file có tên mod.rs, điều này có thể gây nhầm lẫn khi bạn mở chúng cùng lúc trong trình soạn thảo.
Chúng ta đã di chuyển mã của mỗi module vào một file riêng biệt, và cây module
vẫn giữ nguyên. Các lệnh gọi hàm trong eat_at_restaurant sẽ hoạt động mà không
cần bất kỳ sự sửa đổi nào, mặc dù các định nghĩa nằm trong các file khác nhau.
Kỹ thuật này cho phép bạn di chuyển các module vào các file mới khi chúng tăng
kích thước.
Lưu ý rằng câu lệnh pub use crate::front_of_house::hosting trong src/lib.rs
cũng không thay đổi, và use cũng không có bất kỳ tác động nào đến việc những
file nào được biên dịch như một phần của crate. Từ khóa mod khai báo các
module, và Rust tìm kiếm trong một file có cùng tên với module để lấy mã đi vào
module đó.
Tóm tắt
Rust cho phép bạn chia một gói thành nhiều crate và một crate thành nhiều module
để bạn có thể tham chiếu đến các mục được định nghĩa trong một module từ một
module khác. Bạn có thể làm điều này bằng cách chỉ định đường dẫn tuyệt đối hoặc
đường dẫn tương đối. Các đường dẫn này có thể được đưa vào phạm vi với một câu
lệnh use để bạn có thể sử dụng một đường dẫn ngắn hơn cho nhiều lần sử dụng
mục đó trong phạm vi đó. Mã module là riêng tư theo mặc định, nhưng bạn có thể
công khai các định nghĩa bằng cách thêm từ khóa pub.
Trong chương tiếp theo, chúng ta sẽ xem xét một số cấu trúc dữ liệu tập hợp trong thư viện chuẩn mà bạn có thể sử dụng trong mã được tổ chức gọn gàng của mình.
Các Bộ Sưu Tập Thông Dụng
Thư viện chuẩn của Rust bao gồm một số cấu trúc dữ liệu rất hữu ích được gọi là các bộ sưu tập (collections). Hầu hết các kiểu dữ liệu khác đại diện cho một giá trị cụ thể, nhưng các bộ sưu tập có thể chứa nhiều giá trị. Không giống như các kiểu mảng và bộ (tuple) tích hợp sẵn, dữ liệu mà các bộ sưu tập này trỏ đến được lưu trữ trên heap, có nghĩa là lượng dữ liệu không cần phải biết tại thời điểm biên dịch và có thể tăng hoặc giảm khi chương trình chạy. Mỗi loại bộ sưu tập có khả năng và chi phí khác nhau, và việc chọn một bộ sưu tập phù hợp cho tình huống hiện tại của bạn là một kỹ năng mà bạn sẽ phát triển theo thời gian. Trong chương này, chúng ta sẽ thảo luận về ba bộ sưu tập được sử dụng rất thường xuyên trong các chương trình Rust:
- Một vector cho phép bạn lưu trữ một số lượng biến đổi các giá trị cạnh nhau.
- Một chuỗi (string) là một bộ sưu tập các ký tự. Chúng ta đã đề cập đến kiểu
Stringtrước đây, nhưng trong chương này chúng ta sẽ nói về nó một cách chi tiết. - Một bảng băm (hash map) cho phép bạn liên kết một giá trị với một khóa cụ thể. Đây là một triển khai cụ thể của cấu trúc dữ liệu tổng quát hơn được gọi là map.
Để tìm hiểu về các loại bộ sưu tập khác được cung cấp bởi thư viện chuẩn, hãy xem tài liệu.
Chúng ta sẽ thảo luận về cách tạo và cập nhật vector, chuỗi, và bảng băm, cũng như những điều gì làm cho mỗi loại đặc biệt.
Lưu Trữ Danh Sách Giá Trị với Vector
Loại bộ sưu tập đầu tiên mà chúng ta sẽ xem xét là Vec<T>, còn được gọi là
vector. Vector cho phép bạn lưu trữ nhiều giá trị trong một cấu trúc dữ liệu
duy nhất, đặt tất cả các giá trị liền kề nhau trong bộ nhớ. Vector chỉ có thể
lưu trữ các giá trị cùng kiểu. Chúng rất hữu ích khi bạn có một danh sách các
mục, chẳng hạn như các dòng văn bản trong một tập tin hoặc giá của các mặt hàng
trong một giỏ hàng.
Tạo một Vector Mới
Để tạo một vector rỗng mới, chúng ta gọi hàm Vec::new, như hiển thị trong
Listing 8-1.
fn main() { let v: Vec<i32> = Vec::new(); }
Lưu ý rằng chúng ta đã thêm một chú thích kiểu ở đây. Bởi vì chúng ta không chèn
bất kỳ giá trị nào vào vector này, Rust không biết chúng ta dự định lưu trữ
những phần tử kiểu gì. Đây là một điểm quan trọng. Vector được triển khai bằng
cách sử dụng generics; chúng ta sẽ đề cập đến cách sử dụng generics với các kiểu
riêng của bạn trong Chương 10. Hiện tại, hãy biết rằng kiểu Vec<T> được cung
cấp bởi thư viện chuẩn có thể chứa bất kỳ kiểu nào. Khi chúng ta tạo một vector
để chứa một kiểu cụ thể, chúng ta có thể chỉ định kiểu đó trong dấu ngoặc nhọn.
Trong Listing 8-1, chúng ta đã cho Rust biết rằng Vec<T> trong v sẽ chứa các
phần tử kiểu i32.
Thường thì bạn sẽ tạo một Vec<T> với các giá trị ban đầu và Rust sẽ suy luận
kiểu giá trị mà bạn muốn lưu trữ, vì vậy bạn hiếm khi cần phải chú thích kiểu.
Rust cung cấp một cách tiện lợi với macro vec!, sẽ tạo một vector mới chứa các
giá trị bạn cung cấp. Listing 8-2 tạo một Vec<i32> mới chứa các giá trị 1,
2, và 3. Kiểu số nguyên là i32 vì đó là kiểu số nguyên mặc định, như chúng
ta đã thảo luận trong phần "Kiểu Dữ Liệu" của
Chương 3.
fn main() { let v = vec![1, 2, 3]; }
Vì chúng ta đã cung cấp các giá trị i32 ban đầu, Rust có thể suy luận rằng
kiểu của v là Vec<i32>, và không cần thiết phải chú thích kiểu. Tiếp theo,
chúng ta sẽ xem cách sửa đổi một vector.
Cập Nhật một Vector
Để tạo một vector và sau đó thêm các phần tử vào nó, chúng ta có thể sử dụng
phương thức push, như hiển thị trong Listing 8-3.
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
Giống như với bất kỳ biến nào, nếu chúng ta muốn có thể thay đổi giá trị của nó,
chúng ta cần làm cho nó có thể thay đổi bằng cách sử dụng từ khóa mut, như đã
thảo luận trong Chương 3. Các số mà chúng ta đặt vào đều thuộc kiểu i32, và
Rust suy luận điều này từ dữ liệu, vì vậy chúng ta không cần chú thích
Vec<i32>.
Đọc Các Phần Tử của Vector
Có hai cách để tham chiếu đến một giá trị được lưu trữ trong vector: thông qua
chỉ mục hoặc bằng cách sử dụng phương thức get. Trong các ví dụ sau, chúng ta
đã chú thích các kiểu của giá trị được trả về từ các hàm này để có thêm độ rõ
ràng.
Listing 8-4 hiển thị cả hai phương pháp truy cập giá trị trong vector, với cú
pháp lập chỉ mục và phương thức get.
fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("The third element is {third}"); let third: Option<&i32> = v.get(2); match third { Some(third) => println!("The third element is {third}"), None => println!("There is no third element."), } }
Lưu ý một vài chi tiết ở đây. Chúng ta sử dụng giá trị chỉ mục 2 để lấy phần
tử thứ ba vì vector được đánh chỉ mục bằng số, bắt đầu từ không. Sử dụng & và
[] cho chúng ta một tham chiếu đến phần tử tại giá trị chỉ mục. Khi chúng ta
sử dụng phương thức get với chỉ mục được truyền vào dưới dạng đối số, chúng ta
nhận được một Option<&T> mà chúng ta có thể sử dụng với match.
Rust cung cấp hai cách để tham chiếu đến một phần tử để bạn có thể chọn cách chương trình hoạt động khi bạn cố gắng sử dụng một giá trị chỉ mục nằm ngoài phạm vi của các phần tử hiện có. Ví dụ, hãy xem điều gì xảy ra khi chúng ta có một vector gồm năm phần tử và sau đó chúng ta cố gắng truy cập một phần tử tại chỉ mục 100 với mỗi kỹ thuật, như hiển thị trong Listing 8-5.
fn main() { let v = vec![1, 2, 3, 4, 5]; let does_not_exist = &v[100]; let does_not_exist = v.get(100); }
Khi chúng ta chạy mã này, phương thức [] đầu tiên sẽ làm cho chương trình
hoảng loạn vì nó tham chiếu đến một phần tử không tồn tại. Phương pháp này được
sử dụng tốt nhất khi bạn muốn chương trình của mình gặp sự cố nếu có một nỗ lực
truy cập một phần tử ngoài phạm vi của vector.
Khi phương thức get được truyền một chỉ mục ngoài vector, nó trả về None mà
không hoảng loạn. Bạn sẽ sử dụng phương pháp này nếu việc truy cập một phần tử
ngoài phạm vi của vector có thể xảy ra thỉnh thoảng trong các trường hợp bình
thường. Mã của bạn sau đó sẽ có logic để xử lý việc có cả Some(&element) hoặc
None, như đã thảo luận trong Chương 6. Ví dụ, chỉ mục có thể đến từ một người
nhập một số. Nếu họ vô tình nhập một số quá lớn và chương trình nhận được giá
trị None, bạn có thể cho người dùng biết có bao nhiêu mục trong vector hiện
tại và cho họ một cơ hội khác để nhập một giá trị hợp lệ. Điều đó sẽ thân thiện
với người dùng hơn là làm cho chương trình gặp sự cố do một lỗi đánh máy!
Khi chương trình có một tham chiếu hợp lệ, bộ kiểm tra mượn sẽ thực thi các quy tắc quyền sở hữu và mượn (được đề cập trong Chương 4) để đảm bảo tham chiếu này và bất kỳ tham chiếu nào khác tới nội dung của vector vẫn có giá trị. Nhớ lại quy tắc cho rằng bạn không thể có tham chiếu có thể thay đổi và không thể thay đổi trong cùng phạm vi. Quy tắc đó áp dụng trong Listing 8-6, nơi chúng ta giữ một tham chiếu bất biến đến phần tử đầu tiên trong một vector và cố gắng thêm một phần tử vào cuối. Chương trình này sẽ không hoạt động nếu chúng ta cũng cố gắng tham chiếu đến phần tử đó sau đó trong hàm.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}Biên dịch mã này sẽ dẫn đến lỗi này:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Mã trong Listing 8-6 có vẻ như nên hoạt động: tại sao một tham chiếu đến phần tử đầu tiên lại quan tâm đến những thay đổi ở cuối vector? Lỗi này là do cách vector hoạt động: vì vector đặt các giá trị liền kề nhau trong bộ nhớ, việc thêm một phần tử mới vào cuối vector có thể yêu cầu cấp phát bộ nhớ mới và sao chép các phần tử cũ sang không gian mới, nếu không có đủ chỗ để đặt tất cả các phần tử liền kề nhau tại nơi vector hiện đang được lưu trữ. Trong trường hợp đó, tham chiếu đến phần tử đầu tiên sẽ trỏ đến bộ nhớ đã giải phóng. Các quy tắc mượn ngăn chặn các chương trình rơi vào tình huống đó.
Lưu ý: Để biết thêm về chi tiết triển khai của kiểu
Vec<T>, hãy xem "The Rustonomicon".
Lặp Qua Các Giá Trị trong một Vector
Để truy cập từng phần tử trong một vector theo lượt, chúng ta sẽ lặp qua tất cả
các phần tử thay vì sử dụng chỉ mục để truy cập từng phần tử một lần. Listing
8-7 hiển thị cách sử dụng vòng lặp for để lấy các tham chiếu bất biến đến từng
phần tử trong một vector các giá trị i32 và in chúng ra.
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
Chúng ta cũng có thể lặp qua các tham chiếu có thể thay đổi đến từng phần tử
trong một vector có thể thay đổi để thực hiện các thay đổi cho tất cả các phần
tử. Vòng lặp for trong Listing 8-8 sẽ thêm 50 vào mỗi phần tử.
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
Để thay đổi giá trị mà tham chiếu có thể thay đổi đề cập đến, chúng ta phải sử
dụng toán tử giải tham chiếu * để đến được giá trị trong i trước khi có thể
sử dụng toán tử +=. Chúng ta sẽ nói thêm về toán tử giải tham chiếu trong phần
"Tham chiếu đến giá trị" của Chương 15.
Việc lặp qua một vector, dù là bất biến hay có thể thay đổi, đều an toàn nhờ vào
quy tắc của bộ kiểm tra mượn. Nếu chúng ta cố gắng chèn hoặc xóa các mục trong
thân vòng lặp for trong Listing 8-7 và Listing 8-8, chúng ta sẽ gặp lỗi biên
dịch tương tự như lỗi chúng ta gặp với mã trong Listing 8-6. Tham chiếu đến
vector mà vòng lặp for giữ ngăn chặn việc sửa đổi đồng thời toàn bộ vector.
Sử dụng Enum để Lưu Trữ Nhiều Kiểu
Vector chỉ có thể lưu trữ các giá trị có cùng kiểu. Điều này có thể gây bất tiện; chắc chắn có những trường hợp sử dụng cần lưu trữ một danh sách các mục thuộc các kiểu khác nhau. May mắn thay, các biến thể của một enum được định nghĩa dưới cùng một kiểu enum, vì vậy khi chúng ta cần một kiểu để đại diện cho các phần tử của các kiểu khác nhau, chúng ta có thể định nghĩa và sử dụng một enum!
Ví dụ, giả sử chúng ta muốn lấy các giá trị từ một hàng trong một bảng tính trong đó một số cột trong hàng chứa số nguyên, một số chứa số dấu phẩy động, và một số chứa chuỗi. Chúng ta có thể định nghĩa một enum có các biến thể sẽ chứa các kiểu giá trị khác nhau, và tất cả các biến thể enum sẽ được coi là cùng một kiểu: kiểu của enum đó. Sau đó chúng ta có thể tạo một vector để chứa enum đó và do đó, cuối cùng, chứa các kiểu khác nhau. Chúng ta đã minh họa điều này trong Listing 8-9.
fn main() { enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
Rust cần biết những kiểu nào sẽ có trong vector tại thời điểm biên dịch để biết
chính xác bao nhiêu bộ nhớ trên heap sẽ cần để lưu trữ mỗi phần tử. Chúng ta
cũng phải rõ ràng về những kiểu nào được phép trong vector này. Nếu Rust cho
phép một vector chứa bất kỳ kiểu nào, sẽ có khả năng một hoặc nhiều kiểu sẽ gây
ra lỗi với các hoạt động được thực hiện trên các phần tử của vector. Sử dụng
enum cùng với biểu thức match nghĩa là Rust sẽ đảm bảo tại thời điểm biên dịch
rằng mọi trường hợp khả dĩ đều được xử lý, như đã thảo luận trong Chương 6.
Nếu bạn không biết tập hợp đầy đủ các kiểu mà một chương trình sẽ nhận được tại thời điểm chạy để lưu trữ trong vector, kỹ thuật enum sẽ không hoạt động. Thay vào đó, bạn có thể sử dụng trait object, mà chúng ta sẽ đề cập trong Chương 18.
Giờ chúng ta đã thảo luận về một số cách sử dụng vector phổ biến nhất, hãy đảm
bảo xem xét tài liệu API để biết tất cả các phương
thức hữu ích được định nghĩa cho Vec<T> bởi thư viện chuẩn. Ví dụ, ngoài
push, phương thức pop loại bỏ và trả về phần tử cuối cùng.
Giải phóng một Vector sẽ Giải phóng Các Phần tử của Nó
Giống như bất kỳ struct nào khác, một vector được giải phóng khi nó ra khỏi
phạm vi, như được chú thích trong Listing 8-10.
fn main() { { let v = vec![1, 2, 3, 4]; // do stuff with v } // <- v goes out of scope and is freed here }
Khi vector bị giải phóng, tất cả nội dung của nó cũng bị giải phóng, nghĩa là các số nguyên mà nó chứa sẽ được dọn sạch. Bộ kiểm tra mượn đảm bảo rằng bất kỳ tham chiếu nào đến nội dung của vector chỉ được sử dụng khi bản thân vector còn có giá trị.
Hãy chuyển sang loại bộ sưu tập tiếp theo: String!
Lưu Trữ Văn Bản Mã Hóa UTF-8 với Chuỗi
Chúng ta đã nói về chuỗi trong Chương 4, nhưng bây giờ chúng ta sẽ xem xét chúng chi tiết hơn. Những người mới học Rust thường bị mắc kẹt với chuỗi vì sự kết hợp của ba lý do: khuynh hướng của Rust trong việc tiết lộ các lỗi có thể xảy ra, chuỗi là một cấu trúc dữ liệu phức tạp hơn nhiều so với những gì nhiều lập trình viên đánh giá, và UTF-8. Những yếu tố này kết hợp theo cách dường như khó khăn khi bạn đến từ các ngôn ngữ lập trình khác.
Chúng ta thảo luận về chuỗi trong bối cảnh của các bộ sưu tập vì chuỗi được
triển khai như một bộ sưu tập các byte, cộng thêm một số phương thức để cung cấp
chức năng hữu ích khi những byte này được diễn giải dưới dạng văn bản. Trong
phần này, chúng ta sẽ nói về các hoạt động trên String mà mọi loại bộ sưu tập
đều có, chẳng hạn như tạo, cập nhật và đọc. Chúng ta cũng sẽ thảo luận về những
cách mà String khác với các bộ sưu tập khác, cụ thể là cách mà việc lập chỉ
mục vào một String bị phức tạp hóa bởi sự khác biệt giữa cách con người và máy
tính diễn giải dữ liệu String.
Chuỗi Là Gì?
Đầu tiên, chúng ta sẽ định nghĩa những gì chúng ta hiểu bằng thuật ngữ chuỗi.
Rust chỉ có một kiểu chuỗi trong ngôn ngữ cốt lõi, đó là lát cắt chuỗi str
thường được thấy dưới dạng mượn &str. Trong Chương 4, chúng ta đã nói về lát
cắt chuỗi, là tham chiếu đến một số dữ liệu chuỗi mã hóa UTF-8 được lưu trữ ở
nơi khác. Các chuỗi nghĩa đen, chẳng hạn, được lưu trữ trong tệp nhị phân của
chương trình và do đó là lát cắt chuỗi.
Kiểu String, được cung cấp bởi thư viện chuẩn của Rust thay vì được mã hóa
trong ngôn ngữ cốt lõi, là một kiểu chuỗi có thể phát triển, có thể thay đổi,
được sở hữu, mã hóa UTF-8. Khi người dùng Rust nhắc đến "chuỗi" trong Rust, họ
có thể nhắc đến kiểu String hoặc kiểu lát cắt chuỗi &str, không chỉ một
trong những kiểu đó. Mặc dù phần này chủ yếu nói về String, cả hai kiểu đều
được sử dụng nhiều trong thư viện chuẩn của Rust, và cả String và lát cắt
chuỗi đều được mã hóa UTF-8.
Tạo Một Chuỗi Mới
Nhiều hoạt động tương tự có sẵn với Vec<T> cũng có sẵn với String vì
String thực sự được triển khai như một bao bọc xung quanh một vector byte với
một số đảm bảo, hạn chế và khả năng bổ sung. Một ví dụ về một hàm hoạt động
giống nhau với Vec<T> và String là hàm new để tạo một thể hiện, như hiển
thị trong Listing 8-11.
fn main() { let mut s = String::new(); }
Dòng này tạo ra một chuỗi mới, rỗng có tên là s, mà chúng ta sau đó có thể tải
dữ liệu vào. Thường thì chúng ta sẽ có một số dữ liệu ban đầu mà chúng ta muốn
bắt đầu chuỗi với. Để làm điều đó, chúng ta sử dụng phương thức to_string, có
sẵn trên bất kỳ kiểu nào triển khai trait Display, như các chuỗi nghĩa đen có.
Listing 8-12 hiển thị hai ví dụ.
fn main() { let data = "initial contents"; let s = data.to_string(); // The method also works on a literal directly: let s = "initial contents".to_string(); }
Mã này tạo ra một chuỗi chứa initial contents.
Chúng ta cũng có thể sử dụng hàm String::from để tạo một String từ một chuỗi
nghĩa đen. Mã trong Listing 8-13 tương đương với mã trong Listing 8-12 sử dụng
to_string.
fn main() { let s = String::from("initial contents"); }
Vì chuỗi được sử dụng cho rất nhiều thứ, chúng ta có thể sử dụng nhiều API chung
khác nhau cho chuỗi, cung cấp cho chúng ta rất nhiều tùy chọn. Một số trong số
chúng có vẻ thừa thãi, nhưng tất cả đều có vị trí riêng của mình! Trong trường
hợp này, String::from và to_string làm cùng một việc, vì vậy việc bạn chọn
cái nào là vấn đề của phong cách và khả năng đọc.
Hãy nhớ rằng chuỗi được mã hóa UTF-8, vì vậy chúng ta có thể bao gồm bất kỳ dữ liệu nào được mã hóa đúng cách trong chúng, như hiển thị trong Listing 8-14.
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Tất cả những điều này đều là các giá trị String hợp lệ.
Cập Nhật một Chuỗi
Một String có thể tăng kích thước và nội dung của nó có thể thay đổi, giống
như nội dung của một Vec<T>, nếu bạn đẩy thêm dữ liệu vào nó. Ngoài ra, bạn có
thể thuận tiện sử dụng toán tử + hoặc macro format! để nối các giá trị
String.
Thêm vào Chuỗi với push_str và push
Chúng ta có thể làm cho một String phát triển bằng cách sử dụng phương thức
push_str để thêm một lát cắt chuỗi, như hiển thị trong Listing 8-15.
fn main() { let mut s = String::from("foo"); s.push_str("bar"); }
Sau hai dòng này, s sẽ chứa foobar. Phương thức push_str lấy một lát cắt
chuỗi vì chúng ta không nhất thiết muốn lấy quyền sở hữu của tham số. Ví dụ,
trong mã trong Listing 8-16, chúng ta muốn có thể sử dụng s2 sau khi thêm nội
dung của nó vào s1.
fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 is {s2}"); }
Nếu phương thức push_str lấy quyền sở hữu của s2, chúng ta sẽ không thể in
giá trị của nó trên dòng cuối cùng. Tuy nhiên, mã này hoạt động như chúng ta
mong đợi!
Phương thức push lấy một ký tự duy nhất làm tham số và thêm nó vào String.
Listing 8-17 thêm chữ cái l vào một String bằng cách sử dụng phương thức
push.
fn main() { let mut s = String::from("lo"); s.push('l'); }
Kết quả là, s sẽ chứa lol.
Nối với Toán Tử + hoặc Macro format!
Thường thì bạn sẽ muốn kết hợp hai chuỗi hiện có. Một cách để làm điều đó là sử
dụng toán tử +, như hiển thị trong Listing 8-18.
fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
Chuỗi s3 sẽ chứa Hello, world!. Lý do s1 không còn hợp lệ sau khi thêm, và
lý do chúng ta sử dụng một tham chiếu đến s2, có liên quan đến chữ ký của
phương thức được gọi khi chúng ta sử dụng toán tử +. Toán tử + sử dụng
phương thức add, có chữ ký trông giống như thế này:
fn add(self, s: &str) -> String {Trong thư viện chuẩn, bạn sẽ thấy add được định nghĩa bằng cách sử dụng
generics và liên kết kiểu. Ở đây, chúng ta đã thay thế bằng các kiểu cụ thể,
điều này xảy ra khi chúng ta gọi phương thức này với các giá trị String. Chúng
ta sẽ thảo luận về generics trong Chương 10. Chữ ký này cung cấp cho chúng ta
những manh mối chúng ta cần để hiểu các phần phức tạp của toán tử +.
Đầu tiên, s2 có một &, có nghĩa là chúng ta đang thêm một tham chiếu của
chuỗi thứ hai vào chuỗi đầu tiên. Điều này là do tham số s trong hàm add:
chúng ta chỉ có thể thêm một &str vào một String; chúng ta không thể thêm
hai giá trị String với nhau. Nhưng khoan—kiểu của &s2 là &String, không
phải &str, như đã được chỉ định trong tham số thứ hai cho add. Vậy tại sao
Listing 8-18 biên dịch?
Lý do chúng ta có thể sử dụng &s2 trong lệnh gọi đến add là vì trình biên
dịch có thể ép buộc đối số &String thành &str. Khi chúng ta gọi phương
thức add, Rust sử dụng ép buộc deref, nơi đây biến &s2 thành &s2[..].
Chúng ta sẽ thảo luận về ép buộc deref chi tiết hơn trong Chương 15. Bởi vì
add không lấy quyền sở hữu của tham số s, s2 vẫn sẽ là một String hợp lệ
sau hoạt động này.
Thứ hai, chúng ta có thể thấy trong chữ ký rằng add lấy quyền sở hữu của
self vì self không có &. Điều này có nghĩa s1 trong Listing 8-18 sẽ bị
di chuyển vào lệnh gọi add và sẽ không còn hợp lệ sau đó. Vì vậy, mặc dù
let s3 = s1 + &s2; trông như thể nó sẽ sao chép cả hai chuỗi và tạo một chuỗi
mới, câu lệnh này thực sự lấy quyền sở hữu của s1, thêm một bản sao nội dung
của s2, và sau đó trả lại quyền sở hữu của kết quả. Nói cách khác, nó trông
như thể nó đang tạo ra rất nhiều bản sao, nhưng không phải vậy; việc triển khai
hiệu quả hơn là sao chép.
Nếu chúng ta cần nối nhiều chuỗi, hành vi của toán tử + trở nên khó xử lý:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = s1 + "-" + &s2 + "-" + &s3; }
Lúc này, s sẽ là tic-tac-toe. Với tất cả các ký tự + và ", khó có thể
thấy điều gì đang xảy ra. Để kết hợp các chuỗi theo cách phức tạp hơn, chúng ta
có thể sử dụng macro format!:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
Mã này cũng đặt s thành tic-tac-toe. Macro format! hoạt động giống như
println!, nhưng thay vì in đầu ra ra màn hình, nó trả về một String với nội
dung. Phiên bản mã sử dụng format! dễ đọc hơn nhiều, và mã được tạo ra bởi
macro format! sử dụng tham chiếu nên lời gọi này không lấy quyền sở hữu của
bất kỳ tham số nào của nó.
Lập Chỉ Mục vào Chuỗi
Trong nhiều ngôn ngữ lập trình khác, việc truy cập các ký tự riêng lẻ trong một
chuỗi bằng cách tham chiếu đến chúng bằng chỉ mục là một hoạt động hợp lệ và phổ
biến. Tuy nhiên, nếu bạn cố gắng truy cập các phần của một String sử dụng cú
pháp lập chỉ mục trong Rust, bạn sẽ gặp lỗi. Xem xét mã không hợp lệ trong
Listing 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}Mã này sẽ dẫn đến lỗi sau:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Lỗi và ghi chú kể câu chuyện: chuỗi Rust không hỗ trợ lập chỉ mục. Nhưng tại sao không? Để trả lời câu hỏi đó, chúng ta cần thảo luận về cách Rust lưu trữ chuỗi trong bộ nhớ.
Biểu Diễn Nội Bộ
Một String là một bao bọc trên một Vec<u8>. Hãy xem một số ví dụ chuỗi được
mã hóa UTF-8 đúng của chúng ta từ Listing 8-14. Đầu tiên là ví dụ này:
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Trong trường hợp này, len sẽ là 4, có nghĩa là vector lưu trữ chuỗi "Hola"
dài 4 byte. Mỗi chữ cái này chiếm một byte khi được mã hóa trong UTF-8. Tuy
nhiên, dòng sau đây có thể làm bạn ngạc nhiên (lưu ý rằng chuỗi này bắt đầu bằng
chữ cái Cyrillic viết hoa Ze, không phải số 3):
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Nếu bạn được hỏi chuỗi dài bao nhiêu, bạn có thể nói 12. Thực tế, câu trả lời của Rust là 24: đó là số byte cần thiết để mã hóa "Здравствуйте" trong UTF-8, vì mỗi giá trị vô hướng Unicode trong chuỗi đó chiếm 2 byte lưu trữ. Do đó, một chỉ mục vào byte của chuỗi sẽ không phải lúc nào cũng tương quan với một giá trị vô hướng Unicode hợp lệ. Để minh họa, hãy xem xét mã Rust không hợp lệ này:
let hello = "Здравствуйте";
let answer = &hello[0];Bạn đã biết rằng answer sẽ không phải là З, chữ cái đầu tiên. Khi được mã
hóa trong UTF-8, byte đầu tiên của З là 208 và byte thứ hai là 151, vì vậy
nó sẽ có vẻ như answer thực sự nên là 208, nhưng 208 không phải là một ký
tự hợp lệ tự nó. Trả về 208 có thể không phải là điều mà người dùng muốn nếu
họ hỏi về chữ cái đầu tiên của chuỗi này; tuy nhiên, đó là dữ liệu duy nhất mà
Rust có tại chỉ mục byte 0. Người dùng thường không muốn giá trị byte được trả
về, ngay cả khi chuỗi chỉ chứa các chữ cái Latin: nếu &"hi"[0] là mã hợp lệ
trả về giá trị byte, nó sẽ trả về 104, không phải h.
Câu trả lời, vì vậy, là để tránh trả về một giá trị không mong đợi và gây ra lỗi có thể không được phát hiện ngay lập tức, Rust không biên dịch mã này và ngăn chặn hiểu lầm sớm trong quá trình phát triển.
Byte, Giá Trị Vô Hướng và Cụm Tự Hình! Ôi Trời!
Một điểm khác về UTF-8 là thực sự có ba cách liên quan để nhìn chuỗi từ góc độ của Rust: dưới dạng byte, giá trị vô hướng, và cụm tự hình (điều gần nhất với những gì chúng ta gọi là chữ cái).
Nếu chúng ta nhìn vào từ tiếng Hindi "नमस्ते" được viết bằng chữ viết
Devanagari, nó được lưu trữ dưới dạng một vector các giá trị u8 trông như thế
này:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Đó là 18 byte và đây là cách máy tính cuối cùng lưu trữ dữ liệu này. Nếu chúng
ta nhìn vào chúng như các giá trị vô hướng Unicode, đó là kiểu char của Rust,
những byte đó trông như thế này:
['न', 'म', 'स', '्', 'त', 'े']
Có sáu giá trị char ở đây, nhưng giá trị thứ tư và thứ sáu không phải là chữ
cái: đó là các dấu phụ không có ý nghĩa khi đứng một mình. Cuối cùng, nếu chúng
ta nhìn vào chúng như cụm tự hình, chúng ta sẽ có được những gì mà một người sẽ
gọi là bốn chữ cái tạo nên từ tiếng Hindi:
["न", "म", "स्", "ते"]
Rust cung cấp các cách khác nhau để diễn giải dữ liệu chuỗi thô mà máy tính lưu trữ để mỗi chương trình có thể chọn cách diễn giải mà nó cần, bất kể ngôn ngữ con người nào mà dữ liệu đó thuộc về.
Một lý do cuối cùng mà Rust không cho phép chúng ta lập chỉ mục vào một String
để lấy một ký tự là vì các hoạt động lập chỉ mục được mong đợi luôn mất thời
gian không đổi (O(1)). Nhưng không thể đảm bảo hiệu suất đó với một String, vì
Rust sẽ phải đi qua nội dung từ đầu đến chỉ mục để xác định có bao nhiêu ký tự
hợp lệ.
Cắt Chuỗi
Lập chỉ mục vào một chuỗi thường là một ý tưởng tồi vì không rõ kiểu trả về của hoạt động lập chỉ mục chuỗi nên là gì: một giá trị byte, một ký tự, một cụm tự hình, hay một lát cắt chuỗi. Do đó, nếu bạn thực sự cần sử dụng chỉ mục để tạo lát cắt chuỗi, Rust yêu cầu bạn cần cụ thể hơn.
Thay vì lập chỉ mục bằng [] với một số duy nhất, bạn có thể sử dụng [] với
một phạm vi để tạo một lát cắt chuỗi chứa các byte cụ thể:
#![allow(unused)] fn main() { let hello = "Здравствуйте"; let s = &hello[0..4]; }
Ở đây, s sẽ là một &str chứa bốn byte đầu tiên của chuỗi. Trước đó, chúng ta
đã đề cập rằng mỗi ký tự này chiếm hai byte, điều đó có nghĩa s sẽ là Зд.
Nếu chúng ta cố gắng cắt chỉ một phần byte của một ký tự với một cái gì đó như
&hello[0..1], Rust sẽ hoảng loạn tại thời điểm chạy theo cách tương tự như khi
một chỉ mục không hợp lệ được truy cập trong một vector:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Bạn nên thận trọng khi tạo lát cắt chuỗi với phạm vi, vì làm như vậy có thể làm sập chương trình của bạn.
Phương Thức để Lặp Qua Chuỗi
Cách tốt nhất để hoạt động trên các phần của chuỗi là rõ ràng về việc bạn muốn
ký tự hay byte. Đối với các giá trị vô hướng Unicode riêng lẻ, hãy sử dụng
phương thức chars. Gọi chars trên "Зд" tách ra và trả về hai giá trị kiểu
char, và bạn có thể lặp qua kết quả để truy cập từng phần tử:
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } }
Mã này sẽ in ra như sau:
З
д
Ngoài ra, phương thức bytes trả về từng byte thô, điều này có thể phù hợp cho
miền của bạn:
#![allow(unused)] fn main() { for b in "Зд".bytes() { println!("{b}"); } }
Mã này sẽ in ra bốn byte tạo nên chuỗi này:
208
151
208
180
Nhưng hãy nhớ rằng các giá trị vô hướng Unicode hợp lệ có thể bao gồm nhiều hơn một byte.
Lấy cụm tự hình từ chuỗi, như với chữ viết Devanagari, là phức tạp, vì vậy chức năng này không được cung cấp bởi thư viện chuẩn. Các crate có sẵn trên crates.io nếu đây là chức năng bạn cần.
Chuỗi Không Đơn Giản
Tóm lại, chuỗi là phức tạp. Các ngôn ngữ lập trình khác nhau đưa ra những lựa
chọn khác nhau về cách trình bày sự phức tạp này cho lập trình viên. Rust đã
chọn làm cho việc xử lý dữ liệu String đúng cách trở thành hành vi mặc định
cho tất cả các chương trình Rust, điều này có nghĩa là lập trình viên phải suy
nghĩ nhiều hơn về việc xử lý dữ liệu UTF-8 ngay từ đầu. Sự đánh đổi này tiết lộ
nhiều sự phức tạp của chuỗi hơn là rõ ràng trong các ngôn ngữ lập trình khác,
nhưng nó ngăn bạn phải xử lý lỗi liên quan đến các ký tự không phải ASCII sau
này trong vòng đời phát triển của bạn.
Tin tốt là thư viện chuẩn cung cấp rất nhiều chức năng được xây dựng dựa trên
các kiểu String và &str để giúp xử lý các tình huống phức tạp này một cách
chính xác. Hãy chắc chắn kiểm tra tài liệu để biết các phương thức hữu ích như
contains để tìm kiếm trong một chuỗi và replace để thay thế các phần của một
chuỗi bằng một chuỗi khác.
Hãy chuyển sang một thứ ít phức tạp hơn một chút: bảng băm!
Lưu Trữ Khóa với Giá Trị Liên Kết trong Bảng Băm
Loại bộ sưu tập phổ biến cuối cùng của chúng ta là bảng băm. Kiểu
HashMap<K, V> lưu trữ một ánh xạ từ khóa kiểu K đến giá trị kiểu V bằng
cách sử dụng một hàm băm, xác định cách nó đặt các khóa và giá trị này vào bộ
nhớ. Nhiều ngôn ngữ lập trình hỗ trợ cấu trúc dữ liệu này, nhưng chúng thường sử
dụng tên khác nhau, chẳng hạn như hash, map, object, hash table,
dictionary, hoặc associative array, chỉ để kể vài tên.
Bảng băm hữu ích khi bạn muốn tra cứu dữ liệu không bằng cách sử dụng chỉ mục, như bạn có thể làm với vector, mà bằng cách sử dụng khóa có thể thuộc bất kỳ kiểu nào. Ví dụ, trong một trò chơi, bạn có thể theo dõi điểm số của mỗi đội trong một bảng băm trong đó mỗi khóa là tên của một đội và giá trị là điểm số của mỗi đội. Cho tên đội, bạn có thể lấy ra điểm số của nó.
Chúng ta sẽ xem qua API cơ bản của bảng băm trong phần này, nhưng còn nhiều thứ
hữu ích khác ẩn trong các hàm được định nghĩa trên HashMap<K, V> bởi thư viện
chuẩn. Như mọi khi, hãy kiểm tra tài liệu của thư viện chuẩn để biết thêm thông
tin.
Tạo Bảng Băm Mới
Một cách để tạo bảng băm rỗng là sử dụng new và thêm các phần tử bằng
insert. Trong Listing 8-20, chúng ta đang theo dõi điểm số của hai đội có tên
là Blue và Yellow. Đội Blue bắt đầu với 10 điểm, và đội Yellow bắt đầu
với 50.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); }
Lưu ý rằng chúng ta cần use HashMap từ phần collections của thư viện chuẩn
trước. Trong ba bộ sưu tập phổ biến của chúng ta, bộ sưu tập này được sử dụng ít
nhất, nên nó không được đưa vào phạm vi tự động trong phần prelude. Bảng băm
cũng nhận được ít hỗ trợ hơn từ thư viện chuẩn; chẳng hạn, không có macro tích
hợp sẵn để xây dựng chúng.
Giống như vector, bảng băm lưu trữ dữ liệu của chúng trên heap. HashMap này có
khóa kiểu String và giá trị kiểu i32. Giống như vector, bảng băm là đồng
nhất: tất cả các khóa phải có cùng kiểu, và tất cả các giá trị phải có cùng
kiểu.
Truy Cập Giá Trị trong Bảng Băm
Chúng ta có thể lấy một giá trị từ bảng băm bằng cách cung cấp khóa của nó cho
phương thức get, như được hiển thị trong Listing 8-21.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0); }
Ở đây, score sẽ có giá trị được liên kết với đội Blue, và kết quả sẽ là 10.
Phương thức get trả về một Option<&V>; nếu không có giá trị cho khóa đó
trong bảng băm, get sẽ trả về None. Chương trình này xử lý Option bằng
cách gọi copied để lấy một Option<i32> thay vì một Option<&i32>, sau đó
unwrap_or để đặt score thành không nếu scores không có mục cho khóa.
Chúng ta có thể lặp qua từng cặp khóa-giá trị trong một bảng băm theo cách tương
tự như chúng ta làm với vector, sử dụng vòng lặp for:
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{key}: {value}"); } }
Mã này sẽ in mỗi cặp theo thứ tự ngẫu nhiên:
Yellow: 50
Blue: 10
Bảng Băm và Quyền Sở Hữu
Đối với các kiểu triển khai trait Copy, như i32, các giá trị được sao chép
vào bảng băm. Đối với các giá trị được sở hữu như String, các giá trị sẽ bị di
chuyển và bảng băm sẽ là chủ sở hữu của các giá trị đó, như được minh họa trong
Listing 8-22.
fn main() { use std::collections::HashMap; let field_name = String::from("Favorite color"); let field_value = String::from("Blue"); let mut map = HashMap::new(); map.insert(field_name, field_value); // field_name and field_value are invalid at this point, try using them and // see what compiler error you get! }
Chúng ta không thể sử dụng các biến field_name và field_value sau khi chúng
đã được di chuyển vào bảng băm bằng lệnh gọi đến insert.
Nếu chúng ta chèn tham chiếu đến các giá trị vào bảng băm, các giá trị sẽ không bị di chuyển vào bảng băm. Các giá trị mà các tham chiếu trỏ đến phải hợp lệ ít nhất miễn là bảng băm còn hợp lệ. Chúng ta sẽ nói thêm về các vấn đề này trong "Xác thực Tham chiếu với Vòng đời" trong Chương 10.
Cập Nhật Bảng Băm
Mặc dù số lượng cặp khóa và giá trị có thể tăng lên, mỗi khóa duy nhất chỉ có
thể có một giá trị liên kết với nó tại một thời điểm (nhưng không ngược lại: ví
dụ, cả đội Blue và đội Yellow đều có thể có giá trị 10 được lưu trữ trong bảng
băm scores).
Khi bạn muốn thay đổi dữ liệu trong một bảng băm, bạn phải quyết định cách xử lý trường hợp khi một khóa đã có một giá trị được gán. Bạn có thể thay thế giá trị cũ bằng giá trị mới, hoàn toàn bỏ qua giá trị cũ. Bạn có thể giữ giá trị cũ và bỏ qua giá trị mới, chỉ thêm giá trị mới nếu khóa không đã có một giá trị. Hoặc bạn có thể kết hợp giá trị cũ và giá trị mới. Hãy xem cách thực hiện mỗi điều này!
Ghi Đè Một Giá Trị
Nếu chúng ta chèn một khóa và một giá trị vào một bảng băm và sau đó chèn cùng
khóa đó với một giá trị khác, giá trị liên kết với khóa đó sẽ bị thay thế. Mặc
dù mã trong Listing 8-23 gọi insert hai lần, bảng băm sẽ chỉ chứa một cặp
khóa-giá trị vì chúng ta đang chèn giá trị cho khóa của đội Blue cả hai lần.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Blue"), 25); println!("{scores:?}"); }
Mã này sẽ in {"Blue": 25}. Giá trị ban đầu 10 đã bị ghi đè.
Chỉ Thêm Khóa và Giá Trị Nếu Khóa Không Tồn Tại
Thông thường, người ta kiểm tra xem một khóa cụ thể đã tồn tại trong bảng băm với một giá trị hay chưa và sau đó thực hiện các hành động sau: nếu khóa đó tồn tại trong bảng băm, giá trị hiện tại nên giữ nguyên như vậy; nếu khóa không tồn tại, chèn nó và một giá trị cho nó.
Bảng băm có một API đặc biệt cho việc này gọi là entry lấy khóa bạn muốn kiểm
tra làm tham số. Giá trị trả về của phương thức entry là một enum gọi là
Entry đại diện cho một giá trị có thể tồn tại hoặc không. Giả sử chúng ta muốn
kiểm tra xem khóa cho đội Yellow có giá trị liên kết với nó không. Nếu không,
chúng ta muốn chèn giá trị 50, và tương tự cho đội Blue. Sử dụng API entry,
mã trông giống như Listing 8-24.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.entry(String::from("Yellow")).or_insert(50); scores.entry(String::from("Blue")).or_insert(50); println!("{scores:?}"); }
Phương thức or_insert trên Entry được định nghĩa để trả về một tham chiếu có
thể thay đổi đến giá trị cho khóa Entry tương ứng nếu khóa đó tồn tại, và nếu
không, nó chèn tham số làm giá trị mới cho khóa này và trả về một tham chiếu có
thể thay đổi đến giá trị mới. Kỹ thuật này sạch sẽ hơn nhiều so với việc tự viết
logic và, ngoài ra, hoạt động tốt hơn với bộ kiểm tra mượn.
Chạy mã trong Listing 8-24 sẽ in {"Yellow": 50, "Blue": 10}. Lệnh gọi đầu tiên
đến entry sẽ chèn khóa cho đội Yellow với giá trị 50 vì đội Yellow chưa có
giá trị. Lệnh gọi thứ hai đến entry sẽ không thay đổi bảng băm vì đội Blue đã
có giá trị 10.
Cập Nhật Giá Trị Dựa trên Giá Trị Cũ
Trường hợp sử dụng phổ biến khác cho bảng băm là tra cứu giá trị của một khóa và
sau đó cập nhật nó dựa trên giá trị cũ. Ví dụ, Listing 8-25 hiển thị mã đếm số
lần xuất hiện của mỗi từ trong một đoạn văn bản. Chúng ta sử dụng bảng băm với
các từ làm khóa và tăng giá trị để theo dõi số lần chúng ta đã thấy từ đó. Nếu
đó là lần đầu tiên chúng ta thấy một từ, chúng ta sẽ chèn giá trị 0 trước.
fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); *count += 1; } println!("{map:?}"); }
Mã này sẽ in {"world": 2, "hello": 1, "wonderful": 1}. Bạn có thể thấy các cặp
khóa-giá trị giống nhau được in ra theo thứ tự khác nhau: hãy nhớ lại từ "Truy
cập Giá trị trong Bảng băm" rằng việc lặp qua một bảng
băm xảy ra theo thứ tự ngẫu nhiên.
Phương thức split_whitespace trả về một iterator qua các lát cắt con, được
phân tách bởi khoảng trắng, của giá trị trong text. Phương thức or_insert
trả về một tham chiếu có thể thay đổi (&mut V) đến giá trị cho khóa được chỉ
định. Ở đây, chúng ta lưu trữ tham chiếu có thể thay đổi đó trong biến count,
vì vậy để gán cho giá trị đó, chúng ta phải giải tham chiếu count bằng cách sử
dụng dấu hoa thị (*). Tham chiếu có thể thay đổi hết phạm vi tại cuối vòng lặp
for, vì vậy tất cả các thay đổi này là an toàn và được cho phép bởi các quy
tắc mượn.
Hàm Băm
Theo mặc định, HashMap sử dụng một hàm băm gọi là SipHash có thể cung cấp
khả năng chống lại các cuộc tấn công từ chối dịch vụ (DoS) liên quan đến bảng
băm1. Đây không phải là thuật toán băm nhanh nhất có
sẵn, nhưng sự đánh đổi cho bảo mật tốt hơn đi kèm với sự sụt giảm hiệu suất là
đáng giá. Nếu bạn phân tích mã của mình và thấy rằng hàm băm mặc định quá chậm
cho mục đích của bạn, bạn có thể chuyển sang một hàm khác bằng cách chỉ định một
bộ băm khác. Một hasher là một kiểu triển khai trait BuildHasher. Chúng ta
sẽ nói về trait và cách triển khai chúng trong Chương
10. Bạn không nhất thiết phải triển khai bộ băm riêng
của bạn từ đầu; crates.io có các thư viện
được chia sẻ bởi người dùng Rust khác cung cấp các hasher triển khai nhiều thuật
toán băm phổ biến.
Tóm tắt
Vector, chuỗi và bảng băm sẽ cung cấp một lượng lớn chức năng cần thiết trong các chương trình khi bạn cần lưu trữ, truy cập và sửa đổi dữ liệu. Đây là một số bài tập mà bạn bây giờ đã có thể giải quyết:
- Cho một danh sách các số nguyên, sử dụng vector và trả về trung vị (khi được sắp xếp, giá trị ở vị trí giữa) và mode (giá trị xuất hiện nhiều nhất; một bảng băm sẽ hữu ích ở đây) của danh sách.
- Chuyển đổi chuỗi sang pig latin. Phụ âm đầu tiên của mỗi từ được di chuyển đến cuối từ và thêm ay, vì vậy first trở thành irst-fay. Các từ bắt đầu bằng một nguyên âm được thêm hay vào cuối thay vào đó (apple trở thành apple-hay). Hãy ghi nhớ các chi tiết về mã hóa UTF-8!
- Sử dụng bảng băm và vector, tạo một giao diện văn bản để cho phép người dùng thêm tên nhân viên vào một phòng ban trong công ty; ví dụ, "Add Sally to Engineering" hoặc "Add Amir to Sales." Sau đó cho phép người dùng lấy danh sách tất cả mọi người trong một phòng ban hoặc tất cả mọi người trong công ty theo phòng ban, được sắp xếp theo thứ tự bảng chữ cái.
Tài liệu API thư viện chuẩn mô tả các phương thức mà vector, chuỗi, và bảng băm có sẽ hữu ích cho các bài tập này!
Chúng ta đang đi vào các chương trình phức tạp hơn trong đó các hoạt động có thể thất bại, vì vậy đó là thời điểm hoàn hảo để thảo luận về xử lý lỗi. Chúng ta sẽ làm điều đó tiếp theo!
Xử Lý Lỗi
Lỗi là điều không thể tránh khỏi trong phần mềm, vì vậy Rust có một số tính năng để xử lý các tình huống khi có sự cố xảy ra. Trong nhiều trường hợp, Rust yêu cầu bạn phải thừa nhận khả năng xảy ra lỗi và thực hiện một số hành động trước khi mã của bạn được biên dịch. Yêu cầu này làm cho chương trình của bạn trở nên mạnh mẽ hơn bằng cách đảm bảo rằng bạn sẽ phát hiện lỗi và xử lý chúng một cách thích hợp trước khi triển khai mã của bạn lên môi trường sản phẩm!
Rust phân loại lỗi thành hai danh mục chính: lỗi có thể khôi phục và lỗi không thể khôi phục. Đối với lỗi có thể khôi phục, chẳng hạn như lỗi không tìm thấy tệp, chúng ta rất có thể chỉ muốn báo cáo vấn đề cho người dùng và thử lại thao tác đó. Lỗi không thể khôi phục luôn là dấu hiệu của các lỗi phần mềm, chẳng hạn như cố gắng truy cập vào vị trí vượt quá giới hạn của mảng, và vì vậy chúng ta muốn dừng chương trình ngay lập tức.
Hầu hết các ngôn ngữ không phân biệt giữa hai loại lỗi này và xử lý cả hai theo
cùng một cách, sử dụng các cơ chế như exception. Rust không có exception. Thay
vào đó, nó có kiểu Result<T, E> cho lỗi có thể khôi phục và macro panic! để
dừng thực thi khi chương trình gặp lỗi không thể khôi phục. Chương này đề cập
đến việc gọi panic! trước, sau đó nói về việc trả về giá trị Result<T, E>.
Ngoài ra, chúng ta sẽ khám phá các cân nhắc khi quyết định liệu có nên cố gắng
khôi phục từ lỗi hay dừng thực thi.
Lỗi Không Thể Khôi Phục với panic!
Đôi khi những điều không mong muốn xảy ra trong code của bạn, và bạn không thể
làm gì để ngăn chặn nó. Trong những trường hợp này, Rust có macro panic!. Có
hai cách để gây ra panic trong thực tế: thực hiện một hành động khiến code của
chúng ta panic (ví dụ như truy cập vượt quá giới hạn của mảng) hoặc gọi trực
tiếp macro panic!. Trong cả hai trường hợp, chúng ta gây ra panic trong chương
trình. Theo mặc định, những panic này sẽ hiển thị thông báo lỗi, unwind (tháo
gỡ), dọn dẹp stack, và thoát. Thông qua một biến môi trường, bạn cũng có thể yêu
cầu Rust hiển thị call stack khi xảy ra panic để dễ dàng theo dõi nguồn gốc của
panic.
Tháo Gỡ Stack hoặc Hủy Bỏ Khi Xảy Ra Panic
Theo mặc định, khi panic xảy ra, chương trình bắt đầu tháo gỡ (unwinding), có nghĩa là Rust đi ngược lại stack và dọn dẹp dữ liệu từ mỗi hàm mà nó gặp phải. Tuy nhiên, việc đi ngược lại và dọn dẹp tốn rất nhiều công sức. Vì vậy, Rust cho phép bạn chọn phương án thay thế là hủy bỏ (aborting) ngay lập tức, điều này kết thúc chương trình mà không dọn dẹp gì cả.
Bộ nhớ mà chương trình đang sử dụng sau đó sẽ cần được dọn dẹp bởi hệ điều hành. Nếu trong dự án của bạn cần làm cho tệp nhị phân kết quả nhỏ nhất có thể, bạn có thể chuyển từ tháo gỡ sang hủy bỏ khi panic bằng cách thêm
panic = 'abort'vào các phần[profile]thích hợp trong tệp Cargo.toml. Ví dụ, nếu bạn muốn hủy bỏ khi panic trong chế độ phát hành (release mode), hãy thêm điều này:[profile.release] panic = 'abort'
Hãy thử gọi panic! trong một chương trình đơn giản:
fn main() { panic!("crash and burn"); }
Khi bạn chạy chương trình, bạn sẽ thấy điều gì đó như thế này:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Lệnh gọi panic! gây ra thông báo lỗi trong hai dòng cuối cùng. Dòng đầu tiên
hiển thị thông báo panic của chúng ta và vị trí trong mã nguồn nơi panic xảy ra:
src/main.rs:2:5 chỉ ra rằng đó là dòng thứ hai, ký tự thứ năm trong tệp
src/main.rs của chúng ta.
Trong trường hợp này, dòng được chỉ ra là một phần của code chúng ta, và nếu
chúng ta đến dòng đó, chúng ta sẽ thấy lời gọi macro panic!. Trong các trường
hợp khác, lời gọi panic! có thể nằm trong code mà code của chúng ta gọi, và
tên tệp và số dòng được báo cáo bởi thông báo lỗi sẽ là code của người khác nơi
macro panic! được gọi, không phải dòng code của chúng ta cuối cùng dẫn đến lời
gọi panic!.
Chúng ta có thể sử dụng backtrace của các hàm từ lời gọi panic! để tìm ra phần
code của chúng ta đang gây ra vấn đề. Để hiểu cách sử dụng backtrace của
panic!, hãy xem xét một ví dụ khác và xem nó như thế nào khi lời gọi panic!
đến từ một thư viện do lỗi trong code của chúng ta thay vì từ code của chúng ta
gọi trực tiếp macro. Listing 9-1 có một số code cố gắng truy cập một chỉ mục
trong vector vượt quá phạm vi các chỉ mục hợp lệ.
fn main() { let v = vec![1, 2, 3]; v[99]; }
Ở đây, chúng ta đang cố gắng truy cập phần tử thứ 100 của vector (ở chỉ mục 99
vì chỉ mục bắt đầu từ 0), nhưng vector chỉ có ba phần tử. Trong trường hợp này,
Rust sẽ panic. Sử dụng [] được cho là để trả về một phần tử, nhưng nếu bạn
truyền một chỉ mục không hợp lệ, không có phần tử nào mà Rust có thể trả về ở
đây một cách chính xác.
Trong C, việc cố gắng đọc vượt quá giới hạn của một cấu trúc dữ liệu là hành vi không xác định. Bạn có thể nhận được bất cứ thứ gì ở vị trí trong bộ nhớ mà sẽ tương ứng với phần tử đó trong cấu trúc dữ liệu, mặc dù bộ nhớ không thuộc về cấu trúc đó. Điều này được gọi là buffer overread (đọc quá bộ đệm) và có thể dẫn đến lỗ hổng bảo mật nếu kẻ tấn công có thể thao túng chỉ mục theo cách để đọc dữ liệu mà họ không được phép truy cập, được lưu trữ sau cấu trúc dữ liệu.
Để bảo vệ chương trình của bạn khỏi loại lỗ hổng này, nếu bạn cố gắng đọc một phần tử ở chỉ mục không tồn tại, Rust sẽ dừng thực thi và từ chối tiếp tục. Hãy thử và xem:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Lỗi này chỉ đến dòng 4 của tệp main.rs nơi chúng ta cố gắng truy cập chỉ mục
99 của vector trong v.
Dòng note: cho chúng ta biết rằng chúng ta có thể thiết lập biến môi trường
RUST_BACKTRACE để nhận backtrace chính xác về những gì đã xảy ra để gây ra
lỗi. Một backtrace là danh sách tất cả các hàm đã được gọi để đến thời điểm
này. Backtraces trong Rust hoạt động giống như trong các ngôn ngữ khác: chìa
khóa để đọc backtrace là bắt đầu từ đầu và đọc cho đến khi bạn thấy các tệp bạn
đã viết. Đó là nơi vấn đề bắt nguồn. Các dòng phía trên đó là code mà code của
bạn đã gọi; các dòng bên dưới là code đã gọi code của bạn. Các dòng trước và sau
này có thể bao gồm code Rust cốt lõi, code thư viện chuẩn, hoặc các crate mà bạn
đang sử dụng. Hãy thử lấy backtrace bằng cách thiết lập biến môi trường
RUST_BACKTRACE thành bất kỳ giá trị nào ngoại trừ 0. Listing 9-2 hiển thị
đầu ra tương tự như những gì bạn sẽ thấy.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Đó là rất nhiều thông tin! Đầu ra chính xác bạn thấy có thể khác tùy thuộc vào
hệ điều hành và phiên bản Rust của bạn. Để nhận được backtrace với thông tin
này, các ký hiệu gỡ lỗi phải được bật. Các ký hiệu gỡ lỗi được bật theo mặc định
khi sử dụng cargo build hoặc cargo run mà không có cờ --release, như chúng
ta đang làm ở đây.
Trong đầu ra ở Listing 9-2, dòng 6 của backtrace chỉ đến dòng trong dự án chúng ta đang gây ra vấn đề: dòng 4 của src/main.rs. Nếu chúng ta không muốn chương trình của chúng ta panic, chúng ta nên bắt đầu điều tra ở vị trí được chỉ ra bởi dòng đầu tiên đề cập đến tệp chúng ta đã viết. Trong Listing 9-1, nơi chúng ta cố ý viết code sẽ panic, cách để sửa panic là không yêu cầu một phần tử vượt quá phạm vi chỉ mục của vector. Khi code của bạn panic trong tương lai, bạn sẽ cần phải tìm ra hành động nào mà code đang thực hiện với những giá trị nào để gây ra panic và code nên làm gì thay thế.
Chúng ta sẽ quay lại panic! và khi nào chúng ta nên và không nên sử dụng
panic! để xử lý các điều kiện lỗi trong phần "To panic! or Not to
panic!" sau này trong chương này.
Tiếp theo, chúng ta sẽ xem xét cách khôi phục từ lỗi sử dụng Result.
Các lỗi có thể khôi phục với Result
Hầu hết các lỗi không đủ nghiêm trọng để yêu cầu chương trình dừng hoàn toàn. Đôi khi khi một hàm thất bại, đó là vì lý do mà bạn có thể dễ dàng hiểu và phản hồi. Ví dụ, nếu bạn cố mở một tập tin và thao tác đó thất bại vì tập tin không tồn tại, bạn có thể muốn tạo tập tin đó thay vì kết thúc tiến trình.
Nhắc lại từ "Xử lý thất bại tiềm ẩn với Result" trong Chương 2 rằng enum Result được định nghĩa với hai biến thể, Ok
và Err, như sau:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T và E là các tham số kiểu generic: chúng ta sẽ thảo luận chi tiết về
generics trong Chương 10. Điều bạn cần biết ngay bây giờ là T đại diện cho
kiểu của giá trị sẽ được trả về trong trường hợp thành công bên trong biến thể
Ok, và E đại diện cho kiểu của lỗi sẽ được trả về trong trường hợp thất bại
bên trong biến thể Err. Bởi vì Result có các tham số kiểu generic này, chúng
ta có thể sử dụng kiểu Result và các hàm được định nghĩa trên nó trong nhiều
tình huống khác nhau, nơi giá trị thành công và giá trị lỗi mà chúng ta muốn trả
về có thể khác nhau.
Hãy gọi một hàm trả về giá trị Result vì hàm có thể thất bại. Trong Listing
9-3, chúng ta thử mở một tập tin.
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); }
Kiểu trả về của File::open là Result<T, E>. Tham số generic T đã được điền
bởi quá trình triển khai của File::open với kiểu của giá trị thành công,
std::fs::File, là một handle của tập tin. Kiểu của E được sử dụng trong giá
trị lỗi là std::io::Error. Kiểu trả về này có nghĩa là lời gọi đến
File::open có thể thành công và trả về một handle của tập tin mà chúng ta có
thể đọc hoặc ghi. Lời gọi hàm cũng có thể thất bại: ví dụ, tập tin có thể không
tồn tại, hoặc chúng ta có thể không có quyền truy cập vào tập tin. Hàm
File::open cần có cách để nói cho chúng ta biết liệu nó đã thành công hay thất
bại và đồng thời cung cấp cho chúng ta handle của tập tin hoặc thông tin lỗi.
Thông tin này chính xác là những gì mà enum Result truyền đạt.
Trong trường hợp File::open thành công, giá trị trong biến
greeting_file_result sẽ là một thực thể của Ok chứa một handle của tập tin.
Trong trường hợp thất bại, giá trị trong greeting_file_result sẽ là một thực
thể của Err chứa thêm thông tin về loại lỗi đã xảy ra.
Chúng ta cần thêm vào mã trong Listing 9-3 để thực hiện các hành động khác nhau
tùy thuộc vào giá trị mà File::open trả về. Listing 9-4 cho thấy một cách để
xử lý Result bằng cách sử dụng công cụ cơ bản, biểu thức match mà chúng ta
đã thảo luận trong Chương 6.
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); let greeting_file = match greeting_file_result { Ok(file) => file, Err(error) => panic!("Problem opening the file: {error:?}"), }; }
Lưu ý rằng, giống như enum Option, enum Result và các biến thể của nó đã
được đưa vào phạm vi bởi prelude, vì vậy chúng ta không cần chỉ định Result::
trước các biến thể Ok và Err trong các nhánh của match.
Khi kết quả là Ok, mã này sẽ trả về giá trị file bên trong từ biến thể Ok,
và sau đó chúng ta gán giá trị handle của tập tin đó cho biến greeting_file.
Sau match, chúng ta có thể sử dụng handle của tập tin để đọc hoặc ghi.
Nhánh khác của match xử lý trường hợp chúng ta nhận được giá trị Err từ
File::open. Trong ví dụ này, chúng ta đã chọn gọi macro panic!. Nếu không có
tập tin nào có tên hello.txt trong thư mục hiện tại của chúng ta và chúng ta
chạy mã này, chúng ta sẽ thấy đầu ra sau đây từ macro panic!:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Như thường lệ, đầu ra này cho chúng ta biết chính xác điều gì đã sai.
Xử lý các lỗi khác nhau
Mã trong Listing 9-4 sẽ gọi panic! bất kể vì sao File::open thất bại. Tuy
nhiên, chúng ta muốn thực hiện các hành động khác nhau với các lý do thất bại
khác nhau. Nếu File::open thất bại vì tập tin không tồn tại, chúng ta muốn tạo
tập tin và trả về handle cho tập tin mới. Nếu File::open thất bại vì bất kỳ lý
do nào khác—ví dụ, vì chúng ta không có quyền mở tập tin—chúng ta vẫn muốn mã
gọi panic! theo cách giống như trong Listing 9-4. Để làm điều này, chúng ta
thêm một biểu thức match bên trong, như trong Listing 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}Kiểu của giá trị mà File::open trả về bên trong biến thể Err là io::Error,
đây là một struct được cung cấp bởi thư viện chuẩn. Struct này có một phương
thức kind mà chúng ta có thể gọi để lấy một giá trị io::ErrorKind. Enum
io::ErrorKind được cung cấp bởi thư viện chuẩn và có các biến thể đại diện cho
các loại lỗi khác nhau có thể phát sinh từ một thao tác io. Biến thể mà chúng
ta muốn sử dụng là ErrorKind::NotFound, cho biết tập tin mà chúng ta đang cố
gắng mở không tồn tại. Vì vậy, chúng ta khớp với greeting_file_result, nhưng
chúng ta cũng có một match bên trong trên error.kind().
Điều kiện mà chúng ta muốn kiểm tra trong match bên trong là liệu giá trị trả về
bởi error.kind() có phải là biến thể NotFound của enum ErrorKind hay
không. Nếu đúng, chúng ta cố gắng tạo tập tin với File::create. Tuy nhiên, vì
File::create cũng có thể thất bại, chúng ta cần một nhánh thứ hai trong biểu
thức match bên trong. Khi tập tin không thể được tạo, một thông báo lỗi khác
được in ra. Nhánh thứ hai của match bên ngoài không đổi, vì vậy chương trình sẽ
panic khi có bất kỳ lỗi nào khác ngoài lỗi tập tin không tồn tại.
Các lựa chọn thay thế cho việc sử dụng
matchvớiResult<T, E>
matchthật là nhiều! Biểu thứcmatchrất hữu ích nhưng cũng rất nguyên thủy. Trong Chương 13, bạn sẽ học về closures, được sử dụng với nhiều phương thức được định nghĩa trênResult<T, E>. Các phương thức này có thể ngắn gọn hơn việc sử dụngmatchkhi xử lý các giá trịResult<T, E>trong mã của bạn.Ví dụ, đây là một cách khác để viết logic tương tự như đã hiển thị trong Listing 9-5, lần này sử dụng closures và phương thức
unwrap_or_else:use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Có vấn đề khi tạo tập tin: {error:?}"); }) } else { panic!("Có vấn đề khi mở tập tin: {error:?}"); } }); }Mặc dù mã này có cùng hành vi với Listing 9-5, nhưng nó không chứa bất kỳ biểu thức
matchnào và dễ đọc hơn. Quay lại ví dụ này sau khi bạn đã đọc Chương 13, và tìm kiếm phương thứcunwrap_or_elsetrong tài liệu của thư viện chuẩn. Nhiều phương thức khác có thể làm gọn các biểu thứcmatchlồng nhau lớn khi bạn xử lý lỗi.
Các cách viết tắt cho Panic khi có lỗi: unwrap và expect
Sử dụng match hoạt động khá tốt, nhưng có thể hơi dài dòng và không phải lúc
nào cũng truyền đạt ý định rõ ràng. Kiểu Result<T, E> có nhiều phương thức trợ
giúp được định nghĩa trên nó để thực hiện các tác vụ khác nhau, cụ thể hơn.
Phương thức unwrap là một phương thức viết tắt được triển khai giống như biểu
thức match mà chúng ta đã viết trong Listing 9-4. Nếu giá trị Result là biến
thể Ok, unwrap sẽ trả về giá trị bên trong Ok. Nếu Result là biến thể
Err, unwrap sẽ gọi macro panic! cho chúng ta. Đây là một ví dụ về unwrap
đang hoạt động:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt").unwrap(); }
Nếu chúng ta chạy mã này mà không có tập tin hello.txt, chúng ta sẽ thấy một
thông báo lỗi từ lời gọi panic! mà phương thức unwrap thực hiện:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Tương tự, phương thức expect cho phép chúng ta chọn thông báo lỗi panic!. Sử
dụng expect thay vì unwrap và cung cấp thông báo lỗi tốt có thể truyền đạt ý
định của bạn và làm cho việc theo dõi nguồn gốc của một panic dễ dàng hơn. Cú
pháp của expect trông như thế này:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
Chúng ta sử dụng expect theo cách tương tự như unwrap: để trả về handle tập
tin hoặc gọi macro panic!. Thông báo lỗi được sử dụng bởi expect trong lời
gọi của nó đến panic! sẽ là tham số mà chúng ta truyền cho expect, thay vì
thông báo panic! mặc định mà unwrap sử dụng. Đây là cách nó trông:
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Trong mã chất lượng sản xuất, hầu hết các Rustacean chọn expect thay vì
unwrap và cung cấp thêm ngữ cảnh về lý do tại sao thao tác được mong đợi sẽ
luôn thành công. Bằng cách đó, nếu giả định của bạn được chứng minh là sai, bạn
có thêm thông tin để sử dụng trong việc gỡ lỗi.
Lan truyền lỗi
Khi triển khai của một hàm gọi thứ gì đó có thể thất bại, thay vì xử lý lỗi bên trong chính hàm, bạn có thể trả về lỗi cho mã gọi hàm đó để nó có thể quyết định phải làm gì. Điều này được gọi là lan truyền lỗi và cung cấp nhiều quyền kiểm soát hơn cho mã gọi hàm, nơi có thể có nhiều thông tin hoặc logic hơn để quyết định cách xử lý lỗi so với những gì bạn có sẵn trong ngữ cảnh của mã của bạn.
Ví dụ, Listing 9-6 hiển thị một hàm đọc tên người dùng từ một tập tin. Nếu tập tin không tồn tại hoặc không thể đọc được, hàm này sẽ trả về những lỗi đó cho mã đã gọi hàm.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let username_file_result = File::open("hello.txt"); let mut username_file = match username_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut username = String::new(); match username_file.read_to_string(&mut username) { Ok(_) => Ok(username), Err(e) => Err(e), } } }
Hàm này có thể được viết theo cách ngắn gọn hơn nhiều, nhưng chúng ta sẽ bắt đầu
bằng cách làm nhiều thao tác thủ công để khám phá việc xử lý lỗi; cuối cùng,
chúng ta sẽ hiển thị cách viết ngắn gọn hơn. Hãy xem xét kiểu trả về của hàm
trước: Result<String, io::Error>. Điều này có nghĩa là hàm đang trả về một giá
trị thuộc kiểu Result<T, E>, trong đó tham số generic T đã được điền với
kiểu cụ thể String và kiểu generic E đã được điền với kiểu cụ thể
io::Error.
Nếu hàm này thành công mà không có bất kỳ vấn đề nào, mã gọi hàm này sẽ nhận
được một giá trị Ok chứa một String—tên người dùng mà hàm này đã đọc từ tập
tin. Nếu hàm này gặp bất kỳ vấn đề nào, mã gọi sẽ nhận được một giá trị Err
chứa một instance của io::Error có chứa thêm thông tin về những vấn đề đã xảy
ra. Chúng ta đã chọn io::Error làm kiểu trả về của hàm này vì đó là kiểu của
giá trị lỗi được trả về từ cả hai thao tác mà chúng ta đang gọi trong thân hàm
có thể thất bại: hàm File::open và phương thức read_to_string.
Thân hàm bắt đầu bằng cách gọi hàm File::open. Sau đó, chúng ta xử lý giá trị
Result với một match tương tự như match trong Listing 9-4. Nếu
File::open thành công, handle tập tin trong biến mẫu file sẽ trở thành giá
trị trong biến có thể thay đổi username_file và hàm tiếp tục. Trong trường hợp
Err, thay vì gọi panic!, chúng ta sử dụng từ khóa return để thoát sớm khỏi
hàm hoàn toàn và truyền giá trị lỗi từ File::open, hiện đang nằm trong biến
mẫu e, trở lại cho mã gọi như là giá trị lỗi của hàm này.
Vì vậy, nếu chúng ta có một handle tập tin trong username_file, hàm tiếp theo
sẽ tạo một String mới trong biến username và gọi phương thức
read_to_string trên handle tập tin trong username_file để đọc nội dung của
tập tin vào username. Phương thức read_to_string cũng trả về một Result vì
nó có thể thất bại, ngay cả khi File::open đã thành công. Vì vậy, chúng ta cần
một match khác để xử lý Result đó: nếu read_to_string thành công, thì hàm
của chúng ta đã thành công, và chúng ta trả về tên người dùng từ tập tin hiện
đang nằm trong username được bọc trong một Ok. Nếu read_to_string thất
bại, chúng ta trả về giá trị lỗi theo cách tương tự như cách chúng ta trả về giá
trị lỗi trong match đã xử lý giá trị trả về của File::open. Tuy nhiên, chúng
ta không cần nói return một cách rõ ràng, vì đây là biểu thức cuối cùng trong
hàm.
Mã gọi mã này sẽ xử lý việc nhận giá trị Ok chứa tên người dùng hoặc giá trị
Err chứa một io::Error. Mã gọi quyết định phải làm gì với những giá trị này.
Nếu mã gọi nhận được giá trị Err, nó có thể gọi panic! và làm crash chương
trình, sử dụng một tên người dùng mặc định, hoặc tìm kiếm tên người dùng từ một
nơi khác ngoài tập tin, ví dụ vậy. Chúng ta không có đủ thông tin về những gì mã
gọi thực sự đang cố gắng làm, vì vậy chúng ta lan truyền tất cả thông tin thành
công hoặc lỗi lên trên để nó xử lý một cách phù hợp.
Mẫu lan truyền lỗi này rất phổ biến trong Rust đến nỗi Rust cung cấp toán tử dấu
hỏi ? để làm điều này dễ dàng hơn.
Một cách viết tắt để lan truyền lỗi: Toán tử ?
Listing 9-7 hiển thị một triển khai của read_username_from_file có cùng chức
năng như trong Listing 9-6, nhưng triển khai này sử dụng toán tử ?.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username_file = File::open("hello.txt")?; let mut username = String::new(); username_file.read_to_string(&mut username)?; Ok(username) } }
Dấu ? được đặt sau một giá trị Result được định nghĩa để hoạt động theo cách
gần như giống như các biểu thức match mà chúng ta đã định nghĩa để xử lý các
giá trị Result trong Listing 9-6. Nếu giá trị của Result là Ok, giá trị
bên trong Ok sẽ được trả về từ biểu thức này, và chương trình sẽ tiếp tục. Nếu
giá trị là Err, Err sẽ được trả về từ toàn bộ hàm như thể chúng ta đã sử
dụng từ khóa return để giá trị lỗi được lan truyền đến mã gọi.
Có một sự khác biệt giữa những gì mà biểu thức match từ Listing 9-6 làm và
những gì toán tử ? làm: các giá trị lỗi mà toán tử ? được gọi trên chúng đi
qua hàm from, được định nghĩa trong trait From trong thư viện chuẩn, được sử
dụng để chuyển đổi giá trị từ một kiểu sang một kiểu khác. Khi toán tử ? gọi
hàm from, kiểu lỗi nhận được được chuyển đổi thành kiểu lỗi được định nghĩa
trong kiểu trả về của hàm hiện tại. Điều này hữu ích khi một hàm trả về một kiểu
lỗi để đại diện cho tất cả các cách mà một hàm có thể thất bại, ngay cả khi các
phần có thể thất bại vì nhiều lý do khác nhau.
Ví dụ, chúng ta có thể thay đổi hàm read_username_from_file trong Listing 9-7
để trả về một kiểu lỗi tùy chỉnh có tên OurError mà chúng ta định nghĩa. Nếu
chúng ta cũng định nghĩa impl From<io::Error> for OurError để xây dựng một
instance của OurError từ một io::Error, thì các lời gọi toán tử ? trong
thân của read_username_from_file sẽ gọi from và chuyển đổi các kiểu lỗi mà
không cần thêm bất kỳ mã nào vào hàm.
Trong ngữ cảnh của Listing 9-7, dấu ? ở cuối của lời gọi File::open sẽ trả
về giá trị bên trong Ok cho biến username_file. Nếu xảy ra lỗi, toán tử ?
sẽ thoát sớm khỏi toàn bộ hàm và đưa bất kỳ giá trị Err nào cho mã gọi. Điều
tương tự cũng áp dụng cho dấu ? ở cuối lời gọi read_to_string.
Toán tử ? loại bỏ rất nhiều mã soạn sẵn và làm cho triển khai của hàm này đơn
giản hơn. Chúng ta thậm chí có thể làm cho mã này ngắn gọn hơn nữa bằng cách nối
các lời gọi phương thức ngay sau ?, như trong Listing 9-8.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username = String::new(); File::open("hello.txt")?.read_to_string(&mut username)?; Ok(username) } }
Chúng ta đã di chuyển việc tạo String mới trong username lên đầu hàm; phần
đó không thay đổi. Thay vì tạo biến username_file, chúng ta đã nối lời gọi đến
read_to_string trực tiếp vào kết quả của File::open("hello.txt")?. Chúng ta
vẫn có một dấu ? ở cuối lời gọi read_to_string, và chúng ta vẫn trả về một
giá trị Ok chứa username khi cả File::open và read_to_string đều thành
công thay vì trả về lỗi. Chức năng một lần nữa giống như trong Listing 9-6 và
Listing 9-7; đây chỉ là một cách viết khác, phong cách hơn.
Listing 9-9 hiển thị một cách để làm cho nó thậm chí còn ngắn gọn hơn bằng cách
sử dụng fs::read_to_string.
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } }
Đọc một tập tin vào một chuỗi là một hoạt động khá phổ biến, vì vậy thư viện
chuẩn cung cấp hàm fs::read_to_string thuận tiện để mở tập tin, tạo một
String mới, đọc nội dung của tập tin, đưa nội dung vào String đó, và trả về
nó. Tất nhiên, sử dụng fs::read_to_string không cho chúng ta cơ hội để giải
thích tất cả việc xử lý lỗi, vì vậy chúng ta đã làm nó theo cách dài dòng hơn
trước.
Toán tử ? có thể được sử dụng ở đâu
Toán tử ? chỉ có thể được sử dụng trong các hàm có kiểu trả về tương thích với
giá trị mà ? được sử dụng trên đó. Điều này là vì toán tử ? được định nghĩa
để thực hiện việc trả về sớm một giá trị từ hàm, theo cùng cách như biểu thức
match mà chúng ta đã định nghĩa trong Listing 9-6. Trong Listing 9-6, match
đang sử dụng một giá trị Result, và nhánh trả về sớm trả về một giá trị
Err(e). Kiểu trả về của hàm phải là một Result để nó tương thích với
return này.
Trong Listing 9-10, hãy xem lỗi mà chúng ta sẽ nhận được nếu chúng ta sử dụng
toán tử ? trong một hàm main với kiểu trả về không tương thích với kiểu của
giá trị mà chúng ta sử dụng ? trên đó:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}Mã này mở một tập tin, điều này có thể thất bại. Toán tử ? theo sau giá trị
Result được trả về bởi File::open, nhưng hàm main này có kiểu trả về là
(), không phải Result. Khi chúng ta biên dịch mã này, chúng ta nhận được
thông báo lỗi sau:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
Lỗi này chỉ ra rằng chúng ta chỉ được phép sử dụng toán tử ? trong một hàm trả
về Result, Option, hoặc một kiểu khác mà có triển khai FromResidual.
Để sửa lỗi, bạn có hai lựa chọn. Một lựa chọn là thay đổi kiểu trả về của hàm để
tương thích với giá trị mà bạn đang sử dụng toán tử ? trên đó miễn là bạn
không có hạn chế nào ngăn bạn làm điều đó. Lựa chọn khác là sử dụng match hoặc
một trong các phương thức của Result<T, E> để xử lý Result<T, E> theo cách
phù hợp.
Thông báo lỗi cũng đề cập rằng ? có thể được sử dụng với các giá trị
Option<T> cũng như. Như với việc sử dụng ? trên Result, bạn chỉ có thể sử
dụng ? trên Option trong một hàm trả về một Option. Hành vi của toán tử
? khi được gọi trên một Option<T> tương tự như hành vi của nó khi được gọi
trên một Result<T, E>: nếu giá trị là None, None sẽ được trả về sớm từ hàm
tại điểm đó. Nếu giá trị là Some, giá trị bên trong Some là giá trị kết quả
của biểu thức, và hàm tiếp tục. Listing 9-11 có một ví dụ về một hàm tìm ký tự
cuối cùng của dòng đầu tiên trong văn bản đã cho.
fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } fn main() { assert_eq!( last_char_of_first_line("Hello, world\nHow are you today?"), Some('d') ); assert_eq!(last_char_of_first_line(""), None); assert_eq!(last_char_of_first_line("\nhi"), None); }
Hàm này trả về Option<char> vì có thể có một ký tự ở đó, nhưng cũng có thể
không có. Mã này nhận tham số slice chuỗi text và gọi phương thức lines trên
nó, trả về một iterator trên các dòng trong chuỗi. Vì hàm này muốn kiểm tra dòng
đầu tiên, nó gọi next trên iterator để lấy giá trị đầu tiên từ iterator. Nếu
text là chuỗi rỗng, lời gọi này đến next sẽ trả về None, trong trường hợp
đó chúng ta sử dụng ? để dừng và trả về None từ last_char_of_first_line.
Nếu text không phải là chuỗi rỗng, next sẽ trả về một giá trị Some chứa
một slice chuỗi của dòng đầu tiên trong text.
Dấu ? trích xuất slice chuỗi, và chúng ta có thể gọi chars trên slice chuỗi
đó để lấy một iterator của các ký tự của nó. Chúng ta quan tâm đến ký tự cuối
cùng trong dòng đầu tiên này, vì vậy chúng ta gọi last để trả về mục cuối cùng
trong iterator. Đây là một Option vì có thể dòng đầu tiên là chuỗi rỗng; ví
dụ, nếu text bắt đầu bằng một dòng trống nhưng có các ký tự trên các dòng
khác, như trong "\nhi". Tuy nhiên, nếu có một ký tự cuối cùng trên dòng đầu
tiên, nó sẽ được trả về trong biến thể Some. Toán tử ? ở giữa cung cấp cho
chúng ta một cách súc tích để biểu thị logic này, cho phép chúng ta triển khai
hàm trong một dòng. Nếu chúng ta không thể sử dụng toán tử ? trên Option,
chúng ta sẽ phải triển khai logic này bằng cách sử dụng nhiều lời gọi phương
thức hơn hoặc một biểu thức match.
Lưu ý rằng bạn có thể sử dụng toán tử ? trên một Result trong một hàm trả về
Result, và bạn có thể sử dụng toán tử ? trên một Option trong một hàm trả
về Option, nhưng bạn không thể kết hợp và phù hợp. Toán tử ? sẽ không tự
động chuyển đổi một Result thành một Option hoặc ngược lại; trong những
trường hợp đó, bạn có thể sử dụng các phương thức như phương thức ok trên
Result hoặc phương thức ok_or trên Option để thực hiện chuyển đổi một cách
rõ ràng.
Cho đến nay, tất cả các hàm main mà chúng ta đã sử dụng đều trả về (). Hàm
main rất đặc biệt vì nó là điểm vào và điểm ra của một chương trình thực thi,
và có các hạn chế về kiểu trả về của nó để chương trình hoạt động như mong đợi.
May mắn thay, main cũng có thể trả về một Result<(), E>. Listing 9-12 có mã
từ Listing 9-10, nhưng chúng ta đã thay đổi kiểu trả về của main thành
Result<(), Box<dyn Error>> và đã thêm một giá trị trả về Ok(()) vào cuối. Mã
này sẽ biên dịch bây giờ.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}Kiểu Box<dyn Error> là một trait object, chúng ta sẽ nói về nó trong "Sử
dụng các Trait Object cho phép các giá trị của các kiểu khác
nhau" trong Chương 18. Hiện tại, bạn có thể đọc Box<dyn Error> như là "bất
kỳ loại lỗi nào." Sử dụng ? trên một giá trị Result trong một hàm main với
kiểu lỗi Box<dyn Error> được cho phép vì nó cho phép bất kỳ giá trị Err nào được
trả về sớm. Mặc dù thân của hàm main này sẽ chỉ trả về các lỗi của kiểu std::io::Error,
nhưng bằng cách chỉ định Box<dyn Error>, chữ ký này sẽ tiếp tục chính xác ngay
cả khi thêm mã trả về các lỗi khác được thêm vào thân của main.
Khi một hàm main trả về một Result<(), E>, chương trình thực thi sẽ thoát
với giá trị 0 nếu main trả về Ok(()) và sẽ thoát với giá trị khác 0 nếu
main trả về một giá trị Err. Các chương trình thực thi được viết bằng C trả
về số nguyên khi chúng thoát: các chương trình thoát thành công trả về số nguyên
0, và các chương trình bị lỗi trả về một số nguyên khác 0. Rust cũng trả về số
nguyên từ các chương trình thực thi để tương thích với quy ước này.
Hàm main có thể trả về bất kỳ kiểu nào triển khai trait
std::process::Termination, chứa một hàm report
trả về một ExitCode. Tham khảo tài liệu của thư viện chuẩn để biết thêm thông
tin về việc triển khai trait Termination cho các kiểu của riêng bạn.
Bây giờ chúng ta đã thảo luận về chi tiết của việc gọi panic! hoặc trả về
Result, hãy quay lại chủ đề về cách quyết định sử dụng cái nào trong trường
hợp nào.
panic! Hay Không panic!
Vậy làm thế nào để quyết định khi nào nên gọi panic! và khi nào nên trả về
Result? Khi code panic, không có cách nào để phục hồi. Bạn có thể gọi panic!
cho bất kỳ tình huống lỗi nào, dù có cách phục hồi hay không, nhưng như vậy bạn
đang đưa ra quyết định rằng một tình huống là không thể khôi phục thay mặt cho
mã gọi. Khi bạn chọn trả về giá trị Result, bạn đang cung cấp cho mã gọi các
lựa chọn. Mã gọi có thể chọn thử phục hồi theo cách phù hợp với tình huống của
nó, hoặc có thể quyết định rằng giá trị Err trong trường hợp này là không thể
khôi phục, vì vậy nó có thể gọi panic! và biến lỗi có thể khôi phục thành
không thể khôi phục. Do đó, việc trả về Result là lựa chọn mặc định tốt khi
bạn định nghĩa một hàm có thể thất bại.
Trong các tình huống như ví dụ, mã nguyên mẫu và kiểm thử, thì việc viết mã
panic thay vì trả về Result là phù hợp hơn. Hãy tìm hiểu lý do tại sao, sau đó
thảo luận về các tình huống mà trình biên dịch không thể biết thất bại là không
thể, nhưng bạn với tư cách là con người thì có thể biết. Chương này sẽ kết thúc
với một số hướng dẫn chung về cách quyết định liệu có nên panic trong mã thư
viện hay không.
Ví dụ, Mã Nguyên mẫu và Kiểm thử
Khi bạn đang viết một ví dụ để minh họa một khái niệm nào đó, việc thêm vào mã
xử lý lỗi mạnh mẽ có thể làm cho ví dụ kém rõ ràng hơn. Trong các ví dụ, mọi
người hiểu rằng việc gọi một phương thức như unwrap có thể panic là nhằm làm
giữ chỗ cho cách bạn muốn ứng dụng của mình xử lý lỗi, điều này có thể khác nhau
dựa trên những gì phần còn lại của mã bạn đang làm.
Tương tự, các phương thức unwrap và expect rất tiện lợi khi tạo nguyên mẫu,
trước khi bạn sẵn sàng quyết định cách xử lý lỗi. Chúng để lại các dấu hiệu rõ
ràng trong mã của bạn cho khi bạn sẵn sàng làm cho chương trình của mình mạnh mẽ
hơn.
Nếu một lệnh gọi phương thức thất bại trong một bài kiểm thử, bạn muốn toàn bộ
bài kiểm thử thất bại, ngay cả khi phương thức đó không phải là chức năng đang
được kiểm thử. Bởi vì panic! là cách mà một bài kiểm thử được đánh dấu là thất
bại, việc gọi unwrap hoặc expect chính xác là điều nên xảy ra.
Các trường hợp mà bạn có nhiều thông tin hơn trình biên dịch
Việc gọi expect cũng thích hợp khi bạn có một số logic khác đảm bảo rằng
Result sẽ có giá trị Ok, nhưng logic đó không phải là điều mà trình biên
dịch hiểu được. Bạn vẫn sẽ có một giá trị Result mà bạn cần xử lý: bất kỳ hoạt
động nào bạn đang gọi vẫn có khả năng thất bại nói chung, mặc dù về mặt logic
điều đó là không thể trong tình huống cụ thể của bạn. Nếu bạn có thể đảm bảo
bằng cách kiểm tra mã theo cách thủ công rằng bạn sẽ không bao giờ có biến thể
Err, thì hoàn toàn có thể chấp nhận được việc gọi expect, và thậm chí tốt
hơn là ghi lại lý do tại sao bạn nghĩ rằng bạn sẽ không bao giờ có biến thể
Err trong văn bản đối số. Đây là một ví dụ:
fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1" .parse() .expect("Hardcoded IP address should be valid"); }
Chúng ta đang tạo một thể hiện IpAddr bằng cách phân tích một chuỗi được mã
hóa cứng. Chúng ta có thể thấy rằng 127.0.0.1 là một địa chỉ IP hợp lệ, vì vậy
việc sử dụng expect là chấp nhận được ở đây. Tuy nhiên, việc có một chuỗi hợp
lệ được mã hóa cứng không thay đổi kiểu trả về của phương thức parse: chúng ta
vẫn nhận được một giá trị Result, và trình biên dịch sẽ vẫn yêu cầu chúng ta
xử lý Result như thể biến thể Err là một khả năng bởi vì trình biên dịch
không đủ thông minh để thấy rằng chuỗi này luôn là một địa chỉ IP hợp lệ. Nếu
chuỗi địa chỉ IP đến từ người dùng thay vì được mã hóa cứng vào chương trình và
do đó có khả năng thất bại, chúng ta chắc chắn sẽ muốn xử lý Result bằng một
cách mạnh mẽ hơn. Việc đề cập đến giả định rằng địa chỉ IP này được mã hóa cứng
sẽ nhắc nhở chúng ta thay đổi expect thành mã xử lý lỗi tốt hơn nếu trong
tương lai, chúng ta cần lấy địa chỉ IP từ một nguồn khác thay vì mã hóa cứng.
Hướng dẫn cho việc xử lý lỗi
Nên cho phép code của bạn panic khi có khả năng code của bạn có thể kết thúc trong một trạng thái xấu. Trong ngữ cảnh này, một trạng thái xấu là khi một số giả định, đảm bảo, hợp đồng, hoặc bất biến đã bị phá vỡ, chẳng hạn như khi các giá trị không hợp lệ, giá trị mâu thuẫn nhau, hoặc giá trị bị thiếu được truyền vào code của bạn—cộng với một hoặc nhiều điều kiện sau:
- Trạng thái xấu là điều không mong đợi, trái ngược với điều gì đó có thể xảy ra thỉnh thoảng, như người dùng nhập dữ liệu sai định dạng.
- Code của bạn sau điểm này cần dựa vào việc không ở trong trạng thái xấu này, thay vì kiểm tra vấn đề ở từng bước.
- Không có cách tốt để mã hóa thông tin này trong các kiểu dữ liệu bạn sử dụng. Chúng ta sẽ nghiên cứu một ví dụ về ý nghĩa của điều này trong "Mã hóa Trạng thái và Hành vi như Kiểu dữ liệu" trong Chương 18.
Nếu ai đó gọi code của bạn và truyền vào các giá trị không hợp lý, tốt nhất là
trả về một lỗi nếu bạn có thể để người dùng thư viện có thể quyết định họ muốn
làm gì trong trường hợp đó. Tuy nhiên, trong các trường hợp mà việc tiếp tục có
thể không an toàn hoặc có hại, lựa chọn tốt nhất có thể là gọi panic! và cảnh
báo người sử dụng thư viện của bạn về lỗi trong code của họ để họ có thể sửa nó
trong quá trình phát triển. Tương tự, panic! thường là lựa chọn phù hợp nếu
bạn đang gọi code bên ngoài mà bạn không kiểm soát được và nó trả về một trạng
thái không hợp lệ mà bạn không có cách nào để sửa chữa.
Tuy nhiên, khi thất bại là điều được mong đợi, thì việc trả về Result sẽ phù
hợp hơn là gọi panic!. Ví dụ bao gồm một trình phân tích cú pháp được cung cấp
dữ liệu không đúng định dạng hoặc một yêu cầu HTTP trả về trạng thái chỉ ra rằng
bạn đã đạt đến giới hạn tỷ lệ. Trong những trường hợp này, việc trả về Result
cho biết rằng thất bại là một khả năng được mong đợi mà mã gọi phải quyết định
cách xử lý.
Khi code của bạn thực hiện một hoạt động có thể gây rủi ro cho người dùng nếu nó
được gọi bằng các giá trị không hợp lệ, code của bạn nên xác minh các giá trị
hợp lệ trước và panic nếu các giá trị không hợp lệ. Điều này chủ yếu là vì lý do
an toàn: cố gắng hoạt động trên dữ liệu không hợp lệ có thể làm lộ code của bạn
trước các lỗ hổng. Đây là lý do chính khiến thư viện tiêu chuẩn sẽ gọi panic!
nếu bạn cố gắng truy cập bộ nhớ ngoài giới hạn: việc cố gắng truy cập bộ nhớ
không thuộc về cấu trúc dữ liệu hiện tại là một vấn đề bảo mật phổ biến. Các hàm
thường có hợp đồng: hành vi của chúng chỉ được đảm bảo nếu đầu vào đáp ứng các
yêu cầu cụ thể. Việc panic khi hợp đồng bị vi phạm là hợp lý vì vi phạm hợp đồng
luôn chỉ ra lỗi ở phía gọi, và không phải là loại lỗi mà bạn muốn mã gọi phải xử
lý một cách rõ ràng. Trên thực tế, không có cách hợp lý nào để mã gọi có thể
khôi phục; lập trình viên gọi cần sửa mã. Các hợp đồng cho một hàm, đặc biệt
là khi vi phạm sẽ gây ra panic, nên được giải thích trong tài liệu API cho hàm
đó.
Tuy nhiên, việc có nhiều kiểm tra lỗi trong tất cả các hàm của bạn sẽ dài dòng
và phiền toái. May mắn thay, bạn có thể sử dụng hệ thống kiểu của Rust (và do đó
việc kiểm tra kiểu được thực hiện bởi trình biên dịch) để thực hiện nhiều kiểm
tra cho bạn. Nếu hàm của bạn có một kiểu cụ thể làm tham số, bạn có thể tiếp tục
với logic mã của bạn, biết rằng trình biên dịch đã đảm bảo bạn có một giá trị
hợp lệ. Ví dụ, nếu bạn có một kiểu thay vì một Option, chương trình của bạn
mong đợi có cái gì đó chứ không phải không có gì. Mã của bạn sau đó không
phải xử lý hai trường hợp cho các biến thể Some và None: nó sẽ chỉ có một
trường hợp cho việc chắc chắn có một giá trị. Mã cố gắng truyền không vào hàm
của bạn sẽ thậm chí không biên dịch được, vì vậy hàm của bạn không phải kiểm tra
trường hợp đó trong thời gian chạy. Một ví dụ khác là sử dụng kiểu số nguyên
không dấu như u32, điều này đảm bảo tham số không bao giờ âm.
Tạo kiểu tùy chỉnh để xác thực
Hãy phát triển ý tưởng sử dụng hệ thống kiểu của Rust để đảm bảo chúng ta có một giá trị hợp lệ thêm một bước nữa và xem xét việc tạo một kiểu tùy chỉnh để xác thực. Hãy nhớ lại trò chơi đoán số ở Chương 2 trong đó mã của chúng ta yêu cầu người dùng đoán một số từ 1 đến 100. Chúng ta chưa bao giờ xác thực rằng số đoán của người dùng nằm giữa các số đó trước khi kiểm tra nó với số bí mật của chúng ta; chúng ta chỉ xác thực rằng số đoán là dương. Trong trường hợp này, hậu quả không quá nghiêm trọng: kết quả "Quá cao" hoặc "Quá thấp" của chúng ta vẫn sẽ chính xác. Nhưng sẽ là một cải tiến hữu ích để hướng dẫn người dùng đưa ra các đoán hợp lệ và có các hành vi khác nhau khi người dùng đoán một số ngoài phạm vi so với khi người dùng nhập, ví dụ, các chữ cái thay vì số.
Một cách để làm điều này là phân tích số đoán dưới dạng i32 thay vì chỉ là
u32 để cho phép các số âm tiềm năng, và sau đó thêm một kiểm tra xem số có nằm
trong phạm vi hay không, như sau:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Biểu thức if kiểm tra xem giá trị của chúng ta có ngoài phạm vi không, thông
báo cho người dùng về vấn đề, và gọi continue để bắt đầu vòng lặp tiếp theo và
yêu cầu một đoán khác. Sau biểu thức if, chúng ta có thể tiếp tục với các so
sánh giữa guess và số bí mật, biết rằng guess là từ 1 đến 100.
Tuy nhiên, đây không phải là một giải pháp lý tưởng: nếu điều quan trọng tuyệt đối là chương trình chỉ hoạt động trên các giá trị từ 1 đến 100, và nó có nhiều hàm với yêu cầu này, việc có một kiểm tra như thế này trong mọi hàm sẽ là tẻ nhạt (và có thể ảnh hưởng đến hiệu suất).
Thay vào đó, chúng ta có thể tạo một kiểu mới trong một module chuyên dụng và
đặt các xác thực vào một hàm để tạo một thể hiện của kiểu thay vì lặp lại các
xác thực ở khắp mọi nơi. Bằng cách này, sẽ an toàn cho các hàm sử dụng kiểu mới
trong chữ ký của chúng và tự tin sử dụng các giá trị chúng nhận được. Listing
9-13 cho thấy một cách để định nghĩa một kiểu Guess sẽ chỉ tạo một thể hiện
của Guess nếu hàm new nhận một giá trị từ 1 đến 100.
#![allow(unused)] fn main() { pub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {value}."); } Guess { value } } pub fn value(&self) -> i32 { self.value } } }
Lưu ý rằng mã này trong src/guessing_game.rs phụ thuộc vào việc thêm khai báo
module mod guessing_game; trong src/lib.rs mà chúng ta chưa hiển thị ở đây.
Trong file của module mới này, chúng ta định nghĩa một struct trong module đó có
tên Guess có một trường có tên value chứa một i32. Đây là nơi số sẽ được
lưu trữ.
Sau đó chúng ta thực hiện một hàm liên kết có tên new trên Guess tạo các thể
hiện của giá trị Guess. Hàm new được định nghĩa có một tham số có tên
value kiểu i32 và trả về một Guess. Mã trong thân hàm new kiểm tra
value để đảm bảo nó nằm trong khoảng từ 1 đến 100. Nếu value không vượt qua
bài kiểm tra này, chúng ta thực hiện lệnh gọi panic!, điều này sẽ cảnh báo lập
trình viên đang viết mã gọi rằng họ có lỗi cần sửa, vì việc tạo một Guess với
value nằm ngoài phạm vi này sẽ vi phạm hợp đồng mà Guess::new đang dựa vào.
Các điều kiện trong đó Guess::new có thể panic nên được thảo luận trong tài
liệu API hướng đến công chúng của nó; chúng ta sẽ đề cập đến các quy ước tài
liệu chỉ ra khả năng của một panic! trong tài liệu API mà bạn tạo trong
Chương 14. Nếu value vượt qua bài kiểm tra, chúng ta tạo một Guess mới với
trường value được thiết lập thành tham số value và trả về Guess.
Tiếp theo, chúng ta thực hiện một phương thức có tên value mượn self, không
có bất kỳ tham số nào khác, và trả về một i32. Loại phương thức này đôi khi
được gọi là getter vì mục đích của nó là lấy một số dữ liệu từ các trường của
nó và trả về nó. Phương thức công khai này là cần thiết vì trường value của
cấu trúc Guess là private. Điều quan trọng là trường value phải private để
mã sử dụng cấu trúc Guess không được phép đặt value trực tiếp: mã bên ngoài
module guessing_game phải sử dụng hàm Guess::new để tạo một thể hiện của
Guess, từ đó đảm bảo không có cách nào để Guess có một value chưa được
kiểm tra bởi các điều kiện trong hàm Guess::new.
Một hàm có tham số hoặc chỉ trả về số từ 1 đến 100 có thể khai báo trong chữ ký
của nó rằng nó nhận hoặc trả về một Guess thay vì một i32 và sẽ không cần
thực hiện bất kỳ kiểm tra bổ sung nào trong nội dung của nó.
Tóm tắt
Các tính năng xử lý lỗi của Rust được thiết kế để giúp bạn viết mã mạnh mẽ hơn.
Macro panic! báo hiệu rằng chương trình của bạn đang ở trạng thái mà nó không
thể xử lý và cho phép bạn yêu cầu quá trình dừng thay vì cố gắng tiếp tục với
các giá trị không hợp lệ hoặc không chính xác. Enum Result sử dụng hệ thống
kiểu của Rust để chỉ ra rằng các hoạt động có thể thất bại theo cách mà mã của
bạn có thể khôi phục từ đó. Bạn có thể sử dụng Result để nói với mã gọi mã của
bạn rằng nó cần xử lý khả năng thành công hoặc thất bại. Sử dụng panic! và
Result trong các tình huống thích hợp sẽ làm cho mã của bạn đáng tin cậy hơn
đối mặt với các vấn đề không thể tránh khỏi.
Bây giờ bạn đã thấy những cách hữu ích mà thư viện tiêu chuẩn sử dụng generics
với các enum Option và Result, chúng ta sẽ nói về cách thức hoạt động của
generics và cách bạn có thể sử dụng chúng trong mã của mình.
Các Kiểu Generic, Traits và Lifetimes
Mọi ngôn ngữ lập trình đều có công cụ để xử lý hiệu quả sự trùng lặp của các khái niệm. Trong Rust, một công cụ như vậy là generics: các đại diện trừu tượng cho các kiểu dữ liệu cụ thể hoặc các thuộc tính khác. Chúng ta có thể biểu đạt hành vi của generics hoặc cách chúng liên quan đến các generics khác mà không cần biết cái gì sẽ ở vị trí của chúng khi biên dịch và chạy mã.
Các hàm có thể nhận tham số của một số kiểu generic, thay vì một kiểu cụ thể như
i32 hoặc String, theo cách tương tự như chúng nhận tham số với giá trị không
xác định để chạy cùng một mã trên nhiều giá trị cụ thể. Thực tế, chúng ta đã sử
dụng generics trong Chương 6 với Option<T>, trong Chương 8 với Vec<T> và
HashMap<K, V>, và trong Chương 9 với Result<T, E>. Trong chương này, bạn sẽ
khám phá cách định nghĩa các kiểu, hàm và phương thức của riêng mình với
generics!
Đầu tiên chúng ta sẽ xem xét cách trích xuất một hàm để giảm sự trùng lặp mã. Sau đó chúng ta sẽ sử dụng cùng một kỹ thuật để tạo một hàm generic từ hai hàm mà chỉ khác nhau về kiểu của các tham số của chúng. Chúng ta cũng sẽ giải thích cách sử dụng các kiểu generic trong định nghĩa struct và enum.
Sau đó, bạn sẽ học cách sử dụng traits để định nghĩa hành vi theo cách generic. Bạn có thể kết hợp traits với các kiểu generic để ràng buộc một kiểu generic chỉ chấp nhận những kiểu có một hành vi cụ thể, trái ngược với việc chấp nhận bất kỳ kiểu nào.
Cuối cùng, chúng ta sẽ thảo luận về lifetimes: một loại generics cung cấp cho trình biên dịch thông tin về cách các tham chiếu liên quan đến nhau. Lifetimes cho phép chúng ta cung cấp cho trình biên dịch đủ thông tin về các giá trị được mượn để nó có thể đảm bảo các tham chiếu sẽ hợp lệ trong nhiều tình huống hơn so với khi không có sự trợ giúp của chúng ta.
Loại bỏ sự trùng lặp bằng cách trích xuất một hàm
Generics cho phép chúng ta thay thế các kiểu cụ thể bằng một giữ chỗ đại diện cho nhiều kiểu để loại bỏ sự trùng lặp mã. Trước khi đi sâu vào cú pháp generics, hãy xem trước cách loại bỏ sự trùng lặp theo cách không liên quan đến các kiểu generic bằng cách trích xuất một hàm thay thế các giá trị cụ thể bằng một giữ chỗ đại diện cho nhiều giá trị. Sau đó chúng ta sẽ áp dụng cùng một kỹ thuật để trích xuất một hàm generic! Bằng cách xem xét cách nhận biết mã trùng lặp mà bạn có thể trích xuất vào một hàm, bạn sẽ bắt đầu nhận ra mã trùng lặp có thể sử dụng generics.
Chúng ta sẽ bắt đầu với một chương trình ngắn trong Listing 10-1 tìm số lớn nhất trong một danh sách.
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); assert_eq!(*largest, 100); }
Chúng ta lưu trữ một danh sách các số nguyên trong biến number_list và đặt một
tham chiếu tới số đầu tiên trong danh sách vào một biến có tên largest. Sau đó
chúng ta lặp qua tất cả các số trong danh sách, và nếu số hiện tại lớn hơn số
được lưu trữ trong largest, chúng ta thay thế tham chiếu trong biến đó. Tuy
nhiên, nếu số hiện tại nhỏ hơn hoặc bằng số lớn nhất đã thấy cho đến nay, biến
không thay đổi, và mã chuyển sang số tiếp theo trong danh sách. Sau khi xem xét
tất cả các số trong danh sách, largest sẽ tham chiếu đến số lớn nhất, trong
trường hợp này là 100.
Giờ đây chúng ta được giao nhiệm vụ tìm số lớn nhất trong hai danh sách khác nhau của các số. Để làm điều đó, chúng ta có thể chọn sao chép mã trong Listing 10-1 và sử dụng cùng một logic tại hai vị trí khác nhau trong chương trình, như được hiển thị trong Listing 10-2.
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); }
Mặc dù mã này hoạt động, việc sao chép mã là tẻ nhạt và dễ gây lỗi. Chúng ta cũng phải nhớ cập nhật mã ở nhiều vị trí khi chúng ta muốn thay đổi nó.
Để loại bỏ sự trùng lặp này, chúng ta sẽ tạo một sự trừu tượng bằng cách định nghĩa một hàm hoạt động trên bất kỳ danh sách số nguyên nào được truyền vào dưới dạng tham số. Giải pháp này làm cho mã của chúng ta rõ ràng hơn và cho phép chúng ta biểu đạt khái niệm tìm số lớn nhất trong một danh sách một cách trừu tượng.
Trong Listing 10-3, chúng ta trích xuất mã tìm số lớn nhất vào một hàm có tên là
largest. Sau đó chúng ta gọi hàm để tìm số lớn nhất trong hai danh sách từ
Listing 10-2. Chúng ta cũng có thể sử dụng hàm này trên bất kỳ danh sách giá trị
i32 nào khác mà chúng ta có thể có trong tương lai.
fn largest(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 6000); }
Hàm largest có một tham số gọi là list, đại diện cho bất kỳ slice cụ thể nào
của các giá trị i32 mà chúng ta có thể truyền vào hàm. Kết quả là, khi chúng
ta gọi hàm, mã chạy trên các giá trị cụ thể mà chúng ta truyền vào.
Tóm lại, đây là các bước chúng ta đã thực hiện để thay đổi mã từ Listing 10-2 sang Listing 10-3:
- Xác định mã trùng lặp.
- Trích xuất mã trùng lặp vào thân hàm, và chỉ định các đầu vào và giá trị trả về của mã đó trong chữ ký hàm.
- Cập nhật hai trường hợp của mã trùng lặp để gọi hàm thay thế.
Tiếp theo, chúng ta sẽ sử dụng các bước tương tự với generics để giảm sự trùng
lặp mã. Cùng cách mà thân hàm có thể hoạt động trên một list trừu tượng thay
vì các giá trị cụ thể, generics cho phép mã hoạt động trên các kiểu trừu tượng.
Ví dụ, giả sử chúng ta có hai hàm: một hàm tìm phần tử lớn nhất trong một slice
của các giá trị i32 và một hàm tìm phần tử lớn nhất trong một slice của các
giá trị char. Làm thế nào để chúng ta loại bỏ sự trùng lặp đó? Hãy tìm hiểu!
Các Kiểu Dữ Liệu Generic
Chúng ta sử dụng generics để tạo các định nghĩa cho các thành phần như chữ ký hàm hoặc structs, mà sau đó chúng ta có thể sử dụng với nhiều kiểu dữ liệu cụ thể khác nhau. Hãy xem trước cách định nghĩa các hàm, structs, enums và phương thức sử dụng generics. Sau đó chúng ta sẽ thảo luận về cách generics ảnh hưởng đến hiệu năng mã.
Trong Định Nghĩa Hàm
Khi định nghĩa một hàm sử dụng generics, chúng ta đặt generics vào chữ ký của hàm nơi mà chúng ta thường xác định kiểu dữ liệu của các tham số và giá trị trả về. Làm như vậy giúp mã của chúng ta linh hoạt hơn và cung cấp nhiều chức năng hơn cho người gọi hàm của chúng ta đồng thời ngăn chặn trùng lặp mã.
Tiếp tục với hàm largest của chúng ta, Listing 10-4 hiển thị hai hàm mà cả hai
đều tìm giá trị lớn nhất trong một slice. Sau đó chúng ta sẽ kết hợp chúng thành
một hàm duy nhất sử dụng generics.
fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {result}"); assert_eq!(*result, 'y'); }
Hàm largest_i32 là hàm chúng ta đã trích xuất trong Listing 10-3 để tìm giá
trị i32 lớn nhất trong một slice. Hàm largest_char tìm giá trị char lớn
nhất trong một slice. Phần thân của hai hàm có cùng mã nguồn, vì vậy hãy loại bỏ
sự trùng lặp bằng cách giới thiệu một tham số kiểu generic trong một hàm duy
nhất.
Để tham số hóa các kiểu trong một hàm đơn lẻ mới, chúng ta cần đặt tên cho tham
số kiểu, giống như chúng ta làm cho các tham số giá trị cho một hàm. Bạn có thể
sử dụng bất kỳ định danh nào làm tên tham số kiểu. Nhưng chúng ta sẽ sử dụng T
vì, theo quy ước, tên tham số kiểu trong Rust thường ngắn, thường chỉ một chữ
cái, và quy ước đặt tên kiểu của Rust là CamelCase. Viết tắt của type, T là
lựa chọn mặc định của hầu hết lập trình viên Rust.
Khi chúng ta sử dụng một tham số trong thân hàm, chúng ta phải khai báo tên tham
số trong chữ ký để trình biên dịch biết tên đó có ý nghĩa gì. Tương tự, khi
chúng ta sử dụng tên tham số kiểu trong chữ ký hàm, chúng ta phải khai báo tên
tham số kiểu trước khi sử dụng nó. Để định nghĩa hàm generic largest, chúng ta
đặt khai báo tên kiểu bên trong dấu ngoặc nhọn, <>, giữa tên của hàm và danh
sách tham số, như sau:
fn largest<T>(list: &[T]) -> &T {Chúng ta đọc định nghĩa này là: hàm largest là generic trên một số kiểu T.
Hàm này có một tham số tên là list, là một slice của các giá trị của kiểu T.
Hàm largest sẽ trả về một tham chiếu đến một giá trị cùng kiểu T.
Listing 10-5 hiển thị định nghĩa hàm largest kết hợp sử dụng kiểu dữ liệu
generic trong chữ ký của nó. Listing này cũng cho thấy cách chúng ta có thể gọi
hàm với một slice của các giá trị i32 hoặc giá trị char. Lưu ý rằng mã này
sẽ không biên dịch được.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}Nếu chúng ta biên dịch mã này ngay bây giờ, chúng ta sẽ nhận được lỗi này:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Văn bản trợ giúp đề cập đến std::cmp::PartialOrd, đó là một trait, và chúng
ta sẽ nói về traits trong phần tiếp theo. Hiện tại, hãy biết rằng lỗi này cho
biết rằng phần thân của largest sẽ không hoạt động cho tất cả các kiểu có thể
của T. Bởi vì chúng ta muốn so sánh các giá trị của kiểu T trong phần thân,
chúng ta chỉ có thể sử dụng các kiểu mà các giá trị của nó có thể được sắp xếp
theo thứ tự. Để cho phép so sánh, thư viện tiêu chuẩn có trait
std::cmp::PartialOrd mà bạn có thể thực hiện trên các kiểu (xem Phụ lục C để
biết thêm về trait này). Để sửa Listing 10-5, chúng ta có thể làm theo gợi ý của
văn bản trợ giúp và giới hạn các kiểu hợp lệ cho T chỉ với những kiểu thực
hiện PartialOrd. Ví dụ này sau đó sẽ biên dịch, vì thư viện tiêu chuẩn đã thực
hiện PartialOrd cho cả i32 và char.
Trong Định Nghĩa Struct
Chúng ta cũng có thể định nghĩa structs để sử dụng tham số kiểu generic trong
một hoặc nhiều trường bằng cách sử dụng cú pháp <>. Listing 10-6 định nghĩa
một struct Point<T> để chứa các giá trị tọa độ x và y của bất kỳ kiểu nào.
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
Cú pháp để sử dụng generics trong các định nghĩa struct tương tự với cú pháp được sử dụng trong các định nghĩa hàm. Đầu tiên chúng ta khai báo tên của tham số kiểu bên trong dấu ngoặc nhọn ngay sau tên của struct. Sau đó chúng ta sử dụng kiểu generic trong định nghĩa struct ở những vị trí mà chúng ta muốn chỉ định kiểu dữ liệu cụ thể.
Lưu ý rằng vì chúng ta chỉ sử dụng một kiểu generic để định nghĩa Point<T>,
nên định nghĩa này nói rằng struct Point<T> là generic trên một số kiểu T,
và các trường x và y đều có cùng kiểu đó, bất kể kiểu đó là gì. Nếu chúng
ta tạo một thể hiện của Point<T> có giá trị của các kiểu khác nhau, như trong
Listing 10-7, mã của chúng ta sẽ không biên dịch.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}Trong ví dụ này, khi chúng ta gán giá trị số nguyên 5 cho x, chúng ta cho
trình biên dịch biết rằng kiểu generic T sẽ là một số nguyên cho thể hiện này
của Point<T>. Sau đó khi chúng ta chỉ định 4.0 cho y, mà chúng ta đã định
nghĩa là có cùng kiểu với x, chúng ta sẽ nhận được lỗi không khớp kiểu như
sau:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Để định nghĩa một struct Point trong đó x và y đều là generics nhưng có
thể có các kiểu khác nhau, chúng ta có thể sử dụng nhiều tham số kiểu generic.
Ví dụ, trong Listing 10-8, chúng ta thay đổi định nghĩa của Point để generic
trên các kiểu T và U trong đó x có kiểu T và y có kiểu U.
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
Bây giờ tất cả các thể hiện của Point được hiển thị đều được cho phép! Bạn có
thể sử dụng nhiều tham số kiểu generic trong một định nghĩa tùy thích, nhưng
việc sử dụng quá nhiều sẽ làm cho mã của bạn khó đọc. Nếu bạn thấy mình cần
nhiều kiểu generic trong mã của mình, điều đó có thể chỉ ra rằng mã của bạn cần
được cấu trúc lại thành các phần nhỏ hơn.
Trong Định Nghĩa Enum
Như chúng ta đã làm với structs, chúng ta có thể định nghĩa enums để giữ các
kiểu dữ liệu generic trong các biến thể của chúng. Hãy xem lại enum Option<T>
mà thư viện tiêu chuẩn cung cấp, mà chúng ta đã sử dụng trong Chương 6:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Định nghĩa này bây giờ nên có ý nghĩa hơn với bạn. Như bạn có thể thấy, enum
Option<T> là generic trên kiểu T và có hai biến thể: Some, mà giữ một giá
trị của kiểu T, và một biến thể None không giữ bất kỳ giá trị nào. Bằng cách
sử dụng enum Option<T>, chúng ta có thể biểu đạt khái niệm trừu tượng của một
giá trị tùy chọn, và vì Option<T> là generic, chúng ta có thể sử dụng sự trừu
tượng này bất kể kiểu của giá trị tùy chọn là gì.
Enums cũng có thể sử dụng nhiều kiểu generic. Định nghĩa của enum Result mà
chúng ta đã sử dụng trong Chương 9 là một ví dụ:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Enum Result là generic trên hai kiểu, T và E, và có hai biến thể: Ok,
giữ một giá trị của kiểu T, và Err, giữ một giá trị của kiểu E. Định nghĩa
này giúp thuận tiện để sử dụng enum Result ở bất kỳ nơi nào chúng ta có một
hoạt động có thể thành công (trả về một giá trị của một số kiểu T) hoặc thất
bại (trả về một lỗi của một số kiểu E). Trên thực tế, đây là những gì chúng ta
đã sử dụng để mở một tệp trong Listing 9-3, trong đó T được điền với kiểu
std::fs::File khi tệp được mở thành công và E được điền với kiểu
std::io::Error khi có vấn đề khi mở tệp.
Khi bạn nhận ra các tình huống trong mã của mình với nhiều định nghĩa struct hoặc enum khác nhau chỉ ở kiểu của các giá trị mà chúng chứa, bạn có thể tránh trùng lặp bằng cách sử dụng các kiểu generic thay thế.
Trong Định Nghĩa Phương Thức
Chúng ta có thể triển khai các phương thức trên structs và enums (như chúng ta
đã làm trong Chương 5) và sử dụng các kiểu generic trong các định nghĩa của
chúng. Listing 10-9 hiển thị struct Point<T> mà chúng ta đã định nghĩa trong
Listing 10-6 với một phương thức có tên x được triển khai trên nó.
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Ở đây, chúng ta đã định nghĩa một phương thức có tên x trên Point<T> trả về
một tham chiếu đến dữ liệu trong trường x.
Lưu ý rằng chúng ta phải khai báo T ngay sau impl để chúng ta có thể sử dụng
T để chỉ định rằng chúng ta đang triển khai các phương thức trên kiểu
Point<T>. Bằng cách khai báo T như là một kiểu generic sau impl, Rust có
thể xác định rằng kiểu trong dấu ngoặc nhọn trong Point là một kiểu generic
chứ không phải là một kiểu cụ thể. Chúng ta có thể đã chọn một tên khác cho tham
số generic này so với tham số generic đã khai báo trong định nghĩa struct, nhưng
việc sử dụng cùng một tên là quy ước. Nếu bạn viết một phương thức trong một
impl khai báo một kiểu generic, phương thức đó sẽ được định nghĩa trên bất kỳ
thể hiện nào của kiểu, bất kể kiểu cụ thể nào cuối cùng thay thế cho kiểu
generic.
Chúng ta cũng có thể chỉ định các ràng buộc trên các kiểu generic khi định nghĩa
các phương thức trên kiểu. Chúng ta có thể, ví dụ, triển khai các phương thức
chỉ trên các thể hiện Point<f32> thay vì trên các thể hiện Point<T> với bất
kỳ kiểu generic nào. Trong Listing 10-10, chúng ta sử dụng kiểu cụ thể f32,
nghĩa là chúng ta không khai báo bất kỳ kiểu nào sau impl.
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Mã này có nghĩa là kiểu Point<f32> sẽ có phương thức distance_from_origin;
các thể hiện khác của Point<T> mà T không phải là kiểu f32 sẽ không có
phương thức này được định nghĩa. Phương thức đo lường khoảng cách từ điểm của
chúng ta đến điểm có tọa độ (0.0, 0.0) và sử dụng các phép toán toán học là chỉ
có sẵn cho các kiểu số thực.
Các tham số kiểu generic trong định nghĩa struct không phải lúc nào cũng giống
với các tham số bạn sử dụng trong chữ ký phương thức của cùng một struct đó.
Listing 10-11 sử dụng các kiểu generic X1 và Y1 cho struct Point và X2
Y2 cho chữ ký phương thức mixup để làm cho ví dụ rõ ràng hơn. Phương thức
tạo một thể hiện Point mới với giá trị x từ Point self (kiểu X1) và
giá trị y từ Point được truyền vào (kiểu Y2).
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
Trong main, chúng ta đã định nghĩa một Point có một i32 cho x (với giá
trị 5) và một f64 cho y (với giá trị 10.4). Biến p2 là một struct
Point có một string slice cho x (với giá trị "Hello") và một char cho
y (với giá trị c). Gọi mixup trên p1 với đối số p2 cho chúng ta p3,
sẽ có một i32 cho x vì x đến từ p1. Biến p3 sẽ có một char cho y
vì y đến từ p2. Lời gọi macro println! sẽ in ra p3.x = 5, p3.y = c.
Mục đích của ví dụ này là để chứng minh một tình huống trong đó một số tham số
generic được khai báo với impl và một số được khai báo với định nghĩa phương
thức. Ở đây, các tham số generic X1 và Y1 được khai báo sau impl vì chúng
đi với định nghĩa struct. Các tham số generic X2 và Y2 được khai báo sau
fn mixup vì chúng chỉ liên quan đến phương thức.
Hiệu Năng của Mã Sử Dụng Generics
Bạn có thể tự hỏi liệu có chi phí thời gian chạy khi sử dụng các tham số kiểu generic không. Tin tốt là việc sử dụng các kiểu generic sẽ không làm cho chương trình của bạn chạy chậm hơn so với sử dụng các kiểu cụ thể.
Rust thực hiện điều này bằng cách thực hiện monomorphization của mã sử dụng generics tại thời điểm biên dịch. Monomorphization là quá trình chuyển đổi mã generic thành mã cụ thể bằng cách điền các kiểu cụ thể được sử dụng khi biên dịch. Trong quá trình này, trình biên dịch làm ngược lại các bước chúng ta đã sử dụng để tạo hàm generic trong Listing 10-5: trình biên dịch xem xét tất cả các nơi mã generic được gọi và tạo mã cho các kiểu cụ thể mà mã generic được gọi với.
Hãy xem cách hoạt động của nó bằng cách sử dụng enum generic Option<T> của thư
viện tiêu chuẩn:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
Khi Rust biên dịch mã này, nó thực hiện monomorphization. Trong quá trình đó,
trình biên dịch đọc các giá trị đã được sử dụng trong các thể hiện Option<T>
và xác định hai loại Option<T>: một là i32 và loại kia là f64. Như vậy, nó
mở rộng định nghĩa generic của Option<T> thành hai định nghĩa chuyên biệt cho
i32 và f64, từ đó thay thế định nghĩa generic bằng các định nghĩa cụ thể.
Phiên bản monomorphized của mã trông tương tự như sau (trình biên dịch sử dụng các tên khác với những gì chúng ta đang sử dụng ở đây để minh họa):
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
Option<T> generic được thay thế bằng các định nghĩa cụ thể được tạo bởi trình
biên dịch. Bởi vì Rust biên dịch mã generic thành mã chỉ định kiểu trong mỗi thể
hiện, chúng ta không phải trả chi phí thời gian chạy cho việc sử dụng generics.
Khi mã chạy, nó hoạt động giống như nếu chúng ta đã sao chép từng định nghĩa
bằng tay. Quá trình monomorphization làm cho generics của Rust cực kỳ hiệu quả
trong thời gian chạy.
Traits: Định Nghĩa Hành Vi Được Chia Sẻ
Một trait định nghĩa chức năng mà một kiểu cụ thể có và có thể chia sẻ với các kiểu khác. Chúng ta có thể sử dụng traits để định nghĩa hành vi được chia sẻ theo cách trừu tượng. Chúng ta có thể sử dụng trait bounds để chỉ định rằng một kiểu generic có thể là bất kỳ kiểu nào có hành vi nhất định.
Lưu ý: Traits tương tự với một tính năng thường được gọi là interfaces trong các ngôn ngữ khác, mặc dù có một số khác biệt.
Định Nghĩa một Trait
Hành vi của một kiểu bao gồm các phương thức mà chúng ta có thể gọi trên kiểu đó. Các kiểu khác nhau chia sẻ cùng một hành vi nếu chúng ta có thể gọi các phương thức giống nhau trên tất cả các kiểu đó. Định nghĩa trait là một cách để nhóm các chữ ký phương thức lại với nhau để định nghĩa một tập hợp các hành vi cần thiết để hoàn thành một mục đích nào đó.
Ví dụ, giả sử chúng ta có nhiều struct chứa các loại và số lượng văn bản khác
nhau: một struct NewsArticle chứa một câu chuyện tin tức được lưu trữ ở một vị
trí cụ thể và một SocialPost có thể có, nhiều nhất là 280 ký tự cùng với
metadata cho biết liệu đó là một bài viết mới, một bài đăng lại, hoặc một trả
lời cho bài viết khác.
Chúng ta muốn tạo một thư viện tổng hợp phương tiện có tên là aggregator có
thể hiển thị tóm tắt dữ liệu có thể được lưu trữ trong một thể hiện
NewsArticle hoặc SocialPost. Để làm điều này, chúng ta cần một bản tóm tắt
từ mỗi loại, và chúng ta sẽ yêu cầu bản tóm tắt đó bằng cách gọi phương thức
summarize trên một thể hiện. Listing 10-12 hiển thị định nghĩa của một trait
Summary công khai thể hiện hành vi này.
pub trait Summary {
fn summarize(&self) -> String;
}Ở đây, chúng ta khai báo một trait bằng cách sử dụng từ khóa trait và sau đó
là tên của trait, là Summary trong trường hợp này. Chúng ta cũng khai báo
trait là pub để các crate phụ thuộc vào crate này cũng có thể sử dụng trait
này, như chúng ta sẽ thấy trong một vài ví dụ. Bên trong dấu ngoặc nhọn, chúng
ta khai báo các chữ ký phương thức mô tả các hành vi của các kiểu thực hiện
trait này, trong trường hợp này là fn summarize(&self) -> String.
Sau chữ ký phương thức, thay vì cung cấp một triển khai trong dấu ngoặc nhọn,
chúng ta sử dụng dấu chấm phẩy. Mỗi kiểu triển khai trait này phải cung cấp hành
vi tùy chỉnh riêng của nó cho phần thân của phương thức. Trình biên dịch sẽ áp
dụng rằng bất kỳ kiểu nào có trait Summary sẽ phải có phương thức summarize
được định nghĩa với chữ ký này một cách chính xác.
Một trait có thể có nhiều phương thức trong thân: các chữ ký phương thức được liệt kê mỗi phương thức một dòng, và mỗi dòng kết thúc bằng dấu chấm phẩy.
Triển Khai một Trait trên một Kiểu
Bây giờ chúng ta đã định nghĩa các chữ ký mong muốn của các phương thức của
trait Summary, chúng ta có thể triển khai nó trên các kiểu trong trình tổng
hợp phương tiện của chúng ta. Listing 10-13 hiển thị một triển khai của trait
Summary trên struct NewsArticle sử dụng tiêu đề, tác giả và vị trí để tạo
giá trị trả về của summarize. Đối với struct SocialPost, chúng ta định nghĩa
summarize là tên người dùng theo sau là toàn bộ văn bản của bài viết, giả định
rằng nội dung bài viết đã giới hạn ở 280 ký tự.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Triển khai một trait trên một kiểu tương tự như triển khai các phương thức thông
thường. Sự khác biệt là sau impl, chúng ta đặt tên trait mà chúng ta muốn
triển khai, sau đó sử dụng từ khóa for, và sau đó chỉ định tên của kiểu mà
chúng ta muốn triển khai trait cho. Trong khối impl, chúng ta đặt các chữ ký
phương thức mà định nghĩa trait đã định nghĩa. Thay vì thêm dấu chấm phẩy sau
mỗi chữ ký, chúng ta sử dụng dấu ngoặc nhọn và điền vào phần thân phương thức
với hành vi cụ thể mà chúng ta muốn các phương thức của trait có đối với kiểu cụ
thể.
Bây giờ thư viện đã triển khai trait Summary trên NewsArticle và
SocialPost, người dùng của crate có thể gọi các phương thức trait trên các thể
hiện của NewsArticle và SocialPost giống như cách chúng ta gọi các phương
thức thông thường. Sự khác biệt duy nhất là người dùng phải đưa trait vào phạm
vi cũng như các kiểu. Đây là một ví dụ về cách một binary crate có thể sử dụng
thư viện aggregator của chúng ta:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Mã này in ra
1 new post: horse_ebooks: of course, as you probably already know, people.
Các crate khác phụ thuộc vào crate aggregator cũng có thể đưa trait Summary
vào phạm vi để triển khai Summary trên các kiểu riêng của họ. Một hạn chế cần
lưu ý là chúng ta chỉ có thể triển khai một trait trên một kiểu nếu hoặc trait
hoặc kiểu, hoặc cả hai, là local đối với crate của chúng ta. Ví dụ, chúng ta có
thể triển khai các trait của thư viện tiêu chuẩn như Display trên một kiểu tùy
chỉnh như SocialPost như một phần của chức năng crate aggregator của chúng
ta vì kiểu SocialPost là local đối với crate aggregator của chúng ta. Chúng
ta cũng có thể triển khai Summary trên Vec<T> trong crate aggregator của
chúng ta vì trait Summary là local đối với crate aggregator của chúng ta.
Nhưng chúng ta không thể triển khai các trait bên ngoài trên các kiểu bên ngoài.
Ví dụ, chúng ta không thể triển khai trait Display trên Vec<T> trong crate
aggregator của chúng ta vì Display và Vec<T> đều được định nghĩa trong thư
viện tiêu chuẩn và không local đối với crate aggregator của chúng ta. Hạn chế
này là một phần của thuộc tính được gọi là coherence, và cụ thể hơn là quy
tắc mồ côi, được đặt tên như vậy bởi vì kiểu cha không có mặt. Quy tắc này đảm
bảo rằng mã của người khác không thể phá vỡ mã của bạn và ngược lại. Nếu không
có quy tắc này, hai crate có thể triển khai cùng một trait cho cùng một kiểu, và
Rust sẽ không biết triển khai nào để sử dụng.
Các Triển Khai Mặc Định
Đôi khi việc có hành vi mặc định cho một số hoặc tất cả các phương thức trong một trait thay vì yêu cầu triển khai cho tất cả các phương thức trên mọi kiểu là hữu ích. Sau đó, khi chúng ta triển khai trait trên một kiểu cụ thể, chúng ta có thể giữ nguyên hoặc ghi đè hành vi mặc định của từng phương thức.
Trong Listing 10-14, chúng ta chỉ định một chuỗi mặc định cho phương thức
summarize của trait Summary thay vì chỉ định nghĩa chữ ký phương thức, như
chúng ta đã làm trong Listing 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Để sử dụng một triển khai mặc định để tóm tắt các thể hiện của NewsArticle,
chúng ta chỉ định một khối impl trống với impl Summary for NewsArticle {}.
Mặc dù chúng ta không còn định nghĩa phương thức summarize trên NewsArticle
trực tiếp, chúng ta đã cung cấp một triển khai mặc định và chỉ định rằng
NewsArticle triển khai trait Summary. Kết quả là, chúng ta vẫn có thể gọi
phương thức summarize trên một thể hiện của NewsArticle, như thế này:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}Mã này in ra New article available! (Read more...).
Việc tạo một triển khai mặc định không yêu cầu chúng ta thay đổi bất cứ điều gì
về việc triển khai Summary trên SocialPost trong Listing 10-13. Lý do là cú
pháp để ghi đè một triển khai mặc định giống với cú pháp để triển khai một
phương thức trait không có triển khai mặc định.
Các triển khai mặc định có thể gọi các phương thức khác trong cùng trait, ngay
cả khi những phương thức khác đó không có triển khai mặc định. Bằng cách này,
một trait có thể cung cấp nhiều chức năng hữu ích và chỉ yêu cầu những người
triển khai chỉ định một phần nhỏ của nó. Ví dụ, chúng ta có thể định nghĩa trait
Summary có một phương thức summarize_author mà triển khai của nó là bắt
buộc, và sau đó định nghĩa một phương thức summarize có triển khai mặc định
gọi phương thức summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Để sử dụng phiên bản này của Summary, chúng ta chỉ cần định nghĩa
summarize_author khi triển khai trait trên một kiểu:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Sau khi chúng ta định nghĩa summarize_author, chúng ta có thể gọi summarize
trên các thể hiện của struct SocialPost, và triển khai mặc định của
summarize sẽ gọi định nghĩa của summarize_author mà chúng ta đã cung cấp.
Bởi vì chúng ta đã triển khai summarize_author, trait Summary đã cung cấp
cho chúng ta hành vi của phương thức summarize mà không yêu cầu chúng ta viết
thêm bất kỳ mã nào. Đây là cách nó hoạt động:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Mã này in ra 1 new post: (Read more from @horse_ebooks...).
Lưu ý rằng không thể gọi triển khai mặc định từ một triển khai ghi đè của cùng một phương thức.
Traits như Tham Số
Bây giờ bạn đã biết cách định nghĩa và triển khai traits, chúng ta có thể khám
phá cách sử dụng traits để định nghĩa các hàm chấp nhận nhiều kiểu khác nhau.
Chúng ta sẽ sử dụng trait Summary mà chúng ta đã triển khai trên các kiểu
NewsArticle và SocialPost trong Listing 10-13 để định nghĩa một hàm notify
gọi phương thức summarize trên tham số item của nó, là một kiểu nào đó triển
khai trait Summary. Để làm điều này, chúng ta sử dụng cú pháp impl Trait,
như thế này:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}Thay vì một kiểu cụ thể cho tham số item, chúng ta chỉ định từ khóa impl và
tên trait. Tham số này chấp nhận bất kỳ kiểu nào triển khai trait được chỉ định.
Trong thân của notify, chúng ta có thể gọi bất kỳ phương thức nào trên item
mà đến từ trait Summary, chẳng hạn như summarize. Chúng ta có thể gọi
notify và truyền vào bất kỳ thể hiện nào của NewsArticle hoặc SocialPost.
Mã gọi hàm với bất kỳ kiểu nào khác, chẳng hạn như String hoặc i32, sẽ không
biên dịch vì các kiểu đó không triển khai Summary.
Cú Pháp Trait Bound
Cú pháp impl Trait hoạt động cho các trường hợp đơn giản nhưng thực sự là cú
pháp đường tắt cho một hình thức dài hơn được gọi là trait bound; nó trông như
thế này:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}Hình thức dài hơn này tương đương với ví dụ trong phần trước nhưng dài dòng hơn. Chúng ta đặt các trait bound với khai báo của tham số kiểu generic sau dấu hai chấm và bên trong dấu ngoặc nhọn.
Cú pháp impl Trait thuận tiện và tạo ra mã ngắn gọn hơn trong các trường hợp
đơn giản, trong khi cú pháp trait bound đầy đủ hơn có thể biểu đạt phức tạp hơn
trong các trường hợp khác. Ví dụ, chúng ta có thể có hai tham số triển khai
Summary. Thực hiện điều này với cú pháp impl Trait trông như thế này:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Sử dụng impl Trait là phù hợp nếu chúng ta muốn hàm này cho phép item1 và
item2 có các kiểu khác nhau (miễn là cả hai kiểu đều triển khai Summary).
Nếu chúng ta muốn buộc cả hai tham số phải có cùng kiểu, tuy nhiên, chúng ta
phải sử dụng một trait bound, như thế này:
pub fn notify<T: Summary>(item1: &T, item2: &T) {Kiểu generic T được chỉ định làm kiểu của các tham số item1 và item2 ràng
buộc hàm sao cho kiểu cụ thể của giá trị được truyền dưới dạng đối số cho
item1 và item2 phải giống nhau.
Chỉ Định Nhiều Trait Bounds với Cú Pháp +
Chúng ta cũng có thể chỉ định nhiều hơn một trait bound. Giả sử chúng ta muốn
notify sử dụng định dạng hiển thị cũng như summarize trên item: chúng ta
chỉ định trong định nghĩa notify rằng item phải triển khai cả Display và
Summary. Chúng ta có thể làm như vậy bằng cách sử dụng cú pháp +:
pub fn notify(item: &(impl Summary + Display)) {Cú pháp + cũng hợp lệ với trait bounds trên các kiểu generic:
pub fn notify<T: Summary + Display>(item: &T) {Với hai trait bounds đã được chỉ định, thân của notify có thể gọi summarize
và sử dụng {} để định dạng item.
Trait Bounds Rõ Ràng Hơn với Mệnh Đề where
Việc sử dụng quá nhiều trait bounds có nhược điểm. Mỗi generic có trait bound
riêng của nó, vì vậy các hàm với nhiều tham số kiểu generic có thể chứa rất
nhiều thông tin trait bound giữa tên của hàm và danh sách tham số của nó, làm
cho chữ ký hàm khó đọc. Vì lý do này, Rust có cú pháp thay thế để chỉ định trait
bounds bên trong một mệnh đề where sau chữ ký hàm. Vì vậy, thay vì viết như
thế này:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {chúng ta có thể sử dụng một mệnh đề where, như thế này:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Chữ ký của hàm này ít rối hơn: tên hàm, danh sách tham số, và kiểu trả về ở gần nhau, tương tự như một hàm không có nhiều trait bounds.
Trả Về các Kiểu Triển Khai Traits
Chúng ta cũng có thể sử dụng cú pháp impl Trait ở vị trí trả về để trả về một
giá trị của một số kiểu triển khai một trait, như được hiển thị ở đây:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}Bằng cách sử dụng impl Summary cho kiểu trả về, chúng ta chỉ định rằng hàm
returns_summarizable trả về một số kiểu triển khai trait Summary mà không
cần đặt tên kiểu cụ thể. Trong trường hợp này, returns_summarizable trả về một
SocialPost, nhưng mã gọi hàm này không cần biết điều đó.
Khả năng chỉ định một kiểu trả về chỉ bằng trait mà nó triển khai đặc biệt hữu
ích trong ngữ cảnh của closures và iterators, mà chúng ta sẽ đề cập trong
Chương 13. Closures và iterators tạo ra các kiểu mà chỉ trình biên dịch biết
hoặc các kiểu rất dài để chỉ định. Cú pháp impl Trait cho phép bạn ngắn gọn
chỉ định rằng một hàm trả về một số kiểu triển khai trait Iterator mà không
cần viết ra một kiểu rất dài.
Tuy nhiên, bạn chỉ có thể sử dụng impl Trait nếu bạn đang trả về một kiểu duy
nhất. Ví dụ, mã này trả về một NewsArticle hoặc một SocialPost với kiểu trả
về được chỉ định là impl Summary sẽ không hoạt động:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}Việc trả về một NewsArticle hoặc một SocialPost không được phép do các hạn
chế xung quanh cách cú pháp impl Trait được triển khai trong trình biên dịch.
Chúng ta sẽ đề cập đến cách viết một hàm với hành vi này trong phần "Sử dụng
Trait Objects Cho Phép các Giá Trị của Các Kiểu Khác
Nhau" của Chương 18.
Sử Dụng Trait Bounds để Triển Khai Các Phương Thức Có Điều Kiện
Bằng cách sử dụng một trait bound với một khối impl sử dụng các tham số kiểu
generic, chúng ta có thể triển khai các phương thức có điều kiện cho các kiểu
triển khai các traits được chỉ định. Ví dụ, kiểu Pair<T> trong Listing 10-15
luôn triển khai hàm new để trả về một thể hiện mới của Pair<T> (nhớ lại từ
phần "Định Nghĩa Phương Thức" của Chương 5 rằng Self
là một bí danh kiểu cho kiểu của khối impl, trong trường hợp này là
Pair<T>). Nhưng trong khối impl tiếp theo, Pair<T> chỉ triển khai phương
thức cmp_display nếu kiểu bên trong T của nó triển khai trait PartialOrd
cho phép so sánh và trait Display cho phép in.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}Chúng ta cũng có thể triển khai có điều kiện một trait cho bất kỳ kiểu nào triển
khai một trait khác. Việc triển khai một trait trên bất kỳ kiểu nào thỏa mãn các
trait bounds được gọi là blanket implementations và được sử dụng rộng rãi
trong thư viện tiêu chuẩn Rust. Ví dụ, thư viện tiêu chuẩn triển khai trait
ToString trên bất kỳ kiểu nào triển khai trait Display. Khối impl trong
thư viện tiêu chuẩn trông tương tự như mã này:
impl<T: Display> ToString for T {
// --snip--
}Bởi vì thư viện tiêu chuẩn có blanket implementation này, chúng ta có thể gọi
phương thức to_string được định nghĩa bởi trait ToString trên bất kỳ kiểu
nào triển khai trait Display. Ví dụ, chúng ta có thể chuyển các số nguyên
thành các giá trị String tương ứng của chúng như thế này vì số nguyên triển
khai Display:
#![allow(unused)] fn main() { let s = 3.to_string(); }
Các blanket implementation xuất hiện trong tài liệu của trait trong phần "Implementors".
Traits và trait bounds cho phép chúng ta viết mã sử dụng các tham số kiểu generic để giảm sự trùng lặp nhưng cũng chỉ định cho trình biên dịch rằng chúng ta muốn kiểu generic có hành vi cụ thể. Trình biên dịch sau đó có thể sử dụng thông tin trait bound để kiểm tra rằng tất cả các kiểu cụ thể được sử dụng với mã của chúng ta cung cấp hành vi chính xác. Trong các ngôn ngữ kiểu động, chúng ta sẽ gặp lỗi tại thời điểm chạy nếu chúng ta gọi một phương thức trên một kiểu không định nghĩa phương thức đó. Nhưng Rust chuyển các lỗi này sang thời điểm biên dịch để chúng ta buộc phải sửa các vấn đề trước khi mã của chúng ta thậm chí có thể chạy. Ngoài ra, chúng ta không phải viết mã kiểm tra hành vi tại thời điểm chạy vì chúng ta đã kiểm tra tại thời điểm biên dịch. Làm như vậy cải thiện hiệu suất mà không phải từ bỏ tính linh hoạt của generics.
Xác thực tham chiếu với Lifetimes
Lifetimes (thời gian sống) là một loại generic khác mà chúng ta đã sử dụng. Thay vì đảm bảo rằng một kiểu có hành vi chúng ta mong muốn, lifetimes đảm bảo rằng các tham chiếu hợp lệ miễn là chúng ta cần chúng.
Một chi tiết chúng ta chưa thảo luận trong phần "Tham chiếu và Mượn" ở Chương 4 là mỗi tham chiếu trong Rust có một lifetime, là phạm vi mà tham chiếu đó có hiệu lực. Hầu hết thời gian, lifetimes được ngầm định và suy luận, giống như hầu hết thời gian, các kiểu được suy luận. Chúng ta chỉ bị yêu cầu chú thích kiểu khi nhiều kiểu có thể áp dụng. Tương tự, chúng ta phải chú thích lifetimes khi lifetimes của các tham chiếu có thể liên quan theo một số cách khác nhau. Rust yêu cầu chúng ta chú thích các mối quan hệ bằng các tham số lifetime generic để đảm bảo các tham chiếu thực tế được sử dụng trong thời gian chạy chắc chắn sẽ hợp lệ.
Việc chú thích lifetimes thậm chí không phải là một khái niệm mà hầu hết các ngôn ngữ lập trình khác có, vì vậy điều này sẽ cảm thấy không quen thuộc. Mặc dù chúng ta sẽ không bao quát lifetimes một cách đầy đủ trong chương này, chúng ta sẽ thảo luận về các cách phổ biến mà bạn có thể gặp cú pháp lifetime để bạn có thể làm quen với khái niệm này.
Ngăn chặn Dangling References (Tham chiếu treo) với Lifetimes
Mục đích chính của lifetimes là ngăn chặn dangling references, gây ra cho chương trình tham chiếu đến dữ liệu khác với dữ liệu mà nó dự định tham chiếu. Hãy xem xét chương trình trong Listing 10-16, có một phạm vi ngoài và một phạm vi trong.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Lưu ý: Các ví dụ trong Listings 10-16, 10-17, và 10-23 khai báo các biến mà không cung cấp giá trị ban đầu, vì vậy tên biến tồn tại trong phạm vi ngoài. Thoạt nhìn, điều này có thể xuất hiện mâu thuẫn với việc Rust không có giá trị null. Tuy nhiên, nếu chúng ta cố gắng sử dụng một biến trước khi gán giá trị cho nó, chúng ta sẽ nhận được lỗi biên dịch, điều này cho thấy rằng Rust thực sự không cho phép giá trị null.
Phạm vi ngoài khai báo một biến tên r không có giá trị ban đầu, và phạm vi
trong khai báo một biến tên x với giá trị ban đầu là 5. Bên trong phạm vi
trong, chúng ta cố gắng đặt giá trị của r là một tham chiếu đến x. Sau đó
phạm vi trong kết thúc, và chúng ta cố gắng in giá trị trong r. Mã này sẽ
không biên dịch vì giá trị mà r đang tham chiếu đã ra khỏi phạm vi trước khi
chúng ta cố gắng sử dụng nó. Đây là thông báo lỗi:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Thông báo lỗi nói rằng biến x "không sống đủ lâu." Lý do là x sẽ ra khỏi
phạm vi khi phạm vi trong kết thúc ở dòng 7. Nhưng r vẫn hợp lệ cho phạm vi
ngoài; vì phạm vi của nó lớn hơn, chúng ta nói rằng nó "sống lâu hơn." Nếu Rust
cho phép mã này hoạt động, r sẽ tham chiếu đến bộ nhớ đã bị giải phóng khi x
ra khỏi phạm vi, và bất cứ điều gì chúng ta cố gắng làm với r sẽ không hoạt
động đúng. Vậy làm thế nào Rust xác định rằng mã này không hợp lệ? Nó sử dụng
một borrow checker.
Borrow Checker (Kiểm tra Mượn)
Trình biên dịch Rust có một borrow checker so sánh phạm vi để xác định liệu tất cả các mượn có hợp lệ hay không. Listing 10-17 hiển thị cùng một mã như Listing 10-16 nhưng có chú thích hiển thị lifetimes của các biến.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+Ở đây, chúng ta đã chú thích lifetime của r với 'a và lifetime của x với
'b. Như bạn có thể thấy, khối 'b bên trong nhỏ hơn nhiều so với khối
lifetime 'a bên ngoài. Tại thời điểm biên dịch, Rust so sánh kích thước của
hai lifetimes và thấy rằng r có lifetime là 'a nhưng nó tham chiếu đến bộ
nhớ với lifetime là 'b. Chương trình bị từ chối vì 'b ngắn hơn 'a: chủ thể
của tham chiếu không sống lâu bằng tham chiếu.
Listing 10-18 sửa mã để nó không có dangling reference và nó biên dịch mà không có bất kỳ lỗi nào.
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {r}"); // | | // --+ | } // ----------+
Ở đây, x có lifetime 'b, trong trường hợp này lớn hơn 'a. Điều này có
nghĩa là r có thể tham chiếu x vì Rust biết rằng tham chiếu trong r sẽ
luôn hợp lệ trong khi x hợp lệ.
Bây giờ bạn đã biết lifetimes của tham chiếu ở đâu và cách Rust phân tích lifetimes để đảm bảo tham chiếu sẽ luôn hợp lệ, hãy khám phá generic lifetimes của tham số và giá trị trả về trong bối cảnh của các hàm.
Generic Lifetimes trong Hàm
Chúng ta sẽ viết một hàm trả về slice chuỗi dài hơn trong hai slice chuỗi. Hàm
này sẽ nhận hai slice chuỗi và trả về một slice chuỗi. Sau khi chúng ta đã triển
khai hàm longest, mã trong Listing 10-19 sẽ in ra
The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}Lưu ý rằng chúng ta muốn hàm nhận slice chuỗi, là tham chiếu, thay vì chuỗi, vì
chúng ta không muốn hàm longest lấy quyền sở hữu các tham số của nó. Tham khảo
"String Slices as Parameters"
trong Chương 4 để biết thêm thảo luận về lý do tại sao các tham số chúng ta sử
dụng trong Listing 10-19 là những tham số mà chúng ta muốn.
Nếu chúng ta cố gắng triển khai hàm longest như trong Listing 10-20, nó sẽ
không biên dịch.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}Thay vào đó, chúng ta nhận được lỗi sau nói về lifetimes:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Văn bản trợ giúp tiết lộ rằng kiểu trả về cần một tham số lifetime generic vì
Rust không thể biết liệu tham chiếu được trả về tham chiếu đến x hay y. Thực
tế, chúng ta cũng không biết, vì khối if trong thân của hàm này trả về một
tham chiếu đến x và khối else trả về một tham chiếu đến y!
Khi chúng ta định nghĩa hàm này, chúng ta không biết các giá trị cụ thể sẽ được
truyền vào hàm này, vì vậy chúng ta không biết liệu trường hợp if hay trường
hợp else sẽ được thực thi. Chúng ta cũng không biết lifetimes cụ thể của các
tham chiếu sẽ được truyền vào, vì vậy chúng ta không thể xem xét phạm vi như
chúng ta đã làm trong Listing 10-17 và 10-18 để xác định liệu tham chiếu chúng
ta trả về sẽ luôn hợp lệ hay không. Borrow checker cũng không thể xác định điều
này, bởi vì nó không biết lifetimes của x và y liên quan đến lifetime của
giá trị trả về như thế nào. Để sửa lỗi này, chúng ta sẽ thêm tham số lifetime
generic xác định mối quan hệ giữa các tham chiếu để borrow checker có thể thực
hiện phân tích của nó.
Cú pháp Chú thích Lifetime
Chú thích lifetime không thay đổi thời gian tồn tại của bất kỳ tham chiếu nào. Thay vào đó, chúng mô tả mối quan hệ của lifetimes của nhiều tham chiếu với nhau mà không ảnh hưởng đến lifetimes. Giống như các hàm có thể chấp nhận bất kỳ kiểu nào khi chữ ký chỉ định một tham số kiểu generic, các hàm có thể chấp nhận tham chiếu với bất kỳ lifetime nào bằng cách chỉ định một tham số lifetime generic.
Chú thích lifetime có cú pháp hơi khác thường: tên của tham số lifetime phải bắt
đầu bằng dấu nháy đơn (') và thường đều viết thường và rất ngắn, giống như các
kiểu generic. Hầu hết mọi người sử dụng tên 'a cho chú thích lifetime đầu
tiên. Chúng ta đặt chú thích tham số lifetime sau dấu & của tham chiếu, sử
dụng khoảng cách để phân tách chú thích khỏi kiểu của tham chiếu.
Đây là một số ví dụ: một tham chiếu đến i32 không có tham số lifetime, một
tham chiếu đến i32 có tham số lifetime tên 'a, và một tham chiếu có thể thay
đổi đến i32 cũng có lifetime 'a.
&i32 // một tham chiếu
&'a i32 // một tham chiếu với lifetime rõ ràng
&'a mut i32 // một tham chiếu có thể thay đổi với lifetime rõ ràngMột chú thích lifetime tự nó không có nhiều ý nghĩa vì các chú thích được dùng
để nói với Rust cách các tham số lifetime generic của nhiều tham chiếu liên quan
đến nhau. Hãy xem xét cách chú thích lifetime liên quan đến nhau trong bối cảnh
của hàm longest.
Chú thích Lifetime trong Chữ ký Hàm
Để sử dụng chú thích lifetime trong chữ ký hàm, chúng ta cần khai báo các tham số lifetime generic bên trong dấu ngoặc nhọn giữa tên hàm và danh sách tham số, giống như chúng ta đã làm với tham số kiểu generic.
Chúng ta muốn chữ ký thể hiện ràng buộc sau: tham chiếu trả về sẽ hợp lệ miễn là
cả hai tham số đều hợp lệ. Đây là mối quan hệ giữa lifetimes của tham số và giá
trị trả về. Chúng ta sẽ đặt tên lifetime là 'a và sau đó thêm nó vào mỗi tham
chiếu, như trong Listing 10-21.
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Mã này nên biên dịch và tạo ra kết quả chúng ta muốn khi chúng ta sử dụng nó với
hàm main trong Listing 10-19.
Chữ ký hàm bây giờ nói với Rust rằng đối với một lifetime 'a nào đó, hàm nhận
hai tham số, cả hai đều là slice chuỗi sống ít nhất là lifetime 'a. Chữ ký hàm
cũng nói với Rust rằng slice chuỗi được trả về từ hàm sẽ sống ít nhất là
lifetime 'a. Trong thực tế, điều này có nghĩa là lifetime của tham chiếu được
trả về bởi hàm longest giống như lifetime nhỏ hơn của các giá trị được tham
chiếu bởi các đối số hàm. Đây là những mối quan hệ mà chúng ta muốn Rust sử dụng
khi phân tích mã này.
Hãy nhớ rằng, khi chúng ta chỉ định tham số lifetime trong chữ ký hàm này, chúng
ta không thay đổi lifetimes của bất kỳ giá trị nào được truyền vào hoặc trả về.
Thay vào đó, chúng ta đang chỉ định rằng borrow checker nên từ chối bất kỳ giá
trị nào không tuân theo các ràng buộc này. Lưu ý rằng hàm longest không cần
biết chính xác x và y sẽ sống bao lâu, chỉ cần một phạm vi có thể được thay
thế cho 'a sẽ thỏa mãn chữ ký này.
Khi chú thích lifetimes trong hàm, các chú thích được đặt trong chữ ký hàm, không phải trong thân hàm. Các chú thích lifetime trở thành một phần của hợp đồng của hàm, giống như các kiểu trong chữ ký. Việc có chữ ký hàm chứa hợp đồng lifetime có nghĩa là việc phân tích mà trình biên dịch Rust thực hiện có thể đơn giản hơn. Nếu có vấn đề với cách một hàm được chú thích hoặc cách nó được gọi, lỗi của trình biên dịch có thể chỉ ra phần mã của chúng ta và các ràng buộc chính xác hơn. Nếu, thay vào đó, trình biên dịch Rust đưa ra nhiều suy luận hơn về những gì chúng ta dự định mối quan hệ của lifetimes sẽ như thế nào, trình biên dịch có thể chỉ có khả năng chỉ ra việc sử dụng mã của chúng ta nhiều bước cách xa nguyên nhân của vấn đề.
Khi chúng ta truyền các tham chiếu cụ thể cho longest, lifetime cụ thể được
thay thế cho 'a là phần của phạm vi của x trùng với phạm vi của y. Nói
cách khác, lifetime generic 'a sẽ nhận lifetime cụ thể bằng với lifetime nhỏ
hơn của x và y. Bởi vì chúng ta đã chú thích tham chiếu được trả về với cùng
tham số lifetime 'a, tham chiếu được trả về cũng sẽ hợp lệ cho độ dài của
lifetime nhỏ hơn của x và y.
Hãy xem cách các chú thích lifetime hạn chế hàm longest bằng cách truyền vào
các tham chiếu có lifetimes cụ thể khác nhau. Listing 10-22 là một ví dụ đơn
giản.
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {result}"); } } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Trong ví dụ này, string1 hợp lệ cho đến khi kết thúc phạm vi ngoài, string2
hợp lệ cho đến khi kết thúc phạm vi trong, và result tham chiếu đến một thứ
hợp lệ cho đến khi kết thúc phạm vi trong. Chạy mã này và bạn sẽ thấy rằng
borrow checker chấp thuận; nó sẽ biên dịch và in
The longest string is long string is long.
Tiếp theo, hãy thử một ví dụ cho thấy rằng lifetime của tham chiếu trong
result phải là lifetime nhỏ hơn của hai đối số. Chúng ta sẽ di chuyển khai báo
biến result ra ngoài phạm vi trong nhưng để việc gán giá trị cho biến result
bên trong phạm vi với string2. Sau đó, chúng ta sẽ di chuyển println! sử
dụng result ra ngoài phạm vi trong, sau khi phạm vi trong đã kết thúc. Mã
trong Listing 10-23 sẽ không biên dịch.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Khi chúng ta cố gắng biên dịch mã này, chúng ta nhận được lỗi này:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Lỗi cho thấy rằng để result hợp lệ cho câu lệnh println!, string2 cần hợp
lệ cho đến khi kết thúc phạm vi ngoài. Rust biết điều này vì chúng ta đã chú
thích lifetimes của tham số hàm và giá trị trả về bằng cùng một tham số lifetime
'a.
Với tư cách là con người, chúng ta có thể nhìn vào mã này và thấy rằng string1
dài hơn string2, và do đó result sẽ chứa một tham chiếu đến string1. Bởi
vì string1 chưa ra khỏi phạm vi, một tham chiếu đến string1 vẫn sẽ hợp lệ
cho câu lệnh println!. Tuy nhiên, trình biên dịch không thể thấy rằng tham
chiếu hợp lệ trong trường hợp này. Chúng ta đã nói với Rust rằng lifetime của
tham chiếu được trả về bởi hàm longest giống như lifetime nhỏ hơn của các tham
chiếu được truyền vào. Do đó, borrow checker không cho phép mã trong Listing
10-23 vì nó có thể có một tham chiếu không hợp lệ.
Hãy thử thiết kế thêm các thử nghiệm thay đổi giá trị và lifetimes của các tham
chiếu được truyền vào hàm longest và cách tham chiếu trả về được sử dụng. Đưa
ra các giả thuyết về việc các thử nghiệm của bạn sẽ vượt qua borrow checker
trước khi bạn biên dịch; sau đó kiểm tra xem bạn có đúng không!
Suy nghĩ theo Lifetimes
Cách bạn cần chỉ định tham số lifetime phụ thuộc vào những gì hàm của bạn đang
làm. Ví dụ, nếu chúng ta thay đổi triển khai của hàm longest để luôn trả về
tham số đầu tiên thay vì slice chuỗi dài nhất, chúng ta sẽ không cần chỉ định
một lifetime cho tham số y. Mã sau sẽ biên dịch:
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &str) -> &'a str { x }
Chúng ta đã chỉ định một tham số lifetime 'a cho tham số x và kiểu trả về,
nhưng không cho tham số y, bởi vì lifetime của y không có bất kỳ mối quan hệ
nào với lifetime của x hoặc giá trị trả về.
Khi trả về một tham chiếu từ một hàm, tham số lifetime cho kiểu trả về cần phải
khớp với tham số lifetime cho một trong các tham số. Nếu tham chiếu được trả về
không tham chiếu đến một trong các tham số, thì nó phải tham chiếu đến một giá
trị được tạo bên trong hàm này. Tuy nhiên, đây sẽ là một dangling reference vì
giá trị sẽ ra khỏi phạm vi khi kết thúc hàm. Hãy xem xét nỗ lực triển khai hàm
longest sau đây mà không biên dịch:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Ở đây, mặc dù chúng ta đã chỉ định một tham số lifetime 'a cho kiểu trả về,
nhưng triển khai này sẽ không biên dịch vì lifetime của giá trị trả về không
liên quan gì đến lifetime của các tham số. Đây là thông báo lỗi chúng ta nhận
được:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Vấn đề là result ra khỏi phạm vi và bị dọn dẹp vào cuối hàm longest. Chúng
ta cũng đang cố gắng trả về một tham chiếu đến result từ hàm. Không có cách
nào chúng ta có thể chỉ định tham số lifetime để thay đổi dangling reference, và
Rust sẽ không cho phép chúng ta tạo một dangling reference. Trong trường hợp
này, giải pháp tốt nhất là trả về một kiểu dữ liệu sở hữu thay vì một tham chiếu
để hàm gọi sau đó có trách nhiệm dọn dẹp giá trị.
Cuối cùng, cú pháp lifetime là về việc kết nối lifetimes của các tham số và giá trị trả về của các hàm. Một khi chúng được kết nối, Rust có đủ thông tin để cho phép các hoạt động an toàn bộ nhớ và ngăn chặn các hoạt động có thể tạo ra con trỏ treo hoặc vi phạm an toàn bộ nhớ.
Chú thích Lifetime trong Định nghĩa Struct
Cho đến nay, các struct chúng ta đã định nghĩa đều chứa các kiểu sở hữu. Chúng
ta có thể định nghĩa các struct để giữ các tham chiếu, nhưng trong trường hợp đó
chúng ta cần thêm một chú thích lifetime trên mỗi tham chiếu trong định nghĩa
struct. Listing 10-24 có một struct được gọi là ImportantExcerpt giữ một slice
chuỗi.
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
Struct này có trường duy nhất part giữ một slice chuỗi, là một tham chiếu.
Cũng giống như với các kiểu dữ liệu generic, chúng ta khai báo tên của tham số
lifetime generic bên trong dấu ngoặc nhọn sau tên của struct để chúng ta có thể
sử dụng tham số lifetime trong thân định nghĩa struct. Chú thích này có nghĩa là
một thể hiện của ImportantExcerpt không thể tồn tại lâu hơn tham chiếu mà nó
giữ trong trường part.
Hàm main ở đây tạo một thể hiện của struct ImportantExcerpt giữ một tham
chiếu đến câu đầu tiên của String được sở hữu bởi biến novel. Dữ liệu trong
novel tồn tại trước khi thể hiện ImportantExcerpt được tạo. Ngoài ra,
novel không ra khỏi phạm vi cho đến sau khi thể hiện ImportantExcerpt ra
khỏi phạm vi, vì vậy tham chiếu trong thể hiện ImportantExcerpt hợp lệ.
Lifetime Elision (Loại bỏ Lifetime)
Bạn đã học rằng mỗi tham chiếu có một lifetime và bạn cần chỉ định tham số lifetime cho các hàm hoặc struct sử dụng tham chiếu. Tuy nhiên, chúng ta đã có một hàm trong Listing 4-9, được hiển thị lại trong Listing 10-25, đã biên dịch mà không có chú thích lifetime.
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Lý do hàm này biên dịch mà không có chú thích lifetime là lịch sử: trong các phiên bản sớm (trước 1.0) của Rust, mã này sẽ không biên dịch vì mỗi tham chiếu cần một lifetime rõ ràng. Vào thời điểm đó, chữ ký hàm sẽ được viết như sau:
fn first_word<'a>(s: &'a str) -> &'a str {Sau khi viết nhiều mã Rust, nhóm Rust thấy rằng các lập trình viên Rust đang nhập các chú thích lifetime giống nhau lặp đi lặp lại trong các tình huống cụ thể. Các tình huống này có thể dự đoán được và tuân theo một số mẫu xác định. Các nhà phát triển đã lập trình các mẫu này vào mã của trình biên dịch để borrow checker có thể suy ra lifetimes trong các tình huống này và không cần các chú thích rõ ràng.
Phần lịch sử Rust này có liên quan vì có khả năng nhiều mẫu xác định hơn sẽ xuất hiện và được thêm vào trình biên dịch. Trong tương lai, thậm chí có thể cần ít chú thích lifetime hơn.
Các mẫu được lập trình vào phân tích tham chiếu của Rust được gọi là luật loại bỏ lifetime. Đây không phải là luật cho lập trình viên tuân theo; chúng là một tập hợp các trường hợp cụ thể mà trình biên dịch sẽ xem xét, và nếu mã của bạn phù hợp với các trường hợp này, bạn không cần viết lifetimes một cách rõ ràng.
Các luật loại bỏ không cung cấp suy luận hoàn toàn. Nếu vẫn còn sự không rõ ràng về lifetimes mà các tham chiếu có sau khi Rust áp dụng các luật, thì trình biên dịch sẽ không đoán xem lifetime của các tham chiếu còn lại là gì. Thay vì đoán, trình biên dịch sẽ đưa ra một lỗi mà bạn có thể giải quyết bằng cách thêm các chú thích lifetime.
Lifetimes trên tham số hàm hoặc phương thức được gọi là lifetimes đầu vào, và lifetimes trên giá trị trả về được gọi là lifetimes đầu ra.
Trình biên dịch sử dụng ba luật để xác định lifetimes của các tham chiếu khi
không có chú thích rõ ràng. Luật đầu tiên áp dụng cho lifetimes đầu vào, và luật
thứ hai và thứ ba áp dụng cho lifetimes đầu ra. Nếu trình biên dịch đến cuối ba
luật và vẫn còn tham chiếu mà nó không thể xác định lifetimes, trình biên dịch
sẽ dừng lại với một lỗi. Các luật này áp dụng cho các định nghĩa fn cũng như
các khối impl.
Luật đầu tiên là trình biên dịch gán một tham số lifetime cho mỗi tham số là một
tham chiếu. Nói cách khác, một hàm với một tham số nhận một tham số lifetime:
fn foo<'a>(x: &'a i32); một hàm với hai tham số nhận hai tham số lifetime
riêng biệt: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); và vân vân.
Luật thứ hai là, nếu chỉ có một tham số lifetime đầu vào, thì lifetime đó được
gán cho tất cả các tham số lifetime đầu ra: fn foo<'a>(x: &'a i32) -> &'a i32.
Luật thứ ba là, nếu có nhiều tham số lifetime đầu vào, nhưng một trong số đó là
&self hoặc &mut self vì đây là một phương thức, thì lifetime của self được
gán cho tất cả các tham số lifetime đầu ra. Luật thứ ba này làm cho các phương
thức dễ đọc và viết hơn nhiều vì cần ít ký hiệu hơn.
Hãy giả vờ chúng ta là trình biên dịch. Chúng ta sẽ áp dụng các luật này để tìm
ra lifetimes của các tham chiếu trong chữ ký của hàm first_word trong Listing
10-25. Chữ ký bắt đầu mà không có bất kỳ lifetime nào được liên kết với các tham
chiếu:
fn first_word(s: &str) -> &str {Sau đó trình biên dịch áp dụng luật đầu tiên, chỉ định rằng mỗi tham số nhận
lifetime của riêng nó. Chúng ta sẽ gọi nó là 'a như thường lệ, vì vậy bây giờ
chữ ký là như sau:
fn first_word<'a>(s: &'a str) -> &str {Luật thứ hai áp dụng vì có chính xác một lifetime đầu vào. Luật thứ hai chỉ định rằng lifetime của tham số đầu vào duy nhất được gán cho lifetime đầu ra, vì vậy chữ ký bây giờ là như sau:
fn first_word<'a>(s: &'a str) -> &'a str {Bây giờ tất cả các tham chiếu trong chữ ký hàm này có lifetimes, và trình biên dịch có thể tiếp tục phân tích mà không cần lập trình viên chú thích lifetimes trong chữ ký hàm này.
Hãy xem một ví dụ khác, lần này sử dụng hàm longest đã không có tham số
lifetime khi chúng ta bắt đầu làm việc với nó trong Listing 10-20:
fn longest(x: &str, y: &str) -> &str {Hãy áp dụng luật đầu tiên: mỗi tham số nhận lifetime của riêng nó. Lần này chúng ta có hai tham số thay vì một, vì vậy chúng ta có hai lifetimes:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {Bạn có thể thấy rằng luật thứ hai không áp dụng vì có nhiều hơn một lifetime đầu
vào. Luật thứ ba cũng không áp dụng, vì longest là một hàm chứ không phải là
một phương thức, vì vậy không có tham số nào là self. Sau khi làm việc qua tất
cả ba luật, chúng ta vẫn chưa tìm ra lifetime của kiểu trả về là gì. Đây là lý
do tại sao chúng ta nhận được lỗi khi cố gắng biên dịch mã trong Listing 10-20:
trình biên dịch đã làm việc thông qua các luật loại bỏ lifetime nhưng vẫn không
thể tìm ra tất cả lifetimes của các tham chiếu trong chữ ký.
Bởi vì luật thứ ba thực sự chỉ áp dụng trong chữ ký phương thức, chúng ta sẽ xem xét lifetimes trong ngữ cảnh đó tiếp theo để thấy tại sao luật thứ ba có nghĩa là chúng ta không phải chú thích lifetimes trong chữ ký phương thức thường xuyên.
Chú thích Lifetime trong Định nghĩa Phương thức
Khi chúng ta triển khai các phương thức trên một struct với lifetimes, chúng ta sử dụng cùng cú pháp như của tham số kiểu generic, như được hiển thị trong Listing 10-11. Nơi chúng ta khai báo và sử dụng các tham số lifetime phụ thuộc vào việc chúng có liên quan đến các trường của struct hay các tham số phương thức và giá trị trả về.
Tên lifetime cho các trường struct luôn cần được khai báo sau từ khóa impl và
sau đó được sử dụng sau tên của struct vì những lifetimes đó là một phần của
kiểu của struct.
Trong chữ ký phương thức bên trong khối impl, các tham chiếu có thể bị ràng
buộc với lifetime của các tham chiếu trong các trường của struct, hoặc chúng có
thể độc lập. Ngoài ra, các luật loại bỏ lifetime thường làm cho chú thích
lifetime không cần thiết trong chữ ký phương thức. Hãy xem một số ví dụ sử dụng
struct có tên ImportantExcerpt mà chúng ta đã định nghĩa trong Listing 10-24.
Đầu tiên, chúng ta sẽ sử dụng một phương thức có tên level có tham số duy nhất
là tham chiếu đến self và giá trị trả về là i32, không phải là tham chiếu
đến bất kỳ thứ gì:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
Khai báo tham số lifetime sau impl và việc sử dụng nó sau tên kiểu là cần
thiết, nhưng chúng ta không bắt buộc phải chú thích lifetime của tham chiếu đến
self vì luật loại bỏ đầu tiên.
Đây là một ví dụ nơi luật loại bỏ lifetime thứ ba áp dụng:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
Có hai lifetime đầu vào, vì vậy Rust áp dụng luật loại bỏ lifetime đầu tiên và
gán cho cả &self và announcement lifetimes riêng của chúng. Sau đó, bởi vì
một trong các tham số là &self, kiểu trả về nhận lifetime của &self, và tất
cả lifetimes đã được tính đến.
Static Lifetime
Một lifetime đặc biệt mà chúng ta cần thảo luận là 'static, nó biểu thị rằng
tham chiếu bị ảnh hưởng có thể tồn tại trong toàn bộ thời gian của chương
trình. Tất cả các literal chuỗi có lifetime 'static, mà chúng ta có thể chú
thích như sau:
#![allow(unused)] fn main() { let s: &'static str = "I have a static lifetime."; }
Văn bản của chuỗi này được lưu trữ trực tiếp trong tệp nhị phân của chương
trình, mà luôn có sẵn. Do đó, lifetime của tất cả các literal chuỗi là
'static.
Bạn có thể thấy các gợi ý trong thông báo lỗi để sử dụng lifetime 'static.
Nhưng trước khi chỉ định 'static làm lifetime cho một tham chiếu, hãy suy nghĩ
về việc liệu tham chiếu bạn có thực sự tồn tại trong toàn bộ lifetime của chương
trình hay không, và liệu bạn có muốn nó như vậy hay không. Hầu hết thời gian,
một thông báo lỗi gợi ý lifetime 'static là kết quả của việc cố gắng tạo một
dangling reference hoặc không khớp của các lifetimes có sẵn. Trong những trường
hợp như vậy, giải pháp là sửa những vấn đề đó, không phải chỉ định lifetime
'static.
Tham số kiểu Generic, Trait Bounds và Lifetimes cùng nhau
Hãy xem qua cú pháp của việc chỉ định tham số kiểu generic, trait bounds và lifetimes tất cả trong một hàm!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {result}"); } use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {ann}"); if x.len() > y.len() { x } else { y } }
Đây là hàm longest từ Listing 10-21 trả về cái dài hơn trong hai slice chuỗi.
Nhưng bây giờ nó có một tham số bổ sung có tên ann của kiểu generic T, có
thể được điền bởi bất kỳ kiểu nào triển khai trait Display như được chỉ định
bởi mệnh đề where. Tham số bổ sung này sẽ được in bằng {}, đó là lý do tại
sao ràng buộc trait Display là cần thiết. Bởi vì lifetimes là một loại
generic, khai báo của tham số lifetime 'a và tham số kiểu generic T được đặt
trong cùng một danh sách bên trong dấu ngoặc nhọn sau tên hàm.
Tóm tắt
Chúng ta đã bao quát nhiều trong chương này! Bây giờ bạn đã biết về tham số kiểu generic, traits và trait bounds, và tham số lifetime generic, bạn đã sẵn sàng để viết mã không trùng lặp hoạt động trong nhiều tình huống khác nhau. Tham số kiểu generic cho phép bạn áp dụng mã cho các kiểu khác nhau. Traits và trait bounds đảm bảo rằng mặc dù các kiểu là generic, chúng sẽ có hành vi mà mã cần. Bạn đã học cách sử dụng chú thích lifetime để đảm bảo rằng mã linh hoạt này sẽ không có bất kỳ dangling reference nào. Và tất cả những phân tích này xảy ra tại thời điểm biên dịch, không ảnh hưởng đến hiệu suất thời gian chạy!
Tin hay không, có còn nhiều điều để học về các chủ đề chúng ta đã thảo luận trong chương này: Chương 18 thảo luận về trait objects, là một cách khác để sử dụng traits. Cũng có các kịch bản phức tạp hơn liên quan đến chú thích lifetime mà bạn sẽ chỉ cần trong các kịch bản rất nâng cao; cho những điều đó, bạn nên đọc Rust Reference. Nhưng tiếp theo, bạn sẽ học cách viết tests trong Rust để đảm bảo mã của bạn hoạt động theo cách mà nó nên làm.
Viết Kiểm Thử Tự Động
Trong bài luận năm 1972 "The Humble Programmer", Edsger W. Dijkstra đã nói rằng "kiểm thử chương trình có thể là một cách rất hiệu quả để phát hiện lỗi, nhưng nó hoàn toàn không đủ để chứng minh sự vắng mặt của chúng." Điều đó không có nghĩa là chúng ta không nên cố gắng kiểm thử nhiều nhất có thể!
Tính đúng đắn trong chương trình của chúng ta là mức độ mà code của chúng ta thực hiện đúng những gì chúng ta muốn. Rust được thiết kế với sự quan tâm lớn đến tính đúng đắn của chương trình, nhưng tính đúng đắn là phức tạp và không dễ để chứng minh. Hệ thống kiểu của Rust gánh vác phần lớn gánh nặng này, nhưng hệ thống kiểu không thể bắt được tất cả. Do đó, Rust bao gồm hỗ trợ để viết các bài kiểm thử phần mềm tự động.
Giả sử chúng ta viết một hàm add_two cộng thêm 2 vào bất kỳ số nào được truyền
vào nó. Chữ ký của hàm này chấp nhận một số nguyên làm tham số và trả về một số
nguyên làm kết quả. Khi chúng ta triển khai và biên dịch hàm đó, Rust thực hiện
tất cả các kiểm tra kiểu và kiểm tra mượn mà bạn đã học cho đến nay để đảm bảo
rằng, chẳng hạn, chúng ta không truyền giá trị String hoặc tham chiếu không
hợp lệ cho hàm này. Nhưng Rust không thể kiểm tra rằng hàm này sẽ thực hiện
chính xác những gì chúng ta dự định, đó là trả về tham số cộng thêm 2 thay vì,
ví dụ, tham số cộng thêm 10 hoặc tham số trừ đi 50! Đó là lúc các bài kiểm thử
phát huy tác dụng.
Chúng ta có thể viết các bài kiểm thử khẳng định, ví dụ, khi chúng ta truyền 3
vào hàm add_two, giá trị trả về là 5. Chúng ta có thể chạy các bài kiểm thử
này bất cứ khi nào chúng ta thay đổi code của mình để đảm bảo rằng bất kỳ hành
vi đúng đắn hiện có nào cũng không bị thay đổi.
Kiểm thử là một kỹ năng phức tạp: mặc dù chúng ta không thể đề cập đến mọi chi tiết về cách viết các bài kiểm thử tốt trong một chương, nhưng trong chương này chúng ta sẽ thảo luận về cơ chế của các tiện ích kiểm thử của Rust. Chúng ta sẽ nói về các chú thích và macro có sẵn cho bạn khi viết các bài kiểm thử, hành vi mặc định và các tùy chọn được cung cấp để chạy các bài kiểm thử của bạn, và cách tổ chức các bài kiểm thử thành kiểm thử đơn vị và kiểm thử tích hợp.
Cách Viết Các Bài Kiểm Thử
Các bài kiểm thử trong Rust là các hàm xác minh rằng code không phải kiểm thử đang hoạt động theo cách mong đợi. Thân hàm của các bài kiểm thử thường thực hiện ba hành động sau:
- Thiết lập dữ liệu hoặc trạng thái cần thiết.
- Chạy code bạn muốn kiểm thử.
- Khẳng định rằng kết quả là những gì bạn mong đợi.
Hãy xem xét các tính năng Rust cung cấp đặc biệt để viết các bài kiểm thử thực
hiện các hành động này, bao gồm thuộc tính test, một số macro và thuộc tính
should_panic.
Cấu Trúc của Một Hàm Kiểm Thử
Ở dạng đơn giản nhất, một bài kiểm thử trong Rust là một hàm được chú thích với
thuộc tính test. Các thuộc tính là siêu dữ liệu về các phần code Rust; một ví
dụ là thuộc tính derive mà chúng ta đã sử dụng với các cấu trúc trong
Chương 5. Để biến một hàm thành hàm kiểm thử, thêm #[test] vào dòng trước
fn. Khi bạn chạy các bài kiểm thử với lệnh cargo test, Rust xây dựng một tệp
thực thi chạy kiểm thử để chạy các hàm được chú thích và báo cáo xem từng hàm
kiểm thử có thành công hay không.
Bất cứ khi nào chúng ta tạo một dự án thư viện mới với Cargo, một module kiểm thử với một hàm kiểm thử trong đó được tự động tạo ra cho chúng ta. Module này cung cấp cho bạn một mẫu để viết các bài kiểm thử của bạn, vì vậy bạn không phải tìm kiếm cấu trúc và cú pháp chính xác mỗi khi bạn bắt đầu một dự án mới. Bạn có thể thêm bất kỳ hàm kiểm thử bổ sung nào và bất kỳ module kiểm thử nào mà bạn muốn!
Chúng ta sẽ khám phá một số khía cạnh về cách các bài kiểm thử hoạt động bằng cách thử nghiệm với mẫu kiểm thử trước khi chúng ta thực sự kiểm thử bất kỳ mã nào. Sau đó, chúng ta sẽ viết một số bài kiểm thử thực tế gọi một số code mà chúng ta đã viết và khẳng định rằng hành vi của nó là chính xác.
Hãy tạo một dự án thư viện mới có tên adder sẽ cộng hai số:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
Nội dung của tệp src/lib.rs trong thư viện adder của bạn sẽ trông giống như
Listing 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Tệp bắt đầu với một ví dụ hàm add, để chúng ta có thứ gì đó để kiểm thử.
Bây giờ, chúng ta hãy tập trung duy nhất vào hàm it_works. Lưu ý chú thích
#[test]: thuộc tính này chỉ ra rằng đây là một hàm kiểm thử, vì vậy trình chạy
kiểm thử biết xử lý hàm này như một bài kiểm thử. Chúng ta cũng có thể có các
hàm không phải kiểm thử trong module tests để giúp thiết lập các kịch bản
chung hoặc thực hiện các thao tác chung, vì vậy chúng ta luôn cần chỉ ra những
hàm nào là kiểm thử.
Thân hàm ví dụ sử dụng vĩ lệnh assert_eq! để khẳng định rằng result, là kết
quả của việc gọi hàm add với 2 và 2, bằng 4. Khẳng định này đóng vai trò như
một ví dụ về định dạng cho một bài kiểm thử điển hình. Hãy chạy nó để xem bài
kiểm thử này có thành công hay không.
Lệnh cargo test chạy tất cả các bài kiểm thử trong dự án của chúng ta, như
được hiển thị trong Listing 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo đã biên dịch và chạy bài kiểm thử. Chúng ta thấy dòng running 1 test.
Dòng tiếp theo hiển thị tên của hàm kiểm thử được tạo ra, gọi là
tests::it_works, và kết quả chạy bài kiểm thử đó là ok. Tóm lược tổng thể
test result: ok. có nghĩa là tất cả các bài kiểm thử đều thành công, và phần
đọc 1 passed; 0 failed tổng hợp số bài kiểm thử đã thành công hoặc thất bại.
Có thể đánh dấu một bài kiểm thử là bị bỏ qua để nó không chạy trong một trường
hợp cụ thể; chúng ta sẽ đề cập điều này trong phần "Bỏ Qua Một Số Bài Kiểm Thử
Trừ Khi Có Yêu Cầu Cụ Thể" sau này trong chương này.
Vì chúng ta chưa làm điều đó ở đây, tóm lược hiển thị 0 ignored. Chúng ta cũng
có thể truyền một đối số cho lệnh cargo test để chỉ chạy các bài kiểm thử có
tên khớp với một chuỗi; điều này được gọi là lọc, và chúng ta sẽ đề cập đến nó
trong phần "Chạy Một Tập Con của Các Bài Kiểm Thử theo
Tên". Ở đây, chúng ta chưa lọc các bài kiểm thử đang
chạy, vì vậy phần cuối của tóm lược hiển thị 0 filtered out.
Chỉ số 0 measured là dành cho các bài kiểm thử chuẩn đo lường hiệu suất. Các
bài kiểm thử chuẩn, tại thời điểm viết bài này, chỉ có sẵn trong Rust nightly.
Xem tài liệu về các bài kiểm thử chuẩn để tìm hiểu thêm.
Phần tiếp theo của kết quả kiểm thử bắt đầu từ Doc-tests adder là dành cho kết
quả của bất kỳ bài kiểm thử tài liệu nào. Chúng ta chưa có bài kiểm thử tài liệu
nào, nhưng Rust có thể biên dịch bất kỳ ví dụ code nào xuất hiện trong tài liệu
API của chúng ta. Tính năng này giúp duy trì tài liệu và code của bạn đồng bộ!
Chúng ta sẽ thảo luận về cách viết các bài kiểm thử tài liệu trong phần "Bình
Luận Tài Liệu như Các Bài Kiểm Thử" của Chương 14.
Hiện tại, chúng ta sẽ bỏ qua kết quả Doc-tests.
Hãy bắt đầu tùy chỉnh bài kiểm thử theo nhu cầu của riêng mình. Đầu tiên, thay
đổi tên của hàm it_works thành một cái tên khác, chẳng hạn như exploration,
như sau:
Tên tệp: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Sau đó chạy cargo test lần nữa. Kết quả bây giờ hiển thị exploration thay vì
it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bây giờ chúng ta sẽ thêm một bài kiểm thử khác, nhưng lần này chúng ta sẽ tạo
một bài kiểm thử thất bại! Các bài kiểm thử thất bại khi có gì đó trong hàm kiểm
thử hoảng loạn (panic). Mỗi bài kiểm thử được chạy trong một thread mới, và khi
thread chính thấy rằng một thread kiểm thử đã chết, bài kiểm thử được đánh dấu
là đã thất bại. Trong Chương 9, chúng ta đã nói về cách đơn giản nhất để hoảng
loạn là gọi vĩ lệnh panic!. Hãy nhập bài kiểm thử mới dưới dạng một hàm có tên
là another, để tệp src/lib.rs của bạn trông giống như Listing 11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}Chạy các bài kiểm thử một lần nữa bằng cargo test. Kết quả sẽ trông giống như
Listing 11-4, cho thấy bài kiểm thử exploration của chúng ta đã thành công và
bài kiểm thử another đã thất bại.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Thay vì ok, dòng test tests::another hiển thị FAILED. Hai phần mới xuất
hiện giữa các kết quả cá nhân và tóm lược: phần đầu tiên hiển thị lý do chi tiết
cho mỗi bài kiểm thử thất bại. Trong trường hợp này, chúng ta nhận được chi tiết
rằng tests::another đã thất bại vì nó panicked với thông báo
Make this test fail trên dòng 17 trong tệp src/lib.rs. Phần tiếp theo chỉ
liệt kê tên của tất cả các bài kiểm thử thất bại, điều này hữu ích khi có nhiều
bài kiểm thử và nhiều kết quả kiểm thử thất bại chi tiết. Chúng ta có thể sử
dụng tên của bài kiểm thử thất bại để chỉ chạy bài kiểm thử đó để gỡ lỗi dễ dàng
hơn; chúng ta sẽ nói thêm về cách chạy các bài kiểm thử trong phần "Kiểm Soát
Cách Chạy Các Bài Kiểm Thử".
Dòng tóm lược hiển thị ở cuối: nhìn chung, kết quả kiểm thử của chúng ta là
FAILED. Chúng ta có một bài kiểm thử thành công và một bài kiểm thử thất bại.
Bây giờ bạn đã thấy kết quả kiểm thử trông như thế nào trong các tình huống khác
nhau, hãy xem các vĩ lệnh khác ngoài panic! hữu ích trong các bài kiểm thử.
Kiểm Tra Kết Quả với Vĩ Lệnh assert!
Vĩ lệnh assert!, được cung cấp bởi thư viện chuẩn, hữu ích khi bạn muốn đảm
bảo rằng một số điều kiện trong bài kiểm thử được đánh giá là true. Chúng ta
cung cấp cho vĩ lệnh assert! một đối số được đánh giá thành một giá trị
Boolean. Nếu giá trị là true, không có gì xảy ra và bài kiểm thử thành công.
Nếu giá trị là false, vĩ lệnh assert! gọi panic! để khiến bài kiểm thử
thất bại. Việc sử dụng vĩ lệnh assert! giúp chúng ta kiểm tra xem code của
mình có hoạt động theo cách chúng ta dự định hay không.
Trong Chương 5, Listing 5-15, chúng ta đã sử dụng cấu trúc Rectangle và phương
thức can_hold, được lặp lại ở đây trong Listing 11-5. Hãy đặt code này vào tệp
src/lib.rs, sau đó viết một số bài kiểm thử cho nó bằng vĩ lệnh assert!.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Phương thức can_hold trả về một giá trị Boolean, điều này có nghĩa là nó là
một trường hợp sử dụng hoàn hảo cho vĩ lệnh assert!. Trong Listing 11-6, chúng
ta viết một bài kiểm thử thực hiện phương thức can_hold bằng cách tạo một
instance Rectangle có chiều rộng là 8 và chiều cao là 7 và khẳng định rằng nó
có thể chứa một instance Rectangle khác có chiều rộng là 5 và chiều cao là 1.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}Lưu ý dòng use super::*; bên trong module tests. Module tests là một
module bình thường tuân theo các quy tắc khả kiến thông thường mà chúng ta đã đề
cập trong Chương 7 ở phần "Đường Dẫn cho Việc Tham Chiếu đến Một Mục trong Cây
Module". Vì
module tests là một module bên trong, chúng ta cần đưa code đang được kiểm thử
trong module bên ngoài vào phạm vi của module bên trong. Chúng ta sử dụng glob ở
đây, vì vậy bất cứ thứ gì chúng ta xác định trong module bên ngoài đều có sẵn
cho module tests này.
Chúng ta đã đặt tên cho bài kiểm thử của mình là larger_can_hold_smaller, và
chúng ta đã tạo hai instance Rectangle mà chúng ta cần. Sau đó, chúng ta gọi
vĩ lệnh assert! và truyền cho nó kết quả của việc gọi
larger.can_hold(&smaller). Biểu thức này được cho là trả về true, vì vậy bài
kiểm thử của chúng ta sẽ thành công. Hãy tìm hiểu!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Nó đã thành công! Hãy thêm một bài kiểm thử khác, lần này khẳng định rằng một hình chữ nhật nhỏ hơn không thể chứa một hình chữ nhật lớn hơn:
Tên tệp: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Vì kết quả đúng của hàm can_hold trong trường hợp này là false, chúng ta cần
phủ định kết quả đó trước khi truyền nó cho vĩ lệnh assert!. Kết quả là, bài
kiểm thử của chúng ta sẽ thành công nếu can_hold trả về false:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Hai bài kiểm thử đều thành công! Bây giờ, hãy xem điều gì xảy ra với kết quả
kiểm thử của chúng ta khi chúng ta đưa vào một lỗi trong code. Chúng ta sẽ thay
đổi triển khai của phương thức can_hold bằng cách thay thế dấu lớn hơn bằng
dấu nhỏ hơn khi nó so sánh chiều rộng:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Chạy các bài kiểm thử bây giờ sẽ cho kết quả sau:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Các bài kiểm thử của chúng ta đã phát hiện ra lỗi! Bởi vì larger.width là 8
và smaller.width là 5, phép so sánh chiều rộng trong can_hold bây giờ trả
về false: 8 không nhỏ hơn 5.
Kiểm Tra Sự Bằng Nhau với Các Vĩ Lệnh assert_eq! và assert_ne!
Một cách phổ biến để xác minh chức năng là kiểm tra sự bằng nhau giữa kết quả
của code đang được kiểm thử và giá trị bạn mong đợi code trả về. Bạn có thể làm
điều này bằng cách sử dụng vĩ lệnh assert! và truyền cho nó một biểu thức sử
dụng toán tử ==. Tuy nhiên, đây là một bài kiểm thử rất phổ biến mà thư viện
chuẩn cung cấp một cặp vĩ lệnh — assert_eq! và assert_ne!—để thực hiện bài
kiểm thử này một cách thuận tiện hơn. Các vĩ lệnh này so sánh hai đối số xem có
bằng nhau hoặc không bằng nhau, tương ứng. Chúng cũng sẽ in ra hai giá trị nếu
khẳng định thất bại, điều này giúp dễ dàng thấy tại sao bài kiểm thử thất bại;
ngược lại, vĩ lệnh assert! chỉ chỉ ra rằng nó nhận được giá trị false cho
biểu thức ==, mà không in ra các giá trị dẫn đến giá trị false.
Trong Listing 11-7, chúng ta viết một hàm có tên add_two cộng thêm 2 vào
tham số của nó, sau đó chúng ta kiểm thử hàm này bằng vĩ lệnh assert_eq!.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Hãy kiểm tra xem nó có thành công không!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Chúng ta tạo một biến có tên result lưu trữ kết quả của việc gọi add_two(2).
Sau đó, chúng ta truyền result và 4 làm đối số cho macro assert_eq!. Dòng
kết quả cho bài kiểm thử này là test tests::it_adds_two ... ok, và văn bản
ok chỉ ra rằng bài kiểm thử của chúng ta đã thành công!
Hãy đưa một lỗi vào code của chúng ta để xem assert_eq! trông như thế nào khi
nó thất bại. Thay đổi triển khai của hàm add_two để cộng thêm 3 thay vì 2:
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Chạy các bài kiểm thử một lần nữa:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bài kiểm thử của chúng ta đã phát hiện lỗi! Bài kiểm thử test::it_adds_two đã
thất bại, và thông báo cho chúng ta biết rằng khẳng định thất bại là
left == right và giá trị left và right là gì. Thông báo này giúp chúng ta
bắt đầu gỡ lỗi: đối số left, nơi chúng ta có kết quả của việc gọi
add_two(2), là 5 nhưng đối số right là 4. Bạn có thể tưởng tượng điều
này sẽ đặc biệt hữu ích khi chúng ta có nhiều bài kiểm thử đang diễn ra.
Lưu ý rằng trong một số ngôn ngữ và framework kiểm thử, các tham số cho hàm
khẳng định về sự bằng nhau được gọi là expected và actual, và thứ tự mà
chúng ta chỉ định các đối số có vấn đề. Tuy nhiên, trong Rust, chúng được gọi là
left và right, và thứ tự mà chúng ta chỉ định giá trị mà chúng ta mong đợi
và giá trị mà code tạo ra không quan trọng. Chúng ta có thể viết khẳng định
trong bài kiểm thử này là assert_eq!(4, result), điều này sẽ dẫn đến thông báo
lỗi tương tự hiển thị assertion `left == right` failed.
Vĩ lệnh assert_ne! sẽ thành công nếu hai giá trị chúng ta cung cấp cho nó
không bằng nhau và thất bại nếu chúng bằng nhau. Vĩ lệnh này hữu ích nhất cho
các trường hợp khi chúng ta không chắc giá trị sẽ là gì, nhưng chúng ta biết
giá trị đó chắc chắn không nên là gì. Ví dụ, nếu chúng ta đang kiểm thử một
hàm được đảm bảo sẽ thay đổi đầu vào của nó theo cách nào đó, nhưng cách thức
đầu vào được thay đổi phụ thuộc vào ngày trong tuần mà chúng ta chạy các bài
kiểm thử, điều tốt nhất để khẳng định có thể là kết quả của hàm không bằng đầu
vào.
Dưới bề mặt, các vĩ lệnh assert_eq! và assert_ne! sử dụng các toán tử ==
và !=, tương ứng. Khi các khẳng định thất bại, các vĩ lệnh này in ra các đối
số của chúng bằng định dạng debug, điều này có nghĩa là các giá trị đang được so
sánh phải triển khai các trait PartialEq và Debug. Tất cả các kiểu nguyên
thủy và hầu hết các kiểu thư viện chuẩn đều triển khai các trait này. Đối với
các cấu trúc và enum mà bạn tự định nghĩa, bạn cần triển khai PartialEq để
khẳng định bằng nhau cho các kiểu này. Bạn cũng cần triển khai Debug để in ra
các giá trị khi khẳng định thất bại. Bởi vì cả hai trait đều là các trait có thể
dẫn xuất, như đã đề cập trong Listing 5-12 của Chương 5, điều này thường đơn
giản như việc thêm chú thích #[derive(PartialEq, Debug)] vào định nghĩa cấu
trúc hoặc enum của bạn. Xem Phụ lục C, "Các Trait Có Thể Dẫn
Xuất," để biết thêm chi tiết về các trait này
và các trait có thể dẫn xuất khác.
Thêm Thông Báo Thất Bại Tùy Chỉnh
Bạn cũng có thể thêm một thông báo tùy chỉnh để hiển thị với thông báo thất bại
làm đối số tùy chọn cho các vĩ lệnh assert!, assert_eq! và assert_ne!. Bất
kỳ đối số nào được chỉ định sau các đối số bắt buộc đều được chuyển đến vĩ lệnh
format! (được thảo luận trong "Nối Chuỗi với Toán Tử + hoặc Vĩ Lệnh
format!"
ở Chương 8), vì vậy bạn có thể truyền một chuỗi định dạng chứa các placeholder
{} và các giá trị để điền vào các placeholder đó. Các thông báo tùy chỉnh hữu
ích để ghi lại ý nghĩa của khẳng định; khi một bài kiểm thử thất bại, bạn sẽ có
ý tưởng tốt hơn về vấn đề trong code.
Ví dụ, giả sử chúng ta có một hàm chào hỏi mọi người theo tên và chúng ta muốn kiểm tra rằng tên mà chúng ta truyền vào hàm xuất hiện trong kết quả:
Tên tệp: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Các yêu cầu cho chương trình này chưa được thống nhất, và chúng ta khá chắc chắn
rằng văn bản Hello ở đầu lời chào sẽ thay đổi. Chúng ta quyết định không muốn
phải cập nhật bài kiểm thử khi các yêu cầu thay đổi, vì vậy thay vì kiểm tra sự
bằng nhau chính xác với giá trị trả về từ hàm greeting, chúng ta sẽ chỉ khẳng
định rằng kết quả chứa văn bản của tham số đầu vào.
Bây giờ hãy đưa một lỗi vào code này bằng cách thay đổi greeting để loại bỏ
name để xem lỗi kiểm thử mặc định trông như thế nào:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Chạy bài kiểm thử này sẽ cho kết quả sau:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Kết quả này chỉ chỉ ra rằng khẳng định đã thất bại và dòng nào khẳng định đó.
Một thông báo lỗi hữu ích hơn sẽ in ra giá trị từ hàm greeting. Hãy thêm một
thông báo lỗi tùy chỉnh bao gồm một chuỗi định dạng với một placeholder được
điền bằng giá trị thực tế mà chúng ta nhận được từ hàm greeting:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}Bây giờ khi chúng ta chạy bài kiểm thử, chúng ta sẽ nhận được một thông báo lỗi thông tin hơn:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Chúng ta có thể thấy giá trị mà chúng ta thực sự nhận được trong kết quả kiểm thử, điều này sẽ giúp chúng ta gỡ lỗi những gì đã xảy ra thay vì những gì chúng ta mong đợi sẽ xảy ra.
Kiểm Tra Hoảng Loạn với should_panic
Ngoài việc kiểm tra giá trị trả về, điều quan trọng là phải kiểm tra rằng code
của chúng ta xử lý các tình huống lỗi như mong đợi. Ví dụ, hãy xem xét kiểu
Guess mà chúng ta đã tạo trong Chương 9, Listing 9-13. Các code khác sử dụng
Guess phụ thuộc vào sự đảm bảo rằng các instance Guess sẽ chỉ chứa các giá
trị từ 1 đến 100. Chúng ta có thể viết một bài kiểm thử để đảm bảo rằng việc cố
gắng tạo một instance Guess với một giá trị nằm ngoài phạm vi đó sẽ hoảng
loạn.
Chúng ta làm điều này bằng cách thêm thuộc tính should_panic vào hàm kiểm thử
của mình. Bài kiểm thử thành công nếu code bên trong hàm hoảng loạn; bài kiểm
thử thất bại nếu code bên trong hàm không hoảng loạn.
Listing 11-8 cho thấy một bài kiểm thử kiểm tra rằng các điều kiện lỗi của
Guess::new xảy ra khi chúng ta mong đợi.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Chúng ta đặt thuộc tính #[should_panic] sau thuộc tính #[test] và trước hàm
kiểm thử mà nó áp dụng. Hãy xem kết quả khi bài kiểm thử này thành công:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Trông tốt! Bây giờ hãy đưa một lỗi vào code của chúng ta bằng cách loại bỏ điều
kiện mà hàm new sẽ hoảng loạn nếu giá trị lớn hơn 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Khi chúng ta chạy bài kiểm thử trong Listing 11-8, nó sẽ thất bại:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Chúng ta không nhận được thông báo rất hữu ích trong trường hợp này, nhưng khi
chúng ta nhìn vào hàm kiểm thử, chúng ta thấy nó được chú thích với
#[should_panic]. Lỗi mà chúng ta nhận được có nghĩa là code trong hàm kiểm thử
không gây ra hoảng loạn.
Các bài kiểm thử sử dụng should_panic có thể không chính xác. Một bài kiểm thử
should_panic sẽ thành công ngay cả khi bài kiểm thử hoảng loạn vì một lý do
khác với lý do chúng ta mong đợi. Để làm cho các bài kiểm thử should_panic
chính xác hơn, chúng ta có thể thêm một tham số expected tùy chọn vào thuộc
tính should_panic. Công cụ kiểm thử sẽ đảm bảo rằng thông báo lỗi chứa văn bản
được cung cấp. Ví dụ, hãy xem xét code đã sửa đổi cho Guess trong Listing
11-9, trong đó hàm new hoảng loạn với các thông báo khác nhau tùy thuộc vào
việc giá trị quá nhỏ hay quá lớn.
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Bài kiểm thử này sẽ thành công vì giá trị mà chúng ta đặt trong tham số
expected của thuộc tính should_panic là một chuỗi con của thông báo mà hàm
Guess::new hoảng loạn. Chúng ta có thể đã chỉ định toàn bộ thông báo hoảng
loạn mà chúng ta mong đợi, trong trường hợp này sẽ là
Guess value must be less than or equal to 100, got 200. Những gì bạn chọn để
chỉ định phụ thuộc vào phần nào của thông báo hoảng loạn là duy nhất hoặc động
và mức độ chính xác bạn muốn cho bài kiểm thử của mình. Trong trường hợp này,
một chuỗi con của thông báo hoảng loạn là đủ để đảm bảo rằng code trong hàm kiểm
thử thực thi trường hợp else if value > 100.
Để xem điều gì xảy ra khi một bài kiểm thử should_panic với một thông báo
expected thất bại, hãy một lần nữa đưa một lỗi vào code của chúng ta bằng cách
hoán đổi các thân của khối if value < 1 và else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Lần này khi chúng ta chạy bài kiểm thử should_panic, nó sẽ thất bại:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "Guess value must be greater than or equal to 1, got 200."
expected substring: "less than or equal to 100"
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Thông báo lỗi cho biết rằng bài kiểm thử này thực sự hoảng loạn như chúng ta
mong đợi, nhưng thông báo hoảng loạn không chứa chuỗi mong đợi
less than or equal to 100. Thông báo hoảng loạn mà chúng ta nhận được trong
trường hợp này là Guess value must be greater than or equal to 1, got 200. Bây
giờ chúng ta có thể bắt đầu tìm ra lỗi ở đâu!
Sử Dụng Result<T, E> trong Các Bài Kiểm Thử
Cho đến nay, các bài kiểm thử của chúng ta đều hoảng loạn khi chúng thất bại.
Chúng ta cũng có thể viết các bài kiểm thử sử dụng Result<T, E>! Đây là bài
kiểm thử từ Listing 11-1, được viết lại để sử dụng Result<T, E> và trả về một
Err thay vì hoảng loạn:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}Hàm it_works bây giờ có kiểu trả về là Result<(), String>. Trong thân hàm,
thay vì gọi vĩ lệnh assert_eq!, chúng ta trả về Ok(()) khi bài kiểm thử
thành công và một Err với một String bên trong khi bài kiểm thử thất bại.
Viết các bài kiểm thử sao cho chúng trả về Result<T, E> cho phép bạn sử dụng
toán tử dấu hỏi trong thân các bài kiểm thử, điều này có thể là một cách thuận
tiện để viết các bài kiểm thử nên thất bại nếu bất kỳ thao tác nào trong chúng
trả về biến thể Err.
Bạn không thể sử dụng chú thích #[should_panic] trên các bài kiểm thử sử dụng
Result<T, E>. Để khẳng định rằng một thao tác trả về biến thể Err, đừng sử
dụng toán tử dấu hỏi trên giá trị Result<T, E>. Thay vào đó, hãy sử dụng
assert!(value.is_err()).
Bây giờ bạn đã biết một số cách để viết các bài kiểm thử, hãy xem những gì xảy
ra khi chúng ta chạy các bài kiểm thử của mình và khám phá các tùy chọn khác
nhau mà chúng ta có thể sử dụng với cargo test.
Kiểm Soát Cách Chạy Các Bài Kiểm Thử
Giống như cargo run biên dịch code của bạn và sau đó chạy tệp nhị phân kết
quả, cargo test biên dịch code của bạn ở chế độ kiểm thử và chạy tệp nhị phân
kiểm thử kết quả. Hành vi mặc định của tệp nhị phân được tạo ra bởi cargo test
là chạy tất cả các bài kiểm thử song song và thu thập kết quả được tạo ra trong
quá trình chạy kiểm thử, ngăn chặn kết quả được hiển thị và làm cho việc đọc kết
quả liên quan đến kết quả kiểm thử dễ dàng hơn. Tuy nhiên, bạn có thể chỉ định
các tùy chọn dòng lệnh để thay đổi hành vi mặc định này.
Một số tùy chọn dòng lệnh được chuyển tới cargo test, và một số được chuyển
tới tệp nhị phân kiểm thử kết quả. Để phân tách hai loại đối số này, bạn liệt kê
các đối số chuyển tới cargo test theo sau là dấu phân tách -- và sau đó là
các đối số chuyển tới tệp nhị phân kiểm thử. Chạy cargo test --help hiển thị
các tùy chọn bạn có thể sử dụng với cargo test, và chạy cargo test -- --help
hiển thị các tùy chọn bạn có thể sử dụng sau dấu phân tách. Những tùy chọn đó
cũng được ghi lại trong phần "Tests" của sách rustc.
Chạy Các Bài Kiểm Thử Song Song hoặc Tuần Tự
Khi bạn chạy nhiều bài kiểm thử, theo mặc định chúng chạy song song sử dụng các thread, có nghĩa là chúng chạy xong nhanh hơn và bạn nhận được phản hồi nhanh hơn. Vì các bài kiểm thử đang chạy cùng lúc, bạn phải đảm bảo rằng các bài kiểm thử của bạn không phụ thuộc vào nhau hoặc vào bất kỳ trạng thái chung nào, bao gồm cả môi trường chung, chẳng hạn như thư mục làm việc hiện tại hoặc biến môi trường.
Ví dụ, giả sử mỗi bài kiểm thử của bạn chạy một số code tạo ra một tệp trên đĩa có tên test-output.txt và viết một số dữ liệu vào tệp đó. Sau đó, mỗi bài kiểm thử đọc dữ liệu trong tệp đó và khẳng định rằng tệp chứa một giá trị cụ thể, khác nhau trong mỗi bài kiểm thử. Vì các bài kiểm thử chạy cùng lúc, một bài kiểm thử có thể ghi đè lên tệp trong khoảng thời gian giữa một bài kiểm thử khác đang viết và đọc tệp. Bài kiểm thử thứ hai sẽ thất bại, không phải vì code không đúng mà vì các bài kiểm thử đã can thiệp vào nhau trong quá trình chạy song song. Một giải pháp là đảm bảo mỗi bài kiểm thử ghi vào một tệp khác nhau; giải pháp khác là chạy các bài kiểm thử từng cái một.
Nếu bạn không muốn chạy các bài kiểm thử song song hoặc nếu bạn muốn kiểm soát
chi tiết hơn về số lượng thread được sử dụng, bạn có thể gửi cờ --test-threads
và số thread bạn muốn sử dụng cho tệp nhị phân kiểm thử. Hãy xem ví dụ sau:
$ cargo test -- --test-threads=1
Chúng ta đặt số thread kiểm thử thành 1, báo cho chương trình không sử dụng
bất kỳ tính năng song song nào. Chạy các bài kiểm thử bằng một thread sẽ mất
nhiều thời gian hơn so với chạy chúng song song, nhưng các bài kiểm thử sẽ không
can thiệp vào nhau nếu chúng chia sẻ trạng thái.
Hiển Thị Kết Quả Hàm
Theo mặc định, nếu một bài kiểm thử thành công, thư viện kiểm thử của Rust sẽ
thu thập bất kỳ thứ gì được in ra đầu ra tiêu chuẩn. Ví dụ, nếu chúng ta gọi
println! trong một bài kiểm thử và bài kiểm thử thành công, chúng ta sẽ không
thấy kết quả println! trong terminal; chúng ta sẽ chỉ thấy dòng cho biết bài
kiểm thử đã thành công. Nếu một bài kiểm thử thất bại, chúng ta sẽ thấy bất cứ
thứ gì đã được in ra đầu ra tiêu chuẩn cùng với phần còn lại của thông báo lỗi.
Ví dụ, Listing 11-10 có một hàm ngớ ngẩn in ra giá trị của tham số và trả về 10, cũng như một bài kiểm thử thành công và một bài kiểm thử thất bại.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}Khi chúng ta chạy các bài kiểm thử này với cargo test, chúng ta sẽ thấy kết
quả sau:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Lưu ý rằng không có chỗ nào trong kết quả này chúng ta thấy I got the value 4,
được in ra khi bài kiểm thử thành công chạy. Kết quả đó đã bị thu thập. Kết quả
từ bài kiểm thử thất bại, I got the value 8, xuất hiện trong phần tóm tắt kết
quả kiểm thử, phần này cũng hiển thị nguyên nhân của việc thất bại kiểm thử.
Nếu chúng ta muốn thấy các giá trị được in ra cho các bài kiểm thử thành công,
chúng ta có thể báo cho Rust hiển thị kết quả của các bài kiểm thử thành công
bằng --show-output:
$ cargo test -- --show-output
Khi chúng ta chạy lại các bài kiểm thử trong Listing 11-10 với cờ
--show-output, chúng ta thấy kết quả sau:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Chạy Một Tập Con Các Bài Kiểm Thử Theo Tên
Đôi khi, việc chạy một bộ kiểm thử đầy đủ có thể mất nhiều thời gian. Nếu bạn
đang làm việc trên code trong một khu vực cụ thể, bạn có thể muốn chỉ chạy các
bài kiểm thử liên quan đến code đó. Bạn có thể chọn các bài kiểm thử để chạy
bằng cách truyền cho cargo test tên hoặc các tên của (các) bài kiểm thử bạn
muốn chạy làm đối số.
Để minh họa cách chạy một tập con các bài kiểm thử, trước tiên chúng ta sẽ tạo
ba bài kiểm thử cho hàm add_two của chúng ta, như được hiển thị trong Listing
11-11, và chọn những bài nào để chạy.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}Nếu chúng ta chạy các bài kiểm thử mà không truyền bất kỳ đối số nào, như chúng ta đã thấy trước đây, tất cả các bài kiểm thử sẽ chạy song song:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Chạy Các Bài Kiểm Thử Đơn Lẻ
Chúng ta có thể truyền tên của bất kỳ hàm kiểm thử nào cho cargo test để chỉ
chạy bài kiểm thử đó:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Chỉ có bài kiểm thử có tên one_hundred được chạy; hai bài kiểm thử còn lại
không khớp với tên đó. Kết quả kiểm thử cho chúng ta biết rằng chúng ta có nhiều
bài kiểm thử không được chạy bằng cách hiển thị 2 filtered out ở cuối.
Chúng ta không thể chỉ định tên của nhiều bài kiểm thử theo cách này; chỉ có giá
trị đầu tiên được cung cấp cho cargo test sẽ được sử dụng. Nhưng có một cách
để chạy nhiều bài kiểm thử.
Lọc Để Chạy Nhiều Bài Kiểm Thử
Chúng ta có thể chỉ định một phần của tên bài kiểm thử, và bất kỳ bài kiểm thử
nào có tên khớp với giá trị đó sẽ được chạy. Ví dụ, vì hai trong số các bài kiểm
thử của chúng ta có tên chứa add, chúng ta có thể chạy hai bài đó bằng cách
chạy cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Lệnh này đã chạy tất cả các bài kiểm thử có add trong tên và lọc ra bài kiểm
thử có tên one_hundred. Cũng lưu ý rằng module mà bài kiểm thử xuất hiện trở
thành một phần của tên bài kiểm thử, vì vậy chúng ta có thể chạy tất cả các bài
kiểm thử trong một module bằng cách lọc theo tên của module.
Bỏ Qua Một Số Bài Kiểm Thử Trừ Khi Có Yêu Cầu Cụ Thể
Đôi khi một số bài kiểm thử cụ thể có thể tốn rất nhiều thời gian để thực hiện,
vì vậy bạn có thể muốn loại trừ chúng trong hầu hết các lần chạy cargo test.
Thay vì liệt kê làm đối số tất cả các bài kiểm thử bạn muốn chạy, bạn có thể
thay vào đó chú thích các bài kiểm thử tốn thời gian bằng thuộc tính ignore để
loại trừ chúng, như được hiển thị ở đây:
Tên tệp: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}Sau #[test], chúng ta thêm dòng #[ignore] cho bài kiểm thử mà chúng ta muốn
loại trừ. Bây giờ khi chúng ta chạy các bài kiểm thử, it_works chạy, nhưng
expensive_test thì không:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Hàm expensive_test được liệt kê là ignored (bị bỏ qua). Nếu chúng ta chỉ
muốn chạy các bài kiểm thử bị bỏ qua, chúng ta có thể sử dụng
cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bằng cách kiểm soát các bài kiểm thử được chạy, bạn có thể đảm bảo rằng kết quả
cargo test của bạn sẽ được trả về nhanh chóng. Khi bạn ở một điểm mà việc kiểm
tra kết quả của các bài kiểm thử ignored có ý nghĩa và bạn có thời gian để chờ
đợi kết quả, bạn có thể chạy cargo test -- --ignored thay thế. Nếu bạn muốn
chạy tất cả các bài kiểm thử cho dù chúng có bị bỏ qua hay không, bạn có thể
chạy cargo test -- --include-ignored.
Tổ Chức Kiểm Thử
Như đã đề cập ở đầu chương, kiểm thử là một lĩnh vực phức tạp, và nhiều người sử dụng thuật ngữ và tổ chức khác nhau. Cộng đồng Rust nghĩ về kiểm thử theo hai loại chính: kiểm thử đơn vị và kiểm thử tích hợp. Kiểm thử đơn vị nhỏ và tập trung hơn, kiểm thử một module riêng biệt tại một thời điểm, và có thể kiểm thử các giao diện riêng tư. Kiểm thử tích hợp hoàn toàn bên ngoài thư viện của bạn và sử dụng code của bạn theo cách mà bất kỳ mã bên ngoài nào khác sẽ sử dụng, chỉ sử dụng giao diện công cộng và có thể thực hiện nhiều module trong mỗi bài kiểm thử.
Viết cả hai loại kiểm thử là quan trọng để đảm bảo rằng các thành phần của thư viện của bạn đang hoạt động như bạn mong đợi, cả riêng biệt và cùng nhau.
Kiểm Thử Đơn Vị
Mục đích của kiểm thử đơn vị là kiểm thử từng đơn vị code riêng biệt với phần
còn lại của code để nhanh chóng xác định nơi code đang hoạt động và không hoạt
động như mong đợi. Bạn sẽ đặt các kiểm thử đơn vị trong thư mục src trong mỗi
tệp với code mà chúng đang kiểm thử. Quy ước là tạo một module có tên tests
trong mỗi tệp để chứa các hàm kiểm thử và chú thích module bằng cfg(test).
Module Tests và #[cfg(test)]
Chú thích #[cfg(test)] trên module tests nói với Rust biên dịch và chạy code
kiểm thử chỉ khi bạn chạy cargo test, không phải khi bạn chạy cargo build.
Điều này tiết kiệm thời gian biên dịch khi bạn chỉ muốn xây dựng thư viện và
tiết kiệm không gian trong kết quả biên dịch vì các kiểm thử không được bao gồm.
Bạn sẽ thấy rằng vì kiểm thử tích hợp nằm trong một thư mục khác, chúng không
cần chú thích #[cfg(test)]. Tuy nhiên, vì kiểm thử đơn vị nằm trong cùng tệp
với mã, bạn sẽ sử dụng #[cfg(test)] để chỉ định rằng chúng không nên được bao
gồm trong kết quả biên dịch.
Nhớ lại rằng khi chúng ta tạo dự án mới adder trong phần đầu tiên của chương
này, Cargo đã tạo mã này cho chúng ta:
Tên tệp: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Trên module tests được tự động tạo ra, thuộc tính cfg là viết tắt của cấu
hình và nói với Rust rằng mục tiếp theo chỉ nên được bao gồm khi có một tùy
chọn cấu hình nhất định. Trong trường hợp này, tùy chọn cấu hình là test, được
Rust cung cấp để biên dịch và chạy các bài kiểm thử. Bằng cách sử dụng thuộc
tính cfg, Cargo chỉ biên dịch code kiểm thử của chúng ta nếu chúng ta chủ động
chạy các bài kiểm thử với cargo test. Điều này bao gồm bất kỳ hàm trợ giúp nào
có thể nằm trong module này, ngoài các hàm được chú thích với #[test].
Kiểm Thử Các Hàm Riêng Tư
Có tranh luận trong cộng đồng kiểm thử về việc liệu các hàm riêng tư có nên được
kiểm thử trực tiếp hay không, và các ngôn ngữ khác làm cho việc kiểm thử các hàm
riêng tư trở nên khó khăn hoặc không thể. Bất kể bạn tuân theo ý thức hệ kiểm
thử nào, các quy tắc riêng tư của Rust cho phép bạn kiểm thử các hàm riêng tư.
Hãy xem xét mã trong Listing 11-12 với hàm riêng tư internal_adder.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}Lưu ý rằng hàm internal_adder không được đánh dấu là pub. Các bài kiểm thử
chỉ là mã Rust, và module tests chỉ là một module khác. Như chúng ta đã thảo
luận trong "Đường Dẫn cho Việc Tham Chiếu đến Một Mục trong Cây
Module", các mục trong module con có thể sử dụng các mục
trong module tổ tiên của chúng. Trong bài kiểm thử này, chúng ta đưa tất cả các
mục của module cha của module tests vào phạm vi với use super::*, và sau đó
bài kiểm thử có thể gọi internal_adder. Nếu bạn không nghĩ rằng các hàm riêng
tư nên được kiểm thử, không có gì trong Rust buộc bạn phải làm như vậy.
Kiểm Thử Tích Hợp
Trong Rust, kiểm thử tích hợp hoàn toàn bên ngoài thư viện của bạn. Chúng sử dụng thư viện của bạn theo cách mà bất kỳ mã nào khác sẽ sử dụng, có nghĩa là chúng chỉ có thể gọi các hàm là một phần của API công khai của thư viện của bạn. Mục đích của chúng là kiểm tra liệu nhiều phần của thư viện của bạn có hoạt động cùng nhau một cách chính xác hay không. Các đơn vị mã hoạt động chính xác độc lập có thể gặp vấn đề khi được tích hợp, vì vậy việc kiểm thử bao phủ mã tích hợp cũng rất quan trọng. Để tạo kiểm thử tích hợp, trước tiên bạn cần một thư mục tests.
Thư Mục tests
Chúng ta tạo một thư mục tests ở cấp trên cùng của thư mục dự án, bên cạnh src. Cargo biết cách tìm các tệp kiểm thử tích hợp trong thư mục này. Sau đó, chúng ta có thể tạo nhiều tệp kiểm thử tùy thích, và Cargo sẽ biên dịch mỗi tệp dưới dạng một crate riêng biệt.
Hãy tạo một kiểm thử tích hợp. Với mã trong Listing 11-12 vẫn nằm trong tệp src/lib.rs, hãy tạo một thư mục tests, và tạo một tệp mới có tên tests/integration_test.rs. Cấu trúc thư mục của bạn nên trông như thế này:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Nhập mã trong Listing 11-13 vào tệp tests/integration_test.rs.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}Mỗi tệp trong thư mục tests là một crate riêng biệt, vì vậy chúng ta cần đưa
thư viện của mình vào phạm vi của mỗi crate kiểm thử. Vì lý do đó, chúng ta thêm
use adder::add_two; ở đầu mã, điều mà chúng ta không cần trong các kiểm thử
đơn vị.
Chúng ta không cần chú thích bất kỳ mã nào trong tests/integration_test.rs với
#[cfg(test)]. Cargo xử lý thư mục tests đặc biệt và chỉ biên dịch các tệp
trong thư mục này khi chúng ta chạy cargo test. Chạy cargo test ngay bây
giờ:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ba phần của kết quả bao gồm các kiểm thử đơn vị, kiểm thử tích hợp và kiểm thử tài liệu. Lưu ý rằng nếu bất kỳ bài kiểm thử nào trong một phần không thành công, các phần tiếp theo sẽ không được chạy. Ví dụ, nếu một kiểm thử đơn vị không thành công, sẽ không có kết quả nào cho kiểm thử tích hợp và kiểm thử tài liệu vì những kiểm thử đó chỉ được chạy nếu tất cả các kiểm thử đơn vị đều thành công.
Phần đầu tiên cho các kiểm thử đơn vị giống như những gì chúng ta đã thấy: một
dòng cho mỗi kiểm thử đơn vị (một có tên internal mà chúng ta đã thêm trong
Listing 11-12) và sau đó là một dòng tóm tắt cho các kiểm thử đơn vị.
Phần kiểm thử tích hợp bắt đầu bằng dòng Running tests/integration_test.rs.
Tiếp theo, có một dòng cho mỗi hàm kiểm thử trong kiểm thử tích hợp đó và một
dòng tóm tắt cho kết quả của kiểm thử tích hợp ngay trước khi phần
Doc-tests adder bắt đầu.
Mỗi tệp kiểm thử tích hợp có phần riêng của nó, vì vậy nếu chúng ta thêm nhiều tệp hơn trong thư mục tests, sẽ có nhiều phần kiểm thử tích hợp hơn.
Chúng ta vẫn có thể chạy một hàm kiểm thử tích hợp cụ thể bằng cách chỉ định tên
của hàm kiểm thử làm đối số cho cargo test. Để chạy tất cả các kiểm thử trong
một tệp kiểm thử tích hợp cụ thể, hãy sử dụng đối số --test của cargo test
theo sau là tên của tệp:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Lệnh này chỉ chạy các kiểm thử trong tệp tests/integration_test.rs.
Các Module Con trong Kiểm Thử Tích Hợp
Khi bạn thêm nhiều kiểm thử tích hợp, bạn có thể muốn tạo nhiều tệp trong thư mục tests để giúp tổ chức chúng; ví dụ, bạn có thể nhóm các hàm kiểm thử theo chức năng mà chúng đang kiểm thử. Như đã đề cập trước đây, mỗi tệp trong thư mục tests được biên dịch như là crate riêng biệt của nó, điều này hữu ích để tạo các phạm vi riêng biệt để bắt chước chặt chẽ hơn cách người dùng cuối sẽ sử dụng crate của bạn. Tuy nhiên, điều này có nghĩa là các tệp trong thư mục tests không chia sẻ cùng một hành vi như các tệp trong src, như bạn đã học trong Chương 7 về cách tách mã thành các module và tệp.
Hành vi khác nhau của các tệp thư mục tests là rõ ràng nhất khi bạn có một tập
hợp các hàm trợ giúp để sử dụng trong nhiều tệp kiểm thử tích hợp và bạn cố gắng
làm theo các bước trong phần "Tách Module thành Các Tệp Khác
Nhau" của Chương 7 để trích xuất
chúng vào một module chung. Ví dụ, nếu chúng ta tạo tests/common.rs và đặt một
hàm có tên setup trong đó, chúng ta có thể thêm một số mã vào setup mà chúng
ta muốn gọi từ nhiều hàm kiểm thử trong nhiều tệp kiểm thử:
Tên tệp: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}Khi chúng ta chạy các bài kiểm thử một lần nữa, chúng ta sẽ thấy một phần mới
trong kết quả kiểm thử cho tệp common.rs, ngay cả khi tệp này không chứa bất
kỳ hàm kiểm thử nào và chúng ta cũng không gọi hàm setup từ bất cứ đâu:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Việc common xuất hiện trong kết quả kiểm thử với running 0 tests hiển thị
cho nó không phải là điều chúng ta muốn. Chúng ta chỉ muốn chia sẻ một số mã với
các tệp kiểm thử tích hợp khác. Để tránh làm cho common xuất hiện trong kết
quả kiểm thử, thay vì tạo tests/common.rs, chúng ta sẽ tạo
tests/common/mod.rs. Thư mục dự án bây giờ trông như thế này:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
Đây là quy ước đặt tên cũ mà Rust cũng hiểu mà chúng ta đã đề cập trong "Đường
Dẫn Tệp Thay Thế" ở Chương 7. Đặt tên tệp theo cách
này nói với Rust không xử lý module common như một tệp kiểm thử tích hợp. Khi
chúng ta di chuyển mã hàm setup vào tests/common/mod.rs và xóa tệp
tests/common.rs, phần trong kết quả kiểm thử sẽ không còn xuất hiện nữa. Các
tệp trong thư mục con của thư mục tests không được biên dịch như các crate
riêng biệt hoặc có phần trong kết quả kiểm thử.
Sau khi chúng ta đã tạo tests/common/mod.rs, chúng ta có thể sử dụng nó từ bất
kỳ tệp kiểm thử tích hợp nào như một module. Đây là một ví dụ về việc gọi hàm
setup từ kiểm thử it_adds_two trong tests/integration_test.rs:
Tên tệp: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}Lưu ý rằng khai báo mod common; giống như khai báo module mà chúng ta đã minh
họa trong Listing 7-21. Sau đó, trong hàm kiểm thử, chúng ta có thể gọi hàm
common::setup().
Kiểm Thử Tích Hợp cho Các Crate Nhị Phân
Nếu dự án của chúng ta là một crate nhị phân chỉ chứa một tệp src/main.rs và
không có tệp src/lib.rs, chúng ta không thể tạo kiểm thử tích hợp trong thư
mục tests và đưa các hàm được định nghĩa trong tệp src/main.rs vào phạm vi
với một câu lệnh use. Chỉ có các crate thư viện mới để lộ các hàm mà các crate
khác có thể sử dụng; các crate nhị phân được thiết kế để chạy độc lập.
Đây là một trong những lý do các dự án Rust cung cấp một tệp nhị phân có một tệp
src/main.rs đơn giản gọi logic nằm trong tệp src/lib.rs. Sử dụng cấu trúc
đó, kiểm thử tích hợp có thể kiểm thử crate thư viện với use để làm cho chức
năng quan trọng có sẵn. Nếu chức năng quan trọng hoạt động, lượng mã nhỏ trong
tệp src/main.rs cũng sẽ hoạt động, và lượng mã nhỏ đó không cần phải được kiểm
thử.
Tóm Tắt
Các tính năng kiểm thử của Rust cung cấp một cách để chỉ định cách mã nên hoạt động để đảm bảo nó tiếp tục hoạt động như bạn mong đợi, ngay cả khi bạn thực hiện các thay đổi. Kiểm thử đơn vị kiểm tra các phần khác nhau của thư viện một cách riêng biệt và có thể kiểm tra các chi tiết triển khai riêng tư. Kiểm thử tích hợp kiểm tra xem nhiều phần của thư viện có hoạt động cùng nhau một cách chính xác hay không, và chúng sử dụng API công khai của thư viện để kiểm tra mã theo cùng cách mà mã bên ngoài sẽ sử dụng nó. Mặc dù hệ thống kiểu và quy tắc sở hữu của Rust giúp ngăn chặn một số loại lỗi, các kiểm thử vẫn quan trọng để giảm các lỗi logic liên quan đến cách mã của bạn được mong đợi sẽ hoạt động.
Hãy kết hợp kiến thức bạn đã học trong chương này và trong các chương trước để làm việc trên một dự án!
Dự án I/O: Xây dựng chương trình dòng lệnh
Chương này là phần tổng hợp về nhiều kỹ năng mà bạn đã học được và một khám phá thêm một số tính năng thư viện chuẩn. Chúng ta sẽ xây dựng một công cụ dòng lệnh tương tác với tệp và đầu vào/đầu ra dòng lệnh để thực hành các khái niệm Rust mà bạn đã nắm vững.
Tốc độ, tính an toàn, đầu ra nhị phân đơn và hỗ trợ đa nền tảng của Rust làm cho
nó trở thành ngôn ngữ lý tưởng để tạo công cụ dòng lệnh, vì vậy cho dự án của
chúng ta, chúng ta sẽ tạo phiên bản riêng của công cụ tìm kiếm dòng lệnh cổ điển
grep (globally search a regular expression and print - tìm
kiếm biểu thức chính quy toàn cục và in). Trong trường hợp
sử dụng đơn giản nhất, grep tìm kiếm một chuỗi cụ thể trong một tệp cụ thể. Để
làm được điều này, grep nhận đường dẫn tệp và một chuỗi làm đối số. Sau đó nó
đọc tệp, tìm các dòng trong tệp đó có chứa chuỗi đối số, và in các dòng đó.
Trong quá trình này, chúng ta sẽ chỉ ra cách làm cho công cụ dòng lệnh của chúng
ta sử dụng các tính năng terminal mà nhiều công cụ dòng lệnh khác sử dụng. Chúng
ta sẽ đọc giá trị của một biến môi trường để cho phép người dùng cấu hình hành
vi của công cụ của chúng ta. Chúng ta cũng sẽ in thông báo lỗi đến luồng console
lỗi tiêu chuẩn (stderr) thay vì đầu ra tiêu chuẩn (stdout) để, ví dụ, người
dùng có thể chuyển hướng đầu ra thành công đến một tệp trong khi vẫn nhìn thấy
thông báo lỗi trên màn hình.
Một thành viên cộng đồng Rust, Andrew Gallant, đã tạo ra một phiên bản grep
đầy đủ tính năng, rất nhanh, gọi là ripgrep. So với phiên bản của anh ấy,
phiên bản của chúng ta sẽ khá đơn giản, nhưng chương này sẽ cung cấp cho bạn một
số kiến thức nền tảng cần thiết để hiểu một dự án trong thực tế như ripgrep.
Dự án grep của chúng ta sẽ kết hợp một số khái niệm mà bạn đã học được:
- Tổ chức mã (Chương 7)
- Sử dụng vector và chuỗi (Chương 8)
- Xử lý lỗi (Chương 9)
- Sử dụng trait và lifetime khi thích hợp (Chương 10)
- Viết kiểm thử (Chương 11)
Chúng ta cũng sẽ giới thiệu ngắn gọn về closures, iterators và trait objects, mà Chương 13 và Chương 18 sẽ đề cập chi tiết.
Chấp nhận đối số dòng lệnh
Hãy tạo một dự án mới với, như thường lệ, cargo new. Chúng ta sẽ gọi dự án của
mình là minigrep để phân biệt nó với công cụ grep mà có thể bạn đã có trên
hệ thống của mình.
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Nhiệm vụ đầu tiên là làm cho minigrep chấp nhận hai đối số dòng lệnh của nó:
đường dẫn tệp và một chuỗi để tìm kiếm. Nghĩa là, chúng ta muốn có thể chạy
chương trình của mình với cargo run, hai dấu gạch ngang để chỉ ra rằng các đối
số tiếp theo là dành cho chương trình của chúng ta chứ không phải cho cargo,
một chuỗi để tìm kiếm, và một đường dẫn đến một tệp để tìm kiếm, như sau:
$ cargo run -- searchstring example-filename.txt
Hiện tại, chương trình được tạo ra bởi cargo new không thể xử lý các đối số mà
chúng ta cung cấp. Một số thư viện hiện có trên crates.io
có thể giúp viết một chương trình chấp nhận đối số dòng lệnh, nhưng bởi vì bạn
đang học khái niệm này, hãy tự triển khai khả năng này.
Đọc giá trị đối số
Để cho phép minigrep đọc các giá trị của đối số dòng lệnh mà chúng ta truyền
vào nó, chúng ta sẽ cần hàm std::env::args được cung cấp trong thư viện chuẩn
của Rust. Hàm này trả về một iterator của các đối số dòng lệnh được truyền vào
minigrep. Chúng ta sẽ thảo luận đầy đủ về iterator trong Chương
13. Hiện tại, bạn chỉ cần biết hai chi tiết về iterator: iterator tạo ra một chuỗi
giá trị, và chúng ta có thể gọi phương thức collect trên một iterator để chuyển
nó thành một bộ sưu tập, chẳng hạn như một vector, chứa tất cả các phần tử mà iterator
tạo ra.
Mã trong Listing 12-1 cho phép chương trình minigrep của bạn đọc bất kỳ đối số
dòng lệnh nào được truyền vào nó, và sau đó thu thập các giá trị vào một vector.
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
Đầu tiên chúng ta đưa mô-đun std::env vào phạm vi với câu lệnh use để chúng
ta có thể sử dụng hàm args của nó. Lưu ý rằng hàm std::env::args được lồng
trong hai cấp độ mô-đun. Như chúng ta đã thảo luận trong Chương
7, trong trường hợp mà hàm mong muốn được
lồng trong nhiều hơn một mô-đun, chúng ta đã chọn đưa mô-đun cha vào phạm vi
thay vì hàm. Bằng cách này, chúng ta có thể dễ dàng sử dụng các hàm khác từ
std::env. Nó cũng ít gây nhầm lẫn hơn việc thêm use std::env::args và sau đó
gọi hàm chỉ với args, bởi vì args có thể dễ dàng bị nhầm lẫn với một hàm
được định nghĩa trong mô-đun hiện tại.
Hàm
argsvà Unicode không hợp lệLưu ý rằng
std::env::argssẽ panic nếu bất kỳ đối số nào chứa Unicode không hợp lệ. Nếu chương trình của bạn cần chấp nhận các đối số chứa Unicode không hợp lệ, hãy sử dụngstd::env::args_osthay thế. Hàm đó trả về một iterator tạo ra giá trịOsStringthay vì giá trịString. Chúng ta đã chọn sử dụngstd::env::argsở đây để đơn giản hóa bởi vì giá trịOsStringkhác nhau trên mỗi nền tảng và phức tạp hơn để làm việc so với giá trịString.
Ở dòng đầu tiên của main, chúng ta gọi env::args, và ngay lập tức sử dụng
collect để chuyển iterator thành một vector chứa tất cả các giá trị được tạo
ra bởi iterator. Chúng ta có thể sử dụng hàm collect để tạo nhiều loại bộ sưu
tập khác nhau, vì vậy chúng ta chú thích rõ ràng kiểu của args để chỉ định
rằng chúng ta muốn một vector của các chuỗi. Mặc dù bạn rất hiếm khi cần phải
chú thích kiểu trong Rust, collect là một hàm mà bạn thường cần phải chú thích
bởi vì Rust không thể suy luận được loại bộ sưu tập mà bạn muốn.
Cuối cùng, chúng ta in vector sử dụng macro debug. Hãy thử chạy mã này đầu tiên không có đối số và sau đó với hai đối số:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Lưu ý rằng giá trị đầu tiên trong vector là "target/debug/minigrep", đó là tên
của binary của chúng ta. Điều này phù hợp với hành vi của danh sách đối số trong
C, cho phép các chương trình sử dụng tên mà chúng được gọi trong quá trình thực
thi. Thường rất thuận tiện để có quyền truy cập vào tên chương trình trong
trường hợp bạn muốn in nó trong các thông báo hoặc thay đổi hành vi của chương
trình dựa trên alias dòng lệnh nào được sử dụng để gọi chương trình. Nhưng cho
mục đích của chương này, chúng ta sẽ bỏ qua nó và chỉ lưu hai đối số mà chúng ta
cần.
Lưu giá trị đối số trong các biến
Chương trình hiện tại có thể truy cập các giá trị được chỉ định làm đối số dòng lệnh. Bây giờ chúng ta cần lưu giá trị của hai đối số trong các biến để chúng ta có thể sử dụng các giá trị đó trong phần còn lại của chương trình. Chúng ta làm điều đó trong Listing 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}Như chúng ta đã thấy khi in vector, tên của chương trình chiếm vị trí giá trị
đầu tiên trong vector tại args[0], vì vậy chúng ta bắt đầu đối số từ chỉ
mục 1. Đối số đầu tiên mà minigrep nhận là chuỗi chúng ta đang tìm kiếm, vì
vậy chúng ta đặt một tham chiếu đến đối số đầu tiên trong biến query. Đối số
thứ hai sẽ là đường dẫn tệp, vì vậy chúng ta đặt một tham chiếu đến đối số thứ
hai trong biến file_path.
Chúng ta tạm thời in các giá trị của những biến này để chứng minh rằng mã đang
hoạt động như chúng ta mong muốn. Hãy chạy chương trình này một lần nữa với các
đối số test và sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Tuyệt vời, chương trình đang hoạt động! Giá trị của các đối số mà chúng ta cần đang được lưu vào các biến đúng. Sau này, chúng ta sẽ thêm xử lý lỗi để đối phó với một số tình huống lỗi tiềm ẩn, chẳng hạn như khi người dùng không cung cấp đối số; hiện tại, chúng ta sẽ bỏ qua tình huống đó và làm việc để thêm khả năng đọc tệp thay vào đó.
Đọc một tệp
Bây giờ chúng ta sẽ thêm chức năng để đọc tệp được chỉ định trong đối số
file_path. Đầu tiên chúng ta cần một tệp mẫu để kiểm tra: chúng ta sẽ sử dụng
một tệp với một lượng nhỏ văn bản trên nhiều dòng với một số từ được lặp lại.
Listing 12-3 có một bài thơ của Emily Dickinson sẽ phù hợp! Tạo một tệp tên là
poem.txt ở cấp gốc của dự án của bạn, và nhập bài thơ "I'm Nobody! Who are
you?"
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Với văn bản đã sẵn sàng, chỉnh sửa src/main.rs và thêm mã để đọc tệp, như đã hiển thị trong Listing 12-4.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}Đầu tiên, chúng ta đưa một phần liên quan của thư viện chuẩn vào với một câu
lệnh use: chúng ta cần std::fs để xử lý tệp.
Trong main, câu lệnh mới fs::read_to_string nhận file_path, mở tệp đó và
trả về một giá trị kiểu std::io::Result<String> chứa nội dung tệp.
Sau đó, chúng ta lại thêm một câu lệnh println! tạm thời để in giá trị của
contents sau khi tệp được đọc, để chúng ta có thể kiểm tra xem chương trình
đang hoạt động tốt đến đâu.
Hãy chạy mã này với bất kỳ chuỗi nào làm đối số dòng lệnh đầu tiên (vì chúng ta chưa triển khai phần tìm kiếm) và tệp poem.txt làm đối số thứ hai:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Tuyệt vời! Mã đã đọc và sau đó in nội dung của tệp. Nhưng mã có một vài khuyết
điểm. Hiện tại, hàm main có nhiều trách nhiệm: nói chung, các hàm rõ ràng và
dễ bảo trì hơn nếu mỗi hàm chỉ chịu trách nhiệm cho một ý tưởng duy nhất. Vấn đề
khác là chúng ta không xử lý lỗi tốt như chúng ta có thể. Chương trình vẫn còn
nhỏ, nên những khuyết điểm này không phải là vấn đề lớn, nhưng khi chương trình
phát triển, sẽ khó khăn hơn để sửa chúng một cách gọn gàng. Đó là một thực hành
tốt để bắt đầu tái cấu trúc sớm khi phát triển một chương trình vì việc tái cấu
trúc lượng mã nhỏ hơn dễ dàng hơn nhiều. Chúng ta sẽ làm điều đó tiếp theo.
Tái cấu trúc để cải thiện tính module hóa và xử lý lỗi
Để cải thiện chương trình của chúng ta, chúng ta sẽ sửa bốn vấn đề liên quan đến
cấu trúc chương trình và cách nó xử lý các lỗi tiềm ẩn. Đầu tiên, hàm main của
chúng ta hiện thực hiện hai nhiệm vụ: phân tích đối số và đọc tệp. Khi chương
trình của chúng ta phát triển, số lượng nhiệm vụ riêng biệt mà hàm main xử lý
sẽ tăng lên. Khi một hàm có thêm nhiều trách nhiệm, nó trở nên khó hiểu hơn, khó
kiểm thử hơn, và khó thay đổi mà không làm hỏng một trong những phần của nó. Tốt
nhất là tách biệt chức năng để mỗi hàm chịu trách nhiệm cho một nhiệm vụ.
Vấn đề này cũng liên quan đến vấn đề thứ hai: mặc dù query và file_path là
các biến cấu hình cho chương trình của chúng ta, các biến như contents được sử
dụng để thực hiện logic của chương trình. Càng dài main trở nên, càng nhiều
biến chúng ta sẽ cần đưa vào phạm vi; càng nhiều biến chúng ta có trong phạm vi,
càng khó để theo dõi mục đích của mỗi biến. Tốt nhất là nhóm các biến cấu hình
vào một cấu trúc để làm rõ mục đích của chúng.
Vấn đề thứ ba là chúng ta đã sử dụng expect để in một thông báo lỗi khi đọc
tệp thất bại, nhưng thông báo lỗi chỉ in ra
Should have been able to read the file. Đọc một tệp có thể thất bại vì nhiều
lý do: ví dụ, tệp có thể không tồn tại, hoặc chúng ta có thể không có quyền để
mở nó. Hiện tại, bất kể tình huống nào, chúng ta sẽ in cùng một thông báo lỗi
cho mọi thứ, điều này sẽ không cung cấp cho người dùng bất kỳ thông tin nào!
Thứ tư, chúng ta sử dụng expect để xử lý lỗi, và nếu người dùng chạy chương
trình của chúng ta mà không chỉ định đủ đối số, họ sẽ nhận được lỗi
index out of bounds từ Rust không giải thích rõ ràng vấn đề. Sẽ tốt nhất nếu
tất cả mã xử lý lỗi đều ở một nơi để những người bảo trì trong tương lai chỉ có
một nơi để tham khảo mã nếu logic xử lý lỗi cần thay đổi. Có tất cả mã xử lý lỗi
ở một nơi cũng sẽ đảm bảo rằng chúng ta đang in các thông báo có ý nghĩa đối với
người dùng cuối của chúng ta.
Hãy giải quyết bốn vấn đề này bằng cách tái cấu trúc dự án của chúng ta.
Tách biệt các mối quan tâm cho các dự án nhị phân
Vấn đề tổ chức của việc phân bổ trách nhiệm cho nhiều nhiệm vụ cho hàm main là
phổ biến đối với nhiều dự án nhị phân. Kết quả là, nhiều lập trình viên Rust cảm
thấy hữu ích khi tách các mối quan tâm riêng biệt của một chương trình nhị phân
khi hàm main bắt đầu trở nên lớn. Quá trình này có các bước sau:
- Chia chương trình của bạn thành một tệp main.rs và một tệp lib.rs và di chuyển logic chương trình của bạn sang lib.rs.
- Miễn là logic phân tích dòng lệnh của bạn nhỏ, nó có thể ở lại trong hàm
main. - Khi logic phân tích dòng lệnh bắt đầu trở nên phức tạp, hãy trích xuất nó từ
hàm
mainthành các hàm hoặc kiểu dữ liệu khác.
Các trách nhiệm còn lại trong hàm main sau quá trình này nên được giới hạn
trong các nội dung sau:
- Gọi logic phân tích dòng lệnh với các giá trị đối số
- Thiết lập bất kỳ cấu hình nào khác
- Gọi hàm
runtrong lib.rs - Xử lý lỗi nếu
runtrả về lỗi
Mẫu này là về việc tách biệt các mối quan tâm: main.rs xử lý việc chạy chương
trình và lib.rs xử lý tất cả logic của nhiệm vụ hiện tại. Bởi vì bạn không thể
kiểm tra hàm main trực tiếp, cấu trúc này cho phép bạn kiểm tra tất cả logic
chương trình của bạn bằng cách di chuyển ra ngoài hàm main. Mã còn lại trong
hàm main sẽ đủ nhỏ để xác minh tính đúng đắn của nó bằng cách đọc nó. Hãy làm
lại chương trình của chúng ta bằng cách theo quy trình này.
Trích xuất trình phân tích đối số
Chúng ta sẽ trích xuất chức năng phân tích đối số vào một hàm mà main sẽ gọi.
Listing 12-5 hiển thị phần bắt đầu mới của main gọi một hàm mới
parse_config, mà chúng ta sẽ định nghĩa trong src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}Chúng ta vẫn đang thu thập các đối số dòng lệnh vào một vector, nhưng thay vì
gán giá trị đối số tại chỉ số 1 cho biến query và giá trị đối số tại chỉ số 2
cho biến file_path trong hàm main, chúng ta truyền toàn bộ vector cho hàm
parse_config. Hàm parse_config sau đó giữ logic xác định đối số nào vào biến
nào và truyền các giá trị trở lại cho main. Chúng ta vẫn tạo các biến query
và file_path trong main, nhưng main không còn có trách nhiệm xác định cách
các đối số dòng lệnh và các biến tương ứng.
Việc tái cấu trúc này có vẻ như là quá mức cần thiết cho chương trình nhỏ của chúng ta, nhưng chúng ta đang tái cấu trúc theo các bước nhỏ, tăng dần. Sau khi thực hiện thay đổi này, chạy chương trình lần nữa để xác minh rằng việc phân tích đối số vẫn hoạt động. Tốt nhất là kiểm tra tiến trình của bạn thường xuyên, để giúp xác định nguyên nhân của các vấn đề khi chúng xảy ra.
Nhóm các giá trị cấu hình
Chúng ta có thể thực hiện một bước nhỏ nữa để cải thiện hàm parse_config hơn
nữa. Hiện tại, chúng ta đang trả về một tuple, nhưng sau đó chúng ta ngay lập
tức phân chia tuple đó thành các phần riêng biệt một lần nữa. Đây là một dấu
hiệu cho thấy có lẽ chúng ta chưa có sự trừu tượng hóa đúng đắn.
Một chỉ báo khác cho thấy có chỗ để cải thiện là phần config của
parse_config, ngụ ý rằng hai giá trị mà chúng ta trả về có liên quan và đều là
một phần của một giá trị cấu hình. Hiện tại, chúng ta không truyền tải ý nghĩa
này trong cấu trúc của dữ liệu ngoài việc nhóm hai giá trị vào một tuple; thay
vào đó, chúng ta sẽ đặt hai giá trị vào một struct và đặt tên cho mỗi trường của
struct một cách có ý nghĩa. Làm như vậy sẽ giúp cho những người bảo trì mã này
trong tương lai dễ dàng hiểu các giá trị khác nhau liên quan đến nhau như thế
nào và mục đích của chúng là gì.
Listing 12-6 hiển thị các cải tiến cho hàm parse_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}Chúng ta đã thêm một struct có tên Config được định nghĩa để có các trường tên
là query và file_path. Chữ ký của parse_config bây giờ chỉ ra rằng nó trả
về một giá trị Config. Trong thân của parse_config, nơi mà chúng ta đã từng
trả về các slice chuỗi tham chiếu đến các giá trị String trong args, bây giờ
chúng ta định nghĩa Config để chứa các giá trị String sở hữu. Biến args
trong main là chủ sở hữu của các giá trị đối số và chỉ cho phép hàm
parse_config mượn chúng, điều đó có nghĩa là chúng ta sẽ vi phạm quy tắc mượn
của Rust nếu Config cố gắng nắm quyền sở hữu các giá trị trong args.
Có một số cách chúng ta có thể quản lý dữ liệu String; cách dễ nhất, mặc dù
không hiệu quả lắm, là gọi phương thức clone trên các giá trị. Điều này sẽ tạo
một bản sao đầy đủ của dữ liệu cho thể hiện Config để sở hữu, mà tốn nhiều
thời gian và bộ nhớ hơn việc lưu trữ một tham chiếu đến dữ liệu chuỗi. Tuy
nhiên, việc sao chép dữ liệu cũng làm cho mã của chúng ta rất đơn giản vì chúng
ta không phải quản lý thời gian sống của các tham chiếu; trong trường hợp này,
việc hi sinh một chút hiệu suất để đạt được sự đơn giản là một sự đánh đổi đáng
giá.
Sự đánh đổi khi sử dụng
cloneCó một xu hướng trong nhiều người dùng Rust là tránh sử dụng
cloneđể sửa vấn đề sở hữu vì chi phí thời gian chạy của nó. Trong Chương 13, bạn sẽ học cách sử dụng các phương pháp hiệu quả hơn trong loại tình huống này. Nhưng hiện tại, sao chép một vài chuỗi để tiếp tục tiến triển là ổn vì bạn sẽ chỉ tạo các bản sao này một lần và đường dẫn tệp cùng chuỗi truy vấn của bạn rất nhỏ. Tốt hơn là có một chương trình hoạt động mà hơi kém hiệu quả một chút so với việc cố gắng tối ưu hóa quá mức mã trong lần đầu tiên của bạn. Khi bạn có nhiều kinh nghiệm hơn với Rust, sẽ dễ dàng hơn để bắt đầu với giải pháp hiệu quả nhất, nhưng hiện tại, việc gọiclonelà hoàn toàn chấp nhận được.
Chúng ta đã cập nhật main để nó đặt thể hiện Config được trả về bởi
parse_config vào một biến tên là config, và chúng ta đã cập nhật mã mà trước
đây sử dụng các biến query và file_path riêng biệt để bây giờ nó sử dụng các
trường trên struct Config thay thế.
Bây giờ mã của chúng ta truyền tải rõ ràng hơn rằng query và file_path có
liên quan và mục đích của chúng là để cấu hình cách chương trình sẽ hoạt động.
Bất kỳ mã nào sử dụng các giá trị này đều biết tìm chúng trong thể hiện config
trong các trường được đặt tên theo mục đích của chúng.
Tạo một hàm khởi tạo cho Config
Cho đến giờ, chúng ta đã trích xuất logic chịu trách nhiệm phân tích các đối số
dòng lệnh từ main và đặt nó trong hàm parse_config. Làm như vậy đã giúp
chúng ta thấy rằng các giá trị query và file_path có liên quan, và mối quan
hệ đó nên được truyền tải trong mã của chúng ta. Sau đó, chúng ta đã thêm một
struct Config để đặt tên cho mục đích liên quan của query và file_path và
để có thể trả lại tên của các giá trị dưới dạng tên trường struct từ hàm
parse_config.
Do đó, bây giờ mục đích của hàm parse_config là để tạo một thể hiện Config,
chúng ta có thể thay đổi parse_config từ một hàm đơn giản thành một hàm có tên
new được liên kết với struct Config. Thực hiện thay đổi này sẽ làm cho mã
trở nên thông dụng hơn. Chúng ta có thể tạo các thể hiện của các kiểu trong thư
viện chuẩn, chẳng hạn như String, bằng cách gọi String::new. Tương tự, bằng
cách thay đổi parse_config thành một hàm new liên kết với Config, chúng ta
sẽ có thể tạo các thể hiện của Config bằng cách gọi Config::new. Listing
12-7 hiển thị các thay đổi mà chúng ta cần thực hiện.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Chúng ta đã cập nhật main nơi chúng ta đã gọi parse_config để thay vào đó
gọi Config::new. Chúng ta đã thay đổi tên của parse_config thành new và di
chuyển nó trong một khối impl, vốn liên kết hàm new với Config. Hãy thử
biên dịch mã này lần nữa để đảm bảo rằng nó hoạt động.
Sửa chữa việc xử lý lỗi
Bây giờ chúng ta sẽ làm việc để sửa chữa việc xử lý lỗi của mình. Hãy nhớ lại
rằng việc cố gắng truy cập các giá trị trong vector args tại chỉ số 1 hoặc chỉ
số 2 sẽ khiến chương trình panic nếu vector chứa ít hơn ba phần tử. Hãy thử chạy
chương trình mà không có bất kỳ đối số nào; nó sẽ trông như thế này:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Dòng index out of bounds: the len is 1 but the index is 1 là một thông báo lỗi
dành cho lập trình viên. Nó sẽ không giúp người dùng cuối của chúng ta hiểu họ
nên làm gì thay thế. Hãy sửa điều đó ngay bây giờ.
Cải thiện thông báo lỗi
Trong Listing 12-8, chúng ta thêm một kiểm tra trong hàm new sẽ xác minh rằng
slice đủ dài trước khi truy cập chỉ số 1 và chỉ số 2. Nếu slice không đủ dài,
chương trình panic và hiển thị một thông báo lỗi tốt hơn.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Mã này tương tự như hàm Guess::new mà chúng ta đã viết trong Listing
9-13, nơi chúng ta đã gọi panic! khi đối số
value nằm ngoài phạm vi các giá trị hợp lệ. Thay vì kiểm tra cho một phạm vi
giá trị ở đây, chúng ta kiểm tra rằng độ dài của args ít nhất là 3 và phần
còn lại của hàm có thể hoạt động dưới giả định rằng điều kiện này đã được đáp
ứng. Nếu args có ít hơn ba mục, điều kiện này sẽ là true, và chúng ta gọi
macro panic! để kết thúc chương trình ngay lập tức.
Với một vài dòng mã bổ sung này trong new, hãy chạy chương trình mà không có
bất kỳ đối số nào một lần nữa để xem lỗi trông như thế nào bây giờ:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Đầu ra này tốt hơn: bây giờ chúng ta có một thông báo lỗi hợp lý. Tuy nhiên,
chúng ta cũng có thông tin không cần thiết mà chúng ta không muốn cung cấp cho
người dùng. Có lẽ kỹ thuật mà chúng ta đã sử dụng trong Listing 9-13 không phải
là cách tốt nhất để sử dụng ở đây: một cuộc gọi đến panic! thích hợp hơn cho
một vấn đề lập trình hơn là một vấn đề sử dụng, như đã thảo luận trong Chương
9. Thay vào đó, chúng ta sẽ sử dụng kỹ
thuật khác mà bạn đã học về trong Chương 9—trả về một
Result cho biết thành công hoặc một lỗi.
Trả về một Result thay vì gọi panic!
Thay vào đó, chúng ta có thể trả về một giá trị Result sẽ chứa một thể hiện
Config trong trường hợp thành công và sẽ mô tả vấn đề trong trường hợp lỗi.
Chúng ta cũng sẽ thay đổi tên hàm từ new thành build vì nhiều lập trình viên
mong đợi các hàm new không bao giờ thất bại. Khi Config::build đang giao
tiếp với main, chúng ta có thể sử dụng kiểu Result để báo hiệu có một vấn
đề. Sau đó chúng ta có thể thay đổi main để chuyển đổi một biến thể Err
thành một lỗi thực tế hơn cho người dùng của chúng ta mà không có các văn bản
xung quanh về thread 'main' và RUST_BACKTRACE mà một cuộc gọi đến panic!
gây ra.
Listing 12-9 hiển thị các thay đổi mà chúng ta cần thực hiện cho giá trị trả về
của hàm mà chúng ta hiện đang gọi là Config::build và thân của hàm cần thiết
để trả về một Result. Lưu ý rằng điều này sẽ không biên dịch cho đến khi chúng
ta cập nhật main cũng vậy, điều mà chúng ta sẽ làm trong danh sách tiếp theo.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Hàm build của chúng ta trả về một Result với một thể hiện Config trong
trường hợp thành công và một chuỗi chữ trong trường hợp lỗi. Các giá trị lỗi của
chúng ta sẽ luôn luôn là các chuỗi chữ có thời gian sống 'static.
Chúng ta đã thực hiện hai thay đổi trong thân hàm: thay vì gọi panic! khi
người dùng không truyền đủ đối số, chúng ta hiện trả về một giá trị Err, và
chúng ta đã bọc giá trị trả về Config trong một Ok. Những thay đổi này làm
cho hàm phù hợp với chữ ký kiểu mới của nó.
Việc trả về một giá trị Err từ Config::build cho phép hàm main xử lý giá
trị Result được trả về từ hàm build và thoát khỏi quá trình một cách sạch sẽ
hơn trong trường hợp lỗi.
Gọi Config::build và xử lý lỗi
Để xử lý trường hợp lỗi và in một thông báo thân thiện với người dùng, chúng ta
cần cập nhật main để xử lý Result được trả về bởi Config::build, như hiển
thị trong Listing 12-10. Chúng ta cũng sẽ lấy trách nhiệm thoát khỏi công cụ
dòng lệnh với một mã lỗi khác không từ panic! và thay vào đó thực hiện nó bằng
tay. Một trạng thái thoát khác không là một quy ước để báo hiệu cho quá trình
gọi chương trình của chúng ta rằng chương trình đã thoát với trạng thái lỗi.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Trong danh sách này, chúng ta đã sử dụng một phương thức mà chúng ta chưa đề cập
đến chi tiết: unwrap_or_else, nó được định nghĩa trên Result<T, E> bởi thư
viện chuẩn. Sử dụng unwrap_or_else cho phép chúng ta định nghĩa một số xử lý
lỗi tùy chỉnh, không phải panic!. Nếu Result là một giá trị Ok, hành vi
của phương thức này giống với unwrap: nó trả về giá trị bên trong mà Ok đang
bọc. Tuy nhiên, nếu giá trị là một giá trị Err, phương thức này gọi mã trong
closure, đó là một hàm ẩn danh mà chúng ta định nghĩa và truyền làm đối số cho
unwrap_or_else. Chúng ta sẽ đề cập đến closure chi tiết hơn trong Chương
13. Hiện tại, bạn chỉ cần biết rằng unwrap_or_else sẽ
truyền giá trị bên trong của Err, trong trường hợp này là chuỗi tĩnh
"not enough arguments" mà chúng ta đã thêm trong Listing 12-9, cho closure
trong đối số err vốn xuất hiện giữa các đường dọc. Mã trong closure sau đó có
thể sử dụng giá trị err khi nó chạy.
Chúng ta đã thêm một dòng use mới để đưa process từ thư viện chuẩn vào phạm
vi. Mã trong closure sẽ được chạy trong trường hợp lỗi chỉ có hai dòng: chúng ta
in giá trị err và sau đó gọi process::exit. Hàm process::exit sẽ dừng
chương trình ngay lập tức và trả về số được truyền làm mã trạng thái thoát. Điều
này tương tự như xử lý dựa trên panic! mà chúng ta đã sử dụng trong Listing
12-8, nhưng chúng ta không còn nhận được tất cả đầu ra bổ sung. Hãy thử nó:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Tuyệt vời! Đầu ra này thân thiện hơn nhiều với người dùng của chúng ta.
Trích xuất logic từ hàm main
Bây giờ chúng ta đã hoàn thành việc tái cấu trúc phân tích cấu hình, hãy chuyển
sang logic của chương trình. Như chúng ta đã nêu trong
"Tách biệt các mối quan tâm cho các dự án nhị phân",
chúng ta sẽ trích xuất một hàm tên là run sẽ chứa tất cả logic hiện tại trong
hàm main không liên quan đến thiết lập cấu hình hoặc xử lý lỗi. Khi chúng ta
hoàn thành, hàm main sẽ ngắn gọn và dễ dàng xác minh bằng việc kiểm tra, và
chúng ta sẽ có thể viết các bài kiểm tra cho tất cả các logic khác.
Listing 12-11 hiển thị sự cải thiện nhỏ, tăng dần của việc trích xuất một hàm
run.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Hàm run hiện chứa tất cả logic còn lại từ main, bắt đầu từ việc đọc tệp. Hàm
run nhận thể hiện Config làm một đối số.
Trả về lỗi từ hàm run
Với logic chương trình còn lại đã được tách biệt vào hàm run, chúng ta có thể
cải thiện xử lý lỗi, như chúng ta đã làm với Config::build trong Listing 12-9.
Thay vì cho phép chương trình panic bằng cách gọi expect, hàm run sẽ trả về
một Result<T, E> khi có gì đó không ổn. Điều này sẽ cho phép chúng ta hợp nhất
hơn nữa logic xử lý lỗi vào main theo một cách thân thiện với người dùng.
Listing 12-12 hiển thị các thay đổi chúng ta cần thực hiện cho chữ ký và thân
của run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Chúng ta đã thực hiện ba thay đổi đáng kể ở đây. Đầu tiên, chúng ta đã thay đổi
kiểu trả về của hàm run thành Result<(), Box<dyn Error>>. Hàm này trước đây
trả về kiểu đơn vị, (), và chúng ta giữ giá trị đó làm giá trị được trả về
trong trường hợp Ok.
Đối với kiểu lỗi, chúng ta đã sử dụng trait object Box<dyn Error> (và chúng
ta đã đưa std::error::Error vào phạm vi với một câu lệnh use ở đầu). Chúng
ta sẽ nói về trait object trong Chương 18. Hiện tại, chỉ
cần biết rằng Box<dyn Error> có nghĩa là hàm sẽ trả về một kiểu mà thực hiện
trait Error, nhưng chúng ta không phải chỉ định kiểu cụ thể mà giá trị trả về
sẽ là. Điều này cung cấp cho chúng ta sự linh hoạt để trả về các giá trị lỗi có
thể thuộc các kiểu khác nhau trong các trường hợp lỗi khác nhau. Từ khóa dyn
là viết tắt của dynamic.
Thứ hai, chúng ta đã loại bỏ lệnh gọi đến expect để ủng hộ toán tử ?, như
chúng ta đã nói trong Chương 9. Thay vì
panic! khi có lỗi, ? sẽ trả về giá trị lỗi từ hàm hiện tại để người gọi xử
lý.
Thứ ba, hàm run bây giờ trả về một giá trị Ok trong trường hợp thành công.
Chúng ta đã khai báo kiểu thành công của hàm run là () trong chữ ký, có
nghĩa là chúng ta cần bọc giá trị kiểu đơn vị trong giá trị Ok. Cú pháp
Ok(()) này có vẻ hơi kỳ lạ lúc đầu, nhưng sử dụng () như thế này là cách
thông dụng để chỉ ra rằng chúng ta đang gọi run chỉ vì các hiệu ứng phụ của
nó; nó không trả về một giá trị mà chúng ta cần.
Khi bạn chạy mã này, nó sẽ biên dịch nhưng sẽ hiển thị một cảnh báo:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust cho chúng ta biết rằng mã của chúng ta đã bỏ qua giá trị Result và giá
trị Result có thể chỉ ra rằng một lỗi đã xảy ra. Nhưng chúng ta không kiểm tra
xem liệu có hay không có lỗi, và trình biên dịch nhắc nhở chúng ta rằng có lẽ
chúng ta muốn có mã xử lý lỗi ở đây! Hãy sửa vấn đề đó ngay bây giờ.
Xử lý lỗi trả về từ run trong main
Chúng ta sẽ kiểm tra lỗi và xử lý chúng bằng một kỹ thuật tương tự như một kỹ
thuật chúng ta đã sử dụng với Config::build trong Listing 12-10, nhưng với một
chút khác biệt:
Tên tệp: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Chúng ta sử dụng if let thay vì unwrap_or_else để kiểm tra xem run có trả
về một giá trị Err hay không và gọi process::exit(1) nếu nó trả về. Hàm
run không trả về một giá trị mà chúng ta muốn unwrap theo cùng cách mà
Config::build trả về thể hiện Config. Bởi vì run trả về () trong trường
hợp thành công, chúng ta chỉ quan tâm đến việc phát hiện một lỗi, vì vậy chúng
ta không cần unwrap_or_else để trả về giá trị unwrapped, chỉ là ().
Thân của if let và các hàm unwrap_or_else là giống nhau trong cả hai trường
hợp: chúng ta in lỗi và thoát.
Chia mã thành một Crate thư viện
Dự án minigrep của chúng ta đang hoạt động tốt cho đến nay! Bây giờ chúng ta
sẽ chia tệp src/main.rs và đặt một số mã vào tệp src/lib.rs. Bằng cách đó,
chúng ta có thể kiểm tra mã và có một tệp src/main.rs với ít trách nhiệm hơn.
Hãy định nghĩa đoạn code chịu trách nhiệm tìm kiếm văn bản trong file
src/lib.rs thay vì trong src/main.rs. Việc này sẽ cho phép chúng ta (hoặc
bất kỳ ai khác sử dụng thư viện minigrep của chúng ta) gọi hàm tìm kiếm từ
nhiều ngữ cảnh hơn là chỉ từ chương trình nhị phân minigrep của chúng ta.
Nội dung của src/lib.rs nên có các chữ ký được hiển thị trong Listing 12-13 (chúng ta đã bỏ qua thân của các hàm để ngắn gọn). Lưu ý rằng điều này sẽ không biên dịch cho đến khi chúng ta sửa đổi src/main.rs trong Listing 12-14.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}Chúng ta đã sử dụng từ khóa pub trên định nghĩa hàm để chỉ định hàm search là một phần của API công khai của crate thư viện của chúng ta. Giờ đây, chúng ta có một crate thư viện mà chúng ta có thể sử dụng từ crate nhị phân của mình và cũng có thể kiểm thử!
Bây giờ chúng ta cần đưa mã mà chúng ta đã định nghĩa trong src/lib.rs vào phạm vi của crate nhị phân trong src/main.rs và gọi hàm đó, như hiển thị trong Listing 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}Chúng ta thêm dòng use minigrep::search để đưa hàm search từ crate thư viện
vào phạm vi của crate nhị phân. Sau đó, trong hàm run, thay vì in toàn bộ nội
dung của file, chúng ta gọi hàm search và truyền giá trị config.query cùng
với contents làm đối số. Kế tiếp, hàm run sẽ sử dụng vòng lặp for để in ra
mỗi dòng được trả về từ search mà khớp với truy vấn. Đây cũng là thời điểm
thích hợp để xóa các lệnh gọi println! trong hàm main trước đây dùng để hiển
thị truy vấn và đường dẫn file, để chương trình của chúng ta chỉ in ra kết quả
tìm kiếm (nếu không có lỗi xảy ra).
Lưu ý rằng hàm tìm kiếm sẽ thu thập tất cả các kết quả vào một vector mà nó trả về trước khi việc in ấn diễn ra. Việc triển khai này có thể chậm khi hiển thị kết quả lúc tìm kiếm các file lớn vì kết quả không được in ra ngay khi chúng được tìm thấy; chúng ta sẽ thảo luận một cách khả thi để khắc phục điều này bằng cách sử dụng iterators trong Chương 13.
Chà! Đó là một công việc lớn, nhưng chúng ta đã thiết lập bản thân để thành công trong tương lai. Bây giờ việc xử lý lỗi dễ dàng hơn nhiều và chúng ta đã làm cho mã trở nên module hơn. Gần như tất cả công việc của chúng ta sẽ được thực hiện trong src/lib.rs từ bây giờ.
Hãy tận dụng tính module hóa mới này bằng cách làm một điều mà lẽ ra đã khó với mã cũ nhưng dễ dàng với mã mới: chúng ta sẽ viết một số bài kiểm tra!
Phát triển chức năng của thư viện với phát triển hướng kiểm thử
Giờ đây, khi logic tìm kiếm đã được tách ra khỏi hàm main và nằm trong
src/lib.rs, việc viết kiểm thử cho chức năng cốt lõi của code trở nên dễ dàng
hơn rất nhiều. Chúng ta có thể gọi trực tiếp các hàm với nhiều đối số khác nhau
và kiểm tra giá trị trả về mà không cần phải chạy chương trình nhị phân của mình
từ dòng lệnh.
Trong phần này, chúng ta sẽ thêm logic tìm kiếm vào chương trình minigrep bằng
cách sử dụng quy trình phát triển hướng kiểm thử (TDD) với các bước sau:
- Viết một bài kiểm thử thất bại và chạy nó để đảm bảo rằng nó thất bại vì lý do bạn mong đợi.
- Viết hoặc chỉnh sửa đủ mã để làm cho bài kiểm thử mới vượt qua.
- Cải tiến mã bạn vừa thêm hoặc thay đổi và đảm bảo các bài kiểm thử tiếp tục vượt qua.
- Lặp lại từ bước 1!
Mặc dù đây chỉ là một trong nhiều cách để viết phần mềm, TDD có thể giúp định hướng thiết kế mã. Viết bài kiểm thử trước khi bạn viết mã làm cho bài kiểm thử vượt qua giúp duy trì độ phủ kiểm thử cao trong suốt quá trình.
Chúng ta sẽ kiểm tra-hướng việc triển khai chức năng thực sự tìm kiếm chuỗi truy
vấn trong nội dung tệp và tạo ra danh sách các dòng phù hợp với truy vấn. Chúng
ta sẽ thêm chức năng này trong một hàm gọi là search.
Viết một bài kiểm thử thất bại
Trong file src/lib.rs, chúng ta sẽ thêm một module tests cùng với một hàm
kiểm thử, giống như cách chúng ta đã làm trong Chương 11. Hàm
kiểm thử này sẽ chỉ định hành vi mà chúng ta mong muốn hàm search thực hiện:
nó sẽ nhận vào một chuỗi truy vấn (query) và đoạn văn bản cần tìm kiếm (text),
sau đó sẽ chỉ trả về những dòng từ văn bản đó mà có chứa chuỗi truy vấn. Listing
12-15 sẽ thể hiện bài kiểm thử này.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Bài kiểm thử này tìm kiếm chuỗi "duct". Văn bản chúng ta đang tìm kiếm có ba
dòng, chỉ có một dòng chứa "duct" (lưu ý rằng dấu gạch chéo ngược sau dấu
ngoặc kép mở báo với Rust không đặt ký tự xuống dòng vào đầu nội dung của chuỗi
chữ này). Chúng ta khẳng định rằng giá trị trả về từ hàm search chỉ chứa dòng
mà chúng ta mong đợi.
Nếu chúng ta chạy bài kiểm thử này, nó sẽ thất bại hiện tại vì macro
unimplemented! sẽ panic! với thông báo “not implemented”. Tuân thủ nguyên tắc
TDD (Test-Driven Development), chúng ta sẽ thực hiện một bước nhỏ: chỉ thêm đủ
code để bài kiểm thử không bị panic! khi gọi hàm bằng cách định nghĩa hàm
search luôn trả về một vector rỗng, như trong Listing 12-16. Sau đó, bài kiểm
thử sẽ biên dịch được và vẫn thất bại vì một vector rỗng không khớp với vector
chứa dòng "safe, fast, productive."
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Bây giờ, chúng ta hãy thảo luận lý do tại sao chúng ta cần định nghĩa một
lifetime 'a tường minh trong chữ ký của hàm search và sử dụng lifetime đó
với đối số contents cùng với giá trị trả về. Nhớ lại trong Chương
10 rằng các tham số lifetime chỉ định lifetime của đối số nào
được kết nối với lifetime của giá trị trả về. Trong trường hợp này, chúng ta chỉ
ra rằng vector được trả về phải chứa các string slice tham chiếu đến các slice
của đối số contents (chứ không phải đối số query).
Nói cách khác, chúng ta nói với Rust rằng dữ liệu được trả về bởi hàm search
sẽ tồn tại lâu như dữ liệu được truyền vào hàm search trong đối số contents.
Điều này quan trọng! Dữ liệu được tham chiếu bởi một slice cần phải hợp lệ để
tham chiếu hợp lệ; nếu trình biên dịch giả định chúng ta đang tạo slice chuỗi
của query thay vì contents, nó sẽ thực hiện kiểm tra an toàn của nó không
chính xác.
Nếu chúng ta quên chú thích lifetime và cố gắng biên dịch hàm này, chúng ta sẽ gặp lỗi này:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust không biết được chúng ta cần tham số nào trong hai tham số, vì vậy chúng ta
cần phải cho nó biết rõ ràng. Lưu ý rằng văn bản trợ giúp có thể đề xuất chỉ
định cùng một tham số lifetime cho tất cả các tham số và kiểu dữ liệu trả về,
điều này là không chính xác! Bởi vì contents là tham số chứa toàn bộ văn bản
của chúng ta. và chúng ta muốn trả về các phần của văn bản đó phù hợp, chúng ta
biết contents là tham số duy nhất nên được kết nối với giá trị trả về bằng
cách sử dụng cú pháp lifetime.
Các ngôn ngữ lập trình khác không yêu cầu bạn kết nối các đối số với giá trị trả về trong chữ ký, nhưng thực hành này sẽ trở nên dễ dàng hơn theo thời gian. Bạn có thể muốn so sánh ví dụ này với các ví dụ trong phần "Xác thực tham chiếu với Lifetime" trong Chương 10.
Viết mã để vượt qua bài kiểm thử
Hiện tại, bài kiểm thử của chúng ta đang thất bại vì chúng ta luôn trả về một
vector rỗng. Để sửa điều đó và triển khai search, chương trình của chúng ta
cần tuân theo các bước sau:
- Lặp qua từng dòng của nội dung.
- Kiểm tra xem dòng đó có chứa chuỗi truy vấn của chúng ta hay không.
- Nếu có, thêm nó vào danh sách các giá trị mà chúng ta đang trả về.
- Nếu không, không làm gì cả.
- Trả về danh sách các kết quả phù hợp.
Hãy làm việc qua từng bước, bắt đầu với việc lặp qua các dòng.
Lặp qua các dòng với phương thức lines
Rust có một phương thức hữu ích để xử lý lặp từng dòng của chuỗi, tiện lợi được
đặt tên là lines, hoạt động như được hiển thị trong Listing 12-17. Lưu ý rằng
điều này chưa thể biên dịch được.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Phương thức lines trả về một iterator. Chúng ta sẽ nói về iterator một cách
chi tiết trong Chương 13, nhưng hãy nhớ lại
rằng bạn đã thấy cách sử dụng iterator này trong Listing
3-5, nơi chúng ta đã sử dụng vòng lặp for với một
iterator để chạy một đoạn mã trên mỗi phần tử trong một bộ sưu tập.
Tìm kiếm từng dòng cho truy vấn
Tiếp theo, chúng ta sẽ kiểm tra xem dòng hiện tại có chứa chuỗi truy vấn của
chúng ta hay không. May mắn thay, chuỗi có một phương thức hữu ích có tên là
contains làm điều này cho chúng ta! Thêm một lệnh gọi đến phương thức
contains trong hàm search, như được hiển thị trong Listing 12-18. Lưu ý rằng
điều này vẫn chưa biên dịch được.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Hiện tại, chúng ta đang xây dựng chức năng. Để mã biên dịch, chúng ta cần trả về một giá trị từ thân hàm như chúng ta đã chỉ ra trong chữ ký hàm.
Lưu trữ các dòng phù hợp
Để hoàn thành hàm này, chúng ta cần một cách để lưu trữ các dòng phù hợp mà
chúng ta muốn trả về. Để làm điều đó, chúng ta có thể tạo một vector có thể thay
đổi trước vòng lặp for và gọi phương thức push để lưu trữ một line trong
vector. Sau vòng lặp for, chúng ta trả về vector, như được hiển thị trong
Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Bây giờ hàm search chỉ nên trả về các dòng chứa query, và bài kiểm thử của
chúng ta sẽ vượt qua. Hãy chạy bài kiểm thử:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bài kiểm thử của chúng ta đã vượt qua, vì vậy chúng ta biết nó hoạt động!
Tại thời điểm này, chúng ta có thể xem xét các cơ hội để cải tiến việc triển khai hàm tìm kiếm trong khi giữ cho các bài kiểm thử vượt qua để duy trì chức năng tương tự. Mã trong hàm tìm kiếm không quá tệ, nhưng nó không tận dụng một số tính năng hữu ích của iterator. Chúng ta sẽ quay lại ví dụ này trong Chương 13, nơi chúng ta sẽ khám phá iterator một cách chi tiết và xem xét cách cải thiện nó.
Bây giờ toàn bộ chương trình sẽ hoạt động! Hãy thử nó, đầu tiên với một từ nên trả về chính xác một dòng từ bài thơ của Emily Dickinson: frog.
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Tuyệt! Bây giờ hãy thử một từ sẽ khớp với nhiều dòng, như body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
Và cuối cùng, hãy đảm bảo rằng chúng ta không nhận được bất kỳ dòng nào khi chúng ta tìm kiếm một từ không có ở bất kỳ đâu trong bài thơ, ví dụ như monomorphization:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Xuất sắc! Chúng ta đã xây dựng phiên bản mini của riêng mình cho một công cụ cổ điển và đã học được rất nhiều về cách cấu trúc ứng dụng. Chúng ta cũng đã học được một chút về đầu vào và đầu ra tệp, lifetime, kiểm thử và phân tích dòng lệnh.
Để hoàn thành dự án này, chúng ta sẽ trình bày ngắn gọn cách làm việc với biến môi trường và cách in ra lỗi tiêu chuẩn, cả hai đều hữu ích khi bạn đang viết các chương trình dòng lệnh.
Làm việc với Biến Môi trường
Chúng ta sẽ cải thiện minigrep bằng cách thêm một tính năng bổ sung: một tùy
chọn cho tìm kiếm không phân biệt chữ hoa chữ thường mà người dùng có thể bật
thông qua một biến môi trường. Chúng ta có thể biến tính năng này thành một tùy
chọn dòng lệnh và yêu cầu người dùng nhập nó mỗi khi họ muốn áp dụng, nhưng thay
vào đó, bằng cách sử dụng biến môi trường, chúng ta cho phép người dùng đặt biến
môi trường một lần và thực hiện tất cả các tìm kiếm của họ không phân biệt chữ
hoa chữ thường trong phiên terminal đó.
Viết một Test Thất bại cho Hàm search Không Phân biệt Chữ hoa Chữ thường
Đầu tiên, chúng ta sẽ thêm một hàm mới là search_case_insensitive vào thư viện
minigrep. Hàm này sẽ được gọi khi biến môi trường có giá trị. Chúng ta sẽ tiếp
tục tuân thủ quy trình TDD, vì vậy bước đầu tiên vẫn là viết một bài kiểm thử
thất bại. Chúng ta sẽ thêm một bài kiểm thử mới cho hàm
search_case_insensitive vừa rồi và đổi tên bài kiểm thử cũ từ one_result
thành case_sensitive để làm rõ sự khác biệt giữa hai bài kiểm thử, như thể
hiện trong Listing 12-20.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Lưu ý rằng chúng ta cũng đã chỉnh sửa contents của test cũ. Chúng ta đã thêm
một dòng mới với nội dung "Duct tape." sử dụng chữ D viết hoa, nó không nên
khớp với truy vấn "duct" khi chúng ta tìm kiếm phân biệt chữ hoa chữ thường.
Việc thay đổi test cũ theo cách này giúp đảm bảo chúng ta không vô tình phá vỡ
chức năng tìm kiếm phân biệt chữ hoa chữ thường mà chúng ta đã triển khai. Test
này bây giờ nên pass và nên tiếp tục pass khi chúng ta làm việc trên tìm kiếm
không phân biệt chữ hoa chữ thường.
Test mới cho tìm kiếm không phân biệt chữ hoa chữ thường sử dụng "rUsT" làm
truy vấn. Trong hàm search_case_insensitive mà chúng ta sắp thêm, truy vấn
"rUsT" nên khớp với dòng chứa "Rust:" với chữ R viết hoa và khớp với dòng
"Trust me." mặc dù cả hai đều có cách viết hoa thường khác với truy vấn. Đây
là test thất bại của chúng ta, và nó sẽ không biên dịch được vì chúng ta chưa
định nghĩa hàm search_case_insensitive. Hãy thoải mái thêm một cài đặt khung
luôn trả về một vector rỗng, tương tự như cách chúng ta đã làm cho hàm search
trong Listing 12-16 để thấy test biên dịch và thất bại.
Triển khai Hàm search_case_insensitive
Hàm search_case_insensitive, được hiển thị trong Listing 12-21, sẽ gần giống
với hàm search. Sự khác biệt duy nhất là chúng ta sẽ chuyển đổi query và mỗi
line thành chữ thường để dù đầu vào có chữ hoa hay chữ thường như thế nào,
chúng sẽ giống nhau khi chúng ta kiểm tra xem dòng có chứa truy vấn hay không.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Đầu tiên, chúng ta chuyển đổi chuỗi query thành chữ thường và lưu trữ nó trong
một biến mới có cùng tên, ghi đè biến query gốc. Gọi to_lowercase trên truy
vấn là cần thiết để dù truy vấn của người dùng là "rust", "RUST", "Rust",
hay "``rUsT``", chúng ta sẽ xử lý truy vấn như thể nó là "rust" và không
phân biệt chữ hoa chữ thường. Mặc dù to_lowercase sẽ xử lý Unicode cơ bản, nó
sẽ không chính xác 100%. Nếu chúng ta đang viết một ứng dụng thực, chúng ta sẽ
muốn làm thêm một chút công việc ở đây, nhưng phần này là về biến môi trường,
không phải về Unicode, vì vậy chúng ta sẽ để nó như vậy ở đây.
Lưu ý rằng query bây giờ là một String thay vì một string slice vì gọi
to_lowercase tạo ra dữ liệu mới thay vì tham chiếu đến dữ liệu hiện có. Ví dụ,
nếu truy vấn là "rUsT": string slice đó không chứa chữ u hoặc t viết
thường để chúng ta sử dụng, vì vậy chúng ta phải cấp phát một String mới chứa
"rust". Khi chúng ta truyền query làm đối số cho phương thức contains bây
giờ, chúng ta cần thêm dấu và (ampersand) vì chữ ký của contains được định
nghĩa để nhận một string slice.
Tiếp theo, chúng ta thêm một lệnh gọi to_lowercase cho mỗi line để chuyển
tất cả các ký tự thành chữ thường. Bây giờ sau khi chúng ta đã chuyển đổi line
và query thành chữ thường, chúng ta sẽ tìm thấy các kết quả phù hợp bất kể
truy vấn có chữ hoa hay chữ thường.
Hãy xem liệu cài đặt này có vượt qua các bài kiểm tra không:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Tuyệt vời! Chúng đều đã pass. Bây giờ, chúng ta hãy gọi hàm
search_case_insensitive mới từ hàm run. Đầu tiên, chúng ta sẽ thêm một tùy
chọn cấu hình vào struct Config để chuyển đổi giữa tìm kiếm phân biệt chữ hoa
chữ thường và không phân biệt chữ hoa chữ thường. Việc thêm trường này sẽ gây ra
lỗi biên dịch vì chúng ta chưa khởi tạo trường này ở bất kỳ đâu:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Chúng ta đã thêm trường ignore_case chứa một giá trị Boolean. Tiếp theo, chúng
ta cần hàm run kiểm tra giá trị của trường ignore_case và sử dụng nó để
quyết định gọi hàm search hay hàm search_case_insensitive, như được hiển thị
trong Listing 12-22. Điều này vẫn chưa thể biên dịch.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Cuối cùng, chúng ta cần kiểm tra biến môi trường. Các hàm để làm việc với biến
môi trường nằm trong module env trong thư viện tiêu chuẩn, Điều này đã nằm
trong phạm vi ở đầu file src/main.rs. Chúng ta sẽ sử dụng hàm var từ module
env để kiểm tra xem liệu có bất kỳ giá trị nào đã được đặt cho một biến môi
trường tên là IGNORE_CASE hay không, như được trình bày trong Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Ở đây, chúng ta tạo một biến mới, ignore_case. Để đặt giá trị của nó, chúng ta
gọi hàm env::var và truyền tên của biến môi trường IGNORE_CASE. Hàm
env::var trả về một Result sẽ là biến thể Ok thành công chứa giá trị của
biến môi trường nếu biến môi trường được đặt thành bất kỳ giá trị nào. Nó sẽ trả
về biến thể Err nếu biến môi trường không được đặt.
Chúng ta đang sử dụng phương thức is_ok trên Result để kiểm tra xem biến môi
trường có được đặt hay không, nghĩa là chương trình nên thực hiện tìm kiếm không
phân biệt chữ hoa chữ thường. Nếu biến môi trường IGNORE_CASE không được đặt
thành bất kỳ giá trị nào, is_ok sẽ trả về false và chương trình sẽ thực hiện
tìm kiếm phân biệt chữ hoa chữ thường. Chúng ta không quan tâm đến giá trị của
biến môi trường, chỉ quan tâm xem nó được đặt hay không, vì vậy chúng ta đang
kiểm tra is_ok thay vì sử dụng unwrap, expect, hoặc bất kỳ phương thức nào
khác chúng ta đã thấy trên Result.
Chúng ta truyền giá trị trong biến ignore_case cho đối tượng Config để hàm
run có thể đọc giá trị đó và quyết định gọi search_case_insensitive hay
search, như chúng ta đã triển khai trong Listing 12-22.
Hãy thử nó! Đầu tiên, chúng ta sẽ chạy chương trình mà không đặt biến môi trường
và với truy vấn to, sẽ khớp với bất kỳ dòng nào chứa từ to viết thường:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Có vẻ như điều đó vẫn hoạt động! Bây giờ chúng ta hãy chạy chương trình với
IGNORE_CASE được đặt thành 1 nhưng với cùng truy vấn to:
$ IGNORE_CASE=1 cargo run -- to poem.txt
Nếu bạn đang sử dụng PowerShell, bạn sẽ cần đặt biến môi trường và chạy chương trình như các lệnh riêng biệt:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Điều này sẽ làm cho IGNORE_CASE tồn tại trong phiên shell còn lại của bạn. Có
thể bỏ đặt nó bằng lệnh Remove-Item:
PS> Remove-Item Env:IGNORE_CASE
Chúng ta nên nhận được các dòng chứa to có thể có chữ viết hoa:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Tuyệt vời, chúng ta cũng nhận được các dòng chứa To! Chương trình minigrep
của chúng ta bây giờ có thể thực hiện tìm kiếm không phân biệt chữ hoa chữ
thường được điều khiển bởi một biến môi trường. Bây giờ bạn biết cách quản lý
các tùy chọn được đặt bằng cả đối số dòng lệnh hoặc biến môi trường.
Một số chương trình cho phép đối số và biến môi trường cho cùng một cấu hình. Trong những trường hợp đó, các chương trình quyết định rằng một trong hai có quyền ưu tiên. Đối với một bài tập khác tự thực hiện, hãy thử kiểm soát độ nhạy chữ hoa chữ thường thông qua một đối số dòng lệnh hoặc một biến môi trường. Quyết định xem đối số dòng lệnh hay biến môi trường nên có quyền ưu tiên nếu chương trình được chạy với một cái được đặt thành phân biệt chữ hoa chữ thường và một cái được đặt để bỏ qua chữ hoa chữ thường.
Module std::env chứa nhiều tính năng hữu ích hơn để xử lý biến môi trường: hãy
xem tài liệu của nó để biết những gì có sẵn.
Viết Thông Báo Lỗi vào Standard Error Thay vì Standard Output
Hiện tại, chúng ta đang viết tất cả đầu ra của mình vào terminal bằng cách sử
dụng macro println!. Trong hầu hết các terminal, có hai loại đầu ra: standard
output (stdout) cho thông tin chung và standard error (stderr) cho thông
báo lỗi. Sự phân biệt này cho phép người dùng lựa chọn chuyển hướng đầu ra thành
công của chương trình vào một file nhưng vẫn in thông báo lỗi ra màn hình.
Macro println! chỉ có khả năng in vào standard output, vì vậy chúng ta phải sử
dụng một cách khác để in vào standard error.
Kiểm tra Nơi Lỗi Được Ghi
Đầu tiên, hãy quan sát cách nội dung được in bởi minigrep hiện đang được ghi
vào standard output, bao gồm cả các thông báo lỗi mà chúng ta muốn viết vào
standard error thay thế. Chúng ta sẽ làm điều đó bằng cách chuyển hướng luồng
standard output vào một file trong khi chủ ý gây ra lỗi. Chúng ta sẽ không
chuyển hướng luồng standard error, vì vậy bất kỳ nội dung nào được gửi đến
standard error sẽ tiếp tục hiển thị trên màn hình.
Các chương trình dòng lệnh được mong đợi sẽ gửi thông báo lỗi đến standard error stream để chúng ta vẫn có thể thấy thông báo lỗi trên màn hình ngay cả khi chúng ta chuyển hướng standard output stream vào một tệp. Chương trình của chúng ta hiện không hoạt động tốt: chúng ta sắp thấy rằng nó lưu đầu ra thông báo lỗi vào một file thay vì màn hình!
Để chứng minh hành vi này, chúng ta sẽ chạy chương trình với > và đường dẫn
file, output.txt, nơi chúng ta muốn chuyển hướng luồng standard output đến.
Chúng ta sẽ không truyền bất kỳ đối số nào, điều đó sẽ gây ra lỗi:
$ cargo run > output.txt
Cú pháp > nói với shell rằng hãy ghi nội dung của standard output vào
output.txt thay vì màn hình. Chúng ta không thấy thông báo lỗi mà chúng ta đã
mong đợi in trên màn hình, vì vậy điều đó có nghĩa là nó hẳn đã xuất hiện trong
file. Đây là nội dung của output.txt:
Problem parsing arguments: not enough arguments
Đúng vậy, thông báo lỗi của chúng ta đang được in vào standard output. Sẽ hữu ích hơn nhiều nếu các thông báo lỗi như thế này được in ra standard error để chỉ dữ liệu từ một lần chạy thành công mới xuất hiện trong file. Chúng ta sẽ thay đổi điều đó.
In Lỗi vào Standard Error
Chúng ta sẽ sử dụng mã trong Listing 12-24 để thay đổi cách thông báo lỗi được
in. Vì việc cấu trúc lại mã mà chúng ta đã làm trước đó trong chương này, tất cả
mã in thông báo lỗi nằm trong một hàm, main. Thư viện chuẩn cung cấp macro
eprintln! để in vào standard error stream, vì vậy hãy thay đổi hai nơi chúng
ta đã gọi println! để in lỗi bằng cách sử dụng eprintln! thay thế.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Bây giờ hãy chạy chương trình một lần nữa theo cùng một cách, không có đối số
nào và chuyển hướng standard output với >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Bây giờ chúng ta thấy lỗi trên màn hình và output.txt không chứa gì cả, đó là hành vi mà chúng ta mong đợi từ các chương trình dòng lệnh.
Hãy chạy chương trình một lần nữa với các đối số không gây ra lỗi nhưng vẫn chuyển hướng standard output vào một file, như sau:
$ cargo run -- to poem.txt > output.txt
Chúng ta sẽ không thấy bất kỳ đầu ra nào trên terminal, và output.txt sẽ chứa các kết quả của chúng ta:
Filename: output.txt
Are you nobody, too?
How dreary to be somebody!
Điều này chứng minh rằng chúng ta hiện đang sử dụng standard output cho đầu ra thành công và standard error cho đầu ra lỗi một cách thích hợp.
Tóm tắt
Chương này đã nhắc lại một số khái niệm chính mà bạn đã học cho đến nay và đã đề
cập đến cách thực hiện các hoạt động I/O thông thường trong Rust. Bằng cách sử
dụng đối số dòng lệnh, files, biến môi trường, và macro eprintln! để in lỗi,
bạn đã sẵn sàng để viết các ứng dụng dòng lệnh. Kết hợp với các khái niệm trong
các chương trước, mã của bạn sẽ được tổ chức tốt, lưu trữ dữ liệu hiệu quả trong
các cấu trúc dữ liệu phù hợp, xử lý lỗi một cách tốt và được kiểm tra kỹ lưỡng.
Tiếp theo, chúng ta sẽ khám phá một số tính năng của Rust bị ảnh hưởng bởi các ngôn ngữ lập trình hàm: closures và iterators.
Tính năng Ngôn ngữ Hàm: Iterators và Closures
Thiết kế của Rust đã lấy cảm hứng từ nhiều ngôn ngữ và kỹ thuật hiện có, và một ảnh hưởng đáng kể là lập trình hàm. Lập trình theo phong cách hàm thường bao gồm việc sử dụng hàm như là giá trị bằng cách truyền chúng vào đối số, trả về chúng từ các hàm khác, gán chúng cho biến để thực thi sau này, và nhiều điều tương tự.
Trong chương này, chúng ta sẽ không tranh luận về vấn đề lập trình hàm là gì hoặc không phải là gì, mà thay vào đó sẽ thảo luận về một số tính năng của Rust tương tự với các tính năng trong nhiều ngôn ngữ thường được gọi là hàm.
Cụ thể hơn, chúng ta sẽ đề cập đến:
- Closures, một cấu trúc giống hàm mà bạn có thể lưu trữ trong một biến
- Iterators, một cách để xử lý một chuỗi các phần tử
- Cách sử dụng closures và iterators để cải thiện dự án I/O trong Chương 12
- Hiệu suất của closures và iterators (tiết lộ: chúng nhanh hơn bạn nghĩ!)
Chúng ta đã đề cập đến một số tính năng Rust khác, như pattern matching và enums, cũng bị ảnh hưởng bởi phong cách lập trình hàm. Vì việc thành thạo closures và iterators là một phần quan trọng của việc viết mã Rust thông thường, nhanh chóng, chúng ta sẽ dành toàn bộ chương này cho chúng.
Closures: Các Hàm Ẩn Danh Có Thể Capture Môi Trường Của Chúng
Closures trong Rust là các hàm ẩn danh mà bạn có thể lưu trong một biến hoặc truyền như đối số cho các hàm khác. Bạn có thể tạo closure tại một nơi và sau đó gọi closure ở nơi khác để đánh giá nó trong một ngữ cảnh khác. Không giống như các hàm thông thường, closures có thể capture (nắm bắt) các giá trị từ phạm vi mà chúng được định nghĩa. Chúng ta sẽ chứng minh cách các tính năng của closure cho phép tái sử dụng mã và tùy chỉnh hành vi.
Capture Môi Trường với Closures
Đầu tiên, chúng ta sẽ xem xét cách chúng ta có thể sử dụng closures để capture các giá trị từ môi trường mà chúng được định nghĩa để sử dụng sau này. Đây là kịch bản: thỉnh thoảng, công ty áo thun của chúng ta tặng một chiếc áo độc quyền, phiên bản giới hạn cho ai đó trong danh sách gửi thư của chúng ta như một khuyến mãi. Những người trong danh sách gửi thư có thể tùy chọn thêm màu yêu thích của họ vào hồ sơ của họ. Nếu người được chọn để nhận áo miễn phí đã đặt màu yêu thích của họ, họ sẽ nhận được áo có màu đó. Nếu người đó chưa chỉ định màu yêu thích, họ sẽ nhận được bất kỳ màu nào mà công ty hiện có nhiều nhất.
Có nhiều cách để thực hiện điều này. Đối với ví dụ này, chúng ta sẽ sử dụng một
enum gọi là ShirtColor có các biến thể Red và Blue (giới hạn số lượng màu
có sẵn để đơn giản hóa). Chúng ta biểu diễn kho hàng của công ty bằng một struct
Inventory có một trường tên là shirts chứa một Vec<ShirtColor> đại diện
cho các màu áo hiện có trong kho. Phương thức giveaway được định nghĩa trên
Inventory lấy tùy chọn màu áo ưa thích của người thắng áo miễn phí và trả về
màu áo mà người đó sẽ nhận được. Thiết lập này được hiển thị trong Listing 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}store được định nghĩa trong main có hai áo màu xanh và một áo màu đỏ còn lại
để phân phối cho khuyến mãi phiên bản giới hạn này. Chúng ta gọi phương thức
giveaway cho một người dùng có sở thích cho áo màu đỏ và một người dùng không
có bất kỳ sở thích nào.
Một lần nữa, mã này có thể được triển khai theo nhiều cách, và ở đây, để tập
trung vào closures, chúng ta đã gắn bó với các khái niệm bạn đã học, ngoại trừ
phần thân của phương thức giveaway sử dụng một closure. Trong phương thức
giveaway, chúng ta nhận sở thích của người dùng như một tham số kiểu
Option<ShirtColor> và gọi phương thức unwrap_or_else trên user_preference.
Phương thức unwrap_or_else trên Option<T>
được định nghĩa bởi thư viện tiêu chuẩn. Nó lấy một đối số: một closure không có
đối số nào trả về một giá trị T (cùng kiểu được lưu trữ trong biến thể Some
của Option<T>, trong trường hợp này là ShirtColor). Nếu Option<T> là biến
thể Some, unwrap_or_else trả về giá trị từ bên trong Some. Nếu Option<T>
là biến thể None, unwrap_or_else gọi closure và trả về giá trị được trả về
bởi closure.
Chúng ta chỉ định biểu thức closure || self.most_stocked() làm đối số cho
unwrap_or_else. Đây là một closure không có tham số (nếu closure có tham số,
chúng sẽ xuất hiện giữa hai dấu gạch đứng). Phần thân của closure gọi
self.most_stocked(). Chúng ta đang định nghĩa closure ở đây, và việc triển
khai của unwrap_or_else sẽ đánh giá closure sau này nếu kết quả là cần thiết.
Chạy mã này in ra:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Một khía cạnh thú vị ở đây là chúng ta đã truyền một closure gọi
self.most_stocked() trên phiên bản Inventory hiện tại. Thư viện tiêu chuẩn
không cần biết bất cứ điều gì về các kiểu Inventory hoặc ShirtColor mà chúng
ta đã định nghĩa, hoặc logic mà chúng ta muốn sử dụng trong kịch bản này.
Closure capture một tham chiếu bất biến đến phiên bản self Inventory và
truyền nó cùng với mã mà chúng ta chỉ định cho phương thức unwrap_or_else.
Ngược lại, các hàm không thể capture môi trường của chúng theo cách này.
Suy Luận Kiểu và Chú Thích Closure
Có nhiều sự khác biệt giữa các hàm và closures. Closures thường không yêu cầu
bạn phải chú thích kiểu của các tham số hoặc giá trị trả về như các hàm fn
làm. Chú thích kiểu được yêu cầu trên các hàm vì các kiểu là một phần của giao
diện rõ ràng được hiển thị cho người dùng của bạn. Định nghĩa giao diện này một
cách nghiêm ngặt là quan trọng để đảm bảo rằng mọi người đồng ý về các kiểu giá
trị mà một hàm sử dụng và trả về. Ngược lại, closures không được sử dụng trong
một giao diện hiển thị như thế này: chúng được lưu trữ trong các biến và được sử
dụng mà không cần đặt tên chúng và hiển thị chúng cho người dùng của thư viện
chúng ta.
Closures thường ngắn gọn và chỉ liên quan trong một ngữ cảnh hẹp thay vì trong bất kỳ tình huống tùy ý nào. Trong các ngữ cảnh hạn chế này, trình biên dịch có thể suy ra các kiểu của tham số và kiểu trả về, tương tự như cách nó có thể suy ra kiểu của hầu hết các biến (có những trường hợp hiếm khi trình biên dịch cần chú thích kiểu closure).
Giống như với các biến, chúng ta có thể thêm chú thích kiểu nếu chúng ta muốn tăng sự rõ ràng và rõ ràng với chi phí là dài dòng hơn mức cần thiết. Chú thích các kiểu cho một closure sẽ trông giống như định nghĩa được hiển thị trong Listing 13-2. Trong ví dụ này, chúng ta đang định nghĩa một closure và lưu trữ nó trong một biến thay vì định nghĩa closure ở vị trí chúng ta truyền nó làm một đối số, như chúng ta đã làm trong Listing 13-1.
use std::thread; use std::time::Duration; fn generate_workout(intensity: u32, random_number: u32) { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; if intensity < 25 { println!("Today, do {} pushups!", expensive_closure(intensity)); println!("Next, do {} situps!", expensive_closure(intensity)); } else { if random_number == 3 { println!("Take a break today! Remember to stay hydrated!"); } else { println!( "Today, run for {} minutes!", expensive_closure(intensity) ); } } } fn main() { let simulated_user_specified_value = 10; let simulated_random_number = 7; generate_workout(simulated_user_specified_value, simulated_random_number); }
Với chú thích kiểu được thêm vào, cú pháp của closures trông giống hơn với cú pháp của các hàm. Ở đây, chúng ta định nghĩa một hàm thêm 1 vào tham số của nó và một closure có cùng hành vi, để so sánh. Chúng ta đã thêm một số khoảng trắng để căn chỉnh các phần liên quan. Điều này minh họa cách cú pháp closure tương tự với cú pháp hàm ngoại trừ việc sử dụng dấu gạch đứng và lượng cú pháp là tùy chọn:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;Dòng đầu tiên hiển thị định nghĩa hàm và dòng thứ hai hiển thị một định nghĩa
closure được chú thích đầy đủ. Trong dòng thứ ba, chúng ta loại bỏ các chú thích
kiểu từ định nghĩa closure. Trong dòng thứ tư, chúng ta loại bỏ các dấu ngoặc
nhọn, là tùy chọn vì thân closure chỉ có một biểu thức. Tất cả đều là các định
nghĩa hợp lệ sẽ tạo ra cùng một hành vi khi chúng được gọi. Các dòng
add_one_v3 và add_one_v4 yêu cầu các closure phải được đánh giá để có thể
biên dịch vì các kiểu sẽ được suy ra từ việc sử dụng chúng. Điều này tương tự
như let v = Vec::new(); cần chú thích kiểu hoặc giá trị của một số kiểu được
chèn vào Vec để Rust có thể suy ra kiểu.
Đối với các định nghĩa closure, trình biên dịch sẽ suy ra một kiểu cụ thể cho
mỗi tham số và cho giá trị trả về của chúng. Ví dụ, Listing 13-3 hiển thị định
nghĩa của một closure ngắn chỉ trả về giá trị mà nó nhận được như một tham số.
Closure này không hữu ích lắm ngoại trừ mục đích của ví dụ này. Lưu ý rằng chúng
ta chưa thêm bất kỳ chú thích kiểu nào cho định nghĩa. Vì không có chú thích
kiểu, chúng ta có thể gọi closure với bất kỳ kiểu nào, điều mà chúng ta đã làm ở
đây với String lần đầu tiên. Nếu sau đó chúng ta thử gọi example_closure với
một số nguyên, chúng ta sẽ gặp lỗi.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Trình biên dịch đưa ra lỗi này:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
Lần đầu tiên chúng ta gọi example_closure với giá trị String, trình biên
dịch suy ra kiểu của x và kiểu trả về của closure là String. Những kiểu đó
sau đó được khóa vào closure trong example_closure, và chúng ta nhận được một
lỗi kiểu khi chúng ta tiếp theo cố gắng sử dụng một kiểu khác với cùng một
closure.
Capture Tham Chiếu hoặc Di Chuyển Quyền Sở Hữu
Closures có thể capture các giá trị từ môi trường của chúng theo ba cách, điều này trực tiếp ánh xạ đến ba cách mà một hàm có thể lấy một tham số: mượn bất biến, mượn khả biến và lấy quyền sở hữu. Closure sẽ quyết định cái nào trong số này để sử dụng dựa trên những gì phần thân của hàm làm với các giá trị được capture.
Trong Listing 13-4, chúng ta định nghĩa một closure capture một tham chiếu bất
biến đến vector có tên list vì nó chỉ cần một tham chiếu bất biến để in giá
trị.
fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let only_borrows = || println!("From closure: {list:?}"); println!("Before calling closure: {list:?}"); only_borrows(); println!("After calling closure: {list:?}"); }
Ví dụ này cũng minh họa rằng một biến có thể liên kết với một định nghĩa closure, và sau đó chúng ta có thể gọi closure bằng cách sử dụng tên biến và dấu ngoặc đơn như thể tên biến là tên hàm.
Bởi vì chúng ta có thể có nhiều tham chiếu bất biến đến list cùng một lúc,
list vẫn có thể truy cập được từ mã trước khi định nghĩa closure, sau khi định
nghĩa closure nhưng trước khi closure được gọi, và sau khi closure được gọi. Mã
này biên dịch, chạy và in:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
Tiếp theo, trong Listing 13-5, chúng ta thay đổi phần thân closure để nó thêm
một phần tử vào vector list. Closure bây giờ capture một tham chiếu khả biến.
fn main() { let mut list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let mut borrows_mutably = || list.push(7); borrows_mutably(); println!("After calling closure: {list:?}"); }
Mã này biên dịch, chạy và in:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Lưu ý rằng không còn println! giữa định nghĩa và lệnh gọi của closure
borrows_mutably: khi borrows_mutably được định nghĩa, nó capture một tham
chiếu khả biến đến list. Chúng ta không sử dụng closure nữa sau khi closure
được gọi, vì vậy việc mượn khả biến kết thúc. Giữa định nghĩa closure và lệnh
gọi closure, một tham chiếu bất biến để in không được phép vì không có tham
chiếu khác nào được phép khi có một tham chiếu khả biến. Thử thêm một println!
ở đó để xem bạn nhận được thông báo lỗi gì!
Nếu bạn muốn buộc closure lấy quyền sở hữu của các giá trị mà nó sử dụng trong
môi trường mặc dù phần thân của closure không cần thiết phải có quyền sở hữu,
bạn có thể sử dụng từ khóa move trước danh sách tham số.
Kỹ thuật này chủ yếu hữu ích khi truyền một closure cho một luồng mới để di
chuyển dữ liệu để nó được sở hữu bởi luồng mới. Chúng ta sẽ thảo luận về luồng
và tại sao bạn muốn sử dụng chúng chi tiết trong Chương 16 khi chúng ta nói về
đồng thời, nhưng bây giờ, hãy khám phá nhanh việc tạo một luồng mới bằng cách sử
dụng một closure cần từ khóa move. Listing 13-6 hiển thị Listing 13-4 đã được
sửa đổi để in vector trong một luồng mới thay vì trong luồng chính.
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); thread::spawn(move || println!("From thread: {list:?}")) .join() .unwrap(); }
Chúng ta tạo ra một luồng mới, cung cấp cho luồng một closure để chạy như một
đối số. Phần thân closure in ra danh sách. Trong Listing 13-4, closure chỉ
capture list bằng cách sử dụng một tham chiếu bất biến vì đó là lượng truy cập
tối thiểu vào list cần thiết để in nó. Trong ví dụ này, mặc dù phần thân
closure vẫn chỉ cần một tham chiếu bất biến, chúng ta cần chỉ định rằng list
nên được di chuyển vào closure bằng cách đặt từ khóa move ở đầu định nghĩa
closure. Nếu luồng chính thực hiện nhiều hoạt động khác trước khi gọi join
trên luồng mới, luồng mới có thể kết thúc trước phần còn lại của luồng chính kết
thúc, hoặc luồng chính có thể kết thúc trước. Nếu luồng chính duy trì quyền sở
hữu của list nhưng kết thúc trước khi luồng mới và loại bỏ list, tham chiếu
bất biến trong luồng sẽ không hợp lệ. Do đó, trình biên dịch yêu cầu rằng list
phải được di chuyển vào closure được cung cấp cho luồng mới để tham chiếu sẽ hợp
lệ. Hãy thử loại bỏ từ khóa move hoặc sử dụng list trong luồng chính sau khi
closure được định nghĩa để xem bạn nhận được lỗi biên dịch gì!
Di Chuyển Các Giá Trị Đã Capture Ra Khỏi Closures và Các Trait Fn
Một khi closure đã capture một tham chiếu hoặc capture quyền sở hữu của một giá trị từ môi trường nơi closure được định nghĩa (do đó ảnh hưởng đến việc gì, nếu có, được di chuyển vào closure), mã trong phần thân của closure định nghĩa những gì xảy ra với các tham chiếu hoặc giá trị khi closure được đánh giá sau đó (do đó ảnh hưởng đến việc gì, nếu có, được di chuyển ra khỏi closure).
Phần thân closure có thể thực hiện bất kỳ điều nào sau đây: di chuyển một giá trị đã capture ra khỏi closure, thay đổi giá trị đã capture, không di chuyển cũng không thay đổi giá trị, hoặc không capture gì từ môi trường từ ban đầu.
Cách mà một closure capture và xử lý các giá trị từ môi trường ảnh hưởng đến các
trait mà closure thực hiện, và trait là cách mà các hàm và struct có thể chỉ
định loại closures nào chúng có thể sử dụng. Closures sẽ tự động thực hiện một,
hai hoặc cả ba trait Fn này, theo cách cộng dồn, tùy thuộc vào cách mà phần
thân closure xử lý các giá trị:
FnOnceáp dụng cho các closure có thể được gọi một lần. Tất cả các closure thực hiện ít nhất trait này vì tất cả các closure có thể được gọi. Một closure di chuyển các giá trị đã capture ra khỏi phần thân của nó sẽ chỉ thực hiệnFnOncevà không phải các traitFnkhác, vì nó chỉ có thể được gọi một lần.FnMutáp dụng cho các closure không di chuyển các giá trị đã capture ra khỏi phần thân của chúng, nhưng có thể thay đổi các giá trị đã capture. Các closure này có thể được gọi nhiều lần.Fnáp dụng cho các closure không di chuyển các giá trị đã capture ra khỏi phần thân của chúng và không thay đổi các giá trị đã capture, cũng như các closure không capture gì từ môi trường của chúng. Các closure này có thể được gọi nhiều lần mà không thay đổi môi trường của chúng, điều này quan trọng trong các trường hợp như gọi một closure nhiều lần đồng thời.
Hãy xem xét định nghĩa của phương thức unwrap_or_else trên Option<T> mà
chúng ta đã sử dụng trong Listing 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Nhớ lại rằng T là kiểu generic đại diện cho kiểu của giá trị trong biến thể
Some của một Option. Kiểu T đó cũng là kiểu trả về của hàm
unwrap_or_else: mã gọi unwrap_or_else trên một Option<String>, ví dụ, sẽ
nhận được một String.
Tiếp theo, hãy lưu ý rằng hàm unwrap_or_else có tham số kiểu generic bổ sung
F. Kiểu F là kiểu của tham số có tên f, đó là closure mà chúng ta cung cấp
khi gọi unwrap_or_else.
Ràng buộc trait được chỉ định trên kiểu generic F là FnOnce() -> T, có nghĩa
là F phải có khả năng được gọi một lần, không nhận tham số, và trả về một T.
Sử dụng FnOnce trong ràng buộc trait thể hiện ràng buộc rằng unwrap_or_else
chỉ sẽ gọi f nhiều nhất một lần. Trong phần thân unwrap_or_else, chúng ta có
thể thấy rằng nếu Option là Some, f sẽ không được gọi. Nếu Option là
None, f sẽ được gọi một lần. Bởi vì tất cả các closure đều thực hiện
FnOnce, unwrap_or_else chấp nhận cả ba loại closure và linh hoạt nhất có
thể.
Lưu ý: Nếu những gì chúng ta muốn làm không yêu cầu capture một giá trị từ môi trường, chúng ta có thể sử dụng tên của một hàm thay vì một closure ở nơi chúng ta cần thứ gì đó thực hiện một trong các trait
Fn. Ví dụ, trên một giá trịOption<Vec<T>>, chúng ta có thể gọiunwrap_or_else(Vec::new)để nhận một vector mới, trống nếu giá trị làNone. Trình biên dịch tự động thực hiện bất cứ traitFnnào áp dụng được cho một định nghĩa hàm.
Bây giờ hãy xem xét phương thức thư viện tiêu chuẩn sort_by_key, được định
nghĩa trên slices, để xem nó khác với unwrap_or_else như thế nào và tại sao
sort_by_key sử dụng FnMut thay vì FnOnce cho ràng buộc trait. Closure nhận
một đối số dưới dạng một tham chiếu đến mục hiện tại trong slice đang được xem
xét, và trả về một giá trị kiểu K có thể được sắp xếp. Hàm này hữu ích khi bạn
muốn sắp xếp một slice theo một thuộc tính cụ thể của mỗi mục. Trong Listing
13-7, chúng ta có một danh sách các phiên bản Rectangle và chúng ta sử dụng
sort_by_key để sắp xếp chúng theo thuộc tính width của chúng từ thấp đến
cao.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; list.sort_by_key(|r| r.width); println!("{list:#?}"); }
Mã này in:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
Lý do sort_by_key được định nghĩa để lấy một closure FnMut là vì nó gọi
closure nhiều lần: một lần cho mỗi mục trong slice. Closure |r| r.width không
capture, thay đổi, hoặc di chuyển bất cứ thứ gì ra từ môi trường của nó, vì vậy
nó đáp ứng các yêu cầu ràng buộc trait.
Ngược lại, Listing 13-8 hiển thị một ví dụ về một closure chỉ thực hiện trait
FnOnce, vì nó di chuyển một giá trị ra khỏi môi trường. Trình biên dịch sẽ
không cho phép chúng ta sử dụng closure này với sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}Đây là một cách phức tạp và rắc rối (không hoạt động) để cố gắng đếm số lần
sort_by_key gọi closure khi sắp xếp list. Mã này cố gắng làm điều này bằng
cách đẩy value—một String từ môi trường của closure—vào vector
sort_operations. Closure capture value và sau đó di chuyển value ra khỏi
closure bằng cách chuyển quyền sở hữu của value cho vector sort_operations.
Closure này có thể được gọi một lần; cố gắng gọi nó lần thứ hai sẽ không hoạt
động vì value sẽ không còn trong môi trường để được đẩy vào sort_operations
nữa! Do đó, closure này chỉ thực hiện FnOnce. Khi chúng ta cố gắng biên dịch
mã này, chúng ta nhận được lỗi này rằng value không thể được di chuyển ra khỏi
closure vì closure phải thực hiện FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
Lỗi chỉ ra dòng trong phần thân closure di chuyển value ra khỏi môi trường. Để
sửa lỗi này, chúng ta cần thay đổi phần thân closure để nó không di chuyển các
giá trị ra khỏi môi trường. Giữ một bộ đếm trong môi trường và tăng giá trị của
nó trong phần thân closure là một cách trực tiếp hơn để đếm số lần closure được
gọi. Closure trong Listing 13-9 làm việc với sort_by_key vì nó chỉ capture một
tham chiếu khả biến đến bộ đếm num_sort_operations và do đó có thể được gọi
nhiều hơn một lần:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; let mut num_sort_operations = 0; list.sort_by_key(|r| { num_sort_operations += 1; r.width }); println!("{list:#?}, sorted in {num_sort_operations} operations"); }
Các trait Fn là quan trọng khi định nghĩa hoặc sử dụng các hàm hoặc kiểu mà sử
dụng closures. Trong phần tiếp theo, chúng ta sẽ thảo luận về iterators. Nhiều
phương thức iterator lấy các đối số closure, vì vậy hãy ghi nhớ các chi tiết về
closure này khi chúng ta tiếp tục!
Xử lý Một Chuỗi Các Item với Iterators
Mẫu iterator cho phép bạn thực hiện một nhiệm vụ nào đó trên một chuỗi các phần tử lần lượt. Một iterator chịu trách nhiệm cho logic lặp qua từng phần tử và xác định khi nào chuỗi đã kết thúc. Khi bạn sử dụng iterators, bạn không phải tái thực hiện logic đó cho chính mình.
Trong Rust, iterators là lười biếng, nghĩa là chúng không có tác dụng gì cho
đến khi bạn gọi các phương thức tiêu thụ iterator để sử dụng nó. Ví dụ, mã trong
Listing 13-10 tạo một iterator trên các phần tử trong vector v1 bằng cách gọi
phương thức iter được định nghĩa trên Vec<T>. Mã này tự nó không làm gì có
ích.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
Iterator được lưu trữ trong biến v1_iter. Một khi chúng ta đã tạo một
iterator, chúng ta có thể sử dụng nó theo nhiều cách khác nhau. Trong Listing
3-5, chúng ta đã lặp qua một mảng bằng vòng lặp for để thực thi một số mã trên
mỗi phần tử của nó. Bên dưới, điều này ngầm tạo ra và sau đó tiêu thụ một
iterator, nhưng chúng ta đã bỏ qua cách nó hoạt động chính xác cho đến bây giờ.
Trong ví dụ ở Listing 13-11, chúng ta tách việc tạo iterator khỏi việc sử dụng
iterator trong vòng lặp for. Khi vòng lặp for được gọi sử dụng iterator
trong v1_iter, mỗi phần tử trong iterator được sử dụng trong một lần lặp của
vòng lặp, điều này in ra mỗi giá trị.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Got: {val}"); } }
Trong các ngôn ngữ không có iterators được cung cấp bởi thư viện chuẩn của chúng, bạn có thể sẽ viết cùng một chức năng này bằng cách bắt đầu với một biến ở chỉ số 0, sử dụng biến đó để truy cập vào vector để lấy một giá trị, và tăng giá trị biến trong một vòng lặp cho đến khi nó đạt đến tổng số phần tử trong vector.
Iterators xử lý tất cả logic đó cho bạn, cắt giảm mã lặp lại mà bạn có thể làm rối. Iterators cho bạn thêm sự linh hoạt để sử dụng cùng một logic với nhiều loại chuỗi khác nhau, không chỉ các cấu trúc dữ liệu mà bạn có thể truy cập theo chỉ mục, như vectors. Hãy xem cách iterators làm điều đó.
Trait Iterator và Phương thức next
Tất cả iterators đều thực hiện một trait có tên Iterator được định nghĩa trong
thư viện chuẩn. Định nghĩa của trait trông như thế này:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // phương thức với các triển khai mặc định được lược bỏ } }
Lưu ý rằng định nghĩa này sử dụng một số cú pháp mới: type Item và
Self::Item, đang định nghĩa một kiểu liên kết với trait này. Chúng ta sẽ nói
về các kiểu liên kết một cách sâu sắc trong Chương 20. Hiện tại, tất cả những gì
bạn cần biết là mã này nói rằng việc thực hiện trait Iterator yêu cầu bạn cũng
phải định nghĩa một kiểu Item, và kiểu Item này được sử dụng trong kiểu trả
về của phương thức next. Nói cách khác, kiểu Item sẽ là kiểu được trả về từ
iterator.
Trait Iterator chỉ yêu cầu những người thực hiện định nghĩa một phương thức:
phương thức next, trả về một phần tử của iterator mỗi lần, được bọc trong
Some, và, khi lặp kết thúc, trả về None.
Chúng ta có thể gọi phương thức next trực tiếp trên iterators; Listing 13-12
minh họa các giá trị nào được trả về từ các lệnh gọi lặp lại đến next trên
iterator được tạo từ vector.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}Lưu ý rằng chúng ta cần làm cho v1_iter có thể thay đổi: gọi phương thức
next trên một iterator thay đổi trạng thái nội bộ mà iterator sử dụng để theo
dõi vị trí của nó trong chuỗi. Nói cách khác, mã này tiêu thụ, hoặc sử dụng
hết, iterator. Mỗi lệnh gọi đến next tiêu thụ một phần tử từ iterator. Chúng
ta không cần làm cho v1_iter có thể thay đổi khi chúng ta sử dụng vòng lặp
for vì vòng lặp đã lấy quyền sở hữu của v1_iter và làm cho nó có thể thay
đổi đằng sau hậu trường.
Cũng lưu ý rằng các giá trị chúng ta nhận được từ các lệnh gọi đến next là các
tham chiếu bất biến đến các giá trị trong vector. Phương thức iter tạo ra một
iterator trên các tham chiếu bất biến. Nếu chúng ta muốn tạo một iterator lấy
quyền sở hữu của v1 và trả về các giá trị thuộc sở hữu, chúng ta có thể gọi
into_iter thay vì iter. Tương tự, nếu chúng ta muốn lặp qua các tham chiếu
có thể thay đổi, chúng ta có thể gọi iter_mut thay vì iter.
Các Phương thức Tiêu thụ Iterator
Trait Iterator có một số phương thức khác nhau với các triển khai mặc định
được cung cấp bởi thư viện chuẩn; bạn có thể tìm hiểu về các phương thức này
bằng cách xem tài liệu API thư viện chuẩn cho trait Iterator. Một số phương
thức này gọi phương thức next trong định nghĩa của chúng, đó là lý do tại sao
bạn được yêu cầu thực hiện phương thức next khi thực hiện trait Iterator.
Các phương thức gọi next được gọi là bộ điều hợp tiêu thụ, vì gọi chúng sử
dụng hết iterator. Một ví dụ là phương thức sum, lấy quyền sở hữu của iterator
và lặp qua các phần tử bằng cách liên tục gọi next, do đó tiêu thụ iterator.
Khi nó lặp qua, nó thêm mỗi phần tử vào một tổng đang chạy và trả về tổng khi
lặp hoàn thành. Listing 13-13 có một test minh họa việc sử dụng phương thức
sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Chúng ta không được phép sử dụng v1_iter sau lệnh gọi đến sum vì sum lấy
quyền sở hữu của iterator mà chúng ta gọi nó trên.
Các Phương thức tạo ra Iterator Khác
Bộ điều hợp iterator là các phương thức được định nghĩa trên trait Iterator
không tiêu thụ iterator. Thay vào đó, chúng tạo ra các iterator khác nhau bằng
cách thay đổi một số khía cạnh của iterator gốc.
Listing 13-14 hiển thị một ví dụ về việc gọi phương thức điều hợp iterator
map, lấy một closure để gọi trên mỗi phần tử khi các phần tử được lặp qua.
Phương thức map trả về một iterator mới tạo ra các phần tử đã được sửa đổi.
Closure ở đây tạo ra một iterator mới trong đó mỗi phần tử từ vector sẽ được
tăng lên 1.
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
Tuy nhiên, mã này tạo ra một cảnh báo:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Mã trong Listing 13-14 không làm gì cả; closure mà chúng ta đã chỉ định không bao giờ được gọi. Cảnh báo nhắc nhở chúng ta lý do tại sao: bộ điều hợp iterator là lười biếng, và chúng ta cần tiêu thụ iterator ở đây.
Để sửa cảnh báo này và tiêu thụ iterator, chúng ta sẽ sử dụng phương thức
collect, mà chúng ta đã sử dụng với env::args trong Listing 12-1. Phương
thức này tiêu thụ iterator và thu thập các giá trị kết quả vào một kiểu dữ liệu
tập hợp.
Trong Listing 13-15, chúng ta thu thập các kết quả của việc lặp qua iterator
được trả về từ lệnh gọi đến map vào một vector. Vector này sẽ kết thúc chứa
mỗi phần tử từ vector gốc, tăng lên 1.
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
Bởi vì map lấy một closure, chúng ta có thể chỉ định bất kỳ hoạt động nào mà
chúng ta muốn thực hiện trên mỗi phần tử. Đây là một ví dụ tuyệt vời về cách
closures cho phép bạn tùy chỉnh một số hành vi trong khi tái sử dụng hành vi lặp
lại mà trait Iterator cung cấp.
Bạn có thể nối nhiều lệnh gọi đến bộ điều hợp iterator để thực hiện các hoạt động phức tạp theo cách dễ đọc. Nhưng bởi vì tất cả iterators đều lười biếng, bạn phải gọi một trong các phương thức bộ điều hợp tiêu thụ để có được kết quả từ các lệnh gọi đến bộ điều hợp iterator.
Sử dụng Closures Capture Môi trường của Chúng
Nhiều bộ điều hợp iterator lấy closure làm đối số, và thường các closure mà chúng ta sẽ chỉ định làm đối số cho bộ điều hợp iterator sẽ là closure capture môi trường của chúng.
Cho ví dụ này, chúng ta sẽ sử dụng phương thức filter nhận một closure.
Closure lấy một phần tử từ iterator và trả về một bool. Nếu closure trả về
true, giá trị sẽ được bao gồm trong lần lặp được tạo ra bởi filter. Nếu
closure trả về false, giá trị sẽ không được bao gồm.
Trong Listing 13-16, chúng ta sử dụng filter với một closure capture biến
shoe_size từ môi trường của nó để lặp qua một tập hợp các phiên bản struct
Shoe. Nó sẽ chỉ trả về những đôi giày có kích thước được chỉ định.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}Hàm shoes_in_size lấy quyền sở hữu của một vector giày và một kích thước giày
làm tham số. Nó trả về một vector chỉ chứa giày có kích thước được chỉ định.
Trong phần thân của shoes_in_size, chúng ta gọi into_iter để tạo một
iterator lấy quyền sở hữu của vector. Sau đó, chúng ta gọi filter để điều
chỉnh iterator đó thành một iterator mới chỉ chứa các phần tử mà closure trả về
true.
Closure capture tham số shoe_size từ môi trường và so sánh giá trị đó với kích
thước của mỗi đôi giày, giữ lại chỉ những đôi giày có kích thước được chỉ định.
Cuối cùng, gọi collect thu thập các giá trị được trả về bởi iterator đã điều
chỉnh vào một vector được trả về bởi hàm.
Test cho thấy rằng khi chúng ta gọi shoes_in_size, chúng ta chỉ nhận lại những
đôi giày có cùng kích thước với giá trị mà chúng ta đã chỉ định.
Cải thiện Dự án I/O của chúng ta
Với kiến thức mới về iterators, chúng ta có thể cải thiện dự án I/O trong Chương
12 bằng cách sử dụng iterators để làm cho những phần trong mã nguồn trở nên rõ
ràng và ngắn gọn hơn. Hãy xem cách iterators có thể cải thiện cách triển khai
hàm Config::build và hàm search của chúng ta.
Loại bỏ clone bằng cách sử dụng Iterator
Trong Listing 12-6, chúng ta đã thêm mã lấy một slice của các giá trị String
và tạo một thể hiện của struct Config bằng cách lập chỉ mục vào slice và sao
chép các giá trị, cho phép struct Config sở hữu những giá trị đó. Trong
Listing 13-17, chúng ta đã tái hiện lại cách triển khai hàm Config::build như
trong Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Vào thời điểm đó, chúng ta đã nói đừng lo lắng về việc gọi clone không hiệu
quả vì chúng ta sẽ loại bỏ chúng trong tương lai. Vâng, thời điểm đó là bây giờ!
Chúng ta cần clone ở đây vì chúng ta có một slice với các phần tử String
trong tham số args, nhưng hàm build không sở hữu args. Để trả về quyền sở
hữu của một thể hiện Config, chúng ta đã phải sao chép giá trị từ trường
query và file_path của Config để thể hiện Config có thể sở hữu các giá
trị của nó.
Với kiến thức mới của chúng ta về iterators, chúng ta có thể thay đổi hàm
build để nhận quyền sở hữu một iterator làm đối số thay vì mượn một slice.
Chúng ta sẽ sử dụng chức năng của iterator thay vì mã kiểm tra độ dài của slice
và lập chỉ mục vào các vị trí cụ thể. Điều này sẽ làm rõ những gì hàm
Config::build đang làm vì iterator sẽ truy cập các giá trị.
Một khi Config::build nắm quyền sở hữu iterator và ngừng sử dụng các thao tác
lập chỉ mục đang mượn, chúng ta có thể di chuyển các giá trị String từ
iterator vào Config thay vì gọi clone và tạo một phân bổ mới.
Sử dụng Iterator trả về trực tiếp
Mở file src/main.rs của dự án I/O, nó sẽ trông như thế này:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Đầu tiên chúng ta sẽ thay đổi phần đầu của hàm main mà chúng ta đã có trong
Listing 12-24 thành mã trong Listing 13-18, lần này sử dụng một iterator. Điều
này sẽ không biên dịch cho đến khi chúng ta cũng cập nhật Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Hàm env::args trả về một iterator! Thay vì thu thập các giá trị iterator vào
một vector và sau đó truyền một slice cho Config::build, bây giờ chúng ta đang
truyền quyền sở hữu của iterator được trả về từ env::args trực tiếp cho
Config::build.
Tiếp theo, chúng ta cần cập nhật định nghĩa của Config::build. Hãy thay đổi
chữ ký của Config::build để trông giống như Listing 13-19. Điều này vẫn chưa
biên dịch được, vì chúng ta cần cập nhật phần thân hàm.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Tài liệu thư viện tiêu chuẩn cho hàm env::args cho thấy rằng kiểu của iterator
nó trả về là std::env::Args, và kiểu đó triển khai trait Iterator và trả về
các giá trị String.
Chúng ta đã cập nhật chữ ký của hàm Config::build để tham số args có một
kiểu tổng quát với ràng buộc trait impl Iterator<Item = String> thay vì
&[String]. Cách sử dụng cú pháp impl Trait mà chúng ta đã thảo luận trong
phần "Traits as Parameters" của Chương 10 có nghĩa
là args có thể là bất kỳ kiểu nào triển khai trait Iterator và trả về các
mục String.
Bởi vì chúng ta đang lấy quyền sở hữu của args và chúng ta sẽ thay đổi args
bằng cách lặp qua nó, chúng ta có thể thêm từ khóa mut vào chỉ định của tham
số args để làm cho nó có thể thay đổi.
Sử dụng các phương thức Trait Iterator thay vì lập chỉ mục
Tiếp theo, chúng ta sẽ sửa phần thân của Config::build. Bởi vì args triển
khai trait Iterator, chúng ta biết rằng chúng ta có thể gọi phương thức next
trên nó! Listing 13-20 cập nhật mã từ Listing 12-23 để sử dụng phương thức
next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Hãy nhớ rằng giá trị đầu tiên trong giá trị trả về của env::args là tên của
chương trình. Chúng ta muốn bỏ qua nó và chuyển đến giá trị tiếp theo, vì vậy
đầu tiên chúng ta gọi next và không làm gì với giá trị trả về. Tiếp theo chúng
ta gọi next để lấy giá trị mà chúng ta muốn đặt vào trường query của
Config. Nếu next trả về Some, chúng ta sử dụng match để trích xuất giá
trị. Nếu nó trả về None, điều đó có nghĩa là không đủ đối số được đưa ra và
chúng ta trả về sớm với một giá trị Err. Chúng ta cũng làm tương tự cho giá
trị file_path.
Làm cho mã rõ ràng hơn với bộ điều hợp Iterator
Chúng ta cũng có thể tận dụng iterators trong hàm search trong dự án I/O của
chúng ta, được tái hiện ở đây trong Listing 13-21 như trong Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Chúng ta có thể viết mã này một cách ngắn gọn hơn bằng cách sử dụng phương thức
bộ điều hợp iterator. Làm như vậy cũng cho phép chúng ta tránh phải có một
vector results trung gian có thể thay đổi. Phong cách lập trình hàm ưu tiên
việc giảm thiểu lượng trạng thái có thể thay đổi để làm cho mã rõ ràng hơn. Loại
bỏ trạng thái có thể thay đổi có thể cho phép một cải tiến trong tương lai để
làm cho việc tìm kiếm diễn ra song song vì chúng ta sẽ không phải quản lý truy
cập đồng thời vào vector results. Listing 13-22 cho thấy sự thay đổi này.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Nhớ lại rằng mục đích của hàm search là trả về tất cả các dòng trong
contents có chứa query. Tương tự như ví dụ filter trong Listing 13-16, mã
này sử dụng bộ điều hợp filter để chỉ giữ lại các dòng mà
line.contains(query) trả về true. Sau đó, chúng ta thu thập các dòng phù hợp
vào một vector khác với collect. Đơn giản hơn nhiều! Hãy tự nhiên thực hiện
thay đổi tương tự để sử dụng phương thức iterator trong hàm
search_case_insensitive.
Để cải tiến thêm, hãy trả về một iterator từ hàm search bằng cách loại bỏ lệnh
gọi collect và thay đổi kiểu trả về thành impl Iterator<Item = &'a str> để
hàm trở thành một bộ điều hợp iterator. Lưu ý rằng bạn cũng sẽ cần cập nhật các
test! Tìm kiếm qua một file lớn bằng công cụ minigrep của bạn trước và sau khi
thực hiện thay đổi này để quan sát sự khác biệt trong hành vi. Trước thay đổi
này, chương trình sẽ không in bất kỳ kết quả nào cho đến khi nó đã thu thập tất
cả kết quả, nhưng sau thay đổi, kết quả sẽ được in khi mỗi dòng phù hợp được tìm
thấy vì vòng lặp for trong hàm run có thể tận dụng tính lười biếng của
iterator.
Lựa chọn giữa Vòng lặp và Iterators
Câu hỏi hợp lý tiếp theo là phong cách nào bạn nên chọn trong mã của riêng bạn và tại sao: triển khai ban đầu trong Listing 13-21 hoặc phiên bản sử dụng iterators trong Listing 13-22 (giả sử chúng ta đang thu thập tất cả kết quả trước khi trả về chúng thay vì trả về iterator). Hầu hết các lập trình viên Rust đều thích sử dụng phong cách iterator. Nó hơi khó nắm bắt lúc đầu, nhưng một khi bạn đã cảm nhận được các bộ điều hợp iterator khác nhau và những gì chúng làm, iterators có thể dễ hiểu hơn. Thay vì phải vật lộn với các chi tiết khác nhau của vòng lặp và xây dựng vector mới, mã tập trung vào mục tiêu cấp cao của vòng lặp. Điều này trừu tượng hóa một số mã thông thường để dễ dàng hơn khi thấy các khái niệm độc đáo cho mã này, chẳng hạn như điều kiện lọc mỗi phần tử trong iterator phải vượt qua.
Nhưng hai cách triển khai có thực sự tương đương không? Giả định trực giác có thể là vòng lặp cấp thấp hơn sẽ nhanh hơn. Hãy nói về hiệu suất.
So sánh Hiệu suất: Vòng lặp và Iterator
Để quyết định nên sử dụng vòng lặp hay iterator, bạn cần biết triển khai nào
nhanh hơn: phiên bản của hàm search với vòng lặp for rõ ràng hay phiên bản
với iterator.
Chúng tôi đã chạy một bài kiểm tra hiệu suất bằng cách tải toàn bộ nội dung của
The Adventures of Sherlock Holmes của Sir Arthur Conan Doyle vào một String
và tìm kiếm từ the trong nội dung. Dưới đây là kết quả kiểm tra hiệu suất trên
phiên bản search sử dụng vòng lặp for và phiên bản sử dụng iterator:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Hai triển khai có hiệu suất tương tự! Chúng tôi sẽ không giải thích mã kiểm tra hiệu suất ở đây vì điểm quan trọng không phải để chứng minh rằng hai phiên bản là tương đương mà để có cảm nhận chung về cách hai triển khai này so sánh về mặt hiệu suất.
Để có một bài kiểm tra hiệu suất toàn diện hơn, bạn nên kiểm tra sử dụng các văn
bản khác nhau với kích thước khác nhau làm contents, các từ khác nhau và các
từ có độ dài khác nhau làm query, và tất cả các biến thể khác. Điểm quan trọng
là: iterator, mặc dù là một trừu tượng cấp cao, được biên dịch thành mã gần
giống như khi bạn tự viết mã cấp thấp. Iterator là một trong những trừu tượng
không tốn chi phí của Rust, nghĩa là việc sử dụng trừu tượng không áp đặt thêm
chi phí thời gian chạy. Điều này tương tự như cách Bjarne Stroustrup, nhà thiết
kế và người triển khai ban đầu của C++, định nghĩa không tốn chi phí trong
"Foundations of C++" (2012):
Nói chung, các triển khai C++ tuân theo nguyên tắc không tốn chi phí: Những gì bạn không sử dụng, bạn không phải trả giá. Và hơn nữa: Những gì bạn sử dụng, bạn không thể tự viết mã tốt hơn được.
Trong nhiều trường hợp, mã Rust sử dụng iterator được biên dịch thành cùng assembly mà bạn sẽ viết bằng tay. Các tối ưu hóa như mở rộng vòng lặp và loại bỏ kiểm tra giới hạn trên truy cập mảng được áp dụng và làm cho mã kết quả cực kỳ hiệu quả. Bây giờ bạn đã biết điều này, bạn có thể sử dụng iterator và closure mà không sợ hãi! Chúng làm cho mã có vẻ như ở cấp độ cao hơn nhưng không áp đặt hình phạt hiệu suất thời gian chạy khi làm như vậy.
Tóm tắt
Closure và iterator là các tính năng của Rust lấy cảm hứng từ ý tưởng ngôn ngữ lập trình hàm. Chúng đóng góp vào khả năng của Rust trong việc biểu đạt rõ ràng các ý tưởng cấp cao với hiệu suất cấp thấp. Các triển khai của closure và iterator là như vậy để hiệu suất thời gian chạy không bị ảnh hưởng. Đây là một phần trong mục tiêu của Rust nhằm cung cấp các trừu tượng không tốn chi phí.
Bây giờ chúng ta đã cải thiện khả năng biểu đạt của dự án I/O của mình, hãy xem
xét một số tính năng khác của cargo sẽ giúp chúng ta chia sẻ dự án với thế
giới.
Thêm về Cargo và Crates.io
Cho đến nay, chúng ta mới chỉ sử dụng các tính năng cơ bản nhất của Cargo để xây dựng, chạy và kiểm thử mã của mình, nhưng nó có thể làm được nhiều hơn thế. Trong chương này, chúng ta sẽ thảo luận một số tính năng nâng cao khác để chỉ cho bạn cách thực hiện những việc sau:
- Tùy chỉnh bản dựng thông qua các hồ sơ phát hành
- Xuất bản thư viện lên crates.io
- Tổ chức các dự án lớn với workspaces
- Cài đặt các tệp nhị phân từ crates.io
- Mở rộng Cargo bằng cách sử dụng các lệnh tùy chỉnh
Cargo thậm chí có thể làm nhiều hơn cả những chức năng mà chúng ta đề cập trong chương này, vì vậy để có lời giải thích đầy đủ về tất cả các tính năng của nó, hãy xem tài liệu của nó.
Tùy chỉnh Quá trình Xây dựng với Hồ sơ Phát hành
Trong Rust, hồ sơ phát hành (release profiles) là các hồ sơ được định nghĩa trước và có thể tùy chỉnh với các cấu hình khác nhau cho phép lập trình viên có thêm quyền kiểm soát đối với các tùy chọn biên dịch mã. Mỗi hồ sơ được cấu hình độc lập với các hồ sơ khác.
Cargo có hai hồ sơ chính: hồ sơ dev mà Cargo sử dụng khi bạn chạy
cargo build, và hồ sơ release mà Cargo sử dụng khi bạn chạy
cargo build --release. Hồ sơ dev được định nghĩa với các giá trị mặc định
tốt cho quá trình phát triển, và hồ sơ release có các giá trị mặc định tốt cho
các bản dựng phát hành.
Những tên hồ sơ này có thể quen thuộc từ kết quả đầu ra của quá trình xây dựng của bạn:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
dev và release là các hồ sơ khác nhau được sử dụng bởi trình biên dịch.
Cargo có các cài đặt mặc định cho mỗi hồ sơ, áp dụng khi bạn chưa thêm rõ ràng
bất kỳ phần [profile.*] nào vào tệp Cargo.toml của dự án. Bằng cách thêm các
phần [profile.*] cho bất kỳ hồ sơ nào bạn muốn tùy chỉnh, bạn ghi đè lên bất
kỳ tập hợp con nào của các cài đặt mặc định. Ví dụ, đây là các giá trị mặc định
cho cài đặt opt-level của các hồ sơ dev và release:
Tên tệp: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Cài đặt opt-level kiểm soát số lượng tối ưu hóa mà Rust sẽ áp dụng cho mã của
bạn, với phạm vi từ 0 đến 3. Áp dụng nhiều tối ưu hóa hơn sẽ kéo dài thời gian
biên dịch, vì vậy nếu bạn đang trong quá trình phát triển và thường xuyên biên
dịch mã của mình, bạn sẽ muốn ít tối ưu hóa hơn để biên dịch nhanh hơn, ngay cả
khi mã thu được chạy chậm hơn. Do đó, opt-level mặc định cho dev là 0. Khi
bạn đã sẵn sàng phát hành mã của mình, tốt nhất là dành nhiều thời gian hơn cho
việc biên dịch. Bạn sẽ chỉ biên dịch ở chế độ phát hành một lần, nhưng bạn sẽ
chạy chương trình đã biên dịch nhiều lần, vì vậy chế độ phát hành đánh đổi thời
gian biên dịch lâu hơn lấy mã chạy nhanh hơn. Đó là lý do tại sao opt-level
mặc định cho hồ sơ release là 3.
Bạn có thể ghi đè cài đặt mặc định bằng cách thêm một giá trị khác vào Cargo.toml. Ví dụ, nếu chúng ta muốn sử dụng mức tối ưu hóa 1 trong hồ sơ phát triển, chúng ta có thể thêm hai dòng này vào tệp Cargo.toml của dự án:
Tên tệp: Cargo.toml
[profile.dev]
opt-level = 1
Mã này ghi đè lên cài đặt mặc định là 0. Bây giờ khi chúng ta chạy
cargo build, Cargo sẽ sử dụng các giá trị mặc định cho hồ sơ dev cộng với
tùy chỉnh của chúng ta cho opt-level. Vì chúng ta đặt opt-level thành 1,
Cargo sẽ áp dụng nhiều tối ưu hóa hơn so với mặc định, nhưng không nhiều như
trong bản dựng phát hành.
Để biết danh sách đầy đủ các tùy chọn cấu hình và giá trị mặc định cho mỗi hồ sơ, hãy xem tài liệu của Cargo.
Xuất bản một Crate lên Crates.io
Chúng ta đã sử dụng các gói từ crates.io làm các phụ thuộc của dự án, nhưng bạn cũng có thể chia sẻ mã của mình với người khác bằng cách xuất bản các gói của riêng bạn. Sổ đăng ký crate tại crates.io phân phối mã nguồn của các gói của bạn, vì vậy nó chủ yếu lưu trữ mã nguồn mở.
Rust và Cargo có các tính năng giúp gói đã xuất bản của bạn dễ dàng được tìm thấy và sử dụng hơn. Chúng ta sẽ nói về một số tính năng này tiếp theo và sau đó giải thích cách xuất bản một gói.
Tạo Bình luận Tài liệu Hữu ích
Việc tài liệu hóa chính xác các gói sẽ giúp người dùng khác biết cách và khi nào
sử dụng chúng, vì vậy đáng để đầu tư thời gian viết tài liệu. Trong Chương 3,
chúng ta đã thảo luận về cách bình luận mã Rust bằng hai dấu gạch chéo, //.
Rust cũng có một loại bình luận đặc biệt cho tài liệu, được gọi một cách thuận
tiện là bình luận tài liệu, sẽ tạo ra tài liệu HTML. HTML hiển thị nội dung
của các bình luận tài liệu cho các mục API công khai dành cho các lập trình viên
quan tâm đến việc biết cách sử dụng crate của bạn thay vì cách crate của bạn
được triển khai.
Bình luận tài liệu sử dụng ba dấu gạch chéo, ///, thay vì hai và hỗ trợ ký
hiệu Markdown để định dạng văn bản. Đặt bình luận tài liệu ngay trước mục mà
chúng tài liệu hóa. Listing 14-1 hiển thị bình luận tài liệu cho một hàm
add_one trong một crate có tên my_crate.
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Ở đây, chúng ta cung cấp mô tả về những gì hàm add_one làm, bắt đầu một phần
với tiêu đề Examples, và sau đó cung cấp mã minh họa cách sử dụng hàm
add_one. Chúng ta có thể tạo tài liệu HTML từ bình luận tài liệu này bằng cách
chạy cargo doc. Lệnh này chạy công cụ rustdoc được phân phối với Rust và đặt
tài liệu HTML được tạo ra trong thư mục target/doc.
Để thuận tiện, chạy cargo doc --open sẽ xây dựng HTML cho tài liệu của crate
hiện tại (cũng như tài liệu cho tất cả các phụ thuộc của crate) và mở kết quả
trong trình duyệt web. Điều hướng đến hàm add_one và bạn sẽ thấy cách văn bản
trong bình luận tài liệu được hiển thị, như trong Hình 14-1.
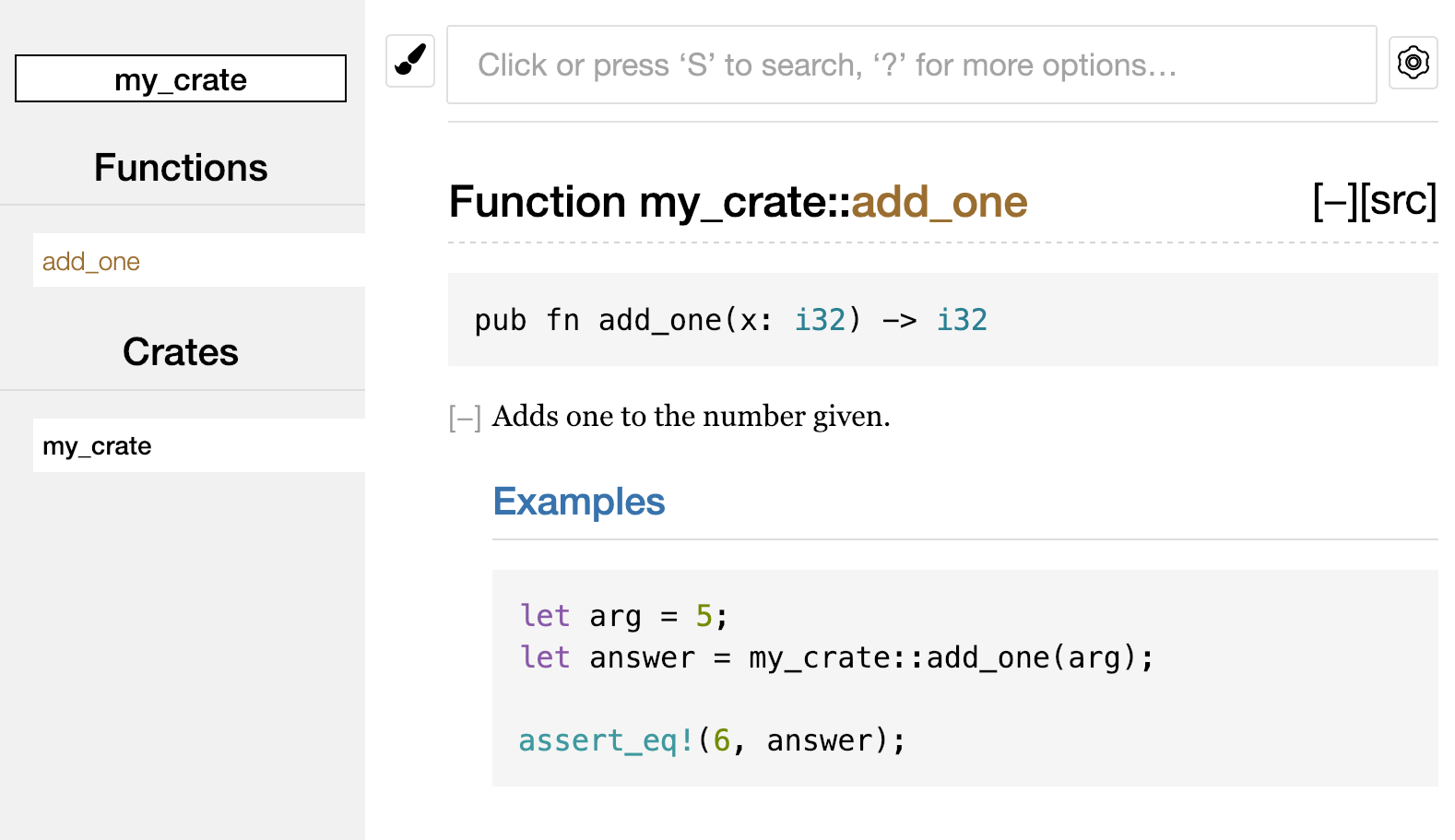
Hình 14-1: Tài liệu HTML cho hàm add_one
Các Phần Thường Được Sử dụng
Chúng ta đã sử dụng tiêu đề Markdown # Examples trong Listing 14-1 để tạo một
phần trong HTML với tiêu đề "Examples." Dưới đây là một số phần khác mà tác giả
crate thường sử dụng trong tài liệu của họ:
- Panics: Các tình huống mà hàm đang được tài liệu hóa có thể gây panic. Người gọi hàm không muốn chương trình của họ bị panic nên đảm bảo rằng họ không gọi hàm trong những tình huống này.
- Errors: Nếu hàm trả về một
Result, mô tả các loại lỗi có thể xảy ra và điều kiện nào có thể gây ra những lỗi đó được trả về có thể hữu ích cho người gọi để họ có thể viết mã xử lý các loại lỗi khác nhau theo các cách khác nhau. - Safety: Nếu hàm là
unsafekhi gọi (chúng ta thảo luận về tính không an toàn trong Chương 20), nên có một phần giải thích tại sao hàm không an toàn và đề cập đến các bất biến mà hàm mong đợi người gọi duy trì.
Hầu hết các bình luận tài liệu không cần tất cả các phần này, nhưng đây là một danh sách kiểm tra tốt để nhắc nhở bạn về các khía cạnh của mã mà người dùng sẽ quan tâm.
Bình luận Tài liệu như Các Bài Kiểm thử
Thêm các khối mã ví dụ trong bình luận tài liệu của bạn có thể giúp minh họa
cách sử dụng thư viện của bạn, và làm như vậy có một lợi ích bổ sung: chạy
cargo test sẽ chạy các ví dụ mã trong tài liệu của bạn như các bài kiểm thử!
Không có gì tốt hơn tài liệu với các ví dụ. Nhưng không có gì tệ hơn các ví dụ
không hoạt động vì mã đã thay đổi kể từ khi tài liệu được viết. Nếu chúng ta
chạy cargo test với tài liệu cho hàm add_one từ Listing 14-1, chúng ta sẽ
thấy một phần trong kết quả kiểm thử trông như thế này:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Bây giờ, nếu chúng ta thay đổi hàm hoặc ví dụ để assert_eq! trong ví dụ gây
panic, và chạy cargo test một lần nữa, chúng ta sẽ thấy rằng các bài kiểm thử
tài liệu phát hiện ra ví dụ và mã không còn đồng bộ với nhau!
Bình luận về Các Mục Chứa
Kiểu bình luận tài liệu //! thêm tài liệu vào mục chứa bình luận thay vì vào
các mục theo sau bình luận. Chúng ta thường sử dụng các bình luận tài liệu này
bên trong tệp gốc crate (src/lib.rs theo quy ước) hoặc bên trong một module để
tài liệu hóa crate hoặc module nói chung.
Ví dụ, để thêm tài liệu mô tả mục đích của crate my_crate chứa hàm add_one,
chúng ta thêm bình luận tài liệu bắt đầu bằng //! vào đầu tệp src/lib.rs,
như trong Listing 14-2.
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Lưu ý rằng không có bất kỳ mã nào sau dòng cuối cùng bắt đầu bằng //!. Bởi vì
chúng ta bắt đầu bình luận bằng //! thay vì ///, chúng ta đang tài liệu hóa
mục chứa bình luận này thay vì một mục theo sau bình luận này. Trong trường hợp
này, mục đó là tệp src/lib.rs, là gốc crate. Các bình luận này mô tả toàn bộ
crate.
Khi chúng ta chạy cargo doc --open, các bình luận này sẽ hiển thị trên trang
đầu của tài liệu cho my_crate phía trên danh sách các mục công khai trong
crate, như trong Hình 14-2.
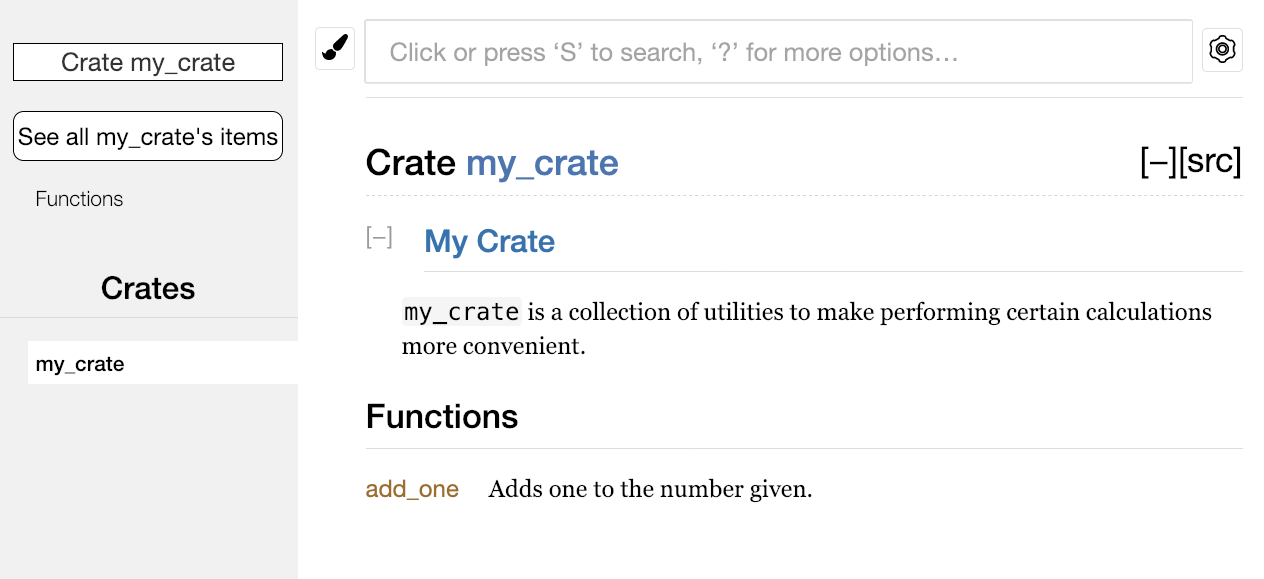
Hình 14-2: Tài liệu được tạo ra cho my_crate, bao gồm
bình luận mô tả toàn bộ crate
Bình luận tài liệu trong các mục rất hữu ích để mô tả crates và modules đặc biệt. Sử dụng chúng để giải thích mục đích tổng thể của container để giúp người dùng hiểu tổ chức của crate.
Xuất một API Công khai Thuận tiện với pub use
Cấu trúc của API công khai của bạn là một cân nhắc quan trọng khi xuất bản một crate. Những người sử dụng crate của bạn ít quen thuộc với cấu trúc hơn bạn và có thể gặp khó khăn khi tìm các phần họ muốn sử dụng nếu crate của bạn có một cấu trúc phân cấp module lớn.
Trong Chương 7, chúng ta đã đề cập đến cách làm cho các mục công khai bằng cách
sử dụng từ khóa pub, và cách đưa các mục vào phạm vi với từ khóa use. Tuy
nhiên, cấu trúc có ý nghĩa đối với bạn trong khi phát triển một crate có thể
không thuận tiện cho người dùng của bạn. Bạn có thể muốn tổ chức các struct của
mình trong một hệ thống phân cấp chứa nhiều cấp, nhưng sau đó những người muốn
sử dụng một kiểu bạn đã định nghĩa sâu trong hệ thống phân cấp có thể gặp khó
khăn khi tìm ra kiểu đó tồn tại. Họ cũng có thể bực mình khi phải nhập
use my_crate::some_module::another_module::UsefulType; thay vì
use my_crate::UsefulType;.
Tin tốt là nếu cấu trúc không thuận tiện cho người khác sử dụng từ một thư
viện khác, bạn không cần phải sắp xếp lại tổ chức nội bộ của mình: thay vào đó,
bạn có thể tái xuất các mục để tạo một cấu trúc công khai khác với cấu trúc
riêng tư của bạn bằng cách sử dụng pub use. Tái xuất lấy một mục công khai ở
một vị trí và làm cho nó công khai ở một vị trí khác, như thể nó được định nghĩa
ở vị trí khác đó.
Ví dụ, giả sử chúng ta đã tạo một thư viện có tên art để mô hình hóa các khái
niệm nghệ thuật. Trong thư viện này có hai module: module kinds chứa hai enum
có tên PrimaryColor và SecondaryColor và module utils chứa một hàm có tên
mix, như trong Listing 14-3:
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}Hình 14-3 hiển thị trang đầu tiên của tài liệu cho crate này được tạo ra bởi
cargo doc sẽ trông như thế nào:
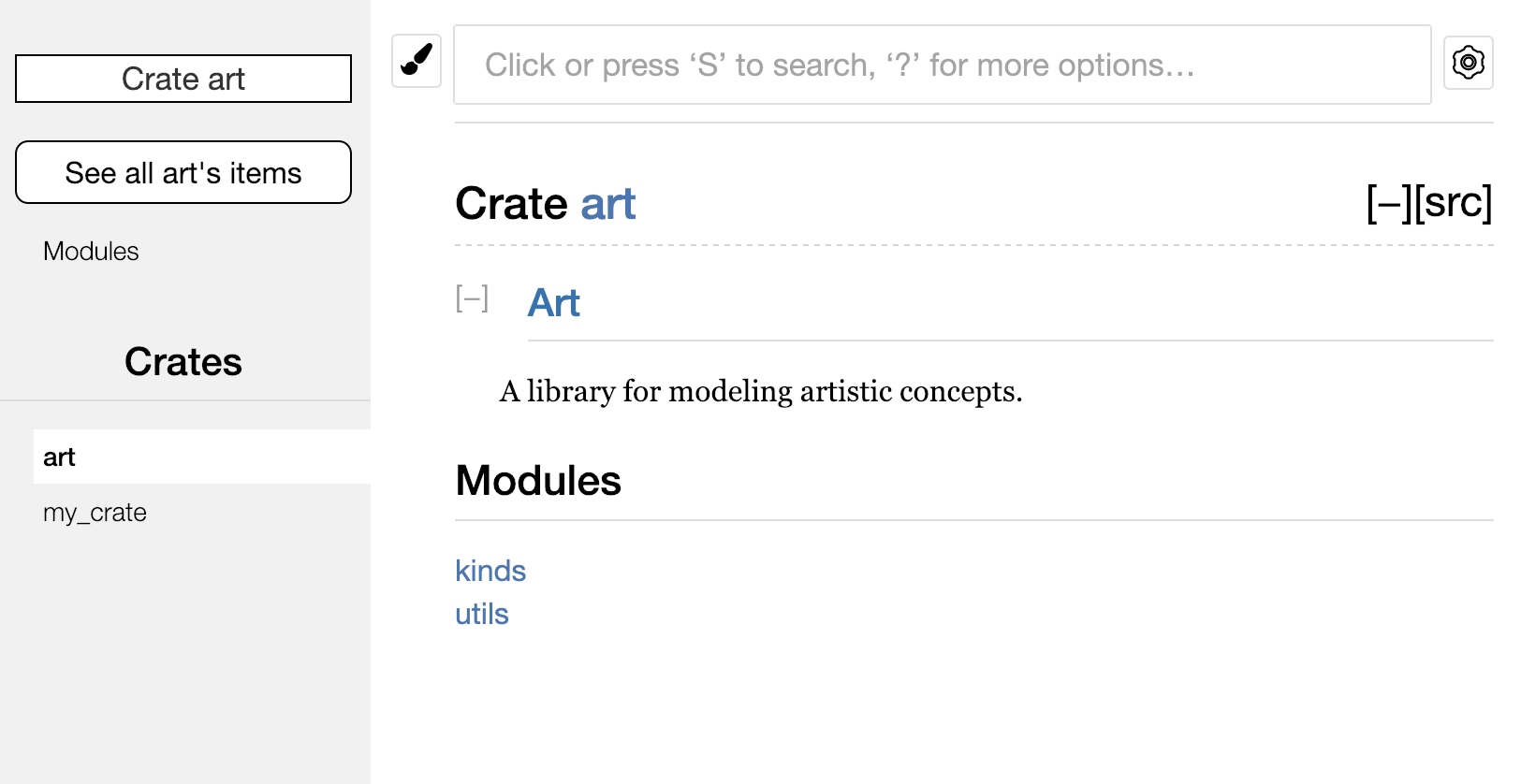
Hình 14-3: Trang đầu tiên của tài liệu cho art liệt kê
các module kinds và utils
Lưu ý rằng các kiểu PrimaryColor và SecondaryColor không được liệt kê trên
trang đầu, cũng như hàm mix. Chúng ta phải nhấp vào kinds và utils để xem
chúng.
Một crate khác phụ thuộc vào thư viện này sẽ cần các câu lệnh use đưa các mục
từ art vào phạm vi, chỉ định cấu trúc module hiện đang được định nghĩa.
Listing 14-4 hiển thị một ví dụ về crate sử dụng các mục PrimaryColor và mix
từ crate art:
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Tác giả của mã trong Listing 14-4, sử dụng crate art, đã phải tìm ra rằng
PrimaryColor nằm trong module kinds và mix nằm trong module utils. Cấu
trúc module của crate art liên quan hơn đến các nhà phát triển làm việc trên
crate art hơn là những người sử dụng nó. Cấu trúc nội bộ không chứa bất kỳ
thông tin hữu ích nào cho ai đó đang cố gắng hiểu cách sử dụng crate art, mà
thay vào đó gây ra nhầm lẫn vì các nhà phát triển sử dụng nó phải tìm ra nơi để
tìm, và phải chỉ định tên module trong các câu lệnh use.
Để loại bỏ tổ chức nội bộ khỏi API công khai, chúng ta có thể sửa đổi mã crate
art trong Listing 14-3 để thêm các câu lệnh pub use để tái xuất các mục ở
cấp cao nhất, như trong Listing 14-5:
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}Tài liệu API mà cargo doc tạo ra cho crate này bây giờ sẽ liệt kê và liên kết
các tái xuất trên trang đầu, như trong Hình 14-4, làm cho các kiểu
PrimaryColor và SecondaryColor và hàm mix dễ tìm hơn.
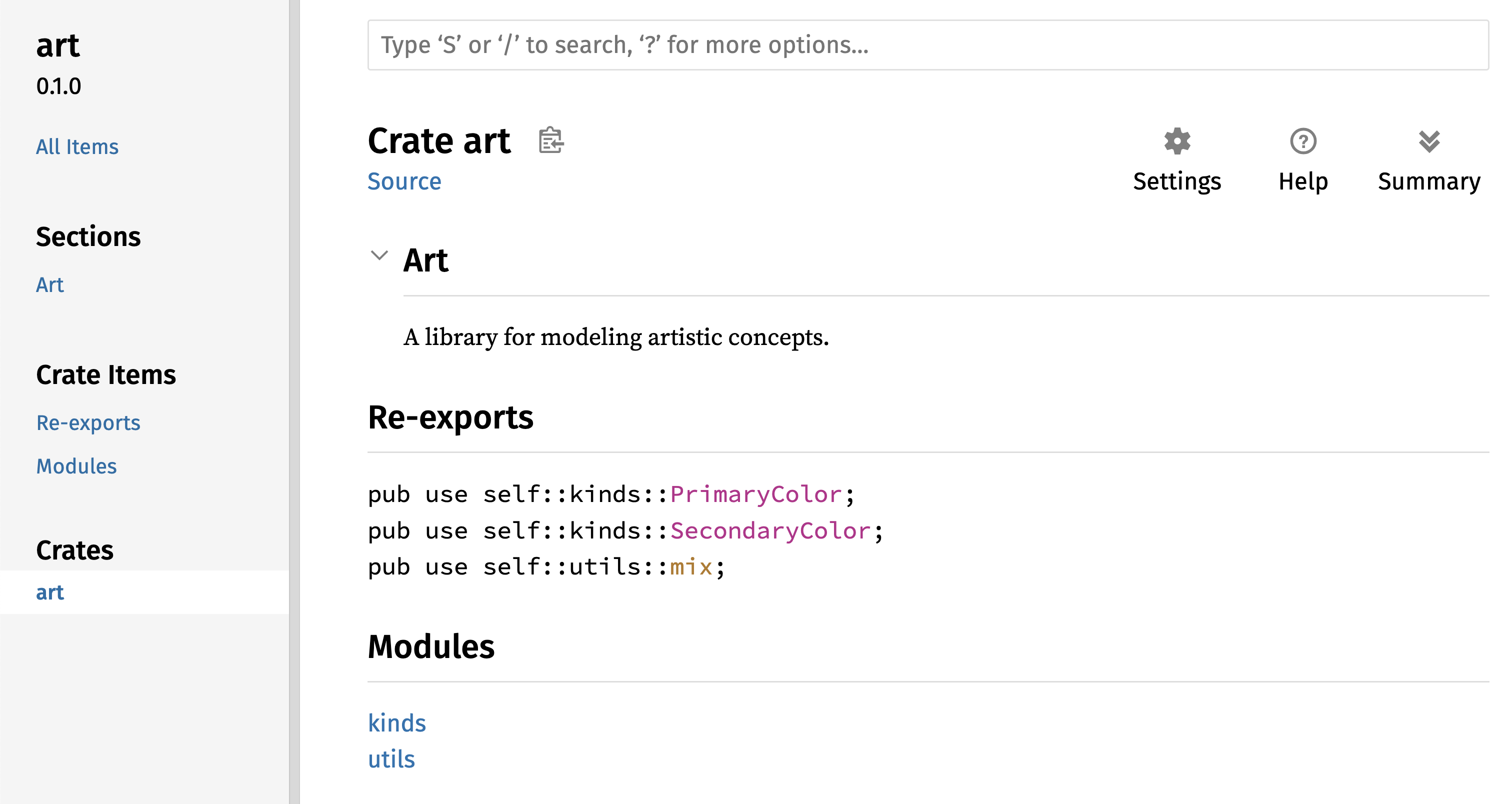
Hình 14-4: Trang đầu tiên của tài liệu cho art liệt kê
các tái xuất
Người dùng crate art vẫn có thể thấy và sử dụng cấu trúc nội bộ từ Listing
14-3 như được minh họa trong Listing 14-4, hoặc họ có thể sử dụng cấu trúc thuận
tiện hơn trong Listing 14-5, như được hiển thị trong Listing 14-6:
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Trong các trường hợp có nhiều module lồng nhau, tái xuất các kiểu ở cấp cao nhất
với pub use có thể tạo ra sự khác biệt đáng kể trong trải nghiệm của những
người sử dụng crate. Một cách sử dụng phổ biến khác của pub use là tái xuất
các định nghĩa của một phụ thuộc trong crate hiện tại để làm cho các định nghĩa
của crate đó trở thành một phần của API công khai của crate của bạn.
Tạo một cấu trúc API công khai hữu ích là một nghệ thuật hơn là một khoa học, và
bạn có thể lặp lại để tìm API hoạt động tốt nhất cho người dùng của bạn. Chọn
pub use cho bạn sự linh hoạt trong cách bạn cấu trúc crate của mình nội bộ và
tách biệt cấu trúc nội bộ đó khỏi những gì bạn trình bày cho người dùng của bạn.
Xem xét một số mã của crates bạn đã cài đặt để xem liệu cấu trúc nội bộ của
chúng có khác với API công khai của chúng hay không.
Thiết lập Tài khoản Crates.io
Trước khi bạn có thể xuất bản bất kỳ crate nào, bạn cần tạo một tài khoản trên
crates.io và nhận một token API. Để làm
điều này, hãy truy cập trang chủ tại
crates.io và đăng nhập thông qua tài khoản
GitHub. (Tài khoản GitHub hiện là một yêu cầu, nhưng trang web có thể hỗ trợ các
cách khác để tạo tài khoản trong tương lai.) Sau khi đăng nhập, hãy truy cập cài
đặt tài khoản của bạn tại
https://crates.io/me/ và lấy khóa API
của bạn. Sau đó chạy lệnh cargo login và dán khóa API của bạn khi được nhắc,
như thế này:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Lệnh này sẽ thông báo cho Cargo về token API của bạn và lưu trữ nó cục bộ trong ~/.cargo/credentials.toml. Lưu ý rằng token này là một bí mật: không chia sẻ nó với bất kỳ ai khác. Nếu bạn chia sẻ nó với bất kỳ ai vì bất kỳ lý do gì, bạn nên thu hồi nó và tạo một token mới trên crates.io.
Thêm Metadata cho một Crate Mới
Giả sử bạn có một crate bạn muốn xuất bản. Trước khi xuất bản, bạn sẽ cần thêm
một số metadata trong phần [package] của tệp Cargo.toml của crate.
Crate của bạn sẽ cần một tên duy nhất. Trong khi bạn đang làm việc trên một
crate cục bộ, bạn có thể đặt tên crate bất cứ điều gì bạn thích. Tuy nhiên, tên
crate trên crates.io được phân bổ theo
nguyên tắc ai đến trước được phục vụ trước. Một khi tên crate được lấy, không ai
khác có thể xuất bản một crate với tên đó. Trước khi cố gắng xuất bản một crate,
hãy tìm kiếm tên bạn muốn sử dụng. Nếu tên đã được sử dụng, bạn sẽ cần tìm một
tên khác và chỉnh sửa trường name trong tệp Cargo.toml dưới phần [package]
để sử dụng tên mới cho việc xuất bản, như sau:
Tên tệp: Cargo.toml
[package]
name = "guessing_game"
Ngay cả khi bạn đã chọn một tên duy nhất, khi bạn chạy cargo publish để xuất
bản crate tại thời điểm này, bạn sẽ nhận được cảnh báo và sau đó là lỗi:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Điều này dẫn đến lỗi vì bạn thiếu một số thông tin quan trọng: một mô tả và giấy
phép là bắt buộc để mọi người biết crate của bạn làm gì và theo những điều khoản
nào họ có thể sử dụng nó. Trong Cargo.toml, thêm một mô tả chỉ là một câu hoặc
hai, vì nó sẽ xuất hiện với crate của bạn trong kết quả tìm kiếm. Đối với trường
license, bạn cần cung cấp một giá trị định danh giấy phép. Trao đổi Dữ liệu
Gói Phần mềm (SPDX) của Quỹ Linux liệt kê các định danh bạn có thể sử
dụng cho giá trị này. Ví dụ, để chỉ định rằng bạn đã cấp phép crate của mình
bằng Giấy phép MIT, hãy thêm định danh MIT:
Tên tệp: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Nếu bạn muốn sử dụng giấy phép không xuất hiện trong SPDX, bạn cần đặt văn bản
của giấy phép đó vào một tệp, bao gồm tệp đó trong dự án của bạn, và sau đó sử
dụng license-file để chỉ định tên của tệp đó thay vì sử dụng khóa license.
Hướng dẫn về giấy phép nào phù hợp cho dự án của bạn nằm ngoài phạm vi của cuốn
sách này. Nhiều người trong cộng đồng Rust cấp phép cho các dự án của họ theo
cách giống như Rust bằng cách sử dụng giấy phép kép là MIT OR Apache-2.0. Thực
hành này cho thấy bạn cũng có thể chỉ định nhiều định danh giấy phép được phân
tách bằng OR để có nhiều giấy phép cho dự án của bạn.
Với một tên duy nhất, phiên bản, mô tả của bạn, và giấy phép được thêm vào, tệp Cargo.toml cho một dự án sẵn sàng xuất bản có thể trông như thế này:
Tên tệp: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "Một trò chơi vui nhộn nơi bạn đoán số mà máy tính đã chọn."
license = "MIT OR Apache-2.0"
[dependencies]
Tài liệu của Cargo mô tả các metadata khác bạn có thể chỉ định để đảm bảo người khác có thể khám phá và sử dụng crate của bạn dễ dàng hơn.
Xuất bản lên Crates.io
Bây giờ bạn đã tạo một tài khoản, lưu token API của bạn, chọn một tên cho crate của bạn, và chỉ định các metadata bắt buộc, bạn đã sẵn sàng để xuất bản! Xuất bản một crate tải lên một phiên bản cụ thể lên crates.io để người khác sử dụng.
Hãy cẩn thận, vì một lần xuất bản là vĩnh viễn. Phiên bản không bao giờ có thể được ghi đè, và mã không thể bị xóa trừ trong một số trường hợp nhất định. Một mục tiêu chính của crates.io là hoạt động như một kho lưu trữ vĩnh viễn của mã để các bản dựng của tất cả các dự án phụ thuộc vào crates từ crates.io sẽ tiếp tục hoạt động. Cho phép xóa phiên bản sẽ làm cho việc đạt được mục tiêu đó là không thể. Tuy nhiên, không có giới hạn về số lượng phiên bản crate bạn có thể xuất bản.
Chạy lệnh cargo publish một lần nữa. Lần này nó sẽ thành công:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Uploaded guessing_game v0.1.0 to registry `crates-io`
note: waiting for `guessing_game v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published guessing_game v0.1.0 at registry `crates-io`
Chúc mừng! Bây giờ bạn đã chia sẻ mã của mình với cộng đồng Rust, và bất kỳ ai cũng có thể dễ dàng thêm crate của bạn làm phụ thuộc của dự án của họ.
Xuất bản Một Phiên bản Mới của Crate Hiện có
Khi bạn đã thực hiện các thay đổi đối với crate của mình và sẵn sàng phát hành
một phiên bản mới, bạn thay đổi giá trị version được chỉ định trong tệp
Cargo.toml của bạn và xuất bản lại. Sử dụng các quy tắc Semantic
Versioning để quyết định một số phiên bản tiếp theo phù hợp dựa trên
các loại thay đổi bạn đã thực hiện. Sau đó chạy cargo publish để tải lên phiên
bản mới.
Không dùng nữa Các Phiên bản từ Crates.io với cargo yank
Mặc dù bạn không thể xóa các phiên bản trước đó của một crate, bạn có thể ngăn bất kỳ dự án tương lai nào thêm chúng làm phụ thuộc mới. Điều này hữu ích khi một phiên bản crate bị lỗi vì lý do nào đó. Trong những tình huống như vậy, Cargo hỗ trợ yanking (rút lại) một phiên bản crate.
Yanking một phiên bản ngăn các dự án mới phụ thuộc vào phiên bản đó trong khi cho phép tất cả các dự án hiện có phụ thuộc vào nó tiếp tục. Về cơ bản, rút lại có nghĩa là tất cả các dự án với Cargo.lock sẽ không bị hỏng, và bất kỳ tệp Cargo.lock nào được tạo ra trong tương lai sẽ không sử dụng phiên bản đã bị rút lại.
Để rút lại một phiên bản của crate, trong thư mục của crate mà bạn đã xuất bản
trước đó, chạy cargo yank và chỉ định phiên bản bạn muốn rút lại. Ví dụ, nếu
chúng ta đã xuất bản một crate có tên guessing_game phiên bản 1.0.1 và chúng
ta muốn rút lại nó, trong thư mục dự án cho guessing_game chúng ta sẽ chạy:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
Bằng cách thêm --undo vào lệnh, bạn cũng có thể hoàn tác việc rút lại và cho
phép các dự án bắt đầu phụ thuộc vào một phiên bản một lần nữa:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
Việc rút lại không xóa bất kỳ mã nào. Ví dụ, nó không thể xóa các bí mật vô tình được tải lên. Nếu điều đó xảy ra, bạn phải đặt lại các bí mật đó ngay lập tức.
Không gian làm việc Cargo
Trong Chương 12, chúng ta đã xây dựng một gói bao gồm một crate nhị phân và một crate thư viện. Khi dự án của bạn phát triển, bạn có thể thấy rằng crate thư viện tiếp tục trở nên lớn hơn và bạn muốn chia gói của mình thành nhiều crate thư viện hơn. Cargo cung cấp một tính năng gọi là workspaces (không gian làm việc) có thể giúp quản lý nhiều gói liên quan được phát triển cùng nhau.
Tạo một Workspace
Một workspace là một tập hợp các gói chia sẻ cùng một Cargo.lock và thư mục
đầu ra. Hãy tạo một dự án sử dụng workspace—chúng ta sẽ sử dụng mã đơn giản để
có thể tập trung vào cấu trúc của workspace. Có nhiều cách để cấu trúc một
workspace, vì vậy chúng ta sẽ chỉ trình bày một cách phổ biến. Chúng ta sẽ có
một workspace chứa một crate nhị phân và hai crate thư viện. Crate nhị phân,
cung cấp chức năng chính, sẽ phụ thuộc vào hai thư viện. Một thư viện sẽ cung
cấp hàm add_one và thư viện khác cung cấp hàm add_two. Ba crate này sẽ là
một phần của cùng một workspace. Chúng ta sẽ bắt đầu bằng cách tạo một thư mục
mới cho workspace:
$ mkdir add
$ cd add
Tiếp theo, trong thư mục add, chúng ta tạo tệp Cargo.toml sẽ cấu hình toàn
bộ workspace. Tệp này sẽ không có phần [package]. Thay vào đó, nó sẽ bắt đầu
với phần [workspace] cho phép chúng ta thêm thành viên vào workspace. Chúng ta
cũng lưu ý sử dụng phiên bản mới nhất và tốt nhất của thuật toán resolver của
Cargo trong workspace của chúng ta bằng cách đặt giá trị resolver thành "3".
Tên tệp: Cargo.toml
[workspace]
resolver = "3"
Tiếp theo, chúng ta sẽ tạo crate nhị phân adder bằng cách chạy cargo new
trong thư mục add:
$ cargo new adder
Created binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
Chạy cargo new bên trong một workspace cũng tự động thêm gói mới tạo vào khóa
members trong định nghĩa [workspace] trong Cargo.toml của workspace, như
thế này:
[workspace]
resolver = "3"
members = ["adder"]
Tại thời điểm này, chúng ta có thể xây dựng workspace bằng cách chạy
cargo build. Các tệp trong thư mục add của bạn sẽ trông như thế này:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Workspace có một thư mục target ở cấp cao nhất nơi các sản phẩm biên dịch sẽ
được đặt vào; gói adder không có thư mục target riêng. Ngay cả khi chúng ta
chạy cargo build từ bên trong thư mục adder, các sản phẩm biên dịch vẫn sẽ
kết thúc trong add/target thay vì add/adder/target. Cargo cấu trúc thư mục
target trong một workspace như thế này vì các crate trong một workspace được
thiết kế để phụ thuộc vào nhau. Nếu mỗi crate có thư mục target riêng, mỗi
crate sẽ phải biên dịch lại từng crate khác trong workspace để đặt các sản phẩm
vào thư mục target riêng của nó. Bằng cách chia sẻ một thư mục target, các
crate có thể tránh việc xây dựng lại không cần thiết.
Tạo Gói Thứ Hai trong Workspace
Tiếp theo, hãy tạo một gói thành viên khác trong workspace và gọi nó là
add_one. Tạo một crate thư viện mới có tên add_one:
$ cargo new add_one --lib
Created library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
Cargo.toml cấp cao nhất sẽ bao gồm đường dẫn add_one trong danh sách
members:
Tên tệp: Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
Thư mục add của bạn bây giờ sẽ có các thư mục và tệp này:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Trong tệp add_one/src/lib.rs, hãy thêm một hàm add_one:
Tên tệp: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}Bây giờ chúng ta có thể để gói adder với chương trình nhị phân của chúng ta
phụ thuộc vào gói add_one chứa thư viện của chúng ta. Trước tiên, chúng ta sẽ
cần thêm một phụ thuộc đường dẫn vào add_one trong adder/Cargo.toml.
Tên tệp: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo không giả định rằng các crate trong một workspace sẽ phụ thuộc vào nhau, vì vậy chúng ta cần chỉ định rõ ràng mối quan hệ phụ thuộc.
Tiếp theo, hãy sử dụng hàm add_one (từ crate add_one) trong crate adder.
Mở tệp adder/src/main.rs và thay đổi hàm main để gọi hàm add_one, như
trong Listing 14-7.
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}Hãy xây dựng workspace bằng cách chạy cargo build trong thư mục add cấp cao
nhất!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Để chạy crate nhị phân từ thư mục add, chúng ta có thể chỉ định gói nào trong
workspace chúng ta muốn chạy bằng cách sử dụng đối số -p và tên gói với
cargo run:
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
Điều này chạy mã trong adder/src/main.rs, mã này phụ thuộc vào crate
add_one.
Phụ thuộc vào một Gói Bên ngoài trong một Workspace
Lưu ý rằng workspace chỉ có một tệp Cargo.lock ở cấp cao nhất, thay vì có
Cargo.lock trong thư mục của mỗi crate. Điều này đảm bảo rằng tất cả các crate
đều sử dụng cùng phiên bản của tất cả các phụ thuộc. Nếu chúng ta thêm gói
rand vào tệp adder/Cargo.toml và add_one/Cargo.toml, Cargo sẽ giải quyết
cả hai gói này thành một phiên bản của rand và ghi lại trong Cargo.lock duy
nhất. Việc làm cho tất cả các crate trong workspace sử dụng cùng các phụ thuộc
có nghĩa là các crate sẽ luôn tương thích với nhau. Hãy thêm crate rand vào
phần [dependencies] trong tệp add_one/Cargo.toml để chúng ta có thể sử dụng
crate rand trong crate add_one:
Tên tệp: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
Bây giờ chúng ta có thể thêm use rand; vào tệp add_one/src/lib.rs, và việc
xây dựng toàn bộ workspace bằng cách chạy cargo build trong thư mục add sẽ
mang rand crate vào và biên dịch nó. Chúng ta sẽ nhận được một cảnh báo vì
chúng ta không tham chiếu đến rand mà chúng ta đã đưa vào phạm vi:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Cargo.lock cấp cao nhất bây giờ chứa thông tin về phụ thuộc của add_one vào
rand. Tuy nhiên, mặc dù rand được sử dụng ở đâu đó trong workspace, chúng ta
không thể sử dụng nó trong các crate khác trong workspace trừ khi chúng ta thêm
rand vào tệp Cargo.toml của họ. Ví dụ: nếu chúng ta thêm use rand; vào tệp
adder/src/main.rs cho gói adder, chúng ta sẽ nhận được lỗi:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Để sửa điều này, hãy chỉnh sửa tệp Cargo.toml cho gói adder và chỉ ra rằng
rand cũng là một phụ thuộc cho nó. Việc xây dựng gói adder sẽ thêm rand
vào danh sách phụ thuộc cho adder trong Cargo.lock, nhưng không có bản sao
bổ sung nào của rand sẽ được tải xuống. Cargo sẽ đảm bảo rằng mọi crate trong
mọi gói trong workspace sử dụng gói rand sẽ sử dụng cùng một phiên bản miễn là
họ chỉ định các phiên bản tương thích của rand, tiết kiệm không gian cho chúng
ta và đảm bảo rằng các crate trong workspace sẽ tương thích với nhau.
Nếu các crate trong workspace chỉ định các phiên bản không tương thích của cùng một phụ thuộc, Cargo sẽ giải quyết từng crate, nhưng vẫn cố gắng giải quyết càng ít phiên bản càng tốt.
Thêm một Bài Kiểm thử vào Workspace
Để một cải tiến khác, hãy thêm một bài kiểm thử cho hàm add_one::add_one trong
crate add_one:
Tên tệp: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Bây giờ chạy cargo test trong thư mục add cấp cao nhất. Chạy cargo test
trong một workspace có cấu trúc như thế này sẽ chạy các bài kiểm thử cho tất cả
các crate trong workspace:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Phần đầu tiên của đầu ra cho thấy bài kiểm thử it_works trong crate add_one
đã thành công. Phần tiếp theo cho thấy không tìm thấy bài kiểm thử nào trong
crate adder, và sau đó phần cuối cùng cho thấy không tìm thấy bài kiểm thử tài
liệu nào trong crate add_one.
Chúng ta cũng có thể chạy các bài kiểm thử cho một crate cụ thể trong workspace
từ thư mục cấp cao nhất bằng cách sử dụng cờ -p và chỉ định tên của crate mà
chúng ta muốn kiểm thử:
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Đầu ra này hiển thị cargo test chỉ chạy các bài kiểm thử cho crate add_one
và không chạy các bài kiểm thử crate adder.
Nếu bạn xuất bản các crate trong workspace lên
crates.io, mỗi crate trong workspace sẽ cần
được xuất bản riêng. Giống như cargo test, chúng ta có thể xuất bản một crate
cụ thể trong workspace của chúng ta bằng cách sử dụng cờ -p và chỉ định tên
của crate mà chúng ta muốn xuất bản.
Để thực hành thêm, hãy thêm một crate add_two vào workspace này theo cách
tương tự như crate add_one!
Khi dự án của bạn phát triển, hãy cân nhắc sử dụng một workspace: nó cho phép bạn làm việc với các thành phần nhỏ hơn, dễ hiểu hơn so với một đống mã lớn. Hơn nữa, việc giữ các crate trong một workspace có thể làm cho việc phối hợp giữa các crate dễ dàng hơn nếu chúng thường xuyên thay đổi cùng một lúc.
Cài đặt Tệp Nhị phân với cargo install
Lệnh cargo install cho phép bạn cài đặt và sử dụng các crate nhị phân một cách
cục bộ. Điều này không nhằm mục đích thay thế các gói hệ thống; nó được thiết kế
để cung cấp một cách thuận tiện cho các nhà phát triển Rust cài đặt các công cụ
mà người khác đã chia sẻ trên crates.io.
Lưu ý rằng bạn chỉ có thể cài đặt các gói có mục tiêu nhị phân. Một mục tiêu
nhị phân là chương trình có thể chạy được tạo ra nếu crate có tệp src/main.rs
hoặc một tệp khác được chỉ định là tệp nhị phân, khác với mục tiêu thư viện
không thể chạy độc lập nhưng phù hợp để bao gồm trong các chương trình khác.
Thông thường, các crate có thông tin trong tệp README về việc liệu một crate
là thư viện, có mục tiêu nhị phân, hoặc cả hai.
Tất cả các tệp nhị phân được cài đặt với cargo install được lưu trữ trong thư
mục bin của thư mục gốc cài đặt. Nếu bạn đã cài đặt Rust bằng rustup.rs và
không có bất kỳ cấu hình tùy chỉnh nào, thư mục này sẽ là $HOME/.cargo/bin.
Đảm bảo rằng thư mục đó nằm trong $PATH của bạn để có thể chạy các chương
trình bạn đã cài đặt với cargo install.
Ví dụ, trong Chương 12 chúng ta đã đề cập rằng có một triển khai Rust của công
cụ grep gọi là ripgrep để tìm kiếm tệp. Để cài đặt ripgrep, chúng ta có
thể chạy như sau:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
Dòng áp chót của đầu ra hiển thị vị trí và tên của tệp nhị phân đã cài đặt,
trong trường hợp của ripgrep là rg. Miễn là thư mục cài đặt nằm trong
$PATH của bạn, như đã đề cập trước đó, bạn có thể chạy rg --help và bắt đầu
sử dụng một công cụ nhanh hơn, "Rust hơn" để tìm kiếm tệp!
Mở rộng Cargo với Lệnh Tùy chỉnh
Cargo được thiết kế để bạn có thể mở rộng nó với các lệnh phụ mới mà không cần
phải sửa đổi nó. Nếu một tệp nhị phân trong $PATH của bạn có tên là
cargo-something, bạn có thể chạy nó như thể nó là một lệnh phụ của Cargo bằng
cách chạy cargo something. Các lệnh tùy chỉnh như thế này cũng được liệt kê
khi bạn chạy cargo --list. Khả năng sử dụng cargo install để cài đặt các
phần mở rộng và sau đó chạy chúng giống như các công cụ Cargo tích hợp là một
lợi ích cực kỳ thuận tiện từ thiết kế của Cargo!
Tóm tắt
Chia sẻ mã với Cargo và crates.io là một phần làm cho hệ sinh thái Rust hữu ích cho nhiều tác vụ khác nhau. Thư viện chuẩn của Rust nhỏ gọn và ổn định, nhưng các crate dễ dàng được chia sẻ, sử dụng và cải tiến theo một tiến độ khác với ngôn ngữ. Đừng ngần ngại chia sẻ mã hữu ích cho bạn trên crates.io; rất có thể nó cũng sẽ hữu ích cho người khác!
Con trỏ Thông minh
Một con trỏ là một khái niệm chung cho một biến chứa một địa chỉ trong bộ nhớ.
Địa chỉ này tham chiếu tới, hoặc "trỏ tới," một số dữ liệu khác. Loại con trỏ
phổ biến nhất trong Rust là tham chiếu, mà bạn đã học trong Chương 4. Tham chiếu
được biểu thị bằng ký hiệu & và mượn giá trị mà chúng trỏ tới. Chúng không có
bất kỳ khả năng đặc biệt nào ngoài việc tham chiếu đến dữ liệu, và chúng không
có chi phí phụ.
Con trỏ thông minh, mặt khác, là các cấu trúc dữ liệu hoạt động như một con trỏ nhưng cũng có thêm siêu dữ liệu và khả năng. Khái niệm về con trỏ thông minh không phải là duy nhất trong Rust: con trỏ thông minh bắt nguồn từ C++ và cũng tồn tại trong các ngôn ngữ khác. Rust có nhiều loại con trỏ thông minh khác nhau được định nghĩa trong thư viện chuẩn cung cấp chức năng vượt xa so với tham chiếu. Để khám phá khái niệm chung, chúng ta sẽ xem xét một vài ví dụ khác nhau về con trỏ thông minh, bao gồm một kiểu con trỏ thông minh đếm tham chiếu. Con trỏ này cho phép bạn cho phép dữ liệu có nhiều chủ sở hữu bằng cách theo dõi số lượng chủ sở hữu và, khi không còn chủ sở hữu nào, dọn dẹp dữ liệu.
Rust, với khái niệm về quyền sở hữu và mượn, có một điểm khác biệt bổ sung giữa tham chiếu và con trỏ thông minh: trong khi tham chiếu chỉ mượn dữ liệu, trong nhiều trường hợp con trỏ thông minh sở hữu dữ liệu mà chúng trỏ tới.
Con trỏ thông minh thường được triển khai bằng cách sử dụng structs. Không giống
như một struct thông thường, con trỏ thông minh triển khai các trait Deref và
Drop. Trait Deref cho phép một thể hiện của struct con trỏ thông minh hoạt
động như một tham chiếu để bạn có thể viết mã của mình để làm việc với cả tham
chiếu hoặc con trỏ thông minh. Trait Drop cho phép bạn tùy chỉnh mã được chạy
khi một thể hiện của con trỏ thông minh ra khỏi phạm vi. Trong chương này, chúng
ta sẽ thảo luận cả hai trait này và minh họa tại sao chúng quan trọng đối với
con trỏ thông minh.
Do mẫu con trỏ thông minh là một mẫu thiết kế chung được sử dụng thường xuyên trong Rust, chương này sẽ không đề cập đến mọi con trỏ thông minh hiện có. Nhiều thư viện có con trỏ thông minh riêng, và bạn thậm chí có thể tự viết. Chúng ta sẽ đề cập đến những con trỏ thông minh phổ biến nhất trong thư viện chuẩn:
Box<T>, để phân bổ giá trị trên heapRc<T>, một kiểu đếm tham chiếu cho phép nhiều quyền sở hữuRef<T>vàRefMut<T>, được truy cập thông quaRefCell<T>, một kiểu thực thi quy tắc mượn tại thời điểm chạy thay vì thời điểm biên dịch
Ngoài ra, chúng ta sẽ đề cập đến mẫu tính thay đổi nội bộ nơi một kiểu không thể thay đổi hiển thị một API để thay đổi một giá trị bên trong. Chúng ta cũng sẽ thảo luận về chu kỳ tham chiếu: cách chúng có thể rò rỉ bộ nhớ và cách ngăn chặn chúng.
Hãy bắt đầu!
Sử dụng Box<T> để Trỏ đến Dữ liệu trên Heap
Con trỏ thông minh đơn giản nhất là một box, có kiểu được viết là Box<T>.
Box cho phép bạn lưu trữ dữ liệu trên heap thay vì stack. Những gì còn lại
trên stack là con trỏ đến dữ liệu heap. Xem lại Chương 4 để ôn lại sự khác biệt
giữa stack và heap.
Box không tạo ra chi phí hiệu suất, ngoại trừ việc lưu trữ dữ liệu của chúng trên heap thay vì trên stack. Nhưng chúng cũng không có nhiều khả năng bổ sung. Bạn sẽ sử dụng chúng thường xuyên nhất trong những tình huống sau:
- Khi bạn có một kiểu mà kích thước không thể biết được tại thời điểm biên dịch và bạn muốn sử dụng một giá trị của kiểu đó trong một ngữ cảnh yêu cầu kích thước chính xác
- Khi bạn có một lượng lớn dữ liệu và bạn muốn chuyển quyền sở hữu nhưng đảm bảo dữ liệu sẽ không bị sao chép khi làm như vậy
- Khi bạn muốn sở hữu một giá trị và bạn chỉ quan tâm rằng nó là một kiểu triển khai một trait cụ thể thay vì thuộc về một kiểu cụ thể
Chúng ta sẽ minh họa tình huống đầu tiên trong "Cho phép Kiểu Đệ quy với Boxes". Trong trường hợp thứ hai, việc chuyển quyền sở hữu của một lượng lớn dữ liệu có thể mất nhiều thời gian vì dữ liệu được sao chép trên stack. Để cải thiện hiệu suất trong tình huống này, chúng ta có thể lưu trữ lượng lớn dữ liệu trên heap trong một box. Sau đó, chỉ có một lượng nhỏ dữ liệu con trỏ được sao chép trên stack, trong khi dữ liệu mà nó tham chiếu vẫn ở một vị trí trên heap. Trường hợp thứ ba được gọi là đối tượng trait, và "Sử dụng Đối tượng Trait Cho phép Các Giá trị Có Kiểu Khác nhau," trong Chương 18 được dành cho chủ đề đó. Vì vậy, những gì bạn học ở đây sẽ áp dụng lại trong phần đó!
Sử dụng Box<T> để Lưu trữ Dữ liệu trên Heap
Trước khi chúng ta thảo luận về trường hợp sử dụng lưu trữ heap cho Box<T>,
chúng ta sẽ đề cập đến cú pháp và cách tương tác với các giá trị được lưu trữ
trong một Box<T>.
Listing 15-1 cho thấy cách sử dụng box để lưu trữ một giá trị i32 trên heap.
fn main() { let b = Box::new(5); println!("b = {b}"); }
Chúng ta định nghĩa biến b có giá trị là một Box trỏ đến giá trị 5, được
cấp phát trên heap. Chương trình này sẽ in ra b = 5; trong trường hợp này,
chúng ta có thể truy cập dữ liệu trong box tương tự như cách chúng ta sẽ làm nếu
dữ liệu này nằm trên stack. Giống như bất kỳ giá trị sở hữu nào, khi một box ra
khỏi phạm vi, như b ở cuối main, nó sẽ bị giải phóng. Việc giải phóng diễn
ra cả cho box (được lưu trữ trên stack) và dữ liệu mà nó trỏ đến (được lưu trữ
trên heap).
Đặt một giá trị đơn lẻ trên heap không quá hữu ích, vì vậy bạn sẽ không thường
xuyên sử dụng box theo cách này. Có các giá trị như một i32 đơn lẻ trên stack,
nơi chúng được lưu trữ theo mặc định, thích hợp hơn trong đa số trường hợp. Hãy
xem xét một trường hợp trong đó box cho phép chúng ta định nghĩa các kiểu mà
chúng ta không được phép định nghĩa nếu không có box.
Cho phép Kiểu Đệ quy với Boxes
Một giá trị của kiểu đệ quy có thể có một giá trị khác của cùng kiểu như một phần của chính nó. Kiểu đệ quy gây ra vấn đề vì Rust cần biết tại thời điểm biên dịch kiểu chiếm bao nhiêu không gian. Tuy nhiên, việc lồng các giá trị của kiểu đệ quy về mặt lý thuyết có thể tiếp tục vô hạn, vì vậy Rust không thể biết giá trị cần bao nhiêu không gian. Vì box có kích thước đã biết, chúng ta có thể cho phép kiểu đệ quy bằng cách chèn một box vào định nghĩa kiểu đệ quy.
Ví dụ về một kiểu đệ quy, hãy khám phá cons list. Đây là một kiểu dữ liệu thường thấy trong các ngôn ngữ lập trình hàm. Kiểu cons list mà chúng ta sẽ định nghĩa khá đơn giản ngoại trừ phần đệ quy; do đó, các khái niệm trong ví dụ chúng ta sẽ làm việc sẽ hữu ích bất cứ khi nào bạn gặp phải các tình huống phức tạp hơn liên quan đến kiểu đệ quy.
Thêm Thông tin về Cons List
Một cons list là một cấu trúc dữ liệu xuất phát từ ngôn ngữ lập trình Lisp và
các phương ngữ của nó, được tạo thành từ các cặp lồng nhau, và là phiên bản Lisp
của danh sách liên kết. Tên của nó xuất phát từ hàm cons (viết tắt của
construct function) trong Lisp xây dựng một cặp mới từ hai đối số của nó. Bằng
cách gọi cons trên một cặp bao gồm một giá trị và một cặp khác, chúng ta có
thể xây dựng các cons list được tạo thành từ các cặp đệ quy.
Ví dụ, đây là biểu diễn mã giả của một cons list chứa danh sách 1, 2, 3 với
mỗi cặp trong ngoặc đơn:
(1, (2, (3, Nil)))
Mỗi phần tử trong một cons list chứa hai thành phần: giá trị của phần tử hiện
tại và phần tử tiếp theo. Phần tử cuối cùng trong danh sách chỉ chứa một giá trị
gọi là Nil mà không có phần tử tiếp theo. Một cons list được tạo ra bằng cách
gọi đệ quy hàm cons. Tên quy ước để biểu thị trường hợp cơ sở của đệ quy là
Nil. Lưu ý rằng điều này không giống với khái niệm "null" hoặc "nil" được thảo
luận trong Chương 6, là một giá trị không hợp lệ hoặc vắng mặt.
Cons list không phải là cấu trúc dữ liệu thường được sử dụng trong Rust. Hầu hết
thời gian khi bạn có một danh sách các mục trong Rust, Vec<T> là một lựa chọn
tốt hơn để sử dụng. Các kiểu dữ liệu đệ quy phức tạp khác thực sự hữu ích
trong nhiều tình huống khác nhau, nhưng bằng cách bắt đầu với cons list trong
chương này, chúng ta có thể khám phá cách box cho phép chúng ta định nghĩa một
kiểu dữ liệu đệ quy mà không bị phân tâm quá nhiều.
Listing 15-2 chứa định nghĩa enum cho một cons list. Lưu ý rằng mã này sẽ chưa
biên dịch được vì kiểu List không có kích thước đã biết, điều này chúng ta sẽ
minh họa.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}Lưu ý: Chúng ta đang triển khai một cons list chỉ chứa các giá trị
i32cho mục đích của ví dụ này. Chúng ta có thể đã triển khai nó bằng cách sử dụng generics, như chúng ta đã thảo luận trong Chương 10, để định nghĩa một kiểu cons list có thể lưu trữ các giá trị của bất kỳ kiểu nào.
Sử dụng kiểu List để lưu trữ danh sách 1, 2, 3 sẽ trông giống như mã trong
Listing 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}Giá trị Cons đầu tiên chứa 1 và một giá trị List khác. Giá trị List này
là một giá trị Cons khác chứa 2 và một giá trị List khác. Giá trị List
này là một giá trị Cons nữa chứa 3 và một giá trị List, cuối cùng là
Nil, biến thể không đệ quy biểu thị kết thúc của danh sách.
Nếu chúng ta cố gắng biên dịch mã trong Listing 15-3, chúng ta sẽ gặp lỗi như trong Listing 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
Lỗi cho thấy kiểu này "có kích thước vô hạn." Lý do là chúng ta đã định nghĩa
List với một biến thể đệ quy: nó trực tiếp chứa một giá trị khác của chính nó.
Kết quả là, Rust không thể tìm ra cần bao nhiêu không gian để lưu trữ một giá
trị List. Hãy phân tích tại sao chúng ta gặp lỗi này. Đầu tiên, chúng ta sẽ
xem cách Rust quyết định cần bao nhiêu không gian để lưu trữ một giá trị của một
kiểu không đệ quy.
Tính toán Kích thước của một Kiểu Không Đệ quy
Nhớ lại enum Message mà chúng ta đã định nghĩa trong Listing 6-2 khi chúng ta
thảo luận về định nghĩa enum trong Chương 6:
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Để xác định bao nhiêu không gian để cấp phát cho một giá trị Message, Rust đi
qua từng biến thể để xem biến thể nào cần nhiều không gian nhất. Rust thấy rằng
Message::Quit không cần bất kỳ không gian nào, Message::Move cần đủ không
gian để lưu trữ hai giá trị i32, và vân vân. Vì chỉ một biến thể sẽ được sử
dụng, không gian nhiều nhất mà một giá trị Message sẽ cần là không gian cần
thiết để lưu trữ biến thể lớn nhất trong số các biến thể của nó.
Đối chiếu với điều xảy ra khi Rust cố gắng xác định bao nhiêu không gian mà một
kiểu đệ quy như enum List trong Listing 15-2 cần. Trình biên dịch bắt đầu bằng
cách nhìn vào biến thể Cons, biến thể này chứa một giá trị của kiểu i32 và
một giá trị của kiểu List. Do đó, Cons cần một lượng không gian bằng kích
thước của i32 cộng với kích thước của List. Để tìm ra bộ nhớ mà kiểu List
cần, trình biên dịch xem xét các biến thể, bắt đầu với biến thể Cons. Biến thể
Cons chứa một giá trị kiểu i32 và một giá trị kiểu List, và quá trình này
tiếp tục vô hạn, như được minh họa trong Hình 15-1.

Hình 15-1: Một List vô hạn bao gồm các biến thể Cons
vô hạn
Sử dụng Box<T> để Có được Kiểu Đệ quy với Kích thước Đã biết
Vì Rust không thể tìm ra bao nhiêu không gian để cấp phát cho các kiểu được định nghĩa đệ quy, trình biên dịch đưa ra một lỗi với gợi ý hữu ích này:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
Trong gợi ý này, sự gián tiếp có nghĩa là thay vì lưu trữ một giá trị trực tiếp, chúng ta nên thay đổi cấu trúc dữ liệu để lưu trữ giá trị gián tiếp bằng cách lưu trữ một con trỏ đến giá trị thay vì lưu trữ giá trị trực tiếp.
Vì Box<T> là một con trỏ, Rust luôn biết bao nhiêu không gian mà một Box<T>
cần: kích thước của một con trỏ không thay đổi dựa trên lượng dữ liệu mà nó trỏ
đến. Điều này có nghĩa là chúng ta có thể đặt một Box<T> bên trong biến thể
Cons thay vì một giá trị List trực tiếp. Box<T> sẽ trỏ đến giá trị List
tiếp theo sẽ nằm trên heap thay vì bên trong biến thể Cons. Về mặt khái niệm,
chúng ta vẫn có một danh sách, được tạo ra với các danh sách chứa các danh sách
khác, nhưng việc triển khai này bây giờ giống như đặt các mục cạnh nhau thay vì
bên trong nhau.
Chúng ta có thể thay đổi định nghĩa của enum List trong Listing 15-2 và cách
sử dụng List trong Listing 15-3 thành mã trong Listing 15-5, mã này sẽ biên
dịch được.
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
Biến thể Cons cần kích thước của một i32 cộng với không gian để lưu trữ dữ
liệu con trỏ của box. Biến thể Nil không lưu trữ giá trị nào, nên nó cần ít
không gian trên stack hơn biến thể Cons. Bây giờ chúng ta biết rằng bất kỳ giá
trị List nào sẽ chiếm kích thước của một i32 cộng với kích thước của dữ liệu
con trỏ của box. Bằng cách sử dụng box, chúng ta đã phá vỡ chuỗi đệ quy vô hạn,
vì vậy trình biên dịch có thể tìm ra kích thước cần thiết để lưu trữ một giá trị
List. Hình 15-2 cho thấy biến thể Cons trông như thế nào bây giờ.

Hình 15-2: Một List không có kích thước vô hạn vì Cons
chứa một Box
Box chỉ cung cấp sự gián tiếp và cấp phát heap; chúng không có bất kỳ khả năng đặc biệt nào khác, như những gì chúng ta sẽ thấy với các kiểu con trỏ thông minh khác. Chúng cũng không có chi phí hiệu suất mà các khả năng đặc biệt này gây ra, vì vậy chúng có thể hữu ích trong các trường hợp như cons list, nơi sự gián tiếp là tính năng duy nhất chúng ta cần. Chúng ta sẽ xem xét thêm các trường hợp sử dụng cho box trong Chương 18.
Kiểu Box<T> là một con trỏ thông minh vì nó triển khai trait Deref, cho phép
các giá trị Box<T> được xử lý như tham chiếu. Khi một giá trị Box<T> ra khỏi
phạm vi, dữ liệu heap mà box đang trỏ đến cũng được dọn dẹp nhờ vào việc triển
khai trait Drop. Hai trait này sẽ càng quan trọng hơn đối với chức năng được
cung cấp bởi các kiểu con trỏ thông minh khác mà chúng ta sẽ thảo luận trong
phần còn lại của chương này. Hãy khám phá hai trait này chi tiết hơn.
Xử lý Con trỏ Thông minh Như Tham chiếu Thông thường với Deref
Việc triển khai trait Deref cho phép bạn tùy chỉnh hành vi của toán tử giải
tham chiếu * (không nên nhầm lẫn với toán tử nhân hoặc toán tử glob). Bằng
cách triển khai Deref theo cách mà một con trỏ thông minh có thể được xử lý
như một tham chiếu thông thường, bạn có thể viết mã hoạt động trên tham chiếu và
sử dụng mã đó với con trỏ thông minh.
Đầu tiên, hãy xem cách toán tử giải tham chiếu hoạt động với tham chiếu thông
thường. Sau đó, chúng ta sẽ thử định nghĩa một kiểu tùy chỉnh hoạt động giống
như Box<T>, và xem tại sao toán tử giải tham chiếu không hoạt động như một
tham chiếu trên kiểu mới định nghĩa của chúng ta. Chúng ta sẽ khám phá cách
triển khai trait Deref khiến con trỏ thông minh có thể hoạt động tương tự như
tham chiếu. Sau đó, chúng ta sẽ xem tính năng chuyển đổi giải tham chiếu
(deref coercion) của Rust và cách nó cho phép chúng ta làm việc với cả tham
chiếu hoặc con trỏ thông minh.
Lưu ý: Có một sự khác biệt lớn giữa kiểu
MyBox<T>mà chúng ta sắp xây dựng vàBox<T>thực tế: phiên bản của chúng ta sẽ không lưu trữ dữ liệu trên heap. Chúng ta đang tập trung ví dụ này vàoDeref, vì vậy nơi dữ liệu thực sự được lưu trữ ít quan trọng hơn hành vi giống con trỏ.
Theo dõi Tham chiếu đến Giá trị
Một tham chiếu thông thường là một loại con trỏ, và một cách để nghĩ về con trỏ
là như một mũi tên đến một giá trị được lưu trữ ở đâu đó. Trong Listing 15-6,
chúng ta tạo một tham chiếu đến một giá trị i32 và sau đó sử dụng toán tử giải
tham chiếu để theo dõi tham chiếu đến giá trị.
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
Biến x chứa một giá trị i32 là 5. Chúng ta đặt y bằng một tham chiếu đến
x. Chúng ta có thể khẳng định rằng x bằng 5. Tuy nhiên, nếu chúng ta muốn
khẳng định về giá trị trong y, chúng ta phải sử dụng *y để theo dõi tham
chiếu đến giá trị mà nó đang trỏ tới (do đó giải tham chiếu) để trình biên
dịch có thể so sánh giá trị thực. Một khi chúng ta giải tham chiếu y, chúng ta
có quyền truy cập vào giá trị số nguyên mà y đang trỏ tới mà chúng ta có thể
so sánh với 5.
Nếu chúng ta cố gắng viết assert_eq!(5, y); thay vào đó, chúng ta sẽ nhận được
lỗi biên dịch này:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
So sánh một số và một tham chiếu đến một số không được phép vì chúng là các kiểu khác nhau. Chúng ta phải sử dụng toán tử giải tham chiếu để theo dõi tham chiếu đến giá trị mà nó đang trỏ tới.
Sử dụng Box<T> Như một Tham chiếu
Chúng ta có thể viết lại mã trong Listing 15-6 để sử dụng Box<T> thay vì một
tham chiếu; toán tử giải tham chiếu được sử dụng trên Box<T> trong Listing
15-7 hoạt động theo cùng một cách như toán tử giải tham chiếu được sử dụng trên
tham chiếu trong Listing 15-6:
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Sự khác biệt chính giữa Listing 15-7 và Listing 15-6 là ở đây chúng ta đặt y
là một thực thể của một box trỏ đến một giá trị sao chép của x thay vì một
tham chiếu trỏ đến giá trị của x. Trong khẳng định cuối cùng, chúng ta có thể
sử dụng toán tử giải tham chiếu để theo dõi con trỏ của box theo cách tương tự
như khi y là một tham chiếu. Tiếp theo, chúng ta sẽ khám phá điều gì đặc biệt
về Box<T> cho phép chúng ta sử dụng toán tử giải tham chiếu bằng cách định
nghĩa kiểu của riêng chúng ta.
Định nghĩa Con trỏ Thông minh Riêng của Chúng ta
Hãy xây dựng một con trỏ thông minh tương tự như kiểu Box<T> được cung cấp bởi
thư viện chuẩn để trải nghiệm cách con trỏ thông minh hoạt động khác với tham
chiếu theo mặc định. Sau đó, chúng ta sẽ xem cách thêm khả năng sử dụng toán tử
giải tham chiếu.
Kiểu Box<T> cuối cùng được định nghĩa như một tuple struct với một phần tử, vì
vậy Listing 15-8 định nghĩa một kiểu MyBox<T> theo cách tương tự. Chúng ta
cũng sẽ định nghĩa một hàm new để phù hợp với hàm new được định nghĩa trên
Box<T>.
struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() {}
Chúng ta định nghĩa một struct có tên MyBox và khai báo một tham số generic
T vì chúng ta muốn kiểu của chúng ta giữ các giá trị của bất kỳ kiểu nào. Kiểu
MyBox là một tuple struct với một phần tử kiểu T. Hàm MyBox::new nhận một
tham số kiểu T và trả về một thực thể MyBox chứa giá trị được truyền vào.
Hãy thử thêm hàm main trong Listing 15-7 vào Listing 15-8 và thay đổi nó để sử
dụng kiểu MyBox<T> mà chúng ta đã định nghĩa thay vì Box<T>. Mã trong
Listing 15-9 sẽ không biên dịch vì Rust không biết cách giải tham chiếu MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Đây là lỗi biên dịch kết quả:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Kiểu MyBox<T> của chúng ta không thể được giải tham chiếu vì chúng ta chưa
triển khai khả năng đó trên kiểu của chúng ta. Để kích hoạt giải tham chiếu với
toán tử *, chúng ta triển khai trait Deref.
Triển khai Trait Deref
Như đã thảo luận trong "Triển khai một Trait trên một
Kiểu" trong Chương 10, để triển khai một trait,
chúng ta cần cung cấp các triển khai cho các phương thức yêu cầu của trait.
Trait Deref, được cung cấp bởi thư viện chuẩn, yêu cầu chúng ta triển khai một
phương thức có tên deref mượn self và trả về một tham chiếu đến dữ liệu bên
trong. Listing 15-10 chứa một triển khai của Deref để thêm vào định nghĩa của
MyBox<T>.
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Cú pháp type Target = T; định nghĩa một kiểu liên kết cho trait Deref để sử
dụng. Kiểu liên kết là một cách khác để khai báo một tham số generic, nhưng bạn
không cần phải lo lắng về chúng bây giờ; chúng ta sẽ đề cập đến chúng chi tiết
hơn trong Chương 20.
Chúng ta điền vào thân của phương thức deref với &self.0 để deref trả về
một tham chiếu đến giá trị mà chúng ta muốn truy cập với toán tử *; nhớ lại từ
"Sử dụng Tuple Structs Không Có Trường Có Tên để Tạo Các Kiểu Khác
nhau" trong Chương 5 rằng .0 truy cập giá trị
đầu tiên trong một tuple struct. Hàm main trong Listing 15-9 gọi * trên giá
trị MyBox<T> bây giờ biên dịch được, và các khẳng định đều thành công!
Không có trait Deref, trình biên dịch chỉ có thể giải tham chiếu tham chiếu
&. Phương thức deref cung cấp cho trình biên dịch khả năng lấy một giá trị
của bất kỳ kiểu nào triển khai Deref và gọi phương thức deref để lấy tham
chiếu & mà nó biết cách giải tham chiếu.
Khi chúng ta nhập *y trong Listing 15-9, đằng sau hậu trường Rust thực sự chạy
mã này:
*(y.deref())Rust thay thế toán tử * bằng một lệnh gọi đến phương thức deref và sau đó là
một giải tham chiếu thông thường để chúng ta không phải suy nghĩ về việc liệu
chúng ta có cần gọi phương thức deref hay không. Tính năng Rust này cho phép
chúng ta viết mã hoạt động giống hệt nhau dù chúng ta có một tham chiếu thông
thường hay một kiểu triển khai Deref.
Lý do phương thức deref trả về một tham chiếu đến một giá trị, và giải tham
chiếu thông thường bên ngoài dấu ngoặc đơn trong *(y.deref()) vẫn cần thiết,
liên quan đến hệ thống sở hữu. Nếu phương thức deref trả về giá trị trực tiếp
thay vì một tham chiếu đến giá trị, giá trị sẽ bị di chuyển ra khỏi self.
Chúng ta không muốn lấy quyền sở hữu của giá trị bên trong MyBox<T> trong
trường hợp này hoặc trong hầu hết các trường hợp khi chúng ta sử dụng toán tử
giải tham chiếu.
Lưu ý rằng toán tử * được thay thế bằng một lệnh gọi đến phương thức deref
và sau đó là một lệnh gọi đến toán tử * chỉ một lần, mỗi lần chúng ta sử dụng
* trong mã của chúng ta. Vì sự thay thế của toán tử * không đệ quy vô hạn,
chúng ta kết thúc với dữ liệu kiểu i32, phù hợp với 5 trong assert_eq!
trong Listing 15-9.
Chuyển đổi Giải tham chiếu Ngầm với Hàm và Phương thức
Chuyển đổi giải tham chiếu (Deref coercion) chuyển đổi một tham chiếu đến một
kiểu triển khai trait Deref thành một tham chiếu đến một kiểu khác. Ví dụ,
chuyển đổi giải tham chiếu có thể chuyển đổi &String thành &str vì String
triển khai trait Deref sao cho nó trả về &str. Chuyển đổi giải tham chiếu là
một tiện ích Rust thực hiện trên các đối số cho hàm và phương thức, và chỉ hoạt
động trên các kiểu triển khai trait Deref. Nó xảy ra tự động khi chúng ta
truyền một tham chiếu đến giá trị của một kiểu cụ thể làm đối số cho một hàm
hoặc phương thức mà không khớp với kiểu tham số trong định nghĩa hàm hoặc phương
thức. Một chuỗi các lệnh gọi đến phương thức deref chuyển đổi kiểu chúng ta đã
cung cấp thành kiểu mà tham số cần.
Chuyển đổi giải tham chiếu được thêm vào Rust để các lập trình viên viết lệnh
gọi hàm và phương thức không cần thêm quá nhiều tham chiếu và giải tham chiếu rõ
ràng với & và *. Tính năng chuyển đổi giải tham chiếu cũng cho phép chúng ta
viết nhiều mã hơn có thể hoạt động cho cả tham chiếu hoặc con trỏ thông minh.
Để thấy chuyển đổi giải tham chiếu trong hành động, hãy sử dụng kiểu MyBox<T>
mà chúng ta đã định nghĩa trong Listing 15-8 cũng như triển khai của Deref mà
chúng ta đã thêm vào trong Listing 15-10. Listing 15-11 hiển thị định nghĩa của
một hàm có tham số là một lát chuỗi.
fn hello(name: &str) { println!("Hello, {name}!"); } fn main() {}
Chúng ta có thể gọi hàm hello với một lát chuỗi làm đối số, chẳng hạn như
hello("Rust");. Chuyển đổi giải tham chiếu làm cho việc gọi hello với một
tham chiếu đến một giá trị kiểu MyBox<String> trở nên khả thi, như trong
Listing 15-12.
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&m); }
Ở đây chúng ta đang gọi hàm hello với đối số &m, là một tham chiếu đến một
giá trị MyBox<String>. Vì chúng ta đã triển khai trait Deref trên MyBox<T>
trong Listing 15-10, Rust có thể chuyển đổi &MyBox<String> thành &String
bằng cách gọi deref. Thư viện chuẩn cung cấp một triển khai của Deref trên
String trả về một lát chuỗi, và điều này có trong tài liệu API cho Deref.
Rust gọi deref một lần nữa để chuyển đổi &String thành &str, khớp với định
nghĩa của hàm hello.
Nếu Rust không triển khai chuyển đổi giải tham chiếu, chúng ta sẽ phải viết mã
trong Listing 15-13 thay vì mã trong Listing 15-12 để gọi hello với một giá
trị kiểu &MyBox<String>.
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&(*m)[..]); }
(*m) giải tham chiếu MyBox<String> thành một String. Sau đó, & và [..]
lấy một lát chuỗi của String bằng với toàn bộ chuỗi để khớp với chữ ký của
hello. Mã này không có chuyển đổi giải tham chiếu khó đọc, viết và hiểu hơn
với tất cả các ký hiệu liên quan. Chuyển đổi giải tham chiếu cho phép Rust xử lý
các chuyển đổi này cho chúng ta tự động.
Khi trait Deref được định nghĩa cho các kiểu liên quan, Rust sẽ phân tích các
kiểu và sử dụng Deref::deref nhiều lần nếu cần để lấy một tham chiếu khớp với
kiểu của tham số. Số lần cần thiết để chèn Deref::deref được giải quyết tại
thời điểm biên dịch, vì vậy không có hình phạt thời gian chạy khi tận dụng lợi
thế của chuyển đổi giải tham chiếu!
Cách Chuyển đổi Giải tham chiếu Tương tác với Tính Thay đổi
Tương tự như cách bạn sử dụng trait Deref để ghi đè lên toán tử * trên tham
chiếu không thay đổi, bạn có thể sử dụng trait DerefMut để ghi đè lên toán tử
* trên tham chiếu có thể thay đổi.
Rust thực hiện chuyển đổi giải tham chiếu khi nó tìm thấy các kiểu và triển khai trait trong ba trường hợp:
- Từ
&Tđến&UkhiT: Deref<Target=U> - Từ
&mut Tđến&mut UkhiT: DerefMut<Target=U> - Từ
&mut Tđến&UkhiT: Deref<Target=U>
Hai trường hợp đầu tiên giống nhau ngoại trừ trường hợp thứ hai triển khai tính
thay đổi. Trường hợp đầu tiên nêu rằng nếu bạn có một &T, và T triển khai
Deref đến một kiểu U nào đó, bạn có thể nhận được một &U một cách trong
suốt. Trường hợp thứ hai nêu rằng sự chuyển đổi giải tham chiếu tương tự cũng
xảy ra cho tham chiếu có thể thay đổi.
Trường hợp thứ ba phức tạp hơn: Rust cũng sẽ chuyển đổi một tham chiếu có thể thay đổi thành một tham chiếu không thay đổi. Nhưng điều ngược lại không khả thi: tham chiếu không thay đổi sẽ không bao giờ chuyển đổi thành tham chiếu có thể thay đổi. Vì quy tắc mượn, nếu bạn có một tham chiếu có thể thay đổi, tham chiếu có thể thay đổi đó phải là tham chiếu duy nhất đến dữ liệu đó (nếu không, chương trình sẽ không biên dịch). Chuyển đổi một tham chiếu có thể thay đổi thành một tham chiếu không thay đổi sẽ không bao giờ phá vỡ quy tắc mượn. Chuyển đổi một tham chiếu không thay đổi thành một tham chiếu có thể thay đổi sẽ yêu cầu tham chiếu không thay đổi ban đầu là tham chiếu không thay đổi duy nhất đến dữ liệu đó, nhưng quy tắc mượn không đảm bảo điều đó. Do đó, Rust không thể đưa ra giả định rằng việc chuyển đổi một tham chiếu không thay đổi thành một tham chiếu có thể thay đổi là khả thi.
Chạy Mã khi Dọn dẹp với Trait Drop
Trait quan trọng thứ hai cho mẫu con trỏ thông minh là Drop, cho phép bạn tùy
chỉnh những gì xảy ra khi một giá trị sắp ra khỏi phạm vi. Bạn có thể cung cấp
một triển khai cho trait Drop trên bất kỳ kiểu nào, và mã đó có thể được sử
dụng để giải phóng tài nguyên như tệp hoặc kết nối mạng.
Chúng ta giới thiệu Drop trong ngữ cảnh của con trỏ thông minh vì chức năng
của trait Drop gần như luôn được sử dụng khi triển khai một con trỏ thông
minh. Ví dụ, khi một Box<T> bị hủy, nó sẽ giải phóng không gian trên heap mà
box trỏ tới.
Trong một số ngôn ngữ, đối với một số kiểu, lập trình viên phải gọi mã để giải phóng bộ nhớ hoặc tài nguyên mỗi khi họ sử dụng xong một thể hiện của những kiểu đó. Ví dụ bao gồm file handles, sockets và locks. Nếu họ quên, hệ thống có thể bị quá tải và gặp sự cố. Trong Rust, bạn có thể chỉ định một đoạn mã cụ thể được chạy bất cứ khi nào một giá trị ra khỏi phạm vi, và trình biên dịch sẽ tự động chèn mã này. Kết quả là, bạn không cần phải cẩn thận đặt mã dọn dẹp ở mọi nơi trong chương trình mà một thể hiện của một kiểu cụ thể đã hoàn thành—bạn vẫn sẽ không rò rỉ tài nguyên!
Bạn chỉ định mã để chạy khi một giá trị ra khỏi phạm vi bằng cách triển khai
trait Drop. Trait Drop yêu cầu bạn triển khai một phương thức có tên drop
nhận một tham chiếu có thể thay đổi tới self. Để xem khi nào Rust gọi drop,
hãy triển khai drop với các câu lệnh println! tạm thời.
Listing 15-14 hiển thị một struct CustomSmartPointer mà chức năng tùy chỉnh
duy nhất của nó là sẽ in Dropping CustomSmartPointer! khi thể hiện ra khỏi
phạm vi, để hiển thị khi Rust chạy phương thức drop.
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("my stuff"), }; let d = CustomSmartPointer { data: String::from("other stuff"), }; println!("CustomSmartPointers created"); }
Trait Drop được bao gồm trong prelude, vì vậy chúng ta không cần phải đưa nó
vào phạm vi. Chúng ta triển khai trait Drop trên CustomSmartPointer và cung
cấp một triển khai cho phương thức drop gọi println!. Phần thân của phương
thức drop là nơi bạn sẽ đặt bất kỳ logic nào mà bạn muốn chạy khi một thể hiện
của kiểu của bạn ra khỏi phạm vi. Chúng ta đang in một số văn bản ở đây để minh
họa trực quan khi Rust sẽ gọi drop.
Trong main, chúng ta tạo hai thể hiện của CustomSmartPointer và sau đó in
CustomSmartPointers created. Ở cuối main, các thể hiện của
CustomSmartPointer của chúng ta sẽ ra khỏi phạm vi, và Rust sẽ gọi mã mà chúng
ta đặt trong phương thức drop, in thông báo cuối cùng của chúng ta. Lưu ý rằng
chúng ta không cần phải gọi phương thức drop một cách rõ ràng.
Khi chúng ta chạy chương trình này, chúng ta sẽ thấy đầu ra sau:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust tự động gọi drop cho chúng ta khi các thể hiện của chúng ta ra khỏi phạm
vi, gọi mã mà chúng ta đã chỉ định. Các biến được hủy theo thứ tự ngược lại so
với việc tạo, vì vậy d đã bị hủy trước c. Mục đích của ví dụ này là cung cấp
cho bạn một hướng dẫn trực quan về cách phương thức drop hoạt động; thông
thường, bạn sẽ chỉ định mã dọn dẹp mà kiểu của bạn cần chạy thay vì một thông
báo in.
Không may, việc vô hiệu hóa chức năng drop tự động không đơn giản. Vô hiệu hóa
drop thường không cần thiết; toàn bộ ý nghĩa của trait Drop là nó được xử lý
tự động. Tuy nhiên, đôi khi bạn có thể muốn dọn dẹp một giá trị sớm. Một ví dụ
là khi sử dụng con trỏ thông minh quản lý khóa: bạn có thể muốn buộc phương thức
drop giải phóng khóa để mã khác trong cùng phạm vi có thể lấy khóa. Rust không
cho phép bạn gọi phương thức drop của trait Drop theo cách thủ công; thay
vào đó, bạn phải gọi hàm std::mem::drop được cung cấp bởi thư viện chuẩn nếu
bạn muốn buộc một giá trị bị hủy trước khi kết thúc phạm vi của nó.
Nếu chúng ta cố gắng gọi phương thức drop của trait Drop theo cách thủ công
bằng cách sửa đổi hàm main từ Listing 15-14, như trong Listing 15-15, chúng ta
sẽ gặp lỗi trình biên dịch.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}Khi chúng ta cố gắng biên dịch mã này, chúng ta sẽ gặp lỗi này:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Thông báo lỗi này nêu rõ rằng chúng ta không được phép gọi drop một cách rõ
ràng. Thông báo lỗi sử dụng thuật ngữ destructor, đó là thuật ngữ lập trình
chung cho một hàm dọn dẹp một thể hiện. Một destructor tương tự như một
constructor, tạo ra một thể hiện. Hàm drop trong Rust là một destructor cụ
thể.
Rust không cho phép chúng ta gọi drop một cách rõ ràng vì Rust vẫn sẽ tự động
gọi drop trên giá trị ở cuối main. Điều này sẽ gây ra lỗi double free vì
Rust sẽ cố gắng dọn dẹp cùng một giá trị hai lần.
Chúng ta không thể vô hiệu hóa việc chèn drop tự động khi một giá trị ra khỏi
phạm vi, và chúng ta không thể gọi phương thức drop một cách rõ ràng. Vì vậy,
nếu chúng ta cần buộc một giá trị được dọn dẹp sớm, chúng ta sử dụng hàm
std::mem::drop.
Hàm std::mem::drop khác với phương thức drop trong trait Drop. Chúng ta
gọi nó bằng cách truyền một đối số là giá trị mà chúng ta muốn buộc hủy. Hàm này
nằm trong prelude, vì vậy chúng ta có thể sửa đổi main trong Listing 15-15 để
gọi hàm drop, như trong Listing 15-16.
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created"); drop(c); println!("CustomSmartPointer dropped before the end of main"); }
Chạy mã này sẽ in ra như sau:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
Văn bản Dropping CustomSmartPointer with data `some data`! được in giữa
văn bản CustomSmartPointer created. và
CustomSmartPointer dropped before the end of main., cho thấy rằng mã phương
thức drop được gọi để hủy c tại thời điểm đó.
Bạn có thể sử dụng mã được chỉ định trong triển khai trait Drop theo nhiều
cách để làm cho việc dọn dẹp trở nên thuận tiện và an toàn: ví dụ, bạn có thể sử
dụng nó để tạo bộ cấp phát bộ nhớ của riêng bạn! Với trait Drop và hệ thống sở
hữu của Rust, bạn không phải nhớ dọn dẹp vì Rust làm điều đó tự động.
Bạn cũng không phải lo lắng về các vấn đề do vô tình dọn dẹp các giá trị vẫn
đang được sử dụng: hệ thống sở hữu đảm bảo các tham chiếu luôn hợp lệ cũng đảm
bảo rằng drop chỉ được gọi một lần khi giá trị không còn được sử dụng.
Bây giờ chúng ta đã xem xét Box<T> và một số đặc điểm của con trỏ thông minh,
hãy xem một vài con trỏ thông minh khác được định nghĩa trong thư viện chuẩn.
Rc<T>, Con Trỏ Thông Minh Đếm Tham Chiếu
Trong đa số trường hợp, quyền sở hữu (ownership) rất rõ ràng: bạn biết chính xác biến nào sở hữu một giá trị cụ thể. Tuy nhiên, có những trường hợp một giá trị có thể có nhiều chủ sở hữu. Ví dụ, trong cấu trúc dữ liệu đồ thị, nhiều cạnh có thể trỏ đến cùng một nút, và nút đó về mặt khái niệm được sở hữu bởi tất cả các cạnh trỏ đến nó. Một nút không nên được dọn dẹp trừ khi nó không có bất kỳ cạnh nào trỏ đến và do đó không có chủ sở hữu nào.
Bạn phải kích hoạt quyền sở hữu đa chủ một cách rõ ràng bằng cách sử dụng kiểu
Rust Rc<T>, viết tắt của reference counting (đếm tham chiếu). Kiểu Rc<T>
theo dõi số lượng tham chiếu đến một giá trị để xác định liệu giá trị đó có còn
đang được sử dụng hay không. Nếu không có tham chiếu nào đến một giá trị, giá
trị có thể được dọn dẹp mà không làm mất hiệu lực bất kỳ tham chiếu nào.
Hãy tưởng tượng Rc<T> như một chiếc TV trong phòng khách gia đình. Khi một
người vào xem TV, họ bật nó lên. Những người khác có thể vào phòng và xem TV.
Khi người cuối cùng rời khỏi phòng, họ tắt TV vì nó không còn được sử dụng nữa.
Nếu ai đó tắt TV trong khi những người khác vẫn đang xem, sẽ có sự phản đối từ
những người xem TV còn lại!
Chúng ta sử dụng kiểu Rc<T> khi muốn cấp phát dữ liệu trên heap cho nhiều phần
của chương trình đọc và chúng ta không thể xác định tại thời điểm biên dịch phần
nào sẽ kết thúc việc sử dụng dữ liệu cuối cùng. Nếu chúng ta biết phần nào sẽ
kết thúc cuối cùng, chúng ta có thể đơn giản làm cho phần đó trở thành chủ sở
hữu của dữ liệu, và các quy tắc sở hữu thông thường được thực thi tại thời điểm
biên dịch sẽ có hiệu lực.
Lưu ý rằng Rc<T> chỉ dùng trong các tình huống đơn luồng. Khi chúng ta thảo
luận về đồng thời trong Chương 16, chúng ta sẽ đề cập đến cách thực hiện đếm
tham chiếu trong các chương trình đa luồng.
Sử dụng Rc<T> để Chia Sẻ Dữ Liệu
Hãy quay lại ví dụ về danh sách cons trong Listing 15-5. Nhớ rằng chúng ta đã
định nghĩa nó bằng Box<T>. Lần này, chúng ta sẽ tạo hai danh sách đều chia sẻ
quyền sở hữu của một danh sách thứ ba. Về mặt khái niệm, điều này trông giống
như Hình 15-3.

Hình 15-3: Hai danh sách, b và c, chia sẻ quyền sở hữu
của danh sách thứ ba, a
Chúng ta sẽ tạo danh sách a chứa 5 và sau đó là 10. Sau đó, chúng ta sẽ
tạo thêm hai danh sách nữa: b bắt đầu bằng 3 và c bắt đầu bằng 4. Cả hai
danh sách b và c sẽ tiếp tục với danh sách a đầu tiên chứa 5 và 10.
Nói cách khác, cả hai danh sách sẽ chia sẻ danh sách đầu tiên chứa 5 và 10.
Việc cố gắng triển khai kịch bản này bằng định nghĩa List với Box<T> sẽ
không hoạt động, như được hiển thị trong Listing 15-17:
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Khi chúng ta biên dịch mã này, chúng ta nhận được lỗi này:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Các biến thể Cons sở hữu dữ liệu mà chúng nắm giữ, vì vậy khi chúng ta tạo
danh sách b, a được chuyển vào b và b sở hữu a. Sau đó, khi chúng ta
cố gắng sử dụng a lần nữa khi tạo c, chúng ta không được phép vì a đã bị
chuyển đi.
Chúng ta có thể thay đổi định nghĩa của Cons để nắm giữ tham chiếu thay thế,
nhưng sau đó chúng ta sẽ phải chỉ định các tham số thời gian sống. Bằng cách chỉ
định tham số thời gian sống, chúng ta sẽ chỉ định rằng mọi phần tử trong danh
sách sẽ tồn tại ít nhất lâu bằng toàn bộ danh sách. Đây là trường hợp cho các
phần tử và danh sách trong Listing 15-17, nhưng không phải trong mọi tình huống.
Thay vào đó, chúng ta sẽ thay đổi định nghĩa của List để sử dụng Rc<T> thay
vì Box<T>, như được hiển thị trong Listing 15-18. Mỗi biến thể Cons bây giờ
sẽ chứa một giá trị và một Rc<T> trỏ đến một List. Khi chúng ta tạo b,
thay vì lấy quyền sở hữu của a, chúng ta sẽ sao chép Rc<List> mà a đang
nắm giữ, do đó tăng số lượng tham chiếu từ một lên hai và cho phép a và b
chia sẻ quyền sở hữu dữ liệu trong Rc<List> đó. Chúng ta cũng sẽ sao chép a
khi tạo c, tăng số lượng tham chiếu từ hai lên ba. Mỗi lần chúng ta gọi
Rc::clone, số lượng tham chiếu đến dữ liệu trong Rc<List> sẽ tăng lên, và dữ
liệu sẽ không được dọn dẹp trừ khi không có tham chiếu nào đến nó.
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
Chúng ta cần thêm câu lệnh use để đưa Rc<T> vào phạm vi vì nó không có trong
prelude. Trong main, chúng ta tạo danh sách chứa 5 và 10 và lưu trữ nó
trong một Rc<List> mới trong a. Sau đó, khi chúng ta tạo b và c, chúng
ta gọi hàm Rc::clone và truyền một tham chiếu đến Rc<List> trong a làm đối
số.
Chúng ta có thể đã gọi a.clone() thay vì Rc::clone(&a), nhưng quy ước của
Rust là sử dụng Rc::clone trong trường hợp này. Việc triển khai Rc::clone
không tạo một bản sao sâu của tất cả dữ liệu như hầu hết các triển khai clone
của các kiểu khác. Lệnh gọi đến Rc::clone chỉ tăng số lượng tham chiếu, điều
này không tốn nhiều thời gian. Việc sao chép sâu dữ liệu có thể tốn nhiều thời
gian. Bằng cách sử dụng Rc::clone cho việc đếm tham chiếu, chúng ta có thể
phân biệt trực quan giữa các loại bản sao sâu và các loại bản sao tăng số lượng
tham chiếu. Khi tìm kiếm vấn đề về hiệu suất trong mã, chúng ta chỉ cần xem xét
các bản sao sâu và có thể bỏ qua các lệnh gọi đến Rc::clone.
Sao Chép một Rc<T> Tăng Số Lượng Tham Chiếu
Hãy thay đổi ví dụ đang hoạt động của chúng ta trong Listing 15-18 để chúng ta
có thể thấy số lượng tham chiếu thay đổi khi chúng ta tạo và loại bỏ các tham
chiếu đến Rc<List> trong a.
Trong Listing 15-19, chúng ta sẽ thay đổi main để nó có một phạm vi bên trong
xung quanh danh sách c; sau đó chúng ta có thể thấy số lượng tham chiếu thay
đổi như thế nào khi c ra khỏi phạm vi.
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; // --snip-- fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
Tại mỗi điểm trong chương trình khi số lượng tham chiếu thay đổi, chúng ta in ra
số lượng tham chiếu, mà chúng ta nhận được bằng cách gọi hàm Rc::strong_count.
Hàm này được đặt tên là strong_count thay vì count vì kiểu Rc<T> cũng có
weak_count; chúng ta sẽ xem weak_count được sử dụng để làm gì trong "Ngăn
chặn Chu kỳ Tham chiếu Bằng cách Sử dụng
Weak<T>".
Mã này in ra như sau:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Chúng ta có thể thấy rằng Rc<List> trong a có số lượng tham chiếu ban đầu là
1; sau đó mỗi lần chúng ta gọi clone, số lượng tăng lên 1. Khi c ra khỏi
phạm vi, số lượng giảm đi 1. Chúng ta không phải gọi một hàm để giảm số lượng
tham chiếu như chúng ta phải gọi Rc::clone để tăng số lượng tham chiếu: việc
triển khai của trait Drop tự động giảm số lượng tham chiếu khi một giá trị
Rc<T> ra khỏi phạm vi.
Điều chúng ta không thể thấy trong ví dụ này là khi b và sau đó a ra khỏi
phạm vi ở cuối main, số lượng lúc đó là 0, và Rc<List> được dọn dẹp hoàn
toàn. Sử dụng Rc<T> cho phép một giá trị có nhiều chủ sở hữu, và số lượng đảm
bảo rằng giá trị vẫn hợp lệ miễn là bất kỳ chủ sở hữu nào vẫn còn tồn tại.
Thông qua các tham chiếu bất biến, Rc<T> cho phép bạn chia sẻ dữ liệu giữa
nhiều phần của chương trình để chỉ đọc. Nếu Rc<T> cho phép bạn có nhiều tham
chiếu thay đổi cũng vậy, bạn có thể vi phạm một trong các quy tắc mượn đã thảo
luận trong Chương 4: nhiều lần mượn thay đổi đến cùng một nơi có thể gây ra các
cuộc đua dữ liệu và sự không nhất quán. Nhưng khả năng thay đổi dữ liệu rất hữu
ích! Trong phần tiếp theo, chúng ta sẽ thảo luận về mẫu khả biến nội bộ và kiểu
RefCell<T> mà bạn có thể sử dụng kết hợp với Rc<T> để làm việc với hạn chế
bất biến này.
RefCell<T> và Mẫu Khả Biến Nội Bộ
Khả biến nội bộ (Interior mutability) là một mẫu thiết kế trong Rust cho phép
bạn thay đổi dữ liệu ngay cả khi có các tham chiếu bất biến đến dữ liệu đó;
thông thường, hành động này bị cấm bởi các quy tắc mượn. Để thay đổi dữ liệu,
mẫu này sử dụng mã unsafe bên trong cấu trúc dữ liệu để uốn cong các quy tắc
thông thường của Rust về việc thay đổi và mượn. Mã không an toàn chỉ ra cho
trình biên dịch rằng chúng ta đang kiểm tra các quy tắc thủ công thay vì dựa vào
trình biên dịch để kiểm tra chúng cho chúng ta; chúng ta sẽ thảo luận thêm về mã
không an toàn trong Chương 20.
Chúng ta chỉ có thể sử dụng các kiểu sử dụng mẫu khả biến nội bộ khi chúng ta có
thể đảm bảo rằng các quy tắc mượn sẽ được tuân thủ trong thời gian chạy, mặc dù
trình biên dịch không thể đảm bảo điều đó. Mã unsafe liên quan sau đó được bọc
trong một API an toàn, và kiểu bên ngoài vẫn bất biến.
Hãy khám phá khái niệm này bằng cách xem xét kiểu RefCell<T> theo mẫu khả biến
nội bộ.
Thực Thi Quy Tắc Mượn trong Thời Gian Chạy với RefCell<T>
Không giống như Rc<T>, kiểu RefCell<T> đại diện cho quyền sở hữu duy nhất
đối với dữ liệu mà nó chứa. Vậy điều gì làm cho RefCell<T> khác với một kiểu
như Box<T>? Hãy nhớ lại các quy tắc mượn mà bạn đã học trong Chương 4:
- Tại bất kỳ thời điểm nào, bạn có thể có hoặc là một tham chiếu có thể thay đổi hoặc bất kỳ số lượng tham chiếu bất biến nào (nhưng không phải cả hai).
- Tham chiếu phải luôn hợp lệ.
Với tham chiếu và Box<T>, các bất biến của quy tắc mượn được thực thi tại thời
điểm biên dịch. Với RefCell<T>, các bất biến này được thực thi trong thời
gian chạy. Với tham chiếu, nếu bạn vi phạm các quy tắc này, bạn sẽ gặp lỗi
trình biên dịch. Với RefCell<T>, nếu bạn vi phạm các quy tắc này, chương trình
của bạn sẽ hoảng loạn và thoát.
Ưu điểm của việc kiểm tra các quy tắc mượn tại thời điểm biên dịch là các lỗi sẽ được phát hiện sớm hơn trong quá trình phát triển, và không có tác động đến hiệu suất thời gian chạy vì tất cả phân tích đều được hoàn thành trước đó. Vì những lý do đó, kiểm tra các quy tắc mượn tại thời điểm biên dịch là lựa chọn tốt nhất trong đa số trường hợp, đó là lý do tại sao đây là mặc định của Rust.
Ưu điểm của việc kiểm tra các quy tắc mượn trong thời gian chạy thay vì thời gian biên dịch là một số kịch bản an toàn bộ nhớ nhất định được cho phép, trong khi chúng sẽ bị từ chối bởi các kiểm tra thời gian biên dịch. Phân tích tĩnh, như trình biên dịch Rust, về bản chất là bảo thủ. Một số thuộc tính của mã không thể phát hiện được bằng cách phân tích mã: ví dụ nổi tiếng nhất là Bài toán Dừng (Halting Problem), nằm ngoài phạm vi của cuốn sách này nhưng là một chủ đề thú vị để nghiên cứu.
Bởi vì một số phân tích là không thể, nếu trình biên dịch Rust không thể chắc
chắn rằng mã tuân thủ các quy tắc sở hữu, nó có thể từ chối một chương trình
đúng; theo cách này, nó là bảo thủ. Nếu Rust chấp nhận một chương trình không
chính xác, người dùng sẽ không thể tin tưởng vào các đảm bảo mà Rust đưa ra. Tuy
nhiên, nếu Rust từ chối một chương trình đúng, lập trình viên sẽ bị bất tiện,
nhưng không có gì thảm khốc có thể xảy ra. Kiểu RefCell<T> hữu ích khi bạn
chắc chắn rằng mã của bạn tuân theo các quy tắc mượn nhưng trình biên dịch không
thể hiểu và đảm bảo điều đó.
Tương tự như Rc<T>, RefCell<T> chỉ để sử dụng trong các tình huống đơn luồng
và sẽ đưa ra lỗi thời gian biên dịch nếu bạn cố gắng sử dụng nó trong bối cảnh
đa luồng. Chúng ta sẽ nói về cách lấy chức năng của RefCell<T> trong chương
trình đa luồng trong Chương 16.
Đây là một tóm tắt về lý do để chọn Box<T>, Rc<T>, hoặc RefCell<T>:
Rc<T>cho phép nhiều chủ sở hữu của cùng một dữ liệu;Box<T>vàRefCell<T>có chủ sở hữu duy nhất.Box<T>cho phép mượn bất biến hoặc có thể thay đổi được kiểm tra tại thời điểm biên dịch;Rc<T>chỉ cho phép mượn bất biến được kiểm tra tại thời điểm biên dịch;RefCell<T>cho phép mượn bất biến hoặc có thể thay đổi được kiểm tra trong thời gian chạy.- Bởi vì
RefCell<T>cho phép mượn có thể thay đổi được kiểm tra trong thời gian chạy, bạn có thể thay đổi giá trị bên trongRefCell<T>ngay cả khiRefCell<T>là bất biến.
Thay đổi giá trị bên trong một giá trị bất biến là mẫu khả biến nội bộ. Hãy xem xét một tình huống mà khả biến nội bộ hữu ích và xem xét cách nó có thể thực hiện được.
Khả Biến Nội Bộ: Mượn Có Thể Thay Đổi cho một Giá Trị Bất Biến
Một hệ quả của các quy tắc mượn là khi bạn có một giá trị bất biến, bạn không thể mượn nó một cách có thể thay đổi. Ví dụ, đoạn mã này sẽ không biên dịch:
fn main() {
let x = 5;
let y = &mut x;
}Nếu bạn cố gắng biên dịch mã này, bạn sẽ gặp lỗi sau:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Tuy nhiên, có những tình huống mà sẽ rất hữu ích nếu một giá trị có thể tự thay
đổi bản thân trong các phương thức của nó nhưng xuất hiện bất biến đối với mã
khác. Mã bên ngoài các phương thức của giá trị sẽ không thể thay đổi giá trị. Sử
dụng RefCell<T> là một cách để có khả năng khả biến nội bộ, nhưng RefCell<T>
không hoàn toàn vượt qua các quy tắc mượn: trình kiểm tra mượn trong trình biên
dịch cho phép khả biến nội bộ này, và các quy tắc mượn được kiểm tra trong thời
gian chạy thay vì. Nếu bạn vi phạm các quy tắc, bạn sẽ nhận được một panic!
thay vì lỗi trình biên dịch.
Hãy làm việc thông qua một ví dụ thực tế mà chúng ta có thể sử dụng RefCell<T>
để thay đổi một giá trị bất biến và xem tại sao điều đó lại hữu ích.
Một Trường Hợp Sử Dụng cho Khả Biến Nội Bộ: Đối Tượng Giả Lập
Đôi khi trong quá trình kiểm thử, một lập trình viên sẽ sử dụng một kiểu thay thế cho một kiểu khác, để quan sát hành vi cụ thể và khẳng định rằng nó được triển khai chính xác. Kiểu thay thế này được gọi là test double. Hãy nghĩ về nó theo nghĩa của một diễn viên đóng thế trong làm phim, nơi một người bước vào và thay thế cho một diễn viên để thực hiện một cảnh đặc biệt khó khăn. Test double đứng thay cho các kiểu khác khi chúng ta đang chạy kiểm thử. Đối tượng giả lập (Mock objects) là các loại test double cụ thể ghi lại những gì xảy ra trong quá trình kiểm thử để bạn có thể khẳng định rằng các hành động đúng đã diễn ra.
Rust không có đối tượng theo cùng nghĩa như các ngôn ngữ khác có đối tượng, và Rust không có chức năng đối tượng giả lập được tích hợp vào thư viện chuẩn như một số ngôn ngữ khác. Tuy nhiên, bạn chắc chắn có thể tạo một struct sẽ phục vụ cùng mục đích như một đối tượng giả lập.
Đây là kịch bản chúng ta sẽ kiểm thử: chúng ta sẽ tạo một thư viện theo dõi một giá trị so với một giá trị tối đa và gửi tin nhắn dựa trên mức độ gần với giá trị tối đa của giá trị hiện tại. Thư viện này có thể được sử dụng để theo dõi hạn ngạch của người dùng đối với số lượng cuộc gọi API mà họ được phép thực hiện, ví dụ.
Thư viện của chúng ta sẽ chỉ cung cấp chức năng theo dõi mức độ gần với tối đa
của một giá trị và các tin nhắn nên là gì ở thời điểm nào. Các ứng dụng sử dụng
thư viện của chúng ta sẽ được kỳ vọng cung cấp cơ chế để gửi tin nhắn: ứng dụng
có thể đặt một tin nhắn trong ứng dụng, gửi email, gửi tin nhắn văn bản, hoặc
làm việc khác. Thư viện không cần biết chi tiết đó. Tất cả những gì nó cần là
một thứ triển khai một trait mà chúng ta sẽ cung cấp gọi là Messenger. Listing
15-20 hiển thị mã thư viện.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Một phần quan trọng của mã này là trait Messenger có một phương thức gọi là
send nhận một tham chiếu bất biến đến self và văn bản của tin nhắn. Trait
này là giao diện mà đối tượng giả lập của chúng ta cần triển khai để có thể được
sử dụng theo cùng cách như một đối tượng thực. Phần quan trọng khác là chúng ta
muốn kiểm thử hành vi của phương thức set_value trên LimitTracker. Chúng ta
có thể thay đổi những gì chúng ta truyền vào cho tham số value, nhưng
set_value không trả về bất cứ thứ gì để chúng ta đưa ra khẳng định. Chúng ta
muốn có thể nói rằng nếu chúng ta tạo một LimitTracker với thứ gì đó triển
khai trait Messenger và một giá trị cụ thể cho max, khi chúng ta truyền các
số khác nhau cho value, messenger được yêu cầu gửi các tin nhắn thích hợp.
Chúng ta cần một đối tượng giả lập mà, thay vì gửi email hoặc tin nhắn văn bản
khi chúng ta gọi send, sẽ chỉ theo dõi các tin nhắn mà nó được yêu cầu gửi.
Chúng ta có thể tạo một thể hiện mới của đối tượng giả lập, tạo một
LimitTracker sử dụng đối tượng giả lập, gọi phương thức set_value trên
LimitTracker, và sau đó kiểm tra xem đối tượng giả lập có các tin nhắn mà
chúng ta mong đợi không. Listing 15-21 hiển thị một nỗ lực triển khai một đối
tượng giả lập để làm điều đó, nhưng trình kiểm tra mượn sẽ không cho phép.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}Mã kiểm thử này định nghĩa một struct MockMessenger có trường sent_messages
với một Vec của các giá trị String để theo dõi các tin nhắn mà nó được yêu
cầu gửi. Chúng ta cũng định nghĩa một hàm liên kết new để thuận tiện cho việc
tạo các giá trị MockMessenger mới bắt đầu với một danh sách tin nhắn trống.
Sau đó, chúng ta triển khai trait Messenger cho MockMessenger để chúng ta có
thể cung cấp một MockMessenger cho một LimitTracker. Trong định nghĩa của
phương thức send, chúng ta lấy tin nhắn được truyền vào dưới dạng một tham số
và lưu trữ nó trong danh sách sent_messages của MockMessenger.
Trong kiểm thử, chúng ta đang kiểm tra những gì xảy ra khi LimitTracker được
yêu cầu đặt value thành một cái gì đó lớn hơn 75 phần trăm của giá trị max.
Đầu tiên, chúng ta tạo một MockMessenger mới, sẽ bắt đầu với một danh sách tin
nhắn trống. Sau đó, chúng ta tạo một LimitTracker mới và cung cấp cho nó một
tham chiếu đến MockMessenger mới và một giá trị max là 100. Chúng ta gọi
phương thức set_value trên LimitTracker với một giá trị 80, lớn hơn 75
phần trăm của 100. Sau đó, chúng ta khẳng định rằng danh sách tin nhắn mà
MockMessenger đang theo dõi bây giờ nên có một tin nhắn trong đó.
Tuy nhiên, có một vấn đề với kiểm thử này, như được hiển thị ở đây:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Chúng ta không thể sửa đổi MockMessenger để theo dõi các tin nhắn, vì phương
thức send nhận một tham chiếu bất biến đến self. Chúng ta cũng không thể làm
theo gợi ý từ văn bản lỗi để sử dụng &mut self trong cả phương thức impl và
định nghĩa trait. Chúng ta không muốn thay đổi trait Messenger chỉ vì mục
đích kiểm thử. Thay vào đó, chúng ta cần tìm một cách để làm cho mã kiểm thử của
chúng ta hoạt động chính xác với thiết kế hiện tại của chúng ta.
Đây là một tình huống mà khả biến nội bộ có thể giúp đỡ! Chúng ta sẽ lưu trữ
sent_messages trong một RefCell<T>, và sau đó phương thức send sẽ có thể
sửa đổi sent_messages để lưu trữ các tin nhắn chúng ta đã thấy. Listing 15-22
hiển thị nó trông như thế nào.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Trường sent_messages bây giờ có kiểu RefCell<Vec<String>> thay vì
Vec<String>. Trong hàm new, chúng ta tạo một thể hiện RefCell<Vec<String>>
mới xung quanh vectơ trống.
Đối với việc triển khai phương thức send, tham số đầu tiên vẫn là một mượn bất
biến của self, phù hợp với định nghĩa trait. Chúng ta gọi borrow_mut trên
RefCell<Vec<String>> trong self.sent_messages để có được một tham chiếu có
thể thay đổi đến giá trị bên trong RefCell<Vec<String>>, đó là vectơ. Sau đó,
chúng ta có thể gọi push trên tham chiếu có thể thay đổi đến vectơ để theo dõi
các tin nhắn được gửi trong quá trình kiểm thử.
Thay đổi cuối cùng chúng ta phải thực hiện là trong khẳng định: để xem có bao
nhiêu mục trong vectơ bên trong, chúng ta gọi borrow trên
RefCell<Vec<String>> để có được một tham chiếu bất biến đến vectơ.
Bây giờ bạn đã thấy cách sử dụng RefCell<T>, hãy đi sâu vào cách nó hoạt động!
Theo dõi các Mượn tại Thời gian Chạy với RefCell<T>
Khi tạo tham chiếu bất biến và có thể thay đổi, chúng ta sử dụng cú pháp & và
&mut, tương ứng. Với RefCell<T>, chúng ta sử dụng các phương thức borrow
và borrow_mut, là một phần của API an toàn thuộc về RefCell<T>. Phương thức
borrow trả về kiểu con trỏ thông minh Ref<T>, và borrow_mut trả về kiểu
con trỏ thông minh RefMut<T>. Cả hai kiểu đều triển khai Deref, vì vậy chúng
ta có thể coi chúng như các tham chiếu thông thường.
RefCell<T> theo dõi có bao nhiêu con trỏ thông minh Ref<T> và RefMut<T>
đang hoạt động. Mỗi lần chúng ta gọi borrow, RefCell<T> tăng số lượng mượn
bất biến đang hoạt động. Khi giá trị Ref<T> ra khỏi phạm vi, số lượng mượn bất
biến giảm xuống 1. Giống như các quy tắc mượn thời gian biên dịch, RefCell<T>
cho phép chúng ta có nhiều mượn bất biến hoặc một mượn có thể thay đổi tại bất
kỳ thời điểm nào.
Nếu chúng ta cố gắng vi phạm các quy tắc này, thay vì nhận được lỗi trình biên
dịch như chúng ta sẽ làm với tham chiếu, việc triển khai RefCell<T> sẽ hoảng
loạn trong thời gian chạy. Listing 15-23 hiển thị một sửa đổi của việc triển
khai send trong Listing 15-22. Chúng ta cố tình cố gắng tạo hai mượn có thể
thay đổi hoạt động cho cùng một phạm vi để minh họa rằng RefCell<T> ngăn chúng
ta làm điều này trong thời gian chạy.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Chúng ta tạo một biến one_borrow cho con trỏ thông minh RefMut<T> được trả
về từ borrow_mut. Sau đó, chúng ta tạo một mượn có thể thay đổi khác theo cùng
cách trong biến two_borrow. Điều này tạo ra hai tham chiếu có thể thay đổi
trong cùng một phạm vi, không được phép. Khi chúng ta chạy các kiểm thử cho thư
viện của mình, mã trong Listing 15-23 sẽ biên dịch mà không có bất kỳ lỗi nào,
nhưng kiểm thử sẽ thất bại:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Lưu ý rằng mã hoảng loạn với thông báo already borrowed: BorrowMutError. Đây
là cách RefCell<T> xử lý vi phạm các quy tắc mượn trong thời gian chạy.
Việc chọn để bắt các lỗi mượn trong thời gian chạy thay vì thời gian biên dịch,
như chúng ta đã làm ở đây, có nghĩa là bạn có khả năng tìm thấy lỗi trong mã của
mình sau này trong quá trình phát triển: có thể không phải cho đến khi mã của
bạn được triển khai lên môi trường sản xuất. Ngoài ra, mã của bạn sẽ phải chịu
một hình phạt hiệu suất thời gian chạy nhỏ do phải theo dõi các mượn trong thời
gian chạy thay vì thời gian biên dịch. Tuy nhiên, việc sử dụng RefCell<T> làm
cho việc viết một đối tượng giả lập có thể tự sửa đổi để theo dõi các tin nhắn
mà nó đã thấy khi bạn đang sử dụng nó trong một bối cảnh chỉ cho phép các giá
trị bất biến trở nên khả thi. Bạn có thể sử dụng RefCell<T> bất chấp sự đánh
đổi của nó để có được nhiều chức năng hơn so với các tham chiếu thông thường
cung cấp.
Cho Phép Nhiều Chủ Sở Hữu của Dữ Liệu Có Thể Thay Đổi với Rc<T> và RefCell<T>
Một cách phổ biến để sử dụng RefCell<T> là kết hợp với Rc<T>. Hãy nhớ rằng
Rc<T> cho phép bạn có nhiều chủ sở hữu của một số dữ liệu, nhưng nó chỉ cung
cấp quyền truy cập bất biến vào dữ liệu đó. Nếu bạn có một Rc<T> chứa một
RefCell<T>, bạn có thể có được một giá trị có thể có nhiều chủ sở hữu và mà
bạn có thể thay đổi!
Ví dụ, hãy nhớ lại ví dụ danh sách cons trong Listing 15-18 nơi chúng ta sử dụng
Rc<T> để cho phép nhiều danh sách chia sẻ quyền sở hữu của một danh sách khác.
Bởi vì Rc<T> chỉ chứa các giá trị bất biến, chúng ta không thể thay đổi bất kỳ
giá trị nào trong danh sách một khi chúng ta đã tạo chúng. Hãy thêm vào
RefCell<T> để có khả năng thay đổi các giá trị trong danh sách. Listing 15-24
hiển thị rằng bằng cách sử dụng RefCell<T> trong định nghĩa Cons, chúng ta
có thể sửa đổi giá trị được lưu trữ trong tất cả các danh sách.
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *value.borrow_mut() += 10; println!("a after = {a:?}"); println!("b after = {b:?}"); println!("c after = {c:?}"); }
Chúng ta tạo một giá trị là một thể hiện của Rc<RefCell<i32>> và lưu trữ nó
trong một biến có tên value để chúng ta có thể truy cập nó trực tiếp sau này.
Sau đó, chúng ta tạo một List trong a với một biến thể Cons chứa value.
Chúng ta cần sao chép value để cả a và value đều có quyền sở hữu của giá
trị bên trong 5 thay vì chuyển quyền sở hữu từ value sang a hoặc có a
mượn từ value.
Chúng ta bọc danh sách a trong một Rc<T> để khi chúng ta tạo danh sách b
và c, cả hai đều có thể tham chiếu đến a, đó là những gì chúng ta đã làm
trong Listing 15-18.
Sau khi chúng ta đã tạo danh sách trong a, b, và c, chúng ta muốn thêm 10
vào giá trị trong value. Chúng ta làm điều này bằng cách gọi borrow_mut trên
value, sử dụng tính năng tự động tham chiếu mà chúng ta đã thảo luận trong
"Where's the -> Operator?") trong
Chương 5 để tham chiếu đến Rc<T> đến giá trị RefCell<T> bên trong. Phương
thức borrow_mut trả về một con trỏ thông minh RefMut<T>, và chúng ta sử dụng
toán tử tham chiếu trên nó và thay đổi giá trị bên trong.
Khi chúng ta in a, b, và c, chúng ta có thể thấy rằng tất cả chúng đều có
giá trị sửa đổi là 15 thay vì 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Kỹ thuật này khá gọn gàng! Bằng cách sử dụng RefCell<T>, chúng ta có một giá
trị List bất biến bên ngoài. Nhưng chúng ta có thể sử dụng các phương thức
trên RefCell<T> cung cấp quyền truy cập vào khả biến nội bộ của nó để chúng ta
có thể sửa đổi dữ liệu của mình khi chúng ta cần. Các kiểm tra thời gian chạy
của các quy tắc mượn bảo vệ chúng ta khỏi các cuộc đua dữ liệu, và đôi khi đáng
để đánh đổi một chút tốc độ để có được sự linh hoạt này trong cấu trúc dữ liệu
của chúng ta. Lưu ý rằng RefCell<T> không hoạt động cho mã đa luồng!
Mutex<T> là phiên bản an toàn cho luồng của RefCell<T>, và chúng ta sẽ thảo
luận về Mutex<T> trong Chương 16.
Chu Kỳ Tham Chiếu Có Thể Rò Rỉ Bộ Nhớ
Các đảm bảo an toàn bộ nhớ của Rust khiến việc vô tình tạo ra bộ nhớ không bao
giờ được dọn dẹp (được gọi là rò rỉ bộ nhớ) trở nên khó khăn, nhưng không phải
là không thể. Việc ngăn chặn hoàn toàn rò rỉ bộ nhớ không phải là một trong
những đảm bảo của Rust, có nghĩa là rò rỉ bộ nhớ là an toàn về mặt bộ nhớ trong
Rust. Chúng ta có thể thấy rằng Rust cho phép rò rỉ bộ nhớ bằng cách sử dụng
Rc<T> và RefCell<T>: có thể tạo các tham chiếu trong đó các mục tham chiếu
lẫn nhau trong một chu kỳ. Điều này tạo ra rò rỉ bộ nhớ vì số lượng tham chiếu
của mỗi mục trong chu kỳ sẽ không bao giờ đạt đến 0, và các giá trị sẽ không bao
giờ bị hủy.
Tạo Chu Kỳ Tham Chiếu
Hãy xem cách một chu kỳ tham chiếu có thể xảy ra và cách ngăn chặn nó, bắt đầu
với định nghĩa của enum List và một phương thức tail trong Listing 15-25.
// ANCHOR: here use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } // ANCHOR_END: here fn main() {}
Chúng ta đang sử dụng một biến thể khác của định nghĩa List từ Listing 15-5.
Phần tử thứ hai trong biến thể Cons bây giờ là RefCell<Rc<List>>, có nghĩa
là thay vì có khả năng sửa đổi giá trị i32 như chúng ta đã làm trong Listing
15-24, chúng ta muốn sửa đổi giá trị List mà một biến thể Cons đang trỏ đến.
Chúng ta cũng thêm một phương thức tail để thuận tiện cho việc truy cập vào
mục thứ hai nếu chúng ta có một biến thể Cons.
Trong Listing 15-26, chúng ta đang thêm một hàm main sử dụng các định nghĩa
trong Listing 15-25. Mã này tạo một danh sách trong a và một danh sách trong
b trỏ đến danh sách trong a. Sau đó, nó sửa đổi danh sách trong a để trỏ
đến b, tạo thành một chu kỳ tham chiếu. Có các câu lệnh println! dọc theo
đường đi để hiển thị số lượng tham chiếu tại các điểm khác nhau trong quá trình
này.
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a)); // Uncomment the next line to see that we have a cycle; // it will overflow the stack. // println!("a next item = {:?}", a.tail()); }
Chúng ta tạo một thể hiện Rc<List> chứa một giá trị List trong biến a với
một danh sách ban đầu của 5, Nil. Sau đó, chúng ta tạo một thể hiện Rc<List>
chứa một giá trị List khác trong biến b chứa giá trị 10 và trỏ đến danh
sách trong a.
Chúng ta sửa đổi a để nó trỏ đến b thay vì Nil, tạo thành một chu kỳ.
Chúng ta làm điều đó bằng cách sử dụng phương thức tail để lấy một tham chiếu
đến RefCell<Rc<List>> trong a, mà chúng ta đặt trong biến link. Sau đó,
chúng ta sử dụng phương thức borrow_mut trên RefCell<Rc<List>> để thay đổi
giá trị bên trong từ một Rc<List> chứa giá trị Nil thành Rc<List> trong
b.
Khi chúng ta chạy mã này, giữ cho println! cuối cùng được comment lại trong
thời điểm này, chúng ta sẽ nhận được đầu ra này:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Số lượng tham chiếu của các thể hiện Rc<List> trong cả a và b là 2 sau khi
chúng ta thay đổi danh sách trong a để trỏ đến b. Vào cuối main, Rust loại
bỏ biến b, giảm số lượng tham chiếu của thể hiện Rc<List> trong b từ 2
xuống 1. Bộ nhớ mà Rc<List> có trên heap sẽ không bị hủy tại thời điểm này vì
số lượng tham chiếu của nó là 1, không phải 0. Sau đó, Rust loại bỏ a, giảm số
lượng tham chiếu của thể hiện Rc<List> trong a từ 2 xuống 1. Bộ nhớ của thể
hiện này cũng không thể bị hủy, vì thể hiện Rc<List> khác vẫn tham chiếu đến
nó. Bộ nhớ được cấp phát cho danh sách sẽ vẫn không được thu gom mãi mãi. Để
hình dung chu kỳ tham chiếu này, chúng ta đã tạo sơ đồ trong Hình 15-4.

Hình 15-4: Một chu kỳ tham chiếu của danh sách a và b
trỏ đến nhau
Nếu bạn bỏ comment dòng println! cuối cùng và chạy chương trình, Rust sẽ cố
gắng in chu kỳ này với a trỏ đến b trỏ đến a và cứ thế cho đến khi nó tràn
ngăn xếp.
So với một chương trình thực tế, hậu quả của việc tạo chu kỳ tham chiếu trong ví dụ này không quá nghiêm trọng: ngay sau khi chúng ta tạo chu kỳ tham chiếu, chương trình kết thúc. Tuy nhiên, nếu một chương trình phức tạp hơn cấp phát nhiều bộ nhớ trong một chu kỳ và giữ nó trong thời gian dài, chương trình sẽ sử dụng nhiều bộ nhớ hơn mức cần thiết và có thể làm quá tải hệ thống, khiến nó hết bộ nhớ khả dụng.
Việc tạo chu kỳ tham chiếu không dễ dàng thực hiện, nhưng cũng không phải là
không thể. Nếu bạn có các giá trị RefCell<T> chứa các giá trị Rc<T> hoặc các
kết hợp lồng nhau tương tự của các kiểu với khả biến nội bộ và đếm tham chiếu,
bạn phải đảm bảo rằng bạn không tạo chu kỳ; bạn không thể dựa vào Rust để phát
hiện chúng. Việc tạo một chu kỳ tham chiếu sẽ là một lỗi logic trong chương
trình của bạn mà bạn nên sử dụng các bài kiểm tra tự động, đánh giá mã và các
thực hành phát triển phần mềm khác để giảm thiểu.
Một giải pháp khác để tránh chu kỳ tham chiếu là tổ chức lại cấu trúc dữ liệu
của bạn để một số tham chiếu thể hiện quyền sở hữu và một số tham chiếu không.
Kết quả là, bạn có thể có các chu kỳ được tạo thành từ một số mối quan hệ sở hữu
và một số mối quan hệ không sở hữu, và chỉ có các mối quan hệ sở hữu ảnh hưởng
đến việc liệu một giá trị có thể bị hủy hay không. Trong Listing 15-25, chúng ta
luôn muốn các biến thể Cons sở hữu danh sách của chúng, vì vậy việc tổ chức
lại cấu trúc dữ liệu là không thể. Hãy xem một ví dụ sử dụng đồ thị được tạo
thành từ các nút cha và nút con để thấy khi nào các mối quan hệ không sở hữu là
một cách thích hợp để ngăn chặn chu kỳ tham chiếu.
Ngăn Chặn Chu Kỳ Tham Chiếu Sử Dụng Weak<T>
Cho đến nay, chúng ta đã chứng minh rằng gọi Rc::clone tăng strong_count của
một thể hiện Rc<T>, và một thể hiện Rc<T> chỉ được dọn dẹp nếu
strong_count của nó là 0. Bạn cũng có thể tạo tham chiếu yếu đến giá trị trong
một thể hiện Rc<T> bằng cách gọi Rc::downgrade và truyền một tham chiếu đến
Rc<T>. Tham chiếu mạnh là cách bạn có thể chia sẻ quyền sở hữu của một thể
hiện Rc<T>. Tham chiếu yếu không thể hiện một mối quan hệ sở hữu, và số
lượng của chúng không ảnh hưởng đến thời điểm một thể hiện Rc<T> được dọn dẹp.
Chúng sẽ không gây ra chu kỳ tham chiếu vì bất kỳ chu kỳ nào liên quan đến một
số tham chiếu yếu sẽ bị phá vỡ khi số lượng tham chiếu mạnh của các giá trị liên
quan là 0.
Khi bạn gọi Rc::downgrade, bạn nhận được một con trỏ thông minh kiểu
Weak<T>. Thay vì tăng strong_count trong thể hiện Rc<T> lên 1, gọi
Rc::downgrade tăng weak_count lên 1. Kiểu Rc<T> sử dụng weak_count để
theo dõi có bao nhiêu tham chiếu Weak<T> tồn tại, tương tự như strong_count.
Sự khác biệt là weak_count không cần phải là 0 để thể hiện Rc<T> được dọn
dẹp.
Bởi vì giá trị mà Weak<T> tham chiếu đến có thể đã bị hủy, để làm bất cứ điều
gì với giá trị mà một Weak<T> đang trỏ đến, bạn phải đảm bảo rằng giá trị vẫn
tồn tại. Làm điều này bằng cách gọi phương thức upgrade trên một thể hiện
Weak<T>, sẽ trả về một Option<Rc<T>>. Bạn sẽ nhận được kết quả là Some nếu
giá trị Rc<T> chưa bị hủy và kết quả là None nếu giá trị Rc<T> đã bị hủy.
Bởi vì upgrade trả về một Option<Rc<T>>, Rust sẽ đảm bảo rằng trường hợp
Some và trường hợp None được xử lý, và sẽ không có con trỏ không hợp lệ.
Ví dụ, thay vì sử dụng một danh sách mà các mục chỉ biết về mục tiếp theo, chúng ta sẽ tạo một cây mà các mục biết về các mục con và các mục cha của chúng.
Tạo Cấu Trúc Dữ Liệu Cây: Một Node với Các Nút Con
Để bắt đầu, chúng ta sẽ xây dựng một cây với các nút biết về các nút con của
chúng. Chúng ta sẽ tạo một struct có tên Node chứa giá trị i32 của riêng nó
cũng như tham chiếu đến các giá trị Node con của nó:
Tên tệp: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Chúng ta muốn một Node sở hữu các con của nó, và chúng ta muốn chia sẻ quyền
sở hữu đó với các biến để chúng ta có thể truy cập trực tiếp vào mỗi Node
trong cây. Để làm điều này, chúng ta định nghĩa các mục Vec<T> là các giá trị
kiểu Rc<Node>. Chúng ta cũng muốn sửa đổi nút nào là con của nút khác, vì vậy
chúng ta có một RefCell<T> trong children bao quanh Vec<Rc<Node>>.
Tiếp theo, chúng ta sẽ sử dụng định nghĩa struct của mình và tạo một thể hiện
Node có tên leaf với giá trị 3 và không có con, và một thể hiện khác có
tên branch với giá trị 5 và leaf là một trong những đứa con của nó, như
trong Listing 15-27.
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Chúng ta sao chép Rc<Node> trong leaf và lưu trữ nó trong branch, có nghĩa
là Node trong leaf bây giờ có hai chủ sở hữu: leaf và branch. Chúng ta
có thể đi từ branch đến leaf thông qua branch.children, nhưng không có
cách nào để đi từ leaf đến branch. Lý do là leaf không có tham chiếu đến
branch và không biết chúng có liên quan. Chúng ta muốn leaf biết rằng
branch là cha của nó. Chúng ta sẽ làm điều đó tiếp theo.
Thêm Tham Chiếu từ Nút Con đến Nút Cha của Nó
Để làm cho nút con nhận thức được nút cha của nó, chúng ta cần thêm một trường
parent vào định nghĩa struct Node của chúng ta. Vấn đề là quyết định kiểu
của parent nên là gì. Chúng ta biết rằng nó không thể chứa một Rc<T>, vì
điều đó sẽ tạo ra một chu kỳ tham chiếu với leaf.parent trỏ đến branch và
branch.children trỏ đến leaf, điều này sẽ khiến giá trị strong_count của
chúng không bao giờ là 0.
Nghĩ về mối quan hệ theo một cách khác, một nút cha nên sở hữu các con của nó: nếu một nút cha bị hủy, các nút con của nó cũng nên bị hủy. Tuy nhiên, một nút con không nên sở hữu nút cha của nó: nếu chúng ta hủy một nút con, nút cha vẫn nên tồn tại. Đây là một trường hợp cho tham chiếu yếu!
Vì vậy thay vì Rc<T>, chúng ta sẽ làm cho kiểu của parent sử dụng Weak<T>,
cụ thể là một RefCell<Weak<Node>>. Bây giờ định nghĩa struct Node của chúng
ta trông như thế này:
Tên tệp: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Một nút sẽ có thể tham chiếu đến nút cha của nó nhưng không sở hữu nút cha của
nó. Trong Listing 15-28, chúng ta cập nhật main để sử dụng định nghĩa mới này
để nút leaf sẽ có cách tham chiếu đến nút cha của nó, branch.
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Việc tạo nút leaf trông giống với Listing 15-27 ngoại trừ trường parent:
leaf bắt đầu mà không có cha, vì vậy chúng ta tạo một thể hiện tham chiếu
Weak<Node> mới và trống.
Tại thời điểm này, khi chúng ta cố gắng lấy tham chiếu đến cha của leaf bằng
cách sử dụng phương thức upgrade, chúng ta nhận được giá trị None. Chúng ta
thấy điều này trong đầu ra từ câu lệnh println! đầu tiên:
leaf parent = None
Khi chúng ta tạo nút branch, nó cũng sẽ có một tham chiếu Weak<Node> mới
trong trường parent vì branch không có nút cha. Chúng ta vẫn có leaf là
một trong những đứa con của branch. Một khi chúng ta có thể hiện Node trong
branch, chúng ta có thể sửa đổi leaf để cung cấp cho nó một tham chiếu
Weak<Node> đến nút cha của nó. Chúng ta sử dụng phương thức borrow_mut trên
RefCell<Weak<Node>> trong trường parent của leaf, và sau đó chúng ta sử
dụng hàm Rc::downgrade để tạo một tham chiếu Weak<Node> đến branch từ
Rc<Node> trong branch.
Khi chúng ta in cha của leaf lần nữa, lần này chúng ta sẽ nhận được một biến
thể Some chứa branch: bây giờ leaf có thể truy cập nút cha của nó! Khi
chúng ta in leaf, chúng ta cũng tránh được chu kỳ cuối cùng dẫn đến tràn ngăn
xếp như chúng ta đã có trong Listing 15-26; các tham chiếu Weak<Node> được in
dưới dạng (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
Sự thiếu đầu ra vô hạn cho thấy mã này không tạo ra một chu kỳ tham chiếu. Chúng
ta cũng có thể nhận thấy điều này bằng cách nhìn vào các giá trị mà chúng ta
nhận được từ việc gọi Rc::strong_count và Rc::weak_count.
Trực Quan Hóa Thay Đổi đối với strong_count và weak_count
Hãy xem giá trị strong_count và weak_count của các thể hiện Rc<Node> thay
đổi như thế nào bằng cách tạo một phạm vi bên trong mới và di chuyển việc tạo
branch vào phạm vi đó. Bằng cách làm như vậy, chúng ta có thể thấy điều gì xảy
ra khi branch được tạo và sau đó bị hủy khi nó ra khỏi phạm vi. Các sửa đổi
được hiển thị trong Listing 15-29.
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
Sau khi leaf được tạo, Rc<Node> của nó có số lượng mạnh là 1 và số lượng yếu
là 0. Trong phạm vi bên trong, chúng ta tạo branch và liên kết nó với leaf,
tại thời điểm đó khi chúng ta in số lượng, Rc<Node> trong branch sẽ có số
lượng mạnh là 1 và số lượng yếu là 1 (vì leaf.parent trỏ đến branch với một
Weak<Node>). Khi chúng ta in số lượng trong leaf, chúng ta sẽ thấy nó sẽ có
số lượng mạnh là 2 vì branch bây giờ có một bản sao của Rc<Node> của leaf
được lưu trữ trong branch.children, nhưng vẫn có số lượng yếu là 0.
Khi phạm vi bên trong kết thúc, branch ra khỏi phạm vi và số lượng mạnh của
Rc<Node> giảm xuống 0, vì vậy Node của nó bị hủy. Số lượng yếu là 1 từ
leaf.parent không ảnh hưởng đến việc Node có bị hủy hay không, vì vậy chúng
ta không bị rò rỉ bộ nhớ!
Nếu chúng ta cố gắng truy cập vào cha của leaf sau khi kết thúc phạm vi, chúng
ta sẽ lại nhận được None. Vào cuối chương trình, Rc<Node> trong leaf có số
lượng mạnh là 1 và số lượng yếu là 0 vì biến leaf bây giờ lại là tham chiếu
duy nhất đến Rc<Node>.
Tất cả logic quản lý số lượng và hủy giá trị được tích hợp vào Rc<T> và
Weak<T> và triển khai của chúng về trait Drop. Bằng cách chỉ định rằng mối
quan hệ từ một nút con đến nút cha của nó nên là một tham chiếu Weak<T> trong
định nghĩa của Node, bạn có thể có các nút cha trỏ đến các nút con và ngược
lại mà không tạo ra một chu kỳ tham chiếu và rò rỉ bộ nhớ.
Tóm Tắt
Chương này đã đề cập đến cách sử dụng con trỏ thông minh để đưa ra các đảm bảo
và đánh đổi khác nhau so với những gì Rust mặc định cung cấp với các tham chiếu
thông thường. Kiểu Box<T> có kích thước đã biết và trỏ đến dữ liệu được cấp
phát trên heap. Kiểu Rc<T> theo dõi số lượng tham chiếu đến dữ liệu trên heap
để dữ liệu có thể có nhiều chủ sở hữu. Kiểu RefCell<T> với khả biến nội bộ của
nó cung cấp cho chúng ta một kiểu mà chúng ta có thể sử dụng khi cần một kiểu
bất biến nhưng cần thay đổi giá trị bên trong của kiểu đó; nó cũng thực thi các
quy tắc mượn trong thời gian chạy thay vì tại thời điểm biên dịch.
Chúng ta cũng đã thảo luận về các trait Deref và Drop, cho phép nhiều chức
năng của con trỏ thông minh. Chúng ta đã khám phá các chu kỳ tham chiếu có thể
gây ra rò rỉ bộ nhớ và cách ngăn chặn chúng bằng cách sử dụng Weak<T>.
Nếu chương này đã kích thích sự quan tâm của bạn và bạn muốn triển khai con trỏ thông minh của riêng mình, hãy xem "The Rustonomicon" để biết thêm thông tin hữu ích.
Tiếp theo, chúng ta sẽ nói về đồng thời trong Rust. Bạn thậm chí sẽ tìm hiểu về một vài con trỏ thông minh mới.
Lập Trình Đồng Thời Không Lo Lắng
Xử lý lập trình đồng thời một cách an toàn và hiệu quả là một mục tiêu chính khác của Rust. Lập trình đồng thời (Concurrent programming), trong đó các phần khác nhau của chương trình thực thi độc lập, và lập trình song song (parallel programming), trong đó các phần khác nhau của chương trình thực thi cùng một lúc, đang ngày càng trở nên quan trọng khi ngày càng nhiều máy tính tận dụng nhiều bộ xử lý của chúng. Trong lịch sử, lập trình trong những bối cảnh này thường khó khăn và dễ gây lỗi. Rust hy vọng sẽ thay đổi điều đó.
Ban đầu, nhóm phát triển Rust nghĩ rằng đảm bảo an toàn bộ nhớ và ngăn chặn các vấn đề đồng thời là hai thách thức riêng biệt cần được giải quyết bằng các phương pháp khác nhau. Theo thời gian, nhóm đã phát hiện ra rằng hệ thống quyền sở hữu (ownership) và kiểu dữ liệu là một bộ công cụ mạnh mẽ để giúp quản lý cả an toàn bộ nhớ và các vấn đề đồng thời! Bằng cách tận dụng quyền sở hữu và kiểm tra kiểu, nhiều lỗi đồng thời trở thành lỗi thời điểm biên dịch trong Rust thay vì lỗi thời gian chạy. Do đó, thay vì khiến bạn tốn nhiều thời gian cố gắng tái hiện chính xác các trường hợp mà lỗi đồng thời thời gian chạy xảy ra, mã không đúng sẽ từ chối biên dịch và hiển thị lỗi giải thích vấn đề. Kết quả là, bạn có thể sửa mã của mình trong khi bạn đang làm việc với nó thay vì có thể phải sửa sau khi nó đã được triển khai vào sản xuất. Chúng tôi đã đặt biệt danh cho khía cạnh này của Rust là lập trình đồng thời không lo lắng (fearless concurrency). Lập trình đồng thời không lo lắng cho phép bạn viết mã không có lỗi tinh vi và dễ dàng tái cấu trúc mà không gây ra lỗi mới.
Lưu ý: Để đơn giản hóa, chúng tôi sẽ gọi nhiều vấn đề là đồng thời (concurrent) thay vì chính xác hơn bằng cách nói đồng thời và/hoặc song song (concurrent and/or parallel). Trong chương này, vui lòng thay thế trong đầu đồng thời và/hoặc song song bất cứ khi nào chúng tôi sử dụng đồng thời. Trong chương tiếp theo, nơi sự phân biệt quan trọng hơn, chúng tôi sẽ cụ thể hơn.
Nhiều ngôn ngữ rất giáo điều về các giải pháp họ cung cấp để xử lý các vấn đề đồng thời. Ví dụ, Erlang có chức năng thanh lịch cho đồng thời truyền tin nhắn nhưng chỉ có cách mơ hồ để chia sẻ trạng thái giữa các luồng. Việc chỉ hỗ trợ một tập con của các giải pháp có thể là một chiến lược hợp lý cho các ngôn ngữ cấp cao hơn bởi vì một ngôn ngữ cấp cao hơn hứa hẹn lợi ích từ việc từ bỏ một số kiểm soát để có được sự trừu tượng. Tuy nhiên, các ngôn ngữ cấp thấp hơn được kỳ vọng sẽ cung cấp giải pháp có hiệu suất tốt nhất trong bất kỳ tình huống nào và có ít sự trừu tượng hơn trên phần cứng. Do đó, Rust cung cấp nhiều công cụ để mô hình hóa vấn đề theo cách phù hợp với tình huống và yêu cầu của bạn.
Dưới đây là các chủ đề chúng ta sẽ đề cập trong chương này:
- Làm thế nào để tạo luồng để chạy nhiều phần mã cùng một lúc
- Đồng thời truyền tin (Message-passing concurrency), nơi các kênh gửi tin nhắn giữa các luồng
- Đồng thời trạng thái chia sẻ (Shared-state concurrency), nơi nhiều luồng có quyền truy cập vào một số phần dữ liệu
- Các trait
SyncvàSend, mở rộng các đảm bảo đồng thời của Rust cho các kiểu do người dùng định nghĩa cũng như các kiểu được cung cấp bởi thư viện chuẩn
Sử Dụng Luồng để Chạy Mã Đồng Thời
Trong hầu hết các hệ điều hành hiện đại, mã của một chương trình đã thực thi được chạy trong một quy trình (process), và hệ điều hành sẽ quản lý nhiều quy trình cùng một lúc. Trong một chương trình, bạn cũng có thể có các phần độc lập chạy đồng thời. Các tính năng chạy các phần độc lập này được gọi là luồng (threads). Ví dụ, một máy chủ web có thể có nhiều luồng để nó có thể phản hồi nhiều hơn một yêu cầu cùng một lúc.
Việc chia nhỏ tính toán trong chương trình của bạn thành nhiều luồng để chạy nhiều tác vụ cùng một lúc có thể cải thiện hiệu suất, nhưng nó cũng làm tăng độ phức tạp. Bởi vì các luồng có thể chạy đồng thời, không có đảm bảo cố hữu về thứ tự mà các phần mã của bạn trên các luồng khác nhau sẽ chạy. Điều này có thể dẫn đến các vấn đề, chẳng hạn như:
- Điều kiện tranh đua (Race conditions), trong đó các luồng đang truy cập dữ liệu hoặc tài nguyên theo thứ tự không nhất quán
- Bế tắc (Deadlocks), trong đó hai luồng đang chờ đợi nhau, ngăn cản cả hai luồng tiếp tục
- Lỗi chỉ xảy ra trong một số tình huống nhất định và khó tái tạo và sửa chữa một cách đáng tin cậy
Rust cố gắng giảm thiểu các tác động tiêu cực của việc sử dụng luồng, nhưng lập trình trong bối cảnh đa luồng vẫn cần suy nghĩ cẩn thận và yêu cầu cấu trúc mã khác với cấu trúc trong các chương trình chạy trong một luồng duy nhất.
Các ngôn ngữ lập trình triển khai luồng theo một vài cách khác nhau, và nhiều hệ điều hành cung cấp một API mà ngôn ngữ lập trình có thể gọi để tạo luồng mới. Thư viện chuẩn của Rust sử dụng mô hình 1:1 cho việc triển khai luồng, theo đó một chương trình sử dụng một luồng hệ điều hành cho mỗi một luồng ngôn ngữ. Có các crate triển khai các mô hình luồng khác có sự đánh đổi khác nhau so với mô hình 1:1. (Hệ thống async của Rust, mà chúng ta sẽ thấy trong chương tiếp theo, cung cấp một cách tiếp cận khác cho đồng thời.)
Tạo Luồng Mới với spawn
Để tạo một luồng mới, chúng ta gọi hàm thread::spawn và truyền cho nó một
closure (chúng ta đã nói về closure trong Chương 13) chứa mã mà chúng ta muốn
chạy trong luồng mới. Ví dụ trong Listing 16-1 in một số văn bản từ luồng chính
và văn bản khác từ một luồng mới.
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
Lưu ý rằng khi luồng chính của một chương trình Rust hoàn thành, tất cả các luồng được tạo ra đều bị tắt, cho dù chúng đã hoàn thành chạy hay chưa. Đầu ra từ chương trình này có thể hơi khác nhau mỗi lần, nhưng nó sẽ trông giống như sau:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Các lệnh gọi đến thread::sleep buộc một luồng dừng thực thi trong một khoảng
thời gian ngắn, cho phép một luồng khác chạy. Các luồng có thể sẽ lần lượt thay
phiên nhau, nhưng điều đó không được đảm bảo: nó phụ thuộc vào cách hệ điều hành
của bạn lên lịch các luồng. Trong lần chạy này, luồng chính in trước, mặc dù câu
lệnh in từ luồng được tạo ra xuất hiện đầu tiên trong mã. Và mặc dù chúng ta bảo
luồng được tạo ra in cho đến khi i là 9, nó chỉ đạt đến 5 trước khi luồng
chính tắt.
Nếu bạn chạy mã này và chỉ thấy đầu ra từ luồng chính, hoặc không thấy bất kỳ sự chồng chéo nào, hãy thử tăng số lượng trong các phạm vi để tạo thêm cơ hội cho hệ điều hành chuyển đổi giữa các luồng.
Chờ Tất Cả Các Luồng Hoàn Thành Bằng Cách Sử Dụng join Handles
Mã trong Listing 16-1 không chỉ dừng luồng được tạo ra sớm hơn dự kiến trong hầu hết thời gian do luồng chính kết thúc, mà còn vì không có đảm bảo về thứ tự chạy của các luồng, chúng ta cũng không thể đảm bảo rằng luồng được tạo ra sẽ có cơ hội chạy!
Chúng ta có thể khắc phục vấn đề luồng được tạo ra không chạy hoặc việc nó kết
thúc sớm bằng cách lưu giá trị trả về của thread::spawn trong một biến. Kiểu
trả về của thread::spawn là JoinHandle<T>. Một JoinHandle<T> là một giá
trị được sở hữu mà, khi chúng ta gọi phương thức join trên nó, sẽ chờ cho
luồng của nó kết thúc. Listing 16-2 hiển thị cách sử dụng JoinHandle<T> của
luồng mà chúng ta đã tạo trong Listing 16-1 và cách gọi join để đảm bảo luồng
được tạo ra hoàn thành trước khi main thoát.
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
Gọi join trên handle sẽ chặn luồng hiện đang chạy cho đến khi luồng được đại
diện bởi handle kết thúc. Chặn (Blocking) một luồng có nghĩa là luồng đó bị
ngăn không cho thực hiện công việc hoặc thoát. Bởi vì chúng ta đã đặt lệnh gọi
đến join sau vòng lặp for của luồng chính, việc chạy Listing 16-2 sẽ tạo ra
đầu ra tương tự như sau:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Hai luồng tiếp tục thay phiên nhau, nhưng luồng chính chờ đợi vì lời gọi đến
handle.join() và không kết thúc cho đến khi luồng được tạo ra hoàn thành.
Nhưng hãy xem điều gì xảy ra khi chúng ta thay vào đó di chuyển handle.join()
trước vòng lặp for trong main, như thế này:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
Luồng chính sẽ chờ luồng được tạo ra hoàn thành và sau đó chạy vòng lặp for
của nó, vì vậy đầu ra sẽ không còn xen kẽ nữa, như hiển thị ở đây:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Các chi tiết nhỏ, chẳng hạn như nơi join được gọi, có thể ảnh hưởng đến việc
các luồng của bạn có chạy cùng lúc hay không.
Sử Dụng Closure move với Luồng
Chúng ta thường sử dụng từ khóa move với closure được truyền cho
thread::spawn bởi vì closure sau đó sẽ lấy quyền sở hữu các giá trị mà nó sử
dụng từ môi trường, do đó chuyển quyền sở hữu của các giá trị đó từ một luồng
này sang luồng khác. Trong "Capturing References or Moving
Ownership" trong Chương 13, chúng ta đã thảo luận về
move trong bối cảnh closure. Bây giờ chúng ta sẽ tập trung nhiều hơn vào sự
tương tác giữa move và thread::spawn.
Lưu ý trong Listing 16-1 rằng closure mà chúng ta truyền cho thread::spawn
không nhận tham số nào: chúng ta không sử dụng bất kỳ dữ liệu nào từ luồng chính
trong mã của luồng được tạo ra. Để sử dụng dữ liệu từ luồng chính trong luồng
được tạo ra, closure của luồng được tạo ra phải bắt các giá trị mà nó cần.
Listing 16-3 hiển thị một nỗ lực tạo một vectơ trong luồng chính và sử dụng nó
trong luồng được tạo ra. Tuy nhiên, điều này chưa hoạt động được, như bạn sẽ
thấy trong một lúc nữa.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Closure sử dụng v, vì vậy nó sẽ bắt v và làm cho nó trở thành một phần của
môi trường của closure. Bởi vì thread::spawn chạy closure này trong một luồng
mới, chúng ta nên có thể truy cập v bên trong luồng mới đó. Nhưng khi chúng ta
biên dịch ví dụ này, chúng ta nhận được lỗi sau:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust suy luận cách bắt v, và bởi vì println! chỉ cần một tham chiếu đến
v, closure cố gắng mượn v. Tuy nhiên, có một vấn đề: Rust không thể biết
luồng được tạo ra sẽ chạy trong bao lâu, vì vậy nó không biết có phải tham chiếu
đến v sẽ luôn hợp lệ hay không.
Listing 16-4 cung cấp một kịch bản mà có khả năng cao hơn có một tham chiếu đến
v mà sẽ không hợp lệ.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}Nếu Rust cho phép chúng ta chạy mã này, có khả năng rằng luồng được tạo ra sẽ
ngay lập tức bị đặt vào nền mà không chạy chút nào. Luồng được tạo ra có một
tham chiếu đến v bên trong, nhưng luồng chính ngay lập tức làm rơi v, sử
dụng hàm drop mà chúng ta đã thảo luận trong Chương 15. Sau đó, khi luồng được
tạo ra bắt đầu thực thi, v không còn hợp lệ nữa, vì vậy một tham chiếu đến nó
cũng không hợp lệ. Ôi không!
Để sửa lỗi trình biên dịch trong Listing 16-3, chúng ta có thể sử dụng lời khuyên từ thông báo lỗi:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Bằng cách thêm từ khóa move trước closure, chúng ta buộc closure lấy quyền sở
hữu các giá trị mà nó đang sử dụng thay vì để Rust suy luận rằng nó nên mượn các
giá trị. Sửa đổi Listing 16-3 như trong Listing 16-5 sẽ biên dịch và chạy như
chúng ta dự định.
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {v:?}"); }); handle.join().unwrap(); }
Chúng ta có thể bị cám dỗ để thử cùng một điều để sửa mã trong Listing 16-4 nơi
luồng chính gọi drop bằng cách sử dụng một closure move. Tuy nhiên, cách sửa
này sẽ không hoạt động vì những gì Listing 16-4 đang cố gắng làm bị cấm vì lý do
khác. Nếu chúng ta thêm move vào closure, chúng ta sẽ di chuyển v vào môi
trường của closure, và chúng ta không thể gọi drop trên nó trong luồng chính
nữa. Chúng ta sẽ nhận được lỗi trình biên dịch này thay thế:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Các quy tắc sở hữu của Rust đã cứu chúng ta một lần nữa! Chúng ta nhận được lỗi
từ mã trong Listing 16-3 vì Rust đang bảo thủ và chỉ mượn v cho luồng, điều đó
có nghĩa là luồng chính có thể theo lý thuyết làm mất hiệu lực tham chiếu của
luồng được tạo ra. Bằng cách nói với Rust để chuyển quyền sở hữu của v cho
luồng được tạo ra, chúng ta đang đảm bảo với Rust rằng luồng chính sẽ không sử
dụng v nữa. Nếu chúng ta thay đổi Listing 16-4 theo cùng một cách, chúng ta sẽ
vi phạm các quy tắc sở hữu khi chúng ta cố gắng sử dụng v trong luồng chính.
Từ khóa move ghi đè mặc định bảo thủ của Rust về việc mượn; nó không cho phép
chúng ta vi phạm các quy tắc sở hữu.
Bây giờ chúng ta đã đề cập những gì là luồng và các phương thức được cung cấp bởi API luồng, hãy xem một số tình huống mà chúng ta có thể sử dụng luồng.
Sử Dụng Trao Đổi Tin Nhắchúng ta sẽ gửi các giá trị đơn giản giữa các thread bằng một kênh để minh họa tính
năng này. Khi bạn đã quen với kỹ thuật này, bạn có thể sử dụng các kênh cho bất kỳ thread nào cần giao tiếp với nhau, chẳng hạn như một hệ thống chat hoặc một hệ thống mà nhiều thread thực hiện các phần của một phép tính và gửi các phần đó đến một thread tổng hợp kết quả.Truyền Dữ Liệu Giữa Các Thread
Một cách tiếp cận ngày càng phổ biến để đảm bảo đồng thời an toàn là trao đổi tin nhắn (message passing), trong đó các thread hoặc actor giao tiếp bằng cách gửi tin nhắn chứa dữ liệu cho nhau. Đây là ý tưởng được tóm tắt trong một khẩu hiệu từ tài liệu của ngôn ngữ Go: "Đừng giao tiếp bằng cách chia sẻ bộ nhớ; thay vào đó, hãy chia sẻ bộ nhớ bằng cách giao tiếp."
Để thực hiện tính đồng thời bằng cách gửi tin nhắn, thư viện chuẩn của Rust cung cấp một cài đặt của các kênh (channels). Một kênh là một khái niệm lập trình chung mà qua đó dữ liệu được gửi từ một thread sang thread khác.
Bạn có thể tưởng tượng một kênh trong lập trình giống như một kênh nước một chiều, chẳng hạn như một dòng suối hoặc một con sông. Nếu bạn đặt một vật gì đó như một con vịt cao su vào sông, nó sẽ trôi xuôi dòng đến cuối đường thủy.
Một kênh có hai nửa: một bộ phát (transmitter) và một bộ thu (receiver). Nửa bộ phát là vị trí thượng nguồn nơi bạn đặt con vịt cao su vào sông, và nửa bộ thu là nơi con vịt cao su kết thúc ở hạ nguồn. Một phần của mã của bạn gọi các phương thức trên bộ phát với dữ liệu bạn muốn gửi, và một phần khác kiểm tra đầu nhận để tìm các tin nhắn đến. Một kênh được gọi là đóng (closed) nếu một trong hai nửa bộ phát hoặc bộ thu bị loại bỏ.
Ở đây, chúng ta sẽ xây dựng một chương trình có một thread để tạo giá trị và gửi chúng qua một kênh, và một thread khác sẽ nhận các giá trị và in chúng ra. Chúng ta sẽ gửi các giá trị đơn giản giữa các thread bằng một kênh để minh họa tính năng này. Khi bạn đã quen với kỹ thuật này, bạn có thể sử dụng các kênh cho bất kỳ thread nào cần giao tiếp với nhau, chẳng hạn như một hệ thống chat hoặc một hệ thống mà nhiều thread thực hiện các phần của một phép tính và gửi các phần đó đến một thread tổng hợp kết quả.
Đầu tiên, trong Listing 16-6, chúng ta sẽ tạo một kênh nhưng chưa làm gì với nó. Lưu ý rằng đoạn mã này chưa thể biên dịch được vì Rust không thể xác định loại giá trị mà chúng ta muốn gửi qua kênh.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Chúng ta tạo một kênh mới bằng hàm mpsc::channel; mpsc là viết tắt của
multiple producer, single consumer (nhiều người sản xuất, một người tiêu
dùng). Nói ngắn gọn, cách thư viện chuẩn của Rust triển khai các kênh có nghĩa
là một kênh có thể có nhiều đầu gửi tạo ra giá trị nhưng chỉ một đầu nhận
tiêu thụ những giá trị đó. Hãy tưởng tượng nhiều dòng suối chảy vào một con sông
lớn: mọi thứ được gửi xuống bất kỳ dòng suối nào đều sẽ kết thúc trong một con
sông ở cuối. Hiện tại chúng ta sẽ bắt đầu với một nhà sản xuất duy nhất, nhưng
chúng ta sẽ thêm nhiều nhà sản xuất khi làm cho ví dụ này hoạt động.
Hàm mpsc::channel trả về một tuple, phần tử đầu tiên là đầu gửi - bộ phát - và
phần tử thứ hai là đầu nhận - bộ thu. Các chữ viết tắt tx và rx theo truyền
thống được sử dụng trong nhiều lĩnh vực cho transmitter (bộ phát) và
receiver (bộ thu) tương ứng, vì vậy chúng ta đặt tên cho các biến của mình như vậy để
chỉ ra mỗi đầu. Chúng ta đang sử dụng câu lệnh let với một mẫu phân rã tuple;
chúng ta sẽ thảo luận về việc sử dụng các mẫu trong câu lệnh let và phân rã
trong Chương 19. Hiện tại, hãy biết rằng sử dụng câu lệnh let như thế này là
một phương pháp thuận tiện để trích xuất các phần của tuple được trả về bởi
mpsc::channel.
Hãy chuyển đầu phát vào một thread được tạo ra và có nó gửi một chuỗi để thread được tạo ra giao tiếp với thread chính, như được hiển thị trong Listing 16-7. Điều này giống như đặt một con vịt cao su vào sông ở thượng nguồn hoặc gửi một tin nhắn trò chuyện từ một thread sang thread khác.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); }
Một lần nữa, chúng ta đang sử dụng thread::spawn để tạo một thread mới và sau
đó sử dụng move để di chuyển tx vào closure để thread được tạo ra sở hữu
tx. Thread được tạo ra cần sở hữu bộ phát để có thể gửi tin nhắn thông qua
kênh.
Bộ phát có một phương thức send nhận giá trị mà chúng ta muốn gửi. Phương thức
send trả về một kiểu Result<T, E>, vì vậy nếu bộ thu đã bị loại bỏ và không
có nơi nào để gửi giá trị, thao tác gửi sẽ trả về một lỗi. Trong ví dụ này,
chúng ta đang gọi unwrap để panic trong trường hợp có lỗi. Nhưng trong một ứng
dụng thực tế, chúng ta sẽ xử lý nó đúng cách: quay lại Chương 9 để xem lại các
chiến lược xử lý lỗi đúng cách.
Trong Listing 16-8, chúng ta sẽ nhận giá trị từ bộ thu trong thread chính. Điều này giống như lấy con vịt cao su từ nước ở cuối sông hoặc nhận một tin nhắn trò chuyện.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); let received = rx.recv().unwrap(); println!("Got: {received}"); }
Bộ thu có hai phương thức hữu ích: recv và try_recv. Chúng ta đang sử dụng
recv, viết tắt của receive, sẽ chặn thực thi của thread chính và đợi cho đến
khi một giá trị được gửi xuống kênh. Khi một giá trị được gửi, recv sẽ trả về
nó trong một Result<T, E>. Khi bộ phát đóng, recv sẽ trả về một lỗi để báo
hiệu rằng không có thêm giá trị nào sẽ đến.
Phương thức try_recv không chặn, nhưng thay vào đó sẽ trả về một
Result<T, E> ngay lập tức: một giá trị Ok chứa một tin nhắn nếu có sẵn và
một giá trị Err nếu không có tin nhắn nào vào lúc này. Sử dụng try_recv rất
hữu ích nếu thread này có công việc khác cần làm trong khi chờ tin nhắn: chúng
ta có thể viết một vòng lặp gọi try_recv thường xuyên, xử lý một tin nhắn nếu
có, và nếu không thì làm việc khác trong một thời gian ngắn cho đến khi kiểm tra
lại.
Chúng ta đã sử dụng recv trong ví dụ này để đơn giản hóa; chúng ta không có
công việc nào khác cho thread chính để làm ngoài việc đợi tin nhắn, vì vậy việc
chặn thread chính là phù hợp.
Khi chúng ta chạy mã trong Listing 16-8, chúng ta sẽ thấy giá trị được in ra từ thread chính:
Got: hi
Hoàn hảo!
Kênh và Chuyển Giao Quyền Sở Hữu
Các quy tắc sở hữu đóng vai trò quan trọng trong việc gửi tin nhắn vì chúng giúp
bạn viết mã đồng thời an toàn. Ngăn chặn lỗi trong lập trình đồng thời là lợi
thế của việc suy nghĩ về quyền sở hữu trong toàn bộ chương trình Rust của bạn.
Hãy thực hiện một thí nghiệm để hiển thị cách kênh và quyền sở hữu hoạt động
cùng nhau để ngăn chặn vấn đề: chúng ta sẽ cố gắng sử dụng một giá trị val
trong thread được tạo ra sau khi chúng ta đã gửi nó xuống kênh. Hãy thử biên
dịch mã trong Listing 16-9 để xem tại sao mã này không được phép.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}Ở đây, chúng ta cố gắng in val sau khi đã gửi nó xuống kênh thông qua
tx.send. Cho phép điều này sẽ là một ý tưởng tồi: một khi giá trị đã được gửi
đến một thread khác, thread đó có thể sửa đổi hoặc loại bỏ nó trước khi chúng ta
cố gắng sử dụng lại giá trị. Có thể, các sửa đổi của thread khác có thể gây ra
lỗi hoặc kết quả không mong muốn do dữ liệu không nhất quán hoặc không tồn tại.
Tuy nhiên, Rust đưa ra một lỗi nếu chúng ta cố gắng biên dịch mã trong Listing
16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Lỗi đồng thời của chúng ta đã gây ra một lỗi thời điểm biên dịch. Hàm send lấy quyền sở
hữu tham số của nó, và khi giá trị được chuyển đi bộ thu nhận quyền sở hữu của
nó. Điều này ngăn chúng ta vô tình sử dụng lại giá trị sau khi gửi nó; hệ thống
sở hữu kiểm tra rằng mọi thứ đều ổn.
Gửi Nhiều Giá Trị và Theo Dõi Bộ Thu Đang Chờ Đợi
Mã trong Listing 16-8 đã được biên dịch và chạy, nhưng nó không hiển thị rõ ràng cho chúng ta thấy rằng hai thread riêng biệt đang nói chuyện với nhau qua kênh.
Trong Listing 16-10, chúng ta đã thực hiện một số sửa đổi sẽ chứng minh rằng mã trong Listing 16-8 đang chạy đồng thời: thread được tạo ra sẽ gửi nhiều tin nhắn và tạm dừng một giây giữa mỗi tin nhắn.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}Lần này, thread được tạo ra có một vector chuỗi mà chúng ta muốn gửi đến thread
chính. Chúng ta lặp qua chúng, gửi từng cái riêng lẻ, và tạm dừng giữa mỗi lần
bằng cách gọi hàm thread::sleep với một giá trị Duration một giây.
Trong thread chính, chúng ta không còn gọi hàm recv một cách rõ ràng nữa: thay
vào đó, chúng ta đang xử lý rx như một iterator. Đối với mỗi giá trị nhận
được, chúng ta đang in nó ra. Khi kênh đóng, việc lặp sẽ kết thúc.
Khi chạy mã trong Listing 16-10, bạn sẽ thấy đầu ra sau với khoảng dừng một giây giữa mỗi dòng:
Got: hi
Got: from
Got: the
Got: thread
Bởi vì chúng ta không có bất kỳ mã nào tạm dừng hoặc trì hoãn trong vòng lặp
for trong thread chính, chúng ta có thể biết rằng thread chính đang đợi để
nhận giá trị từ thread được tạo ra.
Tạo Nhiều Nhà Sản Xuất bằng cách Sao Chép Bộ Phát
Trước đó chúng ta đã đề cập rằng mpsc là từ viết tắt của multiple producer,
single consumer (nhiều nhà sản xuất, một người tiêu dùng). Hãy sử dụng mpsc
và mở rộng mã trong Listing 16-10 để tạo nhiều thread đều gửi giá trị đến cùng
một bộ thu. Chúng ta có thể làm như vậy bằng cách sao chép bộ phát, như được
hiển thị trong Listing 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}Lần này, trước khi chúng ta tạo thread đầu tiên, chúng ta gọi clone trên bộ
phát. Điều này sẽ cung cấp cho chúng ta một bộ phát mới mà chúng ta có thể
truyền cho thread được tạo ra đầu tiên. Chúng ta truyền bộ phát gốc cho thread
thứ hai được tạo ra. Điều này cung cấp cho chúng ta hai thread, mỗi thread gửi
các tin nhắn khác nhau đến một bộ thu.
Khi bạn chạy mã, đầu ra của bạn sẽ trông giống như thế này:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
Bạn có thể thấy các giá trị theo thứ tự khác, tùy thuộc vào hệ thống của bạn.
Đây là điều làm cho tính đồng thời vừa thú vị vừa khó khăn. Nếu bạn thử nghiệm
với thread::sleep, cung cấp cho nó các giá trị khác nhau trong các thread khác
nhau, mỗi lần chạy sẽ không xác định hơn và tạo ra đầu ra khác nhau mỗi lần.
Bây giờ chúng ta đã xem xét cách kênh hoạt động, hãy xem xét một phương pháp đồng thời khác.
Đồng Thời với Trạng Thái Được Chia Sẻ
Truyền tin nhắn là một cách tốt để xử lý tính đồng thời, nhưng không phải là cách duy nhất. Một phương pháp khác là cho phép nhiều thread truy cập cùng một dữ liệu được chia sẻ. Hãy xem xét phần này từ khẩu hiệu trong tài liệu ngôn ngữ Go một lần nữa: "Đừng giao tiếp bằng cách chia sẻ bộ nhớ."
Giao tiếp bằng cách chia sẻ bộ nhớ sẽ trông như thế nào? Ngoài ra, tại sao những người đam mê phương pháp truyền tin nhắn lại khuyên không nên sử dụng việc chia sẻ bộ nhớ?
Theo một cách nào đó, các kênh trong bất kỳ ngôn ngữ lập trình nào cũng tương tự như quyền sở hữu đơn bởi vì một khi bạn truyền một giá trị xuống kênh, bạn không nên sử dụng giá trị đó nữa. Đồng thời với bộ nhớ được chia sẻ giống như quyền sở hữu đa: nhiều thread có thể truy cập cùng một vị trí bộ nhớ tại cùng một thời điểm. Như bạn đã thấy trong Chương 15, nơi các con trỏ thông minh làm cho quyền sở hữu đa trở nên khả thi, quyền sở hữu đa có thể thêm độ phức tạp vì các chủ sở hữu khác nhau này cần được quản lý. Hệ thống kiểu và quy tắc sở hữu của Rust hỗ trợ rất nhiều trong việc quản lý này một cách chính xác. Ví dụ, hãy xem xét mutex, một trong những nguyên thủy đồng thời phổ biến nhất cho bộ nhớ được chia sẻ.
Sử Dụng Mutex để Cho Phép Truy Cập Dữ Liệu từ Một Thread tại Một Thời Điểm
Mutex là viết tắt của mutual exclusion (loại trừ tương hỗ), nghĩa là một mutex chỉ cho phép một thread truy cập một số dữ liệu tại bất kỳ thời điểm nào. Để truy cập dữ liệu trong một mutex, một thread trước tiên phải báo hiệu rằng nó muốn truy cập bằng cách yêu cầu có được khóa của mutex. Khóa là một cấu trúc dữ liệu là một phần của mutex, giúp theo dõi ai hiện đang có quyền truy cập độc quyền vào dữ liệu. Do đó, mutex được mô tả là bảo vệ dữ liệu mà nó chứa thông qua hệ thống khóa.
Mutex có tiếng là khó sử dụng vì bạn phải nhớ hai quy tắc:
- Bạn phải cố gắng có được khóa trước khi sử dụng dữ liệu.
- Khi bạn đã hoàn thành việc sử dụng dữ liệu mà mutex bảo vệ, bạn phải mở khóa dữ liệu để các thread khác có thể có được khóa.
Để có một phép ẩn dụ thực tế cho mutex, hãy tưởng tượng một cuộc thảo luận tại một hội nghị với chỉ một micro. Trước khi một người tham gia có thể nói chuyện, họ phải yêu cầu hoặc báo hiệu rằng họ muốn sử dụng micro. Khi họ nhận được micro, họ có thể nói chuyện trong bao lâu tùy thích và sau đó chuyển micro cho người tham gia tiếp theo muốn phát biểu. Nếu một người tham gia quên chuyển micro khi họ đã nói xong, không ai khác có thể nói chuyện. Nếu việc quản lý micro được chia sẻ bị sai, cuộc thảo luận sẽ không diễn ra như dự kiến!
Việc quản lý mutex có thể rất khó để làm đúng, đó là lý do tại sao rất nhiều người đam mê sử dụng kênh. Tuy nhiên, nhờ có hệ thống kiểu và quy tắc sở hữu của Rust, bạn không thể khóa và mở khóa sai.
API của Mutex<T>
Để làm ví dụ về cách sử dụng mutex, hãy bắt đầu bằng cách sử dụng mutex trong một ngữ cảnh đơn thread, như trong Listing 16-12.
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {m:?}"); }
Giống như nhiều kiểu, chúng ta tạo một Mutex<T> bằng cách sử dụng hàm liên kết
new. Để truy cập dữ liệu bên trong mutex, chúng ta sử dụng phương thức lock
để có được khóa. Lệnh gọi này sẽ chặn thread hiện tại nên nó không thể làm bất
kỳ công việc nào cho đến khi đến lượt chúng ta có khóa.
Lệnh gọi đến lock sẽ thất bại nếu một thread khác đang giữ khóa bị panic.
Trong trường hợp đó, không ai có thể có được khóa, vì vậy chúng ta đã chọn
unwrap và có thread này panic nếu chúng ta ở trong tình huống đó.
Sau khi chúng ta đã có được khóa, chúng ta có thể coi giá trị trả về, có tên là
num trong trường hợp này, như một tham chiếu có thể thay đổi đến dữ liệu bên
trong. Hệ thống kiểu đảm bảo rằng chúng ta có được khóa trước khi sử dụng giá
trị trong m. Kiểu của m là Mutex<i32>, không phải i32, vì vậy chúng ta
phải gọi lock để có thể sử dụng giá trị i32. Chúng ta không thể quên; hệ
thống kiểu sẽ không cho phép chúng ta truy cập giá trị i32 bên trong nếu
không.
Lệnh gọi đến lock trả về một kiểu được gọi là MutexGuard,
được bọc trong một LockResult mà chúng ta đã xử lý bằng cách gọi unwrap. Kiểu MutexGuard
thực hiện Deref để trỏ đến dữ liệu bên trong của
chúng ta; kiểu này cũng có một triển khai Drop giải phóng khóa một
cách tự động khi MutexGuard ra khỏi phạm vi, điều này xảy ra vào cuối phạm vi
bên trong. Kết quả là, chúng ta không có nguy cơ quên giải phóng khóa và chặn
mutex không được sử dụng bởi các thread khác vì việc giải phóng khóa xảy ra tự
động.
Sau khi thả khóa, chúng ta có thể in giá trị mutex và thấy rằng chúng ta đã có
thể thay đổi giá trị i32 bên trong thành 6.
Chia Sẻ Mutex<T> Giữa Nhiều Thread
Bây giờ hãy thử chia sẻ một giá trị giữa nhiều thread bằng cách sử dụng
Mutex<T>. Chúng ta sẽ tạo 10 thread và có mỗi thread tăng giá trị bộ đếm lên
1, vì vậy bộ đếm sẽ tăng từ 0 lên 10. Ví dụ trong Listing 16-13 sẽ có lỗi trình
biên dịch, và chúng ta sẽ sử dụng lỗi đó để tìm hiểu thêm về cách sử dụng
Mutex<T> và cách Rust giúp chúng ta sử dụng nó đúng cách.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Chúng ta tạo một biến counter để chứa một i32 bên trong một Mutex<T>, như
chúng ta đã làm trong Listing 16-12. Tiếp theo, chúng ta tạo 10 thread bằng cách
lặp qua một dãy số. Chúng ta sử dụng thread::spawn và cung cấp cho tất cả các
thread cùng một closure: closure di chuyển bộ đếm vào thread, lấy khóa trên
Mutex<T> bằng cách gọi phương thức lock, và sau đó cộng 1 vào giá trị trong
mutex. Khi một thread hoàn thành việc chạy closure của nó, num sẽ ra khỏi phạm
vi và giải phóng khóa để thread khác có thể lấy khóa.
Trong thread chính, chúng ta thu thập tất cả các handle join. Sau đó, như chúng
ta đã làm trong Listing 16-2, chúng ta gọi join trên mỗi handle để đảm bảo tất
cả các thread đều hoàn thành. Tại thời điểm đó, thread chính sẽ có được khóa và
in kết quả của chương trình này.
Chúng ta đã gợi ý rằng ví dụ này sẽ không biên dịch. Bây giờ hãy tìm hiểu tại sao!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Thông báo lỗi nói rằng giá trị counter đã được di chuyển trong lần lặp trước
của vòng lặp. Rust đang nói với chúng ta rằng chúng ta không thể di chuyển quyền
sở hữu của counter vào nhiều thread. Hãy sửa lỗi trình biên dịch bằng
phương pháp sở hữu đa mà chúng ta đã thảo luận trong Chương 15.
Sở Hữu Đa với Nhiều Thread
Trong Chương 15, chúng ta đã cung cấp một giá trị cho nhiều chủ sở hữu bằng cách sử
dụng con trỏ thông minh Rc<T> để tạo một giá trị được đếm tham chiếu. Hãy làm
tương tự ở đây và xem điều gì xảy ra. Chúng ta sẽ bọc Mutex<T> trong Rc<T>
trong Listing 16-14 và sao chép Rc<T> trước khi di chuyển quyền sở hữu vào
thread.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Một lần nữa, chúng ta biên dịch và nhận được... các lỗi khác nhau! Trình biên dịch đang dạy chúng ta rất nhiều.
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Wow, thông báo lỗi đó rất dài dòng! Đây là phần quan trọng cần tập trung:
`Rc<Mutex<i32>>` không thể được gửi giữa các thread một cách an toàn.
Trình biên dịch cũng đang nói với chúng ta lý do tại sao:
đặc tính `Send` không được triển khai cho `Rc<Mutex<i32>>`. Chúng ta sẽ
nói về Send trong phần tiếp theo: đó là một trong những đặc tính đảm bảo rằng
các kiểu mà chúng ta sử dụng với thread được thiết kế để sử dụng trong các tình
huống đồng thời.
Thật không may, Rc<T> không an toàn để chia sẻ giữa các thread. Khi Rc<T>
quản lý số lượng tham chiếu, nó cộng vào số lượng cho mỗi lệnh gọi clone và
trừ từ số lượng khi mỗi bản sao được loại bỏ. Nhưng nó không sử dụng bất kỳ
nguyên thủy đồng thời nào để đảm bảo rằng các thay đổi đối với số lượng không
thể bị gián đoạn bởi một thread khác. Điều này có thể dẫn đến số lượng sai - các
lỗi tinh vi có thể dẫn đến rò rỉ bộ nhớ hoặc một giá trị bị loại bỏ trước khi
chúng ta hoàn thành với nó. Những gì chúng ta cần là một kiểu giống hệt như
Rc<T>, nhưng thực hiện thay đổi số lượng tham chiếu theo cách an toàn với
thread.
Đếm Tham Chiếu Nguyên Tử với Arc<T>
May mắn thay, Arc<T> là một kiểu giống như Rc<T> mà an toàn để sử dụng
trong các tình huống đồng thời. Chữ a là viết tắt của atomic (nguyên tử), có
nghĩa là nó là một kiểu đếm tham chiếu nguyên tử. Nguyên tử là một loại nguyên
thủy đồng thời bổ sung mà chúng ta sẽ không đề cập chi tiết ở đây: xem tài liệu
thư viện chuẩn cho std::sync::atomic để biết thêm chi
tiết. Tại thời điểm này, bạn chỉ cần biết rằng nguyên tử hoạt động giống như các
kiểu nguyên thủy nhưng an toàn để chia sẻ giữa các thread.
Bạn có thể thắc mắc tại sao tất cả các kiểu nguyên thủy không phải là nguyên tử
và tại sao các kiểu thư viện chuẩn không được triển khai để sử dụng Arc<T>
theo mặc định. Lý do là vì an toàn thread đi kèm với một mức phạt hiệu suất mà
bạn chỉ muốn trả khi thực sự cần. Nếu bạn chỉ thực hiện các thao tác trên các
giá trị trong một thread duy nhất, mã của bạn có thể chạy nhanh hơn nếu nó không
phải thực thi các bảo đảm mà nguyên tử cung cấp.
Hãy quay lại ví dụ của chúng ta: Arc<T> và Rc<T> có cùng một API, vì vậy
chúng ta sửa chương trình của mình bằng cách thay đổi dòng use, lệnh gọi đến
new, và lệnh gọi đến clone. Mã trong Listing 16-15 cuối cùng sẽ biên dịch và
chạy.
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
Mã này sẽ in ra như sau:
Result: 10
Chúng ta đã làm được! Chúng ta đã đếm từ 0 đến 10, điều này có vẻ không quá ấn
tượng, nhưng nó đã dạy chúng ta rất nhiều về Mutex<T> và an toàn thread. Bạn
cũng có thể sử dụng cấu trúc chương trình này để thực hiện các thao tác phức tạp
hơn chỉ là tăng bộ đếm. Sử dụng chiến lược này, bạn có thể chia một phép tính
thành các phần độc lập, chia các phần đó giữa các thread, và sau đó sử dụng
Mutex<T> để có mỗi thread cập nhật kết quả cuối cùng với phần của nó.
Lưu ý rằng nếu bạn đang thực hiện các phép toán số đơn giản, có các kiểu đơn
giản hơn Mutex<T> được cung cấp bởi mô-đun std::sync::atomic của thư viện
chuẩn. Các kiểu này cung cấp truy cập an toàn, đồng
thời, nguyên tử vào các kiểu nguyên thủy. Chúng ta đã chọn sử dụng Mutex<T>
với một kiểu nguyên thủy cho ví dụ này để chúng ta có thể tập trung vào cách
Mutex<T> hoạt động.
Sự Tương Đồng Giữa RefCell<T>/Rc<T> và Mutex<T>/Arc<T>
Bạn có thể đã nhận thấy rằng counter không thể thay đổi nhưng chúng ta có thể
nhận được một tham chiếu có thể thay đổi đến giá trị bên trong nó; điều này có
nghĩa là Mutex<T> cung cấp khả năng thay đổi nội bộ, giống như họ Cell làm.
Theo cách tương tự, chúng ta đã sử dụng RefCell<T> trong Chương 15 để cho phép
chúng ta thay đổi nội dung bên trong Rc<T>, chúng ta sử dụng Mutex<T> để
thay đổi nội dung bên trong Arc<T>.
Một chi tiết khác cần lưu ý là Rust không thể bảo vệ bạn khỏi tất cả các loại
lỗi logic khi bạn sử dụng Mutex<T>. Nhớ lại từ Chương 15 rằng việc sử dụng
Rc<T> đi kèm với nguy cơ tạo ra các chu kỳ tham chiếu, trong đó hai giá trị
Rc<T> tham chiếu đến nhau, gây ra rò rỉ bộ nhớ. Tương tự, Mutex<T> đi kèm
với nguy cơ tạo ra deadlocks (bế tắc). Những điều này xảy ra khi một thao tác
cần khóa hai tài nguyên và hai thread mỗi cái đã có được một trong các khóa,
khiến chúng đợi nhau mãi mãi. Nếu bạn quan tâm đến deadlocks, hãy thử tạo một
chương trình Rust có deadlock; sau đó nghiên cứu các chiến lược giảm thiểu
deadlock cho mutex trong bất kỳ ngôn ngữ nào và thử triển khai chúng trong Rust.
Tài liệu API của thư viện chuẩn cho Mutex<T> và MutexGuard cung cấp thông
tin hữu ích.
Chúng ta sẽ kết thúc chương này bằng cách nói về các đặc tính Send và Sync
và cách chúng ta có thể sử dụng chúng với các kiểu tùy chỉnh.
Đồng Thời Mở Rộng với Các Đặc Tính Send và Sync
Điều thú vị là, hầu hết các tính năng đồng thời mà chúng ta đã nói đến trong chương này đều là một phần của thư viện chuẩn, không phải ngôn ngữ. Lựa chọn của bạn để xử lý tính đồng thời không bị giới hạn ở ngôn ngữ hoặc thư viện chuẩn; bạn có thể viết các tính năng đồng thời của riêng mình hoặc sử dụng những tính năng được viết bởi người khác.
Tuy nhiên, trong số các khái niệm đồng thời quan trọng được nhúng vào ngôn ngữ
thay vì thư viện chuẩn là các đặc tính std::marker là Send và Sync.
Cho Phép Chuyển Giao Quyền Sở Hữu Giữa Các Thread với Send
Đặc tính đánh dấu Send chỉ ra rằng quyền sở hữu của các giá trị thuộc kiểu
triển khai Send có thể được chuyển giao giữa các thread. Hầu hết mọi kiểu Rust
triển khai Send, nhưng có một số ngoại lệ, bao gồm Rc<T>: kiểu này không thể
triển khai Send vì nếu bạn sao chép một giá trị Rc<T> và cố gắng chuyển
quyền sở hữu của bản sao đó sang một thread khác, cả hai thread có thể cập nhật
số lượng tham chiếu cùng một lúc. Vì lý do này, Rc<T> được triển khai để sử
dụng trong các tình huống đơn thread, nơi bạn không muốn trả giá cho hiệu suất
an toàn thread.
Do đó, hệ thống kiểu và ràng buộc đặc tính của Rust đảm bảo rằng bạn không bao
giờ vô tình gửi một giá trị Rc<T> qua các thread một cách không an toàn. Khi
chúng ta cố gắng làm điều này trong Listing 16-14, chúng ta đã nhận được lỗi
the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Khi chúng ta
chuyển sang Arc<T>, vốn triển khai Send, mã đã biên dịch thành công.
Bất kỳ kiểu nào được tạo thành hoàn toàn từ các kiểu Send cũng tự động được
đánh dấu là Send. Hầu hết tất cả các kiểu nguyên thủy triển khai Send, ngoại
trừ con trỏ thô, thứ mà chúng ta sẽ thảo luận trong Chương 20.
Cho Phép Truy Cập từ Nhiều Thread với Sync
Đặc tính đánh dấu Sync chỉ ra rằng kiểu triển khai Sync an toàn để được tham
chiếu từ nhiều thread. Nói cách khác, bất kỳ kiểu T nào triển khai Sync nếu
&T (một tham chiếu không thay đổi đến T) triển khai Send, nghĩa là tham
chiếu có thể được gửi an toàn đến một thread khác. Tương tự như Send, tất cả
các kiểu nguyên thủy đều triển khai Sync, và các kiểu được tạo thành hoàn toàn
từ các kiểu triển khai Sync cũng triển khai Sync.
Con trỏ thông minh Rc<T> cũng không triển khai Sync vì cùng những lý do mà
nó không triển khai Send. Kiểu RefCell<T> (mà chúng ta đã nói đến trong
Chương 15) và họ các kiểu Cell<T> liên quan không triển khai Sync. Việc
triển khai kiểm tra mượn mà RefCell<T> thực hiện trong thời gian chạy không an
toàn cho thread. Con trỏ thông minh Mutex<T> triển khai Sync và có thể được
sử dụng để chia sẻ quyền truy cập với nhiều thread, như bạn đã thấy trong "Chia
Sẻ Mutex<T> Giữa Nhiều
Thread".
Triển Khai Send và Sync Thủ Công Là Không An Toàn
Vì các kiểu được tạo thành hoàn toàn từ các kiểu khác triển khai các đặc tính
Send và Sync cũng tự động triển khai Send và Sync, chúng ta không cần
phải triển khai những đặc tính này thủ công. Là các đặc tính đánh dấu, chúng
thậm chí không có bất kỳ phương thức nào để triển khai. Chúng chỉ hữu ích để
thực thi các bất biến liên quan đến tính đồng thời.
Việc triển khai thủ công các đặc tính này liên quan đến việc triển khai mã Rust
không an toàn. Chúng ta sẽ nói về việc sử dụng mã Rust không an toàn trong
Chương 20; hiện tại, thông tin quan trọng là việc xây dựng các kiểu đồng thời
mới không được tạo từ các phần Send và Sync đòi hỏi suy nghĩ cẩn thận để duy
trì các đảm bảo an toàn. "The Rustonomicon" có thêm thông tin về các
đảm bảo này và cách để duy trì chúng.
Tóm Tắt
Đây không phải là lần cuối cùng bạn thấy tính đồng thời trong cuốn sách này: chương tiếp theo tập trung vào lập trình bất đồng bộ, và dự án trong Chương 21 sẽ sử dụng các khái niệm trong chương này trong một tình huống thực tế hơn so với các ví dụ nhỏ được thảo luận ở đây.
Như đã đề cập trước đó, vì rất ít phần trong cách Rust xử lý tính đồng thời là một phần của ngôn ngữ, nhiều giải pháp đồng thời được triển khai dưới dạng các crate. Những crate này phát triển nhanh hơn so với thư viện chuẩn, vì vậy hãy nhớ tìm kiếm online cho các crate hiện đại, tiên tiến để sử dụng trong các tình huống đa luồng.
Thư viện chuẩn của Rust cung cấp các kênh để truyền tin nhắn và các kiểu con trỏ
thông minh, như Mutex<T> và Arc<T>, an toàn để sử dụng trong các ngữ cảnh
đồng thời. Hệ thống kiểu và bộ kiểm tra mượn đảm bảo rằng mã sử dụng các giải
pháp này sẽ không gặp phải các cuộc đua dữ liệu hoặc tham chiếu không hợp lệ.
Khi bạn đã biên dịch được mã của mình, bạn có thể yên tâm rằng nó sẽ chạy tốt
trên nhiều thread mà không gặp phải những lỗi khó theo dõi thường thấy trong các
ngôn ngữ khác. Lập trình đồng thời không còn là một khái niệm đáng sợ nữa: hãy
tiến tới và làm cho chương trình của bạn chạy đồng thời, không sợ hãi!
Cơ Bản về Lập Trình Bất Đồng Bộ: Async, Await, Futures, và Streams
Nhiều thao tác mà chúng ta yêu cầu máy tính thực hiện có thể mất một khoảng thời
gian để hoàn thành. Sẽ thật tốt nếu chúng ta có thể làm việc khác trong khi đang
chờ đợi những quá trình chạy lâu đó hoàn thành. Máy tính hiện đại cung cấp hai
kỹ thuật để làm nhiều thao tác cùng một lúc: song song và đồng thời. Tuy nhiên,
một khi chúng ta bắt đầu viết các chương trình liên quan đến các thao tác song
song hoặc đồng thời, chúng ta nhanh chóng gặp phải những thách thức mới vốn có
trong lập trình bất đồng bộ, nơi các thao tác có thể không hoàn thành tuần tự
theo thứ tự chúng được bắt đầu. Chương này phát triển từ việc sử dụng thread
trong Chương 16 cho tính song song và đồng thời bằng cách giới thiệu một cách
tiếp cận thay thế cho lập trình bất đồng bộ: Futures, Streams của Rust, cú pháp
async và await hỗ trợ chúng, và các công cụ để quản lý và điều phối giữa các
thao tác bất đồng bộ.
Hãy xem xét một ví dụ. Giả sử bạn đang xuất một video về buổi lễ gia đình mà bạn đã tạo, một thao tác có thể mất từ vài phút đến vài giờ. Việc xuất video sẽ sử dụng càng nhiều năng lực CPU và GPU càng tốt. Nếu bạn chỉ có một lõi CPU và hệ điều hành của bạn không tạm dừng việc xuất đó cho đến khi nó hoàn thành — nghĩa là, nếu nó thực hiện việc xuất đồng bộ — bạn không thể làm bất cứ điều gì khác trên máy tính của mình trong khi tác vụ đó đang chạy. Đó sẽ là một trải nghiệm khá khó chịu. May mắn thay, hệ điều hành của máy tính bạn có thể, và thực sự, ngắt quãng việc xuất một cách vô hình thường xuyên để cho phép bạn làm việc khác đồng thời.
Bây giờ giả sử bạn đang tải xuống một video được chia sẻ bởi người khác, điều này cũng có thể mất một thời gian nhưng không chiếm nhiều thời gian CPU. Trong trường hợp này, CPU phải đợi dữ liệu đến từ mạng. Mặc dù bạn có thể bắt đầu đọc dữ liệu khi nó bắt đầu đến, nhưng có thể mất một thời gian để tất cả hiện lên. Ngay cả khi dữ liệu đã có đầy đủ, nếu video khá lớn, có thể mất ít nhất một hoặc hai giây để tải tất cả. Điều đó có thể không nghe có vẻ nhiều, nhưng đó là một khoảng thời gian rất dài đối với bộ xử lý hiện đại, có thể thực hiện hàng tỷ thao tác mỗi giây. Một lần nữa, hệ điều hành của bạn sẽ ngắt quãng chương trình của bạn một cách vô hình để cho phép CPU thực hiện công việc khác trong khi chờ cuộc gọi mạng hoàn thành.
Việc xuất video là một ví dụ về thao tác bị ràng buộc bởi CPU hoặc bị ràng buộc bởi tính toán. Nó bị giới hạn bởi tốc độ xử lý dữ liệu tiềm năng của máy tính trong CPU hoặc GPU, và bao nhiêu trong số tốc độ đó nó có thể dành cho thao tác đó. Việc tải xuống video là một ví dụ về thao tác bị ràng buộc bởi IO, bởi vì nó bị giới hạn bởi tốc độ của đầu vào và đầu ra của máy tính; nó chỉ có thể nhanh bằng tốc độ dữ liệu có thể được gửi qua mạng.
Trong cả hai ví dụ này, sự gián đoạn vô hình của hệ điều hành cung cấp một hình thức của tính đồng thời. Tuy nhiên, tính đồng thời đó chỉ xảy ra ở cấp độ của toàn bộ chương trình: hệ điều hành ngắt quãng một chương trình để cho phép các chương trình khác thực hiện công việc. Trong nhiều trường hợp, bởi vì chúng ta hiểu các chương trình của mình ở một mức độ chi tiết hơn nhiều so với hệ điều hành, chúng ta có thể phát hiện các cơ hội cho tính đồng thời mà hệ điều hành không thể thấy.
Ví dụ, nếu chúng ta đang xây dựng một công cụ để quản lý việc tải xuống tệp, chúng ta nên có thể viết chương trình của mình để việc bắt đầu một lần tải xuống sẽ không khóa giao diện người dùng, và người dùng nên có thể bắt đầu nhiều lần tải xuống cùng một lúc. Tuy nhiên, nhiều API hệ điều hành để tương tác với mạng là chặn, nghĩa là chúng chặn tiến trình của chương trình cho đến khi dữ liệu mà chúng đang xử lý hoàn toàn sẵn sàng.
Lưu ý: Đây là cách hoạt động của hầu hết các lệnh gọi hàm, nếu bạn nghĩ về nó. Tuy nhiên, thuật ngữ chặn thường được dành riêng cho các lệnh gọi hàm tương tác với tệp, mạng, hoặc các tài nguyên khác trên máy tính, bởi vì đó là những trường hợp mà một chương trình riêng lẻ sẽ được hưởng lợi từ thao tác không chặn.
Chúng ta có thể tránh chặn thread chính của mình bằng cách tạo ra một thread riêng để tải xuống mỗi tệp. Tuy nhiên, chi phí phụ của những thread đó cuối cùng sẽ trở thành một vấn đề. Sẽ tốt hơn nếu lệnh gọi không chặn ngay từ đầu. Cũng sẽ tốt hơn nếu chúng ta có thể viết theo cùng một kiểu trực tiếp mà chúng ta sử dụng trong mã chặn, tương tự như sau:
let data = fetch_data_from(url).await;
println!("{data}");Đó chính xác là những gì mà trừu tượng async (viết tắt của asynchronous) của Rust cung cấp cho chúng ta. Trong chương này, bạn sẽ tìm hiểu tất cả về async khi chúng ta đề cập đến các chủ đề sau:
- Cách sử dụng cú pháp
asyncvàawaitcủa Rust - Cách sử dụng mô hình async để giải quyết một số thách thức tương tự mà chúng ta đã xem xét trong Chương 16
- Cách đa luồng và async cung cấp các giải pháp bổ sung cho nhau, mà bạn có thể kết hợp trong nhiều trường hợp
Tuy nhiên, trước khi chúng ta thấy cách async hoạt động trong thực tế, chúng ta cần có một đoạn ngắn để thảo luận về sự khác biệt giữa tính song song và tính đồng thời.
Tính Song Song và Tính Đồng Thời
Chúng ta đã coi tính song song và tính đồng thời là phần lớn có thể hoán đổi cho nhau cho đến nay. Bây giờ chúng ta cần phân biệt giữa chúng một cách chính xác hơn, bởi vì sự khác biệt sẽ xuất hiện khi chúng ta bắt đầu làm việc.
Hãy xem xét các cách khác nhau mà một nhóm có thể chia nhỏ công việc trên một dự án phần mềm. Bạn có thể giao cho một thành viên nhiều nhiệm vụ, giao cho mỗi thành viên một nhiệm vụ, hoặc sử dụng kết hợp của hai phương pháp.
Khi một cá nhân làm việc trên nhiều nhiệm vụ khác nhau trước khi bất kỳ nhiệm vụ nào hoàn thành, đây là tính đồng thời. Có thể bạn có hai dự án khác nhau được kiểm tra trên máy tính của bạn, và khi bạn cảm thấy chán hoặc bị kẹt trên một dự án, bạn chuyển sang dự án khác. Bạn chỉ là một người, vì vậy bạn không thể tiến triển trên cả hai nhiệm vụ cùng một lúc chính xác, nhưng bạn có thể đa nhiệm, tiến triển trên một nhiệm vụ tại một thời điểm bằng cách chuyển đổi giữa chúng (xem Hình 17-1).

Khi nhóm chia nhỏ một nhóm nhiệm vụ bằng cách để mỗi thành viên nhận một nhiệm vụ và làm việc trên đó một mình, đây là tính song song. Mỗi người trong nhóm có thể tiến triển chính xác cùng một lúc (xem Hình 17-2).

Trong cả hai luồng công việc này, bạn có thể phải phối hợp giữa các nhiệm vụ khác nhau. Có thể bạn nghĩ rằng nhiệm vụ được giao cho một người hoàn toàn độc lập với công việc của mọi người khác, nhưng trên thực tế nó yêu cầu một người khác trong nhóm phải hoàn thành nhiệm vụ của họ trước. Một số công việc có thể được thực hiện song song, nhưng một số công việc lại thực sự là tuần tự: nó chỉ có thể xảy ra trong một chuỗi, một nhiệm vụ sau nhiệm vụ khác, như trong Hình 17-3.

Tương tự, bạn có thể nhận ra rằng một trong các nhiệm vụ của bạn phụ thuộc vào một nhiệm vụ khác của bạn. Bây giờ công việc đồng thời của bạn cũng đã trở thành tuần tự.
Tính song song và tính đồng thời cũng có thể giao nhau. Nếu bạn biết rằng một đồng nghiệp bị kẹt cho đến khi bạn hoàn thành một trong các nhiệm vụ của mình, bạn có thể sẽ tập trung tất cả nỗ lực vào nhiệm vụ đó để "mở khóa" cho đồng nghiệp của bạn. Bạn và đồng nghiệp của bạn không còn có thể làm việc song song, và bạn cũng không còn có thể làm việc đồng thời trên các nhiệm vụ của riêng bạn.
Cùng một động lực cơ bản cũng áp dụng với phần mềm và phần cứng. Trên một máy với một lõi CPU duy nhất, CPU chỉ có thể thực hiện một thao tác tại một thời điểm, nhưng nó vẫn có thể làm việc đồng thời. Sử dụng các công cụ như thread, tiến trình, và async, máy tính có thể tạm dừng một hoạt động và chuyển sang các hoạt động khác trước khi cuối cùng quay lại hoạt động đầu tiên đó. Trên một máy với nhiều lõi CPU, nó cũng có thể làm việc song song. Một lõi có thể thực hiện một nhiệm vụ trong khi một lõi khác thực hiện một nhiệm vụ hoàn toàn không liên quan, và những thao tác đó thực sự xảy ra cùng một lúc.
Khi làm việc với async trong Rust, chúng ta luôn đang xử lý tính đồng thời. Tùy thuộc vào phần cứng, hệ điều hành, và runtime async mà chúng ta đang sử dụng (sẽ nói thêm về runtime async sau), tính đồng thời đó cũng có thể sử dụng tính song song bên dưới nắp capo.
Bây giờ, hãy đi sâu vào cách lập trình async trong Rust thực sự hoạt động.
Futures và Cú Pháp Async
Các yếu tố chính của lập trình bất đồng bộ trong Rust là futures và các từ
khóa async và await của Rust.
Một future là một giá trị có thể chưa sẵn sàng ngay bây giờ nhưng sẽ trở nên
sẵn sàng tại một thời điểm nào đó trong tương lai. (Khái niệm này xuất hiện
trong nhiều ngôn ngữ, đôi khi dưới các tên khác như task hoặc promise.) Rust
cung cấp một đặc tính Future như một khối xây dựng để các thao tác bất đồng bộ
khác nhau có thể được triển khai với các cấu trúc dữ liệu khác nhau nhưng với
một giao diện chung. Trong Rust, futures là các kiểu triển khai đặc tính
Future. Mỗi future chứa thông tin riêng về tiến trình đã được thực hiện và
"sẵn sàng" có nghĩa là gì.
Bạn có thể áp dụng từ khóa async cho các khối và hàm để chỉ định rằng chúng có
thể bị gián đoạn và tiếp tục. Trong một khối async hoặc hàm async, bạn có thể sử
dụng từ khóa await để đợi một future (nghĩa là, đợi nó trở nên sẵn sàng).
Bất kỳ điểm nào mà bạn đợi một future trong một khối async hoặc hàm là một vị
trí tiềm năng để khối async hoặc hàm đó tạm dừng và tiếp tục. Quá trình kiểm tra
với một future để xem giá trị của nó đã có sẵn chưa được gọi là polling.
Một số ngôn ngữ khác, như C# và JavaScript, cũng sử dụng các từ khóa async và
await cho lập trình bất đồng bộ. Nếu bạn quen thuộc với những ngôn ngữ đó, bạn
có thể nhận thấy một số khác biệt đáng kể trong cách Rust thực hiện mọi thứ, bao
gồm cách nó xử lý cú pháp. Điều đó có lý do chính đáng, như chúng ta sẽ thấy!
Khi viết Rust bất đồng bộ, chúng ta sử dụng các từ khóa async và await trong
hầu hết thời gian. Rust biên dịch chúng thành mã tương đương sử dụng đặc tính
Future, giống như nó biên dịch vòng lặp for thành mã tương đương sử dụng đặc
tính Iterator. Tuy nhiên, vì Rust cung cấp đặc tính Future, bạn cũng có thể
triển khai nó cho các kiểu dữ liệu của riêng bạn khi cần. Nhiều hàm mà chúng ta
sẽ thấy trong suốt chương này trả về các kiểu có triển khai Future riêng của
chúng. Chúng ta sẽ quay lại định nghĩa của đặc tính vào cuối chương và đi sâu
vào cách nó hoạt động, nhưng đây là đủ chi tiết để giúp chúng ta tiếp tục tiến
về phía trước.
Điều này có thể cảm thấy hơi trừu tượng, vì vậy hãy viết chương trình bất đồng bộ đầu tiên của chúng ta: một trình thu thập web nhỏ. Chúng ta sẽ truyền vào hai URL từ dòng lệnh, lấy cả hai cùng một lúc, và trả về kết quả của URL nào hoàn thành trước. Ví dụ này sẽ có khá nhiều cú pháp mới, nhưng đừng lo lắng — chúng ta sẽ giải thích mọi thứ bạn cần biết khi tiến hành.
Chương Trình Async Đầu Tiên Của Chúng Ta
Để giữ trọng tâm của chương này vào việc học async thay vì tung hứng các phần
của hệ sinh thái, chúng ta đã tạo ra crate trpl (trpl là viết tắt của "The
Rust Programming Language"). Nó tái xuất tất cả các kiểu, đặc tính và hàm mà bạn
sẽ cần, chủ yếu từ các crate futures và
tokio. Crate futures là nơi chính thức để thử nghiệm
mã async của Rust, và đó thực sự là nơi đặc tính Future được thiết kế ban đầu.
Tokio là runtime async được sử dụng rộng rãi nhất trong Rust hiện nay, đặc biệt
là cho các ứng dụng web. Có những runtime tuyệt vời khác, và chúng có thể phù
hợp hơn cho mục đích của bạn. Chúng ta sử dụng crate tokio bên dưới cho trpl
vì nó đã được kiểm tra kỹ lưỡng và được sử dụng rộng rãi.
Trong một số trường hợp, trpl cũng đổi tên hoặc bọc các API gốc để giúp bạn
tập trung vào các chi tiết liên quan đến chương này. Nếu bạn muốn hiểu những gì
crate làm, chúng tôi khuyến khích bạn kiểm tra mã nguồn của
nó. Bạn sẽ có thể thấy mỗi tái xuất đến từ crate
nào, và chúng tôi đã để lại các bình luận mở rộng giải thích những gì crate làm.
Tạo một dự án nhị phân mới có tên hello-async và thêm crate trpl làm phụ
thuộc:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Bây giờ chúng ta có thể sử dụng các phần khác nhau được cung cấp bởi trpl để
viết chương trình async đầu tiên của chúng ta. Chúng ta sẽ xây dựng một công cụ
dòng lệnh nhỏ lấy hai trang web, kéo phần tử <title> từ mỗi trang, và in ra
tiêu đề của trang nào hoàn thành toàn bộ quá trình đó trước.
Định Nghĩa Hàm page_title
Hãy bắt đầu bằng cách viết một hàm nhận một URL trang làm tham số, gửi yêu cầu đến nó, và trả về văn bản của phần tử tiêu đề (xem Listing 17-1).
extern crate trpl; // required for mdbook test fn main() { // TODO: we'll add this next! } use trpl::Html; async fn page_title(url: &str) -> Option<String> { let response = trpl::get(url).await; let response_text = response.text().await; Html::parse(&response_text) .select_first("title") .map(|title| title.inner_html()) }
Đầu tiên, chúng ta định nghĩa một hàm có tên page_title và đánh dấu nó bằng từ
khóa async. Sau đó, chúng ta sử dụng hàm trpl::get để lấy bất kỳ URL nào
được truyền vào và thêm từ khóa await để đợi phản hồi. Để lấy văn bản của phản
hồi, chúng ta gọi phương thức text của nó, và một lần nữa đợi nó với từ khóa
await. Cả hai bước này đều bất đồng bộ. Đối với hàm get, chúng ta phải đợi
máy chủ gửi lại phần đầu tiên của phản hồi, bao gồm các tiêu đề HTTP, cookie,
v.v., và có thể được gửi riêng biệt với phần thân phản hồi. Đặc biệt nếu phần
thân rất lớn, có thể mất một thời gian để tất cả đến. Bởi vì chúng ta phải đợi
toàn bộ phản hồi đến, phương thức text cũng là bất đồng bộ.
Chúng ta phải rõ ràng đợi cả hai future này, bởi vì futures trong Rust là lười
biếng: chúng không làm gì cho đến khi bạn yêu cầu chúng làm việc với từ khóa
await. (Thực tế, Rust sẽ hiển thị cảnh báo trình biên dịch nếu bạn không sử
dụng một future.) Điều này có thể nhắc bạn về cuộc thảo luận về iterators trong
Chương 13 ở phần Xử Lý Một Loạt Các Mục Với
Iterators. Các iterator không làm gì trừ khi bạn
gọi phương thức next của chúng — dù trực tiếp hay bằng cách sử dụng vòng lặp
for hoặc các phương thức như map sử dụng next bên dưới. Tương tự, futures
không làm gì trừ khi bạn rõ ràng yêu cầu chúng làm. Tính lười biếng này cho phép
Rust tránh chạy mã async cho đến khi nó thực sự cần thiết.
Lưu ý: Điều này khác với hành vi chúng ta đã thấy trong chương trước khi sử dụng
thread::spawntrong Tạo Một Thread Mới với spawn, nơi closure mà chúng ta chuyển cho một thread khác bắt đầu chạy ngay lập tức. Nó cũng khác với cách nhiều ngôn ngữ khác tiếp cận async. Nhưng nó quan trọng để Rust có thể cung cấp các đảm bảo hiệu suất của nó, giống như với iterators.
Khi chúng ta có response_text, chúng ta có thể phân tích nó thành một instance
của kiểu Html bằng cách sử dụng Html::parse. Thay vì một chuỗi thô, bây giờ
chúng ta có một kiểu dữ liệu có thể sử dụng để làm việc với HTML như một cấu
trúc dữ liệu phong phú hơn. Cụ thể, chúng ta có thể sử dụng phương thức
select_first để tìm instance đầu tiên của một bộ chọn CSS. Bằng cách truyền
chuỗi "title", chúng ta sẽ nhận được phần tử <title> đầu tiên trong tài
liệu, nếu có. Bởi vì có thể không có phần tử nào phù hợp, select_first trả về
một Option<ElementRef>. Cuối cùng, chúng ta sử dụng phương thức Option::map,
cho phép chúng ta làm việc với mục trong Option nếu nó hiện diện, và không làm
gì nếu không. (Chúng ta cũng có thể sử dụng biểu thức match ở đây, nhưng map
thường được sử dụng hơn.) Trong phần thân của hàm mà chúng ta cung cấp cho
map, chúng ta gọi inner_html trên title để lấy nội dung của nó, đó là một
String. Khi tất cả đã nói và làm, chúng ta có một Option<String>.
Lưu ý rằng từ khóa await của Rust đi sau biểu thức bạn đang đợi, không phải
trước nó. Nghĩa là, nó là một từ khóa hậu tố. Điều này có thể khác với những
gì bạn quen thuộc nếu bạn đã sử dụng async trong các ngôn ngữ khác, nhưng
trong Rust nó làm cho chuỗi các phương thức dễ dàng làm việc hơn nhiều. Kết quả
là, chúng ta có thể thay đổi phần thân của page_title để nối các lệnh gọi hàm
trpl::get và text với nhau với await ở giữa, như được hiển thị trong
Listing 17-2.
extern crate trpl; // required for mdbook test use trpl::Html; fn main() { // TODO: we'll add this next! } async fn page_title(url: &str) -> Option<String> { let response_text = trpl::get(url).await.text().await; Html::parse(&response_text) .select_first("title") .map(|title| title.inner_html()) }
Với điều đó, chúng ta đã viết thành công hàm async đầu tiên của mình! Trước khi
chúng ta thêm một số mã trong main để gọi nó, hãy nói thêm một chút về những
gì chúng ta đã viết và ý nghĩa của nó.
Khi Rust thấy một khối được đánh dấu bằng từ khóa async, nó biên dịch nó thành
một kiểu dữ liệu duy nhất, ẩn danh triển khai đặc tính Future. Khi Rust thấy
một hàm được đánh dấu bằng async, nó biên dịch nó thành một hàm không bất đồng
bộ có phần thân là một khối async. Kiểu trả về của một hàm async là kiểu của
kiểu dữ liệu ẩn danh mà trình biên dịch tạo ra cho khối async đó.
Do đó, viết async fn tương đương với viết một hàm trả về một future của kiểu
trả về. Đối với trình biên dịch, một định nghĩa hàm như async fn page_title
trong Listing 17-1 tương đương với một hàm không bất đồng bộ được định nghĩa như
sau:
#![allow(unused)] fn main() { extern crate trpl; // required for mdbook test use std::future::Future; use trpl::Html; fn page_title(url: &str) -> impl Future<Output = Option<String>> { async move { let text = trpl::get(url).await.text().await; Html::parse(&text) .select_first("title") .map(|title| title.inner_html()) } } }
Hãy đi qua từng phần của phiên bản được chuyển đổi:
- Nó sử dụng cú pháp
impl Traitmà chúng ta đã thảo luận trở lại Chương 10 trong phần "Đặc Tính như Tham Số". - Đặc tính được trả về là một
Futurevới một kiểu liên kết làOutput. Lưu ý rằng kiểuOutputlàOption<String>, giống với kiểu trả về ban đầu từ phiên bảnasync fncủapage_title. - Tất cả mã được gọi trong phần thân của hàm ban đầu được bọc trong một khối
async move. Hãy nhớ rằng các khối là biểu thức. Toàn bộ khối này là biểu thức được trả về từ hàm. - Khối async này tạo ra một giá trị với kiểu
Option<String>, như vừa mô tả. Giá trị đó khớp với kiểuOutputtrong kiểu trả về. Điều này giống như các khối khác bạn đã thấy. - Phần thân hàm mới là một khối
async movevì cách nó sử dụng tham sốurl. (Chúng ta sẽ nói nhiều hơn vềasyncso vớiasync movesau trong chương.)
Bây giờ chúng ta có thể gọi page_title trong main.
Xác Định Tiêu Đề Một Trang Duy Nhất
Để bắt đầu, chúng ta sẽ chỉ lấy tiêu đề cho một trang duy nhất. Trong Listing
17-3, chúng ta theo cùng một mẫu mà chúng ta đã sử dụng trong Chương 12 để lấy
đối số dòng lệnh trong phần Chấp Nhận Đối Số Dòng
Lệnh. Sau đó, chúng ta truyền URL đầu tiên cho
page_title và đợi kết quả. Bởi vì giá trị được tạo ra bởi future là một
Option<String>, chúng ta sử dụng biểu thức match để in các thông báo khác
nhau để tính đến việc liệu trang có <title> hay không.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Thật không may, mã này không biên dịch. Nơi duy nhất chúng ta có thể sử dụng từ
khóa await là trong các hàm hoặc khối async, và Rust sẽ không cho phép chúng
ta đánh dấu hàm đặc biệt main là async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
Lý do main không thể được đánh dấu async là vì mã async cần một runtime:
một crate Rust quản lý các chi tiết của việc thực thi mã bất đồng bộ. Hàm main
của một chương trình có thể khởi tạo một runtime, nhưng nó không phải là một
runtime bản thân nó. (Chúng ta sẽ thấy thêm về lý do tại sao trong một chút.)
Mỗi chương trình Rust thực thi mã async có ít nhất một nơi mà nó thiết lập
runtime và thực thi các futures.
Hầu hết các ngôn ngữ hỗ trợ async đều gói gọn một runtime, nhưng Rust thì không. Thay vào đó, có nhiều runtime async khác nhau có sẵn, mỗi cái thực hiện những đánh đổi khác nhau phù hợp với trường hợp sử dụng mà nó nhắm tới. Ví dụ, một máy chủ web có thông lượng cao với nhiều lõi CPU và một lượng lớn RAM có nhu cầu rất khác so với một vi điều khiển với một lõi duy nhất, một lượng nhỏ RAM, và không có khả năng cấp phát heap. Các crate cung cấp các runtime đó cũng thường cung cấp các phiên bản async của các chức năng phổ biến như I/O tệp hoặc mạng.
Ở đây, và trong suốt phần còn lại của chương này, chúng ta sẽ sử dụng hàm run
từ crate trpl, lấy một future làm đối số và chạy nó đến khi hoàn thành. Đằng
sau hậu trường, gọi run thiết lập một runtime được sử dụng để chạy future được
truyền vào. Một khi future hoàn thành, run trả về bất cứ giá trị nào mà future
đã tạo ra.
Chúng ta có thể truyền future được trả về bởi page_title trực tiếp cho run,
và một khi nó hoàn thành, chúng ta có thể khớp trên Option<String> kết quả,
như chúng ta đã cố gắng làm trong Listing 17-3. Tuy nhiên, đối với hầu hết các
ví dụ trong chương (và hầu hết mã async trong thế giới thực), chúng ta sẽ làm
nhiều hơn là chỉ một lệnh gọi hàm async, vì vậy thay vào đó chúng ta sẽ truyền
một khối async và rõ ràng đợi kết quả của lệnh gọi page_title, như trong
Listing 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Khi chúng ta chạy mã này, chúng ta nhận được hành vi mà chúng ta mong đợi ban đầu:
$ cargo run -- https://www.rust-lang.org
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Phù—cuối cùng chúng ta đã có một số mã async hoạt động! Nhưng trước khi chúng ta thêm mã để đua hai trang web với nhau, hãy nhanh chóng trở lại cách futures hoạt động.
Mỗi điểm đợi—nghĩa là, mỗi nơi mà mã sử dụng từ khóa await—đại diện cho một
nơi mà quyền kiểm soát được trao lại cho runtime. Để làm cho điều đó hoạt động,
Rust cần phải theo dõi trạng thái liên quan đến khối async để runtime có thể
khởi động một số công việc khác và sau đó quay lại khi nó sẵn sàng để cố gắng
tiếp tục cái đầu tiên. Đây là một máy trạng thái vô hình, như thể bạn đã viết
một enum như thế này để lưu trạng thái hiện tại tại mỗi điểm đợi:
#![allow(unused)] fn main() { extern crate trpl; // required for mdbook test enum PageTitleFuture<'a> { Initial { url: &'a str }, GetAwaitPoint { url: &'a str }, TextAwaitPoint { response: trpl::Response }, } }
Tuy nhiên, viết mã để chuyển đổi giữa mỗi trạng thái bằng tay sẽ là tẻ nhạt và dễ bị lỗi, đặc biệt là khi bạn cần thêm nhiều chức năng và nhiều trạng thái vào mã sau này. May mắn thay, trình biên dịch Rust tạo và quản lý các cấu trúc dữ liệu máy trạng thái cho mã async tự động. Các quy tắc bình thường về việc mượn và sở hữu xung quanh các cấu trúc dữ liệu vẫn áp dụng, và may mắn thay, trình biên dịch cũng xử lý việc kiểm tra những điều đó cho chúng ta và cung cấp các thông báo lỗi hữu ích. Chúng ta sẽ làm việc thông qua một vài điều đó sau trong chương.
Cuối cùng, một cái gì đó phải thực thi máy trạng thái này, và thứ đó là một runtime. (Đây là lý do tại sao bạn có thể gặp phải các tham chiếu đến executors khi tìm hiểu về runtimes: một executor là phần của runtime chịu trách nhiệm thực thi mã async.)
Bây giờ bạn có thể thấy tại sao trình biên dịch đã ngăn chúng ta làm cho main
bản thân là một hàm async trở lại trong Listing 17-3. Nếu main là một hàm
async, một cái gì đó khác sẽ cần quản lý máy trạng thái cho bất kỳ future nào
main trả về, nhưng main là điểm bắt đầu của chương trình! Thay vào đó, chúng
ta đã gọi hàm trpl::run trong main để thiết lập một runtime và chạy future
được trả về bởi khối async cho đến khi nó hoàn thành.
Lưu ý: Một số runtime cung cấp các macro để bạn có thể viết một hàm
mainasync. Những macro đó viết lạiasync fn main() { ... }để là mộtfn mainbình thường, làm cùng một việc mà chúng ta đã làm bằng tay trong Listing 17-4: gọi một hàm chạy một future đến khi hoàn thành giống nhưtrpl::runlàm.
Bây giờ hãy kết hợp các phần này lại với nhau và xem cách chúng ta có thể viết mã đồng thời.
Đua Hai URL Của Chúng Ta Với Nhau
Trong Listing 17-5, chúng ta gọi page_title với hai URL khác nhau được truyền
vào từ dòng lệnh và đua chúng.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}Chúng ta bắt đầu bằng cách gọi page_title cho mỗi URL do người dùng cung cấp.
Chúng ta lưu các future kết quả là title_fut_1 và title_fut_2. Hãy nhớ rằng,
chúng không làm gì cả, bởi vì futures là lười biếng và chúng ta chưa đợi chúng.
Sau đó, chúng ta truyền các future cho trpl::race, trả về một giá trị để chỉ
ra futures nào trong số các futures được truyền cho nó hoàn thành đầu tiên.
Lưu ý: Bên dưới,
raceđược xây dựng trên một hàm tổng quát hơn,select, mà bạn sẽ gặp nhiều hơn trong mã Rust thực tế. Một hàmselectcó thể làm nhiều thứ mà hàmtrpl::racekhông thể, nhưng nó cũng có một số phức tạp bổ sung mà chúng ta có thể bỏ qua bây giờ.
Một trong hai future có thể "thắng" một cách hợp pháp, vì vậy sẽ không hợp lý
khi trả về một Result. Thay vào đó, race trả về một kiểu mà chúng ta chưa
thấy trước đây, trpl::Either. Kiểu Either hơi giống với một Result ở chỗ
nó có hai trường hợp. Không giống như Result, tuy nhiên, không có khái niệm
thành công hay thất bại được nướng vào Either. Thay vào đó, nó sử dụng Left
và Right để chỉ "một hoặc cái kia":
#![allow(unused)] fn main() { enum Either<A, B> { Left(A), Right(B), } }
Hàm race trả về Left với đầu ra từ đối số future đầu tiên nếu nó kết thúc
trước, hoặc Right với đầu ra của đối số future thứ hai nếu đó là cái kết thúc
trước. Điều này phù hợp với thứ tự các đối số xuất hiện khi gọi hàm: đối số đầu
tiên nằm ở bên trái của đối số thứ hai.
Chúng ta cũng cập nhật page_title để trả về cùng URL đã truyền vào. Bằng cách
đó, nếu trang trả về đầu tiên không có <title> mà chúng ta có thể giải quyết,
chúng ta vẫn có thể in một thông báo có ý nghĩa. Với thông tin đó có sẵn, chúng
ta kết thúc bằng cách cập nhật đầu ra println! của chúng ta để chỉ ra cả URL
nào kết thúc trước và <title> là gì, nếu có, cho trang web tại URL đó.
Bây giờ bạn đã xây dựng một trình thu thập web nhỏ hoạt động! Chọn một cặp URL và chạy công cụ dòng lệnh. Bạn có thể khám phá ra rằng một số trang web nhất quán nhanh hơn các trang khác, trong khi trong các trường hợp khác, trang nhanh hơn thay đổi từ lần chạy này sang lần chạy khác. Quan trọng hơn, bạn đã học được những điều cơ bản về làm việc với futures, vì vậy bây giờ chúng ta có thể đi sâu hơn vào những gì chúng ta có thể làm với async.
Áp dụng Đồng thời với Async
Trong phần này, chúng ta sẽ áp dụng async vào một số thách thức đồng thời giống với những gì chúng ta đã giải quyết bằng thread trong chương 16. Vì chúng ta đã thảo luận về nhiều ý tưởng chính ở đó, trong phần này chúng ta sẽ tập trung vào những điểm khác biệt giữa thread và future.
Trong nhiều trường hợp, các API để làm việc với đồng thời sử dụng async rất giống với những API dùng cho thread. Trong các trường hợp khác, chúng lại khá khác biệt. Ngay cả khi các API trông giống nhau giữa thread và async, chúng thường có hành vi khác nhau—và gần như luôn có các đặc điểm hiệu suất khác nhau.
Tạo Task Mới với spawn_task
Thao tác đầu tiên chúng ta đã giải quyết trong Tạo Thread Mới với
Spawn là đếm trên hai thread riêng biệt. Hãy làm
điều tương tự bằng async. Crate trpl cung cấp một hàm spawn_task trông rất
giống với API thread::spawn, và một hàm sleep là phiên bản async của API
thread::sleep. Chúng ta có thể sử dụng chúng cùng nhau để triển khai ví dụ
đếm, như trong Listing 17-6.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { trpl::spawn_task(async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } }); }
Làm điểm bắt đầu, chúng ta thiết lập hàm main với trpl::run để hàm cấp cao
nhất của chúng ta có thể là async.
Lưu ý: Từ điểm này trở đi trong chương, mọi ví dụ sẽ bao gồm mã bao bọc chính xác giống nhau với
trpl::runtrongmain, vì vậy chúng ta thường bỏ qua nó giống như chúng ta làm vớimain. Đừng quên bao gồm nó trong mã của bạn!
Sau đó, chúng ta viết hai vòng lặp trong khối đó, mỗi vòng lặp chứa một lệnh gọi
trpl::sleep, đợi nửa giây (500 mili giây) trước khi gửi tin nhắn tiếp theo.
Chúng ta đặt một vòng lặp trong phần thân của trpl::spawn_task và vòng lặp
khác trong vòng lặp for cấp cao nhất. Chúng ta cũng thêm await sau các lệnh
gọi sleep.
Mã này hoạt động tương tự như triển khai dựa trên thread—bao gồm cả thực tế là bạn có thể thấy các tin nhắn xuất hiện theo thứ tự khác nhau trong terminal của bạn khi bạn chạy nó:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
Phiên bản này dừng ngay khi vòng lặp for trong phần thân của khối async chính
kết thúc, vì task được tạo bởi spawn_task bị tắt khi hàm main kết thúc. Nếu
bạn muốn nó chạy hết đến khi task hoàn thành, bạn sẽ cần sử dụng một join handle
để đợi task đầu tiên hoàn thành. Với thread, chúng ta đã sử dụng phương thức
join để "chặn" cho đến khi thread hoàn tất chạy. Trong Listing 17-7, chúng ta
có thể sử dụng await để làm điều tương tự, bởi vì task handle chính nó là một
future. Kiểu Output của nó là một Result, vì vậy chúng ta cũng unwrap nó sau
khi await nó.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { let handle = trpl::spawn_task(async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } handle.await.unwrap(); }); }
Phiên bản cập nhật này chạy cho đến khi cả hai vòng lặp kết thúc.
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Cho đến nay, có vẻ như async và thread cho chúng ta cùng một kết quả cơ bản, chỉ
với cú pháp khác nhau: sử dụng await thay vì gọi join trên join handle, và
await các lệnh gọi sleep.
Sự khác biệt lớn hơn là chúng ta không cần phải tạo một thread hệ điều hành khác
để làm điều này. Thực tế, chúng ta thậm chí không cần phải tạo một task ở đây.
Bởi vì các khối async được biên dịch thành các future ẩn danh, chúng ta có thể
đặt mỗi vòng lặp trong một khối async và có runtime chạy cả hai đến khi hoàn
thành bằng cách sử dụng hàm trpl::join.
Trong phần Chờ Tất cả Các Thread Hoàn thành Bằng Cách Sử dụng join
Handles, chúng ta đã thấy cách sử dụng phương thức
join trên kiểu JoinHandle được trả về khi bạn gọi std::thread::spawn. Hàm
trpl::join tương tự, nhưng dành cho future. Khi bạn đưa cho nó hai future, nó
tạo ra một future mới duy nhất mà output của nó là một tuple chứa output của mỗi
future bạn đã truyền vào khi cả hai đều hoàn thành. Vì vậy, trong Listing 17-8,
chúng ta sử dụng trpl::join để đợi cả fut1 và fut2 hoàn thành. Chúng ta
không await fut1 và fut2 mà thay vào đó là future mới được tạo ra bởi
trpl::join. Chúng ta bỏ qua output, vì nó chỉ là một tuple chứa hai giá trị
đơn vị.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { let fut1 = async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }; let fut2 = async { for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } }; trpl::join(fut1, fut2).await; }); }
Khi chúng ta chạy điều này, chúng ta thấy cả hai future chạy đến khi hoàn thành:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Bây giờ, bạn sẽ thấy thứ tự chính xác giống nhau mỗi lần, điều này rất khác với
những gì chúng ta đã thấy với thread. Đó là bởi vì hàm trpl::join là công
bằng, nghĩa là nó kiểm tra mỗi future thường xuyên như nhau, luân phiên giữa
chúng, và không bao giờ để một future chạy trước nếu future khác đã sẵn sàng.
Với thread, hệ điều hành quyết định thread nào được kiểm tra và cho phép nó chạy
bao lâu. Với async Rust, runtime quyết định task nào cần kiểm tra. (Trong thực
tế, chi tiết trở nên phức tạp vì một runtime async có thể sử dụng thread hệ điều
hành bên dưới như một phần của cách nó quản lý đồng thời, vì vậy việc đảm bảo
tính công bằng có thể là nhiều việc hơn cho một runtime—nhưng nó vẫn có thể thực
hiện được!) Các runtime không phải đảm bảo sự công bằng cho bất kỳ thao tác nào,
và chúng thường cung cấp các API khác nhau để cho phép bạn chọn liệu bạn có muốn
sự công bằng hay không.
Hãy thử một số biến thể này khi await các future và xem chúng làm gì:
- Xóa bỏ khối async xung quanh một trong hai hoặc cả hai vòng lặp.
- Await mỗi khối async ngay sau khi định nghĩa nó.
- Chỉ bọc vòng lặp đầu tiên trong một khối async, và await future kết quả sau phần thân của vòng lặp thứ hai.
Để thử thách hơn, hãy xem liệu bạn có thể tìm ra output sẽ như thế nào trong mỗi trường hợp trước khi chạy mã!
Đếm trên Hai Task Sử dụng Truyền Thông Điệp
Chia sẻ dữ liệu giữa các future cũng sẽ quen thuộc: chúng ta sẽ sử dụng truyền thông điệp một lần nữa, nhưng lần này với các phiên bản async của các kiểu và hàm. Chúng ta sẽ đi theo một con đường hơi khác với những gì chúng ta đã làm trong Sử dụng Truyền Thông Điệp để Chuyển Dữ liệu Giữa Các Thread để minh họa một số điểm khác biệt chính giữa đồng thời dựa trên thread và dựa trên future. Trong Listing 17-9, chúng ta sẽ bắt đầu với chỉ một khối async duy nhất—không tạo một task riêng biệt như chúng ta đã tạo một thread riêng biệt.
extern crate trpl; // required for mdbook test fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let val = String::from("hi"); tx.send(val).unwrap(); let received = rx.recv().await.unwrap(); println!("received '{received}'"); }); }
Ở đây, chúng ta sử dụng trpl::channel, một phiên bản async của API kênh đa-nhà
sản xuất, đơn-người tiêu dùng mà chúng ta đã sử dụng với thread trong Chương 16.
Phiên bản async của API chỉ hơi khác so với phiên bản dựa trên thread: nó sử
dụng một receiver rx có thể thay đổi thay vì bất biến, và phương thức recv
của nó tạo ra một future mà chúng ta cần await thay vì trực tiếp tạo ra giá trị.
Bây giờ chúng ta có thể gửi tin nhắn từ sender đến receiver. Lưu ý rằng chúng ta
không phải tạo một thread riêng biệt hoặc thậm chí một task; chúng ta chỉ cần
await lệnh gọi rx.recv.
Phương thức đồng bộ Receiver::recv trong std::mpsc::channel chặn cho đến khi
nó nhận được tin nhắn. Phương thức trpl::Receiver::recv không làm vậy, vì nó
là async. Thay vì chặn, nó giao quyền kiểm soát lại cho runtime cho đến khi hoặc
một tin nhắn được nhận hoặc phía gửi của kênh đóng lại. Ngược lại, chúng ta
không await lệnh gọi send, vì nó không chặn. Nó không cần phải làm vậy, vì
kênh mà chúng ta đang gửi vào là không giới hạn.
Lưu ý: Vì tất cả mã async này chạy trong một khối async trong một lệnh gọi
trpl::run, mọi thứ trong đó có thể tránh việc chặn. Tuy nhiên, mã bên ngoài nó sẽ chặn khi hàmruntrả về. Đó là toàn bộ mục đích của hàmtrpl::run: nó cho phép bạn chọn nơi để chặn đối với một số mã async, và do đó là nơi để chuyển đổi giữa mã đồng bộ và async. Trong hầu hết các runtime async,runthực sự được đặt tên làblock_onchính vì lý do này.
Lưu ý hai điều về ví dụ này. Đầu tiên, tin nhắn sẽ đến ngay lập tức. Thứ hai, mặc dù chúng ta sử dụng một future ở đây, nhưng chưa có sự đồng thời. Mọi thứ trong listing xảy ra tuần tự, giống như khi không có future nào tham gia.
Hãy giải quyết phần đầu tiên bằng cách gửi một loạt tin nhắn và ngủ giữa chúng, như trong Listing 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}Ngoài việc gửi tin nhắn, chúng ta cần phải nhận chúng. Trong trường hợp này, vì
chúng ta biết có bao nhiêu tin nhắn đến, chúng ta có thể làm điều đó thủ công
bằng cách gọi rx.recv().await bốn lần. Tuy nhiên, trong thế giới thực, chúng
ta thường đang đợi một số lượng tin nhắn không xác định, vì vậy chúng ta cần
tiếp tục đợi cho đến khi chúng ta xác định rằng không còn tin nhắn nào nữa.
Trong Listing 16-10, chúng ta đã sử dụng một vòng lặp for để xử lý tất cả các
mục nhận được từ một kênh đồng bộ. Tuy nhiên, Rust chưa có cách để viết một vòng
lặp for trên một loạt các mục bất đồng bộ, vì vậy chúng ta cần sử dụng một
vòng lặp mà chúng ta chưa thấy trước đây: vòng lặp điều kiện while let. Đây là
phiên bản vòng lặp của cấu trúc if let mà chúng ta đã thấy trong phần Kiểm
soát Luồng Ngắn gọn với if let và let...else. Vòng lặp
sẽ tiếp tục thực thi miễn là mẫu mà nó chỉ định tiếp tục khớp với giá trị.
Lệnh gọi rx.recv tạo ra một future, mà chúng ta await. Runtime sẽ tạm dừng
future cho đến khi nó sẵn sàng. Khi một tin nhắn đến, future sẽ giải quyết thành
Some(message) nhiều lần khi tin nhắn đến. Khi kênh đóng lại, bất kể bất kỳ
tin nhắn nào đã đến, future sẽ thay vào đó giải quyết thành None để chỉ ra
rằng không còn giá trị nào nữa và do đó chúng ta nên dừng polling—nghĩa là, dừng
awaiting.
Vòng lặp while let kết hợp tất cả những điều này. Nếu kết quả của việc gọi
rx.recv().await là Some(message), chúng ta có quyền truy cập vào tin nhắn và
chúng ta có thể sử dụng nó trong phần thân vòng lặp, giống như chúng ta có thể
làm với if let. Nếu kết quả là None, vòng lặp kết thúc. Mỗi khi vòng lặp
hoàn thành, nó chạm vào điểm await một lần nữa, vì vậy runtime tạm dừng nó một
lần nữa cho đến khi một tin nhắn khác đến.
Mã bây giờ thành công gửi và nhận tất cả các tin nhắn. Đáng tiếc, vẫn còn một vài vấn đề. Một là, các tin nhắn không đến ở các khoảng thời gian nửa giây. Chúng đến cùng một lúc, 2 giây (2.000 mili giây) sau khi chúng ta bắt đầu chương trình. Vấn đề khác là chương trình này không bao giờ thoát! Thay vào đó, nó đợi mãi mãi cho các tin nhắn mới. Bạn sẽ cần phải tắt nó bằng ctrl-c.
Hãy bắt đầu bằng cách kiểm tra lý do tại sao các tin nhắn đến cùng một lúc sau
khi trì hoãn đầy đủ, thay vì đến với độ trễ giữa mỗi tin. Trong một khối async
nhất định, thứ tự mà các từ khóa await xuất hiện trong mã cũng là thứ tự mà
chúng được thực thi khi chương trình chạy.
Chỉ có một khối async trong Listing 17-10, vì vậy mọi thứ trong đó chạy tuyến
tính. Vẫn chưa có sự đồng thời. Tất cả các lệnh gọi tx.send xảy ra, xen kẽ với
tất cả các lệnh gọi trpl::sleep và các điểm await liên quan. Chỉ sau đó vòng
lặp while let mới đi qua bất kỳ điểm await nào trong các lệnh gọi recv.
Để có được hành vi mà chúng ta muốn, nơi độ trễ sleep xảy ra giữa mỗi tin nhắn,
chúng ta cần đặt các thao tác tx và rx trong các khối async riêng của chúng,
như trong Listing 17-11. Sau đó, runtime có thể thực thi từng khối riêng biệt
bằng cách sử dụng trpl::join, giống như trong ví dụ đếm. Một lần nữa, chúng ta
await kết quả của việc gọi trpl::join, không phải các future riêng lẻ. Nếu
chúng ta await các future riêng lẻ một cách tuần tự, chúng ta sẽ chỉ quay lại
một luồng tuần tự—chính xác những gì chúng ta đang cố gắng không làm.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Với mã đã cập nhật trong Listing 17-11, các tin nhắn được in ở khoảng thời gian 500-mili giây, thay vì tất cả cùng một lúc sau 2 giây.
Tuy nhiên, chương trình vẫn không bao giờ thoát, vì cách mà vòng lặp while let
tương tác với trpl::join:
- Future được trả về từ
trpl::joinchỉ hoàn thành khi cả hai future được truyền vào nó đã hoàn thành. - Future
txhoàn thành khi nó hoàn tất việc ngủ sau khi gửi tin nhắn cuối cùng trongvals. - Future
rxsẽ không hoàn thành cho đến khi vòng lặpwhile letkết thúc. - Vòng lặp
while letsẽ không kết thúc cho đến khi awaitrx.recvtạo raNone. - Await
rx.recvsẽ chỉ trả vềNonekhi đầu kia của kênh được đóng lại. - Kênh sẽ chỉ đóng khi chúng ta gọi
rx.closehoặc khi phía gửi,tx, bị drop. - Chúng ta không gọi
rx.closeở bất kỳ đâu, vàtxsẽ không bị drop cho đến khi khối async ngoài cùng được truyền vàotrpl::runkết thúc. - Khối không thể kết thúc vì nó bị chặn trên
trpl::joinđang hoàn thành, điều này đưa chúng ta trở lại đầu danh sách này.
Chúng ta có thể đóng rx thủ công bằng cách gọi rx.close ở đâu đó, nhưng điều
đó không có nhiều ý nghĩa. Việc dừng lại sau khi xử lý một số lượng tin nhắn tùy
ý sẽ làm cho chương trình tắt, nhưng chúng ta có thể bỏ lỡ các tin nhắn. Chúng
ta cần một cách khác để đảm bảo rằng tx bị drop trước khi kết thúc hàm.
Hiện tại, khối async nơi chúng ta gửi tin nhắn chỉ mượn tx vì gửi tin nhắn
không yêu cầu quyền sở hữu, nhưng nếu chúng ta có thể di chuyển tx vào khối
async đó, nó sẽ bị drop khi khối đó kết thúc. Trong phần Chương 13 Nắm bắt Tham
chiếu hoặc Di chuyển Quyền sở hữu, bạn đã học
cách sử dụng từ khóa move với closure, và, như đã thảo luận trong phần Chương
16 Sử dụng Closure move với Thread, chúng ta thường cần di chuyển dữ liệu vào closure khi làm việc với thread. Cùng
động lực cơ bản áp dụng cho các khối async, vì vậy từ khóa move hoạt động với các
khối async giống như với closure.
Trong Listing 17-12, chúng ta thay đổi khối được sử dụng để gửi tin nhắn từ
async thành async move. Khi chúng ta chạy phiên bản mã này, nó tắt một
cách thanh lịch sau khi tin nhắn cuối cùng được gửi và nhận.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let tx_fut = async move { // --snip-- let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; trpl::join(tx_fut, rx_fut).await; }); }
Kênh async này cũng là một kênh đa-nhà sản xuất, vì vậy chúng ta có thể gọi
clone trên tx nếu chúng ta muốn gửi tin nhắn từ nhiều future, như trong
Listing 17-13.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = async move { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx1.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; let tx_fut = async move { let vals = vec![ String::from("more"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(1500)).await; } }; trpl::join!(tx1_fut, tx_fut, rx_fut); }); }
Đầu tiên, chúng ta sao chép tx, tạo ra tx1 bên ngoài khối async đầu tiên.
Chúng ta di chuyển tx1 vào khối đó giống như chúng ta đã làm trước đây với
tx. Sau đó, sau này, chúng ta di chuyển tx ban đầu vào một khối async mới,
nơi chúng ta gửi thêm tin nhắn với độ trễ hơi chậm hơn. Chúng ta tình cờ đặt
khối async mới này sau khối async để nhận tin nhắn, nhưng nó cũng có thể đi
trước nó. Chìa khóa là thứ tự mà các future được await, không phải thứ tự chúng
được tạo ra.
Cả hai khối async để gửi tin nhắn cần phải là các khối async move để cả tx
và tx1 đều bị drop khi các khối đó kết thúc. Nếu không, chúng ta sẽ quay trở
lại vòng lặp vô hạn mà chúng ta đã bắt đầu. Cuối cùng, chúng ta chuyển từ
trpl::join sang trpl::join3 để xử lý future bổ sung.
Bây giờ chúng ta thấy tất cả các tin nhắn từ cả hai future gửi, và vì các future gửi sử dụng các độ trễ hơi khác nhau sau khi gửi, các tin nhắn cũng được nhận ở những khoảng thời gian khác nhau đó.
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
Đây là một khởi đầu tốt, nhưng nó giới hạn chúng ta ở chỉ một vài future: hai
với join, hoặc ba với join3. Hãy xem chúng ta có thể làm việc với nhiều
future hơn như thế nào.
Nhường Quyền Kiểm Soát cho Runtime
Nhớ lại từ phần "Our First Async Program" rằng tại mỗi điểm await, Rust cho phép runtime có cơ hội tạm dừng tác vụ và chuyển sang một tác vụ khác nếu future đang được await chưa sẵn sàng. Điều ngược lại cũng đúng: Rust chỉ tạm dừng các async block và trả quyền kiểm soát lại cho runtime tại một điểm await. Mọi thứ giữa các điểm await là đồng bộ.
Điều đó có nghĩa là nếu bạn thực hiện một loạt công việc trong một async block mà không có điểm await, future đó sẽ chặn bất kỳ future nào khác thực hiện tiến trình. Đôi khi bạn có thể nghe điều này được gọi là một future đói các future khác. Trong một số trường hợp, điều đó có thể không phải là vấn đề lớn. Tuy nhiên, nếu bạn đang thực hiện một số loại thiết lập đắt tiền hoặc công việc chạy dài, hoặc nếu bạn có một future sẽ tiếp tục thực hiện một số tác vụ cụ thể vô thời hạn, bạn sẽ cần suy nghĩ về khi nào và ở đâu để bàn giao quyền kiểm soát cho runtime.
Hãy mô phỏng một hoạt động chạy dài để minh họa vấn đề đói, sau đó khám phá cách
giải quyết nó. Listing 17-14 giới thiệu một hàm slow.
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::block_on(async { // We will call `slow` here later }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
Đây chắc chắn là một cải tiến so với việc chuyển đổi giữa join và join3 và
join4 và v.v.! Tuy nhiên, ngay cả dạng macro này cũng chỉ hoạt động khi chúng
ta biết số lượng future trước. Trong Rust thực tế, việc đưa các future vào một
tập hợp và sau đó đợi một số hoặc tất cả các future hoàn thành là một mẫu phổ
biến.
Để kiểm tra tất cả các future trong một tập hợp, chúng ta cần lặp qua và kết hợp
tất cả chúng. Hàm trpl::join_all chấp nhận bất kỳ kiểu nào thực thi trait
Iterator, mà bạn đã học trong [The Iterator Trait and the next
Method][iterator-trait] Chương 13, vì vậy nó có vẻ như đúng là
thứ chúng ta cần. Hãy thử đặt các future của chúng ta vào một vector và thay thế
join! bằng join_all như trong Listing 17-15.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Thật không may, mã này không biên dịch được. Thay vào đó, chúng ta nhận được lỗi này:
error[E0308]: mismatched types
--> src/main.rs:45:37
|
10 | let tx1_fut = async move {
| ---------- the expected `async` block
...
24 | let rx_fut = async {
| ----- the found `async` block
...
45 | let futures = vec![tx1_fut, rx_fut, tx_fut];
| ^^^^^^ expected `async` block, found a different `async` block
|
= note: expected `async` block `{async block@src/main.rs:10:23: 10:33}`
found `async` block `{async block@src/main.rs:24:22: 24:27}`
= note: no two async blocks, even if identical, have the same type
= help: consider pinning your async block and casting it to a trait object
Điều này có thể gây ngạc nhiên. Rốt cuộc, không có async block nào trả về bất cứ
thứ gì, nên mỗi block tạo ra một Future<Output = ()>. Hãy nhớ rằng Future là
một trait, tuy nhiên, và trình biên dịch tạo ra một enum duy nhất cho mỗi async
block. Bạn không thể đặt hai struct viết tay khác nhau trong một Vec, và quy
tắc tương tự áp dụng cho các enum khác nhau được tạo ra bởi trình biên dịch.
Để làm cho điều này hoạt động, chúng ta cần sử dụng trait objects, giống như
chúng ta đã làm trong ["Returning Errors from the run
function"][dyn] ở Chương 12. (Chúng ta sẽ đề cập chi tiết về các
trait object trong Chương 18.) Sử dụng trait object cho phép chúng ta xem xét
mỗi future ẩn danh được tạo ra bởi các kiểu này là cùng một kiểu, bởi vì tất cả
chúng đều thực thi trait Future.
Lưu ý: Trong [Using an Enum to Store Multiple Values][enum-alt] ở Chương 8, chúng ta đã thảo luận về một cách khác để bao gồm nhiều kiểu trong một
Vec: sử dụng một enum để đại diện cho mỗi kiểu có thể xuất hiện trong vector. Chúng ta không thể làm điều đó ở đây. Một mặt, chúng ta không có cách để đặt tên cho các kiểu khác nhau, bởi vì chúng là ẩn danh. Mặt khác, lý do chúng ta chọn vector vàjoin_allngay từ đầu là để có thể làm việc với một tập hợp động của các future mà chúng ta chỉ quan tâm rằng chúng có cùng kiểu đầu ra.
Chúng ta bắt đầu bằng cách bọc mỗi future trong vec! trong một Box::new, như
trong Listing 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Thật không may, mã này vẫn không biên dịch. Thực tế, chúng ta nhận được cùng lỗi
cơ bản mà chúng ta đã nhận trước đó cho cả hai lệnh gọi Box::new thứ hai và
thứ ba, cũng như các lỗi mới đề cập đến trait Unpin. Chúng ta sẽ quay lại các
lỗi Unpin trong giây lát. Trước tiên, hãy sửa các lỗi kiểu trên các lệnh gọi
Box::new bằng cách chú thích rõ ràng kiểu của biến futures (xem Listing
17-17).
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Khai báo kiểu này hơi phức tạp, vì vậy hãy cùng đi qua nó:
- Kiểu bên trong cùng là future. Chúng ta lưu ý rõ ràng rằng đầu ra của future
là kiểu đơn vị
()bằng cách viếtFuture<Output = ()>. - Sau đó, chúng ta chú thích trait với
dynđể đánh dấu nó là động. - Toàn bộ tham chiếu trait được bọc trong một
Box. - Cuối cùng, chúng ta nêu rõ rằng
futureslà mộtVecchứa những mục này.
Điều đó đã tạo ra một sự khác biệt lớn. Bây giờ khi chúng ta chạy trình biên
dịch, chúng ta chỉ nhận được các lỗi đề cập đến Unpin. Mặc dù có ba lỗi, nhưng
nội dung của chúng rất giống nhau.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:49:24
|
49 | trpl::join_all(futures).await;
| -------------- ^^^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
| |
| required by a bound introduced by this call
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `join_all`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:105:14
|
102 | pub fn join_all<I>(iter: I) -> JoinAll<I::Item>
| -------- required by a bound in this function
...
105 | I::Item: Future,
| ^^^^^^ required by this bound in `join_all`
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:49:9
|
49 | trpl::join_all(futures).await;
| ^^^^^^^^^^^^^^^^^^^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:49:33
|
49 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `async_await` (bin "async_await") due to 3 previous errors
Đó là rất nhiều thông tin để tiêu hóa, vì vậy hãy phân tích nó. Phần đầu tiên
của thông báo cho chúng ta biết rằng async block đầu tiên
(src/main.rs:8:23: 20:10) không thực thi trait Unpin và đề xuất sử dụng
pin! hoặc Box::pin để giải quyết vấn đề. Về sau trong chương, chúng ta sẽ đi
sâu vào một vài chi tiết khác về Pin và Unpin. Tuy nhiên, hiện tại, chúng ta
có thể làm theo lời khuyên của trình biên dịch để giải quyết vấn đề. Trong
Listing 17-18, chúng ta bắt đầu bằng cách import Pin từ std::pin. Tiếp theo,
chúng ta cập nhật chú thích kiểu cho futures, với một Pin bao bọc mỗi Box.
Cuối cùng, chúng ta sử dụng Box::pin để cố định các future.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { let slow = async { trpl::sleep(Duration::from_secs(5)).await; "Finally finished" }; match timeout(slow, Duration::from_secs(2)).await { Ok(message) => println!("Succeeded with '{message}'"), Err(duration) => { println!("Failed after {} seconds", duration.as_secs()) } } }); }
Nếu chúng ta biên dịch và chạy mã này, cuối cùng chúng ta sẽ nhận được kết quả mong muốn:
received 'hi'
received 'more'
received 'from'
received 'messages'
received 'the'
received 'for'
received 'future'
received 'you'
Xong rồi!
Có một chút điều cần khám phá thêm ở đây. Một mặt, việc sử dụng Pin<Box<T>>
thêm một lượng nhỏ chi phí từ việc đưa các future này lên heap với Box—và
chúng ta chỉ làm điều đó để làm cho các kiểu phù hợp. Chúng ta thực sự không
cần cấp phát trên heap, sau tất cả: các future này là cục bộ cho hàm cụ thể
này. Như đã lưu ý trước đó, Pin tự nó là một kiểu bao bọc, vì vậy chúng ta có
thể nhận được lợi ích của việc có một kiểu duy nhất trong Vec—lý do ban đầu
chúng ta chọn Box—mà không cần cấp phát heap. Chúng ta có thể sử dụng Pin
trực tiếp với mỗi future, sử dụng macro std::pin::pin.
Tuy nhiên, chúng ta vẫn phải rõ ràng về kiểu của tham chiếu được ghim; nếu
không, Rust vẫn không biết cách diễn giải chúng như các đối tượng trait động, đó
là những gì chúng ta cần chúng trở thành trong Vec. Do đó, chúng ta thêm pin
vào danh sách import của chúng ta từ std::pin. Sau đó, chúng ta có thể pin!
mỗi future khi chúng ta định nghĩa nó và định nghĩa futures là một Vec chứa
các tham chiếu có thể thay đổi được ghim đến kiểu future động, như trong Listing
17-19.
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::block_on(async { let slow = async { trpl::sleep(Duration::from_secs(5)).await; "Finally finished" }; match timeout(slow, Duration::from_secs(2)).await { Ok(message) => println!("Succeeded with '{message}'"), Err(duration) => { println!("Failed after {} seconds", duration.as_secs()) } } }); } async fn timeout<F: Future>( future_to_try: F, max_time: Duration, ) -> Result<F::Output, Duration> { // Here is where our implementation will go! }
Chúng ta đã đi đến đây bằng cách bỏ qua thực tế rằng chúng ta có thể có các kiểu
Output khác nhau. Ví dụ, trong Listing 17-20, future ẩn danh cho a thực thi
Future<Output = u32>, future ẩn danh cho b thực thi Future<Output = &str>,
và future ẩn danh cho c thực thi Future<Output = bool>.
extern crate trpl; // required for mdbook test use std::time::Duration; use trpl::Either; // --snip-- fn main() { trpl::block_on(async { let slow = async { trpl::sleep(Duration::from_secs(5)).await; "Finally finished" }; match timeout(slow, Duration::from_secs(2)).await { Ok(message) => println!("Succeeded with '{message}'"), Err(duration) => { println!("Failed after {} seconds", duration.as_secs()) } } }); } async fn timeout<F: Future>( future_to_try: F, max_time: Duration, ) -> Result<F::Output, Duration> { match trpl::select(future_to_try, trpl::sleep(max_time)).await { Either::Left(output) => Ok(output), Either::Right(_) => Err(max_time), } }
Chúng ta có thể sử dụng trpl::join! để đợi chúng, bởi vì nó cho phép chúng ta
truyền vào nhiều kiểu future và tạo ra một tuple của các kiểu đó. Chúng ta
không thể sử dụng trpl::join_all, bởi vì nó yêu cầu tất cả các future được
truyền vào phải có cùng kiểu. Hãy nhớ rằng, lỗi đó là những gì khiến chúng ta
bắt đầu cuộc phiêu lưu này với Pin!
Đây là một sự đánh đổi cơ bản: chúng ta có thể xử lý một số lượng động của các
future với join_all, miễn là tất cả chúng đều có cùng kiểu, hoặc chúng ta có
thể xử lý một tập hợp cố định số lượng future với các hàm join hoặc macro
join!, ngay cả khi chúng có các kiểu khác nhau. Đây là cùng một kịch bản chúng
ta gặp phải khi làm việc với bất kỳ kiểu nào khác trong Rust. Future không có gì
đặc biệt, mặc dù chúng ta có một số cú pháp tốt để làm việc với chúng, và đó là
một điều tốt.
Đua Các Future
Khi chúng ta "join" các future với họ hàm join và các macro, chúng ta yêu cầu
tất cả chúng phải hoàn thành trước khi chúng ta tiếp tục. Đôi khi, tuy nhiên,
chúng ta chỉ cần một số future từ một tập hợp hoàn thành trước khi chúng ta
tiếp tục—hơi giống với việc đua một future với một future khác.
Trong Listing 17-21, chúng ta một lần nữa sử dụng trpl::race để chạy hai
future, slow và fast, đua nhau.
extern crate trpl; // required for mdbook test fn main() { trpl::block_on(async { let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let iter = values.iter().map(|n| n * 2); let mut stream = trpl::stream_from_iter(iter); while let Some(value) = stream.next().await { println!("The value was: {value}"); } }); }
Mỗi future in một thông báo khi nó bắt đầu chạy, tạm dừng một khoảng thời gian
bằng cách gọi và đợi sleep, và sau đó in một thông báo khác khi nó hoàn thành.
Sau đó, chúng ta truyền cả slow và fast cho trpl::race và đợi một trong số
chúng hoàn thành. (Kết quả ở đây không quá đáng ngạc nhiên: fast thắng.) Không
giống như khi chúng ta sử dụng race trở lại trong "Our First Async
Program", chúng ta chỉ bỏ qua thể hiện Either mà nó trả về ở đây, bởi vì tất
cả các hành vi thú vị xảy ra trong phần thân của các async block.
Chú ý rằng nếu bạn đảo ngược thứ tự các đối số cho race, thứ tự của các thông
báo "started" sẽ thay đổi, mặc dù future fast luôn hoàn thành trước. Đó là vì
việc thực thi của hàm race cụ thể này là không công bằng. Nó luôn chạy các
future được truyền vào làm đối số theo thứ tự chúng được truyền vào. Các cách
thực thi khác là công bằng và sẽ chọn ngẫu nhiên future nào được poll đầu
tiên. Bất kể việc thực thi race mà chúng ta đang sử dụng có công bằng hay không,
một trong các future sẽ chạy đến điểm await đầu tiên trong phần thân của nó
trước khi một tác vụ khác có thể bắt đầu.
Nhớ lại từ Our First Async Program rằng tại mỗi điểm await, Rust cho phép runtime có cơ hội tạm dừng tác vụ và chuyển sang một tác vụ khác nếu future đang được await chưa sẵn sàng. Điều ngược lại cũng đúng: Rust chỉ tạm dừng các async block và trả quyền kiểm soát lại cho runtime tại một điểm await. Mọi thứ giữa các điểm await là đồng bộ.
Điều đó có nghĩa là nếu bạn thực hiện một loạt công việc trong một async block mà không có điểm await, future đó sẽ chặn bất kỳ future nào khác thực hiện tiến trình. Đôi khi bạn có thể nghe điều này được gọi là một future đói các future khác. Trong một số trường hợp, điều đó có thể không phải là vấn đề lớn. Tuy nhiên, nếu bạn đang thực hiện một số loại thiết lập đắt tiền hoặc công việc chạy dài, hoặc nếu bạn có một future sẽ tiếp tục thực hiện một số tác vụ cụ thể vô thời hạn, bạn sẽ cần suy nghĩ về khi nào và ở đâu để bàn giao quyền kiểm soát cho runtime.
Cũng vậy, nếu bạn có các hoạt động chặn chạy dài, async có thể là một công cụ hữu ích để cung cấp các cách cho các phần khác nhau của chương trình liên quan với nhau.
Nhưng làm thế nào bạn sẽ bàn giao quyền kiểm soát cho runtime trong những trường hợp đó?
Nhường Quyền Kiểm Soát cho Runtime
Hãy mô phỏng một hoạt động chạy dài. Listing 17-22 giới thiệu một hàm slow.
extern crate trpl; // required for mdbook test use trpl::StreamExt; fn main() { trpl::block_on(async { let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; // --snip-- let iter = values.iter().map(|n| n * 2); let mut stream = trpl::stream_from_iter(iter); while let Some(value) = stream.next().await { println!("The value was: {value}"); } }); }
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::block_on(async { // We will call `slow` here later }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
Mã này sử dụng std::thread::sleep thay vì trpl::sleep để khi gọi slow sẽ
chặn thread hiện tại trong một số mili giây. Chúng ta có thể sử dụng slow để
đại diện cho các hoạt động trong thế giới thực vừa chạy lâu vừa chặn.
Trong Listing 17-15, chúng ta sử dụng slow để mô phỏng việc thực hiện loại
công việc gắn với CPU này trong một cặp future.
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::block_on(async { let a = async { println!("'a' started."); slow("a", 30); slow("a", 10); slow("a", 20); trpl::sleep(Duration::from_millis(50)).await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); slow("b", 10); slow("b", 15); slow("b", 350); trpl::sleep(Duration::from_millis(50)).await; println!("'b' finished."); }; trpl::select(a, b).await; }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
Để bắt đầu, mỗi future chỉ trả lại quyền kiểm soát cho runtime sau khi thực hiện một loạt các hoạt động chậm. Nếu bạn chạy mã này, bạn sẽ thấy kết quả này:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Mỗi future trả lại quyền kiểm soát cho runtime chỉ sau khi thực hiện một loạt các hoạt động chậm. Nếu bạn chạy mã này, bạn sẽ thấy kết quả này:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Giống như ví dụ Listing 17-5 khi chúng ta sử dụng trpl::select để đua các
future lấy hai URL, select vẫn kết thúc ngay khi a hoàn thành. Không có sự
xen kẽ giữa các lệnh gọi slow trong hai future. Future a thực hiện tất cả
công việc của nó cho đến khi lệnh gọi trpl::sleep được await, sau đó future
b thực hiện tất cả công việc của nó cho đến khi lệnh gọi trpl::sleep của
riêng nó được await, và cuối cùng future a hoàn thành. Để cho phép cả hai
future thực hiện tiến trình giữa các tác vụ chậm của chúng, chúng ta cần các
điểm await để chúng ta có thể bàn giao quyền kiểm soát cho runtime. Điều đó có
nghĩa là chúng ta cần thứ gì đó mà chúng ta có thể await!
Chúng ta đã có thể thấy loại bàn giao này xảy ra trong Listing 17-15: nếu chúng
ta loại bỏ trpl::sleep ở cuối future a, nó sẽ hoàn thành mà không có future
b chạy chút nào. Hãy thử sử dụng hàm trpl::sleep làm điểm khởi đầu để cho
phép các hoạt động luân phiên thực hiện tiến trình, như được hiển thị trong
Listing 17-16.
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::block_on(async { let one_ms = Duration::from_millis(1); let a = async { println!("'a' started."); slow("a", 30); trpl::sleep(one_ms).await; slow("a", 10); trpl::sleep(one_ms).await; slow("a", 20); trpl::sleep(one_ms).await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); trpl::sleep(one_ms).await; slow("b", 10); trpl::sleep(one_ms).await; slow("b", 15); trpl::sleep(one_ms).await; slow("b", 350); trpl::sleep(one_ms).await; println!("'b' finished."); }; trpl::select(a, b).await; }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
Chúng ta đã thêm các lệnh gọi trpl::sleep với các điểm await giữa mỗi lệnh gọi
đến slow. Bây giờ công việc của hai future được xen kẽ:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
Future a vẫn chạy một chút trước khi bàn giao quyền kiểm soát cho b, bởi vì
nó gọi slow trước khi từng gọi trpl::sleep, nhưng sau đó các future hoán đổi
qua lại mỗi khi một trong số chúng đạt đến một điểm await. Trong trường hợp này,
chúng ta đã làm điều đó sau mỗi lệnh gọi đến slow, nhưng chúng ta có thể chia
nhỏ công việc theo bất kỳ cách nào hợp lý nhất đối với chúng ta.
Tuy nhiên, chúng ta không thực sự muốn ngủ ở đây: chúng ta muốn thực hiện tiến
trình nhanh nhất có thể. Chúng ta chỉ cần trả lại quyền kiểm soát cho runtime.
Chúng ta có thể làm điều đó trực tiếp, sử dụng hàm trpl::yield_now. Trong
Listing 17-17, chúng ta thay thế tất cả những lệnh gọi trpl::sleep bằng
trpl::yield_now.
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::block_on(async { let a = async { println!("'a' started."); slow("a", 30); trpl::yield_now().await; slow("a", 10); trpl::yield_now().await; slow("a", 20); trpl::yield_now().await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); trpl::yield_now().await; slow("b", 10); trpl::yield_now().await; slow("b", 15); trpl::yield_now().await; slow("b", 350); trpl::yield_now().await; println!("'b' finished."); }; trpl::select(a, b).await; }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
Mã này vừa rõ ràng hơn về ý định thực tế vừa có thể nhanh hơn đáng kể so với
việc sử dụng sleep, bởi vì các bộ đếm thời gian như bộ được sử dụng bởi
sleep thường có giới hạn về mức độ chi tiết mà chúng có thể có. Phiên bản
sleep mà chúng ta đang sử dụng, ví dụ, sẽ luôn ngủ ít nhất một mili giây, ngay
cả khi chúng ta truyền cho nó một Duration một nano giây. Một lần nữa, máy
tính hiện đại nhanh: chúng có thể làm rất nhiều trong một mili giây!
Điều này có nghĩa là async có thể hữu ích ngay cả cho các tác vụ gắn với tính toán, tùy thuộc vào những gì chương trình của bạn đang làm, bởi vì nó cung cấp một công cụ hữu ích để cấu trúc các mối quan hệ giữa các phần khác nhau của chương trình (nhưng với chi phí của overhead từ state machine async). Đây là một hình thức đa nhiệm hợp tác, trong đó mỗi future có quyền xác định khi nào nó bàn giao quyền kiểm soát thông qua các điểm await. Mỗi future do đó cũng có trách nhiệm tránh chặn quá lâu. Trong một số hệ điều hành nhúng dựa trên Rust, đây là loại duy nhất của đa nhiệm!
Trong mã thực tế, bạn thường sẽ không thay đổi các lệnh gọi hàm với các điểm await trên mỗi dòng, tất nhiên. Mặc dù nhường quyền kiểm soát theo cách này là tương đối không tốn kém, nhưng nó không miễn phí. Trong nhiều trường hợp, việc cố gắng chia nhỏ một tác vụ gắn với tính toán có thể làm cho nó chậm hơn đáng kể, vì vậy đôi khi tốt hơn cho hiệu suất tổng thể là để một hoạt động chặn ngắn. Luôn đo lường để xem thực sự các nút thắt cổ chai hiệu suất của mã của bạn là gì. Động lực cơ bản là điều quan trọng cần ghi nhớ, tuy nhiên, nếu bạn đang thấy nhiều công việc xảy ra tuần tự mà bạn mong đợi xảy ra đồng thời!
Xây Dựng Các Sự Trừu Tượng Async Của Riêng Chúng Ta
Chúng ta cũng có thể kết hợp các future lại với nhau để tạo ra các mẫu mới. Ví
dụ, chúng ta có thể xây dựng một hàm timeout với các khối xây dựng async mà
chúng ta đã có. Khi chúng ta hoàn thành, kết quả sẽ là một khối xây dựng khác mà
chúng ta có thể sử dụng để tạo ra thêm các sự trừu tượng async.
Listing 17-18 hiển thị cách chúng ta mong đợi timeout này hoạt động với một
future chậm.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}Hãy triển khai điều này! Để bắt đầu, hãy suy nghĩ về API cho timeout:
- Nó cần phải là một hàm async để chúng ta có thể await nó.
- Tham số đầu tiên của nó phải là một future để chạy. Chúng ta có thể làm cho nó generic để cho phép nó hoạt động với bất kỳ future nào.
- Tham số thứ hai của nó sẽ là thời gian tối đa để đợi. Nếu chúng ta sử dụng một
Duration, điều đó sẽ làm cho nó dễ dàng để truyền chotrpl::sleep. - Nó sẽ trả về một
Result. Nếu future hoàn thành thành công,Resultsẽ làOkvới giá trị được tạo ra bởi future. Nếu timeout hết hạn trước,Resultsẽ làErrvới duration mà timeout đã đợi.
Listing 17-19 hiển thị khai báo này.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}Điều đó đáp ứng các mục tiêu của chúng ta cho các kiểu. Bây giờ hãy suy nghĩ về
hành vi mà chúng ta cần: chúng ta muốn đua future được truyền vào với
duration. Chúng ta có thể sử dụng trpl::sleep để tạo một future bộ đếm thời
gian từ duration, và sử dụng trpl::select để chạy bộ đếm thời gian đó với
future mà người gọi truyền vào.
Trong Listing 17-20, chúng ta triển khai timeout bằng cách match trên kết quả
của việc await trpl::select.
extern crate trpl; // required for mdbook test use std::time::Duration; use trpl::Either; // --snip-- fn main() { trpl::block_on(async { let slow = async { trpl::sleep(Duration::from_secs(5)).await; "Finally finished" }; match timeout(slow, Duration::from_secs(2)).await { Ok(message) => println!("Succeeded with '{message}'"), Err(duration) => { println!("Failed after {} seconds", duration.as_secs()) } } }); } async fn timeout<F: Future>( future_to_try: F, max_time: Duration, ) -> Result<F::Output, Duration> { match trpl::select(future_to_try, trpl::sleep(max_time)).await { Either::Left(output) => Ok(output), Either::Right(_) => Err(max_time), } }
Việc triển khai trpl::select không công bằng: nó luôn poll các đối số theo thứ
tự mà chúng được truyền vào (các triển khai select khác sẽ chọn ngẫu nhiên đối
số nào được poll đầu tiên). Do đó, chúng ta truyền future_to_try cho select
trước để nó có cơ hội hoàn thành ngay cả khi max_time là một duration rất
ngắn. Nếu future_to_try hoàn thành trước, select sẽ trả về Left với đầu ra
từ future_to_try. Nếu timer hoàn thành trước, select sẽ trả về Right với
đầu ra của timer là ().
Nếu future_to_try thành công và chúng ta nhận được Left(output), chúng ta
trả về Ok(output). Nếu bộ đếm thời gian ngủ hết hạn thay vào đó và chúng ta
nhận được Right(()), chúng ta bỏ qua () với _ và trả về Err(max_time)
thay thế.
Với điều đó, chúng ta có một timeout hoạt động được xây dựng từ hai trợ giúp
async khác. Nếu chúng ta chạy mã của mình, nó sẽ in chế độ thất bại sau timeout:
Failed after 2 seconds
Bởi vì future kết hợp với các future khác, bạn có thể xây dựng các công cụ thực sự mạnh mẽ sử dụng các khối xây dựng async nhỏ hơn. Ví dụ, bạn có thể sử dụng cùng cách tiếp cận này để kết hợp timeout với thử lại, và đến lượt sử dụng chúng với các hoạt động như các cuộc gọi mạng (như những cuộc gọi trong Listing 17-5).
Trong thực tế, bạn thường sẽ làm việc trực tiếp với async và await, và thứ
hai là với các hàm như select và macro như join! để kiểm soát cách các
future bên ngoài được thực thi.
Bây giờ chúng ta đã thấy một số cách để làm việc với nhiều future cùng một lúc. Tiếp theo, chúng ta sẽ xem cách làm việc với nhiều future trong một chuỗi theo thời gian với streams.
Streams: Future theo Trình tự
Cho đến nay trong chương này, chúng ta chủ yếu đã làm việc với các future riêng
lẻ. Một ngoại lệ lớn là kênh async mà chúng ta đã sử dụng. Hãy nhớ lại cách
chúng ta đã sử dụng bộ thu cho kênh async của chúng ta trước đó trong chương này
ở phần "Message Passing". Phương thức recv
async tạo ra một chuỗi các mục theo thời gian. Đây là một ví dụ của một mẫu tổng
quát hơn được gọi là stream.
Chúng ta đã thấy một chuỗi các mục trong Chương 13, khi chúng ta xem xét trait
Iterator trong phần The Iterator Trait and the next
Method, nhưng có hai sự khác biệt giữa iterators và bộ thu kênh async. Sự khác biệt
đầu tiên là thời gian: iterators là đồng bộ, trong khi bộ thu kênh là bất đồng bộ.
Thứ hai là API. Khi làm việc trực tiếp với Iterator, chúng ta gọi phương thức next
đồng bộ của nó. Với stream trpl::Receiver cụ thể, chúng ta đã gọi một phương thức
recv bất đồng bộ thay thế. Ngoài ra, các API này cảm thấy rất giống nhau, và sự
tương đồng đó không phải là sự trùng hợp. Một stream giống như một hình thức lặp
bất đồng bộ. Trong khi trpl::Receiver cụ thể đợi để nhận tin nhắn, thì API stream
đa năng chung rộng hơn nhiều: nó cung cấp mục tiếp theo theo cách Iterator làm,
nhưng bất đồng bộ.
Sự tương đồng giữa iterators và streams trong Rust có nghĩa là chúng ta thực sự
có thể tạo một stream từ bất kỳ iterator nào. Giống như với một iterator, chúng
ta có thể làm việc với một stream bằng cách gọi phương thức next của nó và sau
đó đợi kết quả, như trong Listing 17-30.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Chúng ta bắt đầu với một mảng các số, mà chúng ta chuyển đổi thành một iterator
và sau đó gọi map trên nó để nhân đôi tất cả các giá trị. Sau đó, chúng ta
chuyển đổi iterator thành stream bằng cách sử dụng hàm trpl::stream_from_iter.
Tiếp theo, chúng ta lặp qua các mục trong stream khi chúng xuất hiện với vòng
lặp while let.
Thật không may, khi chúng ta thử chạy mã, nó không biên dịch được, mà thay vào
đó báo cáo rằng không có phương thức next nào khả dụng:
error[E0599]: no method named `next` found for struct `Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= note: the full type name has been written to 'file:///projects/async-await/target/debug/deps/async_await-575db3dd3197d257.long-type-14490787947592691573.txt'
= note: consider using `--verbose` to print the full type name to the console
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Như kết quả này giải thích, lý do cho lỗi biên dịch là chúng ta cần trait đúng
trong phạm vi để có thể sử dụng phương thức next. Dựa trên cuộc thảo luận của
chúng ta cho đến nay, bạn có thể mong đợi một cách hợp lý rằng trait đó là
Stream, nhưng nó thực sự là StreamExt. Viết tắt của extension, Ext là
một mẫu phổ biến trong cộng đồng Rust để mở rộng một trait với một trait khác.
Chúng ta sẽ giải thích các trait Stream và StreamExt chi tiết hơn một chút
vào cuối chương, nhưng hiện tại tất cả những gì bạn cần biết là trait Stream
định nghĩa một giao diện cấp thấp mà hiệu quả là kết hợp các trait Iterator và
Future. StreamExt cung cấp một tập hợp API cấp cao hơn trên Stream, bao
gồm phương thức next cũng như các phương thức tiện ích khác tương tự như những
phương thức được cung cấp bởi trait Iterator. Stream và StreamExt chưa
phải là một phần của thư viện chuẩn của Rust, nhưng hầu hết các crate trong hệ
sinh thái sử dụng cùng định nghĩa.
Cách sửa lỗi biên dịch là thêm câu lệnh use cho trpl::StreamExt, như trong
Listing 17-31.
// Note: Listing 17-38 code is not available in the listings folder
// This content may be from a different version of the bookVới tất cả các phần đó được kết hợp lại, mã này hoạt động theo cách chúng ta
muốn! Hơn nữa, bây giờ chúng ta có StreamExt trong phạm vi, chúng ta có thể sử
dụng tất cả các phương thức tiện ích của nó, giống như với các iterator. Ví dụ,
trong Listing 17-32, chúng ta sử dụng phương thức filter để lọc ra tất cả trừ
bội số của ba và năm.
// Note: Listing 17-37 code is not available in the listings folder
// This content may be from a different version of the bookTất nhiên, điều này không quá thú vị, vì chúng ta có thể làm tương tự với các iterator thông thường và không cần async gì cả. Hãy xem những gì chúng ta có thể làm mà là độc đáo cho streams.
Kết hợp các Streams
Nhiều khái niệm tự nhiên được biểu diễn dưới dạng streams: các mục trở nên có sẵn trong một hàng đợi, các đoạn dữ liệu được kéo dần từ hệ thống tập tin khi tập dữ liệu đầy đủ quá lớn đối với bộ nhớ của máy tính, hoặc dữ liệu đến qua mạng theo thời gian. Vì streams là futures, chúng ta có thể sử dụng chúng với bất kỳ loại future nào khác và kết hợp chúng theo những cách thú vị. Ví dụ, chúng ta có thể gộp các sự kiện để tránh kích hoạt quá nhiều cuộc gọi mạng, đặt thời gian chờ trên chuỗi các hoạt động chạy dài, hoặc hạn chế các sự kiện giao diện người dùng để tránh làm công việc không cần thiết.
Hãy bắt đầu bằng việc xây dựng một stream nhỏ gồm các tin nhắn như một thay thế cho stream dữ liệu mà chúng ta có thể thấy từ WebSocket hoặc giao thức giao tiếp thời gian thực khác, như được hiển thị trong Listing 17-33.
// Note: Listing 17-33 code is not available in the listings folder
// This content may be from a different version of the bookĐầu tiên, chúng ta tạo một hàm gọi là get_messages mà trả về
impl Stream<Item = String>. Đối với cách thực hiện của nó, chúng ta tạo một
kênh async, lặp qua 10 chữ cái đầu tiên của bảng chữ cái tiếng Anh, và gửi chúng
qua kênh.
Chúng ta cũng sử dụng một kiểu mới: ReceiverStream, nó chuyển đổi bộ thu rx
từ trpl::channel thành một Stream với một phương thức next. Trở lại trong
main, chúng ta sử dụng một vòng lặp while let để in tất cả các tin nhắn từ
stream.
Khi chúng ta chạy mã này, chúng ta nhận được chính xác kết quả mà chúng ta mong đợi:
Message: 'a'
Message: 'b'
Message: 'c'
Message: 'd'
Message: 'e'
Message: 'f'
Message: 'g'
Message: 'h'
Message: 'i'
Message: 'j'
Một lần nữa, chúng ta có thể làm điều này với API Receiver thông thường hoặc
thậm chí API Iterator thông thường, mặc dù vậy, nên hãy thêm một tính năng yêu
cầu streams: thêm một timeout áp dụng cho mọi mục trong stream, và một độ trễ
trên các mục mà chúng ta phát ra, như trong Listing 17-34.
// Note: Listing 17-34 code is not available in the listings folder
// This content may be from a different version of the bookChúng ta bắt đầu bằng việc thêm một timeout vào stream với phương thức
timeout, nó đến từ trait StreamExt. Sau đó, chúng ta cập nhật thân của vòng
lặp while let, bởi vì stream bây giờ trả về một Result. Biến thể Ok chỉ ra
rằng một tin nhắn đã đến kịp thời; biến thể Err chỉ ra rằng timeout đã hết hạn
trước khi bất kỳ tin nhắn nào đến. Chúng ta match trên kết quả đó và hoặc in
tin nhắn khi chúng ta nhận được nó thành công hoặc in một thông báo về timeout.
Cuối cùng, chú ý rằng chúng ta ghim các tin nhắn sau khi áp dụng timeout cho
chúng, bởi vì trợ giúp timeout tạo ra một stream cần được ghim để được poll.
Tuy nhiên, bởi vì không có độ trễ giữa các tin nhắn, timeout này không thay đổi hành vi của chương trình. Hãy thêm một độ trễ thay đổi cho các tin nhắn mà chúng ta gửi, như trong Listing 17-35.
// Note: Listing 17-35 code is not available in the listings folder
// This content may be from a different version of the bookTrong get_messages, chúng ta sử dụng phương thức iterator enumerate với mảng
messages để chúng ta có thể lấy chỉ số của mỗi mục mà chúng ta đang gửi cùng
với chính mục đó. Sau đó, chúng ta áp dụng một độ trễ 100 mili giây cho các mục
có chỉ số chẵn và một độ trễ 300 mili giây cho các mục có chỉ số lẻ để mô phỏng
các độ trễ khác nhau mà chúng ta có thể thấy từ một stream các tin nhắn trong
thế giới thực. Bởi vì timeout của chúng ta là 200 mili giây, điều này sẽ ảnh
hưởng đến một nửa các tin nhắn.
Để ngủ giữa các tin nhắn trong hàm get_messages mà không chặn, chúng ta cần sử
dụng async. Tuy nhiên, chúng ta không thể biến get_messages thành một hàm
async, bởi vì sau đó chúng ta sẽ trả về một
Future<Output = Stream<Item = String>> thay vì một Stream<Item = String>>.
Người gọi sẽ phải await chính get_messages để có quyền truy cập vào stream.
Nhưng hãy nhớ: mọi thứ trong một future nhất định xảy ra tuyến tính; tính đồng
thời xảy ra giữa các future. Awaiting get_messages sẽ yêu cầu nó gửi tất cả
các tin nhắn, bao gồm cả độ trễ sleep giữa mỗi tin nhắn, trước khi trả về stream
bộ thu. Kết quả là, timeout sẽ vô dụng. Sẽ không có độ trễ trong chính stream;
tất cả chúng sẽ xảy ra trước khi stream thậm chí có sẵn.
Thay vào đó, chúng ta để get_messages như một hàm thông thường trả về một
stream, và chúng ta spawn một task để xử lý các lệnh gọi sleep async.
Lưu ý: Gọi
spawn_tasktheo cách này hoạt động bởi vì chúng ta đã thiết lập runtime của mình; nếu không, nó sẽ gây ra hoảng loạn. Các cách thực hiện khác lựa chọn các sự đánh đổi khác nhau: chúng có thể spawn một runtime mới và tránh hoảng loạn nhưng cuối cùng có một chút chi phí bổ sung, hoặc chúng có thể đơn giản không cung cấp một cách độc lập để spawn các task mà không cần tham chiếu đến runtime. Hãy đảm bảo rằng bạn biết sự đánh đổi mà runtime của bạn đã chọn và viết mã của bạn tương ứng!
Bây giờ mã của chúng ta có một kết quả thú vị hơn nhiều. Giữa mỗi cặp tin nhắn
khác, một lỗi Problem: Elapsed(()).
Message: 'a'
Problem: Elapsed(())
Message: 'b'
Message: 'c'
Problem: Elapsed(())
Message: 'd'
Message: 'e'
Problem: Elapsed(())
Message: 'f'
Message: 'g'
Problem: Elapsed(())
Message: 'h'
Message: 'i'
Problem: Elapsed(())
Message: 'j'
Timeout không ngăn chặn các tin nhắn đến cuối cùng. Chúng ta vẫn nhận được tất cả các tin nhắn ban đầu, bởi vì kênh của chúng ta là unbounded: nó có thể chứa nhiều tin nhắn như chúng ta có thể vừa trong bộ nhớ. Nếu tin nhắn không đến trước khi timeout, bộ xử lý stream của chúng ta sẽ tính đến điều đó, nhưng khi nó poll stream một lần nữa, tin nhắn bây giờ có thể đã đến.
Bạn có thể nhận được hành vi khác nhau nếu cần bằng cách sử dụng các loại kênh khác hoặc các loại stream khác nói chung. Hãy xem một trong những điều đó trong thực tế bằng cách kết hợp một stream các khoảng thời gian với stream tin nhắn này.
Hợp nhất các Streams
Trước tiên, hãy tạo một stream khác, nó sẽ phát ra một mục mỗi mili giây nếu
chúng ta để nó chạy trực tiếp. Để đơn giản, chúng ta có thể sử dụng hàm sleep
để gửi một tin nhắn trên một độ trễ và kết hợp nó với cùng cách tiếp cận mà
chúng ta đã sử dụng trong get_messages của việc tạo một stream từ một kênh. Sự
khác biệt là lần này, chúng ta sẽ gửi lại số lượng khoảng thời gian đã trôi qua,
vì vậy kiểu trả về sẽ là impl Stream<Item = u32>, và chúng ta có thể gọi hàm
get_intervals (xem Listing 17-36).
// Note: Listing 17-36 code is not available in the listings folder
// This content may be from a different version of the bookChúng ta bắt đầu bằng việc định nghĩa một count trong task. (Chúng ta cũng có
thể định nghĩa nó bên ngoài task, nhưng rõ ràng hơn là giới hạn phạm vi của bất
kỳ biến nhất định nào.) Sau đó, chúng ta tạo một vòng lặp vô hạn. Mỗi lần lặp
của vòng lặp ngủ bất đồng bộ trong một mili giây, tăng số đếm, và sau đó gửi nó
qua kênh. Bởi vì tất cả điều này được bọc trong task được tạo bởi spawn_task,
tất cả nó—bao gồm cả vòng lặp vô hạn—sẽ được dọn dẹp cùng với runtime.
Loại vòng lặp vô hạn này, nó chỉ kết thúc khi toàn bộ runtime bị tháo dỡ, khá phổ biến trong Rust async: nhiều chương trình cần tiếp tục chạy vô thời hạn. Với async, điều này không chặn bất cứ thứ gì khác, miễn là có ít nhất một điểm await trong mỗi lần lặp qua vòng lặp.
Bây giờ, trở lại async block của hàm main của chúng ta, chúng ta có thể cố gắng
hợp nhất các stream messages và intervals, như trong Listing 17-37.
// Note: Listing 17-32 code is not available in the listings folder
// This content may be from a different version of the bookChúng ta bắt đầu bằng cách gọi get_intervals. Sau đó, chúng ta hợp nhất các
stream messages và intervals với phương thức merge, nó kết hợp nhiều
stream thành một stream mà tạo ra các mục từ bất kỳ stream nguồn nào ngay khi
các mục có sẵn, mà không áp đặt bất kỳ thứ tự cụ thể nào. Cuối cùng, chúng ta
lặp qua stream kết hợp đó thay vì qua messages.
Tại thời điểm này, không messages cũng không intervals cần được ghim hoặc có
thể thay đổi, bởi vì cả hai sẽ được kết hợp vào stream merged duy nhất. Tuy
nhiên, lệnh gọi merge này không biên dịch! (Lệnh gọi next trong vòng lặp
while let cũng không, nhưng chúng ta sẽ quay lại điều đó.) Đây là bởi vì hai
stream có các kiểu khác nhau. Stream messages có kiểu
Timeout<impl Stream<Item = String>>, trong đó Timeout là kiểu thực thi
Stream cho một lệnh gọi timeout. Stream intervals có kiểu
impl Stream<Item = u32>. Để hợp nhất hai stream này, chúng ta cần chuyển đổi
một trong chúng để khớp với stream kia. Chúng ta sẽ cải tạo stream intervals,
bởi vì messages đã ở định dạng cơ bản mà chúng ta muốn và phải xử lý các lỗi
timeout (xem Listing 17-38).
// Note: Listing 17-38 code is not available in the listings folder
// This content may be from a different version of the bookĐầu tiên, chúng ta có thể sử dụng phương thức trợ giúp map để chuyển đổi
intervals thành một chuỗi. Thứ hai, chúng ta cần phải khớp với Timeout từ
messages. Bởi vì chúng ta không thực sự muốn một timeout cho intervals,
tuy nhiên, chúng ta có thể chỉ tạo một timeout dài hơn các khoảng thời gian khác
mà chúng ta đang sử dụng. Ở đây, chúng ta tạo một timeout 10 giây với
Duration::from_secs(10). Cuối cùng, chúng ta cần làm cho stream có thể thay
đổi, để các lệnh gọi next của vòng lặp while let có thể lặp qua stream, và
ghim nó để an toàn khi làm như vậy. Điều đó đưa chúng ta gần đến nơi chúng ta
cần phải đến. Mọi thứ kiểm tra kiểu. Tuy nhiên, nếu bạn chạy điều này, sẽ có hai
vấn đề. Đầu tiên, nó sẽ không bao giờ dừng lại! Bạn sẽ cần dừng nó với
ctrl-c. Thứ hai, các tin nhắn từ bảng chữ cái
tiếng Anh sẽ bị chôn vùi giữa tất cả các tin nhắn bộ đếm khoảng thời gian:
--snip--
Interval: 38
Interval: 39
Interval: 40
Message: 'a'
Interval: 41
Interval: 42
Interval: 43
--snip--
Listing 17-39 hiển thị một cách để giải quyết hai vấn đề cuối cùng này.
// Note: Listing 17-39 code is not available in the listings folder
// This content may be from a different version of the bookĐầu tiên, chúng ta sử dụng phương thức throttle trên stream intervals để nó
không áp đảo stream messages. Throttling là một cách để giới hạn tốc độ mà
một hàm sẽ được gọi—hoặc, trong trường hợp này, bao lâu một lần stream sẽ được
poll. Mỗi 100 mili giây sẽ đủ, bởi vì đó là khoảng thời gian tin nhắn của chúng
ta đến.
Để giới hạn số lượng mục mà chúng ta sẽ chấp nhận từ một stream, chúng ta áp
dụng phương thức take cho stream merged, bởi vì chúng ta muốn giới hạn đầu
ra cuối cùng, không chỉ một stream này hoặc stream kia.
Bây giờ khi chúng ta chạy chương trình, nó dừng lại sau khi kéo 20 mục từ
stream, và các khoảng thời gian không áp đảo các tin nhắn. Chúng ta cũng không
nhận được Interval: 100 hoặc Interval: 200 hoặc vân vân, mà thay vào đó nhận
được Interval: 1, Interval: 2, và v.v.—mặc dù chúng ta có một stream nguồn
có thể tạo ra một sự kiện mỗi mili giây. Đó là bởi vì lệnh gọi throttle tạo
ra một stream mới bao bọc stream ban đầu để stream ban đầu chỉ được poll ở tốc
độ throttle, không phải tốc độ "tự nhiên" của nó. Chúng ta không có một đống tin
nhắn khoảng thời gian không xử lý mà chúng ta đang chọn bỏ qua. Thay vào đó,
chúng ta không bao giờ tạo ra những tin nhắn khoảng thời gian đó ngay từ đầu!
Đây là tính "lười biếng" vốn có của các future của Rust làm việc một lần nữa,
cho phép chúng ta chọn các đặc điểm hiệu suất của mình.
Interval: 1
Message: 'a'
Interval: 2
Interval: 3
Problem: Elapsed(())
Interval: 4
Message: 'b'
Interval: 5
Message: 'c'
Interval: 6
Interval: 7
Problem: Elapsed(())
Interval: 8
Message: 'd'
Interval: 9
Message: 'e'
Interval: 10
Interval: 11
Problem: Elapsed(())
Interval: 12
Có một điều cuối cùng chúng ta cần xử lý: lỗi! Với cả hai stream dựa trên kênh
này, các lệnh gọi send có thể thất bại khi phía bên kia của kênh đóng—và đó
chỉ là một vấn đề về cách runtime thực thi các future tạo nên stream. Cho đến
bây giờ, chúng ta đã bỏ qua khả năng này bằng cách gọi unwrap, nhưng trong một
ứng dụng hoạt động tốt, chúng ta nên xử lý lỗi một cách rõ ràng, tối thiểu là
bằng cách kết thúc vòng lặp để chúng ta không cố gắng gửi thêm tin nhắn. Listing
17-40 hiển thị một chiến lược lỗi đơn giản: in vấn đề và sau đó break khỏi các
vòng lặp.
// Note: Listing 17-40 code is not available in the listings folder
// This content may be from a different version of the bookNhư thường lệ, cách đúng để xử lý lỗi gửi tin nhắn sẽ thay đổi; chỉ cần đảm bảo bạn có một chiến lược.
Bây giờ sau khi chúng ta đã thấy rất nhiều async trong thực tế, hãy lui lại một
bước và đào sâu vào một vài chi tiết về cách Future, Stream, và các trait
quan trọng khác mà Rust sử dụng để làm cho async hoạt động.
Xem xét kỹ hơn về các Trait cho Async
Trong suốt chương này, chúng ta đã sử dụng các trait Future, Pin, Unpin,
Stream, và StreamExt theo nhiều cách khác nhau. Tuy nhiên, cho đến nay,
chúng ta đã tránh đi quá sâu vào chi tiết về cách chúng hoạt động hoặc cách
chúng kết hợp với nhau, điều này phù hợp với công việc Rust hàng ngày của bạn
trong hầu hết thời gian. Tuy nhiên, đôi khi, bạn sẽ gặp phải những tình huống mà
bạn cần hiểu thêm một vài chi tiết này. Trong phần này, chúng ta sẽ đào sâu đủ
để giúp đỡ trong những kịch bản đó, vẫn để lại việc đào sâu thực sự cho các
tài liệu khác.
Trait Future
Hãy bắt đầu bằng cách xem xét kỹ hơn cách trait Future hoạt động. Đây là cách
Rust định nghĩa nó:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
Định nghĩa trait đó bao gồm một loạt các kiểu mới và cũng có một số cú pháp mà chúng ta chưa thấy trước đây, vì vậy hãy đi qua định nghĩa từng phần một.
Đầu tiên, kiểu kết hợp Output của Future nói lên những gì future giải quyết.
Điều này tương tự như kiểu kết hợp Item của trait Iterator. Thứ hai,
Future cũng có phương thức poll, phương thức này lấy một tham chiếu Pin
đặc biệt cho tham số self và một tham chiếu có thể thay đổi đến kiểu
Context, và trả về một Poll<Self::Output>. Chúng ta sẽ nói thêm về Pin và
Context trong một lát. Hiện tại, hãy tập trung vào những gì phương thức trả
về, kiểu Poll:
#![allow(unused)] fn main() { enum Poll<T> { Ready(T), Pending, } }
Kiểu Poll này tương tự như một Option. Nó có một biến thể có giá trị,
Ready(T), và một biến thể không có, Pending. Tuy nhiên, Poll có ý nghĩa
khá khác với Option! Biến thể Pending chỉ ra rằng future vẫn còn việc phải
làm, vì vậy người gọi sẽ cần kiểm tra lại sau. Biến thể Ready chỉ ra rằng
future đã hoàn thành công việc của nó và giá trị T đã có sẵn.
Lưu ý: Với hầu hết các future, người gọi không nên gọi
polllại sau khi future đã trả vềReady. Nhiều future sẽ panic nếu bị poll lại sau khi đã sẵn sàng. Các future an toàn để poll lại sẽ nêu rõ điều đó trong tài liệu của chúng. Điều này tương tự như cáchIterator::nexthoạt động.
Khi bạn thấy mã sử dụng await, Rust biên dịch nó bên dưới thành mã gọi poll.
Nếu bạn nhìn lại Listing 17-4, nơi chúng ta in tiêu đề trang cho một URL duy
nhất sau khi nó được giải quyết, Rust biên dịch nó thành thứ gì đó kiểu như (mặc
dù không chính xác) như thế này:
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// But what goes here?
}
}Chúng ta nên làm gì khi future vẫn còn Pending? Chúng ta cần một cách nào đó
để thử lại, và lại, và lại, cho đến khi future cuối cùng sẵn sàng. Nói cách
khác, chúng ta cần một vòng lặp:
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// continue
}
}
}Tuy nhiên, nếu Rust biên dịch nó thành chính xác mã đó, thì mỗi await sẽ
chặn—chính xác là điều ngược lại với những gì chúng ta đang hướng đến! Thay vào
đó, Rust đảm bảo rằng vòng lặp có thể chuyển quyền kiểm soát cho thứ gì đó có
thể tạm dừng công việc trên future này để làm việc trên các future khác và sau
đó kiểm tra lại future này sau. Như chúng ta đã thấy, thứ đó là một runtime
async, và công việc lập lịch và phối hợp này là một trong những nhiệm vụ chính
của nó.
Trước đó trong chương này, chúng ta đã mô tả việc chờ đợi rx.recv. Lệnh gọi
recv trả về một future, và việc await future sẽ poll nó. Chúng ta đã lưu ý
rằng runtime sẽ tạm dừng future cho đến khi nó sẵn sàng với Some(message) hoặc
None khi kênh đóng. Với sự hiểu biết sâu sắc hơn về trait Future, và cụ thể
là Future::poll, chúng ta có thể thấy cách nó hoạt động. Runtime biết future
chưa sẵn sàng khi nó trả về Poll::Pending. Ngược lại, runtime biết future đã
sẵn sàng và tiến nó khi poll trả về Poll::Ready(Some(message)) hoặc
Poll::Ready(None).
Chi tiết chính xác về cách runtime thực hiện điều đó nằm ngoài phạm vi của cuốn sách này, nhưng chìa khóa là thấy được cơ chế cơ bản của futures: một runtime polls mỗi future mà nó chịu trách nhiệm, đưa future trở lại trạng thái ngủ khi nó chưa sẵn sàng.
Các Trait Pin và Unpin
Khi chúng ta giới thiệu ý tưởng về pinning trong Listing 17-16, chúng ta đã gặp phải một thông báo lỗi rất khó hiểu. Đây là phần liên quan của nó một lần nữa:
error[E0277]: `{async block@src/main.rs:10:23: 10:33}` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `{async block@src/main.rs:10:23: 10:33}`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<{async block@src/main.rs:10:23: 10:33}>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
Thông báo lỗi này cho chúng ta biết không chỉ rằng chúng ta cần ghim các giá trị
mà còn cả lý do tại sao pinning là bắt buộc. Hàm trpl::join_all trả về một
struct có tên JoinAll. Struct đó là generic trên một kiểu F, bị ràng buộc để
thực thi trait Future. Await trực tiếp một future với await ghim future một
cách ngầm định. Đó là lý do tại sao chúng ta không cần sử dụng pin! ở mọi nơi
chúng ta muốn await futures.
Tuy nhiên, chúng ta không await trực tiếp một future ở đây. Thay vào đó, chúng
ta xây dựng một future mới, JoinAll, bằng cách truyền một bộ sưu tập các
future vào hàm join_all. Chữ ký cho join_all yêu cầu rằng các kiểu của các
mục trong bộ sưu tập đều thực thi trait Future, và Box<T> thực thi Future
chỉ khi T mà nó bọc là một future thực thi trait Unpin.
Đó là rất nhiều để hấp thụ! Để thực sự hiểu nó, hãy đi sâu hơn một chút vào cách
trait Future thực sự hoạt động, đặc biệt là xung quanh pinning.
Nhìn lại định nghĩa của trait Future:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; // Required method fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
Tham số cx và kiểu Context của nó là chìa khóa để một runtime thực sự biết
khi nào kiểm tra bất kỳ future nào mà vẫn lười biếng. Một lần nữa, chi tiết về
cách điều đó hoạt động nằm ngoài phạm vi của chương này, và bạn thường chỉ cần
suy nghĩ về điều này khi viết một cách triển khai Future tùy chỉnh. Chúng ta
sẽ tập trung thay vào đó vào kiểu cho self, vì đây là lần đầu tiên chúng ta
thấy một phương thức trong đó self có một chú thích kiểu. Một chú thích kiểu
cho self hoạt động như chú thích kiểu cho các tham số hàm khác, nhưng với hai
khác biệt chính:
-
Nó cho Rust biết
selfphải là kiểu gì để phương thức được gọi. -
Nó không thể là bất kỳ kiểu nào. Nó bị giới hạn trong kiểu mà phương thức được triển khai, một tham chiếu hoặc con trỏ thông minh đến kiểu đó, hoặc một
Pinbao bọc một tham chiếu đến kiểu đó.
Chúng ta sẽ thấy thêm về cú pháp này trong Chương 18.
Hiện tại, điều đủ để biết là nếu chúng ta muốn poll một future để kiểm tra xem
nó là Pending hay Ready(Output), chúng ta cần một tham chiếu có thể thay đổi
được bọc trong Pin đến kiểu.
Pin là một wrapper cho các kiểu giống con trỏ như &, &mut, Box, và Rc.
(Về mặt kỹ thuật, Pin hoạt động với các kiểu triển khai các trait Deref hoặc
DerefMut, nhưng điều này hiệu quả tương đương với việc chỉ làm việc với các
con trỏ.) Pin không phải là một con trỏ và không có bất kỳ hành vi nào của
riêng nó như Rc và Arc với việc đếm tham chiếu; nó thuần túy là một công cụ
mà trình biên dịch có thể sử dụng để áp đặt các ràng buộc về việc sử dụng con
trỏ.
Nhớ lại rằng await được triển khai dưới dạng các lệnh gọi đến poll bắt đầu
giải thích thông báo lỗi chúng ta đã thấy trước đó, nhưng điều đó là về Unpin,
không phải Pin. Vậy chính xác thì Pin liên quan đến Unpin như thế nào, và
tại sao Future cần self là một kiểu Pin để gọi poll?
Hãy nhớ từ trước đó trong chương này, một chuỗi các điểm await trong một future được biên dịch thành một máy trạng thái, và trình biên dịch đảm bảo rằng máy trạng thái đó tuân theo tất cả các quy tắc thông thường của Rust xung quanh sự an toàn, bao gồm cả việc mượn và sở hữu. Để làm cho điều đó hoạt động, Rust xem xét dữ liệu nào là cần thiết giữa một điểm await và điểm await tiếp theo hoặc cuối của async block. Nó sau đó tạo ra một biến thể tương ứng trong máy trạng thái được biên dịch. Mỗi biến thể nhận quyền truy cập mà nó cần đến dữ liệu sẽ được sử dụng trong phần đó của mã nguồn, dù là bằng cách lấy quyền sở hữu dữ liệu đó hoặc bằng cách nhận một tham chiếu có thể thay đổi hoặc không thể thay đổi đến nó.
Cho đến nay, vẫn tốt: nếu chúng ta làm bất cứ điều gì sai về quyền sở hữu hoặc
tham chiếu trong một async block nhất định, trình kiểm tra mượn sẽ cho chúng ta
biết. Khi chúng ta muốn di chuyển future tương ứng với block đó—như đưa nó vào
một Vec để truyền vào join_all—mọi thứ trở nên khó khăn hơn.
Khi chúng ta di chuyển một future—dù là bằng cách đẩy nó vào một cấu trúc dữ
liệu để sử dụng như một iterator với join_all hoặc bằng cách trả về nó từ một
hàm—điều đó thực sự có nghĩa là di chuyển máy trạng thái Rust tạo ra cho chúng
ta. Và không giống như hầu hết các kiểu khác trong Rust, các future mà Rust tạo
ra cho các async block có thể kết thúc với các tham chiếu đến chính nó trong các
trường của bất kỳ biến thể nhất định nào, như được minh họa đơn giản trong Hình
17-4.

Tuy nhiên, theo mặc định, bất kỳ đối tượng nào có tham chiếu đến chính nó đều không an toàn để di chuyển, bởi vì các tham chiếu luôn trỏ đến địa chỉ bộ nhớ thực tế của bất cứ thứ gì chúng tham chiếu đến (xem Hình 17-5). Nếu bạn di chuyển chính cấu trúc dữ liệu, những tham chiếu nội bộ đó sẽ bị để lại trỏ đến vị trí cũ. Tuy nhiên, vị trí bộ nhớ đó giờ đây không hợp lệ. Một mặt, giá trị của nó sẽ không được cập nhật khi bạn thay đổi cấu trúc dữ liệu. Mặt khác—điều quan trọng hơn—là máy tính hiện có thể tự do sử dụng lại bộ nhớ đó cho các mục đích khác! Bạn có thể kết thúc bằng việc đọc dữ liệu hoàn toàn không liên quan sau này.

Về mặt lý thuyết, trình biên dịch Rust có thể cố gắng cập nhật mọi tham chiếu đến một đối tượng bất cứ khi nào nó bị di chuyển, nhưng điều đó có thể thêm rất nhiều chi phí hiệu suất, đặc biệt nếu toàn bộ mạng lưới các tham chiếu cần cập nhật. Nếu thay vào đó chúng ta có thể đảm bảo rằng cấu trúc dữ liệu đang được đề cập không di chuyển trong bộ nhớ, chúng ta sẽ không phải cập nhật bất kỳ tham chiếu nào. Đây chính xác là những gì trình kiểm tra mượn của Rust yêu cầu: trong mã an toàn, nó ngăn bạn di chuyển bất kỳ mục nào có tham chiếu đang hoạt động đến nó.
Pin xây dựng trên điều đó để cung cấp cho chúng ta chính xác sự đảm bảo mà
chúng ta cần. Khi chúng ta ghim một giá trị bằng cách bọc một con trỏ đến giá
trị đó trong Pin, nó không còn có thể di chuyển. Do đó, nếu bạn có
Pin<Box<SomeType>>, bạn thực sự ghim giá trị SomeType, không phải con trỏ
Box. Hình 17-6 minh họa quá trình này.
<img alt="Three boxes laid out side by side. The first is labeled "Pin", the second "b1", and the third "pinned". Within "pinned" is a table labeled "fut", with a single column; it represents a future with cells for each part of the data structure. Its first cell has the value "0", its second cell has an arrow coming out of it and pointing to the fourth and final cell, which has the value "1" in it, and the third cell has dashed lines and an ellipsis to indicate there may be other parts to the data structure. All together, the "fut" table represents a future which is self-referential. An arrow leaves the box labeled "Pin", goes through the box labeled "b1" and has terminates inside the "pinned" box at the "fut" table." src="img/trpl17-06.svg" class="center" />
Trên thực tế, con trỏ Box vẫn có thể di chuyển tự do. Hãy nhớ: chúng ta quan
tâm đến việc đảm bảo rằng dữ liệu cuối cùng được tham chiếu ở yên vị trí của nó.
Nếu một con trỏ di chuyển xung quanh, nhưng dữ liệu mà nó trỏ đến ở cùng một vị
trí, như trong Hình 17-7, không có vấn đề tiềm ẩn nào. Như một bài tập độc lập,
hãy xem tài liệu cho các kiểu cũng như module std::pin và cố gắng tìm ra cách
bạn sẽ làm điều này với một Pin bao bọc một Box.) Điều quan trọng là kiểu tự
tham chiếu không thể di chuyển, bởi vì nó vẫn được ghim.
<img alt="Four boxes laid out in three rough columns, identical to the previous diagram with a change to the second column. Now there are two boxes in the second column, labeled "b1" and "b2", "b1" is grayed out, and the arrow from "Pin" goes through "b2" instead of "b1", indicating that the pointer has moved from "b1" to "b2", but the data in "pinned" has not moved." src="img/trpl17-07.svg" class="center" />
Tuy nhiên, hầu hết các kiểu đều hoàn toàn an toàn để di chuyển, ngay cả khi
chúng tình cờ đứng sau một wrapper Pin. Chúng ta chỉ cần nghĩ về việc ghim khi
các mục có tham chiếu nội bộ. Các giá trị nguyên thủy như số và Boolean là an
toàn bởi vì chúng rõ ràng không có bất kỳ tham chiếu nội bộ nào. Hầu hết các
kiểu mà bạn thường làm việc trong Rust cũng vậy. Bạn có thể di chuyển một Vec,
ví dụ, mà không cần lo lắng. Với những gì chúng ta đã thấy cho đến nay, nếu bạn
có một Pin<Vec<String>>, bạn sẽ phải làm mọi thứ thông qua các API an toàn
nhưng hạn chế được cung cấp bởi Pin, mặc dù một Vec<String> luôn an toàn để
di chuyển nếu không có tham chiếu nào khác đến nó. Chúng ta cần một cách để nói
với trình biên dịch rằng việc di chuyển các mục xung quanh trong những trường
hợp như thế này là tốt—và đó là nơi Unpin đi vào cuộc chơi.
Unpin là một trait đánh dấu, tương tự như các trait Send và Sync mà chúng
ta đã thấy trong Chương 16, và do đó không có chức năng của riêng nó. Các trait
đánh dấu tồn tại chỉ để nói với trình biên dịch rằng việc sử dụng kiểu thực thi
một trait nhất định trong một ngữ cảnh cụ thể là an toàn. Unpin thông báo cho
trình biên dịch rằng một kiểu nhất định không cần duy trì bất kỳ đảm bảo nào
về việc liệu giá trị đang được đề cập có thể được di chuyển an toàn.
Giống như với Send và Sync, trình biên dịch triển khai Unpin tự động cho
tất cả các kiểu mà nó có thể chứng minh là an toàn. Một trường hợp đặc biệt, một
lần nữa tương tự như Send và Sync, là nơi Unpin không được triển khai
cho một kiểu. Ký hiệu cho điều này là impl !Unpin for
SomeType, trong đó SomeType là tên của một
kiểu thực sự cần duy trì những đảm bảo đó để an toàn bất cứ khi nào một con
trỏ đến kiểu đó được sử dụng trong một Pin.
Nói cách khác, có hai điều cần ghi nhớ về mối quan hệ giữa Pin và Unpin. Đầu
tiên, Unpin là trường hợp "bình thường", và !Unpin là trường hợp đặc biệt.
Thứ hai, liệu một kiểu triển khai Unpin hay !Unpin chỉ quan trọng khi bạn
đang sử dụng một con trỏ được ghim cho kiểu đó như Pin<&mut
SomeType>.
Để làm cho điều đó cụ thể, hãy nghĩ về một String: nó có một độ dài và các ký
tự Unicode tạo nên nó. Chúng ta có thể bọc một String trong Pin, như trong
Hình 17-8. Tuy nhiên, String tự động triển khai Unpin, cũng như hầu hết các
kiểu khác trong Rust.

Do đó, chúng ta có thể làm những điều mà sẽ bất hợp pháp nếu String triển khai
!Unpin thay thế, chẳng hạn như thay thế một chuỗi bằng một chuỗi khác tại
chính xác cùng một vị trí trong bộ nhớ như trong Hình 17-9. Điều này không vi
phạm hợp đồng Pin, bởi vì String không có tham chiếu nội bộ làm cho nó không
an toàn để di chuyển! Đó chính xác là lý do tại sao nó triển khai Unpin chứ
không phải !Unpin.

Bây giờ chúng ta biết đủ để hiểu các lỗi được báo cáo cho lệnh gọi join_all từ
Listing 17-17. Ban đầu, chúng ta đã cố gắng di chuyển các future được tạo ra bởi
các async block vào một Vec<Box<dyn Future<Output = ()>>>, nhưng như chúng ta
đã thấy, những future đó có thể có tham chiếu nội bộ, vì vậy chúng không triển
khai Unpin. Chúng cần được ghim, và sau đó chúng ta có thể truyền kiểu Pin
vào Vec, tự tin rằng dữ liệu cơ bản trong các future sẽ không bị di chuyển.
Pin và Unpin chủ yếu quan trọng cho việc xây dựng các thư viện cấp thấp hơn,
hoặc khi bạn đang xây dựng chính một runtime, hơn là cho mã Rust hàng ngày. Tuy
nhiên, khi bạn thấy các trait này trong thông báo lỗi, bây giờ bạn sẽ có một
hiểu biết tốt hơn về cách sửa mã của mình!
Lưu ý: Sự kết hợp này của
PinvàUnpinlàm cho nó có thể triển khai an toàn toàn bộ một lớp các kiểu phức tạp trong Rust mà nếu không sẽ chứng minh đầy thách thức bởi vì chúng tự tham chiếu. Các kiểu yêu cầuPinxuất hiện phổ biến nhất trong async Rust ngày nay, nhưng thỉnh thoảng, bạn có thể thấy chúng trong các ngữ cảnh khác.Các chi tiết cụ thể về cách
PinvàUnpinhoạt động, và các quy tắc mà chúng được yêu cầu để tuân thủ, được đề cập rộng rãi trong tài liệu API chostd::pin, vì vậy nếu bạn quan tâm đến việc tìm hiểu thêm, đó là một nơi tuyệt vời để bắt đầu.Nếu bạn muốn hiểu cách mọi thứ hoạt động bên dưới nắp capo một cách chi tiết hơn, hãy xem Chương 2 và 4 của Asynchronous Programming in Rust.
Trait Stream
Bây giờ bạn đã có một hiểu biết sâu sắc hơn về các trait Future, Pin, và
Unpin, chúng ta có thể chuyển sự chú ý của mình đến trait Stream. Như bạn đã
học được trước đó trong chương, streams tương tự như các iterator bất đồng bộ.
Không giống như Iterator và Future, tuy nhiên, Stream không có định nghĩa
trong thư viện chuẩn vào thời điểm viết bài này, nhưng có một định nghĩa rất
phổ biến từ crate futures được sử dụng trong toàn bộ hệ sinh thái.
Hãy xem lại các định nghĩa của các trait Iterator và Future trước khi xem
xét cách một trait Stream có thể hợp nhất chúng lại với nhau. Từ Iterator,
chúng ta có ý tưởng về một chuỗi: phương thức next của nó cung cấp một
Option<Self::Item>. Từ Future, chúng ta có ý tưởng về sự sẵn sàng theo thời
gian: phương thức poll của nó cung cấp một Poll<Self::Output>. Để đại diện
cho một chuỗi các mục trở nên sẵn sàng theo thời gian, chúng ta định nghĩa một
trait Stream kết hợp các tính năng đó:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; } }
Trait Stream định nghĩa một kiểu kết hợp được gọi là Item cho kiểu của các
mục được tạo ra bởi stream. Điều này tương tự như Iterator, nơi có thể có từ
không đến nhiều mục, và không giống như Future, nơi luôn có một Output duy
nhất, ngay cả khi đó là kiểu đơn vị ().
Stream cũng định nghĩa một phương thức để lấy các mục đó. Chúng ta gọi nó là
poll_next, để làm rõ rằng nó poll theo cùng cách Future::poll làm và tạo ra
một chuỗi các mục theo cùng cách Iterator::next làm. Kiểu trả về của nó kết
hợp Poll với Option. Kiểu bên ngoài là Poll, bởi vì nó phải được kiểm tra
sự sẵn sàng, giống như một future. Kiểu bên trong là Option, bởi vì nó cần
phải báo hiệu liệu có còn tin nhắn nữa hay không, giống như một iterator làm.
Một thứ gì đó rất giống với định nghĩa này sẽ có khả năng trở thành một phần của thư viện chuẩn của Rust. Trong khi đó, nó là một phần của bộ công cụ của hầu hết các runtime, vì vậy bạn có thể dựa vào nó, và mọi thứ chúng ta đề cập tiếp theo nhìn chung sẽ áp dụng!
Trong ví dụ chúng ta đã thấy trong phần về streaming, tuy nhiên, chúng ta đã
không sử dụng poll_next hoặc Stream, mà thay vào đó đã sử dụng next và
StreamExt. Chúng ta có thể làm việc trực tiếp với API poll_next bằng cách
tự viết các máy trạng thái Stream của chúng ta, tất nhiên, giống như chúng ta
có thể làm việc với futures trực tiếp thông qua phương thức poll của chúng.
Tuy nhiên, sử dụng await tốt hơn nhiều, và trait StreamExt cung cấp phương
thức next để chúng ta có thể làm điều đó:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Option<Self::Item>>; } trait StreamExt: Stream { async fn next(&mut self) -> Option<Self::Item> where Self: Unpin; // other methods... } }
Lưu ý: Định nghĩa thực tế mà chúng ta đã sử dụng trước đó trong chương trông hơi khác với điều này, bởi vì nó hỗ trợ các phiên bản của Rust chưa hỗ trợ việc sử dụng các hàm async trong traits. Kết quả là, nó trông như thế này:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Kiểu
Nextđó là mộtstructtriển khaiFuturevà cho phép chúng ta đặt tên cho lifetime của tham chiếu đếnselfvớiNext<'_, Self>, đểawaitcó thể làm việc với phương thức này.
Trait StreamExt cũng là nơi ở của tất cả các phương thức thú vị có sẵn để sử
dụng với streams. StreamExt được triển khai tự động cho mọi kiểu triển khai
Stream, nhưng các trait này được định nghĩa riêng biệt để cho phép cộng đồng
lặp lại trên các API tiện lợi mà không ảnh hưởng đến trait nền tảng.
Trong phiên bản của StreamExt được sử dụng trong crate trpl, trait không chỉ
định nghĩa phương thức next mà còn cung cấp một triển khai mặc định của next
xử lý đúng các chi tiết của việc gọi Stream::poll_next. Điều này có nghĩa là
ngay cả khi bạn cần viết kiểu dữ liệu streaming của riêng mình, bạn chỉ phải
triển khai Stream, và sau đó bất kỳ ai sử dụng kiểu dữ liệu của bạn có thể sử
dụng StreamExt và các phương thức của nó với nó một cách tự động.
Đó là tất cả những gì chúng ta sắp đề cập cho các chi tiết cấp thấp hơn về các trait này. Để kết thúc, hãy xem xét cách các futures (bao gồm streams), tasks, và threads đều phù hợp với nhau!
Tổng hợp tất cả: Futures, Tasks, và Threads
Như chúng ta đã thấy trong Chương 16, threads cung cấp một cách tiếp cận để thực hiện đồng thời. Chúng ta đã thấy một cách tiếp cận khác trong chương này: sử dụng async với futures và streams. Nếu bạn đang tự hỏi khi nào nên chọn phương pháp này thay vì phương pháp kia, câu trả lời là: tùy trường hợp! Và trong nhiều trường hợp, sự lựa chọn không phải là threads hoặc async mà là threads và async.
Nhiều hệ điều hành đã cung cấp các mô hình đồng thời dựa trên threading trong hàng thập kỷ qua, và nhiều ngôn ngữ lập trình hỗ trợ chúng do đó. Tuy nhiên, các mô hình này không phải không có những đánh đổi. Trên nhiều hệ điều hành, chúng sử dụng một lượng khá lớn bộ nhớ cho mỗi thread, và chúng đi kèm với một số chi phí cho việc khởi động và tắt. Thread cũng chỉ là một lựa chọn khi hệ điều hành và phần cứng của bạn hỗ trợ chúng. Không giống như máy tính để bàn và di động phổ biến, một số hệ thống nhúng hoàn toàn không có hệ điều hành, vì vậy chúng cũng không có threads.
Mô hình async cung cấp một tập hợp các đánh đổi khác—và cuối cùng là bổ sung.
Trong mô hình async, các hoạt động đồng thời không yêu cầu thread riêng của
chúng. Thay vào đó, chúng có thể chạy trên các task, như khi chúng ta sử dụng
trpl::spawn_task để khởi động công việc từ một hàm đồng bộ trong phần streams.
Một task tương tự như một thread, nhưng thay vì được quản lý bởi hệ điều hành,
nó được quản lý bởi mã cấp thư viện: runtime.
Trong phần trước, chúng ta đã thấy rằng chúng ta có thể xây dựng một stream bằng
cách sử dụng kênh async và tạo ra một task async mà chúng ta có thể gọi từ mã
đồng bộ. Chúng ta có thể làm điều tương tự với một thread. Trong Listing 17-40,
chúng ta đã sử dụng trpl::spawn_task và trpl::sleep. Trong Listing 17-41,
chúng ta thay thế chúng bằng các API thread::spawn và thread::sleep từ thư
viện chuẩn trong hàm get_intervals.
// Note: Listing 17-41 code is not available in the listings folder
// This content may be from a different version of the book
// Consider using listing-17-25 as referenceNếu bạn chạy mã này, đầu ra giống hệt với của Listing 17-40. Và chú ý có rất ít thay đổi ở đây từ góc độ của mã gọi. Hơn nữa, mặc dù một trong các hàm của chúng ta tạo ra một task async trên runtime và hàm kia tạo ra một thread của hệ điều hành, các stream kết quả không bị ảnh hưởng bởi sự khác biệt.
Mặc dù có những điểm tương đồng, hai cách tiếp cận này hoạt động rất khác nhau, mặc dù chúng ta có thể khó đo lường được điều đó trong ví dụ rất đơn giản này. Chúng ta có thể tạo ra hàng triệu task async trên bất kỳ máy tính cá nhân hiện đại nào. Nếu chúng ta cố gắng làm điều đó với threads, chúng ta sẽ thực sự hết bộ nhớ!
Tuy nhiên, có lý do khiến các API này rất giống nhau. Threads hoạt động như một ranh giới cho các tập hợp các hoạt động đồng bộ; tính đồng thời là có thể giữa các thread. Tasks hoạt động như một ranh giới cho các tập hợp hoạt động bất đồng bộ; tính đồng thời là có thể cả giữa và trong các task, bởi vì một task có thể chuyển đổi giữa các future trong phần thân của nó. Cuối cùng, future là đơn vị đồng thời nhỏ nhất của Rust, và mỗi future có thể đại diện cho một cây các future khác. Runtime—cụ thể là trình thực thi của nó—quản lý tasks, và tasks quản lý futures. Theo nghĩa đó, tasks tương tự như các thread nhẹ, được quản lý bởi runtime với các khả năng bổ sung đến từ việc được quản lý bởi runtime thay vì bởi hệ điều hành.
Điều này không có nghĩa là task async luôn tốt hơn threads (hoặc ngược lại).
Tính đồng thời với threads theo một số cách là một mô hình lập trình đơn giản
hơn tính đồng thời với async. Điều đó có thể là một điểm mạnh hoặc một điểm
yếu. Threads hơi "phóng và quên"; chúng không có tương đương tự nhiên với
future, vì vậy chúng chỉ đơn giản chạy đến khi hoàn thành mà không bị gián đoạn
ngoại trừ bởi chính hệ điều hành. Tức là, chúng không có hỗ trợ tích hợp cho
tính đồng thời nội tác vụ như cách futures có. Threads trong Rust cũng không
có cơ chế cho việc hủy bỏ—một chủ đề chúng ta chưa đề cập rõ ràng trong chương
này nhưng đã được ngụ ý bởi thực tế rằng bất cứ khi nào chúng ta kết thúc một
future, trạng thái của nó được dọn dẹp một cách chính xác.
Những hạn chế này cũng khiến threads khó kết hợp hơn futures. Ví dụ, khó khăn
hơn nhiều để sử dụng threads để xây dựng các trợ giúp như các phương thức
timeout và throttle mà chúng ta đã xây dựng trước đó trong chương này. Việc
futures là các cấu trúc dữ liệu phong phú hơn có nghĩa là chúng có thể được kết
hợp với nhau một cách tự nhiên hơn, như chúng ta đã thấy.
Vậy tasks cho chúng ta kiểm soát bổ sung đối với futures, cho phép chúng ta
chọn nơi và cách nhóm chúng. Và hóa ra threads và tasks thường hoạt động rất tốt
cùng nhau, bởi vì tasks có thể (ít nhất là trong một số runtime) được di chuyển
quanh giữa các thread. Thực tế, bên dưới, runtime mà chúng ta đã sử dụng—bao gồm
các hàm spawn_blocking và spawn_task—là đa luồng theo mặc định! Nhiều
runtime sử dụng một cách tiếp cận được gọi là đánh cắp công việc để di chuyển
các task một cách trong suốt giữa các thread, dựa trên cách các thread hiện đang
được sử dụng, để cải thiện hiệu suất tổng thể của hệ thống. Cách tiếp cận đó
thực sự yêu cầu cả threads và tasks, và do đó là futures.
Khi suy nghĩ về phương pháp nào để sử dụng khi nào, hãy xem xét những quy tắc chung sau:
- Nếu công việc rất có thể song song hóa, chẳng hạn như xử lý một lượng lớn dữ liệu mà mỗi phần có thể được xử lý riêng biệt, threads là lựa chọn tốt hơn.
- Nếu công việc rất đồng thời, chẳng hạn như xử lý tin nhắn từ một loạt nguồn khác nhau có thể đến theo các khoảng thời gian hoặc tốc độ khác nhau, async là lựa chọn tốt hơn.
Và nếu bạn cần cả tính song song và tính đồng thời, bạn không phải chọn giữa threads và async. Bạn có thể sử dụng chúng cùng nhau tự do, để mỗi cái đóng vai trò mà nó làm tốt nhất. Ví dụ, Listing 17-42 hiển thị một ví dụ khá phổ biến về loại kết hợp này trong mã Rust thực tế.
// Note: Listing 17-42 code is not available in the listings folder
// This content may be from a different version of the bookChúng ta bắt đầu bằng cách tạo một kênh async, sau đó tạo ra một thread lấy
quyền sở hữu của phía gửi của kênh. Trong thread, chúng ta gửi các số từ 1 đến
10, ngủ một giây giữa mỗi số. Cuối cùng, chúng ta chạy một future được tạo với
một async block được truyền vào trpl::run giống như chúng ta đã làm trong suốt
chương. Trong future đó, chúng ta đợi những tin nhắn đó, giống như trong các ví
dụ truyền tin nhắn khác mà chúng ta đã thấy.
Quay trở lại kịch bản chúng ta đã mở đầu chương, hãy tưởng tượng chạy một tập hợp các tác vụ mã hóa video sử dụng một thread chuyên dụng (bởi vì mã hóa video là tính toán nặng) nhưng thông báo cho UI rằng các hoạt động đó đã hoàn thành với một kênh async. Có vô số ví dụ về các loại kết hợp này trong các trường hợp sử dụng thực tế.
Tóm tắt
Đây không phải là lần cuối bạn sẽ thấy tính đồng thời trong cuốn sách này. Dự án trong Chương 21 sẽ áp dụng các khái niệm này trong một tình huống thực tế hơn so với các ví dụ đơn giản hơn đã thảo luận ở đây và so sánh việc giải quyết vấn đề với threading đối với tasks một cách trực tiếp hơn.
Bất kể bạn chọn cách tiếp cận nào trong số này, Rust cung cấp cho bạn các công cụ bạn cần để viết mã đồng thời an toàn, nhanh chóng— cho dù là cho một máy chủ web thông lượng cao hay một hệ điều hành nhúng.
Tiếp theo, chúng ta sẽ nói về các cách thành ngữ để mô hình hóa vấn đề và cấu trúc giải pháp khi các chương trình Rust của bạn trở nên lớn hơn. Ngoài ra, chúng ta sẽ thảo luận cách các thành ngữ của Rust liên quan đến những thành ngữ mà bạn có thể quen thuộc từ lập trình hướng đối tượng.
Các Tính Năng Lập Trình Hướng Đối Tượng
Lập trình hướng đối tượng (OOP) là một cách mô hình hóa chương trình. Đối tượng như một khái niệm lập trình được giới thiệu trong ngôn ngữ lập trình Simula vào những năm 1960. Những đối tượng đó đã ảnh hưởng đến kiến trúc lập trình của Alan Kay, trong đó các đối tượng truyền thông điệp cho nhau. Để mô tả kiến trúc này, ông đã đặt ra thuật ngữ lập trình hướng đối tượng vào năm 1967. Có nhiều định nghĩa cạnh tranh mô tả OOP là gì, và theo một số định nghĩa này Rust là hướng đối tượng nhưng theo những định nghĩa khác thì không. Trong chương này, chúng ta sẽ khám phá những đặc điểm nhất định thường được coi là hướng đối tượng và cách những đặc điểm đó được chuyển thành Rust theo phong cách đặc trưng. Sau đó, chúng ta sẽ chỉ cho bạn cách triển khai một mẫu thiết kế hướng đối tượng trong Rust và thảo luận về những đánh đổi khi làm như vậy so với việc triển khai một giải pháp sử dụng một số điểm mạnh của Rust.
Đặc điểm của Ngôn ngữ Hướng đối tượng
Không có sự đồng thuận trong cộng đồng lập trình về việc một ngôn ngữ cần có những tính năng gì để được coi là hướng đối tượng. Rust chịu ảnh hưởng từ nhiều mô hình lập trình, bao gồm cả OOP; ví dụ, chúng ta đã khám phá các tính năng từ lập trình hàm trong Chương 13. Có thể nói, các ngôn ngữ OOP chia sẻ một số đặc điểm chung nhất định, cụ thể là đối tượng, tính đóng gói và tính kế thừa. Hãy xem xét ý nghĩa của từng đặc điểm đó và liệu Rust có hỗ trợ chúng hay không.
Đối tượng Chứa Dữ liệu và Hành vi
Cuốn sách Design Patterns: Elements of Reusable Object-Oriented Software của Erich Gamma, Richard Helm, Ralph Johnson, và John Vlissides (Addison-Wesley, 1994), thường được gọi là cuốn sách Gang of Four (Bộ tứ), là một danh mục các mẫu thiết kế hướng đối tượng. Nó định nghĩa OOP theo cách này:
Các chương trình hướng đối tượng được tạo thành từ các đối tượng. Một đối tượng đóng gói cả dữ liệu và các thủ tục hoạt động trên dữ liệu đó. Các thủ tục này thường được gọi là phương thức hoặc hoạt động.
Theo định nghĩa này, Rust là hướng đối tượng: các struct và enum có dữ liệu, và
các khối impl cung cấp phương thức cho struct và enum. Mặc dù struct và enum
với các phương thức không được gọi là đối tượng, chúng cung cấp cùng một chức
năng, theo định nghĩa về đối tượng của Gang of Four.
Tính Đóng gói Ẩn Chi tiết Triển khai
Một khía cạnh khác thường được liên kết với OOP là ý tưởng về tính đóng gói, có nghĩa là chi tiết triển khai của một đối tượng không thể truy cập bởi mã sử dụng đối tượng đó. Do đó, cách duy nhất để tương tác với một đối tượng là thông qua API công khai của nó; mã sử dụng đối tượng không nên có khả năng truy cập vào bên trong đối tượng và thay đổi dữ liệu hoặc hành vi trực tiếp. Điều này cho phép lập trình viên thay đổi và tái cấu trúc bên trong của một đối tượng mà không cần phải thay đổi mã sử dụng đối tượng đó.
Chúng ta đã thảo luận về cách kiểm soát tính đóng gói trong Chương 7: chúng ta
có thể sử dụng từ khóa pub để quyết định module, kiểu, hàm và phương thức nào
trong mã của chúng ta nên được công khai, và theo mặc định mọi thứ khác đều là
riêng tư. Ví dụ, chúng ta có thể định nghĩa một struct AveragedCollection có
một trường chứa một vector các giá trị i32. Struct này cũng có thể có một
trường chứa giá trị trung bình của các giá trị trong vector, nghĩa là giá trị
trung bình không cần phải được tính toán theo yêu cầu mỗi khi ai đó cần nó. Nói
cách khác, AveragedCollection sẽ lưu trữ giá trị trung bình đã tính toán cho
chúng ta. Listing 18-1 có định nghĩa của struct AveragedCollection.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}Struct được đánh dấu pub để mã khác có thể sử dụng nó, nhưng các trường trong
struct vẫn là riêng tư. Điều này quan trọng trong trường hợp này vì chúng ta
muốn đảm bảo rằng bất cứ khi nào một giá trị được thêm vào hoặc xóa khỏi danh
sách, giá trị trung bình cũng được cập nhật. Chúng ta thực hiện điều này bằng
cách triển khai các phương thức add, remove và average trên struct, như
được hiển thị trong Listing 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}Các phương thức công khai add, remove và average là những cách duy nhất để
truy cập hoặc sửa đổi dữ liệu trong một thể hiện của AveragedCollection. Khi
một mục được thêm vào list bằng phương thức add hoặc bị xóa bằng phương thức
remove, các triển khai của mỗi phương thức gọi phương thức riêng tư
update_average xử lý việc cập nhật trường average.
Chúng ta để các trường list và average là riêng tư để không có cách nào cho
mã bên ngoài thêm hoặc xóa các mục vào hoặc khỏi trường list trực tiếp; nếu
không, trường average có thể không đồng bộ khi list thay đổi. Phương thức
average trả về giá trị trong trường average, cho phép mã bên ngoài đọc
average nhưng không thể sửa đổi nó.
Bởi vì chúng ta đã đóng gói các chi tiết triển khai của struct
AveragedCollection, chúng ta có thể dễ dàng thay đổi các khía cạnh, chẳng hạn
như cấu trúc dữ liệu, trong tương lai. Ví dụ, chúng ta có thể sử dụng
HashSet<i32> thay vì Vec<i32> cho trường list. Miễn là chữ ký của các
phương thức công khai add, remove và average không thay đổi, mã sử dụng
AveragedCollection sẽ không cần phải thay đổi. Nếu chúng ta làm cho list
công khai, điều này không nhất thiết là trường hợp: HashSet<i32> và Vec<i32>
có các phương thức khác nhau để thêm và xóa các mục, vì vậy mã bên ngoài có thể
sẽ phải thay đổi nếu nó đang sửa đổi list trực tiếp.
Nếu tính đóng gói là một khía cạnh bắt buộc để một ngôn ngữ được coi là hướng
đối tượng, thì Rust đáp ứng yêu cầu đó. Tùy chọn sử dụng pub hoặc không cho
các phần khác nhau của mã cho phép đóng gói các chi tiết triển khai.
Tính kế thừa như một Hệ thống Kiểu và như Chia sẻ Mã
Tính kế thừa là một cơ chế mà một đối tượng có thể kế thừa các phần tử từ định nghĩa của một đối tượng khác, do đó có được dữ liệu và hành vi của đối tượng cha mà không cần phải định nghĩa lại chúng.
Nếu một ngôn ngữ phải có tính kế thừa để được coi là hướng đối tượng, thì Rust không phải là một ngôn ngữ như vậy. Không có cách nào để định nghĩa một struct kế thừa các trường của struct cha và triển khai phương thức mà không sử dụng macro.
Tuy nhiên, nếu bạn quen với việc có tính kế thừa trong bộ công cụ lập trình của mình, bạn có thể sử dụng các giải pháp khác trong Rust, tùy thuộc vào lý do bạn chọn tính kế thừa từ đầu.
Bạn sẽ chọn tính kế thừa vì hai lý do chính. Một là để tái sử dụng mã: bạn có
thể triển khai một hành vi cụ thể cho một kiểu, và tính kế thừa cho phép bạn tái
sử dụng triển khai đó cho một kiểu khác. Bạn có thể làm điều này một cách hạn
chế trong mã Rust bằng cách sử dụng triển khai phương thức trait mặc định, mà
bạn đã thấy trong Listing 10-14 khi chúng ta thêm một triển khai mặc định của
phương thức summarize trên trait Summary. Bất kỳ kiểu nào triển khai trait
Summary sẽ có sẵn phương thức summarize mà không cần thêm mã nào nữa. Điều
này tương tự như một lớp cha có một triển khai của một phương thức và một lớp
con kế thừa cũng có triển khai của phương thức đó. Chúng ta cũng có thể ghi đè
triển khai mặc định của phương thức summarize khi chúng ta triển khai trait
Summary, điều này tương tự như một lớp con ghi đè triển khai của một phương
thức kế thừa từ lớp cha.
Lý do khác để sử dụng tính kế thừa liên quan đến hệ thống kiểu: để cho phép một kiểu con được sử dụng ở những nơi mà kiểu cha được sử dụng. Điều này còn được gọi là tính đa hình, có nghĩa là bạn có thể thay thế nhiều đối tượng cho nhau trong thời gian chạy nếu chúng chia sẻ một số đặc điểm nhất định.
Tính đa hình
Đối với nhiều người, tính đa hình đồng nghĩa với tính kế thừa. Nhưng thực tế nó là một khái niệm tổng quát hơn, đề cập đến mã có thể làm việc với dữ liệu của nhiều kiểu. Đối với tính kế thừa, những kiểu đó thường là các lớp con.
Thay vào đó, Rust sử dụng generics để trừu tượng hóa các kiểu khác nhau có thể có và các ràng buộc trait để áp đặt các ràng buộc về những gì các kiểu đó phải cung cấp. Điều này đôi khi được gọi là tính đa hình tham số có giới hạn (bounded parametric polymorphism).
Rust đã chọn một tập hợp các đánh đổi khác nhau bằng cách không cung cấp tính kế thừa. Tính kế thừa thường có nguy cơ chia sẻ nhiều mã hơn mức cần thiết. Các lớp con không phải lúc nào cũng nên chia sẻ tất cả các đặc điểm của lớp cha của chúng nhưng sẽ làm như vậy với tính kế thừa. Điều này có thể làm cho thiết kế của một chương trình kém linh hoạt hơn. Nó cũng tạo ra khả năng gọi các phương thức trên các lớp con mà không hợp lý hoặc gây ra lỗi vì các phương thức không áp dụng cho lớp con. Ngoài ra, một số ngôn ngữ chỉ cho phép đơn kế thừa (có nghĩa là một lớp con chỉ có thể kế thừa từ một lớp), hạn chế hơn nữa tính linh hoạt của thiết kế chương trình.
Vì những lý do này, Rust sử dụng cách tiếp cận khác bằng cách sử dụng các đối tượng trait thay vì tính kế thừa để cho phép tính đa hình. Hãy xem cách các đối tượng trait hoạt động.
Sử dụng Đối tượng Trait để Trừu tượng hóa Hành vi Chung
Trong Chương 8, chúng ta đã đề cập rằng một hạn chế của vector là chúng chỉ có
thể lưu trữ các phần tử của cùng một kiểu. Chúng ta đã tạo ra một giải pháp thay
thế trong Listing 8-9, trong đó chúng ta định nghĩa một enum SpreadsheetCell
có các biến thể để chứa số nguyên, số thực và văn bản. Điều này có nghĩa là
chúng ta có thể lưu trữ các kiểu dữ liệu khác nhau trong mỗi ô và vẫn có một
vector đại diện cho một hàng các ô. Đây là một giải pháp hoàn toàn phù hợp khi
các mục có thể thay thế của chúng ta là một tập hợp các kiểu cố định mà chúng ta
biết khi mã của chúng ta được biên dịch.
Tuy nhiên, đôi khi chúng ta muốn người dùng thư viện của mình có thể mở rộng tập
hợp các kiểu hợp lệ trong một tình huống cụ thể. Để minh họa cách chúng ta có
thể thực hiện điều này, chúng ta sẽ tạo một ví dụ về công cụ giao diện người
dùng đồ họa (GUI) lặp qua danh sách các mục, gọi phương thức draw trên mỗi mục
để vẽ nó lên màn hình—một kỹ thuật phổ biến cho các công cụ GUI. Chúng ta sẽ tạo
một crate thư viện có tên gui chứa cấu trúc của thư viện GUI. Crate này có thể
bao gồm một số kiểu cho mọi người sử dụng, chẳng hạn như Button hoặc
TextField. Ngoài ra, người dùng gui sẽ muốn tạo các kiểu riêng của họ có thể
được vẽ: ví dụ, một lập trình viên có thể thêm Image và một lập trình viên
khác có thể thêm SelectBox.
Tại thời điểm viết thư viện, chúng ta không thể biết và định nghĩa tất cả các
kiểu mà các lập trình viên khác có thể muốn tạo. Nhưng chúng ta biết rằng gui
cần theo dõi nhiều giá trị của các kiểu khác nhau và cần gọi phương thức draw
trên mỗi giá trị có kiểu khác nhau này. Nó không cần biết chính xác điều gì sẽ
xảy ra khi chúng ta gọi phương thức draw, chỉ cần biết rằng giá trị đó sẽ có
phương thức sẵn sàng để gọi.
Để thực hiện điều này trong ngôn ngữ có tính kế thừa, chúng ta có thể định nghĩa
một lớp có tên Component có phương thức tên là draw. Các lớp khác, chẳng hạn
như Button, Image và SelectBox, sẽ kế thừa từ Component và do đó kế thừa
phương thức draw. Mỗi lớp có thể ghi đè phương thức draw để định nghĩa hành
vi tùy chỉnh của nó, nhưng framework có thể xử lý tất cả các kiểu như thể chúng
là các thể hiện của Component và gọi draw trên chúng. Nhưng vì Rust không có
tính kế thừa, chúng ta cần một cách khác để cấu trúc thư viện gui để cho phép
người dùng tạo các kiểu mới tương thích với thư viện.
Định nghĩa một Trait cho Hành vi Chung
Để triển khai hành vi mà chúng ta muốn gui có, chúng ta sẽ định nghĩa một
trait có tên Draw có một phương thức tên draw. Sau đó, chúng ta có thể định
nghĩa một vector nhận một đối tượng trait. Một đối tượng trait trỏ đến cả một
thể hiện của một kiểu triển khai trait được chỉ định của chúng ta và một bảng
được sử dụng để tra cứu các phương thức trait trên kiểu đó tại thời điểm chạy.
Chúng ta tạo một đối tượng trait bằng cách chỉ định một loại con trỏ, chẳng hạn
như tham chiếu & hoặc con trỏ thông minh Box<T>, sau đó là từ khóa dyn, và
sau đó chỉ định trait liên quan. (Chúng ta sẽ nói về lý do đối tượng trait phải
sử dụng con trỏ trong "Các kiểu Kích thước Động và Trait
Sized" trong Chương 20.) Chúng ta có thể sử
dụng đối tượng trait thay thế cho kiểu generic hoặc kiểu cụ thể. Bất cứ khi nào
chúng ta sử dụng đối tượng trait, hệ thống kiểu của Rust sẽ đảm bảo tại thời
điểm biên dịch rằng bất kỳ giá trị nào được sử dụng trong ngữ cảnh đó sẽ triển
khai trait của đối tượng trait. Do đó, chúng ta không cần phải biết tất cả các
kiểu có thể có tại thời điểm biên dịch.
Chúng ta đã đề cập rằng, trong Rust, chúng ta tránh gọi các struct và enum là
"đối tượng" để phân biệt chúng với đối tượng của các ngôn ngữ khác. Trong một
struct hoặc enum, dữ liệu trong các trường struct và hành vi trong các khối
impl được tách biệt, trong khi ở các ngôn ngữ khác, dữ liệu và hành vi kết hợp
thành một khái niệm thường được gọi là đối tượng. Đối tượng trait khác với đối
tượng trong các ngôn ngữ khác ở chỗ chúng ta không thể thêm dữ liệu vào đối
tượng trait. Đối tượng trait không hữu ích một cách tổng quát như đối tượng
trong các ngôn ngữ khác: mục đích cụ thể của chúng là cho phép trừu tượng hóa
qua hành vi chung.
Listing 18-3 cho thấy cách định nghĩa một trait có tên Draw với một phương
thức có tên draw.
pub trait Draw {
fn draw(&self);
}Cú pháp này có thể quen thuộc từ các cuộc thảo luận của chúng ta về cách định
nghĩa trait trong Chương 10. Tiếp theo là một cú pháp mới: Listing 18-4 định
nghĩa một struct có tên Screen chứa một vector có tên components. Vector này
có kiểu Box<dyn Draw>, là một đối tượng trait; nó là một đại diện cho bất kỳ
kiểu nào bên trong một Box triển khai trait Draw.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Trên struct Screen, chúng ta sẽ định nghĩa một phương thức có tên run sẽ gọi
phương thức draw trên mỗi components của nó, như được hiển thị trong Listing
18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Điều này hoạt động khác với việc định nghĩa một struct sử dụng tham số kiểu
generic với ràng buộc trait. Một tham số kiểu generic chỉ có thể được thay thế
bằng một kiểu cụ thể tại một thời điểm, trong khi đối tượng trait cho phép nhiều
kiểu cụ thể điền vào đối tượng trait tại thời điểm chạy. Ví dụ, chúng ta có thể
đã định nghĩa struct Screen sử dụng kiểu generic và ràng buộc trait, như trong
Listing 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Điều này giới hạn chúng ta vào một thể hiện Screen có danh sách các thành phần
tất cả đều có kiểu Button hoặc tất cả đều có kiểu TextField. Nếu bạn chỉ
muốn có các bộ sưu tập đồng nhất, sử dụng generic và ràng buộc trait là tốt hơn
vì các định nghĩa sẽ được đơn hình hóa tại thời điểm biên dịch để sử dụng các
kiểu cụ thể.
Mặt khác, với phương pháp sử dụng đối tượng trait, một thể hiện Screen có thể
chứa một Vec<T> bao gồm cả Box<Button> và Box<TextField>. Hãy xem cách
điều này hoạt động, và sau đó chúng ta sẽ nói về các hệ quả hiệu suất thời gian
chạy.
Triển khai Trait
Bây giờ chúng ta sẽ thêm một số kiểu triển khai trait Draw. Chúng ta sẽ cung
cấp kiểu Button. Một lần nữa, việc thực sự triển khai một thư viện GUI nằm
ngoài phạm vi của cuốn sách này, vì vậy phương thức draw sẽ không có bất kỳ
triển khai hữu ích nào trong phần thân của nó. Để hình dung triển khai có thể
trông như thế nào, một struct Button có thể có các trường cho width,
height và label, như được hiển thị trong Listing 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Các trường width, height và label trên Button sẽ khác với các trường
trên các thành phần khác; ví dụ, một kiểu TextField có thể có những trường
giống nhau cộng với trường placeholder. Mỗi kiểu mà chúng ta muốn vẽ trên màn
hình sẽ triển khai trait Draw nhưng sẽ sử dụng mã khác nhau trong phương thức
draw để định nghĩa cách vẽ kiểu cụ thể đó, như Button đã làm ở đây (không có
mã GUI thực tế, như đã đề cập). Kiểu Button, ví dụ, có thể có một khối impl
bổ sung chứa các phương thức liên quan đến những gì xảy ra khi người dùng nhấp
vào nút. Những loại phương thức này sẽ không áp dụng cho các kiểu như
TextField.
Nếu ai đó sử dụng thư viện của chúng ta quyết định triển khai một struct
SelectBox có các trường width, height và options, họ cũng sẽ triển khai
trait Draw trên kiểu SelectBox, như được hiển thị trong Listing 18-8.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}Người dùng thư viện của chúng ta bây giờ có thể viết hàm main của họ để tạo
một thể hiện Screen. Với thể hiện Screen, họ có thể thêm một SelectBox và
một Button bằng cách đặt mỗi cái vào một Box<T> để trở thành một đối tượng
trait. Sau đó, họ có thể gọi phương thức run trên thể hiện Screen, sẽ gọi
draw trên mỗi thành phần. Listing 18-9 cho thấy triển khai này.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Khi chúng ta viết thư viện, chúng ta không biết rằng ai đó có thể thêm kiểu
SelectBox, nhưng triển khai Screen của chúng ta có thể hoạt động với kiểu
mới và vẽ nó vì SelectBox triển khai trait Draw, có nghĩa là nó triển khai
phương thức draw.
Khái niệm này—chỉ quan tâm đến các thông điệp mà một giá trị phản hồi thay vì
kiểu cụ thể của giá trị—tương tự như khái niệm duck typing trong các ngôn ngữ
kiểu động: nếu nó đi như một con vịt và kêu quạc quạc như một con vịt, thì nó
phải là một con vịt! Trong triển khai của run trên Screen trong Listing
18-5, run không cần biết kiểu cụ thể của mỗi thành phần là gì. Nó không kiểm
tra liệu một thành phần có phải là một thể hiện của Button hay SelectBox, nó
chỉ gọi phương thức draw trên thành phần. Bằng cách chỉ định Box<dyn Draw>
là kiểu của các giá trị trong vector components, chúng ta đã định nghĩa
Screen cần các giá trị mà chúng ta có thể gọi phương thức draw trên đó.
Lợi thế của việc sử dụng đối tượng trait và hệ thống kiểu của Rust để viết mã tương tự như mã sử dụng duck typing là chúng ta không bao giờ phải kiểm tra liệu một giá trị có triển khai một phương thức cụ thể nào đó tại thời điểm chạy hoặc lo lắng về việc gặp lỗi nếu một giá trị không triển khai một phương thức nhưng chúng ta vẫn gọi nó. Rust sẽ không biên dịch mã của chúng ta nếu các giá trị không triển khai các trait mà đối tượng trait cần.
Ví dụ, Listing 18-10 cho thấy điều gì xảy ra nếu chúng ta cố gắng tạo một
Screen với một String làm thành phần.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}Chúng ta sẽ nhận được lỗi này vì String không triển khai trait Draw:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
Lỗi này cho chúng ta biết rằng hoặc là chúng ta đang truyền một thứ gì đó cho
Screen mà chúng ta không có ý định truyền và do đó nên truyền một kiểu khác,
hoặc chúng ta nên triển khai Draw trên String để Screen có thể gọi draw
trên nó.
Đối tượng Trait Thực hiện Điều phối Động
Nhớ lại trong "Hiệu suất của Mã Sử dụng Generic" trong Chương 10, chúng ta đã thảo luận về quá trình đơn hình hóa được thực hiện trên generic bởi trình biên dịch: trình biên dịch tạo ra các triển khai không generic của các hàm và phương thức cho mỗi kiểu cụ thể mà chúng ta sử dụng thay thế cho tham số kiểu generic. Mã kết quả từ quá trình đơn hình hóa đang thực hiện điều phối tĩnh, đó là khi trình biên dịch biết phương thức nào bạn đang gọi tại thời điểm biên dịch. Điều này trái ngược với điều phối động, là khi trình biên dịch không thể biết tại thời điểm biên dịch phương thức nào bạn đang gọi. Trong các trường hợp điều phối động, trình biên dịch tạo ra mã mà tại thời điểm chạy sẽ biết phương thức nào để gọi.
Khi chúng ta sử dụng đối tượng trait, Rust phải sử dụng điều phối động. Trình biên dịch không biết tất cả các kiểu có thể được sử dụng với mã đang sử dụng đối tượng trait, vì vậy nó không biết phương thức nào được triển khai trên kiểu nào để gọi. Thay vào đó, tại thời điểm chạy, Rust sử dụng các con trỏ bên trong đối tượng trait để biết phương thức nào cần gọi. Việc tra cứu này phát sinh chi phí thời gian chạy không xảy ra với điều phối tĩnh. Điều phối động cũng ngăn trình biên dịch chọn để nội tuyến mã của một phương thức, từ đó ngăn chặn một số tối ưu hóa, và Rust có một số quy tắc về nơi bạn có thể và không thể sử dụng điều phối động, được gọi là khả năng tương thích dyn. Những quy tắc đó nằm ngoài phạm vi của cuộc thảo luận này, nhưng bạn có thể đọc thêm về chúng trong tài liệu tham khảo. Tuy nhiên, chúng ta đã có được sự linh hoạt bổ sung trong mã mà chúng ta đã viết trong Listing 18-5 và có thể hỗ trợ trong Listing 18-9, vì vậy đó là một sự đánh đổi cần cân nhắc.
Triển khai một Mẫu Thiết kế Hướng đối tượng
Mẫu trạng thái (state pattern) là một mẫu thiết kế hướng đối tượng. Trọng tâm của mẫu này là chúng ta định nghĩa một tập hợp các trạng thái mà một giá trị có thể có bên trong. Các trạng thái được biểu diễn bởi một tập hợp các đối tượng trạng thái, và hành vi của giá trị thay đổi dựa trên trạng thái của nó. Chúng ta sẽ tiến hành thực hiện một ví dụ về một struct bài đăng blog có một trường để lưu trữ trạng thái của nó, trường này sẽ là một đối tượng trạng thái từ tập hợp "nháp", "đang xét duyệt", hoặc "đã xuất bản".
Các đối tượng trạng thái chia sẻ chức năng: trong Rust, tất nhiên, chúng ta sử dụng struct và trait thay vì đối tượng và tính kế thừa. Mỗi đối tượng trạng thái chịu trách nhiệm cho hành vi của chính nó và cho việc quản lý khi nào nó nên chuyển sang trạng thái khác. Giá trị chứa đối tượng trạng thái không biết gì về các hành vi khác nhau của các trạng thái hoặc khi nào chuyển đổi giữa các trạng thái.
Lợi thế của việc sử dụng mẫu trạng thái là khi các yêu cầu nghiệp vụ của chương trình thay đổi, chúng ta sẽ không cần phải thay đổi mã của giá trị đang giữ trạng thái hoặc mã sử dụng giá trị đó. Chúng ta sẽ chỉ cần cập nhật mã bên trong một trong các đối tượng trạng thái để thay đổi quy tắc của nó hoặc có thể thêm nhiều đối tượng trạng thái hơn.
Đầu tiên, chúng ta sẽ triển khai mẫu trạng thái theo cách hướng đối tượng truyền thống hơn, sau đó chúng ta sẽ sử dụng một cách tiếp cận tự nhiên hơn một chút trong Rust. Hãy đi sâu vào việc triển khai dần dần một quy trình làm việc của bài đăng blog bằng cách sử dụng mẫu trạng thái.
Chức năng cuối cùng sẽ trông như thế này:
- Một bài đăng blog bắt đầu như một bản nháp trống.
- Khi bản nháp hoàn thành, một đánh giá của bài đăng được yêu cầu.
- Khi bài đăng được phê duyệt, nó được xuất bản.
- Chỉ có các bài đăng blog đã xuất bản mới trả về nội dung để in, vì vậy các bài đăng chưa được phê duyệt không thể vô tình được xuất bản.
Bất kỳ thay đổi nào khác được thử trên một bài đăng sẽ không có hiệu lực. Ví dụ, nếu chúng ta cố gắng phê duyệt một bài đăng blog nháp trước khi chúng ta yêu cầu đánh giá, bài đăng vẫn sẽ là một bản nháp chưa xuất bản.
Một Cách Tiếp cận Hướng đối tượng Truyền thống
Có vô số cách để cấu trúc mã để giải quyết cùng một vấn đề, mỗi cách có những đánh đổi khác nhau. Việc triển khai của phần này thiên về phong cách hướng đối tượng truyền thống hơn, điều này có thể viết được trong Rust, nhưng không tận dụng một số điểm mạnh của Rust. Sau đó, chúng ta sẽ trình bày một giải pháp khác vẫn sử dụng mẫu thiết kế hướng đối tượng nhưng được cấu trúc theo cách có thể trông ít quen thuộc hơn đối với các lập trình viên có kinh nghiệm hướng đối tượng. Chúng ta sẽ so sánh hai giải pháp để trải nghiệm những đánh đổi khi thiết kế mã Rust khác với mã trong các ngôn ngữ khác.
Danh sách 18-11 hiển thị quy trình làm việc này dưới dạng mã: đây là một ví dụ
về việc sử dụng API mà chúng ta sẽ triển khai trong một thư viện crate có tên là
blog. Điều này sẽ không biên dịch được vì chúng ta chưa triển khai crate
blog.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Chúng ta muốn cho phép người dùng tạo một bài đăng blog nháp mới với
Post::new. Chúng ta muốn cho phép thêm văn bản vào bài đăng blog. Nếu chúng ta
cố gắng lấy nội dung của bài đăng ngay lập tức, trước khi phê duyệt, chúng ta sẽ
không nhận được bất kỳ văn bản nào vì bài đăng vẫn đang ở trạng thái nháp. Chúng
ta đã thêm assert_eq! trong mã để minh họa. Một bài kiểm tra đơn vị xuất sắc
cho trường hợp này sẽ khẳng định rằng một bài đăng blog nháp trả về một chuỗi
rỗng từ phương thức content, nhưng chúng ta sẽ không viết kiểm tra cho ví dụ
này.
Tiếp theo, chúng ta muốn cho phép yêu cầu đánh giá bài đăng, và chúng ta muốn
content trả về một chuỗi rỗng trong khi chờ đánh giá. Khi bài đăng nhận được
sự chấp thuận, nó sẽ được xuất bản, nghĩa là văn bản của bài đăng sẽ được trả về
khi gọi content.
Lưu ý rằng kiểu duy nhất mà chúng ta tương tác từ crate là kiểu Post. Kiểu này
sẽ sử dụng mẫu trạng thái và sẽ chứa một giá trị sẽ là một trong ba đối tượng
trạng thái đại diện cho các trạng thái khác nhau mà một bài đăng có thể có—nháp,
đang xét duyệt, hoặc đã xuất bản. Việc thay đổi từ trạng thái này sang trạng
thái khác sẽ được quản lý nội bộ trong kiểu Post. Các trạng thái thay đổi để
đáp ứng với các phương thức được gọi bởi người dùng thư viện của chúng ta trên
thực thể Post, nhưng họ không phải quản lý các thay đổi trạng thái trực tiếp.
Ngoài ra, người dùng không thể mắc lỗi với các trạng thái, chẳng hạn như xuất
bản một bài đăng trước khi nó được xem xét.
Định nghĩa Post và Tạo một Thực thể Mới ở Trạng thái Nháp
Hãy bắt đầu với việc triển khai thư viện! Chúng ta biết rằng chúng ta cần một
struct Post công khai chứa một số nội dung, vì vậy chúng ta sẽ bắt đầu với
định nghĩa của struct và một hàm new công khai liên quan để tạo một thực thể
của Post, như trong Danh sách 18-12. Chúng ta cũng sẽ tạo một trait State
riêng tư sẽ định nghĩa hành vi mà tất cả các đối tượng trạng thái cho một Post
phải có.
Sau đó, Post sẽ chứa một đối tượng trait của Box<dyn State> bên trong một
Option<T> trong một trường riêng tư có tên là state để lưu trữ đối tượng
trạng thái. Bạn sẽ thấy tại sao Option<T> là cần thiết sau một chút.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Trait State định nghĩa hành vi được chia sẻ bởi các trạng thái bài đăng khác
nhau. Các đối tượng trạng thái là Draft, PendingReview, và Published, và
tất cả chúng sẽ triển khai trait State. Hiện tại, trait không có bất kỳ phương
thức nào, và chúng ta sẽ bắt đầu bằng cách định nghĩa chỉ trạng thái Draft vì
đó là trạng thái mà chúng ta muốn một bài đăng bắt đầu.
Khi chúng ta tạo một Post mới, chúng ta đặt trường state của nó thành một
giá trị Some chứa một Box. Box này trỏ đến một thực thể mới của struct
Draft. Điều này đảm bảo rằng bất cứ khi nào chúng ta tạo một thực thể mới của
Post, nó sẽ bắt đầu như một bản nháp. Vì trường state của Post là riêng
tư, không có cách nào để tạo một Post ở bất kỳ trạng thái nào khác! Trong hàm
Post::new, chúng ta đặt trường content thành một String rỗng, mới.
Lưu trữ Văn bản của Nội dung Bài đăng
Chúng ta đã thấy trong Danh sách 18-11 rằng chúng ta muốn có thể gọi một phương
thức có tên là add_text và truyền cho nó một &str để sau đó được thêm vào
như là nội dung văn bản của bài đăng blog. Chúng ta triển khai điều này như một
phương thức, thay vì để lộ trường content dưới dạng pub, để sau này chúng ta
có thể triển khai một phương thức sẽ kiểm soát cách dữ liệu của trường content
được đọc. Phương thức add_text khá đơn giản, vì vậy hãy thêm triển khai trong
Danh sách 18-13 vào khối impl Post.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}Phương thức add_text lấy một tham chiếu có thể thay đổi đến self vì chúng ta
đang thay đổi thực thể Post mà chúng ta đang gọi add_text trên đó. Sau đó,
chúng ta gọi push_str trên String trong content và truyền đối số text để
thêm vào content đã lưu. Hành vi này không phụ thuộc vào trạng thái mà bài
đăng đang ở, vì vậy nó không phải là một phần của mẫu trạng thái. Phương thức
add_text không tương tác với trường state chút nào, nhưng nó là một phần của
hành vi mà chúng ta muốn hỗ trợ.
Đảm bảo Nội dung của một Bài đăng Nháp là Trống
Ngay cả sau khi chúng ta đã gọi add_text và thêm một số nội dung vào bài đăng
của chúng ta, chúng ta vẫn muốn phương thức content trả về một lát cắt chuỗi
rỗng vì bài đăng vẫn đang ở trạng thái nháp, như được hiển thị trên dòng 7 của
Danh sách 18-11. Hiện tại, hãy triển khai phương thức content với thứ đơn giản
nhất sẽ hoàn thành yêu cầu này: luôn trả về một lát cắt chuỗi rỗng. Chúng ta sẽ
thay đổi điều này sau khi chúng ta triển khai khả năng thay đổi trạng thái của
một bài đăng để nó có thể được xuất bản. Cho đến nay, các bài đăng chỉ có thể ở
trạng thái nháp, vì vậy nội dung bài đăng sẽ luôn trống. Danh sách 18-14 hiển
thị triển khai giữ chỗ này.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}Với phương thức content đã thêm này, mọi thứ trong Danh sách 18-11 cho đến
dòng 7 hoạt động như dự định.
Yêu cầu Đánh giá Thay đổi Trạng thái của Bài đăng
Tiếp theo, chúng ta cần thêm chức năng để yêu cầu đánh giá một bài đăng, điều
này sẽ thay đổi trạng thái của nó từ Draft sang PendingReview. Danh sách
18-15 hiển thị mã này.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}Chúng ta cung cấp cho Post một phương thức công khai có tên là
request_review sẽ lấy một tham chiếu có thể thay đổi đến self. Sau đó, chúng
ta gọi một phương thức request_review nội bộ trên trạng thái hiện tại của
Post, và phương thức request_review thứ hai này tiêu thụ trạng thái hiện tại
và trả về một trạng thái mới.
Chúng ta thêm phương thức request_review vào trait State; tất cả các kiểu
triển khai trait sẽ cần phải triển khai phương thức request_review. Lưu ý rằng
thay vì có self, &self, hoặc &mut self làm tham số đầu tiên của phương
thức, chúng ta có self: Box<Self>. Cú pháp này có nghĩa là phương thức chỉ hợp
lệ khi được gọi trên một Box chứa kiểu. Cú pháp này lấy quyền sở hữu của
Box<Self>, làm mất hiệu lực trạng thái cũ để giá trị trạng thái của Post có
thể chuyển đổi thành một trạng thái mới.
Để tiêu thụ trạng thái cũ, phương thức request_review cần lấy quyền sở hữu của
giá trị trạng thái. Đây là nơi mà Option trong trường state của Post xuất
hiện: chúng ta gọi phương thức take để lấy giá trị Some ra khỏi trường
state và để lại một None trong vị trí của nó vì Rust không cho phép chúng ta
có các trường không được điền trong struct. Điều này cho phép chúng ta di chuyển
giá trị state ra khỏi Post thay vì mượn nó. Sau đó, chúng ta sẽ đặt giá trị
state của bài đăng thành kết quả của thao tác này.
Chúng ta cần đặt state thành None tạm thời thay vì đặt nó trực tiếp với mã
như self.state = self.state.request_review(); để lấy quyền sở hữu của giá trị
state. Điều này đảm bảo Post không thể sử dụng giá trị state cũ sau khi
chúng ta đã chuyển đổi nó thành một trạng thái mới.
Phương thức request_review trên Draft trả về một thực thể mới, được đóng hộp
của một struct PendingReview mới, đại diện cho trạng thái khi một bài đăng
đang chờ đánh giá. Struct PendingReview cũng triển khai phương thức
request_review nhưng không thực hiện bất kỳ chuyển đổi nào. Thay vào đó, nó
trả về chính nó vì khi chúng ta yêu cầu đánh giá một bài đăng đã ở trạng thái
PendingReview, nó nên tiếp tục ở trạng thái PendingReview.
Bây giờ chúng ta có thể bắt đầu thấy những lợi thế của mẫu trạng thái: phương
thức request_review trên Post giống nhau bất kể giá trị state của nó là
gì. Mỗi trạng thái chịu trách nhiệm cho các quy tắc của riêng nó.
Chúng ta sẽ để phương thức content trên Post như hiện tại, trả về một lát
cắt chuỗi rỗng. Bây giờ chúng ta có thể có một Post ở trạng thái
PendingReview cũng như ở trạng thái Draft, nhưng chúng ta muốn có hành vi
giống nhau ở trạng thái PendingReview. Danh sách 18-11 hiện hoạt động cho đến
dòng 10!
Thêm approve để Thay đổi Hành vi của content
Phương thức approve sẽ tương tự như phương thức request_review: nó sẽ đặt
state thành giá trị mà trạng thái hiện tại nói rằng nó nên có khi trạng thái
đó được phê duyệt, như được hiển thị trong Danh sách 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Chúng ta thêm phương thức approve vào trait State và thêm một struct mới
triển khai State, trạng thái Published.
Tương tự như cách request_review trên PendingReview hoạt động, nếu chúng ta
gọi phương thức approve trên một Draft, nó sẽ không có hiệu lực gì vì
approve sẽ trả về self. Khi chúng ta gọi approve trên PendingReview, nó
trả về một thực thể mới, được đóng hộp của struct Published. Struct
Published triển khai trait State, và đối với cả phương thức request_review
và phương thức approve, nó trả về chính nó vì bài đăng nên ở trong trạng thái
Published trong các trường hợp đó.
Bây giờ chúng ta cần cập nhật phương thức content trên Post. Chúng ta muốn
giá trị trả về từ content phụ thuộc vào trạng thái hiện tại của Post, vì vậy
chúng ta sẽ để Post ủy quyền cho một phương thức content được định nghĩa
trên state của nó, như được hiển thị trong Danh sách 18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Vì mục tiêu là giữ tất cả các quy tắc này bên trong các struct triển khai
State, chúng ta gọi một phương thức content trên giá trị trong state và
truyền thực thể bài đăng (tức là self) như một đối số. Sau đó, chúng ta trả về
giá trị được trả về từ việc sử dụng phương thức content trên giá trị state.
Chúng ta gọi phương thức as_ref trên Option vì chúng ta muốn một tham chiếu
đến giá trị bên trong Option chứ không phải quyền sở hữu của giá trị. Vì
state là một Option<Box<dyn State>>, khi chúng ta gọi as_ref, một
Option<&Box<dyn State>> được trả về. Nếu chúng ta không gọi as_ref, chúng ta
sẽ gặp lỗi vì chúng ta không thể di chuyển state ra khỏi &self được mượn của
tham số hàm.
Sau đó, chúng ta gọi phương thức unwrap, mà chúng ta biết sẽ không bao giờ gây
panic vì chúng ta biết các phương thức trên Post đảm bảo rằng state sẽ luôn
chứa một giá trị Some khi các phương thức đó hoàn thành. Đây là một trong
những trường hợp chúng ta đã nói đến trong "Các trường hợp Trong Đó Bạn Có Thêm
Thông tin Hơn Trình biên dịch" trong
Chương 9 khi chúng ta biết rằng một giá trị None không bao giờ có thể xảy ra,
mặc dù trình biên dịch không thể hiểu điều đó.
Ở thời điểm này, khi chúng ta gọi content trên &Box<dyn State>, ép buộc giải
tham chiếu sẽ có hiệu lực trên & và Box để phương thức content cuối cùng
sẽ được gọi trên kiểu triển khai trait State. Điều đó có nghĩa là chúng ta cần
thêm content vào định nghĩa trait State, và đó là nơi chúng ta sẽ đặt logic
cho nội dung nào sẽ trả về tùy thuộc vào trạng thái nào chúng ta có, như được
hiển thị trong Danh sách 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}Chúng ta thêm một triển khai mặc định cho phương thức content trả về một lát
cắt chuỗi rỗng. Điều đó có nghĩa là chúng ta không cần triển khai content trên
các struct Draft và PendingReview. Struct Published sẽ ghi đè phương thức
content và trả về giá trị trong post.content. Mặc dù thuận tiện, việc có
phương thức content trên State quyết định content của Post đang làm mờ
ranh giới giữa trách nhiệm của State và trách nhiệm của Post.
Lưu ý rằng chúng ta cần chú thích thời gian sống cho phương thức này, như chúng
ta đã thảo luận trong Chương 10. Chúng ta đang lấy một tham chiếu đến một post
làm đối số và trả về một tham chiếu đến một phần của post đó, vì vậy thời gian
sống của tham chiếu trả về có liên quan đến thời gian sống của đối số post.
Và chúng ta đã hoàn thành—tất cả Danh sách 18-11 hiện hoạt động! Chúng ta đã
triển khai mẫu trạng thái với các quy tắc của quy trình làm việc bài đăng blog.
Logic liên quan đến các quy tắc nằm trong các đối tượng trạng thái thay vì bị
phân tán khắp Post.
Tại sao Không Phải Một Enum?
Bạn có thể đã tự hỏi tại sao chúng ta không sử dụng một
enumvới các biến thể trạng thái bài đăng khác nhau. Đó chắc chắn là một giải pháp có thể; hãy thử nó và so sánh kết quả cuối cùng để xem bạn thích cái nào hơn! Một nhược điểm của việc sử dụng enum là mỗi nơi kiểm tra giá trị của enum sẽ cần một biểu thứcmatchhoặc tương tự để xử lý mọi biến thể có thể. Điều này có thể trở nên lặp lại hơn so với giải pháp đối tượng trait này.
Nhược điểm của Mẫu Trạng thái
Chúng ta đã chỉ ra rằng Rust có khả năng triển khai mẫu trạng thái hướng đối
tượng để đóng gói các loại hành vi khác nhau mà một bài đăng nên có trong mỗi
trạng thái. Các phương thức trên Post không biết gì về các hành vi khác nhau.
Cách chúng ta tổ chức mã, chúng ta chỉ phải nhìn vào một nơi để biết các cách
khác nhau mà một bài đăng đã xuất bản có thể hành xử: triển khai của trait
State trên struct Published.
Nếu chúng ta tạo một triển khai thay thế không sử dụng mẫu trạng thái, thay vào
đó chúng ta có thể sử dụng các biểu thức match trong các phương thức trên
Post hoặc thậm chí trong mã main kiểm tra trạng thái của bài đăng và thay
đổi hành vi ở những nơi đó. Điều đó có nghĩa là chúng ta sẽ phải nhìn vào nhiều
nơi để hiểu tất cả các hàm ý của việc một bài đăng ở trạng thái đã xuất bản.
Với mẫu trạng thái, các phương thức Post và những nơi chúng ta sử dụng Post
không cần các biểu thức match, và để thêm một trạng thái mới, chúng ta chỉ cần
thêm một struct mới và triển khai các phương thức trait trên struct đó ở một vị
trí.
Việc triển khai sử dụng mẫu trạng thái rất dễ mở rộng để thêm chức năng. Để thấy sự đơn giản của việc duy trì mã sử dụng mẫu trạng thái, hãy thử một vài gợi ý này:
- Thêm một phương thức
rejectthay đổi trạng thái của bài đăng từPendingReviewtrở lạiDraft. - Yêu cầu hai lần gọi
approvetrước khi trạng thái có thể được thay đổi thànhPublished. - Chỉ cho phép người dùng thêm nội dung văn bản khi bài đăng ở trạng thái
Draft. Gợi ý: để đối tượng trạng thái chịu trách nhiệm cho những gì có thể thay đổi về nội dung nhưng không chịu trách nhiệm sửa đổiPost.
Một nhược điểm của mẫu trạng thái là, vì các trạng thái triển khai các chuyển
đổi giữa các trạng thái, một số trạng thái được kết nối với nhau. Nếu chúng ta
thêm một trạng thái khác giữa PendingReview và Published, chẳng hạn như
Scheduled, chúng ta sẽ phải thay đổi mã trong PendingReview để chuyển sang
Scheduled thay vì Published. Sẽ ít công việc hơn nếu PendingReview không
cần thay đổi với việc thêm một trạng thái mới, nhưng điều đó có nghĩa là chuyển
sang một mẫu thiết kế khác.
Một nhược điểm khác là chúng ta đã lặp lại một số logic. Để loại bỏ một số sự
lặp lại, chúng ta có thể thử tạo các triển khai mặc định cho các phương thức
request_review và approve trên trait State trả về self. Tuy nhiên, điều
này sẽ không hoạt động: khi sử dụng State như một đối tượng trait, trait không
biết self cụ thể sẽ là gì chính xác, vì vậy kiểu trả về không được biết tại
thời điểm biên dịch. (Đây là một trong những quy tắc tương thích dyn được đề
cập trước đó.)
Sự lặp lại khác bao gồm các triển khai tương tự của các phương thức
request_review và approve trên Post. Cả hai phương thức đều sử dụng
Option::take với trường state của Post, và nếu state là Some, chúng ủy
quyền cho triển khai của cùng một phương thức trong giá trị được bọc và đặt giá
trị mới của trường state thành kết quả. Nếu chúng ta có nhiều phương thức trên
Post tuân theo mẫu này, chúng ta có thể cân nhắc định nghĩa một macro để loại
bỏ sự lặp lại (xem "Macro" trong Chương 20).
Bằng cách triển khai mẫu trạng thái chính xác như được định nghĩa cho các ngôn
ngữ hướng đối tượng, chúng ta không tận dụng hết các điểm mạnh của Rust như
chúng ta có thể. Hãy xem xét một số thay đổi chúng ta có thể thực hiện đối với
crate blog có thể biến các trạng thái và chuyển đổi không hợp lệ thành các lỗi
thời điểm biên dịch.
Mã hóa Trạng thái và Hành vi dưới dạng Kiểu
Chúng ta sẽ chỉ cho bạn cách suy nghĩ lại về mẫu trạng thái để có được một tập hợp các đánh đổi khác. Thay vì đóng gói hoàn toàn các trạng thái và chuyển đổi để mã bên ngoài không có kiến thức về chúng, chúng ta sẽ mã hóa các trạng thái thành các kiểu khác nhau. Do đó, hệ thống kiểm tra kiểu của Rust sẽ ngăn chặn các nỗ lực sử dụng bài đăng nháp ở những nơi chỉ có bài đăng đã xuất bản được phép bằng cách đưa ra lỗi trình biên dịch.
Hãy xem xét phần đầu tiên của main trong Danh sách 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Chúng ta vẫn cho phép tạo bài đăng mới ở trạng thái nháp bằng Post::new và khả
năng thêm văn bản vào nội dung của bài đăng. Nhưng thay vì có một phương thức
content trên bài đăng nháp trả về một chuỗi rỗng, chúng ta sẽ làm cho bài đăng
nháp không có phương thức content chút nào. Bằng cách đó, nếu chúng ta cố gắng
lấy nội dung của một bài đăng nháp, chúng ta sẽ nhận được lỗi trình biên dịch
cho chúng ta biết rằng phương thức không tồn tại. Kết quả là, sẽ không thể cho
chúng ta vô tình hiển thị nội dung bài đăng nháp trong sản xuất vì mã đó thậm
chí sẽ không biên dịch. Danh sách 18-19 hiển thị định nghĩa của một struct
Post và một struct DraftPost, cũng như các phương thức trên mỗi struct.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Cả hai struct Post và DraftPost đều có một trường riêng tư content lưu trữ
văn bản của bài đăng blog. Các struct không còn có trường state vì chúng ta
đang di chuyển việc mã hóa trạng thái vào các kiểu của struct. Struct Post sẽ
đại diện cho một bài đăng đã xuất bản, và nó có một phương thức content trả về
content.
Chúng ta vẫn có một hàm Post::new, nhưng thay vì trả về một thực thể của
Post, nó trả về một thực thể của DraftPost. Vì content là riêng tư và
không có bất kỳ hàm nào trả về Post, hiện tại không thể tạo một thực thể của
Post.
Struct DraftPost có một phương thức add_text, vì vậy chúng ta có thể thêm
văn bản vào content như trước, nhưng lưu ý rằng DraftPost không có phương
thức content được định nghĩa! Vì vậy, bây giờ chương trình đảm bảo tất cả các
bài đăng bắt đầu là bài đăng nháp, và bài đăng nháp không có nội dung của chúng
sẵn có để hiển thị. Bất kỳ nỗ lực nào để vượt qua các ràng buộc này sẽ dẫn đến
lỗi trình biên dịch.
Triển khai Chuyển đổi dưới dạng Chuyển đổi thành Các Kiểu Khác nhau
Vậy làm thế nào để chúng ta có được một bài đăng đã xuất bản? Chúng ta muốn thực
thi quy tắc rằng một bài đăng nháp phải được xem xét và phê duyệt trước khi nó
có thể được xuất bản. Một bài đăng trong trạng thái chờ xem xét vẫn không nên
hiển thị bất kỳ nội dung nào. Hãy triển khai các ràng buộc này bằng cách thêm
một struct khác, PendingReviewPost, định nghĩa phương thức request_review
trên DraftPost để trả về một PendingReviewPost và định nghĩa một phương thức
approve trên PendingReviewPost để trả về một Post, như được hiển thị trong
Danh sách 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}Các phương thức request_review và approve lấy quyền sở hữu của self, do đó
tiêu thụ các thực thể DraftPost và PendingReviewPost và chuyển đổi chúng
thành một PendingReviewPost và một Post đã xuất bản, tương ứng. Bằng cách
này, chúng ta sẽ không có bất kỳ thực thể DraftPost nào còn tồn tại sau khi
chúng ta đã gọi request_review trên chúng, và tương tự. Struct
PendingReviewPost không có phương thức content được định nghĩa trên nó, vì
vậy việc cố gắng đọc nội dung của nó dẫn đến lỗi trình biên dịch, cũng giống như
với DraftPost. Vì cách duy nhất để có được một thực thể Post đã xuất bản có
phương thức content được định nghĩa là gọi phương thức approve trên một
PendingReviewPost, và cách duy nhất để có được một PendingReviewPost là gọi
phương thức request_review trên một DraftPost, chúng ta đã mã hóa quy trình
làm việc của bài đăng blog vào hệ thống kiểu.
Nhưng chúng ta cũng phải thực hiện một số thay đổi nhỏ đối với main. Các
phương thức request_review và approve trả về các thực thể mới thay vì sửa
đổi struct mà chúng được gọi trên, vì vậy chúng ta cần thêm nhiều phép gán
let post = che khuất để lưu các thực thể trả về. Chúng ta cũng không thể có
các xác nhận về nội dung của bài đăng nháp và bài đăng đang chờ xem xét là các
chuỗi rỗng, và chúng ta cũng không cần chúng: chúng ta không thể biên dịch mã cố
gắng sử dụng nội dung của bài đăng ở những trạng thái đó nữa. Mã đã cập nhật
trong main được hiển thị trong Danh sách 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Các thay đổi chúng ta cần thực hiện đối với main để gán lại post có nghĩa là
việc triển khai này không hoàn toàn tuân theo mẫu trạng thái hướng đối tượng
nữa: các chuyển đổi giữa các trạng thái không còn được đóng gói hoàn toàn trong
triển khai Post. Tuy nhiên, lợi ích của chúng ta là các trạng thái không hợp
lệ hiện không thể xảy ra nhờ vào hệ thống kiểu và việc kiểm tra kiểu xảy ra tại
thời điểm biên dịch! Điều này đảm bảo rằng các lỗi nhất định, chẳng hạn như hiển
thị nội dung của một bài đăng chưa xuất bản, sẽ được phát hiện trước khi chúng
xuất hiện trong sản xuất.
Thử các nhiệm vụ được đề xuất ở đầu phần này trên crate blog như nó là sau
Danh sách 18-21 để xem bạn nghĩ gì về thiết kế của phiên bản mã này. Lưu ý rằng
một số nhiệm vụ có thể đã được hoàn thành trong thiết kế này.
Chúng ta đã thấy rằng mặc dù Rust có khả năng triển khai các mẫu thiết kế hướng đối tượng, các mẫu khác, chẳng hạn như mã hóa trạng thái vào hệ thống kiểu, cũng có sẵn trong Rust. Các mẫu này có các đánh đổi khác nhau. Mặc dù bạn có thể rất quen thuộc với các mẫu hướng đối tượng, việc suy nghĩ lại về vấn đề để tận dụng các tính năng của Rust có thể mang lại lợi ích, chẳng hạn như ngăn chặn một số lỗi tại thời điểm biên dịch. Các mẫu hướng đối tượng sẽ không phải lúc nào cũng là giải pháp tốt nhất trong Rust do một số tính năng nhất định, như quyền sở hữu, mà các ngôn ngữ hướng đối tượng không có.
Tóm tắt
Bất kể việc bạn có cho rằng Rust là một ngôn ngữ hướng đối tượng sau khi đọc chương này hay không, bây giờ bạn biết rằng bạn có thể sử dụng các đối tượng trait để có được một số tính năng hướng đối tượng trong Rust. Điều phối động có thể cung cấp cho mã của bạn một số tính linh hoạt để đổi lấy một chút hiệu suất thời gian chạy. Bạn có thể sử dụng tính linh hoạt này để triển khai các mẫu hướng đối tượng có thể giúp cải thiện khả năng bảo trì của mã. Rust cũng có các tính năng khác, như quyền sở hữu, mà các ngôn ngữ hướng đối tượng không có. Một mẫu hướng đối tượng sẽ không phải lúc nào cũng là cách tốt nhất để tận dụng các điểm mạnh của Rust, nhưng đó là một tùy chọn có sẵn.
Tiếp theo, chúng ta sẽ xem xét các mẫu, là một tính năng khác của Rust cho phép nhiều tính linh hoạt. Chúng ta đã xem xét chúng một cách ngắn gọn trong suốt cuốn sách nhưng chưa thấy được khả năng đầy đủ của chúng. Hãy tiếp tục!
Mẫu và Khớp mẫu
Mẫu (pattern) là một cú pháp đặc biệt trong Rust để so khớp với cấu trúc của
các kiểu dữ liệu, từ đơn giản đến phức tạp. Sử dụng mẫu kết hợp với biểu thức
match và các cấu trúc khác cung cấp cho bạn nhiều kiểm soát hơn đối với luồng
điều khiển chương trình. Một mẫu bao gồm một số kết hợp của các thành phần sau:
- Các giá trị nghĩa đen (Literals)
- Phân rã mảng, enum, struct, hoặc tuple
- Biến
- Ký tự đại diện (Wildcards)
- Vị trí giữ chỗ (Placeholders)
Một số ví dụ về mẫu bao gồm x, (a, 3), và Some(Color::Red). Trong các ngữ
cảnh mà mẫu có giá trị, những thành phần này mô tả hình dạng của dữ liệu. Chương
trình của chúng ta sau đó so khớp giá trị với mẫu để xác định liệu nó có đúng
hình dạng dữ liệu để tiếp tục chạy một phần mã cụ thể không.
Để sử dụng một mẫu, chúng ta so sánh nó với một giá trị nào đó. Nếu mẫu khớp với
giá trị, chúng ta sử dụng các phần của giá trị trong mã của mình. Hãy nhớ lại
biểu thức match trong Chương 6 đã sử dụng mẫu, chẳng hạn như ví dụ về máy phân
loại tiền xu. Nếu giá trị phù hợp với hình dạng của mẫu, chúng ta có thể sử dụng
các phần được đặt tên. Nếu nó không phù hợp, mã liên kết với mẫu sẽ không chạy.
Chương này là tài liệu tham khảo về tất cả các vấn đề liên quan đến mẫu. Chúng ta sẽ đề cập đến những nơi hợp lệ để sử dụng mẫu, sự khác biệt giữa mẫu có thể bác bỏ và không thể bác bỏ, và các loại cú pháp mẫu khác nhau mà bạn có thể thấy. Đến cuối chương, bạn sẽ biết cách sử dụng mẫu để biểu đạt nhiều khái niệm một cách rõ ràng.
Tất cả những nơi có thể sử dụng Mẫu
Mẫu xuất hiện ở nhiều nơi trong Rust, và bạn đã sử dụng chúng rất nhiều mà không nhận ra! Phần này sẽ thảo luận về tất cả những nơi mà mẫu có hiệu lực.
Các nhánh của match
Như đã thảo luận trong Chương 6, chúng ta sử dụng mẫu trong các nhánh của biểu
thức match. Chính thức thì, biểu thức match được định nghĩa bằng từ khóa
match, một giá trị để so khớp, và một hoặc nhiều nhánh khớp bao gồm một mẫu và
một biểu thức để chạy nếu giá trị khớp với mẫu của nhánh đó, như thế này:
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}Ví dụ, đây là biểu thức match từ Listing 6-5 khớp với một giá trị
Option<i32> trong biến x:
match x {
None => None,
Some(i) => Some(i + 1),
}Các mẫu trong biểu thức match này là None và Some(i) ở bên trái của mỗi
mũi tên.
Một yêu cầu đối với biểu thức match là chúng cần phải toàn diện theo nghĩa
là tất cả các khả năng cho giá trị trong biểu thức match phải được tính đến.
Một cách để đảm bảo bạn đã bao quát mọi khả năng là có một mẫu bao trùm tất cả
cho nhánh cuối cùng: ví dụ, một tên biến khớp với bất kỳ giá trị nào không bao
giờ thất bại và do đó bao gồm mọi trường hợp còn lại.
Mẫu đặc biệt _ sẽ khớp với bất cứ thứ gì, nhưng nó không bao giờ gắn kết với
một biến, vì vậy nó thường được sử dụng trong nhánh match cuối cùng. Mẫu _ có
thể hữu ích khi bạn muốn bỏ qua bất kỳ giá trị nào không được chỉ định, ví dụ.
Chúng ta sẽ đề cập đến mẫu _ chi tiết hơn trong "Bỏ qua các giá trị trong
Mẫu" sau trong chương này.
Câu lệnh let
Trước chương này, chúng ta chỉ thảo luận rõ ràng về việc sử dụng mẫu với match
và if let, nhưng trên thực tế, chúng ta đã sử dụng mẫu ở những nơi khác nữa,
bao gồm cả câu lệnh let. Ví dụ, hãy xem xét việc gán biến đơn giản này với
let:
#![allow(unused)] fn main() { let x = 5; }
Mỗi lần bạn sử dụng câu lệnh let như thế này, bạn đã sử dụng mẫu, mặc dù bạn
có thể không nhận ra điều đó! Chính thức hơn, câu lệnh let trông như thế này:
let PATTERN = EXPRESSION;
Trong các câu lệnh như let x = 5; với tên biến trong vị trí PATTERN, tên biến
chỉ là một dạng đặc biệt đơn giản của mẫu. Rust so sánh biểu thức với mẫu và gán
bất kỳ tên nào nó tìm thấy. Vì vậy, trong ví dụ let x = 5;, x là một mẫu có
nghĩa là "gán cái gì khớp ở đây vào biến x." Bởi vì tên x là toàn bộ mẫu,
mẫu này về cơ bản có nghĩa là "gán mọi thứ vào biến x, bất kể giá trị là gì."
Để thấy rõ hơn khía cạnh khớp mẫu của let, hãy xem xét Listing 19-1, sử dụng
một mẫu với let để phân rã một tuple.
fn main() { let (x, y, z) = (1, 2, 3); }
Ở đây, chúng ta khớp một tuple với một mẫu. Rust so sánh giá trị (1, 2, 3) với
mẫu (x, y, z) và thấy rằng giá trị khớp với mẫu, ở chỗ số lượng phần tử là
giống nhau trong cả hai, nên Rust gắn 1 với x, 2 với y, và 3 với z.
Bạn có thể xem mẫu tuple này như là lồng ba mẫu biến cá nhân bên trong nó.
Nếu số lượng phần tử trong mẫu không khớp với số lượng phần tử trong tuple, kiểu tổng thể sẽ không khớp và chúng ta sẽ gặp lỗi trình biên dịch. Ví dụ, Listing 19-2 cho thấy một nỗ lực phân rã một tuple với ba phần tử thành hai biến, điều này sẽ không hoạt động.
fn main() {
let (x, y) = (1, 2, 3);
}Cố gắng biên dịch mã này dẫn đến lỗi kiểu này:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Để sửa lỗi, chúng ta có thể bỏ qua một hoặc nhiều giá trị trong tuple bằng cách
sử dụng _ hoặc .., như bạn sẽ thấy trong phần "Bỏ qua các giá trị trong
Mẫu". Nếu vấn đề là chúng ta có
quá nhiều biến trong mẫu, giải pháp là làm cho các kiểu khớp bằng cách loại bỏ
các biến để số lượng biến bằng với số lượng phần tử trong tuple.
Biểu thức điều kiện if let
Trong Chương 6, chúng ta đã thảo luận về cách sử dụng biểu thức if let chủ yếu
như một cách ngắn hơn để viết tương đương với một match chỉ khớp một trường
hợp. Tùy chọn, if let có thể có một else tương ứng chứa mã để chạy nếu mẫu
trong if let không khớp.
Listing 19-1 cho thấy rằng cũng có thể kết hợp if let, else if, và
else if let. Làm như vậy giúp chúng ta linh hoạt hơn so với biểu thức match
mà chúng ta chỉ có thể biểu thị một giá trị để so sánh với các mẫu. Ngoài ra,
Rust không yêu cầu các điều kiện trong một chuỗi if let, else if,
else if let phải liên quan đến nhau.
Mã trong Listing 19-1 xác định màu nền dựa trên một loạt các kiểm tra cho một số điều kiện. Đối với ví dụ này, chúng tôi đã tạo các biến với giá trị cứng mà một chương trình thực sự có thể nhận từ người dùng đầu vào.
fn main() { // ANCHOR: here let (x, y, z) = (1, 2, 3); // ANCHOR_END: here }
Nếu người dùng chỉ định một màu yêu thích, màu đó được sử dụng làm nền. Nếu không có màu yêu thích nào được chỉ định và hôm nay là thứ Ba, màu nền là xanh lá cây. Nếu không, nếu người dùng chỉ định tuổi của họ dưới dạng chuỗi và chúng ta có thể phân tích nó thành một số thành công, màu sắc sẽ là tím hoặc cam tùy thuộc vào giá trị của số đó. Nếu không có điều kiện nào áp dụng, màu nền là xanh dương.
Cấu trúc điều kiện này cho phép chúng ta hỗ trợ các yêu cầu phức tạp. Với các
giá trị cứng mà chúng ta có ở đây, ví dụ này sẽ in ra
Using purple as the background color.
Bạn có thể thấy rằng if let cũng có thể giới thiệu các biến mới che khuất các
biến hiện có theo cách tương tự như các nhánh match: dòng
if let Ok(age) = age giới thiệu một biến age mới chứa giá trị bên trong biến
thể Ok, che khuất biến age hiện có. Điều này có nghĩa là chúng ta cần đặt
điều kiện if age > 30 trong khối đó: chúng ta không thể kết hợp hai điều kiện
này thành if let Ok(age) = age && age > 30. Biến age mới mà chúng ta muốn so
sánh với 30 không hợp lệ cho đến khi phạm vi mới bắt đầu với dấu ngoặc nhọn.
Nhược điểm của việc sử dụng biểu thức if let là trình biên dịch không kiểm tra
tính toàn diện, trong khi với biểu thức match thì có. Nếu chúng ta bỏ qua khối
else cuối cùng và do đó bỏ lỡ việc xử lý một số trường hợp, trình biên dịch sẽ
không cảnh báo chúng ta về lỗi logic có thể xảy ra.
Vòng lặp điều kiện while let
Tương tự như cấu trúc if let, vòng lặp điều kiện while let cho phép vòng lặp
while chạy miễn là một mẫu tiếp tục khớp. Trong Listing 19-3 chúng ta thấy một
vòng lặp while let đợi các tin nhắn được gửi giữa các luồng, nhưng trong
trường hợp này kiểm tra một Result thay vì một Option.
fn main() { let (x, y) = (1, 2, 3); }
Ví dụ này in ra 1, 2, và sau đó 3. Phương thức recv lấy tin nhắn đầu
tiên từ phía nhận của kênh và trả về Ok(value). Khi chúng ta lần đầu tiên thấy
recv trở lại trong Chương 16, chúng ta đã unwrap lỗi trực tiếp, hoặc tương tác
với nó như một iterator sử dụng vòng lặp for. Như Listing 19-2 cho thấy, tuy
nhiên, chúng ta cũng có thể sử dụng while let, vì phương thức recv trả về
Ok mỗi lần một tin nhắn đến, miễn là người gửi tồn tại, và sau đó tạo ra một
Err khi phía người gửi ngắt kết nối.
Vòng lặp for
Trong vòng lặp for, giá trị theo sau từ khóa for là một mẫu. Ví dụ, trong
for x in y, x là mẫu. Listing 19-4 minh họa cách sử dụng mẫu trong vòng lặp
for để phân rã, hoặc chia nhỏ, một tuple như một phần của vòng lặp for.
fn main() { let favorite_color: Option<&str> = None; let is_tuesday = false; let age: Result<u8, _> = "34".parse(); if let Some(color) = favorite_color { println!("Using your favorite color, {color}, as the background"); } else if is_tuesday { println!("Tuesday is green day!"); } else if let Ok(age) = age { if age > 30 { println!("Using purple as the background color"); } else { println!("Using orange as the background color"); } } else { println!("Using blue as the background color"); } }
Mã trong Listing 19-4 sẽ in ra như sau:
0: a
1: b
2: c
Chúng ta điều chỉnh một iterator bằng phương thức enumerate để nó tạo ra một
giá trị và chỉ số cho giá trị đó, đặt vào một tuple. Giá trị đầu tiên được tạo
ra là tuple (0, 'a'). Khi giá trị này được khớp với mẫu (index, value),
index sẽ là 0 và value sẽ là 'a', in ra dòng đầu tiên của đầu ra.
Tham số hàm
Tham số hàm cũng có thể là mẫu. Mã trong Listing 19-5, khai báo một hàm tên
foo nhận một tham số tên x kiểu i32, giờ đây có lẽ đã trông quen thuộc.
fn foo(x: i32) { // code goes here } fn main() {}
Phần x là một mẫu! Giống như với let, chúng ta có thể khớp một tuple trong
đối số của một hàm với mẫu. Listing 19-6 chia các giá trị trong một tuple khi
chúng ta truyền nó vào một hàm.
fn print_coordinates(&(x, y): &(i32, i32)) { println!("Current location: ({x}, {y})"); } fn main() { let point = (3, 5); print_coordinates(&point); }
Mã này in ra Current location: (3, 5). Các giá trị &(3, 5) khớp với mẫu
&(x, y), vì vậy x là giá trị 3 và y là giá trị 5.
Chúng ta cũng có thể sử dụng mẫu trong danh sách tham số closure giống như trong danh sách tham số hàm vì closure tương tự như hàm, như đã thảo luận trong Chương 13.
Ở thời điểm này, bạn đã thấy một số cách sử dụng mẫu, nhưng mẫu không hoạt động giống nhau ở mọi nơi chúng ta có thể sử dụng chúng. Ở một số nơi, các mẫu phải không thể bác bỏ; trong các trường hợp khác, chúng có thể bị bác bỏ. Chúng ta sẽ thảo luận về hai khái niệm này tiếp theo.
Tính bác bỏ: Liệu một Mẫu Có Thể Không Khớp
Các mẫu có hai dạng: bác bỏ được (refutable) và không bác bỏ được (irrefutable).
Các mẫu sẽ khớp với bất kỳ giá trị có thể nào được truyền vào được gọi là không
bác bỏ được. Một ví dụ là x trong câu lệnh let x = 5; bởi vì x khớp với
bất cứ thứ gì và do đó không thể thất bại khi khớp. Các mẫu có thể không khớp
với một số giá trị có thể có được gọi là bác bỏ được. Một ví dụ là Some(x)
trong biểu thức if let Some(x) = a_value bởi vì nếu giá trị trong biến
a_value là None thay vì Some, thì mẫu Some(x) sẽ không khớp.
Tham số hàm, câu lệnh let, và vòng lặp for chỉ có thể chấp nhận các mẫu
không bác bỏ được bởi vì chương trình không thể làm bất cứ điều gì có ý nghĩa
khi giá trị không khớp. Các biểu thức if let và while let và câu lệnh
let...else chấp nhận cả mẫu bác bỏ được và không bác bỏ được, nhưng trình biên
dịch cảnh báo đối với các mẫu không bác bỏ được bởi vì, theo định nghĩa, chúng
được dùng để xử lý khả năng thất bại: chức năng của một điều kiện nằm ở khả năng
thực hiện khác nhau tùy thuộc vào thành công hay thất bại.
Nhìn chung, bạn không nên phải lo lắng về sự khác biệt giữa các mẫu bác bỏ được và không bác bỏ được; tuy nhiên, bạn cần phải làm quen với khái niệm tính bác bỏ để có thể phản ứng khi bạn thấy nó trong thông báo lỗi. Trong những trường hợp đó, bạn sẽ cần thay đổi hoặc mẫu hoặc cấu trúc mà bạn đang sử dụng với mẫu, tùy thuộc vào hành vi dự định của mã.
Hãy xem một ví dụ về điều gì xảy ra khi chúng ta cố gắng sử dụng một mẫu bác bỏ
được trong khi Rust yêu cầu một mẫu không bác bỏ được và ngược lại. Listing 19-8
cho thấy một câu lệnh let, nhưng đối với mẫu, chúng ta đã chỉ định Some(x),
một mẫu bác bỏ được. Như bạn có thể mong đợi, mã này sẽ không biên dịch.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}Nếu some_option_value là một giá trị None, nó sẽ không khớp với mẫu
Some(x), có nghĩa là mẫu là bác bỏ được. Tuy nhiên, câu lệnh let chỉ có thể
chấp nhận một mẫu không bác bỏ được vì không có điều gì hợp lệ mà mã có thể làm
với một giá trị None. Tại thời điểm biên dịch, Rust sẽ phàn nàn rằng chúng ta
đã cố gắng sử dụng một mẫu bác bỏ được ở nơi yêu cầu một mẫu không bác bỏ được:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Bởi vì chúng ta không bao quát (và không thể bao quát!) mọi giá trị hợp lệ với
mẫu Some(x), Rust đúng đắn tạo ra một lỗi biên dịch.
Nếu chúng ta có một mẫu bác bỏ được ở nơi cần một mẫu không bác bỏ được, chúng
ta có thể sửa nó bằng cách thay đổi mã sử dụng mẫu: thay vì sử dụng let, chúng
ta có thể sử dụng let...else. Sau đó, nếu mẫu không khớp, mã trong ngoặc nhọn sẽ
xử lý giá trị. Listing 19-9 cho thấy cách sửa mã trong Listing 19-8.
fn main() { let some_option_value: Option<i32> = None; let Some(x) = some_option_value else { return; }; }
Chúng ta đã cho mã một lối thoát! Mã này bây giờ hoàn toàn hợp lệ, mặc dù điều
này có nghĩa là chúng ta không thể sử dụng mẫu không bác bỏ được mà không nhận
được cảnh báo. Nếu chúng ta cung cấp cho let...else một mẫu sẽ luôn khớp,
chẳng hạn như x, như được hiển thị trong Listing 19-10, trình biên dịch sẽ đưa
ra cảnh báo.
fn main() { let x = 5 else { return; }; }
Rust phàn nàn rằng việc sử dụng let...else với một mẫu không bác bỏ được là
không hợp lý:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
Vì lý do này, các nhánh của match phải sử dụng các mẫu bác bỏ được, ngoại trừ
nhánh cuối cùng, nên khớp với bất kỳ giá trị còn lại nào bằng một mẫu không bác
bỏ được. Rust cho phép chúng ta sử dụng một mẫu không bác bỏ được trong một
match với chỉ một nhánh, nhưng cú pháp này không đặc biệt hữu ích và có thể
được thay thế bằng một câu lệnh let đơn giản hơn.
Bây giờ bạn đã biết nơi sử dụng các mẫu và sự khác biệt giữa các mẫu bác bỏ được và không bác bỏ được, hãy cùng xem tất cả các cú pháp mà chúng ta có thể sử dụng để tạo mẫu.
Cú Pháp Mẫu
Trong phần này, chúng ta tập hợp tất cả các syntax hợp lệ trong các mẫu và thảo luận về lý do và thời điểm bạn có thể muốn sử dụng mỗi syntax.
Khớp với Giá Trị Cụ Thể
Như bạn đã thấy trong Chương 6, bạn có thể khớp các mẫu trực tiếp với các giá trị cụ thể. Đoạn mã sau đây đưa ra một số ví dụ:
fn main() { let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } }
Đoạn mã này in ra one vì giá trị trong x là 1. Cú pháp này hữu ích khi bạn
muốn mã của mình thực hiện một hành động nếu nó nhận được một giá trị cụ thể.
Khớp với Biến Có Tên
Các biến có tên là các mẫu không thể bác bỏ (irrefutable) khớp với bất kỳ giá
trị nào, và chúng ta đã sử dụng chúng nhiều lần trong cuốn sách này. Tuy nhiên,
có một phức tạp khi bạn sử dụng các biến có tên trong expression match,
if let hoặc while let. Bởi vì mỗi loại expression này bắt đầu một phạm vi
mới, các biến được khai báo như một phần của mẫu bên trong expression sẽ che
khuất (shadow) các biến có cùng tên bên ngoài, như trường hợp với tất cả các
biến. Trong Listing 19-11, chúng ta khai báo một biến có tên x với giá trị
Some(5) và một biến y với giá trị 10. Sau đó, chúng ta tạo một expression
match dựa trên giá trị x. Hãy nhìn vào các mẫu trong các arm của match và
println! ở cuối, và thử tìm hiểu xem đoạn mã sẽ in ra gì trước khi chạy mã này
hoặc đọc tiếp.
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {y}"), _ => println!("Default case, x = {x:?}"), } println!("at the end: x = {x:?}, y = {y}"); }
Hãy cùng xem xét những gì xảy ra khi biểu thức match chạy. Mẫu trong arm match
đầu tiên không khớp với giá trị đã định nghĩa của x, vì vậy mã tiếp tục.
Mẫu trong arm match thứ hai giới thiệu một biến mới có tên y sẽ khớp với bất
kỳ giá trị nào bên trong một giá trị Some. Vì chúng ta đang ở trong một phạm
vi mới bên trong biểu thức match, đây là một biến y mới, không phải biến y
mà chúng ta đã khai báo ở đầu với giá trị 10. Ràng buộc y mới này sẽ khớp
với bất kỳ giá trị nào bên trong một Some, đó chính là những gì chúng ta có
trong x. Do đó, y mới này ràng buộc với giá trị bên trong của Some trong
x. Giá trị đó là 5, vì vậy biểu thức cho arm đó thực thi và in ra
Matched, y = 5.
Nếu x đã là giá trị None thay vì Some(5), thì các mẫu trong hai arm đầu
tiên sẽ không khớp, vì vậy giá trị sẽ khớp với dấu gạch dưới. Chúng ta không
giới thiệu biến x trong mẫu của arm dấu gạch dưới, vì vậy x trong biểu thức
vẫn là x bên ngoài chưa bị che khuất. Trong trường hợp giả định này, phép
match sẽ in ra Default case, x = None.
Khi biểu thức match kết thúc, phạm vi của nó cũng kết thúc, và phạm vi của y
bên trong cũng vậy. println! cuối cùng tạo ra
at the end: x = Some(5), y = 10.
Để tạo một biểu thức match so sánh giá trị của x và y bên ngoài, thay vì
giới thiệu một biến mới che khuất biến y hiện có, chúng ta cần sử dụng một
điều kiện bảo vệ match (match guard) thay thế. Chúng ta sẽ nói về match guard
sau trong phần
"Điều Kiện Bổ Sung với Match Guards".
Nhiều Mẫu
Bạn có thể khớp nhiều mẫu bằng cách sử dụng cú pháp |, đó là toán tử hoặc
trong mẫu. Ví dụ, trong đoạn mã sau, chúng ta so khớp giá trị của x với các
arm match, arm đầu tiên có một tùy chọn hoặc, có nghĩa là nếu giá trị của x
khớp với bất kỳ giá trị nào trong arm đó, thì mã của arm đó sẽ chạy:
fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
Đoạn mã này in ra one or two.
Khớp với Phạm Vi Giá Trị bằng ..=
Cú pháp ..= cho phép chúng ta khớp với một phạm vi giá trị bao gồm
(inclusive). Trong đoạn mã sau, khi một mẫu khớp với bất kỳ giá trị nào trong
phạm vi đã cho, arm đó sẽ thực thi:
fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
Nếu x là 1, 2, 3, 4, hoặc 5, arm đầu tiên sẽ khớp. Cú pháp này thuận
tiện hơn cho nhiều giá trị khớp so với việc sử dụng toán tử | để biểu thị cùng
một ý tưởng; nếu chúng ta sử dụng |, chúng ta sẽ phải chỉ định
1 | 2 | 3 | 4 | 5. Việc chỉ định một phạm vi ngắn gọn hơn nhiều, đặc biệt là
nếu chúng ta muốn khớp, chẳng hạn, bất kỳ số nào từ 1 đến 1.000!
Trình biên dịch kiểm tra xem phạm vi có trống không tại thời điểm biên dịch, và
vì các loại duy nhất mà Rust có thể xác định xem một phạm vi có trống hay không
là các giá trị char và số, nên các phạm vi chỉ được phép với các giá trị số
hoặc char.
Đây là một ví dụ sử dụng phạm vi của các giá trị char:
fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust có thể biết rằng 'c' nằm trong phạm vi của mẫu đầu tiên và in ra
early ASCII letter.
Phá Vỡ để Tách Các Giá Trị
Chúng ta cũng có thể sử dụng các mẫu để phá vỡ các structs, enums và tuples để sử dụng các phần khác nhau của các giá trị này. Hãy cùng xem xét từng giá trị.
Phá Vỡ Structs
Listing 19-12 cho thấy một struct Point với hai trường, x và y, mà chúng
ta có thể tách ra bằng cách sử dụng một mẫu với một câu lệnh let.
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
Đoạn mã này tạo ra các biến a và b khớp với các giá trị của các trường x
và y của struct p. Ví dụ này cho thấy rằng tên của các biến trong mẫu không
cần phải khớp với tên của các trường của struct. Tuy nhiên, thông thường người
ta đặt tên biến trùng với tên trường để dễ nhớ biến nào đến từ trường nào. Vì
cách sử dụng phổ biến này, và vì việc viết let Point { x: x, y: y } = p; chứa
nhiều sự lặp lại, Rust có một cách viết ngắn gọn cho các mẫu khớp với các trường
struct: bạn chỉ cần liệt kê tên của trường struct, và các biến được tạo từ mẫu
sẽ có cùng tên. Listing 19-13 hoạt động giống như đoạn mã trong Listing 19-12,
nhưng các biến được tạo trong mẫu let là x và y thay vì a và b.
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
Đoạn mã này tạo ra các biến x và y khớp với các trường x và y của biến
p. Kết quả là các biến x và y chứa các giá trị từ struct p.
Chúng ta cũng có thể phá vỡ với các giá trị cụ thể như một phần của mẫu struct thay vì tạo các biến cho tất cả các trường. Làm như vậy cho phép chúng ta kiểm tra một số trường cho các giá trị cụ thể trong khi tạo các biến để phá vỡ các trường khác.
Trong Listing 19-14, chúng ta có một biểu thức match phân tách các giá trị
Point thành ba trường hợp: các điểm nằm trực tiếp trên trục x (điều này đúng
khi y = 0), trên trục y (x = 0), hoặc không nằm trên trục nào.
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => { println!("On neither axis: ({x}, {y})"); } } }
Arm đầu tiên sẽ khớp với bất kỳ điểm nào nằm trên trục x bằng cách chỉ định
rằng trường y khớp nếu giá trị của nó khớp với giá trị cụ thể 0. Mẫu vẫn tạo
ra một biến x mà chúng ta có thể sử dụng trong mã cho arm này.
Tương tự, arm thứ hai khớp với bất kỳ điểm nào trên trục y bằng cách chỉ định
rằng trường x khớp nếu giá trị của nó là 0 và tạo ra một biến y cho giá
trị của trường y. Arm thứ ba không chỉ định bất kỳ giá trị cụ thể nào, vì vậy
nó khớp với bất kỳ Point nào khác và tạo ra các biến cho cả trường x và y.
Trong ví dụ này, giá trị p khớp với arm thứ hai bởi vì x chứa một 0, vì
vậy đoạn mã này sẽ in ra On the y axis at 7.
Hãy nhớ rằng biểu thức match dừng kiểm tra các arm ngay khi nó tìm thấy mẫu
khớp đầu tiên, vì vậy mặc dù Point { x: 0, y: 0 } nằm trên cả trục x và trục
y, đoạn mã này sẽ chỉ in ra On the x axis at 0.
Phá Vỡ Enums
Chúng ta đã phá vỡ enums trong cuốn sách này (ví dụ, Listing 6-5), nhưng chúng
ta chưa thảo luận rõ ràng rằng mẫu để phá vỡ một enum tương ứng với cách dữ liệu
được lưu trữ trong enum được định nghĩa. Ví dụ, trong Listing 19-15 chúng ta sử
dụng enum Message từ Listing 6-2 và viết một match với các mẫu sẽ phá vỡ
từng giá trị bên trong.
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure."); } Message::Move { x, y } => { println!("Move in the x direction {x} and in the y direction {y}"); } Message::Write(text) => { println!("Text message: {text}"); } Message::ChangeColor(r, g, b) => { println!("Change color to red {r}, green {g}, and blue {b}"); } } }
Đoạn mã này sẽ in ra Change color to red 0, green 160, and blue 255. Hãy thử
thay đổi giá trị của msg để xem mã từ các arm khác chạy.
Đối với các biến thể enum không có dữ liệu, như Message::Quit, chúng ta không
thể phá vỡ giá trị thêm nữa. Chúng ta chỉ có thể khớp với giá trị cụ thể
Message::Quit, và không có biến nào trong mẫu đó.
Đối với các biến thể enum giống struct, như Message::Move, chúng ta có thể sử
dụng một mẫu tương tự như mẫu chúng ta chỉ định để khớp với các struct. Sau tên
biến thể, chúng ta đặt dấu ngoặc nhọn và sau đó liệt kê các trường với các biến
để chúng ta tách các phần ra để sử dụng trong mã cho arm này. Ở đây chúng ta sử
dụng dạng ngắn gọn như chúng ta đã làm trong Listing 19-13.
Đối với các biến thể enum giống tuple, như Message::Write chứa một tuple với
một phần tử và Message::ChangeColor chứa một tuple với ba phần tử, mẫu tương
tự như mẫu chúng ta chỉ định để khớp với các tuple. Số lượng biến trong mẫu phải
khớp với số lượng phần tử trong biến thể mà chúng ta đang khớp.
Phá Vỡ Các Structs và Enums Lồng Nhau
Cho đến nay, các ví dụ của chúng ta đều khớp với các struct hoặc enum một cấp độ
sâu, nhưng việc khớp cũng có thể hoạt động trên các mục lồng nhau! Ví dụ, chúng
ta có thể tái cấu trúc mã trong Listing 19-15 để hỗ trợ các màu RGB và HSV trong
thông điệp ChangeColor, như được hiển thị trong Listing 19-16.
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!("Change color to red {r}, green {g}, and blue {b}"); } Message::ChangeColor(Color::Hsv(h, s, v)) => { println!("Change color to hue {h}, saturation {s}, value {v}"); } _ => (), } }
Mẫu của arm đầu tiên trong biểu thức match khớp với một biến thể enum
Message::ChangeColor chứa một biến thể Color::Rgb; sau đó mẫu ràng buộc với
ba giá trị i32 bên trong. Mẫu của arm thứ hai cũng khớp với một biến thể enum
Message::ChangeColor, nhưng enum bên trong khớp với Color::Hsv thay thế.
Chúng ta có thể chỉ định các điều kiện phức tạp này trong một biểu thức match,
ngay cả khi hai enum có liên quan.
Phá Vỡ Structs và Tuples
Chúng ta có thể kết hợp, khớp, và lồng các mẫu phá vỡ theo những cách phức tạp hơn. Ví dụ sau đây cho thấy một phép phá vỡ phức tạp trong đó chúng ta lồng các struct và tuple bên trong một tuple và phá vỡ tất cả các giá trị nguyên thủy:
fn main() { struct Point { x: i32, y: i32, } let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 }); }
Đoạn mã này cho phép chúng ta phá vỡ các loại phức tạp thành các thành phần của chúng để chúng ta có thể sử dụng riêng biệt các giá trị mà chúng ta quan tâm.
Phá vỡ với các mẫu là một cách thuận tiện để sử dụng các phần của giá trị, chẳng hạn như giá trị từ mỗi trường trong một struct, tách biệt với nhau.
Bỏ Qua Giá Trị trong Mẫu
Đôi khi việc bỏ qua các giá trị trong một mẫu rất hữu ích, chẳng hạn như trong
arm cuối cùng của match, để có một catchall không thực sự làm gì nhưng tính
đến tất cả các giá trị còn lại có thể có. Có một vài cách để bỏ qua toàn bộ giá
trị hoặc các phần của giá trị trong một mẫu: sử dụng mẫu _ (mà bạn đã thấy),
sử dụng mẫu _ trong một mẫu khác, sử dụng một tên bắt đầu bằng dấu gạch dưới,
hoặc sử dụng .. để bỏ qua các phần còn lại của một giá trị. Hãy khám phá cách
và lý do sử dụng từng mẫu này.
Toàn Bộ Giá Trị với _
Chúng ta đã sử dụng dấu gạch dưới làm mẫu đại diện (wildcard) sẽ khớp với bất kỳ
giá trị nào nhưng không ràng buộc với giá trị. Điều này đặc biệt hữu ích làm arm
cuối cùng trong biểu thức match, nhưng chúng ta cũng có thể sử dụng nó trong
bất kỳ mẫu nào, bao gồm cả tham số hàm, như được hiển thị trong Listing 19-17.
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {y}"); } fn main() { foo(3, 4); }
Đoạn mã này sẽ hoàn toàn bỏ qua giá trị 3 được truyền làm đối số đầu tiên và
sẽ in ra This code only uses the y parameter: 4.
Trong hầu hết các trường hợp khi bạn không còn cần một tham số hàm cụ thể nào đó, bạn sẽ thay đổi chữ ký sao cho nó không bao gồm tham số không sử dụng. Việc bỏ qua một tham số hàm có thể đặc biệt hữu ích trong trường hợp, ví dụ, bạn đang triển khai một trait khi bạn cần một chữ ký loại nhất định nhưng thân hàm trong triển khai của bạn không cần một trong các tham số. Khi đó bạn tránh được cảnh báo của trình biên dịch về các tham số hàm không sử dụng, như bạn sẽ gặp nếu bạn sử dụng một tên thay thế.
Các Phần của Giá Trị với _ Lồng Nhau
Chúng ta cũng có thể sử dụng _ bên trong một mẫu khác để bỏ qua chỉ một phần
của một giá trị, ví dụ, khi chúng ta muốn kiểm tra chỉ một phần của một giá trị
nhưng không sử dụng các phần khác trong mã tương ứng mà chúng ta muốn chạy.
Listing 19-18 hiển thị mã chịu trách nhiệm quản lý giá trị của một cài đặt. Yêu
cầu kinh doanh là người dùng không được phép ghi đè một tùy chỉnh hiện có của
cài đặt, nhưng có thể bỏ cài đặt và cung cấp giá trị cho nó nếu hiện tại nó chưa
được đặt.
fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {setting_value:?}"); }
Đoạn mã này sẽ in ra Can't overwrite an existing customized value và sau đó là
setting is Some(5). Trong arm match đầu tiên, chúng ta không cần phải khớp
hoặc sử dụng các giá trị bên trong cả hai biến thể Some, nhưng chúng ta cần
kiểm tra trường hợp khi setting_value và new_setting_value là biến thể
Some. Trong trường hợp đó, chúng ta in ra lý do không thay đổi
setting_value, và nó không bị thay đổi.
Trong tất cả các trường hợp khác (nếu setting_value hoặc new_setting_value
là None) được biểu thị bởi mẫu _ trong arm thứ hai, chúng ta muốn cho phép
new_setting_value trở thành setting_value.
Chúng ta cũng có thể sử dụng dấu gạch dưới ở nhiều vị trí trong một mẫu để bỏ qua các giá trị cụ thể. Listing 19-19 cho thấy một ví dụ về việc bỏ qua giá trị thứ hai và thứ tư trong một tuple gồm năm mục.
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {first}, {third}, {fifth}"); } } }
Đoạn mã này sẽ in ra Some numbers: 2, 8, 32, và các giá trị 4 và 16 sẽ bị
bỏ qua.
Một Biến Không Sử Dụng bằng Cách Bắt Đầu Tên Của Nó với _
Nếu bạn tạo một biến nhưng không sử dụng nó ở bất kỳ đâu, Rust thường sẽ đưa ra cảnh báo vì một biến không sử dụng có thể là một lỗi. Tuy nhiên, đôi khi việc tạo một biến mà bạn sẽ không sử dụng ngay là hữu ích, chẳng hạn như khi bạn đang tạo nguyên mẫu hoặc chỉ mới bắt đầu một dự án. Trong tình huống này, bạn có thể bảo Rust không cảnh báo bạn về biến không sử dụng bằng cách bắt đầu tên của biến bằng dấu gạch dưới. Trong Listing 19-20, chúng ta tạo hai biến không sử dụng, nhưng khi chúng ta biên dịch mã này, chúng ta chỉ nhận được cảnh báo về một trong số chúng.
fn main() { let _x = 5; let y = 10; }
Ở đây, chúng ta nhận được cảnh báo về việc không sử dụng biến y, nhưng chúng
ta không nhận được cảnh báo về việc không sử dụng _x.
Lưu ý rằng có sự khác biệt tinh tế giữa việc chỉ sử dụng _ và sử dụng một tên
bắt đầu bằng dấu gạch dưới. Cú pháp _x vẫn ràng buộc giá trị với biến, trong
khi _ hoàn toàn không ràng buộc. Để hiển thị một trường hợp mà sự khác biệt
này quan trọng, Listing 19-21 sẽ cung cấp cho chúng ta một lỗi.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}Chúng ta sẽ nhận được lỗi vì giá trị s vẫn sẽ được chuyển vào _s, điều này
ngăn chúng ta sử dụng lại s. Tuy nhiên, việc sử dụng dấu gạch dưới một mình
không bao giờ ràng buộc với giá trị. Listing 19-22 sẽ biên dịch mà không có bất
kỳ lỗi nào vì s không bị chuyển vào _.
fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{s:?}"); }
Đoạn mã này hoạt động tốt vì chúng ta không bao giờ ràng buộc s với bất cứ thứ
gì; nó không bị chuyển đi.
Các Phần Còn Lại của Giá Trị với ..
Với các giá trị có nhiều phần, chúng ta có thể sử dụng cú pháp .. để sử dụng
các phần cụ thể và bỏ qua phần còn lại, tránh cần liệt kê dấu gạch dưới cho mỗi
giá trị bị bỏ qua. Mẫu .. bỏ qua bất kỳ phần nào của giá trị mà chúng ta chưa
khớp rõ ràng trong phần còn lại của mẫu. Trong Listing 19-23, chúng ta có một
struct Point lưu trữ một tọa độ trong không gian ba chiều. Trong biểu thức
match, chúng ta chỉ muốn hoạt động trên tọa độ x và bỏ qua các giá trị trong
các trường y và z.
fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {x}"), } }
Chúng ta liệt kê giá trị x và sau đó chỉ bao gồm mẫu ... Điều này nhanh hơn
việc phải liệt kê y: _ và z: _, đặc biệt là khi chúng ta làm việc với các
struct có nhiều trường trong tình huống chỉ một hoặc hai trường là liên quan.
Cú pháp .. sẽ mở rộng tới nhiều giá trị khi cần thiết. Listing 19-24 cho thấy
cách sử dụng .. với một tuple.
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {first}, {last}"); } } }
Trong đoạn mã này, giá trị đầu tiên và cuối cùng được khớp với first và
last. .. sẽ khớp và bỏ qua mọi thứ ở giữa.
Tuy nhiên, việc sử dụng .. phải rõ ràng không mơ hồ. Nếu không rõ ràng giá trị
nào dùng để khớp và giá trị nào nên bị bỏ qua, Rust sẽ đưa ra lỗi cho chúng ta.
Listing 19-25 hiển thị một ví dụ về việc sử dụng .. một cách mơ hồ, vì vậy nó
sẽ không biên dịch.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}Khi chúng ta biên dịch ví dụ này, chúng ta nhận được lỗi này:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Không thể nào để Rust xác định được có bao nhiêu giá trị trong tuple cần bỏ qua
trước khi khớp một giá trị với second và sau đó còn bao nhiêu giá trị nữa cần
bỏ qua sau đó. Đoạn mã này có thể có nghĩa là chúng ta muốn bỏ qua 2, ràng
buộc second với 4, rồi bỏ qua 8, 16 và 32; hoặc rằng chúng ta muốn bỏ
qua 2 và 4, ràng buộc second với 8, rồi bỏ qua 16 và 32; và vân vân.
Tên biến second không có ý nghĩa đặc biệt gì đối với Rust, vì vậy chúng ta
nhận được lỗi biên dịch vì việc sử dụng .. ở hai nơi như thế này là mơ hồ.
Điều Kiện Bổ Sung với Match Guards
Match guard là một điều kiện if bổ sung, được chỉ định sau mẫu trong một arm
match, cũng phải khớp để arm đó được chọn. Match guard hữu ích để biểu thị các ý
tưởng phức tạp hơn những gì chỉ riêng một mẫu cho phép. Tuy nhiên, lưu ý rằng
chúng chỉ có sẵn trong biểu thức match, không có trong biểu thức if let hoặc
while let.
Điều kiện có thể sử dụng các biến được tạo trong mẫu. Listing 19-26 hiển thị một
match trong đó arm đầu tiên có mẫu Some(x) và cũng có một match guard là
if x % 2 == 0 (sẽ là true nếu số là chẵn).
fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("The number {x} is even"), Some(x) => println!("The number {x} is odd"), None => (), } }
Ví dụ này sẽ in ra The number 4 is even. Khi num được so sánh với mẫu trong
arm đầu tiên, nó khớp vì Some(4) khớp với Some(x). Sau đó match guard kiểm
tra xem phần dư của việc chia x cho 2 có bằng 0 không, và vì vậy, arm đầu tiên
được chọn.
Nếu num đã là Some(5) thay vào đó, match guard trong arm đầu tiên sẽ là
false vì phần dư của 5 chia cho 2 là 1, không bằng 0. Rust sau đó sẽ đi đến
arm thứ hai, match do arm thứ hai không có match guard và do đó khớp với bất kỳ
biến thể Some nào.
Không có cách nào để biểu thị điều kiện if x % 2 == 0 trong một mẫu, vì vậy
match guard cho chúng ta khả năng biểu thị logic này. Nhược điểm của tính biểu
đạt bổ sung này là trình biên dịch không cố gắng kiểm tra tính đầy đủ khi các
biểu thức match guard có liên quan.
Trong Listing 19-11, chúng ta đã đề cập rằng chúng ta có thể sử dụng match guard
để giải quyết vấn đề che khuất (shadowing) mẫu. Hãy nhớ rằng chúng ta đã tạo một
biến mới bên trong mẫu trong biểu thức match thay vì sử dụng biến bên ngoài
match. Biến mới đó có nghĩa là chúng ta không thể kiểm tra giá trị của biến
bên ngoài. Listing 19-27 cho thấy cách chúng ta có thể sử dụng match guard để
sửa lỗi này.
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {n}"), _ => println!("Default case, x = {x:?}"), } println!("at the end: x = {x:?}, y = {y}"); }
Đoạn mã này sẽ in ra Default case, x = Some(5). Mẫu trong arm match thứ hai
không giới thiệu một biến mới y sẽ che khuất biến y bên ngoài, có nghĩa là
chúng ta có thể sử dụng y bên ngoài trong match guard. Thay vì chỉ định mẫu là
Some(y), sẽ che khuất y bên ngoài, chúng ta chỉ định Some(n). Điều này tạo
ra một biến mới n không che khuất bất cứ thứ gì vì không có biến n nào bên
ngoài match.
Match guard if n == y không phải là một mẫu và do đó không giới thiệu các biến
mới. y này là y bên ngoài chứ không phải một y mới che khuất nó, và
chúng ta có thể tìm kiếm một giá trị có cùng giá trị với y bên ngoài bằng cách
so sánh n với y.
Bạn cũng có thể sử dụng toán tử hoặc | trong một match guard để chỉ định
nhiều mẫu; điều kiện match guard sẽ áp dụng cho tất cả các mẫu. Listing 19-28
hiển thị sự ưu tiên khi kết hợp một mẫu sử dụng | với một match guard. Phần
quan trọng của ví dụ này là match guard if y áp dụng cho 4, 5, và 6,
mặc dù nó có vẻ như if y chỉ áp dụng cho 6.
fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
Điều kiện match nêu rõ rằng arm chỉ khớp nếu giá trị của x bằng 4, 5, hoặc
6 và nếu y là true. Khi đoạn mã này chạy, mẫu của arm đầu tiên khớp vì
x là 4, nhưng match guard if y là false, vì vậy arm đầu tiên không được
chọn. Đoạn mã chuyển sang arm thứ hai, khớp, và chương trình này in ra no. Lý
do là điều kiện if áp dụng cho toàn bộ mẫu 4 | 5 | 6, không chỉ cho giá trị
cuối cùng 6. Nói cách khác, ưu tiên của một match guard trong mối quan hệ với
một mẫu hoạt động như thế này:
(4 | 5 | 6) if y => ...
chứ không phải như thế này:
4 | 5 | (6 if y) => ...
Sau khi chạy đoạn mã, hành vi ưu tiên là rõ ràng: nếu match guard chỉ được áp
dụng cho giá trị cuối cùng trong danh sách các giá trị được chỉ định bằng toán
tử |, thì arm đã khớp và chương trình đã in ra yes.
Ràng Buộc @
Toán tử at @ cho phép chúng ta tạo một biến giữ một giá trị đồng thời kiểm
tra giá trị đó để khớp với một mẫu. Trong Listing 19-29, chúng ta muốn kiểm tra
rằng trường id của Message::Hello nằm trong phạm vi 3..=7. Chúng ta cũng
muốn ràng buộc giá trị với biến id_variable để chúng ta có thể sử dụng nó
trong mã liên kết với arm. Chúng ta có thể đặt tên biến này là id, giống như
tên trường, nhưng trong ví dụ này chúng ta sẽ sử dụng một tên khác.
fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id @ 3..=7 } => { println!("Found an id in range: {id}") } Message::Hello { id: 10..=12 } => { println!("Found an id in another range") } Message::Hello { id } => println!("Found some other id: {id}"), } }
Ví dụ này sẽ in ra Found an id in range: 5. Bằng cách chỉ định id_variable @
trước phạm vi 3..=7, chúng ta đang bắt bất kỳ giá trị nào khớp với phạm vi
đồng thời kiểm tra rằng giá trị đó khớp với mẫu phạm vi.
Trong arm thứ hai, nơi chúng ta chỉ có một phạm vi được chỉ định trong mẫu, mã
liên kết với arm không có biến chứa giá trị thực tế của trường id. Giá trị của
trường id có thể là 10, 11, hoặc 12, nhưng mã đi kèm với mẫu đó không biết nó
là gì. Mã mẫu không thể sử dụng giá trị từ trường id, vì chúng ta chưa lưu giá
trị id trong một biến.
Trong arm cuối cùng, nơi chúng ta đã chỉ định một biến mà không có phạm vi,
chúng ta có giá trị có sẵn để sử dụng trong mã của arm trong một biến có tên là
id. Lý do là chúng ta đã sử dụng cú pháp rút gọn trường struct. Nhưng chúng ta
chưa áp dụng bất kỳ kiểm tra nào cho giá trị trong trường id trong arm này,
như chúng ta đã làm với hai arm đầu tiên: bất kỳ giá trị nào cũng sẽ khớp với
mẫu này.
Sử dụng @ cho phép chúng ta kiểm tra một giá trị và lưu nó trong một biến
trong một mẫu.
Tóm Tắt
Các mẫu của Rust rất hữu ích trong việc phân biệt giữa các loại dữ liệu khác
nhau. Khi được sử dụng trong biểu thức match, Rust đảm bảo rằng các mẫu của
bạn bao gồm mọi giá trị có thể có, nếu không chương trình của bạn sẽ không biên
dịch. Các mẫu trong câu lệnh let và tham số hàm làm cho các cấu trúc đó hữu
ích hơn, cho phép phá vỡ các giá trị thành các phần nhỏ hơn đồng thời gán các
phần đó cho các biến. Chúng ta có thể tạo các mẫu đơn giản hoặc phức tạp để phù
hợp với nhu cầu của chúng ta.
Tiếp theo, ở chương gần cuối của cuốn sách, chúng ta sẽ xem xét một số khía cạnh nâng cao của nhiều tính năng của Rust.
Các Tính Năng Nâng Cao
Đến lúc này, bạn đã học được những phần thường được sử dụng nhất của ngôn ngữ lập trình Rust. Trước khi chúng ta thực hiện một dự án nữa, trong Chương 21, chúng ta sẽ xem xét một số khía cạnh của ngôn ngữ mà bạn có thể gặp phải thỉnh thoảng, nhưng có thể không sử dụng hàng ngày. Bạn có thể sử dụng chương này như một tài liệu tham khảo khi bạn gặp phải những điều chưa biết. Các tính năng được đề cập ở đây rất hữu ích trong những tình huống rất cụ thể. Mặc dù bạn có thể không sử dụng chúng thường xuyên, chúng tôi muốn đảm bảo rằng bạn nắm được tất cả các tính năng mà Rust cung cấp.
Trong chương này, chúng ta sẽ đề cập đến:
- Unsafe Rust: cách từ bỏ một số đảm bảo của Rust và tự chịu trách nhiệm về việc duy trì những đảm bảo đó một cách thủ công
- Traits nâng cao: các kiểu liên kết, tham số kiểu mặc định, cú pháp đầy đủ, supertraits, và mẫu newtype liên quan đến traits
- Kiểu dữ liệu nâng cao: thêm về mẫu newtype, bí danh kiểu, kiểu never, và các kiểu có kích thước động
- Hàm và closure nâng cao: con trỏ hàm và trả về closures
- Macro: các cách để định nghĩa mã nguồn định nghĩa thêm mã nguồn ở thời điểm biên dịch
Đây là một tập hợp đa dạng các tính năng của Rust với điều gì đó cho tất cả mọi người! Hãy bắt đầu!
Unsafe Rust
Tất cả mã nguồn mà chúng ta đã thảo luận cho đến nay đều có các đảm bảo về an toàn bộ nhớ của Rust được thực thi tại thời điểm biên dịch. Tuy nhiên, Rust có một ngôn ngữ thứ hai ẩn bên trong nó không thực thi các đảm bảo an toàn bộ nhớ này: nó được gọi là unsafe Rust và hoạt động giống như Rust thông thường, nhưng cung cấp cho chúng ta các siêu năng lực bổ sung.
Unsafe Rust tồn tại bởi vì, về bản chất, phân tích tĩnh là bảo thủ. Khi trình biên dịch cố gắng xác định liệu mã có duy trì các đảm bảo hay không, tốt hơn là nó từ chối một số chương trình hợp lệ còn hơn là chấp nhận một số chương trình không hợp lệ. Mặc dù mã có thể ổn, nhưng nếu trình biên dịch Rust không có đủ thông tin để tự tin, nó sẽ từ chối mã. Trong những trường hợp này, bạn có thể sử dụng mã unsafe để nói với trình biên dịch rằng, "Hãy tin tôi, tôi biết mình đang làm gì." Tuy nhiên, hãy cảnh giác, rằng bạn sử dụng unsafe Rust với rủi ro của riêng mình: nếu bạn sử dụng mã unsafe không chính xác, các vấn đề có thể xảy ra do không an toàn bộ nhớ, chẳng hạn như giải tham chiếu con trỏ null.
Một lý do khác khiến Rust có một phiên bản khác là unsafe là vì phần cứng máy tính cơ bản vốn không an toàn. Nếu Rust không cho phép bạn thực hiện các hoạt động không an toàn, bạn không thể thực hiện một số tác vụ nhất định. Rust cần cho phép bạn thực hiện lập trình hệ thống cấp thấp, chẳng hạn như tương tác trực tiếp với hệ điều hành hoặc thậm chí viết hệ điều hành của riêng bạn. Làm việc với lập trình hệ thống cấp thấp là một trong những mục tiêu của ngôn ngữ này. Hãy khám phá những gì chúng ta có thể làm với unsafe Rust và cách thực hiện.
Siêu Năng Lực Unsafe
Để chuyển sang unsafe Rust, sử dụng từ khóa unsafe và sau đó bắt đầu một khối
mới chứa mã unsafe. Bạn có thể thực hiện năm hành động trong unsafe Rust mà bạn
không thể thực hiện trong safe Rust, mà chúng ta gọi là siêu năng lực unsafe.
Những siêu năng lực đó bao gồm khả năng:
-
- Giải tham chiếu một con trỏ thô
-
- Gọi một hàm hoặc phương thức unsafe
-
- Truy cập hoặc sửa đổi một biến tĩnh có thể thay đổi
-
- Triển khai một trait unsafe
-
- Truy cập các trường của một
union
- Truy cập các trường của một
Điều quan trọng cần hiểu là unsafe không tắt trình kiểm tra mượn hoặc vô hiệu
hóa bất kỳ kiểm tra an toàn nào khác của Rust: nếu bạn sử dụng một tham chiếu
trong mã unsafe, nó vẫn sẽ được kiểm tra. Từ khóa unsafe chỉ cung cấp cho bạn
quyền truy cập vào năm tính năng này, sau đó không được trình biên dịch kiểm tra
về an toàn bộ nhớ. Bạn vẫn sẽ có một mức độ an toàn nhất định bên trong khối
unsafe.
Ngoài ra, unsafe không có nghĩa là mã bên trong khối nhất thiết phải nguy hiểm
hoặc chắc chắn sẽ có vấn đề về an toàn bộ nhớ: ý định là với tư cách là lập
trình viên, bạn sẽ đảm bảo rằng mã bên trong khối unsafe sẽ truy cập bộ nhớ
theo cách hợp lệ.
Con người có thể mắc lỗi và lỗi sẽ xảy ra, nhưng bằng cách yêu cầu năm hoạt động
unsafe này phải nằm trong các khối được chú thích với unsafe, bạn sẽ biết rằng
bất kỳ lỗi nào liên quan đến an toàn bộ nhớ phải nằm trong một khối unsafe.
Giữ các khối unsafe nhỏ; bạn sẽ biết ơn sau này khi điều tra các lỗi bộ nhớ.
Để cô lập mã unsafe càng nhiều càng tốt, tốt nhất là bao bọc mã đó trong một
trừu tượng an toàn và cung cấp một API an toàn, điều mà chúng ta sẽ thảo luận
sau trong chương khi chúng ta xem xét các hàm và phương thức unsafe. Các phần
của thư viện tiêu chuẩn được triển khai như các trừu tượng an toàn trên mã
unsafe đã được kiểm tra. Bao bọc mã unsafe trong một trừu tượng an toàn ngăn
việc sử dụng unsafe rò rỉ ra tất cả các nơi mà bạn hoặc người dùng của bạn có
thể muốn sử dụng chức năng được triển khai với mã unsafe, bởi vì việc sử dụng
một trừu tượng an toàn là an toàn.
Hãy xem xét từng siêu năng lực unsafe một. Chúng ta cũng sẽ xem xét một số trừu tượng cung cấp giao diện an toàn cho mã unsafe.
Giải Tham Chiếu một Con Trỏ Thô
Trong Chương 4, trong "Tham Chiếu Đang
Treo", chúng ta đã đề cập rằng trình biên
dịch đảm bảo các tham chiếu luôn hợp lệ. Unsafe Rust có hai loại mới được gọi là
con trỏ thô tương tự như tham chiếu. Giống như với các tham chiếu, con trỏ thô
có thể bất biến hoặc có thể thay đổi và được viết là *const T và *mut T,
tương ứng. Dấu hoa thị không phải là toán tử giải tham chiếu; nó là một phần của
tên kiểu. Trong bối cảnh của con trỏ thô, bất biến có nghĩa là con trỏ không
thể được gán trực tiếp sau khi được giải tham chiếu.
Khác với tham chiếu và con trỏ thông minh, con trỏ thô:
- Được phép bỏ qua các quy tắc mượn bằng cách có cả con trỏ bất biến và có thể thay đổi hoặc nhiều con trỏ có thể thay đổi đến cùng một vị trí
- Không được đảm bảo trỏ đến bộ nhớ hợp lệ
- Được phép là null
- Không triển khai bất kỳ quá trình dọn dẹp tự động nào
Bằng cách chọn không để Rust thực thi các đảm bảo này, bạn có thể từ bỏ an toàn được đảm bảo để đổi lấy hiệu suất cao hơn hoặc khả năng giao tiếp với ngôn ngữ hoặc phần cứng khác nơi mà các đảm bảo của Rust không áp dụng.
Listing 20-1 cho thấy cách tạo một con trỏ bất biến và một con trỏ có thể thay đổi.
fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; }
Lưu ý rằng chúng ta không đưa từ khóa unsafe vào mã này. Chúng ta có thể tạo
con trỏ thô trong mã an toàn; chúng ta chỉ không thể giải tham chiếu con trỏ thô
bên ngoài một khối unsafe, như bạn sẽ thấy sau đây.
Chúng ta đã tạo con trỏ thô bằng cách sử dụng các toán tử mượn thô:
&raw const num tạo một con trỏ thô bất biến *const i32, và &raw mut num
tạo một con trỏ thô có thể thay đổi *mut i32. Bởi vì chúng ta tạo chúng trực
tiếp từ một biến cục bộ, chúng ta biết các con trỏ thô cụ thể này là hợp lệ,
nhưng chúng ta không thể đưa ra giả định đó về bất kỳ con trỏ thô nào.
Để minh họa điều này, tiếp theo chúng ta sẽ tạo một con trỏ thô mà tính hợp lệ
của nó chúng ta không thể chắc chắn, sử dụng từ khóa as để ép kiểu một giá trị
thay vì sử dụng toán tử mượn thô. Listing 20-2 cho thấy cách tạo một con trỏ thô
đến một vị trí bộ nhớ tùy ý. Việc cố gắng sử dụng bộ nhớ tùy ý là không xác
định: có thể có dữ liệu tại địa chỉ đó hoặc có thể không, trình biên dịch có thể
tối ưu hóa mã để không có truy cập bộ nhớ, hoặc chương trình có thể kết thúc với
lỗi phân đoạn. Thông thường, không có lý do tốt để viết mã như thế này, đặc biệt
là trong các trường hợp mà bạn có thể sử dụng toán tử mượn thô thay thế, nhưng
điều đó là có thể.
fn main() { let address = 0x012345usize; let r = address as *const i32; }
Nhớ rằng chúng ta có thể tạo con trỏ thô trong mã an toàn, nhưng chúng ta không
thể giải tham chiếu con trỏ thô và đọc dữ liệu đang được trỏ đến. Trong
Listing 20-3, chúng ta sử dụng toán tử giải tham chiếu * trên một con trỏ thô
đòi hỏi một khối unsafe.
fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
Việc tạo một con trỏ không gây hại gì; chỉ khi chúng ta cố gắng truy cập giá trị mà nó trỏ đến, chúng ta mới có thể phải đối mặt với một giá trị không hợp lệ.
Cũng lưu ý rằng trong Listings 20-1 và 20-3, chúng ta đã tạo các con trỏ thô
*const i32 và *mut i32 đều trỏ đến cùng một vị trí bộ nhớ, nơi num được
lưu trữ. Nếu thay vào đó, chúng ta cố gắng tạo một tham chiếu bất biến và một
tham chiếu có thể thay đổi đến num, mã sẽ không biên dịch được vì các quy tắc
sở hữu của Rust không cho phép một tham chiếu có thể thay đổi cùng lúc với bất
kỳ tham chiếu bất biến nào. Với con trỏ thô, chúng ta có thể tạo một con trỏ có
thể thay đổi và một con trỏ bất biến đến cùng một vị trí và thay đổi dữ liệu
thông qua con trỏ có thể thay đổi, có khả năng tạo ra cuộc đua dữ liệu. Hãy cẩn
thận!
Với tất cả những nguy hiểm này, tại sao bạn lại sử dụng con trỏ thô? Một trường hợp sử dụng chính là khi giao tiếp với mã C, như bạn sẽ thấy trong phần tiếp theo. Một trường hợp khác là khi xây dựng các trừu tượng an toàn mà trình kiểm tra mượn không hiểu. Chúng ta sẽ giới thiệu các hàm unsafe và sau đó xem xét một ví dụ về một trừu tượng an toàn sử dụng mã unsafe.
Gọi Hàm hoặc Phương Thức Unsafe
Loại hoạt động thứ hai mà bạn có thể thực hiện trong một khối unsafe là gọi các
hàm unsafe. Các hàm và phương thức unsafe trông giống như các hàm và phương thức
thông thường, nhưng chúng có thêm unsafe trước phần còn lại của định nghĩa. Từ
khóa unsafe trong bối cảnh này chỉ ra rằng hàm có các yêu cầu mà chúng ta cần
duy trì khi gọi hàm này, bởi vì Rust không thể đảm bảo rằng chúng ta đã đáp ứng
các yêu cầu này. Bằng cách gọi một hàm unsafe trong một khối unsafe, chúng ta
đang nói rằng chúng ta đã đọc tài liệu của hàm này và chúng ta chịu trách nhiệm
duy trì các hợp đồng của hàm.
Đây là một hàm unsafe có tên dangerous không làm gì trong thân hàm:
fn main() { unsafe fn dangerous() {} unsafe { dangerous(); } }
Chúng ta phải gọi hàm dangerous trong một khối unsafe riêng biệt. Nếu chúng
ta cố gắng gọi dangerous mà không có khối unsafe, chúng ta sẽ gặp lỗi:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Với khối unsafe, chúng ta đang khẳng định với Rust rằng chúng ta đã đọc tài
liệu của hàm, chúng ta hiểu cách sử dụng nó đúng cách và chúng ta đã xác minh
rằng chúng ta đang thực hiện hợp đồng của hàm.
Để thực hiện các hoạt động unsafe trong thân của một hàm unsafe, bạn vẫn cần
sử dụng một khối unsafe, giống như trong một hàm thông thường, và trình biên
dịch sẽ cảnh báo bạn nếu bạn quên. Điều này giúp chúng ta giữ cho các khối
unsafe càng nhỏ càng tốt, vì các hoạt động unsafe có thể không cần thiết trên
toàn bộ thân hàm.
Tạo một Trừu Tượng An Toàn trên Mã Unsafe
Chỉ vì một hàm chứa mã unsafe không có nghĩa là chúng ta cần đánh dấu toàn bộ
hàm là unsafe. Trên thực tế, việc bao bọc mã unsafe trong một hàm an toàn là một
trừu tượng phổ biến. Ví dụ, hãy nghiên cứu hàm split_at_mut từ thư viện tiêu
chuẩn, hàm này yêu cầu một số mã unsafe. Chúng ta sẽ khám phá cách chúng ta có
thể triển khai nó. Phương thức an toàn này được định nghĩa trên các slice có thể
thay đổi: nó lấy một slice và tạo ra hai slice bằng cách chia slice tại chỉ số
được đưa vào dưới dạng đối số. Listing 20-4 cho thấy cách sử dụng
split_at_mut.
fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = r.split_at_mut(3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
Chúng ta không thể triển khai hàm này chỉ bằng Rust an toàn. Một nỗ lực có thể
trông giống như Listing 20-5, nhưng sẽ không biên dịch được. Để đơn giản, chúng
ta sẽ triển khai split_at_mut dưới dạng một hàm thay vì một phương thức và chỉ
cho các slice của giá trị i32 thay vì cho một kiểu chung T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}Hàm này đầu tiên lấy tổng độ dài của slice. Sau đó, nó khẳng định rằng chỉ số được đưa vào dưới dạng tham số nằm trong slice bằng cách kiểm tra xem nó có nhỏ hơn hoặc bằng độ dài hay không. Sự khẳng định có nghĩa là nếu chúng ta truyền một chỉ số lớn hơn độ dài để chia slice, hàm sẽ panic trước khi nó cố gắng sử dụng chỉ số đó.
Sau đó, chúng ta trả về hai slice có thể thay đổi trong một tuple: một từ đầu
slice ban đầu đến chỉ số mid và một từ mid đến cuối slice.
Khi chúng ta cố gắng biên dịch mã trong Listing 20-5, chúng ta sẽ gặp lỗi:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Trình kiểm tra mượn của Rust không thể hiểu rằng chúng ta đang mượn các phần khác nhau của slice; nó chỉ biết rằng chúng ta đang mượn từ cùng một slice hai lần. Việc mượn các phần khác nhau của một slice về cơ bản là ổn vì hai slice không chồng chéo nhau, nhưng Rust không đủ thông minh để biết điều này. Khi chúng ta biết mã là ổn, nhưng Rust không biết, đó là lúc chúng ta cần sử dụng mã unsafe.
Listing 20-6 cho thấy cách sử dụng khối unsafe, con trỏ thô và một số lệnh gọi
đến các hàm unsafe để làm cho việc triển khai split_at_mut hoạt động.
use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
Nhớ lại từ "Kiểu Slice" trong Chương 4 rằng một
slice là một con trỏ đến một số dữ liệu và độ dài của slice. Chúng ta sử dụng
phương thức len để lấy độ dài của một slice và phương thức as_mut_ptr để
truy cập con trỏ thô của một slice. Trong trường hợp này, vì chúng ta có một
slice có thể thay đổi cho các giá trị i32, as_mut_ptr trả về một con trỏ thô
với kiểu *mut i32, mà chúng ta đã lưu trữ trong biến ptr.
Chúng ta giữ khẳng định rằng chỉ số mid nằm trong slice. Sau đó, chúng ta đi
đến mã unsafe: hàm slice::from_raw_parts_mut nhận một con trỏ thô và một độ
dài, và nó tạo ra một slice. Chúng ta sử dụng hàm này để tạo một slice bắt đầu
từ ptr và dài mid phần tử. Sau đó, chúng ta gọi phương thức add trên ptr
với mid là đối số để có được một con trỏ thô bắt đầu tại mid, và chúng ta
tạo một slice sử dụng con trỏ đó và số phần tử còn lại sau mid làm độ dài.
Hàm slice::from_raw_parts_mut là unsafe vì nó nhận một con trỏ thô và phải tin
rằng con trỏ này là hợp lệ. Phương thức add trên các con trỏ thô cũng là
unsafe vì nó phải tin rằng vị trí offset cũng là một con trỏ hợp lệ. Do đó,
chúng ta phải đặt một khối unsafe xung quanh các lệnh gọi của chúng ta đến
slice::from_raw_parts_mut và add để chúng ta có thể gọi chúng. Bằng cách xem
xét mã và thêm khẳng định rằng mid phải nhỏ hơn hoặc bằng len, chúng ta có
thể nói rằng tất cả các con trỏ thô được sử dụng trong khối unsafe sẽ là các
con trỏ hợp lệ đến dữ liệu trong slice. Đây là một cách sử dụng unsafe có thể
chấp nhận và thích hợp.
Lưu ý rằng chúng ta không cần phải đánh dấu hàm split_at_mut kết quả là
unsafe, và chúng ta có thể gọi hàm này từ Rust an toàn. Chúng ta đã tạo một
trừu tượng an toàn cho mã unsafe với một triển khai của hàm sử dụng mã unsafe
theo cách an toàn, bởi vì nó chỉ tạo các con trỏ hợp lệ từ dữ liệu mà hàm này có
quyền truy cập.
Ngược lại, việc sử dụng slice::from_raw_parts_mut trong Listing 20-7 có thể sẽ
gây crash khi slice được sử dụng. Mã này lấy một vị trí bộ nhớ tùy ý và tạo một
slice dài 10.000 phần tử.
fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
Chúng ta không sở hữu bộ nhớ tại vị trí tùy ý này, và không có đảm bảo rằng
slice mà mã này tạo ra chứa các giá trị i32 hợp lệ. Cố gắng sử dụng values
như thể nó là một slice hợp lệ dẫn đến hành vi không xác định.
Sử dụng Hàm extern để Gọi Mã Bên Ngoài
Đôi khi mã Rust của bạn có thể cần tương tác với mã được viết bằng một ngôn ngữ
khác. Đối với điều này, Rust có từ khóa extern tạo điều kiện cho việc tạo và
sử dụng một Giao Diện Hàm Ngoại (FFI), là một cách để một ngôn ngữ lập trình
định nghĩa các hàm và cho phép một ngôn ngữ lập trình khác (ngoại) gọi các hàm
đó.
Listing 20-8 minh họa cách thiết lập tích hợp với hàm abs từ thư viện tiêu
chuẩn C. Các hàm được khai báo trong các khối extern thường không an toàn khi
gọi từ mã Rust, vì vậy các khối extern cũng phải được đánh dấu là unsafe. Lý
do là vì các ngôn ngữ khác không thực thi các quy tắc và đảm bảo của Rust, và
Rust không thể kiểm tra chúng, vì vậy trách nhiệm thuộc về lập trình viên để đảm
bảo an toàn.
unsafe extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
Trong khối unsafe extern "C", chúng ta liệt kê tên và chữ ký của các hàm bên
ngoài từ một ngôn ngữ khác mà chúng ta muốn gọi. Phần "C" định nghĩa giao
diện nhị phân ứng dụng (ABI) mà hàm bên ngoài sử dụng: ABI định nghĩa cách gọi
hàm ở cấp độ assembly. ABI "C" là phổ biến nhất và tuân theo ABI của ngôn ngữ
lập trình C. Thông tin về tất cả các ABI mà Rust hỗ trợ có sẵn trong Tài liệu
tham khảo Rust.
Mỗi mục được khai báo trong một khối unsafe extern đều được ngầm hiểu là
unsafe. Tuy nhiên, một số hàm FFI thực sự an toàn để gọi. Ví dụ, hàm abs
từ thư viện tiêu chuẩn của C không có bất kỳ cân nhắc an toàn bộ nhớ nào và
chúng ta biết nó có thể được gọi với bất kỳ giá trị i32 nào. Trong những
trường hợp như thế này, chúng ta có thể sử dụng từ khóa safe để nói rằng hàm
cụ thể này an toàn để gọi ngay cả khi nó nằm trong một khối unsafe extern. Sau
khi chúng ta thực hiện thay đổi đó, việc gọi nó không còn yêu cầu một khối
unsafe, như thể hiện trong Listing 20-9.
unsafe extern "C" { safe fn abs(input: i32) -> i32; } fn main() { println!("Absolute value of -3 according to C: {}", abs(-3)); }
Việc đánh dấu một hàm là safe không tự nhiên làm cho nó an toàn! Thay vào đó,
nó giống như một lời hứa mà bạn đang tạo với Rust rằng nó là an toàn. Vẫn là
trách nhiệm của bạn để đảm bảo lời hứa đó được giữ!
Gọi Hàm Rust từ Các Ngôn Ngữ Khác
Chúng ta cũng có thể sử dụng
externđể tạo một giao diện cho phép các ngôn ngữ khác gọi các hàm Rust. Thay vì tạo một khốiexternhoàn chỉnh, chúng ta thêm từ khóaexternvà chỉ định ABI để sử dụng ngay trước từ khóafncho hàm liên quan. Chúng ta cũng cần thêm chú thích#[unsafe(no_mangle)]để nói với trình biên dịch Rust không làm rối tên của hàm này. Làm rối là khi một trình biên dịch thay đổi tên mà chúng ta đã đặt cho một hàm thành một tên khác chứa thêm thông tin cho các phần khác của quá trình biên dịch sử dụng nhưng ít dễ đọc hơn đối với con người. Mỗi trình biên dịch ngôn ngữ lập trình làm rối tên hơi khác nhau, vì vậy để một hàm Rust có thể được đặt tên bởi các ngôn ngữ khác, chúng ta phải vô hiệu hóa việc làm rối tên của trình biên dịch Rust. Điều này là không an toàn vì có thể có xung đột tên giữa các thư viện mà không có cơ chế làm rối tên tích hợp, vì vậy đó là trách nhiệm của chúng ta để đảm bảo tên mà chúng ta chọn là an toàn để xuất mà không làm rối.Trong ví dụ sau, chúng ta làm cho hàm
call_from_ccó thể truy cập từ mã C, sau khi nó được biên dịch thành một thư viện chia sẻ và được liên kết từ C:#![allow(unused)] fn main() { #[unsafe(no_mangle)] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }Cách sử dụng
externnày chỉ yêu cầuunsafetrong thuộc tính, không phải trên khốiextern.
Truy Cập hoặc Sửa Đổi một Biến Tĩnh Có Thể Thay Đổi
Trong sách này, chúng ta vẫn chưa nói về các biến toàn cục, mà Rust có hỗ trợ nhưng có thể gây ra vấn đề với các quy tắc sở hữu của Rust. Nếu hai luồng đang truy cập cùng một biến toàn cục có thể thay đổi, nó có thể gây ra đua dữ liệu.
Trong Rust, các biến toàn cục được gọi là biến tĩnh. Listing 20-10 cho thấy một ví dụ về khai báo và sử dụng một biến tĩnh với một slice chuỗi làm giá trị.
static HELLO_WORLD: &str = "Hello, world!"; fn main() { println!("value is: {HELLO_WORLD}"); }
Các biến tĩnh tương tự như các hằng số, mà chúng ta đã thảo luận trong "Hằng
Số" trong Chương 3.
Tên của các biến tĩnh là SCREAMING_SNAKE_CASE theo quy ước. Các biến tĩnh chỉ
có thể lưu trữ các tham chiếu với thời gian sống 'static, có nghĩa là trình
biên dịch Rust có thể tính toán thời gian sống và chúng ta không cần phải chú
thích nó một cách rõ ràng. Truy cập một biến tĩnh bất biến là an toàn.
Một sự khác biệt tinh tế giữa các hằng số và các biến tĩnh bất biến là các giá
trị trong một biến tĩnh có một địa chỉ cố định trong bộ nhớ. Việc sử dụng giá
trị sẽ luôn truy cập cùng một dữ liệu. Các hằng số, mặt khác, được phép nhân bản
dữ liệu của chúng bất cứ khi nào chúng được sử dụng. Một sự khác biệt khác là
các biến tĩnh có thể có thể thay đổi. Truy cập và sửa đổi các biến tĩnh có thể
thay đổi là không an toàn. Listing 20-11 cho thấy cách khai báo, truy cập và
sửa đổi một biến tĩnh có thể thay đổi có tên là COUNTER.
static mut COUNTER: u32 = 0; /// SAFETY: Calling this from more than a single thread at a time is undefined /// behavior, so you *must* guarantee you only call it from a single thread at /// a time. unsafe fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { unsafe { // SAFETY: This is only called from a single thread in `main`. add_to_count(3); println!("COUNTER: {}", *(&raw const COUNTER)); } }
Giống như với các biến thông thường, chúng ta chỉ định khả năng thay đổi bằng từ
khóa mut. Bất kỳ mã nào đọc hoặc ghi từ COUNTER phải nằm trong một khối
unsafe. Mã này biên dịch và in COUNTER: 3 như chúng ta mong đợi vì nó là đơn
luồng. Việc có nhiều luồng truy cập COUNTER có thể dẫn đến đua dữ liệu, vì vậy
nó là hành vi không xác định. Do đó, chúng ta cần đánh dấu toàn bộ hàm là
unsafe, và ghi chú giới hạn an toàn, để bất kỳ ai gọi hàm đều biết những gì họ
được và không được phép làm một cách an toàn.
Bất cứ khi nào chúng ta viết một hàm unsafe, theo quy ước, chúng ta nên viết một
bình luận bắt đầu bằng SAFETY và giải thích những gì người gọi cần làm để gọi
hàm một cách an toàn. Tương tự, bất cứ khi nào chúng ta thực hiện một hoạt động
unsafe, theo quy ước, chúng ta nên viết một bình luận bắt đầu bằng SAFETY để
giải thích cách các quy tắc an toàn được duy trì.
Ngoài ra, trình biên dịch sẽ không cho phép bạn tạo các tham chiếu đến một biến
tĩnh có thể thay đổi. Bạn chỉ có thể truy cập nó thông qua một con trỏ thô, được
tạo bằng một trong các toán tử mượn thô. Điều đó bao gồm cả trong các trường hợp
khi tham chiếu được tạo một cách vô hình, như khi nó được sử dụng trong
println! trong mã này. Yêu cầu rằng các tham chiếu đến các biến tĩnh có thể
thay đổi chỉ có thể được tạo thông qua các con trỏ thô giúp làm cho các yêu cầu
an toàn để sử dụng chúng trở nên rõ ràng hơn.
Với dữ liệu có thể thay đổi mà có thể truy cập toàn cục, khó để đảm bảo rằng không có đua dữ liệu, đó là lý do tại sao Rust coi các biến tĩnh có thể thay đổi là không an toàn. Khi có thể, tốt hơn là sử dụng các kỹ thuật đồng thời và các con trỏ thông minh an toàn với luồng mà chúng ta đã thảo luận trong Chương 16 để trình biên dịch kiểm tra rằng việc truy cập dữ liệu từ các luồng khác nhau được thực hiện một cách an toàn.
Triển Khai một Trait Unsafe
Chúng ta có thể sử dụng unsafe để triển khai một trait unsafe. Một trait là
unsafe khi ít nhất một trong các phương thức của nó có một bất biến mà trình
biên dịch không thể xác minh. Chúng ta khai báo rằng một trait là unsafe bằng
cách thêm từ khóa unsafe trước trait và đánh dấu việc triển khai trait cũng
là unsafe, như thể hiện trong Listing 20-12.
unsafe trait Foo { // methods go here } unsafe impl Foo for i32 { // method implementations go here } fn main() {}
Bằng cách sử dụng unsafe impl, chúng ta đang hứa rằng chúng ta sẽ duy trì các
bất biến mà trình biên dịch không thể xác minh.
Ví dụ, nhớ lại các trait đánh dấu Sync và Send mà chúng ta đã thảo luận
trong "Khả năng mở rộng đồng thời với các Trait Sync và
Send"
trong Chương 16: trình biên dịch triển khai các trait này tự động nếu các kiểu
của chúng ta được tạo thành hoàn toàn từ các kiểu khác triển khai Send và
Sync. Nếu chúng ta triển khai một kiểu chứa một kiểu không triển khai Send
hoặc Sync, chẳng hạn như con trỏ thô, và chúng ta muốn đánh dấu kiểu đó là
Send hoặc Sync, chúng ta phải sử dụng unsafe. Rust không thể xác minh rằng
kiểu của chúng ta duy trì các đảm bảo rằng nó có thể được gửi an toàn qua các
luồng hoặc truy cập từ nhiều luồng; do đó, chúng ta cần thực hiện các kiểm tra
đó thủ công và chỉ ra như vậy với unsafe.
Truy Cập các Trường của một Union
Hành động cuối cùng chỉ hoạt động với unsafe là truy cập các trường của một
union. Một union tương tự như một struct, nhưng chỉ một trường được khai báo
được sử dụng trong một phiên bản cụ thể tại một thời điểm. Unions chủ yếu được
sử dụng để giao tiếp với các unions trong mã C. Truy cập các trường của union là
unsafe vì Rust không thể đảm bảo kiểu của dữ liệu hiện đang được lưu trữ trong
phiên bản union. Bạn có thể tìm hiểu thêm về unions trong Tài liệu tham khảo
Rust.
Sử Dụng Miri để Kiểm Tra Mã Unsafe
Khi viết mã unsafe, bạn có thể muốn kiểm tra rằng những gì bạn đã viết thực sự là an toàn và chính xác. Một trong những cách tốt nhất để làm điều đó là sử dụng Miri, một công cụ Rust chính thức để phát hiện hành vi không xác định. Trong khi trình kiểm tra mượn là một công cụ tĩnh hoạt động tại thời điểm biên dịch, Miri là một công cụ động hoạt động tại thời điểm chạy. Nó kiểm tra mã của bạn bằng cách chạy chương trình của bạn, hoặc bộ kiểm tra của nó, và phát hiện khi bạn vi phạm các quy tắc mà nó hiểu về cách Rust nên hoạt động.
Sử dụng Miri yêu cầu một bản dựng nightly của Rust (mà chúng ta nói thêm trong
Phụ lục G: Rust được tạo ra như thế nào và "Rust Nightly"). Bạn có
thể cài đặt cả phiên bản nightly của Rust và công cụ Miri bằng cách nhập
rustup +nightly component add miri. Điều này không thay đổi phiên bản Rust mà
dự án của bạn sử dụng; nó chỉ thêm công cụ vào hệ thống của bạn để bạn có thể sử
dụng nó khi muốn. Bạn có thể chạy Miri trên một dự án bằng cách nhập
cargo +nightly miri run hoặc cargo +nightly miri test.
Ví dụ về việc điều này có thể hữu ích như thế nào, hãy xem điều gì xảy ra khi chúng ta chạy nó với Listing 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri chính xác cảnh báo chúng ta rằng chúng ta đang ép kiểu một số nguyên thành một con trỏ, điều này có thể là một vấn đề nhưng Miri không thể phát hiện nếu có vì nó không biết con trỏ bắt nguồn từ đâu. Sau đó, Miri trả về một lỗi trong đó Listing 20-7 có hành vi không xác định vì chúng ta có một con trỏ lơ lửng. Nhờ Miri, chúng ta bây giờ biết có rủi ro về hành vi không xác định, và chúng ta có thể suy nghĩ về cách làm cho mã an toàn. Trong một số trường hợp, Miri thậm chí có thể đưa ra các khuyến nghị về cách khắc phục lỗi.
Miri không bắt tất cả mọi thứ mà bạn có thể làm sai khi viết mã unsafe. Miri là một công cụ phân tích động, vì vậy nó chỉ bắt các vấn đề với mã thực sự được chạy. Điều đó có nghĩa là bạn sẽ cần sử dụng nó kết hợp với các kỹ thuật kiểm tra tốt để tăng sự tự tin về mã unsafe mà bạn đã viết. Miri cũng không bao gồm mọi cách có thể mà mã của bạn có thể không đúng.
Nói cách khác: Nếu Miri phát hiện một vấn đề, bạn biết có một lỗi, nhưng chỉ vì Miri không bắt được lỗi không có nghĩa là không có vấn đề. Tuy nhiên, nó có thể bắt được nhiều lỗi. Hãy thử chạy nó trên các ví dụ khác về mã unsafe trong chương này và xem nó nói gì!
Bạn có thể tìm hiểu thêm về Miri tại kho lưu trữ GitHub của nó.
Khi Nào Nên Sử Dụng Mã Unsafe
Việc sử dụng unsafe để sử dụng một trong năm siêu năng lực vừa thảo luận không
sai hoặc thậm chí không bị coi là xấu, nhưng nó phức tạp hơn để có được mã
unsafe chính xác vì trình biên dịch không thể giúp duy trì an toàn bộ nhớ. Khi
bạn có lý do để sử dụng mã unsafe, bạn có thể làm như vậy, và việc có chú
thích unsafe rõ ràng giúp dễ dàng theo dõi nguồn gốc của các vấn đề khi chúng
xảy ra. Bất cứ khi nào bạn viết mã unsafe, bạn có thể sử dụng Miri để giúp bạn
tự tin hơn rằng mã bạn đã viết tuân theo các quy tắc của Rust.
Để khám phá sâu hơn về cách làm việc hiệu quả với unsafe Rust, hãy đọc hướng dẫn chính thức của Rust về chủ đề này, Rustonomicon.
Trait Nâng Cao
Chúng ta đã đề cập đến trait trong "Trait: Định Nghĩa Hành Vi Chung" ở Chương 10, nhưng chúng ta chưa thảo luận về các chi tiết nâng cao hơn. Giờ đây khi bạn đã biết nhiều hơn về Rust, chúng ta có thể đi sâu vào chi tiết.
Kiểu Liên Kết (Associated Types)
Kiểu liên kết kết nối một placeholder kiểu với một trait để các định nghĩa phương thức của trait có thể sử dụng các placeholder kiểu này trong chữ ký của chúng. Người triển khai trait sẽ chỉ định kiểu cụ thể được sử dụng thay vì kiểu placeholder cho việc triển khai cụ thể. Bằng cách đó, chúng ta có thể định nghĩa một trait sử dụng một số kiểu mà không cần biết chính xác những kiểu đó là gì cho đến khi trait được triển khai.
Chúng ta đã mô tả hầu hết các tính năng nâng cao trong chương này là ít khi cần đến. Kiểu liên kết nằm đâu đó ở giữa: chúng được sử dụng ít thường xuyên hơn các tính năng được giải thích trong phần còn lại của cuốn sách nhưng phổ biến hơn nhiều tính năng khác được thảo luận trong chương này.
Một ví dụ về trait với kiểu liên kết là trait Iterator mà thư viện chuẩn cung
cấp. Kiểu liên kết được đặt tên là Item và đại diện cho kiểu của các giá trị
mà kiểu thực hiện trait Iterator đang lặp qua. Định nghĩa của trait Iterator
được hiển thị trong Listing 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Kiểu Item là một placeholder, và định nghĩa của phương thức next cho thấy nó
sẽ trả về các giá trị kiểu Option<Self::Item>. Người triển khai trait
Iterator sẽ chỉ định kiểu cụ thể cho Item, và phương thức next sẽ trả về
một Option chứa giá trị của kiểu cụ thể đó.
Kiểu liên kết có thể giống với khái niệm generics, vì generics cũng cho phép
chúng ta định nghĩa một hàm mà không cần chỉ định kiểu nào nó có thể xử lý. Để
xem xét sự khác biệt giữa hai khái niệm này, chúng ta sẽ xem xét việc triển khai
trait Iterator trên một kiểu có tên là Counter chỉ định kiểu Item là
u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Cú pháp này có vẻ tương đương với generics. Vậy tại sao không chỉ định nghĩa
trait Iterator với generics, như được hiển thị trong Listing 20-14?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Sự khác biệt là khi sử dụng generics, như trong Listing 20-14, chúng ta phải chú
thích các kiểu trong mỗi triển khai; bởi vì chúng ta cũng có thể triển khai
Iterator<String> for Counter hoặc bất kỳ kiểu nào khác, chúng ta có thể có
nhiều triển khai của Iterator cho Counter. Nói cách khác, khi một trait có
tham số generic, nó có thể được triển khai cho một kiểu nhiều lần, thay đổi kiểu
cụ thể của các tham số kiểu generic mỗi lần. Khi chúng ta sử dụng phương thức
next trên Counter, chúng ta sẽ phải cung cấp chú thích kiểu để chỉ ra triển
khai nào của Iterator chúng ta muốn sử dụng.
Với kiểu liên kết, chúng ta không cần phải chú thích kiểu vì chúng ta không thể
triển khai một trait trên một kiểu nhiều lần. Trong Listing 20-13 với định nghĩa
sử dụng kiểu liên kết, chúng ta chỉ có thể chọn kiểu của Item sẽ là gì một lần
vì chỉ có thể có một impl Iterator for Counter. Chúng ta không phải chỉ định
rằng chúng ta muốn một iterator của các giá trị u32 ở mọi nơi chúng ta gọi
next trên Counter.
Kiểu liên kết cũng trở thành một phần của hợp đồng trait: người triển khai trait phải cung cấp một kiểu để thay thế cho placeholder kiểu liên kết. Kiểu liên kết thường có tên mô tả cách kiểu sẽ được sử dụng, và việc ghi tài liệu cho kiểu liên kết trong tài liệu API là một thực hành tốt.
Tham Số Kiểu Generic Mặc Định và Nạp Chồng Toán Tử
Khi chúng ta sử dụng các tham số kiểu generic, chúng ta có thể chỉ định một kiểu
cụ thể mặc định cho kiểu generic. Điều này loại bỏ nhu cầu cho người triển khai
trait phải chỉ định một kiểu cụ thể nếu kiểu mặc định hoạt động. Bạn chỉ định
một kiểu mặc định khi khai báo một kiểu generic với cú pháp
<PlaceholderType=ConcreteType>.
Một ví dụ tuyệt vời về tình huống mà kỹ thuật này hữu ích là với nạp chồng toán
tử, trong đó bạn tùy chỉnh hành vi của một toán tử (như +) trong các tình
huống cụ thể.
Rust không cho phép bạn tạo các toán tử của riêng mình hoặc nạp chồng các toán
tử tùy ý. Nhưng bạn có thể nạp chồng các hoạt động và các trait tương ứng được
liệt kê trong std::ops bằng cách triển khai các trait liên quan đến toán tử.
Ví dụ, trong Listing 20-15, chúng ta nạp chồng toán tử + để cộng hai thể hiện
Point với nhau. Chúng ta làm điều này bằng cách triển khai trait Add trên
struct Point.
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!( Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 } ); }
Phương thức add cộng các giá trị x của hai thể hiện Point và các giá trị
y của hai thể hiện Point để tạo ra một Point mới. Trait Add có một kiểu
liên kết có tên là Output xác định kiểu trả về từ phương thức add.
Kiểu generic mặc định trong mã này nằm trong trait Add. Đây là định nghĩa của
nó:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
Mã này có vẻ quen thuộc: một trait với một phương thức và một kiểu liên kết.
Phần mới là Rhs=Self: cú pháp này được gọi là tham số kiểu mặc định. Tham số
kiểu generic Rhs (viết tắt của "right-hand side") định nghĩa kiểu của tham số
rhs trong phương thức add. Nếu chúng ta không chỉ định một kiểu cụ thể cho
Rhs khi triển khai trait Add, kiểu của Rhs sẽ mặc định là Self, là kiểu
mà chúng ta đang triển khai Add trên đó.
Khi chúng ta triển khai Add cho Point, chúng ta đã sử dụng giá trị mặc định
cho Rhs bởi vì chúng ta muốn cộng hai thể hiện Point. Hãy xem xét một ví dụ
về việc triển khai trait Add trong đó chúng ta muốn tùy chỉnh kiểu Rhs thay
vì sử dụng giá trị mặc định.
Chúng ta có hai struct, Millimeters và Meters, chứa các giá trị trong các
đơn vị khác nhau. Việc bọc mỏng của một kiểu hiện có trong một struct khác được
gọi là mẫu newtype, mà chúng ta mô tả chi tiết hơn trong phần "Sử Dụng Mẫu
Newtype để Triển Khai Trait Bên Ngoài trên Kiểu Bên
Ngoài". Chúng ta muốn cộng các giá trị tính bằng
milimet với các giá trị tính bằng mét và có triển khai của Add thực hiện
chuyển đổi một cách chính xác. Chúng ta có thể triển khai Add cho
Millimeters với Meters là Rhs, như hiển thị trong Listing 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Để cộng Millimeters và Meters, chúng ta chỉ định impl Add<Meters> để đặt
giá trị của tham số kiểu Rhs thay vì sử dụng giá trị mặc định là Self.
Bạn sẽ sử dụng các tham số kiểu mặc định theo hai cách chính:
- Để mở rộng một kiểu mà không phá vỡ mã hiện có
- Để cho phép tùy chỉnh trong các trường hợp cụ thể mà hầu hết người dùng không cần
Trait Add của thư viện chuẩn là một ví dụ cho mục đích thứ hai: thông thường,
bạn sẽ cộng hai kiểu giống nhau, nhưng trait Add cung cấp khả năng tùy chỉnh
vượt ra ngoài điều đó. Sử dụng một tham số kiểu mặc định trong định nghĩa trait
Add có nghĩa là bạn không phải chỉ định tham số bổ sung trong hầu hết các
trường hợp. Nói cách khác, một chút mã soạn sẵn triển khai không cần thiết, làm
cho việc sử dụng trait dễ dàng hơn.
Mục đích đầu tiên tương tự như mục đích thứ hai nhưng ngược lại: nếu bạn muốn thêm một tham số kiểu vào một trait hiện có, bạn có thể cho nó một giá trị mặc định để cho phép mở rộng chức năng của trait mà không phá vỡ mã triển khai hiện có.
Phân Biệt Giữa Các Phương Thức Có Cùng Tên
Không có gì trong Rust ngăn cản một trait có một phương thức có cùng tên với phương thức của trait khác, Rust cũng không ngăn bạn triển khai cả hai trait trên một kiểu. Cũng có thể triển khai một phương thức trực tiếp trên kiểu với cùng tên như các phương thức từ các trait.
Khi gọi các phương thức có cùng tên, bạn cần phải nói cho Rust biết bạn muốn sử
dụng cái nào. Xem xét mã trong Listing 20-17 trong đó chúng ta đã định nghĩa hai
trait, Pilot và Wizard, cả hai đều có một phương thức được gọi là fly. Sau
đó, chúng ta triển khai cả hai trait trên một kiểu Human đã có một phương thức
tên là fly được triển khai trên nó. Mỗi phương thức fly làm một điều gì đó
khác nhau.
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() {}
Khi chúng ta gọi fly trên một thể hiện của Human, trình biên dịch mặc định
gọi phương thức được triển khai trực tiếp trên kiểu, như hiển thị trong Listing
20-18.
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; person.fly(); }
Chạy mã này sẽ in ra *waving arms furiously*, cho thấy Rust đã gọi phương thức
fly được triển khai trực tiếp trên Human.
Để gọi các phương thức fly từ trait Pilot hoặc trait Wizard, chúng ta cần
sử dụng cú pháp rõ ràng hơn để chỉ định phương thức fly nào chúng ta muốn.
Listing 20-19 minh họa cú pháp này.
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; Pilot::fly(&person); Wizard::fly(&person); person.fly(); }
Chỉ định tên trait trước tên phương thức làm rõ cho Rust biết chúng ta muốn gọi
triển khai fly nào. Chúng ta cũng có thể viết Human::fly(&person), tương
đương với person.fly() mà chúng ta đã sử dụng trong Listing 20-19, nhưng điều
này dài hơn một chút nếu chúng ta không cần phân biệt.
Chạy mã này in ra như sau:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Bởi vì phương thức fly nhận một tham số self, nếu chúng ta có hai kiểu đều
triển khai một trait, Rust có thể xác định triển khai nào của trait sẽ được sử
dụng dựa trên kiểu của self.
Tuy nhiên, các hàm liên kết không phải là phương thức không có tham số self.
Khi có nhiều kiểu hoặc trait định nghĩa các hàm không phải phương thức với cùng
tên hàm, Rust không phải lúc nào cũng biết bạn muốn ý nghĩa kiểu nào trừ khi bạn
sử dụng cú pháp đầy đủ. Ví dụ, trong Listing 20-20, chúng ta tạo một trait cho
một nơi trú ẩn động vật muốn đặt tên cho tất cả chó con là Spot. Chúng ta tạo
một trait Animal với một hàm liên kết không phải phương thức baby_name.
Trait Animal được triển khai cho struct Dog, trên đó chúng ta cũng cung cấp
một hàm liên kết không phải phương thức baby_name trực tiếp.
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
Chúng ta triển khai mã để đặt tên cho tất cả chó con là Spot trong hàm liên kết
baby_name được định nghĩa trên Dog. Kiểu Dog cũng triển khai trait
Animal, mô tả các đặc điểm mà tất cả động vật có. Chó con được gọi là puppies,
và điều đó được thể hiện trong việc triển khai trait Animal trên Dog trong
hàm baby_name liên kết với trait Animal.
Trong main, chúng ta gọi hàm Dog::baby_name, hàm này gọi hàm liên kết được
định nghĩa trực tiếp trên Dog. Mã này in ra:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Đầu ra này không phải là những gì chúng ta muốn. Chúng ta muốn gọi hàm
baby_name là một phần của trait Animal mà chúng ta đã triển khai trên Dog
để mã in ra A baby dog is called a puppy. Kỹ thuật chỉ định tên trait mà chúng
ta đã sử dụng trong Listing 20-19 không giúp ích ở đây; nếu chúng ta thay đổi
main thành mã trong Listing 20-21, chúng ta sẽ nhận được lỗi biên dịch.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}Bởi vì Animal::baby_name không có tham số self, và có thể có các kiểu khác
triển khai trait Animal, Rust không thể xác định triển khai
Animal::baby_name nào chúng ta muốn. Chúng ta sẽ nhận được lỗi trình biên dịch
này:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
Để loại bỏ sự không rõ ràng và nói cho Rust biết rằng chúng ta muốn sử dụng
triển khai của Animal cho Dog thay vì triển khai của Animal cho một số
kiểu khác, chúng ta cần sử dụng cú pháp đầy đủ. Listing 20-22 minh họa cách sử
dụng cú pháp đầy đủ.
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
Chúng ta đang cung cấp cho Rust một chú thích kiểu trong dấu ngoặc nhọn, cho
biết chúng ta muốn gọi phương thức baby_name từ trait Animal như được triển
khai trên Dog bằng cách nói rằng chúng ta muốn coi kiểu Dog như một Animal
cho lệnh gọi hàm này. Mã này giờ đây sẽ in ra những gì chúng ta muốn:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
Nhìn chung, cú pháp đầy đủ được định nghĩa như sau:
<Type as Trait>::function(receiver_if_method, next_arg, ...);Đối với các hàm liên kết không phải phương thức, sẽ không có receiver: sẽ chỉ
có danh sách các đối số khác. Bạn có thể sử dụng cú pháp đầy đủ ở mọi nơi mà bạn
gọi hàm hoặc phương thức. Tuy nhiên, bạn được phép bỏ qua bất kỳ phần nào của cú
pháp này mà Rust có thể tìm ra từ thông tin khác trong chương trình. Bạn chỉ cần
sử dụng cú pháp dài dòng hơn này trong các trường hợp có nhiều triển khai sử
dụng cùng một tên và Rust cần trợ giúp để xác định triển khai nào bạn muốn gọi.
Sử Dụng Supertraits
Đôi khi bạn có thể viết một định nghĩa trait phụ thuộc vào một trait khác: để một kiểu triển khai trait đầu tiên, bạn muốn yêu cầu kiểu đó cũng phải triển khai trait thứ hai. Bạn sẽ làm điều này để định nghĩa trait của bạn có thể sử dụng các phần tử liên kết của trait thứ hai. Trait mà định nghĩa trait của bạn dựa vào được gọi là supertrait của trait của bạn.
Ví dụ, giả sử chúng ta muốn tạo một trait OutlinePrint với một phương thức
outline_print sẽ in một giá trị đã cho được định dạng để nó được đóng khung
bằng dấu hoa thị. Nghĩa là, với một struct Point triển khai trait Display
của thư viện chuẩn để có kết quả là (x, y), khi chúng ta gọi outline_print
trên một thể hiện Point có 1 cho x và 3 cho y, nó sẽ in ra:
**********
* *
* (1, 3) *
* *
**********
Trong việc triển khai phương thức outline_print, chúng ta muốn sử dụng chức
năng của trait Display. Do đó, chúng ta cần chỉ định rằng trait OutlinePrint
sẽ chỉ hoạt động cho các kiểu cũng triển khai Display và cung cấp chức năng mà
OutlinePrint cần. Chúng ta có thể làm điều đó trong định nghĩa trait bằng cách
chỉ định OutlinePrint: Display. Kỹ thuật này tương tự như việc thêm một ràng
buộc trait cho trait. Listing 20-23 cho thấy một triển khai của trait
OutlinePrint.
use std::fmt; trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } fn main() {}
Bởi vì chúng ta đã chỉ định rằng OutlinePrint yêu cầu trait Display, chúng
ta có thể sử dụng hàm to_string được tự động triển khai cho bất kỳ kiểu nào
triển khai Display. Nếu chúng ta cố gắng sử dụng to_string mà không thêm dấu
hai chấm và chỉ định trait Display sau tên trait, chúng ta sẽ gặp lỗi nói rằng
không tìm thấy phương thức nào có tên là to_string cho kiểu &Self trong phạm
vi hiện tại.
Hãy xem điều gì xảy ra khi chúng ta cố gắng triển khai OutlinePrint trên một
kiểu không triển khai Display, chẳng hạn như struct Point:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Chúng ta nhận được lỗi nói rằng Display là cần thiết nhưng không được triển
khai:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Để sửa lỗi này, chúng ta triển khai Display trên Point và thỏa mãn ràng buộc
mà OutlinePrint yêu cầu, như sau:
trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Point { x: 1, y: 3 }; p.outline_print(); }
Sau đó, việc triển khai trait OutlinePrint trên Point sẽ biên dịch thành
công, và chúng ta có thể gọi outline_print trên một thể hiện Point để hiển
thị nó trong một đường viền dấu hoa thị.
Sử Dụng Mẫu Newtype để Triển Khai Trait Bên Ngoài trên Kiểu Bên Ngoài
Trong "Triển Khai một Trait trên một Kiểu" ở Chương 10, chúng ta đã đề cập đến quy tắc orphan nói rằng chúng ta chỉ được phép triển khai một trait trên một kiểu nếu một trong hai trait hoặc kiểu, hoặc cả hai, là cục bộ đối với crate của chúng ta. Có thể vượt qua hạn chế này bằng cách sử dụng mẫu newtype, liên quan đến việc tạo một kiểu mới trong một tuple struct. (Chúng ta đã đề cập đến tuple struct trong "Sử Dụng Tuple Structs Không Có Trường Đặt Tên để Tạo Các Kiểu Khác Nhau" ở Chương 5.) Tuple struct sẽ có một trường và là một bản bọc mỏng xung quanh kiểu mà chúng ta muốn triển khai trait. Sau đó, kiểu bọc sẽ là cục bộ đối với crate của chúng ta, và chúng ta có thể triển khai trait trên bản bọc. Newtype là một thuật ngữ có nguồn gốc từ ngôn ngữ lập trình Haskell. Không có mất mát hiệu suất thời gian chạy khi sử dụng mẫu này, và kiểu bọc được loại bỏ tại thời điểm biên dịch.
Ví dụ, giả sử chúng ta muốn triển khai Display trên Vec<T>, mà quy tắc
orphan ngăn chúng ta làm trực tiếp vì trait Display và kiểu Vec<T> được định
nghĩa bên ngoài crate của chúng ta. Chúng ta có thể tạo một struct Wrapper
chứa một thể hiện của Vec<T>; sau đó chúng ta có thể triển khai Display trên
Wrapper và sử dụng giá trị Vec<T>, như hiển thị trong Listing 20-24.
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {w}"); }
Triển khai của Display sử dụng self.0 để truy cập Vec<T> bên trong, vì
Wrapper là một tuple struct và Vec<T> là phần tử ở chỉ số 0 trong tuple. Sau
đó, chúng ta có thể sử dụng chức năng của trait Display trên Wrapper.
Nhược điểm của việc sử dụng kỹ thuật này là Wrapper là một kiểu mới, vì vậy nó
không có các phương thức của giá trị mà nó đang giữ. Chúng ta sẽ phải triển khai
trực tiếp tất cả các phương thức của Vec<T> trên Wrapper sao cho các phương
thức ủy quyền cho self.0, điều này sẽ cho phép chúng ta đối xử với Wrapper
chính xác như một Vec<T>. Nếu chúng ta muốn kiểu mới có mọi phương thức mà
kiểu bên trong có, việc triển khai trait Deref trên Wrapper để trả về kiểu
bên trong sẽ là một giải pháp (chúng ta đã thảo luận về việc triển khai trait
Deref trong "Đối Xử với Smart Pointers Như Tham Chiếu Thông Thường với Trait
Deref" ở Chương 15). Nếu chúng ta không
muốn kiểu Wrapper có tất cả các phương thức của kiểu bên trong — ví dụ, để hạn
chế hành vi của kiểu Wrapper — chúng ta sẽ phải tự triển khai các phương thức
mà chúng ta muốn.
Mẫu newtype này cũng hữu ích ngay cả khi các trait không liên quan. Hãy chuyển sang xem xét một số cách tiên tiến để tương tác với hệ thống kiểu của Rust.
Kiểu Dữ Liệu Nâng Cao
Hệ thống kiểu dữ liệu của Rust có một số tính năng mà chúng ta đã đề cập nhưng
chưa thảo luận chi tiết. Chúng ta sẽ bắt đầu bằng việc thảo luận về newtype nói
chung khi chúng ta xem xét tại sao newtype là kiểu dữ liệu hữu ích. Sau đó,
chúng ta sẽ chuyển sang bí danh kiểu (type aliases), một tính năng tương tự như
newtype nhưng có ngữ nghĩa hơi khác một chút. Chúng ta cũng sẽ thảo luận về kiểu
! và các kiểu có kích thước động.
Sử Dụng Mẫu Newtype cho An Toàn Kiểu và Trừu Tượng Hóa
Phần này giả định bạn đã đọc phần trước "Sử Dụng Mẫu Newtype để Triển Khai
Trait Bên Ngoài trên Kiểu Bên
Ngoài.". Mẫu newtype cũng hữu ích cho
các nhiệm vụ ngoài những gì chúng ta đã thảo luận cho đến nay, bao gồm việc đảm
bảo tĩnh rằng các giá trị không bao giờ bị nhầm lẫn và chỉ ra đơn vị của một giá
trị. Bạn đã thấy một ví dụ về việc sử dụng newtype để chỉ ra đơn vị trong
Listing 20-16: nhớ lại rằng các struct Millimeters và Meters bọc các giá trị
u32 trong một newtype. Nếu chúng ta viết một hàm với tham số có kiểu
Millimeters, chúng ta sẽ không thể biên dịch một chương trình mà vô tình cố
gắng gọi hàm đó với một giá trị có kiểu Meters hoặc một u32 đơn giản.
Chúng ta cũng có thể sử dụng mẫu newtype để trừu tượng hóa một số chi tiết triển khai của một kiểu: kiểu mới có thể hiển thị một API công khai khác với API của kiểu bên trong riêng tư.
Newtype cũng có thể ẩn triển khai nội bộ. Ví dụ, chúng ta có thể cung cấp một
kiểu People để bọc một HashMap<i32, String> lưu trữ ID của một người kết hợp
với tên của họ. Mã sử dụng People sẽ chỉ tương tác với API công khai mà chúng
ta cung cấp, chẳng hạn như một phương thức để thêm một chuỗi tên vào bộ sưu tập
People; mã đó sẽ không cần biết rằng chúng ta gán một ID i32 cho tên một
cách nội bộ. Mẫu newtype là một cách nhẹ nhàng để đạt được sự đóng gói để ẩn chi
tiết triển khai, điều mà chúng ta đã thảo luận trong "Đóng Gói ẩn chi tiết
triển khai"
trong Chương 18.
Tạo Đồng Nghĩa Kiểu với Bí Danh Kiểu
Rust cung cấp khả năng khai báo một bí danh kiểu để đặt tên khác cho một kiểu
hiện có. Đối với điều này, chúng ta sử dụng từ khóa type. Ví dụ, chúng ta có
thể tạo bí danh Kilometers cho i32 như sau:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Bây giờ, bí danh Kilometers là một từ đồng nghĩa cho i32; không giống như
các kiểu Millimeters và Meters mà chúng ta đã tạo trong Listing 20-16,
Kilometers không phải là một kiểu mới, riêng biệt. Các giá trị có kiểu
Kilometers sẽ được xử lý giống như các giá trị kiểu i32:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Bởi vì Kilometers và i32 là cùng một kiểu, chúng ta có thể cộng các giá trị
của cả hai kiểu và chúng ta có thể truyền các giá trị Kilometers cho các hàm
nhận tham số i32. Tuy nhiên, khi sử dụng phương pháp này, chúng ta không nhận
được lợi ích kiểm tra kiểu mà chúng ta nhận được từ mẫu newtype đã thảo luận
trước đó. Nói cách khác, nếu chúng ta nhầm lẫn giữa các giá trị Kilometers và
i32 ở đâu đó, trình biên dịch sẽ không đưa ra lỗi.
Trường hợp sử dụng chính cho bí danh kiểu là giảm sự lặp lại. Ví dụ, chúng ta có thể có một kiểu dài như thế này:
Box<dyn Fn() + Send + 'static>Viết kiểu dài này trong chữ ký hàm và chú thích kiểu trên khắp mã có thể nhàm chán và dễ gây lỗi. Hãy tưởng tượng có một dự án đầy mã như trong Listing 20-25.
fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --snip-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --snip-- Box::new(|| ()) } }
Một bí danh kiểu làm cho mã này dễ quản lý hơn bằng cách giảm sự lặp lại. Trong
Listing 20-26, chúng ta đã giới thiệu một bí danh có tên Thunk cho kiểu dài
dòng và có thể thay thế tất cả các sử dụng của kiểu đó bằng bí danh ngắn gọn hơn
Thunk.
fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --snip-- } fn returns_long_type() -> Thunk { // --snip-- Box::new(|| ()) } }
Mã này dễ đọc và viết hơn nhiều! Việc chọn một tên có ý nghĩa cho bí danh kiểu có thể giúp truyền đạt ý định của bạn (thunk là một từ chỉ mã được đánh giá vào thời điểm sau, vì vậy đó là một tên thích hợp cho một closure được lưu trữ).
Bí danh kiểu cũng thường được sử dụng với kiểu Result<T, E> để giảm sự lặp
lại. Xem xét module std::io trong thư viện chuẩn. Các hoạt động I/O thường trả
về một Result<T, E> để xử lý các tình huống khi các hoạt động không thành
công. Thư viện này có một struct std::io::Error đại diện cho tất cả các lỗi
I/O có thể xảy ra. Nhiều hàm trong std::io sẽ trả về Result<T, E> trong đó
E là std::io::Error, chẳng hạn như các hàm trong trait Write:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Result<..., Error> được lặp lại rất nhiều. Do đó, std::io có khai báo bí
danh kiểu này:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Vì khai báo này nằm trong module std::io, chúng ta có thể sử dụng bí danh đầy
đủ std::io::Result<T>; đó là một Result<T, E> với E được điền là
std::io::Error. Chữ ký hàm của trait Write cuối cùng trông như thế này:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Bí danh kiểu giúp ích theo hai cách: nó làm cho mã dễ viết hơn và cung cấp cho
chúng ta một giao diện nhất quán trên toàn bộ std::io. Bởi vì nó là một bí
danh, nó chỉ là một Result<T, E> khác, có nghĩa là chúng ta có thể sử dụng bất
kỳ phương thức nào hoạt động với Result<T, E> với nó, cũng như cú pháp đặc
biệt như toán tử ?.
Kiểu Never Không Bao Giờ Trả Về
Rust có một kiểu đặc biệt có tên là ! được biết đến trong thuật ngữ lý thuyết
kiểu là kiểu rỗng vì nó không có giá trị. Chúng ta thích gọi nó là kiểu
never vì nó đứng ở vị trí của kiểu trả về khi một hàm không bao giờ trả về. Đây
là một ví dụ:
fn bar() -> ! {
// --snip--
panic!();
}Mã này được đọc là "hàm bar không bao giờ trả về." Các hàm không bao giờ trả
về được gọi là hàm phân kỳ. Chúng ta không thể tạo giá trị của kiểu ! nên
bar không thể trả về.
Nhưng ích lợi gì của một kiểu mà bạn không bao giờ có thể tạo giá trị cho nó? Nhớ lại mã từ Listing 2-5, một phần của trò chơi đoán số; chúng ta đã tái hiện một phần của nó ở đây trong Listing 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Tại thời điểm đó, chúng ta đã bỏ qua một số chi tiết trong mã này. Trong "Toán
Tử Điều Khiển Luồng match"
trong Chương 6, chúng ta đã thảo luận rằng các nhánh của match phải trả về
cùng một kiểu. Vì vậy, ví dụ, mã sau đây không hoạt động:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}Kiểu của guess trong mã này sẽ phải là một số nguyên và một chuỗi, và Rust
yêu cầu guess chỉ có một kiểu. Vậy continue trả về gì? Làm thế nào mà chúng
ta được phép trả về một u32 từ một nhánh và có một nhánh khác kết thúc bằng
continue trong Listing 20-27?
Như bạn có thể đã đoán, continue có một giá trị !. Nghĩa là, khi Rust tính
toán kiểu của guess, nó xem xét cả hai nhánh match, nhánh trước với giá trị
u32 và nhánh sau với giá trị !. Bởi vì ! không bao giờ có thể có một giá
trị, Rust quyết định rằng kiểu của guess là u32.
Cách chính thức để mô tả hành vi này là các biểu thức của kiểu ! có thể được
ép buộc vào bất kỳ kiểu nào khác. Chúng ta được phép kết thúc nhánh match này
với continue bởi vì continue không trả về giá trị; thay vào đó, nó chuyển
điều khiển trở lại đầu vòng lặp, vì vậy trong trường hợp Err, chúng ta không
bao giờ gán giá trị cho guess.
Kiểu never cũng hữu ích với macro panic!. Nhớ lại hàm unwrap mà chúng ta gọi
trên các giá trị Option<T> để tạo ra một giá trị hoặc gây panic với định nghĩa
này:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}Trong mã này, điều tương tự xảy ra như trong match ở Listing 20-27: Rust thấy
rằng val có kiểu T và panic! có kiểu !, vì vậy kết quả của toàn bộ biểu
thức match là T. Mã này hoạt động bởi vì panic! không tạo ra một giá trị;
nó kết thúc chương trình. Trong trường hợp None, chúng ta sẽ không trả về giá
trị từ unwrap, vì vậy mã này hợp lệ.
Một biểu thức cuối cùng có kiểu ! là vòng lặp loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Ở đây, vòng lặp không bao giờ kết thúc, vì vậy ! là giá trị của biểu thức. Tuy
nhiên, điều này sẽ không đúng nếu chúng ta đưa vào một break, bởi vì vòng lặp
sẽ kết thúc khi nó đến break.
Kiểu Có Kích Thước Động và Trait Sized
Rust cần biết một số chi tiết về các kiểu của nó, chẳng hạn như cần bao nhiêu không gian để cấp phát cho một giá trị của một kiểu cụ thể. Điều này để lại một góc của hệ thống kiểu hơi khó hiểu lúc đầu: khái niệm về kiểu có kích thước động. Đôi khi được gọi là DST hoặc kiểu không có kích thước, những kiểu này cho phép chúng ta viết mã sử dụng các giá trị mà chúng ta chỉ có thể biết kích thước vào thời điểm chạy.
Hãy đi sâu vào chi tiết của một kiểu có kích thước động có tên là str, mà
chúng ta đã sử dụng trong suốt cuốn sách. Đúng vậy, không phải &str, mà là
str tự nó, là một DST. Chúng ta không thể biết chuỗi dài bao nhiêu cho đến
thời điểm chạy, có nghĩa là chúng ta không thể tạo một biến kiểu str, cũng
không thể nhận một đối số kiểu str. Xem xét mã sau, mã này không hoạt động:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust cần biết cần cấp phát bao nhiêu bộ nhớ cho bất kỳ giá trị nào của một kiểu
cụ thể, và tất cả các giá trị của một kiểu phải sử dụng cùng một lượng bộ nhớ.
Nếu Rust cho phép chúng ta viết mã này, hai giá trị str này sẽ cần chiếm cùng
một lượng không gian. Nhưng chúng có độ dài khác nhau: s1 cần 12 byte lưu trữ
và s2 cần 15. Đó là lý do tại sao không thể tạo một biến chứa một kiểu có kích
thước động.
Vậy chúng ta làm gì? Trong trường hợp này, bạn đã biết câu trả lời: chúng ta làm
cho kiểu của s1 và s2 là &str thay vì str. Nhớ lại từ "Slice
Chuỗi" trong Chương 4 rằng cấu trúc dữ liệu slice
chỉ lưu trữ vị trí bắt đầu và độ dài của slice. Vì vậy, mặc dù một &T là một
giá trị đơn lẻ lưu trữ địa chỉ bộ nhớ của nơi T nằm, một &str là hai giá
trị: địa chỉ của str và độ dài của nó. Do đó, chúng ta có thể biết kích thước
của một giá trị &str tại thời điểm biên dịch: nó gấp đôi độ dài của một
usize. Nghĩa là, chúng ta luôn biết kích thước của một &str, dù chuỗi mà nó
tham chiếu đến dài bao nhiêu. Nói chung, đây là cách mà các kiểu có kích thước
động được sử dụng trong Rust: chúng có một bit siêu dữ liệu bổ sung lưu trữ kích
thước của thông tin động. Quy tắc vàng của các kiểu có kích thước động là chúng
ta phải luôn đặt các giá trị của kiểu có kích thước động sau một con trỏ nào đó.
Chúng ta có thể kết hợp str với tất cả các loại con trỏ: ví dụ, Box<str>
hoặc Rc<str>. Thực tế, bạn đã thấy điều này trước đây nhưng với một kiểu có
kích thước động khác: trait. Mỗi trait là một kiểu có kích thước động mà chúng
ta có thể tham chiếu bằng cách sử dụng tên của trait. Trong "Sử Dụng Đối Tượng
Trait Cho Phép Cho Giá Trị Của Các Kiểu Khác
Nhau"
trong Chương 18, chúng ta đã đề cập rằng để sử dụng trait làm đối tượng trait,
chúng ta phải đặt chúng sau một con trỏ, chẳng hạn như &dyn Trait hoặc
Box<dyn Trait> (Rc<dyn Trait> cũng sẽ hoạt động).
Để làm việc với DST, Rust cung cấp trait Sized để xác định liệu kích thước của
một kiểu có được biết tại thời điểm biên dịch hay không. Trait này được tự động
triển khai cho mọi thứ có kích thước được biết tại thời điểm biên dịch. Ngoài
ra, Rust ngầm thêm một ràng buộc về Sized vào mọi hàm generic. Nghĩa là, một
định nghĩa hàm generic như thế này:
fn generic<T>(t: T) {
// --snip--
}thực tế được xử lý như thể chúng ta đã viết điều này:
fn generic<T: Sized>(t: T) {
// --snip--
}Theo mặc định, các hàm generic sẽ chỉ hoạt động trên các kiểu có kích thước đã biết tại thời điểm biên dịch. Tuy nhiên, bạn có thể sử dụng cú pháp đặc biệt sau đây để nới lỏng hạn chế này:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}Một ràng buộc trait trên ?Sized có nghĩa là "T có thể hoặc có thể không là
Sized" và ký hiệu này ghi đè mặc định rằng các kiểu generic phải có kích thước
đã biết tại thời điểm biên dịch. Cú pháp ?Trait với ý nghĩa này chỉ có sẵn cho
Sized, không cho bất kỳ trait nào khác.
Cũng lưu ý rằng chúng ta đã chuyển kiểu của tham số t từ T sang &T. Bởi vì
kiểu có thể không phải là Sized, chúng ta cần sử dụng nó sau một loại con trỏ
nào đó. Trong trường hợp này, chúng ta đã chọn một tham chiếu.
Tiếp theo, chúng ta sẽ nói về các hàm và closure!
Hàm và Closure Nâng Cao
Phần này khám phá một số tính năng nâng cao liên quan đến hàm và closure, bao gồm con trỏ hàm và trả về closure.
Con Trỏ Hàm
Chúng ta đã nói về cách truyền closure cho các hàm; bạn cũng có thể truyền các
hàm thông thường cho hàm! Kỹ thuật này hữu ích khi bạn muốn truyền một hàm bạn
đã định nghĩa thay vì định nghĩa một closure mới. Hàm được ép kiểu thành kiểu
fn (với f viết thường), không nên nhầm lẫn với trait closure Fn. Kiểu fn
được gọi là con trỏ hàm. Truyền hàm với con trỏ hàm sẽ cho phép bạn sử dụng
hàm làm đối số cho các hàm khác.
Cú pháp để chỉ định rằng một tham số là con trỏ hàm tương tự như của closure,
như được hiển thị trong Listing 20-28, nơi chúng ta đã định nghĩa một hàm
add_one để cộng 1 vào tham số của nó. Hàm do_twice nhận hai tham số: một con
trỏ hàm tới bất kỳ hàm nào nhận một tham số i32 và trả về một i32, và một
giá trị i32. Hàm do_twice gọi hàm f hai lần, truyền cho nó giá trị arg,
sau đó cộng hai kết quả gọi hàm lại với nhau. Hàm main gọi do_twice với các
đối số add_one và 5.
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {answer}"); }
Mã này in ra The answer is: 12. Chúng ta chỉ định rằng tham số f trong
do_twice là một fn nhận một tham số kiểu i32 và trả về một i32. Sau đó,
chúng ta có thể gọi f trong thân hàm của do_twice. Trong main, chúng ta có
thể truyền tên hàm add_one làm đối số đầu tiên cho do_twice.
Không giống như closure, fn là một kiểu chứ không phải một trait, vì vậy chúng
ta chỉ định fn làm kiểu tham số trực tiếp thay vì khai báo một tham số kiểu
generic với một trong các trait Fn làm ràng buộc trait.
Con trỏ hàm triển khai cả ba trait closure (Fn, FnMut, và FnOnce), có
nghĩa là bạn luôn có thể truyền con trỏ hàm làm đối số cho một hàm mà mong đợi
một closure. Tốt nhất là viết các hàm sử dụng một kiểu generic và một trong các
trait closure để hàm của bạn có thể chấp nhận cả hàm hoặc closure.
Dù vậy, một ví dụ về trường hợp bạn muốn chỉ chấp nhận fn và không chấp nhận
closure là khi giao tiếp với mã bên ngoài không có closure: Các hàm C có thể
chấp nhận hàm làm đối số, nhưng C không có closure.
Để xem ví dụ về nơi bạn có thể sử dụng một closure được định nghĩa inline hoặc
một hàm có tên, hãy xem xét việc sử dụng phương thức map được cung cấp bởi
trait Iterator trong thư viện chuẩn. Để sử dụng phương thức map để biến một
vector số thành một vector chuỗi, chúng ta có thể sử dụng một closure, như trong
Listing 20-29.
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(|i| i.to_string()).collect(); }
Hoặc chúng ta có thể đặt tên một hàm làm đối số cho map thay vì closure.
Listing 20-30 cho thấy điều này sẽ trông như thế nào.
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(ToString::to_string).collect(); }
Lưu ý rằng chúng ta phải sử dụng cú pháp đầy đủ mà chúng ta đã nói trong "Trait
Nâng Cao" bởi vì có nhiều hàm có sẵn có tên là
to_string.
Ở đây, chúng ta đang sử dụng hàm to_string được định nghĩa trong trait
ToString, mà thư viện chuẩn đã triển khai cho bất kỳ kiểu nào triển khai
Display.
Nhớ lại từ "Giá trị Enum" trong Chương 6 rằng tên của mỗi biến thể enum mà chúng ta định nghĩa cũng trở thành một hàm khởi tạo. Chúng ta có thể sử dụng các hàm khởi tạo này làm con trỏ hàm triển khai các trait closure, điều này có nghĩa là chúng ta có thể chỉ định các hàm khởi tạo làm đối số cho các phương thức nhận closure, như được thấy trong Listing 20-31.
fn main() { enum Status { Value(u32), Stop, } let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect(); }
Ở đây, chúng ta tạo các thể hiện Status::Value bằng cách sử dụng mỗi giá trị
u32 trong phạm vi mà map được gọi bằng cách sử dụng hàm khởi tạo của
Status::Value. Một số người thích phong cách này và một số người thích sử dụng
closure. Chúng được biên dịch thành cùng một mã, vì vậy hãy sử dụng phong cách
nào rõ ràng hơn với bạn.
Trả Về Closure
Closure được biểu diễn bởi các trait, có nghĩa là bạn không thể trả về closure
trực tiếp. Trong hầu hết các trường hợp mà bạn có thể muốn trả về một trait, bạn
có thể thay vào đó sử dụng kiểu cụ thể triển khai trait đó làm giá trị trả về
của hàm. Tuy nhiên, bạn thường không thể làm điều đó với closure vì chúng không
có kiểu cụ thể có thể trả về; bạn không được phép sử dụng con trỏ hàm fn làm
kiểu trả về nếu closure bắt bất kỳ giá trị nào từ phạm vi của nó, chẳng hạn.
Thay vào đó, bạn thường sẽ sử dụng cú pháp impl Trait mà chúng ta đã học trong
Chương 10. Bạn có thể trả về bất kỳ kiểu hàm nào, sử dụng Fn, FnOnce và
FnMut. Ví dụ, mã trong Listing 20-32 sẽ biên dịch tốt.
#![allow(unused)] fn main() { fn returns_closure() -> impl Fn(i32) -> i32 { |x| x + 1 } }
Tuy nhiên, như chúng ta đã lưu ý trong "Suy Luận Kiểu và Chú Thích Closure" trong Chương 13, mỗi closure cũng là kiểu riêng biệt của nó. Nếu bạn cần làm việc với nhiều hàm có cùng chữ ký nhưng các triển khai khác nhau, bạn sẽ cần sử dụng đối tượng trait cho chúng. Hãy xem xét điều gì xảy ra nếu bạn viết mã như trong Listing 20-33.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Ở đây chúng ta có hai hàm, returns_closure và returns_initialized_closure,
cả hai đều trả về impl Fn(i32) -> i32. Lưu ý rằng các closure mà chúng trả về
là khác nhau, mặc dù chúng triển khai cùng một kiểu. Nếu chúng ta cố gắng biên
dịch điều này, Rust cho chúng ta biết rằng nó sẽ không hoạt động:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
Thông báo lỗi cho chúng ta biết rằng bất cứ khi nào chúng ta trả về một
impl Trait, Rust tạo ra một kiểu mờ duy nhất, một kiểu mà chúng ta không thể
nhìn vào chi tiết của những gì Rust xây dựng cho chúng ta, cũng như không thể
đoán kiểu mà Rust sẽ tạo ra để tự viết. Vì vậy, mặc dù cả hai hàm này đều trả về
closure triển khai cùng một trait, Fn(i32) -> i32, các kiểu mờ mà Rust tạo ra
cho mỗi hàm là khác biệt. (Điều này tương tự như cách Rust tạo ra các kiểu cụ
thể khác nhau cho các khối async riêng biệt ngay cả khi chúng có cùng kiểu đầu
ra, như chúng ta đã thấy trong "Làm việc với Bất kỳ Số Lượng
Futures" trong Chương 17.) Chúng ta đã
thấy một giải pháp cho vấn đề này vài lần: chúng ta có thể sử dụng một đối tượng
trait, như trong Listing 20-34.
fn main() { let handlers = vec![returns_closure(), returns_initialized_closure(123)]; for handler in handlers { let output = handler(5); println!("{output}"); } } fn returns_closure() -> Box<dyn Fn(i32) -> i32> { Box::new(|x| x + 1) } fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> { Box::new(move |x| x + init) }
Mã này sẽ biên dịch tốt. Để biết thêm về đối tượng trait, hãy tham khảo phần ["Sử Dụng Đối Tượng Trait Cho Phép Cho Giá Trị Của Các Kiểu Khác Nhau"][using-trait-objects-that-allow-for-values-of-different-types] trong Chương 18.
Tiếp theo, hãy xem xét các macro!
Macro
Chúng ta đã sử dụng các macro như println! trong suốt cuốn sách này, nhưng
chúng ta chưa khám phá đầy đủ về macro là gì và cách nó hoạt động. Thuật ngữ
macro đề cập đến một họ các tính năng trong Rust: macro khai báo với
macro_rules! và ba loại macro thủ tục:
- Macro
#[derive]tùy chỉnh chỉ định mã được thêm vào với thuộc tínhderiveđược sử dụng trên các struct và enum - Macro giống thuộc tính định nghĩa các thuộc tính tùy chỉnh có thể sử dụng trên bất kỳ mục nào
- Macro giống hàm trông giống như lời gọi hàm nhưng hoạt động trên các token được chỉ định làm đối số của chúng
Chúng ta sẽ nói về từng loại này lần lượt, nhưng trước tiên, hãy xem tại sao chúng ta thậm chí cần macro khi chúng ta đã có hàm.
Sự Khác Biệt Giữa Macro và Hàm
Về cơ bản, macro là một cách để viết mã tạo ra mã khác, điều này được gọi là
lập trình meta. Trong Phụ lục C, chúng ta thảo luận về thuộc tính derive,
tạo ra một triển khai của các trait khác nhau cho bạn. Chúng ta cũng đã sử dụng
các macro println! và vec! trong suốt cuốn sách. Tất cả các macro này mở
rộng để tạo ra nhiều mã hơn so với mã bạn đã viết thủ công.
Lập trình meta hữu ích để giảm lượng mã bạn phải viết và bảo trì, đây cũng là một trong những vai trò của hàm. Tuy nhiên, macro có một số sức mạnh bổ sung mà hàm không có.
Chữ ký hàm phải khai báo số lượng và kiểu của các tham số mà hàm có. Ngược lại,
macro có thể nhận một số lượng tham số thay đổi: chúng ta có thể gọi
println!("hello") với một đối số hoặc println!("hello {}", name) với hai đối
số. Ngoài ra, macro được mở rộng trước khi trình biên dịch diễn giải ý nghĩa của
mã, vì vậy một macro có thể, ví dụ, triển khai một trait trên một kiểu nhất
định. Một hàm không thể làm điều này, vì nó được gọi trong thời gian chạy và một
trait cần được triển khai tại thời điểm biên dịch.
Nhược điểm của việc triển khai một macro thay vì một hàm là định nghĩa macro phức tạp hơn định nghĩa hàm vì bạn đang viết mã Rust để viết mã Rust. Do sự gián tiếp này, định nghĩa macro thường khó đọc, khó hiểu và khó bảo trì hơn định nghĩa hàm.
Một sự khác biệt quan trọng khác giữa macro và hàm là bạn phải định nghĩa macro hoặc đưa chúng vào phạm vi trước khi bạn gọi chúng trong một tệp, trái ngược với các hàm mà bạn có thể định nghĩa ở bất kỳ đâu và gọi ở bất kỳ đâu.
Macro Khai Báo với macro_rules! cho Lập Trình Meta Tổng Quát
Hình thức macro được sử dụng rộng rãi nhất trong Rust là macro khai báo. Đôi
khi chúng còn được gọi là "macro bằng ví dụ," "macro macro_rules!," hoặc đơn
giản là "macro." Về cơ bản, macro khai báo cho phép bạn viết một cái gì đó tương
tự như một biểu thức match của Rust. Như đã thảo luận trong Chương 6, biểu
thức match là cấu trúc điều khiển nhận một biểu thức, so sánh giá trị kết quả
của biểu thức với các mẫu, và sau đó chạy mã liên kết với mẫu phù hợp. Macro
cũng so sánh một giá trị với các mẫu được liên kết với mã cụ thể: trong tình
huống này, giá trị là mã nguồn Rust theo nghĩa đen được truyền cho macro; các
mẫu được so sánh với cấu trúc của mã nguồn đó; và mã liên kết với mỗi mẫu, khi
khớp, thay thế mã được truyền cho macro. Tất cả điều này diễn ra trong quá trình
biên dịch.
Để định nghĩa một macro, bạn sử dụng cấu trúc macro_rules!. Hãy khám phá cách
sử dụng macro_rules! bằng cách xem cách định nghĩa macro vec!. Chương 8 đã
đề cập đến cách chúng ta có thể sử dụng macro vec! để tạo một vector mới với
các giá trị cụ thể. Ví dụ, macro sau tạo một vector mới chứa ba số nguyên:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
Chúng ta cũng có thể sử dụng macro vec! để tạo một vector của hai số nguyên
hoặc một vector của năm slice chuỗi. Chúng ta sẽ không thể sử dụng một hàm để
làm điều tương tự vì chúng ta sẽ không biết số lượng hoặc kiểu giá trị trước.
Listing 20-35 hiển thị một định nghĩa hơi đơn giản hóa của macro vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}Lưu ý: Định nghĩa thực tế của macro
vec!trong thư viện chuẩn bao gồm mã để cấp phát trước đúng lượng bộ nhớ. Mã đó là một tối ưu hóa mà chúng ta không bao gồm ở đây, để làm cho ví dụ đơn giản hơn.
Chú thích #[macro_export] chỉ ra rằng macro này nên được làm cho có sẵn bất cứ
khi nào crate mà macro được định nghĩa trong đó được đưa vào phạm vi. Nếu không
có chú thích này, macro không thể được đưa vào phạm vi.
Sau đó, chúng ta bắt đầu định nghĩa macro với macro_rules! và tên của macro
chúng ta đang định nghĩa không có dấu chấm than. Tên, trong trường hợp này là
vec, được theo sau bởi dấu ngoặc nhọn biểu thị thân của định nghĩa macro.
Cấu trúc trong thân vec! tương tự như cấu trúc của một biểu thức match. Ở
đây, chúng ta có một nhánh với mẫu ( $( $x:expr ),* ), theo sau là => và
khối mã liên kết với mẫu này. Nếu mẫu khớp, khối mã liên kết sẽ được phát ra. Vì
đây là mẫu duy nhất trong macro này, chỉ có một cách hợp lệ để khớp; bất kỳ mẫu
nào khác sẽ dẫn đến lỗi. Các macro phức tạp hơn sẽ có nhiều hơn một nhánh.
Cú pháp mẫu hợp lệ trong định nghĩa macro khác với cú pháp mẫu được đề cập trong Chương 19 vì các mẫu macro được khớp với cấu trúc mã Rust chứ không phải giá trị. Hãy đi qua ý nghĩa của các phần mẫu trong Listing 20-29; để biết cú pháp mẫu macro đầy đủ, hãy xem Tài liệu tham khảo Rust.
Đầu tiên, chúng ta sử dụng một bộ dấu ngoặc đơn để bao quanh toàn bộ mẫu. Chúng
ta sử dụng dấu đô la ($) để khai báo một biến trong hệ thống macro sẽ chứa mã
Rust khớp với mẫu. Dấu đô la làm rõ đây là một biến macro chứ không phải một
biến Rust thông thường. Tiếp theo là một bộ dấu ngoặc đơn bắt các giá trị khớp
với mẫu trong dấu ngoặc đơn để sử dụng trong mã thay thế. Trong $() là
$x:expr, khớp với bất kỳ biểu thức Rust nào và gán cho biểu thức tên $x.
Dấu phẩy sau $() chỉ ra rằng một ký tự phân cách dấu phẩy theo nghĩa đen phải
xuất hiện giữa mỗi thể hiện của mã khớp với mã trong $(). Dấu * chỉ định
rằng mẫu khớp với zero hoặc nhiều của bất cứ thứ gì đứng trước dấu *.
Khi chúng ta gọi macro này với vec![1, 2, 3];, mẫu $x khớp ba lần với ba
biểu thức 1, 2, và 3.
Bây giờ, hãy nhìn vào mẫu trong phần thân của mã liên kết với nhánh này:
temp_vec.push() trong $()* được tạo ra cho mỗi phần khớp với $() trong mẫu
zero hoặc nhiều lần tùy thuộc vào số lần mẫu khớp. Biến $x được thay thế bằng
mỗi biểu thức khớp. Khi chúng ta gọi macro này với vec![1, 2, 3];, mã được tạo
ra thay thế lời gọi macro này sẽ là như sau:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Chúng ta đã định nghĩa một macro có thể nhận bất kỳ số lượng đối số nào với bất kỳ kiểu nào và có thể tạo mã để tạo một vector chứa các phần tử được chỉ định.
Để tìm hiểu thêm về cách viết macro, hãy tham khảo tài liệu trực tuyến hoặc các tài nguyên khác, chẳng hạn như "The Little Book of Rust Macros" do Daniel Keep bắt đầu và Lukas Wirth tiếp tục.
Macro Thủ Tục cho Tạo Mã từ Thuộc Tính
Hình thức thứ hai của macro là macro thủ tục, hoạt động giống như một hàm (và là
một loại thủ tục). Macro thủ tục chấp nhận một số mã làm đầu vào, hoạt động
trên mã đó, và tạo ra một số mã làm đầu ra thay vì khớp với các mẫu và thay thế
mã bằng mã khác như macro khai báo. Ba loại macro thủ tục là derive tùy chỉnh,
giống thuộc tính, và giống hàm, và tất cả đều hoạt động theo cách tương tự.
Khi tạo macro thủ tục, các định nghĩa phải nằm trong crate riêng của chúng với
một loại crate đặc biệt. Điều này là do lý do kỹ thuật phức tạp mà chúng tôi hy
vọng sẽ loại bỏ trong tương lai. Trong Listing 20-36, chúng tôi cho thấy cách
định nghĩa một macro thủ tục, trong đó some_attribute là một placeholder cho
việc sử dụng một biến thể macro cụ thể.
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Hàm định nghĩa một macro thủ tục nhận một TokenStream làm đầu vào và tạo ra
một TokenStream làm đầu ra. Kiểu TokenStream được định nghĩa bởi crate
proc_macro được bao gồm với Rust và đại diện cho một chuỗi các token. Đây là
cốt lõi của macro: mã nguồn mà macro đang hoạt động trên tạo thành TokenStream
đầu vào, và mã mà macro tạo ra là TokenStream đầu ra. Hàm cũng có một thuộc
tính được gắn vào nó chỉ định loại macro thủ tục nào chúng ta đang tạo. Chúng ta
có thể có nhiều loại macro thủ tục trong cùng một crate.
Hãy xem xét các loại macro thủ tục khác nhau. Chúng ta sẽ bắt đầu với một macro
derive tùy chỉnh và sau đó giải thích sự khác biệt nhỏ làm cho các hình thức
khác khác nhau.
Cách Viết Một Macro derive Tùy Chỉnh
Hãy tạo một crate có tên hello_macro định nghĩa một trait có tên HelloMacro
với một hàm liên kết có tên hello_macro. Thay vì yêu cầu người dùng của chúng
ta triển khai trait HelloMacro cho từng kiểu của họ, chúng ta sẽ cung cấp một
macro thủ tục để người dùng có thể chú thích kiểu của họ với
#[derive(HelloMacro)] để có được một triển khai mặc định của hàm
hello_macro. Triển khai mặc định sẽ in Hello, Macro! My name is TypeName!
trong đó TypeName là tên của kiểu mà trait này đã được định nghĩa trên. Nói
cách khác, chúng ta sẽ viết một crate cho phép một lập trình viên khác viết mã
như Listing 20-37 sử dụng crate của chúng ta.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Mã này sẽ in Hello, Macro! My name is Pancakes! khi chúng ta hoàn thành. Bước
đầu tiên là tạo một crate thư viện mới, như sau:
$ cargo new hello_macro --lib
Tiếp theo, trong Listing 20-38, chúng ta sẽ định nghĩa trait HelloMacro và hàm
liên kết của nó.
pub trait HelloMacro {
fn hello_macro();
}Chúng ta có một trait và hàm của nó. Tại thời điểm này, người dùng crate của chúng ta có thể triển khai trait để đạt được chức năng mong muốn, như trong Listing 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}Tuy nhiên, họ sẽ cần phải viết khối triển khai cho mỗi kiểu họ muốn sử dụng với
hello_macro; chúng ta muốn giúp họ không phải làm công việc này.
Ngoài ra, chúng ta chưa thể cung cấp hàm hello_macro với triển khai mặc định
sẽ in tên của kiểu mà trait được triển khai: Rust không có khả năng phản ánh, vì
vậy nó không thể tra cứu tên kiểu tại thời điểm chạy. Chúng ta cần một macro để
tạo mã tại thời điểm biên dịch.
Bước tiếp theo là định nghĩa macro thủ tục. Tại thời điểm viết bài này, macro
thủ tục cần phải nằm trong crate riêng của chúng. Cuối cùng, hạn chế này có thể
được dỡ bỏ. Quy ước cho việc cấu trúc các crate và crate macro là như sau: đối
với một crate có tên foo, một crate macro thủ tục derive tùy chỉnh được gọi
là foo_derive. Hãy bắt đầu một crate mới có tên hello_macro_derive bên trong
dự án hello_macro của chúng ta:
$ cargo new hello_macro_derive --lib
Hai crate của chúng ta có liên quan chặt chẽ với nhau, vì vậy chúng ta tạo crate
macro thủ tục trong thư mục của crate hello_macro. Nếu chúng ta thay đổi định
nghĩa trait trong hello_macro, chúng ta cũng sẽ phải thay đổi triển khai của
macro thủ tục trong hello_macro_derive. Hai crate sẽ cần được xuất bản riêng
biệt, và các lập trình viên sử dụng các crate này sẽ cần thêm cả hai làm phụ
thuộc và đưa cả hai vào phạm vi. Chúng ta có thể thay vào đó cho crate
hello_macro sử dụng hello_macro_derive làm phụ thuộc và tái xuất mã macro
thủ tục. Tuy nhiên, cách chúng ta đã cấu trúc dự án làm cho các lập trình viên
có thể sử dụng hello_macro ngay cả khi họ không muốn chức năng derive.
Chúng ta cần khai báo crate hello_macro_derive là một crate macro thủ tục.
Chúng ta cũng sẽ cần chức năng từ các crate syn và quote, như bạn sẽ thấy
sau đây, vì vậy chúng ta cần thêm chúng làm phụ thuộc. Thêm phần sau vào tệp
Cargo.toml cho hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Để bắt đầu định nghĩa macro thủ tục, đặt mã trong Listing 20-40 vào tệp
src/lib.rs của bạn cho crate hello_macro_derive. Lưu ý rằng mã này sẽ không
biên dịch cho đến khi chúng ta thêm một định nghĩa cho hàm impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}Lưu ý rằng chúng ta đã chia mã thành hàm hello_macro_derive, chịu trách nhiệm
phân tích TokenStream, và hàm impl_hello_macro, chịu trách nhiệm chuyển đổi
cây cú pháp: điều này làm cho việc viết một macro thủ tục thuận tiện hơn. Mã
trong hàm ngoài (trong trường hợp này là hello_macro_derive) sẽ giống nhau cho
hầu hết mọi crate macro thủ tục mà bạn thấy hoặc tạo. Mã mà bạn chỉ định trong
thân hàm bên trong (trong trường hợp này là impl_hello_macro) sẽ khác nhau tùy
thuộc vào mục đích của macro thủ tục của bạn.
Chúng ta đã giới thiệu ba crate mới: proc_macro, syn,
và quote. Crate proc_macro đi kèm với Rust, vì vậy
chúng ta không cần thêm nó vào phụ thuộc trong Cargo.toml. Crate proc_macro
là API của trình biên dịch cho phép chúng ta đọc và thao tác mã Rust từ mã của
chúng ta.
Crate syn phân tích mã Rust từ một chuỗi thành một cấu trúc dữ liệu mà chúng
ta có thể thực hiện các thao tác. Crate quote chuyển đổi các cấu trúc dữ liệu
syn trở lại mã Rust. Các crate này làm cho việc phân tích bất kỳ loại mã Rust
nào mà chúng ta có thể muốn xử lý trở nên đơn giản hơn nhiều: viết một trình
phân tích cú pháp đầy đủ cho mã Rust không phải là một nhiệm vụ đơn giản.
Hàm hello_macro_derive sẽ được gọi khi người dùng của thư viện của chúng ta
chỉ định #[derive(HelloMacro)] trên một kiểu. Điều này có thể vì chúng ta đã
chú thích hàm hello_macro_derive ở đây với proc_macro_derive và chỉ định tên
HelloMacro, khớp với tên trait của chúng ta; đây là quy ước mà hầu hết các
macro thủ tục tuân theo.
Hàm hello_macro_derive đầu tiên chuyển đổi input từ một TokenStream thành
một cấu trúc dữ liệu mà sau đó chúng ta có thể giải thích và thực hiện các thao
tác. Đây là nơi syn phát huy tác dụng. Hàm parse trong syn nhận một
TokenStream và trả về một cấu trúc DeriveInput đại diện cho mã Rust đã được
phân tích. Listing 20-41 hiển thị các phần liên quan của cấu trúc DeriveInput
mà chúng ta nhận được khi phân tích chuỗi struct Pancakes;.
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}Các trường của cấu trúc này cho thấy rằng mã Rust mà chúng ta đã phân tích là
một struct đơn vị với ident (định danh, nghĩa là tên) là Pancakes. Có
nhiều trường hơn trên cấu trúc này để mô tả tất cả các loại mã Rust; kiểm tra
tài liệu syn cho DeriveInput để biết thêm thông tin.
Chẳng bao lâu nữa chúng ta sẽ định nghĩa hàm impl_hello_macro, nơi mà chúng ta
sẽ xây dựng mã Rust mới mà chúng ta muốn bao gồm. Nhưng trước khi chúng ta làm
điều đó, hãy lưu ý rằng đầu ra cho macro derive của chúng ta cũng là một
TokenStream. TokenStream trả về được thêm vào mã mà người dùng crate của
chúng ta viết, vì vậy khi họ biên dịch crate của họ, họ sẽ nhận được chức năng
bổ sung mà chúng ta cung cấp trong TokenStream đã được sửa đổi.
Bạn có thể đã nhận thấy rằng chúng ta gọi unwrap để khiến hàm
hello_macro_derive panic nếu lời gọi hàm syn::parse không thành công ở đây.
Cần thiết cho macro thủ tục của chúng ta panic về lỗi vì các hàm
proc_macro_derive phải trả về TokenStream chứ không phải Result để phù hợp
với API macro thủ tục. Chúng ta đã đơn giản hóa ví dụ này bằng cách sử dụng
unwrap; trong mã sản xuất, bạn nên cung cấp thông báo lỗi cụ thể hơn về những
gì đã xảy ra sai bằng cách sử dụng panic! hoặc expect.
Bây giờ chúng ta đã có mã để chuyển đổi mã Rust được chú thích từ một
TokenStream thành một thể hiện DeriveInput, hãy tạo mã triển khai trait
HelloMacro trên kiểu được chú thích, như hiển thị trong Listing 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}Chúng ta nhận được một thể hiện của cấu trúc Ident chứa tên (định danh) của
kiểu được chú thích bằng cách sử dụng ast.ident. Cấu trúc trong Listing 20-41
cho thấy rằng khi chúng ta chạy hàm impl_hello_macro trên mã trong Listing
20-37, ident mà chúng ta nhận được sẽ có trường ident với giá trị là
"Pancakes". Do đó, biến name trong Listing 20-42 sẽ chứa một thể hiện của
cấu trúc Ident mà, khi được in ra, sẽ là chuỗi "Pancakes", tên của struct
trong Listing 20-37.
Macro quote! cho phép chúng ta định nghĩa mã Rust mà chúng ta muốn trả về.
Trình biên dịch mong đợi một thứ khác với kết quả trực tiếp của thực thi macro
quote!, vì vậy chúng ta cần chuyển đổi nó thành một TokenStream. Chúng ta
làm điều này bằng cách gọi phương thức into, tiêu thụ biểu diễn trung gian này
và trả về một giá trị của kiểu TokenStream cần thiết.
Macro quote! cũng cung cấp một số cơ chế mẫu rất tuyệt: chúng ta có thể nhập
#name, và quote! sẽ thay thế nó bằng giá trị trong biến name. Bạn thậm chí
có thể làm một số lặp lại tương tự như cách hoạt động của các macro thông
thường. Kiểm tra tài liệu của crate quote để có một giới thiệu
kỹ lưỡng.
Chúng ta muốn macro thủ tục của chúng ta tạo ra một triển khai của trait
HelloMacro cho kiểu mà người dùng đã chú thích, đó là những gì chúng ta có thể
nhận được bằng cách sử dụng #name. Việc triển khai trait có một hàm
hello_macro, thân của nó chứa chức năng mà chúng ta muốn cung cấp: in
Hello, Macro! My name is và sau đó là tên của kiểu được chú thích.
Macro stringify! được sử dụng ở đây là được tích hợp sẵn trong Rust. Nó lấy
một biểu thức Rust, chẳng hạn như 1 + 2, và vào thời điểm biên dịch chuyển đổi
biểu thức thành một chuỗi theo nghĩa đen, chẳng hạn như "1 + 2". Điều này khác
với format! hoặc println!, các macro đánh giá biểu thức và sau đó chuyển đổi
kết quả thành một String. Có khả năng là đầu vào #name có thể là một biểu
thức để in ra theo nghĩa đen, vì vậy chúng ta sử dụng stringify!. Sử dụng
stringify! cũng tiết kiệm một phân bổ bằng cách chuyển đổi #name thành một
chuỗi theo nghĩa đen vào thời điểm biên dịch.
Tại thời điểm này, cargo build nên hoàn thành thành công trong cả
hello_macro và hello_macro_derive. Hãy kết nối các crate này với mã trong
Listing 20-31 để xem macro thủ tục hoạt động! Tạo một dự án nhị phân mới trong
thư mục projects của bạn bằng cách sử dụng cargo new pancakes. Chúng ta cần
thêm hello_macro và hello_macro_derive làm phụ thuộc trong crate pancakes
của Cargo.toml. Nếu bạn đang xuất bản phiên bản của hello_macro và
hello_macro_derive lên crates.io, chúng sẽ là phụ thuộc
thông thường; nếu không, bạn có thể chỉ định chúng như phụ thuộc path như sau:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Đặt mã trong Listing 20-37 vào src/main.rs, và chạy cargo run: nó sẽ in
Hello, Macro! My name is Pancakes! Việc triển khai trait HelloMacro từ macro
thủ tục đã được bao gồm mà không cần crate pancakes phải triển khai nó;
#[derive(HelloMacro)] đã thêm việc triển khai trait.
Tiếp theo, hãy khám phá cách các loại macro thủ tục khác khác với macro derive
tùy chỉnh.
Macro Giống Thuộc Tính
Macro giống thuộc tính tương tự như macro derive tùy chỉnh, nhưng thay vì tạo
mã cho thuộc tính derive, chúng cho phép bạn tạo thuộc tính mới. Chúng cũng
linh hoạt hơn: derive chỉ hoạt động cho struct và enum; thuộc tính có thể được
áp dụng cho các mục khác, chẳng hạn như hàm. Đây là một ví dụ về việc sử dụng
một macro giống thuộc tính. Giả sử bạn có một thuộc tính tên là route chú
thích các hàm khi sử dụng một framework ứng dụng web:
#[route(GET, "/")]
fn index() {Thuộc tính #[route] này sẽ được định nghĩa bởi framework như một macro thủ
tục. Chữ ký của hàm định nghĩa macro sẽ trông như thế này:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Tại đây, chúng ta có hai tham số kiểu TokenStream. Tham số đầu tiên là cho nội
dung của thuộc tính: phần GET, "/". Tham số thứ hai là cho phần thân của mục
mà thuộc tính được gắn vào: trong trường hợp này, fn index() {} và phần còn
lại của thân hàm.
Ngoài ra, macro giống thuộc tính hoạt động theo cách tương tự như macro derive
tùy chỉnh: bạn tạo một crate với loại crate proc-macro và triển khai một hàm
tạo ra mã bạn muốn!
Macro Giống Hàm
Macro giống hàm định nghĩa các macro trông giống như lời gọi hàm. Tương tự như
macro macro_rules!, chúng linh hoạt hơn các hàm; ví dụ, chúng có thể nhận một
số lượng đối số không xác định. Tuy nhiên, macro macro_rules! chỉ có thể được
định nghĩa bằng cách sử dụng cú pháp giống match mà chúng ta đã thảo luận trong
"Macro Khai Báo với macro_rules! cho Lập Trình Meta Tổng
Quát" trước đó. Macro giống hàm nhận một tham số
TokenStream, và định nghĩa của chúng thao tác trên TokenStream đó bằng mã
Rust giống như hai loại macro thủ tục khác. Một ví dụ về một macro giống hàm là
macro sql! có thể được gọi như sau:
let sql = sql!(SELECT * FROM posts WHERE id=1);Macro này sẽ phân tích câu lệnh SQL bên trong nó và kiểm tra xem nó có đúng cú
pháp hay không, đây là quá trình xử lý phức tạp hơn nhiều so với những gì một
macro macro_rules! có thể làm. Macro sql! sẽ được định nghĩa như sau:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Định nghĩa này tương tự như chữ ký của macro derive tùy chỉnh: chúng ta nhận
các token nằm trong dấu ngoặc đơn và trả về mã mà chúng ta muốn tạo ra.
Tóm Tắt
Whew! Bây giờ bạn đã có một số tính năng Rust trong hộp công cụ của mình mà bạn có thể sẽ không sử dụng thường xuyên, nhưng bạn sẽ biết chúng có sẵn trong những tình huống rất cụ thể. Chúng ta đã giới thiệu một số chủ đề phức tạp để khi bạn gặp chúng trong các gợi ý thông báo lỗi hoặc trong mã của người khác, bạn sẽ có thể nhận ra các khái niệm và cú pháp này. Sử dụng chương này như một tài liệu tham khảo để hướng dẫn bạn đến các giải pháp.
Tiếp theo, chúng ta sẽ đưa tất cả những gì chúng ta đã thảo luận trong suốt cuốn sách vào thực hành và thực hiện một dự án nữa!
Dự Án Cuối Cùng: Xây Dựng Một Web Server
Trong chương này, chúng ta sẽ cùng nhau xây dựng một dự án cuối cùng để trình diễn một số khái niệm mà chúng ta đã đề cập trong các chương trước và tổng kết lại các bài học.
Đối với dự án cuối cùng của chúng ta, chúng ta sẽ tạo một web server nói "hello" và trông giống như Hình 21-1 trong trình duyệt web.
Đây là kế hoạch của chúng ta để xây dựng web server:
- Tìm hiểu một chút về TCP và HTTP.
- Lắng nghe các kết nối TCP.
- Phân tích một số ít các yêu cầu HTTP.
- Tạo một phản hồi HTTP hợp lệ.
- Cải thiện thông lượng của server của chúng ta với một thread pool.
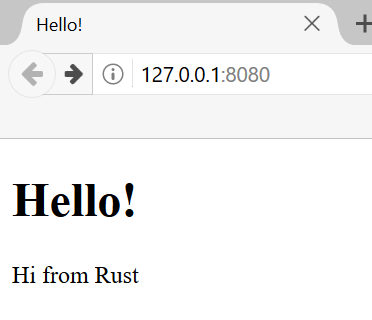
Hình 21-1: Dự án chung cuối cùng của chúng ta
Trước khi chúng ta bắt đầu, chúng ta nên đề cập đến hai chi tiết. Đầu tiên, phương pháp chúng ta sẽ sử dụng sẽ không phải là cách tốt nhất để xây dựng một web server với Rust. Các thành viên cộng đồng đã xuất bản một số crate sẵn sàng cho sản xuất có sẵn tại crates.io cung cấp các triển khai web server và thread pool hoàn chỉnh hơn so với những gì chúng ta sẽ xây dựng. Tuy nhiên, ý định của chúng ta trong chương này là giúp bạn học, không phải đi đường tắt. Bởi vì Rust là một ngôn ngữ lập trình hệ thống, chúng ta có thể chọn mức độ trừu tượng mà chúng ta muốn làm việc và có thể đi đến mức thấp hơn so với những gì có thể hoặc thực tế trong các ngôn ngữ khác.
Thứ hai, chúng ta sẽ không sử dụng async và await ở đây. Việc xây dựng một thread pool đã là một thách thức đủ lớn, mà không cần thêm việc xây dựng một runtime async! Tuy nhiên, chúng ta sẽ lưu ý cách async và await có thể áp dụng cho một số vấn đề tương tự mà chúng ta sẽ thấy trong chương này. Cuối cùng, như chúng ta đã lưu ý trong Chương 17, nhiều runtime async sử dụng thread pool để quản lý công việc của chúng.
Do đó, chúng ta sẽ viết máy chủ HTTP cơ bản và thread pool thủ công để bạn có thể học các ý tưởng và kỹ thuật chung đằng sau các crate mà bạn có thể sử dụng trong tương lai.
Xây Dựng Một Web Server Đơn Luồng
Chúng ta sẽ bắt đầu bằng việc xây dựng một web server chạy trên một luồng duy nhất. Trước khi bắt đầu, hãy xem qua tổng quan nhanh về các giao thức liên quan đến việc xây dựng web server. Chi tiết của các giao thức này nằm ngoài phạm vi của cuốn sách này, nhưng một tổng quan ngắn gọn sẽ cung cấp cho bạn thông tin cần thiết.
Hai giao thức chính liên quan đến web server là Hypertext Transfer Protocol (HTTP) và Transmission Control Protocol (TCP). Cả hai giao thức đều là các giao thức yêu cầu-phản hồi, nghĩa là khách hàng (client) khởi tạo yêu cầu và máy chủ (server) lắng nghe các yêu cầu và cung cấp phản hồi cho khách hàng. Nội dung của các yêu cầu và phản hồi đó được định nghĩa bởi các giao thức.
TCP là một giao thức cấp thấp hơn mô tả chi tiết về cách thông tin được truyền từ một máy chủ sang máy chủ khác nhưng không chỉ định thông tin đó là gì. HTTP xây dựng trên TCP bằng cách định nghĩa nội dung của các yêu cầu và phản hồi. Về mặt kỹ thuật, có thể sử dụng HTTP với các giao thức khác, nhưng trong phần lớn trường hợp, HTTP gửi dữ liệu qua TCP. Chúng ta sẽ làm việc với các byte thô của yêu cầu và phản hồi TCP và HTTP.
Lắng Nghe Kết Nối TCP
Web server của chúng ta cần lắng nghe kết nối TCP, vì vậy đó là phần đầu tiên mà
chúng ta sẽ xử lý. Thư viện chuẩn cung cấp một module std::net cho phép chúng
ta làm điều này. Hãy tạo một dự án mới theo cách thông thường với cargo new:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Bây giờ nhập mã trong Listing 21-1 vào src/main.rs để bắt đầu. Mã này sẽ lắng
nghe tại địa chỉ cục bộ 127.0.0.1:7878 để tìm các luồng TCP đến. Khi nó nhận
được một luồng đến, nó sẽ in ra Connection established!.
Lưu ý: nếu bạn đang chạy chương trình này trên một máy từ xa thay vì cục bộ, trình duyệt web của bạn sẽ không thể kết nối. Để cho phép kết nối, hãy tìm địa chỉ IP công cộng của máy từ xa của bạn và thay thế
127.0.0.1bằng địa chỉ IP công cộng của bạn trong cả src/main.rs và URL bạn sử dụng trong trình duyệt.
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connection established!"); } }
Sử dụng TcpListener, chúng ta có thể lắng nghe các kết nối TCP tại địa chỉ
127.0.0.1:7878. Trong địa chỉ, phần trước dấu hai chấm là địa chỉ IP đại diện
cho máy tính của bạn (điều này giống nhau trên mọi máy tính và không đại diện cụ
thể cho máy tính của tác giả), và 7878 là cổng. Chúng ta đã chọn cổng này vì
hai lý do: HTTP thường không được chấp nhận trên cổng này nên server của chúng
ta khó có thể xung đột với bất kỳ web server nào khác mà bạn có thể đang chạy
trên máy của mình, và 7878 là rust được gõ trên điện thoại.
Hàm bind trong tình huống này hoạt động giống như hàm new vì nó sẽ trả về
một thể hiện TcpListener mới. Hàm này được gọi là bind vì trong mạng, việc
kết nối với một cổng để lắng nghe được gọi là "binding to a port".
Hàm bind trả về một Result<T, E>, cho thấy rằng việc liên kết có thể thất
bại. Ví dụ, kết nối với cổng 80 yêu cầu quyền quản trị viên (người dùng không
phải quản trị viên chỉ có thể lắng nghe trên các cổng cao hơn 1023), vì vậy nếu
chúng ta cố kết nối với cổng 80 mà không phải là quản trị viên, việc liên kết sẽ
không hoạt động. Việc liên kết cũng sẽ không hoạt động, ví dụ, nếu chúng ta chạy
hai thể hiện của chương trình và do đó có hai chương trình lắng nghe cùng một
cổng. Bởi vì chúng ta đang viết một server cơ bản chỉ để học, chúng ta sẽ không
lo lắng về việc xử lý các loại lỗi này; thay vào đó, chúng ta sử dụng unwrap
để dừng chương trình nếu có lỗi xảy ra.
Phương thức incoming trên TcpListener trả về một iterator cung cấp cho chúng
ta một chuỗi các luồng (cụ thể hơn, các luồng thuộc loại TcpStream). Một
luồng (stream) đơn lẻ đại diện cho một kết nối mở giữa khách hàng và máy chủ.
Một kết nối (connection) là tên cho toàn bộ quá trình yêu cầu và phản hồi
trong đó khách hàng kết nối với máy chủ, máy chủ tạo ra phản hồi, và máy chủ
đóng kết nối. Do đó, TcpStream cho phép chúng ta đọc từ nó để xem khách hàng
đã gửi gì và sau đó viết phản hồi của chúng ta vào luồng để gửi dữ liệu trở lại
cho khách hàng. Nhìn chung, vòng lặp for này sẽ xử lý từng kết nối lần lượt và
tạo ra một chuỗi các luồng để chúng ta xử lý.
Hiện tại, việc xử lý luồng của chúng ta bao gồm việc gọi unwrap để chấm dứt
chương trình của chúng ta nếu luồng có bất kỳ lỗi nào; nếu không có lỗi nào,
chương trình sẽ in ra một thông báo. Chúng ta sẽ thêm chức năng cho trường hợp
thành công trong các ví dụ sau. Lý do chúng ta có thể nhận được lỗi từ phương
thức incoming khi khách hàng kết nối với máy chủ là vì chúng ta không thực sự
lặp qua các kết nối. Thay vào đó, chúng ta đang lặp qua các nỗ lực kết nối.
Kết nối có thể không thành công vì nhiều lý do, nhiều lý do phụ thuộc vào hệ
điều hành. Ví dụ, nhiều hệ điều hành có giới hạn về số lượng kết nối đồng thời
mở mà chúng có thể hỗ trợ; các nỗ lực kết nối mới vượt quá số đó sẽ tạo ra lỗi
cho đến khi một số kết nối mở được đóng lại.
Hãy thử chạy mã này! Gọi cargo run trong terminal và sau đó tải
127.0.0.1:7878 trong trình duyệt web. Trình duyệt sẽ hiển thị một thông báo
lỗi như "Connection reset" vì máy chủ hiện không gửi lại bất kỳ dữ liệu nào.
Nhưng khi bạn nhìn vào terminal của mình, bạn sẽ thấy một số thông báo đã được
in ra khi trình duyệt kết nối với máy chủ!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Đôi khi bạn sẽ thấy nhiều thông báo được in ra cho một yêu cầu trình duyệt; lý do có thể là trình duyệt đang gửi yêu cầu cho trang cũng như yêu cầu cho các tài nguyên khác, như biểu tượng favicon.ico xuất hiện trong tab trình duyệt.
Cũng có thể là trình duyệt đang cố gắng kết nối với máy chủ nhiều lần vì máy chủ
không phản hồi với bất kỳ dữ liệu nào. Khi stream ra khỏi phạm vi và bị drop
vào cuối vòng lặp, kết nối sẽ bị đóng như một phần của việc triển khai drop.
Trình duyệt đôi khi xử lý các kết nối bị đóng bằng cách thử lại, vì vấn đề có
thể là tạm thời. Điều quan trọng là chúng ta đã thành công trong việc có được
một handle cho kết nối TCP!
Hãy nhớ dừng chương trình bằng cách nhấn ctrl-c khi bạn đã
chạy xong một phiên bản cụ thể của mã. Sau đó khởi động lại chương trình bằng
cách gọi lệnh cargo run sau khi bạn đã thực hiện mỗi bộ thay đổi mã để đảm bảo
bạn đang chạy mã mới nhất.
Đọc Yêu Cầu
Hãy triển khai chức năng để đọc yêu cầu từ trình duyệt! Để tách biệt các mối
quan tâm về việc đầu tiên là nhận được kết nối và sau đó thực hiện một số hành
động với kết nối, chúng ta sẽ bắt đầu một hàm mới để xử lý các kết nối. Trong
hàm handle_connection mới này, chúng ta sẽ đọc dữ liệu từ luồng TCP và in nó
ra để chúng ta có thể thấy dữ liệu được gửi từ trình duyệt. Thay đổi mã để trông
giống như Listing 21-2.
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Request: {http_request:#?}"); }
Chúng ta đưa std::io::prelude và std::io::BufReader vào phạm vi để có quyền
truy cập vào các traits và kiểu cho phép chúng ta đọc từ và viết vào luồng.
Trong vòng lặp for trong hàm main, thay vì in một thông báo cho biết chúng
ta đã thiết lập kết nối, bây giờ chúng ta gọi hàm handle_connection mới và
truyền stream vào nó.
Trong hàm handle_connection, chúng ta tạo một thể hiện BufReader mới bao bọc
một tham chiếu đến stream. BufReader thêm bộ đệm bằng cách quản lý các cuộc
gọi đến các phương thức của trait std::io::Read cho chúng ta.
Chúng ta tạo một biến có tên http_request để thu thập các dòng của yêu cầu mà
trình duyệt gửi đến máy chủ của chúng ta. Chúng ta chỉ ra rằng chúng ta muốn thu
thập các dòng này trong một vector bằng cách thêm chú thích kiểu Vec<_>.
BufReader triển khai trait std::io::BufRead, cung cấp phương thức lines.
Phương thức lines trả về một iterator của Result<String, std::io::Error>
bằng cách chia luồng dữ liệu bất cứ khi nào nó thấy một byte xuống dòng. Để lấy
mỗi String, chúng ta map và unwrap mỗi Result. Result có thể là một lỗi
nếu dữ liệu không phải là UTF-8 hợp lệ hoặc nếu có vấn đề khi đọc từ luồng. Một
lần nữa, một chương trình sản xuất nên xử lý các lỗi này một cách thanh lịch
hơn, nhưng chúng ta chọn dừng chương trình trong trường hợp lỗi để đơn giản.
Trình duyệt báo hiệu kết thúc của một yêu cầu HTTP bằng cách gửi hai ký tự xuống dòng liên tiếp, vì vậy để nhận một yêu cầu từ luồng, chúng ta lấy các dòng cho đến khi chúng ta nhận được một dòng là chuỗi rỗng. Một khi chúng ta đã thu thập các dòng vào vector, chúng ta in chúng ra bằng cách sử dụng định dạng gỡ lỗi đẹp để chúng ta có thể xem xét các hướng dẫn mà trình duyệt web đang gửi đến máy chủ của chúng ta.
Hãy thử mã này! Khởi động chương trình và tạo yêu cầu trong trình duyệt web một lần nữa. Lưu ý rằng chúng ta vẫn sẽ nhận được một trang lỗi trong trình duyệt, nhưng đầu ra của chương trình của chúng ta trong terminal bây giờ sẽ trông giống như thế này:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
]
Tùy thuộc vào trình duyệt của bạn, bạn có thể nhận được đầu ra hơi khác. Bây giờ
chúng ta đang in dữ liệu yêu cầu, chúng ta có thể thấy tại sao chúng ta nhận
được nhiều kết nối từ một yêu cầu trình duyệt bằng cách nhìn vào đường dẫn sau
GET trong dòng đầu tiên của yêu cầu. Nếu các kết nối lặp lại đều yêu cầu /,
chúng ta biết rằng trình duyệt đang cố gắng tìm nạp / nhiều lần vì nó không
nhận được phản hồi từ chương trình của chúng ta.
Hãy phân tích dữ liệu yêu cầu này để hiểu những gì trình duyệt đang yêu cầu từ chương trình của chúng ta.
Xem Xét Kỹ Hơn về Yêu Cầu HTTP
HTTP là một giao thức dựa trên văn bản, và một yêu cầu có định dạng này:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
Dòng đầu tiên là dòng yêu cầu (request line) chứa thông tin về những gì khách
hàng đang yêu cầu. Phần đầu tiên của dòng yêu cầu chỉ ra phương thức (method)
được sử dụng, chẳng hạn như GET hoặc POST, mô tả cách khách hàng đang thực
hiện yêu cầu này. Khách hàng của chúng ta sử dụng yêu cầu GET, có nghĩa là nó
đang yêu cầu thông tin.
Phần tiếp theo của dòng yêu cầu là /, chỉ ra bộ nhận dạng tài nguyên thống nhất (URI) mà khách hàng đang yêu cầu: một URI gần như, nhưng không hoàn toàn, giống như định vị tài nguyên thống nhất (URL). Sự khác biệt giữa URI và URL không quan trọng cho mục đích của chúng ta trong chương này, nhưng đặc tả HTTP sử dụng thuật ngữ URI, vì vậy chúng ta có thể chỉ thay thế URL cho URI ở đây.
Phần cuối cùng là phiên bản HTTP mà khách hàng sử dụng, và sau đó dòng yêu cầu
kết thúc bằng một chuỗi CRLF. (CRLF là viết tắt của carriage return và line
feed, là các thuật ngữ từ thời máy đánh chữ!) Chuỗi CRLF cũng có thể được viết
là \r\n, trong đó \r là carriage return và \n là line feed. Chuỗi CRLF
phân tách dòng yêu cầu khỏi phần còn lại của dữ liệu yêu cầu. Lưu ý rằng khi
CRLF được in, chúng ta thấy một dòng mới bắt đầu thay vì \r\n.
Nhìn vào dữ liệu dòng yêu cầu mà chúng ta đã nhận được từ việc chạy chương trình
của mình cho đến nay, chúng ta thấy rằng GET là phương thức, / là URI yêu
cầu, và HTTP/1.1 là phiên bản.
Sau dòng yêu cầu, các dòng còn lại bắt đầu từ Host: trở đi là các header. Yêu
cầu GET không có phần thân.
Hãy thử tạo một yêu cầu từ một trình duyệt khác hoặc yêu cầu một địa chỉ khác, chẳng hạn như 127.0.0.1:7878/test, để xem dữ liệu yêu cầu thay đổi như thế nào.
Bây giờ chúng ta biết trình duyệt đang yêu cầu gì, hãy gửi lại một số dữ liệu!
Viết Phản Hồi
Chúng ta sẽ triển khai việc gửi dữ liệu để đáp ứng yêu cầu của khách hàng. Các phản hồi có định dạng sau:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
Dòng đầu tiên là dòng trạng thái (status line) chứa phiên bản HTTP được sử dụng trong phản hồi, một mã trạng thái số tóm tắt kết quả của yêu cầu, và một cụm từ lý do cung cấp mô tả văn bản của mã trạng thái. Sau chuỗi CRLF là bất kỳ header nào, một chuỗi CRLF khác, và thân của phản hồi.
Dưới đây là một ví dụ về phản hồi sử dụng phiên bản HTTP 1.1, có mã trạng thái 200, cụm từ lý do OK, không có header, và không có thân:
HTTP/1.1 200 OK\r\n\r\n
Mã trạng thái 200 là phản hồi thành công tiêu chuẩn. Văn bản là một phản hồi
HTTP thành công nhỏ. Hãy viết điều này vào luồng như phản hồi của chúng ta cho
một yêu cầu thành công! Từ hàm handle_connection, xóa println! đã in dữ liệu
yêu cầu và thay thế nó bằng mã trong Listing 21-3.
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let response = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(response.as_bytes()).unwrap(); }
Dòng mới đầu tiên định nghĩa biến response giữ dữ liệu của thông báo thành
công. Sau đó chúng ta gọi as_bytes trên response để chuyển đổi dữ liệu chuỗi
thành byte. Phương thức write_all trên stream nhận một &[u8] và gửi các
byte đó trực tiếp qua kết nối. Vì thao tác write_all có thể thất bại, chúng ta
sử dụng unwrap trên bất kỳ kết quả lỗi nào như trước đây. Một lần nữa, trong
một ứng dụng thực tế, bạn sẽ thêm xử lý lỗi ở đây.
Với những thay đổi này, hãy chạy mã của chúng ta và tạo một yêu cầu. Chúng ta không còn in bất kỳ dữ liệu nào vào terminal, vì vậy chúng ta sẽ không thấy bất kỳ đầu ra nào ngoài đầu ra từ Cargo. Khi bạn tải 127.0.0.1:7878 trong trình duyệt web, bạn sẽ nhận được một trang trống thay vì lỗi. Bạn vừa viết mã bằng tay để nhận yêu cầu HTTP và gửi phản hồi!
Trả về HTML Thực Sự
Hãy triển khai chức năng để trả về nhiều hơn một trang trống. Tạo file mới hello.html trong thư mục gốc của dự án của bạn, không phải trong thư mục src. Bạn có thể nhập bất kỳ HTML nào bạn muốn; Listing 21-4 hiển thị một khả năng.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Đây là một tài liệu HTML5 tối thiểu với một tiêu đề và một số văn bản. Để trả về
từ máy chủ khi một yêu cầu được nhận, chúng ta sẽ sửa đổi handle_connection
như trong Listing 21-5 để đọc file HTML, thêm nó vào phản hồi dưới dạng thân, và
gửi nó.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Chúng ta đã thêm fs vào câu lệnh use để đưa module filesystem của thư viện
chuẩn vào phạm vi. Mã để đọc nội dung của một file vào một chuỗi sẽ trông quen
thuộc; chúng ta đã sử dụng nó khi chúng ta đọc nội dung của một file cho dự án
I/O của chúng ta trong Listing 12-4.
Tiếp theo, chúng ta sử dụng format! để thêm nội dung của file dưới dạng thân
của phản hồi thành công. Để đảm bảo một phản hồi HTTP hợp lệ, chúng ta thêm
header Content-Length được thiết lập bằng kích thước của thân phản hồi, trong
trường hợp này là kích thước của contents.
Chạy mã này với cargo run và tải 127.0.0.1:7878 trong trình duyệt của bạn;
bạn sẽ thấy HTML của bạn được hiển thị!
Hiện tại, chúng ta đang bỏ qua dữ liệu yêu cầu trong http_request và chỉ đơn
giản gửi lại nội dung của file HTML một cách vô điều kiện. Điều đó có nghĩa là
nếu bạn thử yêu cầu 127.0.0.1:7878/something-else trong trình duyệt của bạn,
bạn vẫn sẽ nhận lại cùng một phản hồi HTML. Ở thời điểm hiện tại, máy chủ của
chúng ta rất hạn chế và không làm những gì hầu hết các máy chủ web làm. Chúng ta
muốn tùy chỉnh các phản hồi của mình tùy thuộc vào yêu cầu và chỉ gửi lại file
HTML cho một yêu cầu được định dạng tốt tới /.
Xác Thực Yêu Cầu và Phản Hồi Có Chọn Lọc
Hiện tại, máy chủ web của chúng ta sẽ trả về HTML trong file bất kể khách hàng
yêu cầu gì. Hãy thêm chức năng để kiểm tra xem trình duyệt có yêu cầu / trước
khi trả về file HTML và trả về lỗi nếu trình duyệt yêu cầu bất cứ thứ gì khác.
Để làm điều này, chúng ta cần sửa đổi handle_connection, như trong Listing
21-6. Mã mới này kiểm tra nội dung của yêu cầu nhận được so với những gì chúng
ta biết một yêu cầu cho / trông như thế nào và thêm các khối if và else để
xử lý các yêu cầu khác nhau.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } else { // some other request } }
Chúng ta chỉ xem xét dòng đầu tiên của yêu cầu HTTP, vì vậy thay vì đọc toàn bộ
yêu cầu vào vector, chúng ta đang gọi next để lấy mục đầu tiên từ iterator.
unwrap đầu tiên xử lý Option và dừng chương trình nếu iterator không có mục
nào. unwrap thứ hai xử lý Result và có cùng tác dụng với unwrap đã được
thêm vào map trong Listing 21-2.
Tiếp theo, chúng ta kiểm tra request_line để xem nó có bằng với dòng yêu cầu
của một yêu cầu GET đến đường dẫn / không. Nếu có, khối if trả về nội dung
của file HTML của chúng ta.
Nếu request_line không bằng với yêu cầu GET đến đường dẫn /, có nghĩa là
chúng ta đã nhận được một số yêu cầu khác. Chúng ta sẽ thêm mã vào khối else
ngay bây giờ để phản hồi tất cả các yêu cầu khác.
Chạy mã này bây giờ và yêu cầu 127.0.0.1:7878; bạn sẽ nhận được HTML trong hello.html. Nếu bạn thực hiện bất kỳ yêu cầu nào khác, chẳng hạn như 127.0.0.1:7878/something-else, bạn sẽ nhận được lỗi kết nối giống như những lỗi bạn đã thấy khi chạy mã trong Listing 21-1 và Listing 21-2.
Bây giờ hãy thêm mã trong Listing 21-7 vào khối else để trả về phản hồi với mã
trạng thái 404, báo hiệu rằng nội dung cho yêu cầu không được tìm thấy. Chúng ta
cũng sẽ trả về một số HTML cho một trang để hiển thị trong trình duyệt cho biết
phản hồi cho người dùng cuối.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); // --snip-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contents = fs::read_to_string("404.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } }
Ở đây, phản hồi của chúng ta có một dòng trạng thái với mã trạng thái 404 và cụm
từ lý do NOT FOUND. Thân của phản hồi sẽ là HTML trong file 404.html. Bạn sẽ
cần tạo một file 404.html cạnh hello.html cho trang lỗi; một lần nữa, hãy tự
do sử dụng bất kỳ HTML nào bạn muốn hoặc sử dụng HTML mẫu trong Listing 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Với những thay đổi này, hãy chạy lại máy chủ của bạn. Yêu cầu 127.0.0.1:7878 sẽ trả về nội dung của hello.html, và bất kỳ yêu cầu nào khác, như 127.0.0.1:7878/foo, sẽ trả về HTML lỗi từ 404.html.
Một Chút Tái Cấu Trúc
Tại thời điểm này, các khối if và else có nhiều sự lặp lại: cả hai đều đang
đọc các file và viết nội dung của các file vào luồng. Những khác biệt duy nhất
là dòng trạng thái và tên file. Hãy làm cho mã ngắn gọn hơn bằng cách rút ra
những khác biệt đó thành các dòng if và else riêng biệt sẽ gán giá trị của
dòng trạng thái và tên file cho các biến; sau đó chúng ta có thể sử dụng vô điều
kiện các biến đó trong mã để đọc file và viết phản hồi. Listing 21-9 hiển thị mã
kết quả sau khi thay thế các khối if và else lớn.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Bây giờ các khối if và else chỉ trả về các giá trị thích hợp cho dòng trạng
thái và tên file trong một tuple; sau đó chúng ta sử dụng destructuring để gán
hai giá trị này cho status_line và filename bằng cách sử dụng một mẫu trong
câu lệnh let, như đã thảo luận trong Chương 19.
Mã đã được lặp lại trước đây hiện nằm ngoài các khối if và else và sử dụng
các biến status_line và filename. Điều này làm cho nó dễ dàng hơn để thấy sự
khác biệt giữa hai trường hợp, và có nghĩa là chúng ta chỉ có một nơi để cập
nhật mã nếu chúng ta muốn thay đổi cách đọc file và viết phản hồi. Hành vi của
mã trong Listing 21-9 sẽ giống với mã trong Listing 21-7.
Tuyệt vời! Bây giờ chúng ta có một máy chủ web đơn giản trong khoảng 40 dòng mã Rust phản hồi một yêu cầu với một trang nội dung và phản hồi tất cả các yêu cầu khác với phản hồi 404.
Hiện tại, máy chủ của chúng ta chạy trong một luồng duy nhất, nghĩa là nó chỉ có thể phục vụ một yêu cầu tại một thời điểm. Hãy xem xét làm thế nào điều đó có thể là một vấn đề bằng cách mô phỏng một số yêu cầu chậm. Sau đó, chúng ta sẽ khắc phục nó để máy chủ của chúng ta có thể xử lý nhiều yêu cầu cùng một lúc.
Chuyển Đổi Máy Chủ Đơn Luồng Thành Máy Chủ Đa Luồng
Hiện tại, máy chủ sẽ xử lý từng yêu cầu lần lượt, nghĩa là nó sẽ không xử lý kết nối thứ hai cho đến khi kết nối đầu tiên hoàn tất. Nếu máy chủ nhận được ngày càng nhiều yêu cầu, việc thực thi tuần tự này sẽ ngày càng kém hiệu quả. Nếu máy chủ nhận được một yêu cầu mất nhiều thời gian để xử lý, các yêu cầu tiếp theo sẽ phải đợi cho đến khi yêu cầu dài hoàn thành, ngay cả khi các yêu cầu mới có thể được xử lý nhanh chóng. Chúng ta cần khắc phục điều này, nhưng trước tiên chúng ta sẽ xem xét vấn đề trong thực tế.
Mô Phỏng Yêu Cầu Chậm
Chúng ta sẽ xem xét cách một yêu cầu xử lý chậm có thể ảnh hưởng đến các yêu cầu khác được gửi đến cài đặt máy chủ hiện tại của chúng ta. Listing 21-10 triển khai việc xử lý yêu cầu đến /sleep với một phản hồi chậm mô phỏng sẽ khiến máy chủ ngủ trong năm giây trước khi phản hồi.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --snip-- let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Chúng ta đã chuyển từ if sang match khi đã có ba trường hợp. Chúng ta cần
phải so khớp rõ ràng trên một lát cắt của request_line để khớp mẫu với các giá
trị chuỗi; match không tự động tham chiếu và hủy tham chiếu, như phương thức
so sánh bằng.
Cánh tay đầu tiên giống như khối if từ Listing 21-9. Cánh tay thứ hai khớp với
một yêu cầu đến /sleep. Khi yêu cầu đó được nhận, máy chủ sẽ ngủ trong năm
giây trước khi hiển thị trang HTML thành công. Cánh tay thứ ba giống như khối
else từ Listing 21-9.
Bạn có thể thấy máy chủ của chúng ta nguyên thủy như thế nào: các thư viện thực tế sẽ xử lý việc nhận dạng nhiều yêu cầu theo cách ít dài dòng hơn nhiều!
Khởi động máy chủ bằng cách sử dụng cargo run. Sau đó mở hai cửa sổ trình
duyệt: một cho http://127.0.0.1:7878 và cái kia cho
http://127.0.0.1:7878/sleep. Nếu bạn nhập URI / vài lần, như trước đây, bạn
sẽ thấy nó phản hồi nhanh chóng. Nhưng nếu bạn nhập /sleep và sau đó tải /,
bạn sẽ thấy / đợi cho đến khi sleep đã ngủ đủ năm giây trước khi tải.
Có nhiều kỹ thuật chúng ta có thể sử dụng để tránh các yêu cầu ùn tắc phía sau một yêu cầu chậm, bao gồm việc sử dụng async như chúng ta đã làm trong Chương 17; kỹ thuật chúng ta sẽ triển khai là một thread pool.
Cải Thiện Thông Lượng với Thread Pool
Một thread pool là một nhóm các luồng được tạo ra đang chờ đợi và sẵn sàng xử lý một tác vụ. Khi chương trình nhận được một tác vụ mới, nó gán một trong các luồng trong pool cho tác vụ đó, và luồng đó sẽ xử lý tác vụ. Các luồng còn lại trong pool sẵn sàng xử lý bất kỳ tác vụ nào khác đến trong khi luồng đầu tiên đang xử lý. Khi luồng đầu tiên hoàn thành việc xử lý tác vụ của nó, nó được trả lại pool của các luồng rảnh, sẵn sàng xử lý một tác vụ mới. Thread pool cho phép bạn xử lý các kết nối đồng thời, tăng thông lượng của máy chủ của bạn.
Chúng ta sẽ giới hạn số lượng luồng trong pool ở một số nhỏ để bảo vệ chúng ta khỏi các cuộc tấn công DoS; nếu chúng ta để chương trình của mình tạo một luồng mới cho mỗi yêu cầu khi nó đến, ai đó gửi 10 triệu yêu cầu đến máy chủ của chúng ta có thể gây rối bằng cách sử dụng hết tài nguyên của máy chủ và làm cho việc xử lý yêu cầu dừng lại.
Thay vì tạo ra không giới hạn luồng, chúng ta sẽ có một số lượng cố định luồng
đang chờ trong pool. Các yêu cầu đến được gửi đến pool để xử lý. Pool sẽ duy trì
một hàng đợi các yêu cầu đến. Mỗi luồng trong pool sẽ lấy một yêu cầu từ hàng
đợi này, xử lý yêu cầu, và sau đó hỏi hàng đợi về yêu cầu khác. Với thiết kế
này, chúng ta có thể xử lý đồng thời tối đa N yêu cầu, trong đó N là số
lượng luồng. Nếu mỗi luồng đang đáp ứng một yêu cầu chạy lâu, các yêu cầu tiếp
theo vẫn có thể ùn tắc trong hàng đợi, nhưng chúng ta đã tăng số lượng yêu cầu
chạy lâu mà chúng ta có thể xử lý trước khi đạt đến điểm đó.
Kỹ thuật này chỉ là một trong nhiều cách để cải thiện thông lượng của máy chủ web. Các tùy chọn khác mà bạn có thể khám phá là mô hình fork/join, mô hình I/O không đồng bộ đơn luồng, và mô hình I/O không đồng bộ đa luồng. Nếu bạn quan tâm đến chủ đề này, bạn có thể đọc thêm về các giải pháp khác và thử triển khai chúng; với một ngôn ngữ cấp thấp như Rust, tất cả các tùy chọn này đều có thể.
Trước khi bắt đầu triển khai thread pool, hãy nói về việc sử dụng pool sẽ trông như thế nào. Khi bạn đang cố gắng thiết kế mã, việc viết giao diện khách hàng trước có thể giúp hướng dẫn thiết kế của bạn. Viết API của mã sao cho nó được cấu trúc theo cách bạn muốn gọi nó; sau đó triển khai chức năng trong cấu trúc đó thay vì triển khai chức năng và sau đó thiết kế API công khai.
Tương tự như cách chúng ta đã sử dụng phát triển dựa trên kiểm thử trong dự án trong Chương 12, chúng ta sẽ sử dụng phát triển dựa trên trình biên dịch ở đây. Chúng ta sẽ viết mã gọi các hàm mà chúng ta muốn, và sau đó chúng ta sẽ xem xét các lỗi từ trình biên dịch để xác định những gì chúng ta nên thay đổi tiếp theo để làm cho mã hoạt động. Tuy nhiên, trước khi làm điều đó, chúng ta sẽ khám phá kỹ thuật mà chúng ta sẽ không sử dụng làm điểm khởi đầu.
Tạo một Luồng cho Mỗi Yêu Cầu
Đầu tiên, hãy khám phá cách mã của chúng ta có thể trông như thế nào nếu nó thực sự tạo ra một luồng mới cho mỗi kết nối. Như đã đề cập trước đó, đây không phải là kế hoạch cuối cùng của chúng ta do các vấn đề với việc có thể tạo ra một số lượng không giới hạn các luồng, nhưng nó là một điểm khởi đầu để có được một máy chủ đa luồng hoạt động trước. Sau đó, chúng ta sẽ thêm thread pool như một cải tiến, và việc so sánh hai giải pháp sẽ dễ dàng hơn.
Listing 21-11 hiển thị các thay đổi cần thực hiện đối với main để tạo một
luồng mới để xử lý mỗi luồng trong vòng lặp for.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { handle_connection(stream); }); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Như bạn đã học trong Chương 16, thread::spawn sẽ tạo một luồng mới và sau đó
chạy mã trong closure trong luồng mới. Nếu bạn chạy mã này và tải /sleep trong
trình duyệt của bạn, sau đó / trong hai tab trình duyệt khác, bạn sẽ thấy rằng
các yêu cầu đến / không phải đợi /sleep hoàn thành. Tuy nhiên, như chúng ta
đã đề cập, điều này cuối cùng sẽ làm quá tải hệ thống vì bạn sẽ tạo ra các luồng
mới mà không có bất kỳ giới hạn nào.
Bạn cũng có thể nhớ lại từ Chương 17 rằng đây chính xác là loại tình huống mà async và await thực sự tỏa sáng! Hãy nhớ điều đó khi chúng ta xây dựng thread pool và nghĩ về việc mọi thứ sẽ trông khác hoặc giống nhau như thế nào với async.
Tạo một Số Lượng Giới Hạn Các Luồng
Chúng ta muốn thread pool của mình hoạt động theo cách tương tự, quen thuộc để
việc chuyển đổi từ luồng sang thread pool không yêu cầu thay đổi lớn đối với mã
sử dụng API của chúng ta. Listing 21-12 hiển thị giao diện giả thuyết cho một
cấu trúc ThreadPool mà chúng ta muốn sử dụng thay vì thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Chúng ta sử dụng ThreadPool::new để tạo một thread pool mới với một số lượng
luồng có thể cấu hình, trong trường hợp này là bốn. Sau đó, trong vòng lặp
for, pool.execute có một giao diện tương tự như thread::spawn ở chỗ nó
nhận một closure mà pool nên chạy cho mỗi luồng. Chúng ta cần triển khai
pool.execute để nó lấy closure và đưa nó cho một luồng trong pool để chạy. Mã
này chưa biên dịch, nhưng chúng ta sẽ thử để trình biên dịch có thể hướng dẫn
chúng ta cách khắc phục nó.
Xây Dựng ThreadPool Sử Dụng Phát Triển Dựa Trên Trình Biên Dịch
Thực hiện các thay đổi trong Listing 21-12 cho src/main.rs, và sau đó hãy sử
dụng các lỗi biên dịch từ cargo check để hướng dẫn phát triển của chúng ta.
Đây là lỗi đầu tiên chúng ta nhận được:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Tuyệt! Lỗi này cho chúng ta biết rằng chúng ta cần một loại hoặc module
ThreadPool, vì vậy chúng ta sẽ xây dựng nó ngay bây giờ. Việc triển khai
ThreadPool của chúng ta sẽ độc lập với loại công việc mà máy chủ web của chúng
ta đang làm. Vì vậy, hãy chuyển crate hello từ một crate nhị phân thành một
crate thư viện để giữ việc triển khai ThreadPool của chúng ta. Sau khi chúng
ta chuyển sang crate thư viện, chúng ta cũng có thể sử dụng thư viện thread pool
riêng biệt cho bất kỳ công việc nào chúng ta muốn làm bằng cách sử dụng thread
pool, không chỉ để phục vụ các yêu cầu web.
Tạo một file src/lib.rs chứa những điều sau, đây là định nghĩa đơn giản nhất
của một cấu trúc ThreadPool mà chúng ta có thể có bây giờ:
pub struct ThreadPool;Sau đó chỉnh sửa file main.rs để đưa ThreadPool vào phạm vi từ crate thư
viện bằng cách thêm mã sau vào đầu của src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Mã này vẫn chưa hoạt động, nhưng hãy kiểm tra lại để có được lỗi tiếp theo mà chúng ta cần giải quyết:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Lỗi này chỉ ra rằng tiếp theo chúng ta cần tạo một hàm liên kết có tên new cho
ThreadPool. Chúng ta cũng biết rằng new cần có một tham số có thể chấp nhận
4 làm đối số và nên trả về một thể hiện ThreadPool. Hãy triển khai hàm new
đơn giản nhất có những đặc điểm đó:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}Chúng ta đã chọn usize làm loại của tham số size vì chúng ta biết rằng một
số âm của luồng không có ý nghĩa. Chúng ta cũng biết rằng chúng ta sẽ sử dụng
4 này làm số lượng phần tử trong một bộ sưu tập các luồng, đó là mục đích của
loại usize, như đã thảo luận trong "Các Loại Số
Nguyên" trong Chương 3.
Hãy kiểm tra mã một lần nữa:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Bây giờ lỗi xảy ra vì chúng ta không có phương thức execute trên ThreadPool.
Nhớ lại từ
"Tạo một Số Lượng Giới Hạn Các Luồng"
rằng chúng ta đã quyết định thread pool của mình nên có một giao diện tương tự
như thread::spawn. Ngoài ra, chúng ta sẽ triển khai hàm execute để nó lấy
closure mà nó được cung cấp và giao nó cho một luồng rảnh trong pool để chạy.
Chúng ta sẽ định nghĩa phương thức execute trên ThreadPool để nhận một
closure làm tham số. Nhớ lại từ "Di Chuyển Các Giá Trị Được Bắt Giữ Ra Khỏi
Closure và Các Đặc Điểm Fn" trong Chương 13 rằng
chúng ta có thể lấy closures làm tham số với ba đặc điểm khác nhau: Fn,
FnMut, và FnOnce. Chúng ta cần quyết định loại closure nào để sử dụng ở đây.
Chúng ta biết rằng cuối cùng chúng ta sẽ làm điều gì đó tương tự như việc triển
khai thread::spawn của thư viện chuẩn, vì vậy chúng ta có thể xem xét những
ràng buộc nào mà chữ ký của thread::spawn có trên tham số của nó. Tài liệu
hiển thị cho chúng ta những điều sau:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Tham số loại F là loại chúng ta quan tâm ở đây; tham số loại T liên quan đến
giá trị trả về, và chúng ta không quan tâm đến điều đó. Chúng ta có thể thấy
rằng spawn sử dụng FnOnce làm ràng buộc đặc điểm trên F. Đây có lẽ là điều
chúng ta cũng muốn, vì cuối cùng chúng ta sẽ truyền đối số mà chúng ta nhận được
trong execute cho spawn. Chúng ta có thể tin tưởng hơn rằng FnOnce là đặc
điểm mà chúng ta muốn sử dụng vì luồng để chạy một yêu cầu sẽ chỉ thực thi
closure của yêu cầu đó một lần, điều này phù hợp với Once trong FnOnce.
Tham số loại F cũng có ràng buộc đặc điểm Send và ràng buộc vòng đời
'static, điều này hữu ích trong tình huống của chúng ta: chúng ta cần Send
để chuyển closure từ một luồng sang luồng khác và 'static vì chúng ta không
biết luồng sẽ mất bao lâu để thực thi. Hãy tạo một phương thức execute trên
ThreadPool sẽ lấy một tham số chung kiểu F với những ràng buộc này:
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Chúng ta vẫn sử dụng () sau FnOnce vì FnOnce này đại diện cho một closure
không nhận tham số nào và trả về kiểu đơn vị (). Giống như các định nghĩa hàm,
kiểu trả về có thể được bỏ qua khỏi chữ ký, nhưng ngay cả khi chúng ta không có
tham số nào, chúng ta vẫn cần dấu ngoặc đơn.
Một lần nữa, đây là cách triển khai đơn giản nhất của phương thức execute: nó
không làm gì cả, nhưng chúng ta chỉ đang cố gắng làm cho mã của mình biên dịch.
Hãy kiểm tra lại:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Nó biên dịch! Nhưng lưu ý rằng nếu bạn thử cargo run và thực hiện một yêu cầu
trong trình duyệt, bạn sẽ thấy các lỗi trong trình duyệt mà chúng ta đã thấy ở
đầu chương. Thư viện của chúng ta không thực sự gọi closure được truyền vào
execute nữa!
Lưu ý: Một câu nói mà bạn có thể nghe về các ngôn ngữ với trình biên dịch nghiêm ngặt, như Haskell và Rust, là "nếu mã biên dịch, nó hoạt động." Nhưng câu nói này không phải là sự thật phổ quát. Dự án của chúng ta biên dịch, nhưng nó hoàn toàn không làm gì cả! Nếu chúng ta đang xây dựng một dự án thực tế, hoàn chỉnh, đây sẽ là thời điểm tốt để bắt đầu viết các bài kiểm tra đơn vị để kiểm tra rằng mã biên dịch và có hành vi mà chúng ta muốn.
Hãy xem xét: điều gì sẽ khác ở đây nếu chúng ta sẽ thực thi một future thay vì một closure?
Xác Thực Số Lượng Luồng trong new
Chúng ta không làm gì với các tham số cho new và execute. Hãy triển khai các
thân của các hàm này với hành vi mà chúng ta muốn. Để bắt đầu, hãy nghĩ về
new. Trước đó, chúng ta đã chọn một loại không dấu cho tham số size vì một
pool với số lượng luồng âm không có ý nghĩa. Tuy nhiên, một pool với số luồng là
không cũng không có ý nghĩa, nhưng không là một usize hoàn toàn hợp lệ. Chúng
ta sẽ thêm mã để kiểm tra rằng size lớn hơn không trước khi chúng ta trả về
một thể hiện ThreadPool và có chương trình hoảng sợ nếu nó nhận được một số
không bằng cách sử dụng macro assert!, như được hiển thị trong Listing 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Chúng ta cũng đã thêm một số tài liệu cho ThreadPool của chúng ta với các chú
thích tài liệu. Lưu ý rằng chúng ta đã tuân theo các thực hành tài liệu tốt bằng
cách thêm một phần nêu ra các tình huống mà hàm của chúng ta có thể hoảng sợ,
như đã thảo luận trong Chương 14. Hãy thử chạy cargo doc --open và nhấp vào
cấu trúc ThreadPool để xem tài liệu được tạo ra cho new trông như thế nào!
Thay vì thêm macro assert! như chúng ta đã làm ở đây, chúng ta có thể thay đổi
new thành build và trả về một Result như chúng ta đã làm với
Config::build trong dự án I/O trong Listing 12-9. Nhưng chúng ta đã quyết định
trong trường hợp này rằng việc cố gắng tạo một thread pool mà không có bất kỳ
luồng nào nên là một lỗi không thể khôi phục. Nếu bạn cảm thấy tham vọng, hãy
thử viết một hàm có tên build với chữ ký sau để so sánh với hàm new:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Tạo Không Gian Để Lưu Trữ Các Luồng
Bây giờ chúng ta có một cách để biết chúng ta có một số lượng luồng hợp lệ để
lưu trữ trong pool, chúng ta có thể tạo các luồng đó và lưu trữ chúng trong cấu
trúc ThreadPool trước khi trả về cấu trúc. Nhưng làm thế nào để chúng ta "lưu
trữ" một luồng? Hãy xem lại chữ ký của thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Hàm spawn trả về một JoinHandle<T>, trong đó T là loại mà closure trả về.
Hãy thử sử dụng JoinHandle và xem điều gì xảy ra. Trong trường hợp của chúng
ta, các closure mà chúng ta đang truyền cho thread pool sẽ xử lý kết nối và
không trả về bất cứ điều gì, vì vậy T sẽ là kiểu đơn vị ().
Mã trong Listing 21-14 sẽ biên dịch nhưng chưa tạo bất kỳ luồng nào. Chúng ta đã
thay đổi định nghĩa của ThreadPool để chứa một vector của các thể hiện
thread::JoinHandle<()>, khởi tạo vector với dung lượng là size, thiết lập
một vòng lặp for sẽ chạy một số mã để tạo các luồng, và trả về một thể hiện
ThreadPool chứa chúng.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Chúng ta đã đưa std::thread vào phạm vi trong crate thư viện vì chúng ta đang
sử dụng thread::JoinHandle làm kiểu của các mục trong vector trong
ThreadPool.
Khi một kích thước hợp lệ được nhận, ThreadPool của chúng ta tạo một vector
mới có thể chứa size mục. Hàm with_capacity thực hiện cùng một nhiệm vụ như
Vec::new nhưng với một sự khác biệt quan trọng: nó cấp phát trước không gian
trong vector. Vì chúng ta biết chúng ta cần lưu trữ size phần tử trong vector,
việc thực hiện cấp phát này trước là hiệu quả hơn một chút so với việc sử dụng
Vec::new, việc này tự điều chỉnh kích thước khi các phần tử được chèn vào.
Khi bạn chạy cargo check một lần nữa, nó sẽ thành công.
Gửi Mã từ ThreadPool đến một Luồng
Chúng ta đã để lại một chú thích trong vòng lặp for trong Listing 21-14 liên
quan đến việc tạo các luồng. Ở đây, chúng ta sẽ xem xét cách chúng ta thực sự
tạo ra các luồng. Thư viện chuẩn cung cấp thread::spawn như một cách để tạo
các luồng, và thread::spawn mong đợi nhận được một số mã mà luồng nên chạy
ngay khi luồng được tạo. Tuy nhiên, trong trường hợp của chúng ta, chúng ta muốn
tạo các luồng và có chúng đợi mã mà chúng ta sẽ gửi sau này. Việc triển khai
các luồng của thư viện chuẩn không bao gồm bất kỳ cách nào để làm điều đó; chúng
ta phải triển khai nó theo cách thủ công.
Chúng ta sẽ triển khai hành vi này bằng cách giới thiệu một cấu trúc dữ liệu mới
giữa ThreadPool và các luồng sẽ quản lý hành vi mới này. Chúng ta sẽ gọi cấu
trúc dữ liệu này là Worker, đây là một thuật ngữ phổ biến trong các triển khai
pooling. Worker nhận mã cần được chạy và chạy mã đó trong luồng của nó.
Hãy nghĩ về những người làm việc trong nhà bếp của một nhà hàng: các công nhân đợi cho đến khi đơn đặt hàng đến từ khách hàng, và sau đó họ chịu trách nhiệm lấy các đơn đặt hàng đó và thực hiện chúng.
Thay vì lưu trữ một vector các thể hiện JoinHandle<()> trong thread pool,
chúng ta sẽ lưu trữ các thể hiện của cấu trúc Worker. Mỗi Worker sẽ lưu trữ
một thể hiện JoinHandle<()> duy nhất. Sau đó, chúng ta sẽ triển khai một
phương thức trên Worker sẽ lấy một closure của mã để chạy và gửi nó đến luồng
đã chạy để thực thi. Chúng ta cũng sẽ cung cấp cho mỗi Worker một id để
chúng ta có thể phân biệt giữa các thể hiện khác nhau của Worker trong pool
khi ghi nhật ký hoặc gỡ lỗi.
Đây là quy trình mới sẽ xảy ra khi chúng ta tạo một ThreadPool. Chúng ta sẽ
triển khai mã gửi closure đến luồng sau khi chúng ta đã thiết lập Worker theo
cách này:
- Định nghĩa một cấu trúc
Workerchứa mộtidvà mộtJoinHandle<()>. - Thay đổi
ThreadPoolđể chứa một vector các thể hiệnWorker. - Định nghĩa một hàm
Worker::newnhận một sốidvà trả về một thể hiệnWorkerchứaidvà một luồng được tạo ra với một closure rỗng. - Trong
ThreadPool::new, sử dụng bộ đếm vòng lặpforđể tạo ra mộtid, tạo mộtWorkermới vớiidđó, và lưu trữWorkertrong vector.
Nếu bạn sẵn sàng cho một thử thách, hãy thử triển khai các thay đổi này một mình trước khi xem mã trong Listing 21-15.
Sẵn sàng chưa? Đây là Listing 21-15 với một cách để thực hiện các sửa đổi trước đó.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Chúng ta đã thay đổi tên của trường trên ThreadPool từ threads thành
workers vì nó hiện đang chứa các thể hiện Worker thay vì các thể hiện
JoinHandle<()>. Chúng ta sử dụng bộ đếm trong vòng lặp for làm đối số cho
Worker::new, và chúng ta lưu trữ mỗi Worker mới trong vector có tên
workers.
Mã bên ngoài (như máy chủ của chúng ta trong src/main.rs) không cần biết các
chi tiết triển khai liên quan đến việc sử dụng cấu trúc Worker trong
ThreadPool, vì vậy chúng ta làm cho cấu trúc Worker và hàm new của nó là
riêng tư. Hàm Worker::new sử dụng id mà chúng ta cung cấp và lưu trữ một thể
hiện JoinHandle<()> được tạo ra bằng cách tạo một luồng mới bằng một closure
rỗng.
Lưu ý: Nếu hệ điều hành không thể tạo một luồng vì không có đủ tài nguyên hệ thống,
thread::spawnsẽ hoảng sợ. Điều đó sẽ khiến toàn bộ máy chủ của chúng ta hoảng sợ, ngay cả khi việc tạo một số luồng có thể thành công. Để đơn giản, hành vi này là tốt, nhưng trong một triển khai thread pool sản xuất, bạn có thể muốn sử dụngstd::thread::Buildervà phương thứcspawncủa nó trả vềResultthay thế.
Mã này sẽ biên dịch và sẽ lưu trữ số lượng thể hiện Worker mà chúng ta đã chỉ
định làm đối số cho ThreadPool::new. Nhưng chúng ta vẫn không xử lý closure
mà chúng ta nhận được trong execute. Hãy xem cách làm điều đó tiếp theo.
Gửi Yêu Cầu đến Các Luồng thông qua Các Kênh
Vấn đề tiếp theo mà chúng ta sẽ giải quyết là các closure được đưa cho
thread::spawn hoàn toàn không làm gì cả. Hiện tại, chúng ta nhận được closure
mà chúng ta muốn thực thi trong phương thức execute. Nhưng chúng ta cần cung
cấp cho thread::spawn một closure để chạy khi chúng ta tạo mỗi Worker trong
quá trình tạo ThreadPool.
Chúng ta muốn các cấu trúc Worker mà chúng ta vừa tạo lấy mã để chạy từ một
hàng đợi được giữ trong ThreadPool và gửi mã đó đến luồng của nó để chạy.
Các kênh mà chúng ta đã học trong Chương 16—một cách đơn giản để giao tiếp giữa
hai luồng—sẽ hoàn hảo cho trường hợp sử dụng này. Chúng ta sẽ sử dụng một kênh
để hoạt động như hàng đợi các công việc, và execute sẽ gửi một công việc từ
ThreadPool đến các thể hiện Worker, sẽ gửi công việc đến luồng của nó để
chạy. Đây là kế hoạch:
ThreadPoolsẽ tạo một kênh và giữ người gửi.- Mỗi
Workersẽ giữ người nhận. - Chúng ta sẽ tạo một cấu trúc
Jobmới sẽ chứa các closure mà chúng ta muốn gửi qua kênh. - Phương thức
executesẽ gửi công việc mà nó muốn thực thi thông qua người gửi. - Trong luồng của nó,
Workersẽ lặp qua người nhận của nó và thực thi các closure của bất kỳ công việc nào nó nhận được.
Hãy bắt đầu bằng cách tạo một kênh trong ThreadPool::new và giữ người gửi
trong thể hiện ThreadPool, như được hiển thị trong Listing 21-16. Cấu trúc
Job không chứa gì bây giờ nhưng sẽ là loại mục mà chúng ta đang gửi qua kênh.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Trong ThreadPool::new, chúng ta tạo kênh mới của mình và có pool giữ người
gửi. Điều này sẽ biên dịch thành công.
Hãy thử truyền người nhận của kênh vào mỗi Worker khi thread pool tạo kênh.
Chúng ta biết rằng chúng ta muốn sử dụng người nhận trong luồng mà các thể hiện
Worker tạo ra, vì vậy chúng ta sẽ tham chiếu đến tham số receiver trong
closure. Mã trong Listing 21-17 chưa biên dịch hoàn toàn.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Chúng ta đã thực hiện một số thay đổi nhỏ và đơn giản: chúng ta truyền người
nhận vào Worker::new, và sau đó chúng ta sử dụng nó bên trong closure.
Khi chúng ta cố gắng kiểm tra mã này, chúng ta nhận được lỗi này:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
Mã đang cố gắng truyền receiver cho nhiều thể hiện Worker. Điều này sẽ không
hoạt động, như bạn sẽ nhớ lại từ Chương 16: việc triển khai kênh mà Rust cung
cấp là nhiều producer, một consumer. Điều này có nghĩa là chúng ta không thể
chỉ sao chép đầu tiêu thụ của kênh để sửa mã này. Chúng ta cũng không muốn gửi
một thông điệp nhiều lần đến nhiều người tiêu dùng; chúng ta muốn một danh sách
các thông điệp với nhiều thể hiện Worker sao cho mỗi thông điệp được xử lý một
lần.
Ngoài ra, việc lấy một công việc khỏi hàng đợi kênh liên quan đến việc thay đổi
receiver, vì vậy các luồng cần một cách an toàn để chia sẻ và sửa đổi
receiver; nếu không, chúng ta có thể gặp phải các điều kiện đua (như đã đề cập
trong Chương 16).
Nhớ lại các con trỏ thông minh an toàn cho luồng được thảo luận trong Chương 16:
để chia sẻ quyền sở hữu trên nhiều luồng và cho phép các luồng thay đổi giá trị,
chúng ta cần sử dụng Arc<Mutex<T>>. Loại Arc sẽ cho phép nhiều thể hiện
Worker sở hữu người nhận, và Mutex sẽ đảm bảo rằng chỉ một Worker nhận
được một công việc từ người nhận tại một thời điểm. Listing 21-18 hiển thị các
thay đổi chúng ta cần thực hiện.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Trong ThreadPool::new, chúng ta đặt người nhận trong một Arc và một Mutex.
Đối với mỗi Worker mới, chúng ta sao chép Arc để tăng số đếm tham chiếu để
các thể hiện Worker có thể chia sẻ quyền sở hữu của người nhận.
Với những thay đổi này, mã biên dịch! Chúng ta đang tiến gần đến đích!
Triển Khai Phương Thức execute
Cuối cùng, hãy triển khai phương thức execute trên ThreadPool. Chúng ta cũng
sẽ thay đổi Job từ một cấu trúc thành một bí danh kiểu cho một đối tượng đặc
điểm chứa loại closure mà execute nhận được. Như đã thảo luận trong "Tạo Đồng
Nghĩa Kiểu với Bí Danh
Kiểu" trong Chương 20,
bí danh kiểu cho phép chúng ta làm cho các kiểu dài ngắn hơn để dễ sử dụng. Hãy
xem Listing 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Sau khi tạo một thể hiện Job mới bằng cách sử dụng closure mà chúng ta nhận
được trong execute, chúng ta gửi công việc đó qua đầu gửi của kênh. Chúng ta
đang gọi unwrap trên send cho trường hợp gửi thất bại. Điều này có thể xảy
ra nếu, ví dụ, chúng ta dừng tất cả các luồng của mình từ việc thực thi, nghĩa
là đầu nhận đã dừng nhận các thông điệp mới. Tại thời điểm này, chúng ta không
thể dừng các luồng của mình từ việc thực thi: các luồng của chúng ta tiếp tục
thực thi miễn là pool tồn tại. Lý do chúng ta sử dụng unwrap là vì chúng ta
biết trường hợp thất bại sẽ không xảy ra, nhưng trình biên dịch không biết điều
đó.
Nhưng chúng ta chưa hoàn thành! Trong Worker, closure của chúng ta đang được
truyền cho thread::spawn vẫn chỉ tham chiếu đến đầu nhận của kênh. Thay vào
đó, chúng ta cần closure để lặp mãi mãi, yêu cầu đầu nhận của kênh một công việc
và chạy công việc khi nó nhận được một. Hãy thực hiện thay đổi được hiển thị
trong Listing 21-20 cho Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Ở đây, trước tiên chúng ta gọi lock trên receiver để có được mutex, và sau
đó chúng ta gọi unwrap để hoảng sợ khi có bất kỳ lỗi nào. Việc có được một
khóa có thể không thành công nếu mutex đang ở trạng thái poisoned, điều này có
thể xảy ra nếu một số luồng khác hoảng sợ trong khi giữ khóa thay vì giải phóng
khóa. Trong tình huống này, việc gọi unwrap để có luồng này hoảng sợ là hành
động đúng đắn để thực hiện. Đừng ngại thay đổi unwrap này thành expect với
một thông báo lỗi có ý nghĩa đối với bạn.
Nếu chúng ta có được khóa trên mutex, chúng ta gọi recv để nhận một Job từ
kênh. Một unwrap cuối cùng vượt qua bất kỳ lỗi nào ở đây cũng vậy, có thể xảy
ra nếu luồng giữ người gửi đã tắt, tương tự như cách phương thức send trả về
Err nếu người nhận tắt.
Cuộc gọi đến recv chặn, vì vậy nếu chưa có công việc, luồng hiện tại sẽ đợi
cho đến khi một công việc có sẵn. Mutex<T> đảm bảo rằng chỉ một luồng Worker
tại một thời điểm đang cố gắng yêu cầu một công việc.
Thread pool của chúng ta bây giờ đang ở trạng thái hoạt động! Hãy thử
cargo run và thực hiện một số yêu cầu:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Thành công! Bây giờ chúng ta có một thread pool thực thi các kết nối không đồng bộ. Không bao giờ có nhiều hơn bốn luồng được tạo ra, vì vậy hệ thống của chúng ta sẽ không bị quá tải nếu máy chủ nhận được rất nhiều yêu cầu. Nếu chúng ta thực hiện một yêu cầu đến /sleep, máy chủ sẽ có thể phục vụ các yêu cầu khác bằng cách có một luồng khác chạy chúng.
Lưu ý: Nếu bạn mở /sleep trong nhiều cửa sổ trình duyệt cùng một lúc, chúng có thể tải một cái một lúc trong khoảng thời gian năm giây. Một số trình duyệt web thực thi nhiều phiên bản của cùng một yêu cầu tuần tự vì lý do cache. Hạn chế này không phải do máy chủ web của chúng ta gây ra.
Đây là một thời điểm tốt để tạm dừng và xem xét cách mã trong Listings 21-18, 21-19, và 21-20 sẽ khác nhau nếu chúng ta đang sử dụng futures thay vì closure cho công việc cần thực hiện. Những kiểu nào sẽ thay đổi? Chữ ký phương thức sẽ khác nhau như thế nào, nếu có? Những phần nào của mã sẽ giữ nguyên?
Sau khi học về vòng lặp while let trong Chương 17 và Chương 19, bạn có thể
đang tự hỏi tại sao chúng ta không viết mã luồng công nhân như được hiển thị
trong Listing 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Mã này biên dịch và chạy nhưng không dẫn đến hành vi luồng mong muốn: một yêu
cầu chậm vẫn sẽ khiến các yêu cầu khác phải đợi để được xử lý. Lý do hơi tinh
tế: cấu trúc Mutex không có phương thức unlock công khai vì quyền sở hữu của
khóa dựa trên vòng đời của MutexGuard<T> trong LockResult<MutexGuard<T>> mà
phương thức lock trả về. Tại thời điểm biên dịch, trình kiểm tra mượn sau đó
có thể thực thi quy tắc rằng một tài nguyên được bảo vệ bởi Mutex không thể
được truy cập trừ khi chúng ta giữ khóa. Tuy nhiên, việc triển khai này cũng có
thể dẫn đến khóa được giữ lâu hơn dự định nếu chúng ta không chú ý đến vòng đời
của MutexGuard<T>.
Mã trong Listing 21-20 sử dụng
let job = receiver.lock().unwrap().recv().unwrap(); hoạt động vì với let,
bất kỳ giá trị tạm thời nào được sử dụng trong biểu thức ở phía bên phải của dấu
bằng sẽ bị bỏ ngay lập tức khi câu lệnh let kết thúc. Tuy nhiên, while let
(và if let và match) không bỏ các giá trị tạm thời cho đến khi kết thúc khối
liên kết. Trong Listing 21-21, khóa vẫn được giữ trong suốt thời gian gọi
job(), có nghĩa là các thể hiện Worker khác không thể nhận công việc.
Tắt Máy Nhẹ Nhàng và Dọn Dẹp
Đoạn mã trong Listing 21-20 đang phản hồi các yêu cầu bất đồng bộ thông qua việc
sử dụng thread pool, như chúng ta dự định. Chúng ta nhận được một số cảnh báo về
các trường workers, id, và thread mà chúng ta không sử dụng trực tiếp,
điều này nhắc nhở chúng ta rằng chúng ta không dọn dẹp bất cứ thứ gì. Khi chúng
ta sử dụng phương pháp kém thanh lịch ctrl-C để dừng luồng
chính, tất cả các luồng khác cũng bị dừng ngay lập tức, ngay cả khi chúng đang
trong quá trình phục vụ một yêu cầu.
Tiếp theo, chúng ta sẽ thực hiện đặc tính Drop để gọi join trên mỗi luồng
trong pool để chúng có thể hoàn thành các yêu cầu mà chúng đang xử lý trước khi
đóng. Sau đó, chúng ta sẽ thực hiện một cách để cho các luồng biết rằng chúng
nên dừng chấp nhận các yêu cầu mới và tắt. Để xem mã này hoạt động, chúng ta sẽ
sửa đổi máy chủ của mình để chỉ chấp nhận hai yêu cầu trước khi tắt thread pool
một cách nhẹ nhàng.
Một điều cần lưu ý khi chúng ta tiến hành: không có gì trong phần này ảnh hưởng đến các phần của mã xử lý việc thực thi các closure, vì vậy mọi thứ ở đây sẽ giống hệt nhau nếu chúng ta đang sử dụng thread pool cho một môi trường thực thi bất đồng bộ.
Thực Hiện Đặc Tính Drop trên ThreadPool
Hãy bắt đầu với việc thực hiện Drop trên thread pool của chúng ta. Khi pool bị
huỷ, các luồng của chúng ta đều nên tham gia (join) để đảm bảo chúng hoàn thành
công việc của mình. Listing 21-22 hiển thị nỗ lực đầu tiên để thực hiện Drop;
mã này chưa hoạt động hoàn toàn.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Đầu tiên chúng ta lặp qua từng worker trong thread pool. Chúng ta sử dụng
&mut cho việc này vì self là một tham chiếu có thể thay đổi, và chúng ta
cũng cần có khả năng thay đổi worker. Đối với mỗi worker, chúng ta in một
thông báo cho biết thể hiện Worker cụ thể này đang tắt, sau đó chúng ta gọi
join trên luồng của thể hiện Worker đó. Nếu lệnh gọi join thất bại, chúng
ta sử dụng unwrap để làm cho Rust hoảng loạn (panic) và chuyển sang tắt không
nhẹ nhàng.
Đây là lỗi chúng ta nhận được khi biên dịch mã này:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
Lỗi cho chúng ta biết rằng chúng ta không thể gọi join vì chúng ta chỉ có một
tham chiếu có thể thay đổi của mỗi worker và join lấy quyền sở hữu của đối
số của nó. Để giải quyết vấn đề này, chúng ta cần di chuyển luồng ra khỏi thể
hiện Worker sở hữu thread để join có thể tiêu thụ luồng. Một cách để làm
điều này là bằng cách sử dụng cùng một phương pháp mà chúng ta đã làm trong
Listing 18-15. Nếu Worker giữ một Option<thread::JoinHandle<()>>, chúng ta
có thể gọi phương thức take trên Option để di chuyển giá trị ra khỏi biến
thể Some và để lại một biến thể None ở vị trí của nó. Nói cách khác, một
Worker đang chạy sẽ có một biến thể Some trong thread, và khi chúng ta
muốn dọn dẹp một Worker, chúng ta sẽ thay thế Some bằng None để Worker
không có luồng để chạy.
Tuy nhiên, chỉ thời điểm này sẽ xuất hiện là khi huỷ Worker. Để đổi lại,
chúng ta sẽ phải xử lý một Option<thread::JoinHandle<()>> bất cứ nơi nào chúng
ta truy cập worker.thread. Rust thành ngữ sử dụng Option khá nhiều, nhưng
khi bạn thấy mình bọc thứ gì đó mà bạn biết sẽ luôn có mặt trong Option như
một giải pháp tạm thời như thế này, đó là một ý tưởng tốt để tìm kiếm các phương
pháp thay thế để làm cho mã của bạn sạch hơn và ít dễ xảy ra lỗi hơn.
Trong trường hợp này, một giải pháp thay thế tốt hơn tồn tại: phương thức
Vec::drain. Nó chấp nhận một tham số phạm vi để chỉ định các mục cần xóa khỏi
vector và trả về một iterator của các mục đó. Truyền cú pháp phạm vi .. sẽ xóa
mọi giá trị khỏi vector.
Vì vậy, chúng ta cần cập nhật việc thực hiện drop của ThreadPool như thế
này:
#![allow(unused)] fn main() { use std::{ sync::{Arc, Mutex, mpsc}, thread, }; pub struct ThreadPool { workers: Vec<Worker>, sender: mpsc::Sender<Job>, } type Job = Box<dyn FnOnce() + Send + 'static>; impl ThreadPool { /// Create a new ThreadPool. /// /// The size is the number of threads in the pool. /// /// # Panics /// /// The `new` function will panic if the size is zero. pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let (sender, receiver) = mpsc::channel(); let receiver = Arc::new(Mutex::new(receiver)); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id, Arc::clone(&receiver))); } ThreadPool { workers, sender } } pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { let job = Box::new(f); self.sender.send(job).unwrap(); } } impl Drop for ThreadPool { fn drop(&mut self) { for worker in self.workers.drain(..) { println!("Shutting down worker {}", worker.id); worker.thread.join().unwrap(); } } } struct Worker { id: usize, thread: thread::JoinHandle<()>, } impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { loop { let job = receiver.lock().unwrap().recv().unwrap(); println!("Worker {id} got a job; executing."); job(); } }); Worker { id, thread } } } }
Điều này giải quyết lỗi biên dịch và không yêu cầu bất kỳ thay đổi nào khác cho mã của chúng ta. Lưu ý rằng, vì drop có thể được gọi khi hoảng loạn, unwrap cũng có thể hoảng loạn và gây ra hoảng loạn kép, điều này ngay lập tức làm sập chương trình và kết thúc bất kỳ quá trình dọn dẹp nào đang diễn ra. Điều này ổn đối với một chương trình ví dụ, nhưng không được khuyến nghị cho mã sản xuất.
Báo Hiệu cho Các Luồng Dừng Lắng Nghe Công Việc
Với tất cả các thay đổi chúng ta đã thực hiện, mã của chúng ta biên dịch mà
không có bất kỳ cảnh báo nào. Tuy nhiên, tin xấu là mã này chưa hoạt động theo
cách chúng ta muốn. Chìa khóa là logic trong các closure được chạy bởi các luồng
của các thể hiện Worker: tại thời điểm này, chúng ta gọi join, nhưng điều đó
sẽ không tắt các luồng, vì chúng loop mãi mãi tìm kiếm công việc. Nếu chúng ta
thử huỷ ThreadPool của mình với cách thực hiện drop hiện tại, luồng chính sẽ
bị chặn mãi mãi, chờ đợi luồng đầu tiên hoàn thành.
Để khắc phục vấn đề này, chúng ta sẽ cần thay đổi trong cách thực hiện drop
của ThreadPool và sau đó thay đổi trong vòng lặp Worker.
Đầu tiên, chúng ta sẽ thay đổi cách thực hiện drop của ThreadPool để rõ ràng
huỷ sender trước khi đợi các luồng hoàn thành. Listing 21-23 hiển thị các thay
đổi đối với ThreadPool để rõ ràng huỷ sender. Không giống như với luồng, ở
đây chúng ta thực sự cần sử dụng Option để có thể di chuyển sender ra khỏi
ThreadPool với Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Việc huỷ sender đóng kênh, điều này chỉ ra rằng không có thêm thông báo nào sẽ
được gửi. Khi điều đó xảy ra, tất cả các lệnh gọi recv mà các thể hiện
Worker thực hiện trong vòng lặp vô hạn sẽ trả về một lỗi. Trong Listing 21-24,
chúng ta thay đổi vòng lặp Worker để nhẹ nhàng thoát khỏi vòng lặp trong
trường hợp đó, điều đó có nghĩa là các luồng sẽ kết thúc khi thực hiện drop
của ThreadPool gọi join trên chúng.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}Để xem mã này hoạt động, hãy sửa đổi main để chỉ chấp nhận hai yêu cầu trước
khi tắt máy chủ một cách nhẹ nhàng, như được hiển thị trong Listing 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Bạn sẽ không muốn một máy chủ web trong thế giới thực tắt sau khi phục vụ chỉ hai yêu cầu. Mã này chỉ chứng minh rằng việc tắt nhẹ nhàng và dọn dẹp đang hoạt động tốt.
Phương thức take được định nghĩa trong đặc tính Iterator và giới hạn vòng
lặp tối đa là hai mục đầu tiên. ThreadPool sẽ ra khỏi phạm vi khi kết thúc
main, và việc thực hiện drop sẽ chạy.
Khởi động máy chủ với cargo run, và thực hiện ba yêu cầu. Yêu cầu thứ ba sẽ bị
lỗi, và trong terminal của bạn, bạn sẽ thấy đầu ra tương tự như thế này:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
Bạn có thể thấy thứ tự ID Worker và thông báo được in khác nhau. Chúng ta có
thể thấy cách mã này hoạt động từ các thông báo: các thể hiện Worker 0 và 3
nhận hai yêu cầu đầu tiên. Máy chủ dừng chấp nhận kết nối sau kết nối thứ hai,
và việc thực hiện Drop trên ThreadPool bắt đầu thực thi trước khi Worker 3
thậm chí bắt đầu công việc của nó. Việc huỷ sender ngắt kết nối tất cả các thể
hiện Worker và cho chúng biết phải tắt. Các thể hiện Worker mỗi thể hiện in
một thông báo khi chúng ngắt kết nối, và sau đó thread pool gọi join để đợi
mỗi luồng Worker hoàn thành.
Hãy chú ý một khía cạnh thú vị của việc thực thi cụ thể này: ThreadPool đã huỷ
sender, và trước khi bất kỳ Worker nào nhận được lỗi, chúng ta đã cố gắng
tham gia Worker 0. Worker 0 chưa nhận được lỗi từ recv, vì vậy luồng chính
bị chặn, chờ đợi Worker 0 hoàn thành. Trong khi đó, Worker 3 nhận được một
công việc và sau đó tất cả các luồng nhận được lỗi. Khi Worker 0 hoàn thành,
luồng chính đợi phần còn lại của các thể hiện Worker hoàn thành. Tại thời điểm
đó, tất cả chúng đều đã thoát khỏi vòng lặp của chúng và dừng lại.
Xin chúc mừng! Bây giờ chúng ta đã hoàn thành dự án của mình; chúng ta có một máy chủ web cơ bản sử dụng thread pool để phản hồi bất đồng bộ. Chúng ta có thể thực hiện việc tắt máy chủ một cách nhẹ nhàng, điều này dọn dẹp tất cả các luồng trong pool.
Đây là toàn bộ mã để tham khảo:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Chúng ta có thể làm nhiều hơn nữa ở đây! Nếu bạn muốn tiếp tục nâng cao dự án này, đây là một số ý tưởng:
- Thêm nhiều tài liệu vào
ThreadPoolvà các phương thức công khai của nó. - Thêm các bài kiểm tra chức năng của thư viện.
- Thay đổi các lệnh gọi
unwrapthành xử lý lỗi mạnh mẽ hơn. - Sử dụng
ThreadPoolđể thực hiện một số tác vụ khác ngoài việc phục vụ các yêu cầu web. - Tìm một crate thread pool trên crates.io và thực hiện một máy chủ web tương tự bằng cách sử dụng crate thay thế. Sau đó so sánh API và độ mạnh mẽ của nó với thread pool mà chúng ta đã thực hiện.
Tổng Kết
Làm tốt lắm! Bạn đã đến được cuối sách! Chúng tôi muốn cảm ơn bạn đã tham gia cùng chúng tôi trong chuyến tham quan Rust này. Bây giờ bạn đã sẵn sàng để thực hiện các dự án Rust của riêng mình và giúp đỡ với các dự án của người khác. Hãy nhớ rằng có một cộng đồng chào đón của các Rustacean khác sẵn sàng giúp đỡ bạn với bất kỳ thách thức nào bạn gặp phải trên hành trình Rust của mình.
Phụ lục
Các phần sau đây chứa những tài liệu tham khảo mà bạn có thể thấy hữu ích trong hành trình học Rust của mình.
Phụ lục A: Các từ khóa
Danh sách sau đây chứa các từ khóa được dành riêng cho việc sử dụng hiện tại hoặc trong tương lai của ngôn ngữ Rust. Do đó, chúng không thể được sử dụng làm định danh (ngoại trừ khi dùng làm định danh thô như chúng ta thảo luận trong phần “Định danh thô“). Định danh là tên của các hàm, biến, tham số, trường của struct, module, crate, hằng số, macro, giá trị tĩnh, thuộc tính, kiểu dữ liệu, trait, hoặc lifetime.
Các từ khóa hiện đang được sử dụng
Sau đây là danh sách các từ khóa hiện đang được sử dụng, cùng với mô tả chức năng của chúng.
as: thực hiện ép kiểu nguyên thủy, làm rõ trait cụ thể chứa một item, hoặc đổi tên các item trong câu lệnhuseasync: trả về mộtFuturethay vì chặn luồng hiện tạiawait: tạm dừng thực thi cho đến khi kết quả của mộtFuturesẵn sàngbreak: thoát khỏi vòng lặp ngay lập tứcconst: định nghĩa các hằng số item hoặc hằng số con trỏ thôcontinue: tiếp tục với vòng lặp tiếp theocrate: trong đường dẫn module, tham chiếu đến gốc của cratedyn: phân phối động (dynamic dispatch) đến một trait objectelse: dự phòng cho các cấu trúc luồng điều khiểnifvàif letenum: định nghĩa một kiểu liệt kêextern: liên kết một hàm hoặc biến bên ngoàifalse: giá trị Boolean falsefn: định nghĩa một hàm hoặc kiểu con trỏ hàmfor: lặp qua các item từ một iterator, triển khai một trait, hoặc chỉ định một lifetime cao hơnif: rẽ nhánh dựa trên kết quả của một biểu thức điều kiệnimpl: triển khai phương thức gốc hoặc traitin: một phần của cú pháp vòng lặpforlet: gán một biếnloop: lặp vô điều kiệnmatch: so khớp một giá trị với các mẫumod: định nghĩa một modulemove: làm cho một closure chiếm quyền sở hữu của tất cả các giá trị mà nó bắt giữmut: chỉ định tính khả biến trong các tham chiếu, con trỏ thô, hoặc gán mẫupub: chỉ định tính công khai trong các trường của struct, khốiimpl, hoặc moduleref: gán bằng tham chiếureturn: trả về từ hàmSelf: một kiểu bí danh cho kiểu mà chúng ta đang định nghĩa hoặc triển khaiself: đối tượng hiện tại trong phương thức hoặc module hiện tạistatic: biến toàn cục hoặc lifetime kéo dài trong toàn bộ thời gian thực thi của chương trìnhstruct: định nghĩa một structsuper: module cha của module hiện tạitrait: định nghĩa một traittrue: giá trị Boolean truetype: định nghĩa một kiểu bí danh hoặc kiểu liên kếtunion: định nghĩa một union; chỉ là từ khóa khi được sử dụng trong một khai báo unionunsafe: chỉ định mã, hàm, trait, hoặc triển khai không an toànuse: đưa các ký hiệu vào phạm vi; chỉ định các capture chính xác cho generic và ràng buộc lifetimewhere: chỉ định các điều kiện ràng buộc một kiểuwhile: lặp có điều kiện dựa trên kết quả của một biểu thức
Các từ khóa được dành riêng cho sử dụng trong tương lai
Các từ khóa sau đây chưa có chức năng cụ thể nhưng được Rust dành riêng cho khả năng sử dụng trong tương lai:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Định danh thô
Định danh thô là cú pháp cho phép bạn sử dụng các từ khóa ở những nơi thông
thường không được phép. Bạn sử dụng định danh thô bằng cách thêm tiền tố r#
vào trước từ khóa.
Ví dụ, match là một từ khóa. Nếu bạn thử biên dịch hàm sau đây sử dụng match
làm tên của nó:
Tên tệp: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}bạn sẽ nhận được lỗi này:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Lỗi này cho thấy bạn không thể sử dụng từ khóa match làm định danh hàm. Để sử
dụng match làm tên hàm, bạn cần sử dụng cú pháp định danh thô, như sau:
Tên tệp: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
Mã này sẽ biên dịch mà không có bất kỳ lỗi nào. Lưu ý tiền tố r# trên tên hàm
trong định nghĩa cũng như nơi hàm được gọi trong main.
Định danh thô cho phép bạn sử dụng bất kỳ từ nào làm định danh, ngay cả khi từ
đó tình cờ là một từ khóa dành riêng. Điều này mang lại cho chúng ta nhiều tự do
hơn trong việc chọn tên định danh, cũng như cho phép chúng ta tích hợp với các
chương trình được viết bằng ngôn ngữ mà các từ này không phải là từ khóa. Ngoài
ra, định danh thô cho phép bạn sử dụng các thư viện được viết bằng phiên bản
Rust khác với phiên bản mà crate của bạn sử dụng. Ví dụ, try không phải là từ
khóa trong phiên bản 2015 nhưng lại là từ khóa trong các phiên bản 2018, 2021,
và 2024. Nếu bạn phụ thuộc vào một thư viện được viết bằng phiên bản 2015 và có
một hàm try, bạn sẽ cần sử dụng cú pháp định danh thô, r#try trong trường
hợp này, để gọi hàm đó từ mã của bạn trên các phiên bản sau. Xem Phụ lục
E để biết thêm thông tin về các phiên bản.
Phụ lục B: Các toán tử và ký hiệu
Phụ lục này chứa danh mục các cú pháp của Rust, bao gồm các toán tử và các ký hiệu khác xuất hiện độc lập hoặc trong ngữ cảnh của đường dẫn, generics, ràng buộc trait, macro, thuộc tính, bình luận, tuple và dấu ngoặc.
Các toán tử
Bảng B-1 chứa các toán tử trong Rust, một ví dụ về cách toán tử xuất hiện trong ngữ cảnh, một lời giải thích ngắn gọn và liệu toán tử đó có thể được nạp chồng hay không. Nếu một toán tử có thể được nạp chồng, trait có liên quan được sử dụng để nạp chồng toán tử đó được liệt kê.
Bảng B-1: Các toán tử
| Toán tử | Ví dụ | Giải thích | Nạp chồng? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Mở rộng macro | |
! | !expr | Phủ định bit hoặc logic | Not |
!= | expr != expr | So sánh không bằng | PartialEq |
% | expr % expr | Phép chia lấy dư | Rem |
%= | var %= expr | Phép chia lấy dư và gán | RemAssign |
& | &expr, &mut expr | Mượn (borrow) | |
& | &type, &mut type, &'a type, &'a mut type | Kiểu con trỏ mượn | |
& | expr & expr | Phép AND bit | BitAnd |
&= | var &= expr | Phép AND bit và gán | BitAndAssign |
&& | expr && expr | Phép AND logic ngắn mạch | |
* | expr * expr | Phép nhân số học | Mul |
*= | var *= expr | Phép nhân số học và gán | MulAssign |
* | *expr | Dereference (giải tham chiếu) | Deref |
* | *const type, *mut type | Con trỏ thô | |
+ | trait + trait, 'a + trait | Ràng buộc kiểu phức hợp | |
+ | expr + expr | Phép cộng số học | Add |
+= | var += expr | Phép cộng số học và gán | AddAssign |
, | expr, expr | Phân cách đối số và phần tử | |
- | - expr | Phủ định số học (đổi dấu) | Neg |
- | expr - expr | Phép trừ số học | Sub |
-= | var -= expr | Phép trừ số học và gán | SubAssign |
-> | fn(...) -> type, |...| -> type | Kiểu trả về của hàm và closure | |
. | expr.ident | Truy cập trường | |
. | expr.ident(expr, ...) | Gọi phương thức | |
. | expr.0, expr.1, v.v. | Truy cập phần tử của tuple theo chỉ mục | |
.. | .., expr.., ..expr, expr..expr | Khoảng (range) loại trừ bên phải | PartialOrd |
..= | ..=expr, expr..=expr | Khoảng (range) bao gồm bên phải | PartialOrd |
.. | ..expr | Cú pháp cập nhật biểu thức struct | |
.. | variant(x, ..), struct_type { x, .. } | Gán mẫu "và phần còn lại" | |
... | expr...expr | (Đã lỗi thời, sử dụng ..= thay thế) Trong mẫu: mẫu khoảng bao gồm | |
/ | expr / expr | Phép chia số học | Div |
/= | var /= expr | Phép chia số học và gán | DivAssign |
: | pat: type, ident: type | Ràng buộc | |
: | ident: expr | Khởi tạo trường struct | |
: | 'a: loop {...} | Nhãn vòng lặp | |
; | expr; | Kết thúc câu lệnh và mục | |
; | [...; len] | Một phần của cú pháp mảng kích thước cố định | |
<< | expr << expr | Dịch trái | Shl |
<<= | var <<= expr | Dịch trái và gán | ShlAssign |
< | expr < expr | So sánh nhỏ hơn | PartialOrd |
<= | expr <= expr | So sánh nhỏ hơn hoặc bằng | PartialOrd |
= | var = expr, ident = type | Gán/tương đương | |
== | expr == expr | So sánh bằng | PartialEq |
=> | pat => expr | Một phần của cú pháp nhánh match | |
> | expr > expr | So sánh lớn hơn | PartialOrd |
>= | expr >= expr | So sánh lớn hơn hoặc bằng | PartialOrd |
>> | expr >> expr | Dịch phải | Shr |
>>= | var >>= expr | Dịch phải và gán | ShrAssign |
@ | ident @ pat | Gán mẫu | |
^ | expr ^ expr | Phép XOR bit | BitXor |
^= | var ^= expr | Phép XOR bit và gán | BitXorAssign |
| | pat | pat | Các mẫu thay thế | |
| | expr | expr | Phép OR bit | BitOr |
|= | var |= expr | Phép OR bit và gán | BitOrAssign |
|| | expr || expr | Phép OR logic ngắn mạch | |
? | expr? | Truyền lỗi |
Các ký hiệu không phải toán tử
Các bảng sau đây chứa tất cả các ký hiệu không hoạt động như các toán tử; nghĩa là, chúng không hoạt động như một lời gọi hàm hoặc phương thức.
Bảng B-2 hiển thị các ký hiệu xuất hiện độc lập và hợp lệ trong nhiều vị trí khác nhau.
Bảng B-2: Cú pháp độc lập
| Ký hiệu | Giải thích |
|---|---|
'ident | Tên Lifetime hoặc nhãn vòng lặp |
Chữ số theo ngay sau bởi u8, i32, f64, usize, v.v. | Giá trị số có kiểu cụ thể |
"..." | Chuỗi ký tự |
r"...", r#"..."#, r##"..."##, v.v. | Chuỗi ký tự thô; các ký tự thoát không được xử lý |
b"..." | Chuỗi byte; tạo mảng byte thay vì chuỗi |
br"...", br#"..."#, br##"..."##, v.v. | Chuỗi byte thô; kết hợp của chuỗi thô và chuỗi byte |
'...' | Ký tự |
b'...' | Byte ASCII |
|...| expr | Closure |
! | Kiểu bottom luôn trống cho các hàm phân kỳ |
_ | Gán mẫu "bị bỏ qua"; cũng được sử dụng để làm cho số nguyên dễ đọc hơn |
Bảng B-3 hiển thị các ký hiệu xuất hiện trong ngữ cảnh của đường dẫn thông qua hệ thống phân cấp module đến một mục.
Bảng B-3: Cú pháp đường dẫn liên kết
| Ký hiệu | Giải thích |
|---|---|
ident::ident | Đường dẫn namespace |
::path | Đường dẫn liên kết tới crate gốc (tức là, một đường dẫn tuyệt đối) |
self::path | Đường dẫn liên kết tới module hiện tại (tức là, một đường dẫn tương đối). |
super::path | Đường dẫn liên kết với module cha của module hiện tại |
type::ident, <type as trait>::ident | Các hằng số, hàm và kiểu liên kết |
<type>::... | Mục liên kết cho một kiểu không thể được đặt tên trực tiếp (ví dụ, <&T>::..., <[T]>::..., v.v.) |
trait::method(...) | Làm rõ lời gọi phương thức bằng cách đặt tên trait định nghĩa nó |
type::method(...) | Làm rõ lời gọi phương thức bằng cách đặt tên kiểu mà nó được định nghĩa |
<type as trait>::method(...) | Làm rõ lời gọi phương thức bằng cách đặt tên trait và kiểu |
Bảng B-4 hiển thị các ký hiệu xuất hiện trong ngữ cảnh của việc sử dụng các tham số kiểu generic.
Bảng B-4: Generics
| Ký hiệu | Giải thích |
|---|---|
path<...> | Chỉ định tham số cho một kiểu generic trong một kiểu (ví dụ, Vec<u8>) |
path::<...>, method::<...> | Chỉ định tham số cho một kiểu generic, hàm hoặc phương thức trong một biểu thức; thường được gọi là turbofish (ví dụ, "42".parse::<i32>()) |
fn ident<...> ... | Định nghĩa hàm generic |
struct ident<...> ... | Định nghĩa struct generic |
enum ident<...> ... | Định nghĩa enum generic |
impl<...> ... | Định nghĩa triển khai generic |
for<...> type | Ràng buộc lifetime bậc cao hơn |
type<ident=type> | Một kiểu generic trong đó một hoặc nhiều kiểu liên kết có gán cụ thể (ví dụ, Iterator<Item=T>) |
Bảng B-5 hiển thị các ký hiệu xuất hiện trong ngữ cảnh của việc ràng buộc các tham số kiểu generic với các ràng buộc trait.
Bảng B-5: Ràng buộc Trait
| Ký hiệu | Giải thích |
|---|---|
T: U | Tham số generic T bị ràng buộc vào các kiểu triển khai U |
T: 'a | Kiểu generic T phải tồn tại lâu hơn lifetime 'a (nghĩa là kiểu không thể chứa bất kỳ tham chiếu nào có lifetime ngắn hơn 'a) |
T: 'static | Kiểu generic T không chứa các tham chiếu được mượn ngoài tham chiếu 'static |
'b: 'a | Lifetime generic 'b phải tồn tại lâu hơn lifetime 'a |
T: ?Sized | Cho phép tham số kiểu generic là một kiểu có kích thước động |
'a + trait, trait + trait | Ràng buộc kiểu phức hợp |
Bảng B-6 hiển thị các ký hiệu xuất hiện trong ngữ cảnh của việc gọi hoặc định nghĩa macro và chỉ định thuộc tính trên một mục.
Bảng B-6: Macro và thuộc tính
| Ký hiệu | Giải thích |
|---|---|
#[meta] | Thuộc tính ngoài |
#![meta] | Thuộc tính trong |
$ident | Thay thế macro |
$ident:kind | Biến siêu macro |
$(...)... | Lặp lại macro |
ident!(...), ident!{...}, ident![...] | Gọi macro |
Bảng B-7 hiển thị các ký hiệu tạo bình luận.
Bảng B-7: Bình luận
| Ký hiệu | Giải thích |
|---|---|
// | Bình luận dòng |
//! | Bình luận tài liệu dòng bên trong |
/// | Bình luận tài liệu dòng bên ngoài |
/*...*/ | Bình luận khối |
/*!...*/ | Bình luận tài liệu khối bên trong |
/**...*/ | Bình luận tài liệu khối bên ngoài |
Bảng B-8 hiển thị các ngữ cảnh mà dấu ngoặc đơn được sử dụng.
Bảng B-8: Dấu ngoặc đơn
| Ký hiệu | Giải thích |
|---|---|
() | Tuple rỗng (còn gọi là unit), cả kiểu và giá trị |
(expr) | Biểu thức trong ngoặc đơn |
(expr,) | Biểu thức tuple một phần tử |
(type,) | Kiểu tuple một phần tử |
(expr, ...) | Biểu thức tuple |
(type, ...) | Kiểu tuple |
expr(expr, ...) | Biểu thức gọi hàm; cũng được sử dụng để khởi tạo struct tuple và biến thể enum tuple |
Bảng B-9 hiển thị các ngữ cảnh mà dấu ngoặc nhọn được sử dụng.
Bảng B-9: Dấu ngoặc nhọn
| Ngữ cảnh | Giải thích |
|---|---|
{...} | Biểu thức khối |
Type {...} | Giá trị struct |
Bảng B-10 hiển thị các ngữ cảnh mà dấu ngoặc vuông được sử dụng.
Bảng B-10: Dấu ngoặc vuông
| Ngữ cảnh | Giải thích |
|---|---|
[...] | Giá trị mảng |
[expr; len] | Giá trị mảng chứa len bản sao của expr |
[type; len] | Kiểu mảng chứa len thể hiện của type |
expr[expr] | Truy cập phần tử của collection; có thể nạp chồng (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Truy cập phần tử của collection thành lát cắt collection, sử dụng Range, RangeFrom, RangeTo hoặc RangeFull làm "chỉ mục" |
Phụ lục C: Các Trait có thể dẫn xuất
Trong nhiều phần của cuốn sách này, chúng ta đã thảo luận về thuộc tính
derive, có thể áp dụng cho định nghĩa struct hoặc enum. Thuộc tính derive
tạo ra mã sẽ triển khai một trait với triển khai mặc định của nó trên kiểu mà
bạn đã chú thích với cú pháp derive (dẫn xuất).
Trong phụ lục này, chúng tôi cung cấp một tài liệu tham khảo về tất cả các trait
trong thư viện chuẩn mà bạn có thể sử dụng với derive. Mỗi phần bao gồm:
- Những toán tử và phương thức nào mà trait này sẽ kích hoạt
- Triển khai của trait được cung cấp bởi
derivelàm gì - Việc triển khai trait báo hiệu điều gì về kiểu đó
- Những điều kiện mà bạn được phép hoặc không được phép triển khai trait
- Các ví dụ về các hoạt động yêu cầu trait này
Nếu bạn muốn có hành vi khác với hành vi được cung cấp bởi thuộc tính derive,
hãy tham khảo
tài liệu thư viện chuẩn
cho mỗi trait để biết chi tiết về cách triển khai chúng thủ công.
Các trait được liệt kê ở đây là những trait được định nghĩa bởi thư viện chuẩn
mà có thể được triển khai cho các kiểu của bạn bằng cách sử dụng derive. Các
trait khác được định nghĩa trong thư viện chuẩn không có hành vi mặc định hợp
lý, vì vậy việc triển khai chúng theo cách phù hợp với mục đích của bạn là tùy
thuộc vào bạn.
Một ví dụ về trait không thể được derive là Display, xử lý việc định dạng cho
người dùng cuối. Bạn nên luôn cân nhắc cách thích hợp để hiển thị một kiểu cho
người dùng cuối. Những phần nào của kiểu mà người dùng cuối nên được phép xem?
Những phần nào họ sẽ thấy liên quan? Định dạng dữ liệu nào sẽ liên quan nhất đối
với họ? Trình biên dịch Rust không có cái nhìn sâu sắc này, vì vậy nó không thể
cung cấp hành vi mặc định phù hợp cho bạn.
Danh sách các trait có thể derive được cung cấp trong phụ lục này không toàn
diện: Các thư viện có thể triển khai derive cho các trait của riêng họ, làm
cho danh sách các trait mà bạn có thể sử dụng derive thực sự mở rộng. Việc
triển khai derive liên quan đến việc sử dụng một macro thủ tục, được đề cập
trong phần "Macro derive tuỳ chỉnh"
trong Chương 20.
Debug cho đầu ra dành cho lập trình viên
Trait Debug cho phép định dạng gỡ lỗi trong chuỗi định dạng, bạn chỉ định bằng
cách thêm :? trong các placeholder {}.
Trait Debug cho phép bạn in các thể hiện của một kiểu cho mục đích gỡ lỗi, để
bạn và các lập trình viên khác sử dụng kiểu của bạn có thể kiểm tra một thể hiện
tại một điểm cụ thể trong quá trình thực thi của chương trình.
Trait Debug được yêu cầu, ví dụ, khi sử dụng macro assert_eq!. Macro này in
ra giá trị của các thể hiện được đưa ra làm đối số nếu phép khẳng định bằng thất
bại để các lập trình viên có thể thấy tại sao hai thể hiện không bằng nhau.
PartialEq và Eq cho so sánh bằng
Trait PartialEq cho phép bạn so sánh các thể hiện của một kiểu để kiểm tra sự
bằng nhau và cho phép sử dụng các toán tử == và !=.
Việc derive PartialEq triển khai phương thức eq. Khi PartialEq được derive
trên các struct, hai thể hiện chỉ bình đẳng khi tất cả các trường bằng nhau,
và các thể hiện không bằng nhau nếu bất kỳ trường nào không bằng nhau. Khi
được derive trên enum, mỗi biến thể bằng nhau với chính nó và không bằng nhau
với các biến thể khác.
Trait PartialEq là cần thiết, ví dụ, khi sử dụng macro assert_eq!, cần có
khả năng so sánh hai thể hiện của một kiểu về sự bằng nhau.
Trait Eq không có phương thức nào. Mục đích của nó là báo hiệu rằng với mọi
giá trị của kiểu được chú thích, giá trị đó bằng chính nó. Trait Eq chỉ có thể
được áp dụng cho các kiểu cũng triển khai PartialEq, mặc dù không phải tất cả
các kiểu triển khai PartialEq đều có thể triển khai Eq. Một ví dụ về điều
này là các kiểu số thực dấu phẩy động: Việc triển khai số thực dấu phẩy động nêu
rõ rằng hai thể hiện của giá trị không phải một số (NaN) không bằng nhau.
Một ví dụ về khi Eq được yêu cầu là đối với các khóa trong HashMap<K, V> để
HashMap<K, V> có thể biết liệu hai khóa có giống nhau hay không.
PartialOrd và Ord cho so sánh thứ tự
Trait PartialOrd cho phép bạn so sánh các thể hiện của một kiểu để sắp xếp.
Một kiểu triển khai PartialOrd có thể được sử dụng với các toán tử <, >,
<= và >=. Bạn chỉ có thể áp dụng trait PartialOrd cho các kiểu cũng triển
khai PartialEq.
Việc derive PartialOrd triển khai phương thức partial_cmp, trả về một
Option<Ordering> sẽ là None khi các giá trị được đưa ra không tạo ra một thứ
tự. Một ví dụ về giá trị không tạo ra thứ tự, mặc dù hầu hết các giá trị của
kiểu đó có thể được so sánh, là giá trị số dấu phẩy động NaN. Gọi
partial_cmp với bất kỳ số dấu phẩy động nào và giá trị dấu phẩy động NaN sẽ
trả về None.
Khi được derive trên struct, PartialOrd so sánh hai thể hiện bằng cách so sánh
giá trị trong mỗi trường theo thứ tự mà các trường xuất hiện trong định nghĩa
struct. Khi được derive trên enum, các biến thể của enum được khai báo sớm hơn
trong định nghĩa enum được coi là nhỏ hơn các biến thể được liệt kê sau đó.
Trait PartialOrd được yêu cầu, ví dụ, cho phương thức gen_range từ crate
rand tạo ra một giá trị ngẫu nhiên trong phạm vi được chỉ định bởi một biểu
thức phạm vi.
Trait Ord cho phép bạn biết rằng đối với bất kỳ hai giá trị nào của kiểu được
chú thích, một thứ tự hợp lệ sẽ tồn tại. Trait Ord triển khai phương thức
cmp, trả về một Ordering thay vì một Option<Ordering> vì một thứ tự hợp lệ
sẽ luôn có thể xảy ra. Bạn chỉ có thể áp dụng trait Ord cho các kiểu cũng
triển khai PartialOrd và Eq (và Eq yêu cầu PartialEq). Khi được derive
trên struct và enum, cmp hoạt động giống như triển khai được derive cho
partial_cmp với PartialOrd.
Một ví dụ về khi Ord được yêu cầu là khi lưu trữ giá trị trong BTreeSet<T>,
một cấu trúc dữ liệu lưu trữ dữ liệu dựa trên thứ tự sắp xếp của các giá trị.
Clone và Copy để Sao chép Giá trị
Trait Clone cho phép bạn tạo một bản sao sâu của một giá trị một cách rõ ràng,
và quá trình sao chép có thể liên quan đến việc chạy mã tùy ý và sao chép dữ
liệu trên heap. Xem phần Biến và Dữ liệu Tương tác với
Clone trong Chương 4
để biết thêm thông tin về Clone.
Việc derive Clone triển khai phương thức clone, khi được triển khai cho toàn
bộ kiểu, gọi clone trên từng phần của kiểu. Điều này có nghĩa là tất cả các
trường hoặc giá trị trong kiểu cũng phải triển khai Clone để derive Clone.
Một ví dụ về khi Clone được yêu cầu là khi gọi phương thức to_vec trên một
slice. Slice không sở hữu các thể hiện kiểu mà nó chứa, nhưng vector trả về từ
to_vec sẽ cần sở hữu các thể hiện của nó, vì vậy to_vec gọi clone trên mỗi
mục. Do đó, kiểu được lưu trữ trong slice phải triển khai Clone.
Trait Copy cho phép bạn sao chép một giá trị bằng cách chỉ sao chép các bit
được lưu trữ trên ngăn xếp; không cần mã tùy ý nào. Xem phần "Dữ liệu
Chỉ-Ngăn-Xếp: Copy" trong Chương 4 để biết
thêm thông tin về Copy.
Trait Copy không định nghĩa bất kỳ phương thức nào để ngăn chặn các lập trình
viên ghi đè các phương thức đó và vi phạm giả định rằng không có mã tùy ý nào
đang được chạy. Bằng cách đó, tất cả các lập trình viên có thể giả định rằng
việc sao chép một giá trị sẽ rất nhanh.
Bạn có thể derive Copy trên bất kỳ kiểu nào mà tất cả các phần của nó đều
triển khai Copy. Một kiểu triển khai Copy cũng phải triển khai Clone bởi
vì một kiểu triển khai Copy có một triển khai tầm thường của Clone thực hiện
cùng một nhiệm vụ như Copy.
Trait Copy hiếm khi được yêu cầu; các kiểu triển khai Copy có các tối ưu hóa
khả dụng, có nghĩa là bạn không phải gọi clone, điều này làm cho mã ngắn gọn
hơn.
Mọi thứ có thể làm được với Copy bạn cũng có thể thực hiện với Clone, nhưng
mã có thể chậm hơn hoặc phải sử dụng clone ở nhiều nơi.
Hash để Ánh xạ một Giá trị thành một Giá trị có Kích thước Cố định
Trait Hash cho phép bạn lấy một thể hiện của một kiểu có kích thước tùy ý và
ánh xạ thể hiện đó thành một giá trị có kích thước cố định bằng cách sử dụng một
hàm băm. Việc derive Hash triển khai phương thức hash. Triển khai được
derive của phương thức hash kết hợp kết quả của việc gọi hash trên từng phần
của kiểu, có nghĩa là tất cả các trường hoặc giá trị cũng phải triển khai Hash
để derive Hash.
Một ví dụ về khi Hash được yêu cầu là trong việc lưu trữ khóa trong
HashMap<K, V> để lưu trữ dữ liệu một cách hiệu quả.
Default cho Giá trị Mặc định
Trait Default cho phép bạn tạo một giá trị mặc định cho một kiểu. Việc derive
Default triển khai hàm default. Triển khai được derive của hàm default gọi
hàm default trên từng phần của kiểu, có nghĩa là tất cả các trường hoặc giá
trị trong kiểu cũng phải triển khai Default để derive Default.
Hàm Default::default thường được sử dụng kết hợp với cú pháp cập nhật struct
được thảo luận trong phần "Tạo Thể hiện từ Các Thể hiện Khác với Cú pháp Cập
nhật
Struct"
trong Chương 5. Bạn có thể tùy chỉnh một vài trường của một struct và sau đó
thiết lập và sử dụng giá trị mặc định cho phần còn lại của các trường bằng cách
sử dụng ..Default::default().
Trait Default được yêu cầu khi bạn sử dụng phương thức unwrap_or_default
trên các thể hiện Option<T>, ví dụ. Nếu Option<T> là None, phương thức
unwrap_or_default sẽ trả về kết quả của Default::default cho kiểu T được
lưu trữ trong Option<T>.
Phụ lục D: Công cụ Phát triển Hữu ích
Trong phụ lục này, chúng ta nói về một số công cụ phát triển hữu ích mà dự án Rust cung cấp. Chúng ta sẽ xem xét định dạng tự động, cách nhanh chóng để áp dụng các sửa lỗi cảnh báo, công cụ kiểm tra và tích hợp với các IDE.
Định dạng Tự động với rustfmt
Công cụ rustfmt định dạng lại mã của bạn theo phong cách mã của cộng đồng.
Nhiều dự án hợp tác sử dụng rustfmt để ngăn chặn các tranh cãi về phong cách
nào để sử dụng khi viết Rust: Mọi người đều định dạng mã của họ bằng công cụ
này.
Cài đặt Rust bao gồm rustfmt theo mặc định, vì vậy bạn nên đã có sẵn các
chương trình rustfmt và cargo-fmt trên hệ thống của mình. Hai lệnh này tương
tự như rustc và cargo ở chỗ rustfmt cho phép kiểm soát chi tiết hơn và
cargo-fmt hiểu các quy ước của dự án sử dụng Cargo. Để định dạng bất kỳ dự án
Cargo nào, hãy nhập như sau:
$ cargo fmt
Chạy lệnh này sẽ định dạng lại tất cả mã Rust trong crate hiện tại. Điều này chỉ
nên thay đổi phong cách mã, không phải ngữ nghĩa mã. Để biết thêm thông tin về
rustfmt, hãy xem tài liệu của nó.
Sửa Mã của Bạn với rustfix
Công cụ rustfix được bao gồm trong cài đặt Rust và có thể tự động sửa các cảnh
báo của trình biên dịch có cách rõ ràng để sửa vấn đề mà có thể là điều bạn
muốn. Bạn có thể đã thấy các cảnh báo của trình biên dịch trước đây. Ví dụ, hãy
xem xét mã này:
Tên tệp: src/main.rs
fn main() { let mut x = 42; println!("{x}"); }
Ở đây, chúng ta đang định nghĩa biến x là có thể thay đổi, nhưng chúng ta
không bao giờ thực sự thay đổi nó. Rust cảnh báo chúng ta về điều đó:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
Cảnh báo gợi ý rằng chúng ta nên xóa từ khóa mut. Chúng ta có thể tự động áp
dụng gợi ý đó bằng cách sử dụng công cụ rustfix bằng cách chạy lệnh
cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Khi chúng ta xem lại src/main.rs, chúng ta sẽ thấy rằng cargo fix đã thay
đổi mã:
Tên tệp: src/main.rs
fn main() { let x = 42; println!("{x}"); }
Biến x giờ đây không thể thay đổi, và cảnh báo không còn xuất hiện nữa.
Bạn cũng có thể sử dụng lệnh cargo fix để chuyển đổi mã của mình giữa các
phiên bản Rust khác nhau. Các phiên bản được đề cập trong Phụ lục
E.
Kiểm tra Nhiều hơn với Clippy
Công cụ Clippy là một bộ sưu tập các công cụ kiểm tra để phân tích mã của bạn để bạn có thể phát hiện các lỗi thông thường và cải thiện mã Rust của mình. Clippy được bao gồm trong cài đặt Rust tiêu chuẩn.
Để chạy kiểm tra của Clippy trên bất kỳ dự án Cargo nào, hãy nhập như sau:
$ cargo clippy
Ví dụ, giả sử bạn viết một chương trình sử dụng một giá trị xấp xỉ của một hằng số toán học, như pi, như chương trình này:
fn main() { let x = 3.1415; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Chạy cargo clippy trên dự án này sẽ dẫn đến lỗi này:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Lỗi này cho bạn biết rằng Rust đã có một hằng số PI chính xác hơn được định
nghĩa sẵn, và chương trình của bạn sẽ chính xác hơn nếu bạn sử dụng hằng số đó
thay vì. Sau đó bạn sẽ thay đổi mã của mình để sử dụng hằng số PI.
Mã sau đây không gây ra bất kỳ lỗi hoặc cảnh báo nào từ Clippy:
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Để biết thêm thông tin về Clippy, hãy xem tài liệu của nó.
Tích hợp IDE bằng rust-analyzer
Để giúp tích hợp IDE, cộng đồng Rust khuyến nghị sử dụng
rust-analyzer. Công cụ này là một bộ các tiện
ích tập trung vào trình biên dịch, nói Giao thức Máy chủ Ngôn ngữ, đây là một đặc tả cho các IDE và ngôn ngữ lập trình để giao tiếp với
nhau. Các máy khách khác nhau có thể sử dụng rust-analyzer, chẳng hạn như plug-in
Rust analyzer cho Visual Studio Code.
Truy cập trang chủ của dự án rust-analyzer trang
chủ để biết hướng dẫn cài đặt, sau đó cài đặt hỗ
trợ máy chủ ngôn ngữ trong IDE cụ thể của bạn. IDE của bạn sẽ có được các khả
năng như tự động hoàn thành, chuyển đến định nghĩa và lỗi nội tuyến.
Phụ lục E: Các Phiên bản
Trong Chương 1, bạn đã thấy rằng cargo new thêm một số siêu dữ liệu vào file
Cargo.toml của bạn về phiên bản. Phụ lục này nói về ý nghĩa của điều đó!
Ngôn ngữ và trình biên dịch Rust có chu kỳ phát hành sáu tuần một lần, có nghĩa là người dùng nhận được một dòng liên tục các tính năng mới. Các ngôn ngữ lập trình khác phát hành những thay đổi lớn hơn ít thường xuyên hơn; Rust phát hành các bản cập nhật nhỏ hơn thường xuyên hơn. Sau một thời gian, tất cả những thay đổi nhỏ này cộng lại. Nhưng từ phiên bản này sang phiên bản khác, có thể khó để nhìn lại và nói, "Wow, giữa Rust 1.10 và Rust 1.31, Rust đã thay đổi rất nhiều!"
Cứ khoảng ba năm một lần, đội ngũ Rust tạo ra một phiên bản Rust mới. Mỗi phiên bản tập hợp các tính năng đã ra mắt thành một gói rõ ràng với tài liệu và công cụ được cập nhật đầy đủ. Các phiên bản mới được phát hành như một phần của quy trình phát hành sáu tuần một lần thông thường.
Các phiên bản phục vụ những mục đích khác nhau cho những người khác nhau:
- Đối với người dùng Rust tích cực, một phiên bản mới tập hợp các thay đổi tăng dần thành một gói dễ hiểu.
- Đối với người không phải người dùng, một phiên bản mới báo hiệu rằng một số cải tiến lớn đã xuất hiện, điều này có thể khiến Rust đáng để xem xét lại.
- Đối với những người phát triển Rust, một phiên bản mới cung cấp một điểm tụ họp cho dự án nói chung.
Tại thời điểm viết bài này, có bốn phiên bản Rust: Rust 2015, Rust 2018, Rust 2021, và Rust 2024. Cuốn sách này được viết bằng các cách dùng của phiên bản Rust 2024.
Khóa edition trong Cargo.toml chỉ ra phiên bản nào trình biên dịch nên sử
dụng cho mã của bạn. Nếu khóa không tồn tại, Rust sử dụng 2015 làm giá trị
phiên bản vì lý do tương thích ngược.
Mỗi dự án có thể chọn một phiên bản khác với phiên bản mặc định 2015. Các phiên bản có thể chứa các thay đổi không tương thích, chẳng hạn như bao gồm một từ khóa mới xung đột với các định danh trong mã. Tuy nhiên, trừ khi bạn chọn những thay đổi đó, mã của bạn sẽ tiếp tục được biên dịch ngay cả khi bạn nâng cấp phiên bản trình biên dịch Rust mà bạn sử dụng.
Tất cả các phiên bản trình biên dịch Rust hỗ trợ bất kỳ phiên bản nào tồn tại trước khi phát hành trình biên dịch đó, và chúng có thể liên kết các crate của bất kỳ phiên bản được hỗ trợ nào với nhau. Các thay đổi phiên bản chỉ ảnh hưởng đến cách trình biên dịch phân tích mã ban đầu. Do đó, nếu bạn đang sử dụng Rust 2015 và một trong những dependency của bạn sử dụng Rust 2018, dự án của bạn sẽ biên dịch được và có thể sử dụng dependency đó. Tình huống ngược lại, nơi dự án của bạn sử dụng Rust 2018 và một dependency sử dụng Rust 2015, cũng hoạt động tốt.
Để làm rõ: Hầu hết các tính năng sẽ có sẵn trên tất cả các phiên bản. Các nhà phát triển sử dụng bất kỳ phiên bản Rust nào sẽ tiếp tục thấy những cải tiến khi các phiên bản ổn định mới được phát hành. Tuy nhiên, trong một số trường hợp, chủ yếu khi các từ khóa mới được thêm, một số tính năng mới chỉ có thể có sẵn trong các phiên bản sau. Bạn sẽ cần chuyển đổi phiên bản nếu bạn muốn tận dụng các tính năng như vậy.
Để biết thêm chi tiết, hãy xem Hướng dẫn Phiên bản Rust. Đây
là một cuốn sách hoàn chỉnh liệt kê các khác biệt giữa các phiên bản và giải
thích cách tự động nâng cấp mã của bạn lên phiên bản mới thông qua cargo fix.
Phụ lục F: Các bản dịch của Sách
Cho các tài nguyên bằng ngôn ngữ khác ngoài tiếng Anh. Hầu hết vẫn đang được tiến hành; xem nhãn Translations để giúp đỡ hoặc cho chúng tôi biết về một bản dịch mới!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O'zbek
- Tiếng Việt
- Italiano
- বাংলা
Phụ lục G - Cách Rust Được Tạo Ra và "Rust Nightly"
Phụ lục này nói về cách Rust được tạo ra và điều đó ảnh hưởng như thế nào đến bạn với tư cách là một nhà phát triển Rust.
Sự Ổn Định Không Đình Trệ
Là một ngôn ngữ, Rust quan tâm rất nhiều về tính ổn định của mã của bạn. Chúng tôi muốn Rust trở thành nền tảng vững chắc mà bạn có thể xây dựng trên đó, và nếu mọi thứ liên tục thay đổi, điều đó sẽ là không thể. Đồng thời, nếu chúng ta không thể thử nghiệm với các tính năng mới, chúng ta có thể không phát hiện ra những lỗi quan trọng cho đến sau khi phát hành, khi chúng ta không thể thay đổi mọi thứ nữa.
Giải pháp của chúng tôi cho vấn đề này là điều chúng tôi gọi là "sự ổn định không đình trệ", và nguyên tắc hướng dẫn của chúng tôi là: bạn không bao giờ phải lo sợ việc nâng cấp lên phiên bản mới của Rust ổn định. Mỗi lần nâng cấp nên diễn ra suôn sẻ, nhưng cũng nên mang đến cho bạn các tính năng mới, ít lỗi hơn và thời gian biên dịch nhanh hơn.
Choo, Choo! Các Kênh Phát Hành và Đi Theo Các Đoàn Tàu
Sự phát triển của Rust hoạt động theo một lịch trình đoàn tàu. Nghĩa là, tất cả sự phát triển được thực hiện trong nhánh main của kho lưu trữ Rust. Các phiên bản phát hành tuân theo mô hình đoàn tàu phát hành phần mềm, đã được sử dụng bởi Cisco IOS và các dự án phần mềm khác. Có ba kênh phát hành cho Rust:
- Nightly
- Beta
- Stable
Hầu hết các nhà phát triển Rust chủ yếu sử dụng kênh ổn định, nhưng những người muốn thử các tính năng mới có thể sử dụng nightly hoặc beta.
Dưới đây là một ví dụ về cách quá trình phát triển và phát hành hoạt động: giả sử rằng nhóm Rust đang làm việc trên phiên bản Rust 1.5. Phiên bản đó đã được phát hành vào tháng 12 năm 2015, nhưng nó sẽ cung cấp cho chúng ta các số phiên bản thực tế. Một tính năng mới được thêm vào Rust: một commit mới được đưa vào nhánh main. Mỗi đêm, một phiên bản nightly mới của Rust được tạo ra. Mỗi ngày là một ngày phát hành, và các phiên bản này được tạo ra bởi cơ sở hạ tầng phát hành của chúng tôi một cách tự động. Vì vậy, theo thời gian, các phiên bản của chúng tôi trông như thế này, mỗi đêm một lần:
nightly: * - - * - - *
Cứ mỗi sáu tuần, đã đến lúc chuẩn bị một phiên bản mới! Nhánh beta của kho lưu
trữ Rust tách ra từ nhánh main được sử dụng bởi nightly. Bây giờ, có hai phiên
bản:
nightly: * - - * - - *
|
beta: *
Hầu hết người dùng Rust không sử dụng các phiên bản beta một cách tích cực, nhưng kiểm tra chống lại beta trong hệ thống CI của họ để giúp Rust phát hiện các lỗi có thể xảy ra. Trong khi đó, vẫn có một phiên bản nightly mỗi đêm:
nightly: * - - * - - * - - * - - *
|
beta: *
Giả sử một lỗi được phát hiện. Thật may mắn là chúng tôi đã có thời gian để kiểm
tra phiên bản beta trước khi lỗi này lẻn vào phiên bản ổn định! Bản sửa lỗi được
áp dụng cho nhánh main, để nightly được sửa, và sau đó bản sửa lỗi được chuyển
lại cho nhánh beta, và một phiên bản beta mới được tạo ra:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Sáu tuần sau khi phiên bản beta đầu tiên được tạo ra, đã đến lúc phát hành phiên
bản ổn định! Nhánh stable được tạo ra từ nhánh beta:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Hoan hô! Rust 1.5 đã hoàn thành! Tuy nhiên, chúng tôi đã quên một điều: vì sáu
tuần đã trôi qua, chúng tôi cũng cần một phiên bản beta mới của phiên bản tiếp
theo của Rust, 1.6. Vì vậy, sau khi stable tách ra từ beta, phiên bản tiếp
theo của beta lại tách ra từ nightly:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
Điều này được gọi là "mô hình đoàn tàu" vì cứ mỗi sáu tuần, một phiên bản "rời khỏi nhà ga", nhưng vẫn phải trải qua một hành trình qua kênh beta trước khi nó đến như một phiên bản ổn định.
Rust phát hành mỗi sáu tuần, như đồng hồ. Nếu bạn biết ngày của một phiên bản Rust, bạn có thể biết ngày của phiên bản tiếp theo: nó là sáu tuần sau đó. Một khía cạnh hay của việc có các phiên bản được lên lịch mỗi sáu tuần là đoàn tàu tiếp theo đang đến sớm. Nếu một tính năng tình cờ bỏ lỡ một phiên bản cụ thể, không cần phải lo lắng: một phiên bản khác đang diễn ra trong thời gian ngắn! Điều này giúp giảm áp lực để lén lút các tính năng có thể chưa hoàn thiện vào gần thời hạn phát hành.
Nhờ quá trình này, bạn luôn có thể kiểm tra bản dựng tiếp theo của Rust và tự
mình xác minh rằng việc nâng cấp là dễ dàng: nếu một phiên bản beta không hoạt
động như mong đợi, bạn có thể báo cáo cho nhóm và sửa lỗi trước khi phiên bản ổn
định tiếp theo diễn ra! Sự cố trong một phiên bản beta là tương đối hiếm, nhưng
rustc vẫn là một phần mềm, và lỗi vẫn tồn tại.
Thời gian bảo trì
Dự án Rust hỗ trợ phiên bản ổn định mới nhất. Khi một phiên bản ổn định mới được phát hành, phiên bản cũ sẽ đạt đến cuối vòng đời (EOL). Điều này có nghĩa là mỗi phiên bản được hỗ trợ trong sáu tuần.
Các Tính Năng Không Ổn Định
Có một điều nữa với mô hình phát hành này: các tính năng không ổn định. Rust sử dụng một kỹ thuật gọi là "cờ tính năng" để xác định các tính năng nào được kích hoạt trong một phiên bản nhất định. Nếu một tính năng mới đang được phát triển tích cực, nó sẽ được đưa vào nhánh main, và do đó, trong nightly, nhưng đằng sau một cờ tính năng. Nếu bạn, với tư cách là người dùng, muốn thử tính năng đang trong quá trình phát triển, bạn có thể, nhưng bạn phải sử dụng phiên bản nightly của Rust và chú thích mã nguồn của bạn với cờ thích hợp để chọn tham gia.
Nếu bạn đang sử dụng phiên bản beta hoặc ổn định của Rust, bạn không thể sử dụng bất kỳ cờ tính năng nào. Đây là chìa khóa cho phép chúng tôi sử dụng thực tế với các tính năng mới trước khi chúng tôi tuyên bố chúng ổn định mãi mãi. Những người muốn tham gia vào cạnh tiên tiến có thể làm như vậy, và những người muốn có trải nghiệm vững chắc có thể gắn bó với ổn định và biết rằng mã của họ sẽ không bị hỏng. Sự ổn định không đình trệ.
Cuốn sách này chỉ chứa thông tin về các tính năng ổn định, vì các tính năng đang trong quá trình phát triển vẫn đang thay đổi, và chắc chắn chúng sẽ khác nhau giữa khi cuốn sách này được viết và khi chúng được kích hoạt trong các bản dựng ổn định. Bạn có thể tìm thấy tài liệu cho các tính năng chỉ có trong nightly trực tuyến.
Rustup và Vai Trò của Rust Nightly
Rustup giúp dễ dàng chuyển đổi giữa các kênh phát hành khác nhau của Rust, trên toàn cầu hoặc theo dự án. Theo mặc định, bạn sẽ có Rust ổn định được cài đặt. Để cài đặt nightly, ví dụ:
$ rustup toolchain install nightly
Bạn cũng có thể xem tất cả các toolchains (các phiên bản của Rust và các thành
phần liên quan) mà bạn đã cài đặt với rustup. Dưới đây là một ví dụ trên máy
tính Windows của một trong những tác giả của bạn:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Như bạn có thể thấy, toolchain ổn định là mặc định. Hầu hết người dùng Rust sử
dụng ổn định hầu hết thời gian. Bạn có thể muốn sử dụng ổn định hầu hết thời
gian, nhưng sử dụng nightly trên một dự án cụ thể, vì bạn quan tâm đến một tính
năng tiên tiến. Để làm điều đó, bạn có thể sử dụng rustup override trong thư
mục của dự án đó để đặt toolchain nightly là toolchain mà rustup nên sử dụng
khi bạn ở trong thư mục đó:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Bây giờ, mỗi khi bạn gọi rustc hoặc cargo bên trong
~/projects/needs-nightly, rustup sẽ đảm bảo rằng bạn đang sử dụng Rust
nightly, thay vì mặc định của bạn là Rust ổn định. Điều này rất hữu ích khi bạn
có nhiều dự án Rust!
Quy Trình RFC và Các Nhóm
Vậy làm thế nào để bạn biết về những tính năng mới này? Mô hình phát triển của Rust tuân theo một Quy Trình Yêu Cầu Bình Luận (RFC). Nếu bạn muốn cải thiện Rust, bạn có thể viết một đề xuất, gọi là RFC.
Bất kỳ ai cũng có thể viết RFC để cải thiện Rust, và các đề xuất được xem xét và thảo luận bởi nhóm Rust, bao gồm nhiều nhóm chủ đề. Có một danh sách đầy đủ các nhóm trên trang web của Rust, bao gồm các nhóm cho mỗi lĩnh vực của dự án: thiết kế ngôn ngữ, triển khai trình biên dịch, cơ sở hạ tầng, tài liệu và nhiều hơn nữa. Nhóm thích hợp đọc đề xuất và các bình luận, viết một số bình luận của riêng họ, và cuối cùng, có sự đồng thuận để chấp nhận hoặc từ chối tính năng.
Nếu tính năng được chấp nhận, một vấn đề được mở trên kho lưu trữ Rust, và ai đó có thể triển khai nó. Người triển khai nó rất có thể không phải là người đề xuất tính năng ban đầu! Khi việc triển khai đã sẵn sàng, nó sẽ được đưa vào nhánh main đằng sau một cờ tính năng, như chúng tôi đã thảo luận trong phần “Các Tính Năng Không Ổn Định”.
Sau một thời gian, khi các nhà phát triển Rust sử dụng các phiên bản nightly đã có thể thử tính năng mới, các thành viên nhóm sẽ thảo luận về tính năng, cách nó hoạt động trên nightly, và quyết định xem nó có nên được đưa vào Rust ổn định hay không. Nếu quyết định là tiến lên, cờ tính năng sẽ được gỡ bỏ, và tính năng này bây giờ được coi là ổn định! Nó sẽ đi theo các đoàn tàu vào một phiên bản ổn định mới của Rust.